基于多源数据关联融合的交通图像深度补全技术
2023-10-21杨睿华赵季中
王 鸽,杨睿华,惠 维,赵季中
(西安交通大学 计算机科学与技术学院,陕西 西安 710049)
智慧交通指利用先进的信息技术、物联网技术、人工智能以及计算机视觉等技术手段,实现交通系统的高效和智能化管理,以提升道路通行能力,减少交通拥堵,降低能源消耗,保障道路交通安全和改善出行体验,对城市的可持续发展具有重要意义。
现有的智慧城市交通系统采用图像感知方法来检测目标,以满足车辆行驶情况估计和交通流量检测等实际需求。然而,图像感知方案难以估计车辆三维距离,给探测引入一定误差。为解决该问题,针对图像的深度补全技术得到了广泛重视。使用深度补全技术可填补深度图像中的缺失部分或不准确部分,从而提高路面深度估计的准确性。但基于图像的深度补全仍存在一定挑战:1)深度图可能受到天气、光照、遮挡和反射等多种干扰和影响,摄像机和毫米波雷达获取的深度图可能包含缺失或不准确部分,无法保证深度图的质量和完整性;2)路面上存在的障碍物使深度估计可能受到一定干扰。为解决以上问题,基于多源异构数据融合和深度学习的深度补全等技术应运而生。
深度补全是计算机视觉领域的重要研究方向之一,目的是利用稀疏的深度数据(例如毫米波雷达采集的数据)来生成高质量和高分辨率的深度图。深度补全不仅需处理深度图中的噪声、遮挡和反射等干扰因素,还需解决不同传感器之间的数据对齐问题。因此,单一数据源难以满足深度补全的需求,需要结合多种数据源来提高深度补全的准确性。多源异构数据融合在深度补全任务中具有重要作用,可充分利用多种数据源的信息来提高深度补全的精度和效率。同时,不同数据源之间的关联性和规律性不仅可以提高数据的知识含量和价值,还可以通过降低单一数据源的噪声和偏差来提高数据的稳定性和可操作性。
目前,室外场景的深度补全由激光雷达、立体相机和单目相机技术主导。视频和激光雷达数据的融合可使密集深度图的预测越来越精准。与此同时,毫米波雷达已降级到用于车辆高级驾驶辅助系统的目标检测任务。然而,相控阵汽车雷达技术在精度和鉴别方面一直在进步。本文调查了在不使用激光雷达的情况下,使用毫米波雷达进行密集深度补全任务的可行性。与激光雷达相比,毫米波雷达已普遍安装于自动驾驶车辆上,用于碰撞检测以及其他类似任务。若能成功地使用图像和毫米波雷达进行三维场景建模和感知任务,将有效降低成本。但毫米波雷达同样具有点云稀疏、分辨率低等缺点,将给深度补全引入误差。
为解决上述问题,本文提出了一种基于多源数据关联融合的深度补全技术,利用多源异构数据融合算法和深度学习方法对不完整或缺失的深度信息进行恢复,从而生成质量更高的深度图。该技术通过融合毫米波雷达数据和图像数据进行深度补全,在不使用激光雷达数据(成本高昂且易受环境干扰)的情况下,实现低成本、高普适性以及高性能的深度补全技术。首先,将图像与毫米波雷达点云数据进行逐点关联,生成多通道置信度增强深度图。再将处理后的深度图输入基于数据层逐点关联网络中进行深度补全,从而生成高质量深度图。
本文在公开的nuScenes[1]数据集上进行了大量实验,实验结果验证了本文所提方法的有效性,并与其他相关方法进行了对比分析,展示了本文所提方法的优势之处。相较于KITTI[2]、Waymo[3]和ArgoVerse[4]等数据集,nuScenes数据集是一个包含毫米波雷达数据、图像、激光雷达数据以及每个场景的标注信息的数据集,适用范围较广。本文结合多源异构数据融合算法和深度神经网络模型,实现低成本、高普适性以及高性能的深度补全技术,为多源异构数据融合以及深度补全技术的研究提供了新的思路和方法。
1 基于数据层逐点关联的多源数据融合
