基于生成对抗网络的文本生成图像研究综述
2023-10-21李乐阳佟国香赵迎志
李乐阳,佟国香,赵迎志,罗 琦
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着深度学习的发展,机器已经可以模仿人类根据文本描述将内容视觉化,达到信息共享和理解的效果。图像生成技术在人工智能领域具有广泛应用,例如图像修复[1]、图像到图像的转换[2]、风格转换[3]、超分辨率图像生成[4]、数据增强[5]以及表征学习[6]等。
文本生成图像可以视作是图像字幕生成的反向工作,主要包括3个任务:1)将文本中蕴含的信息提取出来;2)根据所提取的信息生成图像;3)图像真实性测试和文本-图像语义一致性匹配。在早期研究中,文本生成图像主要依赖搜索方法和监督学习的结合[7]。该方法从一般且不受限制的文本中生成图像,首先识别具有信息且“可描绘” 的文本单元,再搜索最可能出现的图像区域,从而以文本和图像区域为条件优化图像布局。然而,这种传统的图像生成方法缺乏多样性,只能通过改变给定的文本重新得到图像特征,生成图像的质量也难以保证。随着深度学习的发展,基于生成模型的图像生成技术逐渐成熟,变分自编码器(Variational Auto-Encoder, VAE)方法[8]和深度卷积注意力机制模型[9]得到了广泛关注。
基于生成模型的图像生成技术受到有限属性的限制,生成的图像大多模糊且未有效地表达文本信息,更不具备创造复杂图像的能力。文献[10]提出了生成对抗网络(Generative Adversarial Networks, GAN),GAN由两个神经网络组成:生成器和鉴别器,这两个网络通过对抗的方式进行学习。由于GAN的对抗训练思想适用于文本生成图像任务,较多相关的研究相继产生。文献[11]首次提出生成图像模型,该模型以GAN为模型骨干,同时增加文本特征作为生成器和鉴别器的约束条件,最终生成64×64的图像。文献[12]在前者的基础上提出了一种新颖的网络,该网络增加了bounding box和keypoint限定,根据本文描述的位置指定所绘制的内容,使生成的图像精度进一步提高。
随着多模态学习任务的发展,越来越多的研究人员在GAN的基础上提出富有创意的文本生成图像网络,包括:1)关注于自然语言描述中单词的注意力生成对抗网络(Attention Generative Adversarial Networks, AttnGAN)[13];2)文本分类作为条件约束图像生成的文本条件辅助分类器生成对抗网络(Text Conditional Auxiliary Classifier Generative Adversarial Networks, TAC-GAN)[14];3)首次提出分多阶段生成图像的堆叠式生成对抗网络(Stacked Generative Adversarial Networks, StackGAN)[15];4)利用场景图的Scene Graph[16];5)将图像字幕生成任务用于辅助文本生成图像的MirrorGAN框架[17];6)添加单句生成和多句判别模块的多语句辅助生成对抗网络(Multi-Statement Assisted Generative Adversarial Networks, MA-GAN)[18]等。
为了提供一个逻辑性思路,本文提出了一种分类法,将GANs模型主要归纳为3类,并详细讨论每一类的经典模型,最后介绍一些标准数据集和评价指标。
1 基于GAN的文本生成图像工作
