基于知识蒸馏的多模态融合行为识别方法
2023-10-17詹健浩甘利鹏毕永辉曾鹏李晓潮
詹健浩,甘利鹏,毕永辉,曾鹏,李晓潮
(1.厦门大学 电子科学与技术学院,福建 厦门 361005;2.厦门市美亚柏科信息股份有限公司,福建 厦门 361016;3.厦门市公安局,福建 厦门 361104)
0 概述
多模态融合是将多个模态网络提取出的互补信息在特征或者预测分数层面进行融合,从而获得比单一模态网络更好的识别效果[1-2]。由于多模态数据是从不同来源或传感器收集的异构数据,因此它们在提供的外观、运动、几何信息、光照、遮挡、背景变化等信息方面各有特点,如RGB 模态包含丰富的外观信息,但对遮挡、环境变化或阴影的干扰敏感[3],而骨骼模态对视角、背景等变化不敏感但缺乏外观信息。因此,不同模态的优缺点可以互补[4]。如何融合多模态数据从而获得更好的识别效果是多模态行为识别方法的关键技术[5]。
基于知识蒸馏的多模态融合方法不仅能够充分利用多模态数据的互补优势,而且在推理阶段只需要单个RGB 模态模型即可完成预测[6],从而降低模型复杂度并提高推理速度。知识蒸馏的关键是将教师网络提取的其他模态特征信息及对动作预测结果的分布信息转移到学生网络中。MARS 网络[7]将光流模态教师网络和RGB 模态学生网络的特征通过MSE 损失函数进行知识蒸馏,并将其和学生网络的交叉熵损失函数线性组合进行训练,从而将光流的运动特征信息转移到RGB 学生网络中。D3D 网络[8]在光流模态教师网络和RGB 模态学生网络的预测分数上求MSE 损失函数进行知识蒸馏,并将其与学生网络的交叉熵损失函数线性组合进行训练,从而使学生网络学习到光流网络对动作预测结果的分布。多视角跨模态知识蒸馏网络[6]在骨骼模态教师网络与RGB 模态学生网络的特征和预测分数上分别通过L1 损失函数和KL 散度进行知识蒸馏,并将其与学生网络的交叉熵损失函数线性组合进行训练,从而使学生网络同时学习到其他模态的特征信息和教师网络对动作预测结果的分布。这些方法都是利用单一的教师网络进行知识蒸馏,分别通过特征或预测分数的知识蒸馏将其他模态的特征和对动作预测结果的分布信息转移到学生网络上。
采用多教师知识蒸馏结构进行多模态融合可以将不同模态的信息同时转移到RGB 模态学生网络中,通过学习多个教师提取的互补模态信息,获得比单一教师网络知识蒸馏更好的效果[6]。PERF-Net[9]通过PoseNet[10]从RGB 图像中提取骨骼信息,然后叠加在RGB 模态上作为姿势模态数据,将姿势和光流模态网络同时作为教师网络,在预测分数上分别与RGB 模态学生网络的预测分数求MSE 损失函数进行多教师知识蒸馏。在基于压缩视频行为识别的研究中,文献[11]分别利用压缩视频编码中的I、P帧运动向量和P 帧残差作为教师网络的输入进行知识蒸馏,探索了不同教师网络组合对多教师知识蒸馏的影响,并通过实验发现将I 帧作为学生网络的输入时单教师知识蒸馏比多教师知识蒸馏的识别准确率更高,而将P 帧运动向量或P 帧残差作为学生网络的输入进行多教师知识蒸馏时可以获得更高的识别准确率。
从上述研究中得到启发,本文在特征上采用MSE 损失函数、在预测分数上采用KL 散度进行知识蒸馏,并采用原始的骨骼模态和光流教师网络的组合进行多模态融合。在与本文相似的研究中,多视角跨模态知识蒸馏网络[6]提取单一的姿势模态数据输入教师网络,并与RGB 模态学生网络在特征和预测分数上分别使用MAE 损失函数和KL 散度同时进行知识蒸馏,而本文进一步研究在特征和预测分数上分别采用不同损失函数进行知识蒸馏的效果,最后在特征上采用MSE 损失函数、在预测分数上采用KL 散度同时对学生网络进行知识蒸馏。此外,本文将骨骼和光流模态网络的组合同时作为教师网络对RGB 模态学生网络进行知识蒸馏。不同于PERF-Net[9],本文仅提取原始的骨骼模态信息进行知识蒸馏,且在预测分数上采用KL 散度、在特征上采用MSE 损失函数,从而学习教师网络提取的其他模态数据的特征,同时采用不同模态教师网络包括光流、骨骼、红外和深度模态教师网络的不同组合对RGB 模态学生网络进行多教师知识蒸馏。