在智慧交通系统中,自动驾驶汽车的毫米波雷达一般通过天线单行扫描发射调频连续波信号(Chirp)。该毫米波雷达点投影模型可以建立在一个平行于地面的水平面上[5]。虽然调频连续波雷达点云在深度测量方面比较准确,但当投影到相机坐标系中时,得到的深度值不正确。这是因为即使毫米波雷达点投影到了被测目标的周围区域,但在图像上的位置与实际位置也有可能完全不符。另外,在建立毫米波雷达点和相机投影模型之前,毫米波雷达点云相较激光雷达的点云稀疏较多。通常毫米波雷达扫描结果只有1行回波,而激光雷达最多可以达到128行回波,毫米波雷达的稀疏性增加了深度补全任务的难度。对此,本文提出将在一定时间间隔内将毫米波雷达点云进行累积,并使用汽车自身运动和径向速度来对应其空间位置。然而,这种累积会额外引入像素关联错误和更多的投影点遮挡误差。
1.1 基于特征一致性的遮挡消除
将毫米波雷达点进行多帧累积时,距离雷达较近的目标可能会遮挡一些投影点,因此生成的深度图会有较严重误差。由于nuScenes数据集中没有可用的立体图像来过滤掉被遮挡的点,本文根据光学场景流一致性检测来移除被遮挡的毫米波雷达点。
毫米波雷达点的场景流被称为毫米波雷达流。在移动物体上,点的位置随物体的运动进行变化。在静态可见物体上,毫米波雷达流等于图像光流,而在被遮挡的物体表面上,其通常与同一像素处的光流不同。因此,本文首先计算毫米波雷达流和图像光流之间的L2范数,然后比较它们之间的差值是否大于一定阈值(该阈值为实验选定值),若大于该阈值,则该点视为被遮挡点,进行滤除,否则将该点保留下来。本文计算光流图的方法基于RAFT(Recurrent All-Pairs Field Transforms)模型[6]。
在两种特殊情况下,基于光流一致性的被遮挡点滤除可能会失效。第1种情况是被测目标距离毫米波雷达和相机较远或与测量者的运动方向一致时,测得的两帧之间会由于视差较小,导致图像光流和毫米波雷达流都会偏小,它们的差异不可测量。第2种情况是移动物体上的毫米波雷达流与其背后被遮挡的毫米波雷达流相同。在这两种情况下,光流一致性不足以从最终的深度补全中滤除被遮挡的点。为解决该问题,本文结合使用3D边界框和语义分割技术来移除出现在被测目标顶部的雷达遮挡点。首先将被测目标的准确像素区域由3D边界框投影和语义分割的交集确定。边界框4个角的最大深度用于决定落在被测目标上的毫米波雷达点是落在物体上还是在物体后面。落在3D边界框投影和语义分割交集内的点以及比最大深度更近的点会被保留下来,而其他点作为被遮挡的点将被滤除。本文使用在CityScape数据集[7]上进行过训练的语义分割模型Panoptic-DeepLab[8]来分割被测目标以及滤除遮挡点。
1.2 多源数据点映射
在将毫米波雷达投影点与图像像素进行数据层逐点关联时,确定投影到相机坐标系下的毫米波雷达点在图像中对应的像素点是一个需要解决的问题,这也是进行数据层关联时普遍面临的一个难题。
对于该难题,本文提出一种数据层的逐点关联方法,可将上述难题转换为投影到相机坐标系下的毫米波雷达点附近具有与该雷达点相同深度值的点。数据层逐点关联方法的目的是找到毫米波雷达投影点与图像像素之间的对应关系,即哪些像素与雷达像素有相同的深度。这样能够解决毫米波雷达投影到相机平面时的不确定性和遮挡问题,也可增加毫米波雷达深度图的密度,从而提高深度补全的准确性。该方法的基本思想是对每个毫米波雷达投影点,学习一个概率分布,表示其邻域内的像素与其有相同深度的可能性。这个概率分布称为关联置信度,用深度神经网络来预测。