目前,基于GANs的文本生成图像任务引起了研究人员的广泛关注。文献[19]总结了利用生成对抗网络进行图像生成和编辑应用的最新研究成果。首先,介绍了GANs变体,讨论了图像生成的应用,包括纹理生成、图像嵌入、人脸和人体图像生成。其次,讨论了约束图像生成的应用,包括图像和图像的转换、文本生成图像以及草图生成图像。然后,讨论了图像编辑和视频生成的应用。最后,提供了总结以及基于GAN方法所面临的挑战和自身的局限性。文献[20]提供了基于GAN的图像合成的详细概述,讨论了图像合成的背景和GANs变体的理论概念,并总结了几种主要的图像合成方法:直接法、迭代法、分层法以及其他方法。在每个方法中,分析了文本生成图像的不同模型,并详细介绍了几种评价指标。本文总结文本生成图像任务,并对基于GAN的各种变体做结构、技术上的讨论,进行性能对比。文献[21]讨论文本生成图像的动机和背景,将文本生成图像的任务归纳为4种类别,即语义增强GAN、分辨率增强GAN、多样性增强GAN以及运动增强GAN。文献[22]扩大了基于文本的图像生成的讨论范围,将文本信息分为3种,即普通文本、场景文本和对话文本。基于这3类文本,总结了近20种GANs变体的应用研究。文献[23]提出了一种基于监督学习的分类方法,批判性地讨论文本生成图像模型方法,突出其缺点,并确定新的研究领域。本文简要介绍GANs的基本原理,重点关注基于GAN的各种变体模型,并按照所提出的分类展开讨论。
2 文本生成图像分类和GAN框架基本原理
2.1 文本生成图像分类
本文提出4种分类法,即:注意力增强方法、多阶段增强方法、场景布局增强方法和普适性增强方法[3,8,13,16,24-57]。
2.1.1 注意力增强方法
如表1所示,注意力增强方法是GANs种类最多的方法,原因在于基于注意力的GAN框架关注自然语言文本中的重要单词或语句,生成图像中不同子区域的细粒度细节,从而更好描绘图像的纹理特征,突出重点。该方法主要包括双注意力模块[24]、特征金字塔注意力模块[25]、动态记忆模块[26]以及自注意力模块[27]等。

表1 基于注意力增强方法的GANs变体总结Table 1. Summary of GANs based on attention enhancement
2.1.2 多阶段增强方法
如表2所示,在多阶段增强方法中,GANs模型通过把多个GAN框架进行组合,达到提高图像分辨率的效果。例如采用多阶段GANs[15]、使用多个鉴别器和鉴别器进行组合[28]、渐进式地训练生成器和鉴别器[29]以及采用分层嵌套的鉴别器进行端到端训练[30]。

表2 基于多阶段增强方法的GANs变体总结Table 2. Summary of GANs based on multi-stage enhancement
2.1.3 场景布局增强方法
如表3所示,当文本描述中的对象及其之间的关系过于复杂时,研究人员考虑在GAN框架之间引入场景布局[31]进行文本信息提取,本文将其总结为场景布局增强方法。这类方法关注生成图像的质量和文本-图像语义对齐能力,例如将文本特征信息组合成有向图,经图神经网络处理后,通过级联细化网络(Cascaded Refinement Networks, CRN)将场景布局转换为图像[16]。

表3 基于场景布局增强方法的GANs变体总结Table 3. Summary of GANs based on scene layout enhancement
2.1.4 普适性增强方法
如表4所示,普适性增强方法正是基于GANs的文本生成图像领域中的常用方法,其提出一种新颖的文本信息提取方法,结合图像生成框架进行整体联合训练,在图像真实性、分辨率以及语义关系对齐等方面都有不同程度的贡献。

表4 基于普适性增强方法的GANs变体总结Table 4. Summary of GANs based on universality enhancement
2.2 GAN框架的基本原理
2.2.1 GAN
GAN[10]主要由生成器和鉴别器组成。生成器捕捉样本数据的分布来生成指定数据,鉴别器是二分类模型。生成器和鉴别器可以由各种非线性映射函数充当,例如感知机、卷积神经网络以及循环神经网络等。
以生成图像任务为例,生成器的输入服从某一简单分布的噪声变量,输出与训练图像相同尺寸的生成图像。鉴别器输入真实图像和生成图像,输出一个0~1之间生成图像是真实图像的概率。生成器欺骗鉴别器,使得鉴别器输出高概率。对于鉴别器来说,要尽可能地输出低概率。