1 基于知识蒸馏的多模态融合行为识别
本文提出的基于知识蒸馏的多模态融合行为识别方法如图1 所示,其中,虚线框表示N个模态的教师网络。各个模态教师网络都提前采用不同模态的数据进行单独训练,知识蒸馏时,教师网络的参数是固定的。对于多模态数据集D的训练集和测试集分别为Dtrain和Dtest,训练数据可表示为{(X0,X1,…,Xk,…,XN);y},其中,X0表示学生网络对应的模态数据,Xk表示第k个教师网络对应的模态数据,1≤k≤N,N表示模态数量,y表示样本X的标签。

图1 基于知识蒸馏的多模态融合行为识别方法Fig.1 Action recognition method with multi-modality fusion based on knowledge distillation
图1 中的教师网络fteacher,k和学生网络fstudent都采用3D ResNeXt-101 作为骨干网络,将RGB、光流、骨骼、深度、红外等不同模态的数据,通过3D CNN 提取时间和空间特征。为了实现语义信息的蒸馏,将4 个 Layer 的 3D ResNeXt-101 网络分为fθ和fφ两部分。例如:当特征知识蒸馏发生在网络的Layer2层时,fθ包含了Layer1 和Layer2,fφ包含了Layer3、Layer4 和预测分数层;当特征知识蒸馏发生在网络的Layer3层时,fθ包含了Layer1、Layer2 和Layer3,fφ包含了Layer4 和预测分数层;依此类推。
本文所提出的基于知识蒸馏的多模态融合行为识别方法将不同模态的样本数据X1,X2,…,Xk,…,XN输入模态k对应的已单独训练好并冻结参数的教师网络fteacher,k,并将X0输入未训练且可训练的相同结构的学生网络fstudent对应网络的前面部分fteacher,k,θ和fstudent,θ,得到教师网络 对应的特征图Fteacher,k,θ和Fstudent,θ,如式(1)和式(2)所示:
其中:X0为学生网络的输入模态数据;Xk(1≤k≤N)为教师网络的输入模态数据。
得到教师网络和学生网络的特征图Fteacher,1,θ,Fteacher,2,θ,…,Fteacher,N,θ和Fstudent,θ后,分别输入网络fteacher,1,φ,fteacher,2,φ,…,fteacher,N,φ和fstudent,φ后通过Softmax温度激活函数(GSoftmax)得到对应预测分数Pteacher,1,Pteacher,2,…,Pteacher,N和Pstudent,如 式(3)和 式(4)所示:
为了实现多模态数据的知识蒸馏,使用不同的蒸馏损失函数将教师特征信息和预测分布信息传递到学生网络中。在特征知识蒸馏过程中,使用教师网络构建语义特征,并将这些特征作为知识转移到学生网络对应网络层,从而产生特征监督信息。通过最小化MSE 损失函数将教师网络和学生网络对应网络层次提取到的语义特征进行知识蒸馏,从而更好地利用多模态数据的互补优势。第k个模态教师网络与学生网络之间的MSE 损失函数Lfeat,k如式(5)所示:
在预测分数上,通过KL 散度使学生网络模仿学习多个教师网络对行为预测结果的分布,第k个模态教师网络与学生网络之间的KL 散度LKLD,k如式(6)所示:
其中:Pteacher,k是第k个模态教师网络通过Softmax 温度激活函数后得到的软标签;Pstudent是学生网络通过Softmax 温度激活函数后得到的软标签。引入Softmax 温度激活函数是为了使预测分数的概率分布更平滑[11],避免出现除正确类别之外其他类别预测概率都接近于零分布的情况,从而提供更多教师网络预测结果中与正确类接近的类信息,改善知识蒸馏的KL 散度对齐效果。Softmax 温度激活函数如式(7)所示[11]:
其中:n表示分类数;zi表示Softmax 温度激活函数前网络对第i类行为的预测值;T为温度系数,T越大,输出的类别分布越平滑。本文将Softmax 温度激活函数的输出Pi作为软标签与学生网络对应软标签进行知识蒸馏,使学生网络预测结果的分布尽可能接近教师网络对行为其他模态输入预测结果的分布。
将学生网络预测分数通过Softmax 温度激活函数后作为q(x)与标签p(x)求交叉熵损失函数Lcls,将交叉熵损失函数与学生网络和所有教师网络的MSE损失函数和KL 散度进行线性组合,构成本文设计的基于知识蒸馏的多模态融合行为识别方法中总体的损失函数L,如式(8)所示:
其中:λfeat,k和λKLD,k是调节第k个模态教师网络与学生网络之间损失函数的权重系数;λcls用于调整交叉熵损失函数的权重系数,这些权重在实验部分中的作用是平衡各损失函数值,使其基本保持一致
2 实验与结果分析
2.1 相关数据集
本文实验采用的行为识别数据集包括多模态数据 集NTU RGB+D 60(NTU 60)[12]、UTD-MHAD[13]、Northwestern-UCLA Multiview Action 3D(N-UCLA)[14]以及常用的单模态数据集HMDB51[15]。
NTU 60[12]数据集由3 台Microsoft Kinect v2 相机采集,包含60 类动作共56 880 个样本,其中含有40 个受测者的RGB、深度、3D 骨骼和红外模态数据,包 含2 个性能评价标准:CS(Cross-Subject)和CV(Cross-View),CS 按人物来划分训练集和测试集,而CV 按相机来划分训练集和测试集。
UTD-MHAD[13]数据集由Kinect 摄像头和可穿戴惯性传感器在室内环境中收集,包含27 类动作共861 个视频样本,8 名受试者各重复动作4次。在实验中,来自受试者1、3、5、7 的样本数据用于训练,来自受试者2、4、6、8 的样本数据用于测试。
N-UCLA[14]是一个多视角多模态数据集,由3 个Kinect 摄像头同时捕捉并由10 名受试者执行多次。N-UCLA 包含1 494 个视频序列共10 个日常动作类别,包 含3 个视角(View1、View2 和View3)[16]的RGB、深度和3D 骨骼模态等3 种模态数据,以视角划分训练集和测试集。
HMDB51[15]数据集主要来源于网站视频或电影,共有51 类人体行为的6 849 个视频,每个动作至少包含51 个视频,视频分辨率为320×240 像素,动作类型主要包括面部动作、肢体动作、交互动作等。
2.2 训练过程
在网络训练阶段,采用多教师知识蒸馏结构[11]。首先分别输入光流、骨骼、深度和红外模态数据训练对应网络作为教师网络,然后在知识蒸馏阶段加载训练好的教师网络并将其参数冻结,使知识蒸馏时不会更新教师网络的参数,并将教师网络与学生网络在特征和预测分数上分别求MSE 损失函数和KL 散度进行知识蒸馏。在网络测试阶段,仅需将RGB 模态数据输入到训练好的学生网络中即可。
在多模态数据上,将RGB 模态作为学生网络的输入数据模态,将光流、深度、红外和骨骼模态作为教师网络的输入数据模态。在多模态行为识别数据集上通过将3D 骨骼模态的x、y轴的坐标按关节点之间的关系绘制成2D 图像作为骨骼模态,而在常用的单模态行为识别数据集HMDB51 上通过Openpose[17]将RGB 模态转换成相应的骨骼模态。