图1为毫米波雷达点云和图像的目标检测模型。图1表明毫米波雷达点的投影建模在平行于地面的水平面上(如图1中虚线所示),毫米波雷达的真实回波(角标为“真实”的标注点)可能落在该平面之外。图2展示了将平面内的毫米波雷达点投影到相机坐标系上。在相机视角平面中,毫米波雷达点的投影为角标为“投影”的标注点。图2展示了图1中每一个毫米波雷达投影点的邻域内与图像像素逐点关联的情况。其中α投影和β投影可见,γ投影被广告牌支柱挡住,不可见。

图1 毫米波雷达和相机目标检测模型Figure 1. Millimeter wave radar and camera target detection model

图2 毫米波雷达和相机目标关联模型Figure 2. Millimeter wave radar and camera target association model

1.3 基于关联置信度预测的多通道置信度增强
数据层逐点关联置信度给出了测得的毫米波雷达投影点与其N-邻域内像素具有相同深度的概率,然后可将预测的置信度转换为一种增强的毫米波雷达深度表示,即生成多通道置信度增强深度图。该深度图将每个关联置信度矩阵中高于置信度阈值的像素赋予雷达投影点深度值,从而得到一个增强的深度图像。多通道置信度增强深度图可以与图像和毫米波雷达稀疏深度图一起作为数据关联引导的深度补全网络的输入,以生成密集的深度图。
图3为多个毫米波雷达投影点的样例。其中,图3(a)表示相机坐标系下的毫米波雷达投影点,图3(b)表示对于每一个毫米波雷达投影点。计算N-邻域内像素的逐点关联置信度,用阴影轮廓表示,不同颜色代表不同阈值下的深度值。图3(c)表示毫米波雷达投影点深度扩展到邻域内像素以此创建多通道置信度增强深度图。在每一种情况下,与毫米波雷达投影点具有相似深度的邻域图像像素可被赋予高置信度的毫米波雷达深度值,而其余邻域像素被赋予低置信度,并且它们的深度值在多通道置信度增强深度图的通道上单独指定。优点是高置信度通道可以提供最好的预测信息,但低置信度通道也可能提供有用数据,使网络可以学习到每个通道的特征,继而进行高质量的深度补全任务。

图3 多通道置信度增强深度图(a)毫米波雷达投影点 (b)投影点对应邻域 (c)增强深度图Figure 3. Multichannel confidence enhanced depth map(a)Projection points of mm wave (b)Neighborhood of projected points (c)Enhanced depth map
2 基于数据关联引导的深度补全网络
为实现彩色图像、语义图像、毫米波雷达深度特征和多通道置信度增强深度图之间的自适应融合,本文提出了一种在级联沙漏网络模型中对彩色图像、语义图像、毫米波雷达深度特征和多通道置信度增强深度图应用基于注意力的融合模型[9],如图4所示。该模型帮助网络捕捉显著的特征图,同时抑制不必要的特征图,可进一步细化不同模态特征图之间的连接。

图4 数据关联引导的深度补全网络Figure 4. Deep completion network guided by data association
2.1 基于注意力机制的深度补全网络
在3种不同设置中应用注意力融合模型。首先将其应用于融合彩色图像和语义引导模块的中间特征图;然后对于毫米波雷达深度图引导模块,将前面两个分支的特征图以及雷达稀疏深度图进行融合;最后对于多通道置信度增强深度图引导模块,将前面所有的中间特征图进行融合。
图像编码器是一个单一的收缩网络,包含多层下采样卷积层,用于编码彩色图像的多尺度特征,然后与不同尺度的深度特征进行协调。其可以有效处理彩色图像中的细节和语义信息,不需要手动地对图像进行下采样。图像编码器网络是由4个不同尺度的卷积块和ReLU激活函数组成的。输入原始图像,输出4种不同尺度的特征图像,对应的分辨率分别为320×180、160×90、80×45以及40×22。