当GAN处于初始状态时,鉴别器不能较好区分真实数据和生成数据。通过不断更新鉴别器和生成器达到平衡状态,生成数据分布和真实数据分布重合。
GAN的优化过程可以归结为一个二元极大极小博弈问题,网络损失函数如式(1)所示。
(1)
式中,pdata(x)是真实数据分布;z为随机噪声;pz为噪声分布;G为生成映射函数;D为鉴别映射函数。
2.2.2 CGAN
针对神经网络模型难以适应大量预测类别以及一对多的概率映射未被考虑等问题,文献[32]提出条件生成对抗网络(Conditional Generative Adversarial Networks, CGAN),也是对GAN框架的扩展。通过给原始GAN的生成器和鉴别器添加额外的条件信息,实现条件生成模型。网络结构如图1所示。
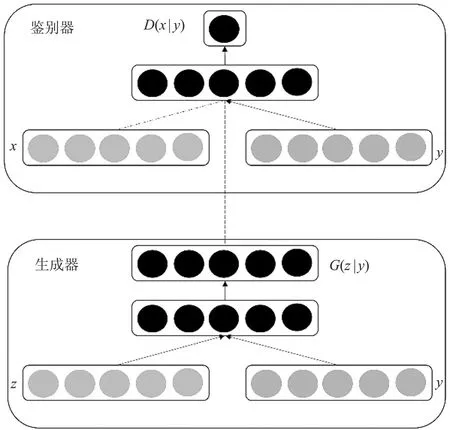
图1 CGAN结构Figure 1. Architecture of CGAN
将条件信息加入GAN中可以分两种:1)原始GAN生成器的输入是噪声信号,类别标签可以和噪声信号组合作为隐空间表示;2)原始GAN鉴别器的输入是图像数据(真实图像和生成图像),可以将类别标签和图像数据进行拼接作为鉴别器输入。
网络损失函数如式(2)所示。
(2)
2.2.3 DCGAN
文献[33]基于GAN框架提出了深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Networks, DCGAN),该网络将卷积神经网络(Convolutional Neural Networks,CNN)和GAN相结合来弥补CNN在监督学习和无监督学习之间的局限性。网络结构如图2所示,网络损失函数如式(1)所示。
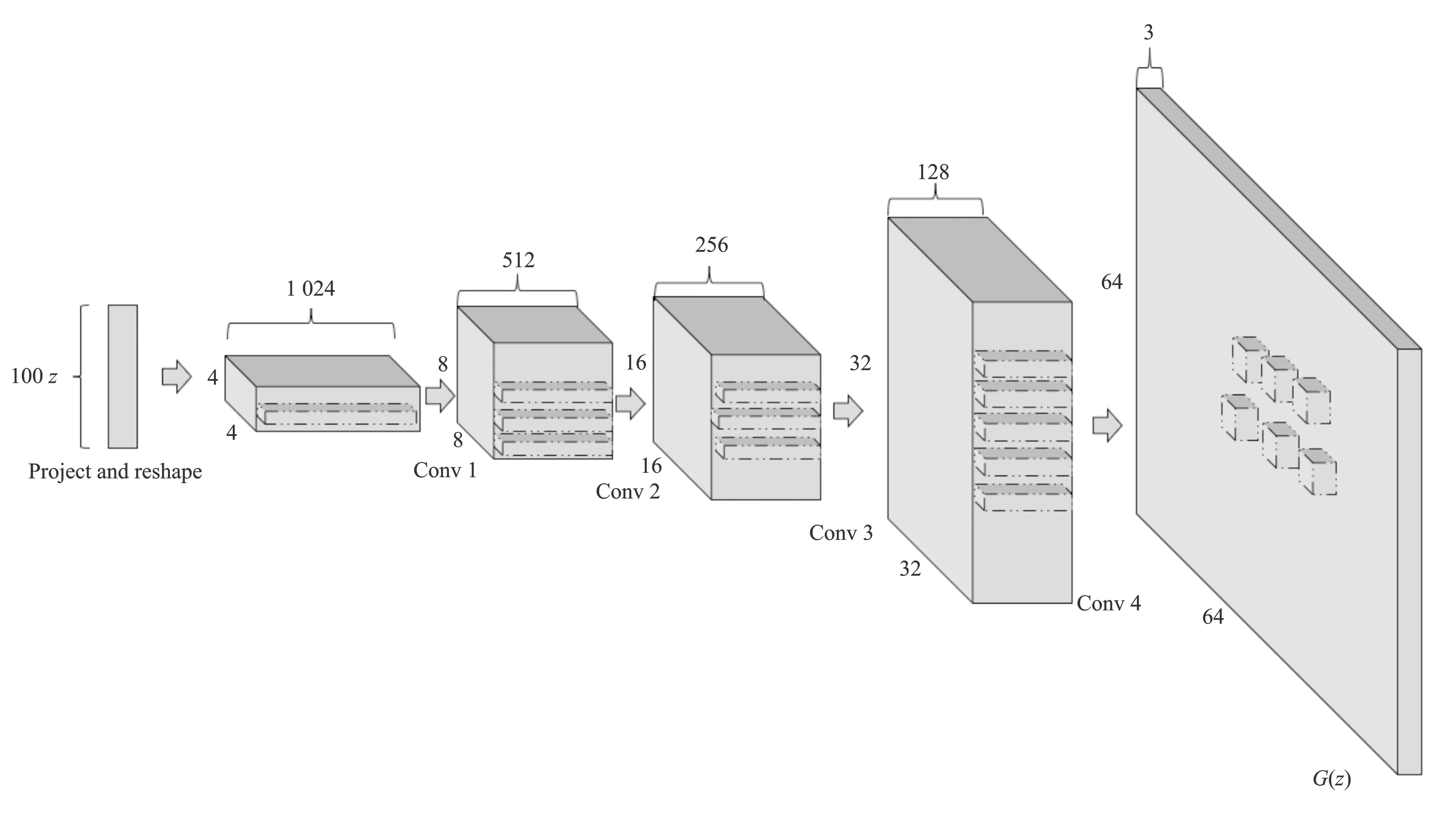
图2 DCGAN结构Figure 2. Architecture of DCGAN
相较于GAN,DCGAN具有以下改进:
1)在生成器和鉴别器中使用反卷积替代池化层;
2)在生成器和鉴别器中使用归一化;
3)在隐藏层中移除全连接层;
4)在生成器中,除了输出层使用tanh激活函数,其它层都使用ReLU激活函数;
5)在鉴别器中,所有层都使用LeakyReLU激活函数[34]。
3 文本生成图像的GANs变体
3.1 注意力增强方法
3.1.1 AttnGAN
针对当对全局文本向量进行处理而忽略单词的细粒度信息会生成低质量图像的问题,文献[13]提出了AttnGAN来优化细粒度文本到图像的生成。该网络通过关注自然语言描述中的相关词语来生成图像不同子区域的细粒度细节。在此基础上还提出了一种深层注意力多模态相似模型(Deep Attention Multimodal Similarity Model, DAMSM)来计算细粒度图文匹配损失,用于训练生成器。网络结构如图3所示。
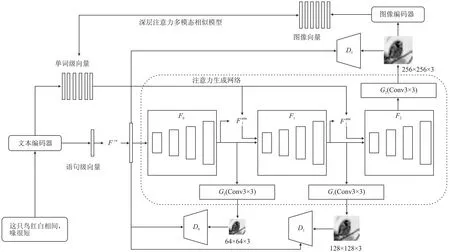
图3 AttnGAN结构 Figure 3. Architecture of AttnGAN
该网络由AttnGAN和DAMSM两大模块构成:
1)AttnGAN模块将文本向量和来自上一个隐藏层的图像向量作为输入。首先通过增加一个新的感知层将文本向量转换到图像向量的公共语义空间,再根据图像的隐藏特征为图像的每个子区域计算单词上下文向量,从而将图像向量和相应单词上下文向量结合,生成下一阶段的图像。
2)DAMSM模块学习两个神经网络。首先将图像和单词的子区域映射到一个公共语义空间,再基于单词度量图像-文本的相似度,从而计算出用于生成图像的细粒度损失。
该方法能够捕获细粒度的单词级别和子区域级别的信息,但可能在捕捉全局相干结构方面还不够完善。
3.1.2 DualAttn-GAN
针对以往图像生成方法会产生扭曲的全局结构和不自然的局部语义细节的问题,文献[24]提出了一种双重注意力生成对抗网络(Dual Attention Generative Adversarial Networks, DualAttn-GAN)。网络结构如图4所示。