在知识蒸馏的 损失函数权重λfeat、λKLD和λcls的设置上,单教师网络情况下通过调整这几个权重使得MSE 损失函数、KL 散度和交叉熵损失函数基本相等,多教师网络情况下通过调整这几个权重使得多个教师网络MSE 损失函数之和、KL 散度之和与交叉熵损失函数基本相等。T的设置与二阶段教师学生网络[6]相同,设为2,其他实验设置均与骨干网络[7]保持一致。
2.3 消融实验
在消融实验中,HMDB51 和N-UCLA 数据集分别采用最常用的指标,即HMDB51 数据集官方提供的第一个划分Split1 和N-UCLA 的View3 指标进行实验和对比,而NTU 60 采用最常用的CS 指标进行实验。本文采用骨干网络3D-ResNeXt-101[18]在各个数据集中单一模态网络的识别准确率如表1 所示,文献[19-20]方法在各数据集中单一模态网络的识别准确率如表2 所示。将表1 中单一RGB 模态网络作为基线与后续多模态融合的性能进行对比,而训练好的光流、骨骼、红外和深度模态在后续实验作为教师网络。由于HMDB51、UTD-MHAD 和N-UCLA没有红外模态,同时HMDB51 没有深度模态数据,在此并没有列出相关结果。表2 列出了其他多模态融合方法在各个数据集中单一模态网络的识别准确率。
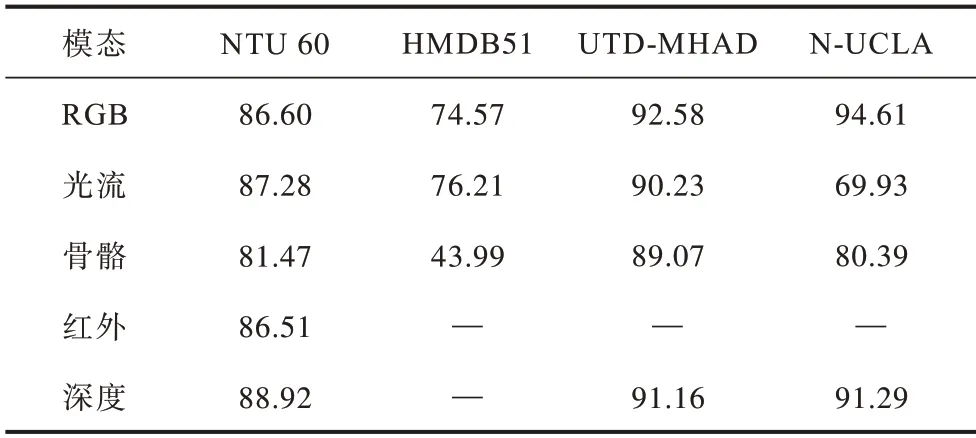
表1 本文方法在各数据集中单一模态网络的识别准确率Table 1 Recognition accuracy of single modality network on each dataset by the method in this paper %

表2 其他方法在各数据集中单一模态网络的识别准确率Table 2 Recognition accuracy of single modality network on each dataset by other methods %
2.3.1 知识蒸馏在网络不同位置的影响
由于网络的不同位置代表不同层次的语义信息,为了进一步探索在不同层次语义信息对应的特征上进行知识蒸馏的效果,分别在骨干网络的不同分层[7]的特征上对教师网络和学生网络进行知识蒸馏。本文的教师网络和学生网络采用相同的网络结构[7]来提取不同模态的特征信息,并在对应特征上采用MSE 损失函数进行知识蒸馏,效果如表3所示。其中,Layer4、Layer3、Layer2 是3D-ResNeXt-101网络的网络分层[18],Layer4 对应高层次语义信息,Layer2 对应低层次语义信息,All 代表在上述所有分层中都进行了知识蒸馏。从表3 中可以看出,在网络高层次语义信息Layer4 层的特征进行知识蒸馏的效果好于在网络其他分层包括多个分层同时进行知识蒸馏的效果,同时,在Layer4 层进行知识蒸馏的效果还好于单独在预测分数层进行知识蒸馏的效果。

表3 NTU 60 数据集中在网络不同位置进行知识蒸馏的效果Table 3 Effect of knowledge distillation in different locations on the network on NTU 60 dataset %
知识蒸馏时式(1)中温度系数T对知识蒸馏效果的影响如表4 所示。从表4 中可以看出,当温度系数T=2时。在N-UCLA 和UTD-MHAD 数据集中效果最好,可以分别取得95.86%和94.88%的识别准确率。
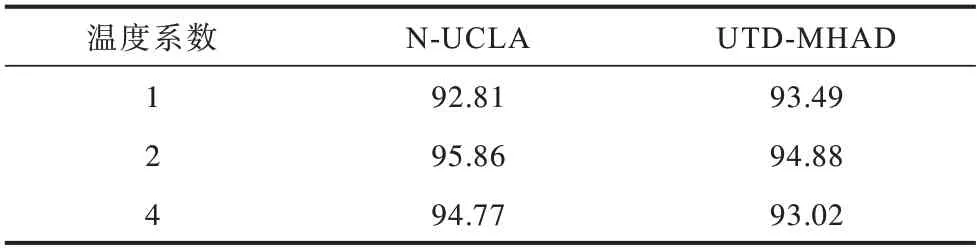
表4 温度系数对知识蒸馏效果的影响Table 4 The effect of temperature coefficient on knowledge distillation %