深度补全网络中的每一个模块包含4个不同尺度的编-解码器,分别接收1/8、1/4、1/2和全分辨率的稀疏深度图作为输入。图像编码器的输出Feature1、Feature2、Feature3和Feature4先分别与深度网络的编码器Encoder1、Encoder2、Encoder3和Encoder4进行相加操作,然后再与深度网络的解码器Decoder1、Decoder2、Decoder3和Decoder4进行结合,以融合多尺度图像和深度特征。不同Feature和Encoder输出结果的不同之处在于:1)Feature包含了彩色图像中的细节和语义信息;2)而Encoder输出结果中包含了稀疏深度图中的结构和语义信息。Feature可帮助深度网络处理一些难以从深度图中推断的场景,例如光滑、明亮、透明和远处的表面,而Encoder输出结果可以帮助深度网络保持稀疏深度图中的观测值和约束。Feature特征和Encoder输出结果相加可以压缩特征通道的长度,减少计算复杂度以及提高深度补全的质量和稳定性。
彩色图像输入模块的目的是学习对密集深度补全任务有用的颜色特征。它将彩色图像和对齐的稀疏深度图进行连接,输入到网络第1个模块中,并输出一个深度图和置信度矩阵。其中,将对齐的稀疏深度图与彩色图像连接起来,有助于预测密集深度[10]。彩色图像输入模块仍是编码器和解码器网络结构,具有跳跃连接。
语义分割模块不仅有助于去除遮挡点,还可帮助网络理解图像场景。仅靠彩色图像的引导还不足以学习到语义特征,因此本文在深度补全网络中提出加入语义分割图像模块来学习有效的语义特征。语义分割图像模块的输入为彩色图像模块生成的深度图、语义分割图像和毫米波雷达稀疏深度图的连接,并输出一个包含颜色和语义线索的稀疏深度图和置信度矩阵。nuScenes数据集未提供图像的语义分割图,因此本文利用预训练的Panoptic-DeepLab模型[8]在nuScenes数据集上进行图像的语义分割。本文将彩色图像模块的解码器特征融合到语义分割图像模块的相应编码器特征中。
毫米波雷达深度图模块的目的是学习深度值主导的特征,有助于生成准确的稀疏深度图。它将彩色图像模块的输出、语义分割图像模块的输出和毫米波雷达深度图的连接作为输入,并输出一个准确的稀疏深度图和置信度矩阵。与彩色图像和语义分割图像模块的特征融合方法类似,该模块将前两个模块的解码器特征融合到毫米波雷达深度图模块的相应编码器特征中,融合起来的特征图包含了来自前两个模块的有用信息,指导毫米波雷达深度图模块学习有效的深度特征表示。
多通道置信度增强深度图融合模块将置信度预测网络输出的置信度分为多个维度,作为多个通道输入到网络中。对于置信度属于区间(0.50、0.60、0.70、0.80、0.90、0.95)的毫米波雷达深度增强图,组成一个6通道的深度图,然后输入到多通道置信度增强深度图融合模块中。该操作的目的是利用多个预测深度值的不同置信度信息来主导深度的训练,从而在训练过程中提高网络对于高置信度预测的关注度,将置信度信息与预测的深度值相结合,为每个像素生成一个加权的深度值,可通过对预测深度值和置信度信息进行逐元素相乘来实现,以此来改善网络在深度补全任务中的性能表现。与前面模块类似,将毫米波雷达深度的输出和毫米波雷达深度的连接进行融合,并得到最终的密集深度图。为防止过拟合,在损失函数的计算过程中进行正则化。在整个训练中同时加入权重的衰减因子(L2正则化),有助于网络在测试数据上实现更好的泛化性能。
2.2 损失函数