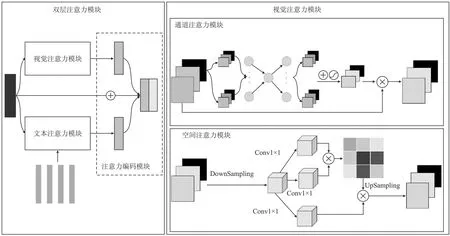
图4 DualAttn-GAN结构Figure 4. Architecture of DualAttn-GAN
该网络引入双重注意力模块,包括文本注意模块和视觉注意模块。前者探索视觉和语言之间的细粒度交互作用,后者从通道和空间层面对视觉的内部表征进行建模,能够更好地捕捉全局结构。在此基础上还提出了一种倒置残差结构来提高CNN的信息提取能力,并应用归一化来稳定GAN训练。
DualAttn-GAN的目标函数是每个鉴别器和生成器的联合条件-无条件损耗,同时被引入来联合近似条件-无条件图像分布。鉴别器的损失计算式为
(3)
生成器的损失计算式如式(4)所示。
(4)
DualAttn-GAN能够关注相关词和不同视觉区域的相关特征来增强局部细节和全局结构,但在一定程度上缺少对图像的多样性约束。
3.1.3 FesFPA-GAN
针对GAN训练过程中容易出现图像与文本内容不一致以及模型崩溃[35]等问题,文献[25]提出了一种残差块特征金字塔注意力生成对抗网络(Residual Block Feature Pyramid Attention Generative Adversarial Networks, FesFPA-GAN)。该网络嵌入特征金字塔结构进行特征融合,从而实现细粒度的图像生成,网络结构如图5所示。
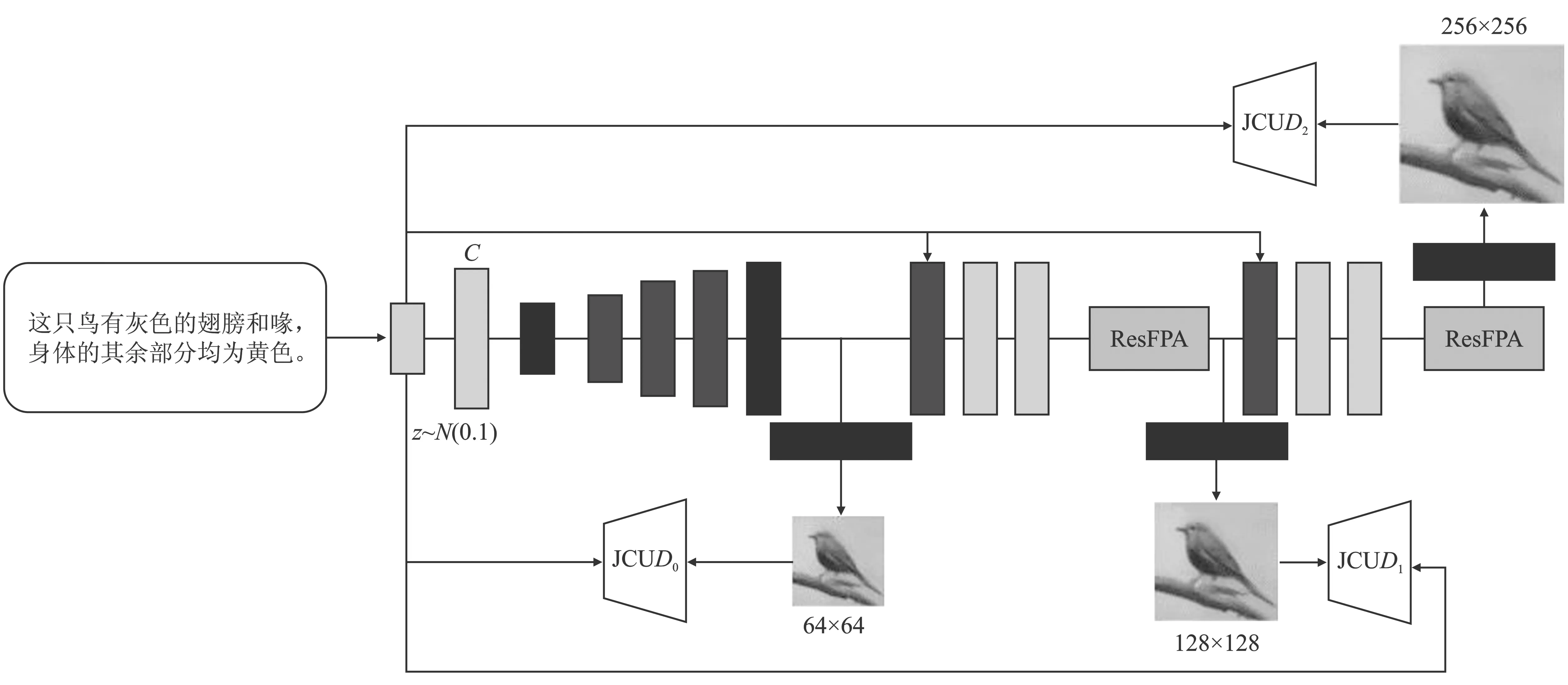
图5 FesFPA-GAN结构 Figure 5. Architecture of FesFPA-GAN
编码器对文本描述进行编码,生成文本嵌入向量,再与噪声向量进行拼接,经过全连接和形状重塑进行迭代训练网络。FesFPA-GAN由3个生成器和3个鉴别器组成,每个生成器用于捕获当前尺度下的图像分布,每个鉴别器用于计算当前阶段得到样本的概率。
FesFPA-GAN的网络损失函数如式(3)和式(5)所示。与DualAttn-GAN类似,将F0和Fi的条件向量转换为输入,例如h0=F0(c,z)和h1=F0(hi-1,c)。噪声向量被条件向量代替,使得生成器能够完善更多的图像细节。
FesFPA-GAN通过嵌入特征金字塔结构引入多尺度特征融合,但在更复杂场景下生成图像容易出现分辨率不高的问题。
3.1.4 性能对比
表5给出了在3个常用数据上几种注意力增强方法IS值的比较。可以看出,早期典型的注意力增强方法效果并不理想,特别是在CUB鸟类数据集中IS值普遍较低。随着研究的不断深入,生成图像的质量和真实性进一步提升,图像和文本的语义一致性得到增强。文献[27]使用自注意机制有效地提取文本特征,取得了较高的IS值。
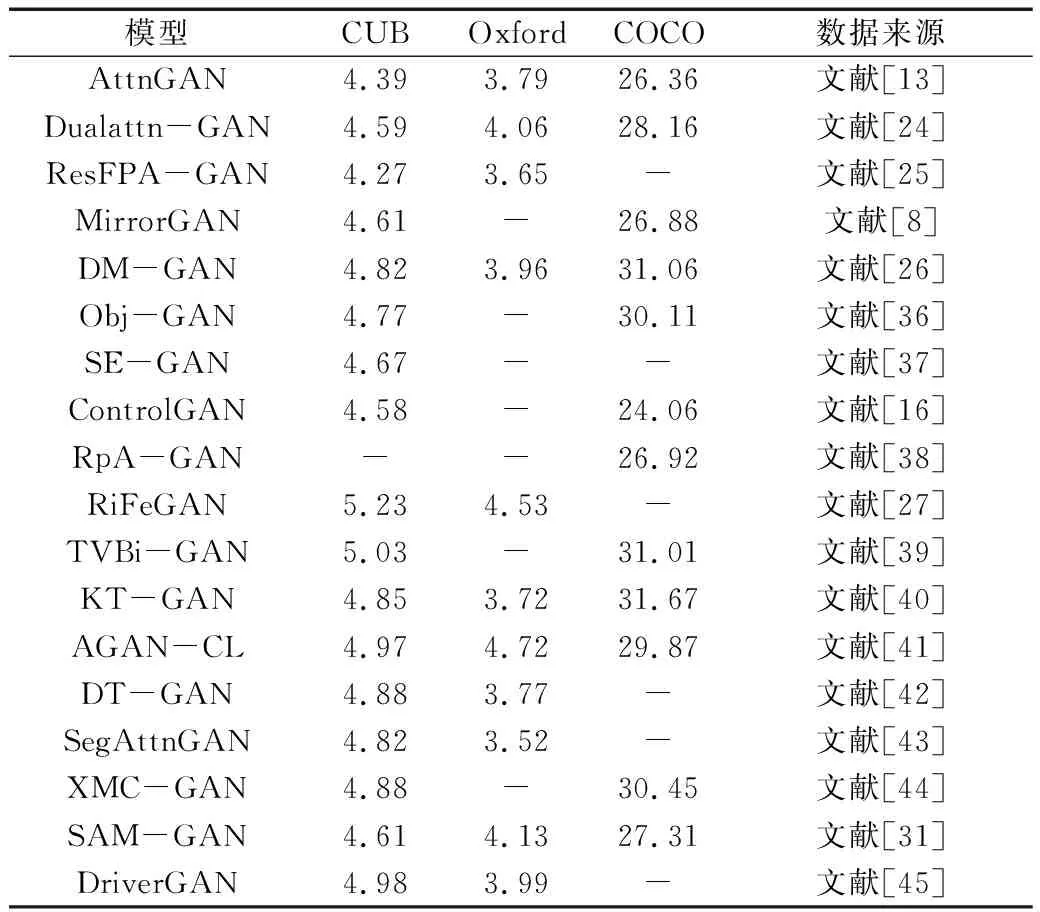
表5 几种典型的注意力增强方法IS值比较Table 5. Comparison of IS of typical attention enhancement methods
3.2 多阶段增强方法
3.2.1 StackGAN
文献[15]提出了StackGAN来生成256×256的图像。在此基础上还引入一种新的条件增强技术,该技术使得图像生成更加平滑。网络结构如图6所示。
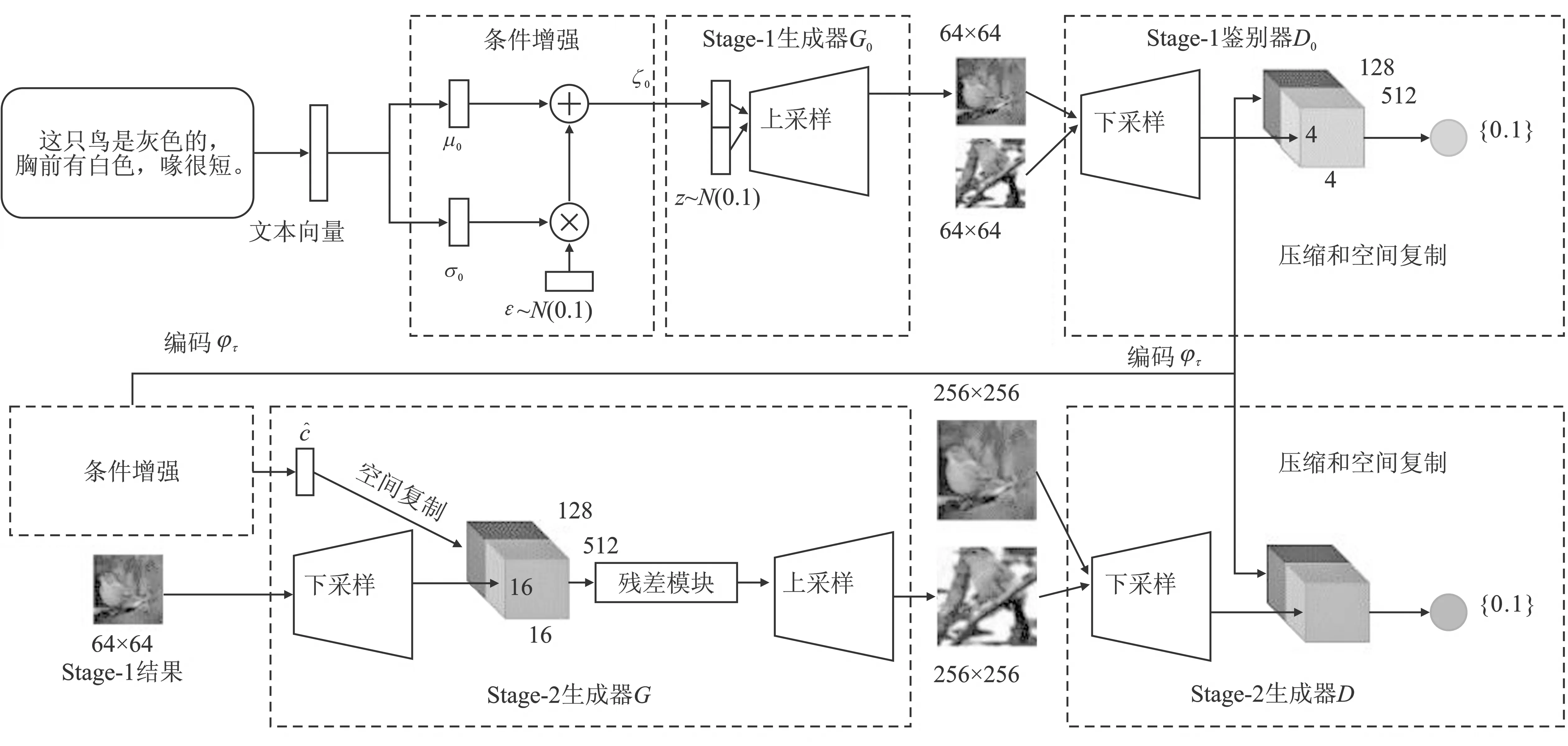
图6 AttnGAN结构 Figure 6. Architecture of AttnGAN
StackGAN网络分为两个阶段,第1阶段根据给定的文本描述绘制文本对象的基本形状和颜色,并从随机噪声向量中绘制背景布局,从而产生低分辨率图像。第2阶段将文本描述和第1阶段输出的低分辨率图像作为输入来纠正第1阶段结果中的缺陷,并通过再次提取文本描述来完善对象细节,生成具有照片级的高分辨率图像。
第1阶段的生成器损失函数LG如式(5)所示。
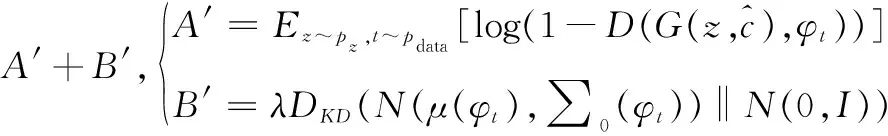
(5)