因为本文网络的各个模块的输入不同,所以需要对每个模块单独计算损失,最后再计算各个模块损失的加权和,以优化网络训练。损失函数采用Focal Loss,该函数最初是为解决目标检测任务中的类别不平衡问题。在本文所使用的场景中,由于需要进行深度检测的类别并不均衡,所以该函数也可以被用于深度补全任务,对于复杂模型来说,其效果显著,衡量了模型预测值和实际值之间的均方误差。为了将Focal Loss整合到深度补全任务中,可以按照如下步骤进行:
步骤1定义一个基本的回归损失函数,本文计算真实值与预测值的均方误差(Mean Squared Error,MSE)L(D真实-D预测)。然后,将损失函数转换为一个概率分布,即将MSE损失归一化到[0,1]范围内
(1)
式中,L最大表示损失的最大值。
步骤2将归一化的损失值Pt带入Focal Loss计算式中,同时引入调节参数γ和权重系数α,使用得到的Focal Loss作为网络中每个模块的损失函数进行训练
Focal Loss(Pt)=-α×(1-Pt)γ×log(Pt)
(2)
式中,α是平滑不同深度值区间的损失权重,解决不平衡问题;γ是一个可调节参数,用于控制损失函数对简单样本和困难样本的关注程度。
彩色图像模块Loss颜色的计算使用Focal Loss,计算式为

(3)
式中,颜色代表彩色图像模块预测深度;真实代表激光雷达真实深度。
语义分割图像模块的损失函数Loss语义、毫米波雷达深度图模块的损失函数Loss雷达以及多通道置信度增强深度图融合模块的损失函数Loss融合计算以相同的方式计算Focal Loss。网络的训练Loss整体是由彩色图像模块、语义分割图像模块、毫米波雷达深度图模块和多通道置信度增强深度图模块训练损失函数的加权总和,计算式为
Loss整体=
μ×Loss颜色+ϑ×Loss语义+φ×Loss雷达+Loss融合
(4)
式中,μ、ϑ和φ分别是彩色图像模块、语义分割图像模块和毫米波雷达深度图模块的权重系数。该系数为超参数,通过观察多次实验结果选取,若采用其他数据集,则需要进行重新选取。
3 实验与评估
3.1 实验设置
本文使用nuScenes公开数据集,在进行数据集划分时,将其划分为训练集、验证集和测试集,占比分别为70%、15%和15%。为便于进行光流图计算,提取晴天下所有移动场景的样本(不保存头两帧、最后两帧和当前关键帧4邻域内位移过小的帧)。训练集和测试集的最大深度阈值设置为60 m。本文使用32射线激光雷达,并累积前后共26帧的激光雷达点云数据作为深度值真实标签,毫米波雷达帧融合前后总共9帧的点云数据。本文的硬件包括Intel Core i7-11700k CPU,RTX 3060 12G显卡,内存为128 GB。
3.2 参数设置
方法设计部分的毫米波雷达投影点邻域N的选取是150个像素点,其中高度h为30,宽度w为5。基础的实验配置见前文所述。本文网络训练使用PyTorch框架,优化器使用Adam,其中和权重衰减10-6,batch为4,初始学习率5×10-5。此外对于训练中损失函数的系数初始分别设置为0.2、0.3和0.4。
本文在训练过程中采取多阶段方案。首先将4个模块训练20个epoch。然后,将前3个模块的损失权重系数都降到0.1,再训练20个epoch。最后将前3个模块的损失权重系数都降到0,只训练最后一个子模块,训练20个epoch。可使每个子模块都能充分地学习到对应尺度的特征和深度补全图。
3.3 评价标准
对于本文所提方法,评估性能主要使用深度补全任务主流文献[11~14]所使用的指标进行评估,包括平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)。其中,MAE主要衡量预测误差的平均大小,数值越小,预测结果越准确;RMSE对较大误差的惩罚更严重,因此其更关注较大的误差。
3.4 总体实验评估
3.4.1 网络整体性能
将本文提出的注意力引导的多尺度级联深度补全网络的性能与文献[15]和文献[16]中的结果进行了对比。不同分辨率会对评估指标有影响,本文所用分辨率为320×180,故在进行定性比较时,将文献[15]和文献[16]网络模型更改为与本文所提方法的图像相匹配的分辨率,评估指标得到的结果与原文献等价。结果表明,本文的网络模型在性能上优于先前的工作。如表1所示,在nuScenes数据集上,本文所提方法与其他先进方法相比,RMSE低0.345 m,MAE低0.330 m,为现有最优结果。

表1 前期工作对比结果Table 1. Comparison with prior works
从图5来看,本文提出的基于注意力的多尺度级联深度补全网络生成的密集深度图不仅能看出物体的具体深度状况,还具有更明显的边界。由图5第2行可看出,不同车辆的深度值不同,可明显地看出有3辆车,主要得益于多通道置信度增强深度图的特征提取。由图5第3行能看出来卡车的车身和车头的深度值明显不同,主要得益于彩色图像的特征提取,将颜色信息带入到网络训练中。由图5第4行能看出来路标牌的深度值明显不同于墙壁的深度值,主要得益于语义分割图像的特征提取[17-18]。

图5 网络输出定性结果(a)彩色图像 (b)雷达投影点 (c)深度误差 (d)本文结果Figure 5. Qualitative result(a)RGB image (b)Projection points of radar (c)Depth errors (d)Results of this study
3.4.2 不同级联沙漏网络结构实验
表2展示了不同级联沙漏网络结构的性能比较。通过结果可知,替换当前网络模块的任何部分都会造成网络性能下降,证明本文设计的网络结构能够有效地提取不同模态中的特征,生成高质量的密集深度图,并且降低了计算复杂度。

表2 不同级联沙漏网络结构性能比较Table 2. Comparison of different cascading modules
3.5 消融实验
3.5.1 多模态模块消融实验
消融实验设计的目的是通过增删每一个模块来测试网络性能的变化。如表3所示,语义分割图像模块的删除对网络性能影响最大,其次是多通道置信度增强深度图模块的删除。因为存在图像编码器模块,所以彩色图像的输入对网络性能的影响较小。同时,因为网络模型级联的输出直接输入到下一个模块中,所以毫米波雷达稀疏深度图的输入对网络的影响最小。结果证明,本文提出的基于注意力的多尺度级联深度补全网络的性能最好,RMSE达到了2.834 m,MAE达到了1.142 m。
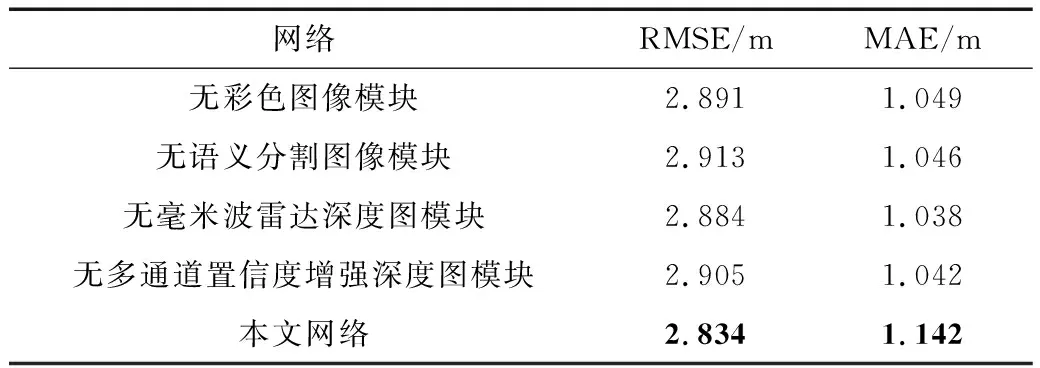
表3 不同模块对网络性能的影响Table 3. Comparison with different modules
3.5.2 注意力融合模块消融实验
对于本文提出的注意力融合模型,需进行消融实验验证其有效性。表4列出了本文注意力融合方法的性能比较。可看出在使用注意力融合模型的网络中,RMSE显著提高了0.16 m,因此注意力融合方法优于朴素的融合方法是一种更好的融合策略。

表4 不同融合方法比较Table 4. Comparison with different fusion method
4 结束语
本文针对交通图像,本文提出了基于多源数据融合的深度补全网络。该网络综合了注意力机制、多尺度信息、多模态特征引导策略和级联结构,以提高深度补全任务的质量。通过多尺度级联沙漏结构,捕捉到多个模态的特征信息,逐步优化和细化深度预测结果。实验结果表明,本文提出的注意力引导的多尺度级联深度补全网络在公开数据集上进行的深度补全测试验证中达到了高于基准线的性能。