第1阶段的鉴别器损失函数LD如式(6)所示。
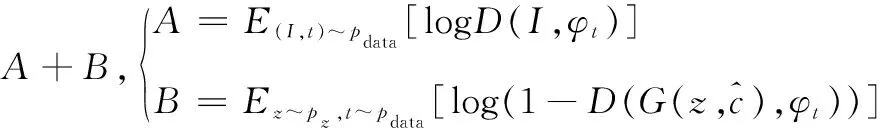
(6)
第2阶段的生成器损失函数LG如式(7)所示。
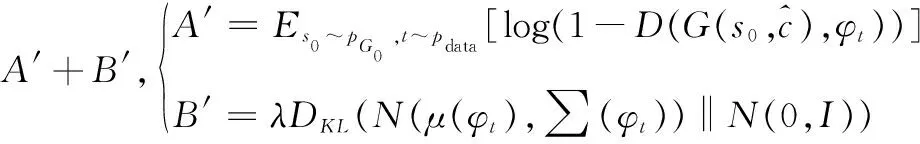
(7)
第2阶段的鉴别器损失函数LD如式(8)所示。
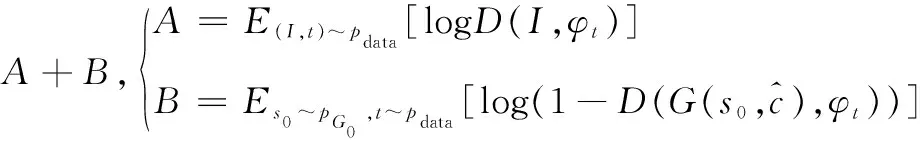
(8)
3.2.2 StackGAN++
针对条件生成任务和无条件生成任务,文献[15]基于StackGAN网络进一步提出了多级生成性对抗网络结构(Stacked++ Generative Adversarial Networks, StackGAN++)。该网络由树状结构排列的多个生成器和多个鉴别器组成[46],网络结构如图7所示。
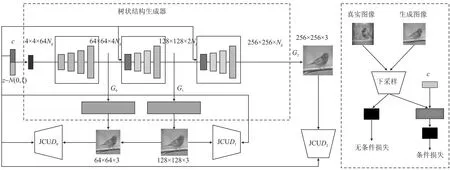
图7 StackGAN++结构Figure 7. Architecture of StackGAN++
StackGAN++网络由多个生成器和鉴别器组成,并将其以树状结构排列,树的不同分支会生成同一场景的多个尺度图像[47]。在每个分支上,生成器会捕获该尺度上的图像分布,鉴别器度量样本概率。第1阶段将噪声向量和条件变量组合到第1个生成器,该生成器在默认情况下生成64×64的低分辨率图像。之后的每个阶段会使用前一阶段的结果和条件变量来产生高分辨率图像。最后阶段会产生256×256的高质量图像。
3.2.3 性能对比
表6给出了在3个常用数据上几种多阶段增强方法IS值的比较。与表5相比,注意力增强方法的IS值明显高于多阶段增强方法的IS值,生成图像效果相对较好。注意力增强方法相较于其他方法更能捕捉图像中的细节特征,在细粒度上关注重点,对文本生成图像领域作用较
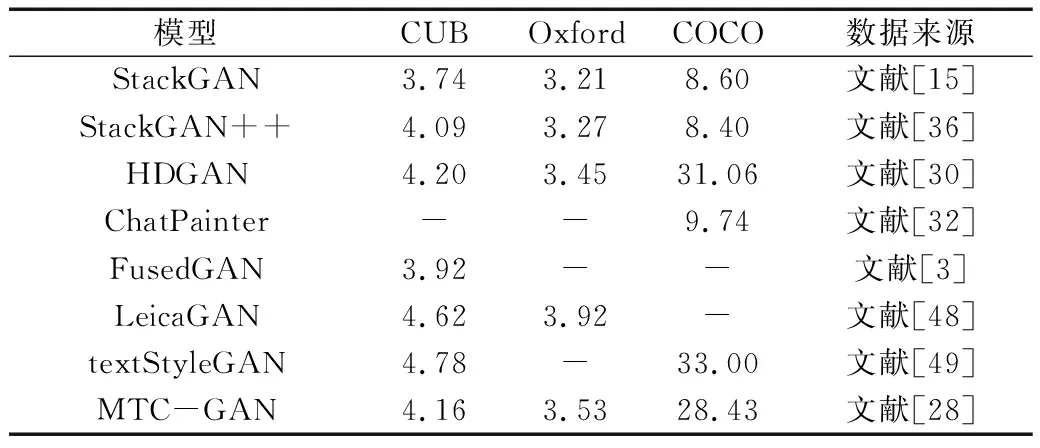
表6 几种典型的多阶段增强方法IS值比较Table 6. Comparison of IS of typical multi-stage enhancement methods
大。在多阶段增强方法中,textStyleGAN的IS值较高,表明在潜在语义空间中生成图像效果较好。此外,StackGAN++相比于StackGAN在各个指标均得到一定提升,表明将生成器和鉴别器组织成树状结构,能够使模型性能进一步提升。
3.3 场景布局增强方法
3.3.1 Scene Graph
针对以往方法难以处理包含复杂场景文本的问题,文献[16]提出了一种从场景图生成图像的方法(Scene Graph),能够显式地推理文本中对象及其关系。该方法使用图卷积神经网络[37]来处理输入图形,通过预测对象的边界框和分割子区域来计算出场景布局,并利用级联优化网络将场景布局转换为图像。网络结构如图8所示。
Scene Graph的输入是包含对象及其关系的场景图。首先利用图卷积神经网络进行处理,图卷积神经网络沿边传递信息,计算出所有对象的嵌入向量,用于预测对象的边界框和分割掩码,并将其组合成场景布局,从而使用CRN将场景布局转换为图像。此外,该网络使用一对鉴别器进行对抗训练。网络损失函数如式(9)所示。
LGAN=EX~preallogD(x)+EX~pfakelog(1-D(x))
(9)
Scene Graph能够明确地推理对象和关系,并生成包含较多可识别的复杂图像,但易产生图像不够清晰、分辨率不高等问题。
3.3.2 InferringGAN
文献[50]提出一种新颖的基于语义布局推理的层次化文本生成图像方法InferringGAN。该方法首先由布局生成器从文本构建语义布局,再通过图像生成器将布局转换为图像。不仅可以生成语义层面上具有意义的图像,还可以通过修改生成场景布局来自动标注图像和过程。网络结构如图9所示。
InferringGAN主要由框生成器、形状生成器以及图像生成器组成:
1)框生成器接收一个文本向量作为输入,并通过在图像中组合对象实例来生成一个粗糙的布局。最后输出的是一组边界框B1:T={B1,…,BT},其中每个边界框BT定义了第t个对象的位置、大小以及类别标签。
2)形状生成器接收一组边界框,再预测框内对象的形状。最后输出的是一组二进制掩码M1:T={M1,…,MT},其中每个二进制掩码MT定义了第t个对象的基本形状。
3)图像生成器通过聚合掩码获取语义标签映射关系M,并将文本向量作为输入,再通过将语义布局转换为与文本描述匹配的图像。
通过优化损失函数Limg如式(10)所示,对生成器和鉴别器进行联合训练。
(10)
InferringGAN能够生成保留语义细节并与文本描述高度相关的复杂图像,且其预测的布局可用于控制,但面对复杂场景的图像,预测的对象位置不够精确,缺乏对位置约束。
3.3.3 性能对比
表7给出了在3个常用数据上几种多阶段增强方法IS值的比较。基于COCO数据集与表5和表6可以看出,场景布局方法的IS值相对较低。文献[39]在COCO数据集上IS值较高,使用边框回归网络计算每个实例的类别和位置的布局,能够提取更理想的图像特征。由此可以看出,文本生成图像应该利用场景布局方法处理文本,将多阶段骨架作为网络主干,把注意力机制作为辅助工具,三者结合能够达到更好的图像生成效果。
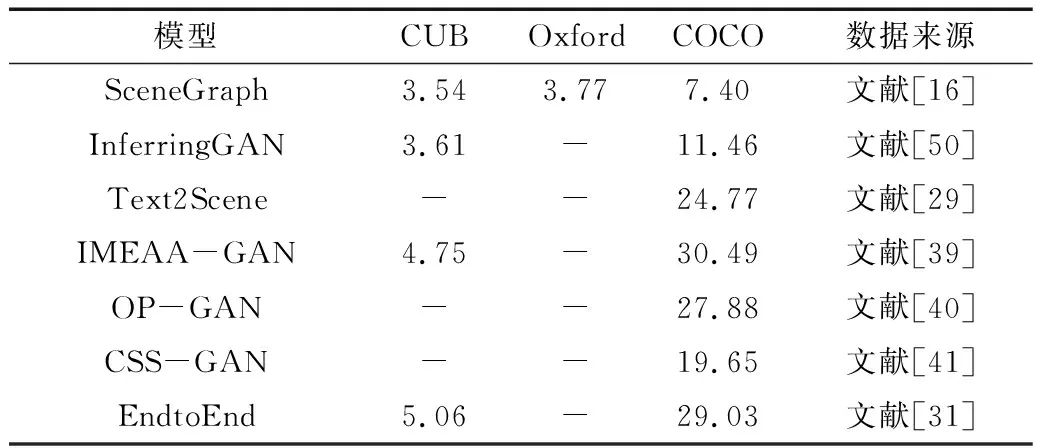
表7 几种典型的场景布局增强方法IS值比较Table 7. Comparison of IS of typical scene layout enhancement methods
3.4 普适性增强方法
3.4.1 TAC-GAN
文献[14]提出了TAC-GAN,该网络将文本数据和其类别信息相结合,使生成的图像多样化并提高其结构连贯性。网络结构如图10所示。
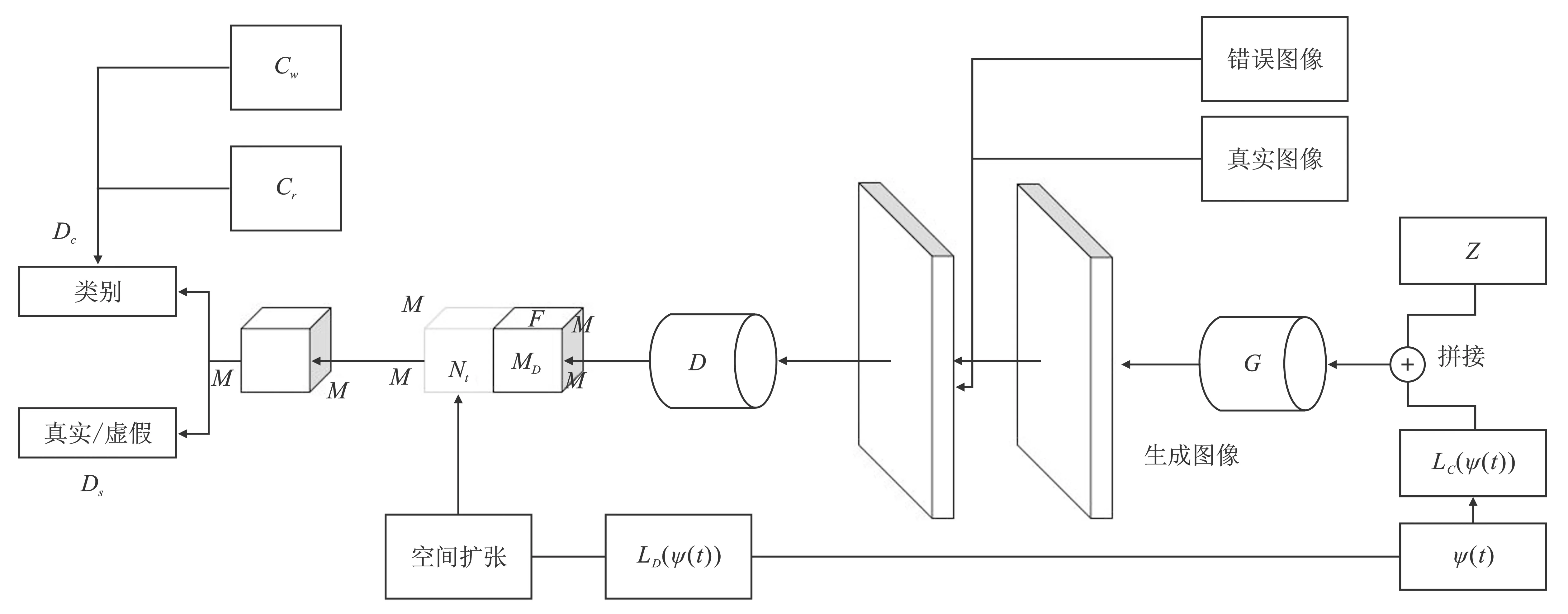
图10 TAC-GAN结构 Figure 10. Architecture of TAC-GAN
在TAC-GAN网络中,生成器将生成的图像限制在其类别标签上,而鉴别器执行辅助任务,将生成图像和真实图像分类到各自的类别标签中。其中,每个生成图像都与类别标签和噪声向量相关联。鉴别器输出(真或假)的概率分布和类标签上的概率分布分别是DS(I)=P(S|I)和DC(I)=P(C|I)。
目标函数由两部分组成:真实来源LS的对数似然和真实类别LC的对数似然。定义为
LS=E[logP(S=r|Xreal)]+E[logP(S=f|Xfake)]
(11)
LC=E[logP(S=c|Xreal)]+E[logP(S=c|Xfake)]
(12)
式中,鉴别器最大化为LS+LC;生成器最小化为LC-LS。
TAC-GAN相较于其他方法易于扩展,能以任何类型有用的潜在信息对网络进行调节。但是额外的信息对模型训练的稳定性可能会产生一定影响,并且其在多大程度上是帮助而不是阻碍模型产生更好质量、更高分辨率的图像的能力,仍有待研究。
3.4.2 MA-GAN
文献[8]提出了MA-GAN,该网络挖掘描述同一图像的不同语句之间的语义相似性,既提高了生成图像的质量,又保证了相关语句的生成相似度。在此基础上提出了一个单句生成和多句判别(Single Sentence Generation and Multiple Sentence Discrimination, SGMD)模块,探索多个相关语句之间的语义关联,以减少生成图像之间的差异。此外,设计了一种渐进式负值样本,有效地提高产生式模型的细节判别能力。网络结构如图11所示。
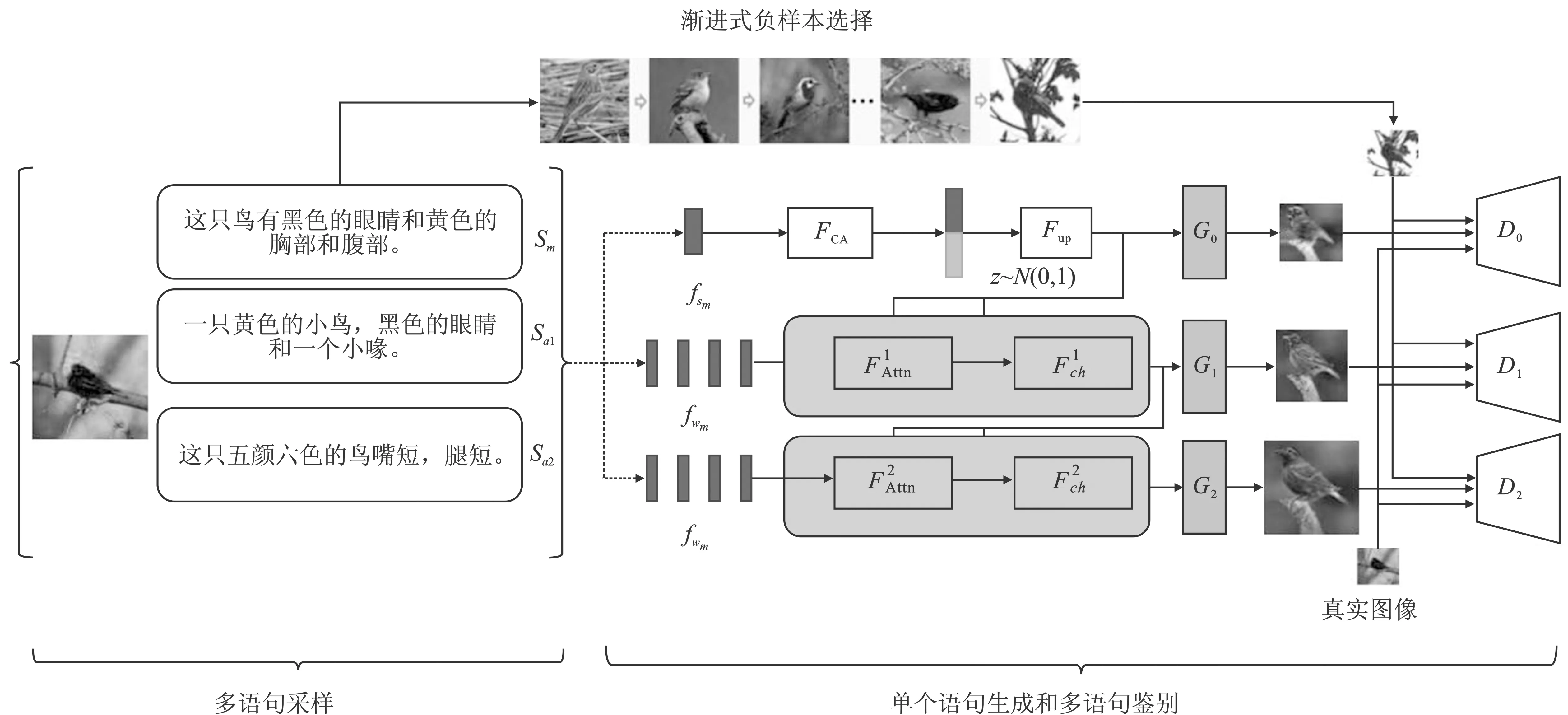
图11 MA-GAN结构Figure 11. Architecture of MA-GAN
MA-GAN主要由3大模块组成:多语句采样模块、单句生成和多句鉴别模块以及渐进式负样本选择模块。
1)多语句采样模块是将一个图像和多个语句P={Ir;Sm,Sa0,Sa1,…,San}作为输入。其中,Ir是真实图像,Sm是目标语句,Sai是辅助语句,由真实图像的相关语句中随机采样的得到。通过预先训练的文本编码器提取语句特征和单词特征,再利用条件增强来增强文本描述,得到增广的语句向量。
2)句生成和多句鉴别模块包含3对生成器和鉴别器,对应不同分辨率的图像。在3个生成阶段,使用同一个语句作为生成条件,而在鉴别阶段使用多个不同的语句。
3)渐进式负样本选择模块则是在训练过程中引入负样本来提高模型性能,再生成细粒度图像。
生成器损失函数LG如式(13)所示。
(13)
鉴别器损失函数LD如式(14)所示。
(14)
式中,LDi是3个阶段的鉴别器损失;LC是分类损失。
MA-GAN引入了多个相关语句中的语义信息,减少了相关语句生成的图像之间的差异。但忽略了视觉信息与语义信息之间的不平衡,需要引入更多的上下文信息,例如边界框、属性信息、掩码信息等。更好地利用上下文信息是值得研究的问题。
3.4.3 性能对比
表8给出了在3个常用数据上几种普适性增强方法IS值的比较。从表8可以看出,基于COCO数据集,相较于其他增强方法。文献[51]所提方法的IS值最高,达到52.73,表明该文献设计的内存结构是一种有效的图像生成方法。
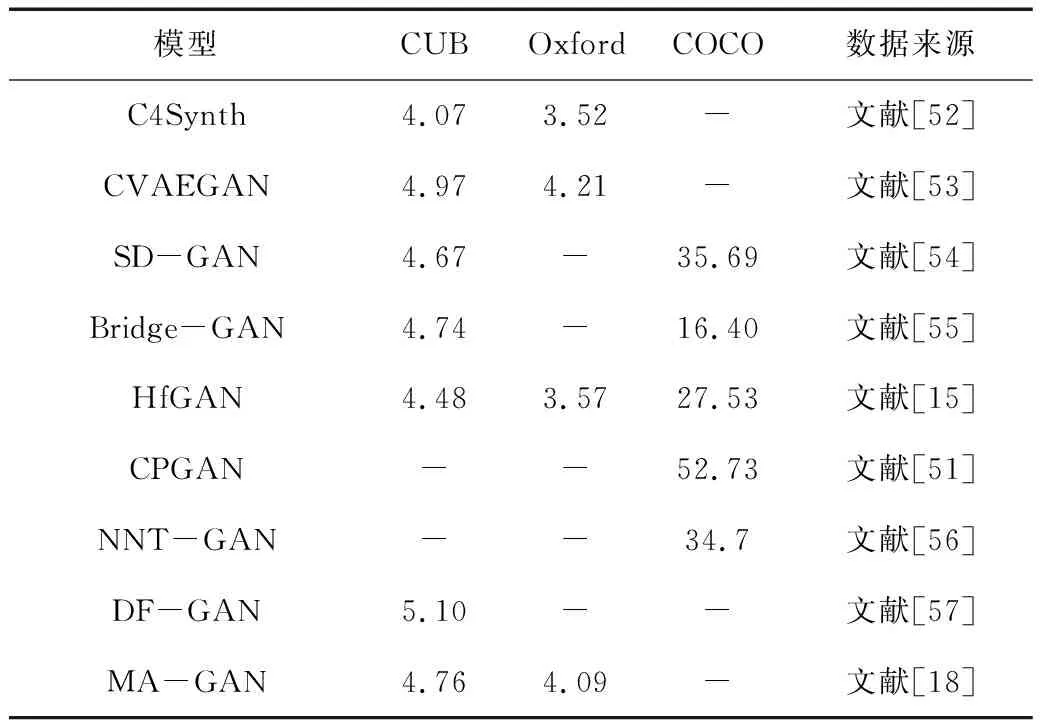
表8 几种典型的普适性增强方法IS值比较Table 8. Comparison of IS of typical universality enhancement methods
4 评估方法
在完成文本生成图像任务之后通常对生成图像进行评估。图像的评估目标主要有3个方面,即质量、多样性以及语义一致性。
4.1 图像质量和多样性
Inception Score (IS)[58]被广泛用于评估图像的质量和多样性。IS是基于一个预训练InceptionV3网络[59],通过统计该网络的输出来计算生成网络的性能,其计算式为
IS(G)=exp(Ex~pg[DKL(p(y|x)‖p(y))])
(15)
式中,p(y|x) 是预训练模型估计的图像条件标签分布,即初始InceptionV3网络的输出;p(y)是关于图像的边缘分布。
Frechet Ineption Distance (FID)[60]根据预训练的网络提取的特征来衡量真实图像分布和生成图像分布之间的距离。FID在评估GAN方面比IS更具有一般性,可更好地捕捉各种外界干扰。与IS相似,FID通常从真实和生成的图像中计算,使用预训练的Inception V3网络的最后一个池化层来获取视觉特征。之后用从两种图像中所提取特征的均值和方差(μr,∑r)和(μg,∑g),通过式(16)计算FID
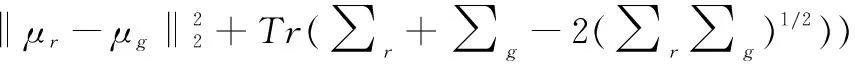
(16)
FID将生成图像的分布与真实图像的分布进行比较,生成图像与真实图像之间的距离越小,则FID越低。
文献[2]提出了一种FCN-scores,其基本思想是GAN生成的图像应该能够在利用相同分布的真实图像所训练的分类器上被正确分类。因此,如果分类器准确地对一组合成图像进行分类,则该图像可能是真实的,并且相应的GAN获得较高的FCN分数。
Structural Similarity Index Measurement (SSIM)[61]即为结构相似性,是一种衡量两幅图像相似度的指标。该指标假设人类视觉主要从可视区域内获取结构信息,所以通过检测结构信息是否发生改变来感知图像的近似信息。SSIM测量系统由3个对比模块组成:亮度、对比度、结构。测量系统的定义如式(17)所示。
S(x,y)=f(l(x,y),c(x,y),s(x,y))
(17)
式中,(x,y)是不同的图像;l(x,y) 是图像亮度对比;c(x,y)是对比度;s(x,y) 是图像结构对比。
(18)
式中,μ、σ、σxy分别是图像的均值、方差以及x和y的协方差;C1、C2、C3为常数,且C3=C2/2。故整体有
(19)
SSIM范围为-1~1,越接近1,表明两张图像越相似。
除以上介绍外,还有一些未被广泛使用的指标,例如适合多对象图像的质量评估(the detect based score)[37]、适合多对象图像的真实性评估(SceneFID)[62]、自动显示生成模型中无法捕获数据分布的特定类别(CAS)[63]、可以估计单个样本的感知质量并研究潜在空间插值(precision and recall metrics)[64]以及可以检测两个相同分布之间的匹配(density and coverage metrics)[65]。这些指标利用不同的思想来评估图像的质量和多样性。
4.2 语义一致性
在文本生成图像的过程中,保留文本原有的语义信息必不可少。生成图像必须符合文本所描述的内容和人类的主观感受。近年来,关于衡量文本-图像语义一致性的评估指标受到了越来越多的关注。常见的评估指标如表9所示。

表9 几种典型的语义一致性评估指标Table 9. Several typical semantic consistency evaluation metric
5 数据集
5.1 CUB
CUB数据集[1]共有11 788张鸟类图像,包含200类鸟类子类,其中训练数据集有5 994张图像,测试集有5 794张图像,每张图像均提供了图像类标记信息,图像中鸟类的bounding box、鸟类的关键part信息以及鸟类的属性信息。
5.2 Oxford-102
Oxford-102[69]数据集是牛津大学于2008年发布的一个花卉数据集,在计算机视觉领域被广泛使用。该数据集包含102个类别的8 189张花卉图像,每个类别包含40~256张图像。训练集和验证集中各类别包含10张图像(共1 030张),而测试集中各类别至少包含20张图像(共6 129张)。
5.3 MSCOCO
MSCOCO[70](Microsoft Common Objects in Context)是微软于2014年出资标注的数据集。该数据集是一个大型、丰富的物体检测,分割和字幕数据集。该数据集以理解场景为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定。图像包括91类目标,32.8万影像和250万个label。
5.4 CIFAR-10
CIFAR-10是一个接近真实物体的彩色图像数据集,目的用于识别日常物体。一共包含10个类别的RGB彩色图像,每个图像的尺寸为32×32,每个类别有6 000个图像,数据集中一共有50 000张训练图像和10 000张测试图像。
除上述数据集之外,还有MNIST[35]、SVHN[5]以及CelebA-HQ[29]等。总之,目前文本生成图像的数据集主要以场景和稀疏对象为主,但考虑到现实情况更为复杂,加入更多的对象-对象和对象-场景交互动作,能够让模型更好地理解文本信息,提高模型的图像生成效果。
6 结束语
本文总结了各种基于GAN的文本生成图像方法。根据GANs结构的不同,将文本生成图像方法归纳为4类:注意力增强方法、多阶段增强方法、场景布局增强方法和普适性增强方法。讨论了每一种模型的思想、原理以及贡献。这些模型都可以基于文本类型的自然语言生成具有视觉效果和照片级真实感的图像。最后,在CUB、Oxford-102和MSCOCO数据集上对模型进行了评估。从两个方面展开未来的研究工作:
1)评估指标。从表9可以看出,目前还有较多未展开广泛应用的新评估指标,它们都有一定的理论根据,但是缺乏具体的研究实践。此外,生成图像有多个维度需要评估,例如真实性、多样性和语义一致性等,但目前缺少足够可靠的评估指标,该评估指标应该在多个角度对图像进行综合评估。因此,新评估指标的广泛应用和研究具有综合性图像评估效果的指标是未来文本生成图像领域的方向之一。
2)GAN结构。综合本文对比分析近几年的GAN模型变体的性能结果可知,目前大多研究集中在本文归纳的方法类别中,虽然有不同方法可以使生成图像的视觉效果较好,但模型仍然存在不足,例如图像不够真实、缺乏多样性约束以及不适应复杂场景和文本等问题。因此,综合多个类别来构建模型是亟待解决的问题。