2.3.2 知识蒸馏的损失函数构成
为了研究采用包括MAE、MSE、MMD、KL 散度等不同的损失函数将教师网络提取的其他模态特征信息及对动作预测结果的分布信息转移到学生网络中的效果,比较在骨干网络Layer4[18]输出的特征上以及预测分数上采用不同损失函数进行知识蒸馏对识别性能的影响,结果如表5 所示。实验采用光流作为教师网络进行知识蒸馏,在特征上讨论MAE 和MSE 损失函数、在预测分数上讨论MSE、MMD 损失函数和KL 散度进行知识蒸馏的效果。从表5 中可以看出,在特征上采用MSE 损失函数进行知识蒸馏的效果较好,在预测分数上采用KL 散度进行知识蒸馏的效果较好,而同时在特征和预测分数上采用这2 种方法进行知识蒸馏的效果最好,因此,本文的设计同时在特征上采用MSE 损失函数、在预测分数上采用KL 散度进行知识蒸馏,使学生网络学习不同模态的特征信息和教师网络对动作预测结果的分布。
2.3.3 采用骨骼模态进行知识蒸馏的效果
不同于将骨骼信息叠加在RGB 模态上的姿势模态[9],本文将原始骨骼信息作为骨骼模态并研究采用骨骼模态教师网络对RGB 学生网络进行知识蒸馏的效果,如表6 所示。其中,单一骨骼模态网络的识别准确率仅为43.99%,远低于单一姿势模态网络的71.96%,但采用骨骼模态作为单一教师网络的输入进行知识蒸馏的识别准确率达到了78.37%,高于姿势模态对应的77.52%,证明了原始的骨骼模态信息的有效性。

表6 姿势和骨骼模态进行知识蒸馏的效果Table 6 Effect of pose and skeleton modalities on knowledge distillation %
2.3.4 多模态融合的效果
采用多教师结构进行多模态融合相比于采用单一教师网络进行多模态融合可以使识别准确率获得进一步提升,但由于不同教师网络的不同组合对多教师知识蒸馏的影响各不相同,因此进一步研究采用多教师知识蒸馏方法进行多模态融合的效果,包括不同模态单教师网络与RGB 学生网络进行多模态融合的效果以及采用光流、骨骼、红外和深度4 个不同教师网络的不同组合进行多模态融合的效果,如表7 所示,其中加粗表示最优数据。
从表7 中可以看出:对于光流和骨骼模态而言,在所有4 个数据集中光流和骨骼模态作为教师网络与RGB 模态通过知识蒸馏进行多模态融合都可以获得很好的性能提升,并且当光流和骨骼模态同时作为教师网络进行多模态融合时在所有数据集中都可以达到最好的效果;对于红外模态,在NTU 60 数据集中进行多模态融合获得了一定的性能提升,但是由于其他数据集没有提供红外模态,因此对于红外模态的研究还需要进一步深入;对于深度模态,采用单教师网络进行知识蒸馏时,在NTU 60和N-UCLA数据集中效果较好,但在UTD-MHAD数据集中效果较差,而采用多教师知识蒸馏结构时,在NTU 60 和N-UCLA 数据集中效果较差,在UTD-MHAD 数据集中准确率反而下降。实验结果表明,光流和骨骼模态的组合作为教师网络的输入进行多教师知识蒸馏的效果最好,初步说明RGB、光流和骨骼3 个模态数据的互补性较好。同时,在表7 采用多模态知识蒸馏方法进行多模态融合的实验结果中,当骨骼模态进一步作为教师网络之一进行多模态知识蒸馏时行为识别准确率都得到了有效的提升,如RGB+光流+骨骼相比于RGB+光流在各数据集上分别提升1.29、0.26、0.24 和1.96 个百分点,RGB+骨骼+深度相比于RGB+深度在NTU 60、UTD-MHAD 和N-UCLA 上分别提升了0.08、0.23、0.24 和1.31 个百分点。
为了更好地分析本文提出的基于知识蒸馏的多模态融合行为识别方法的效果,对在RGB、光流、骨骼、红外和深度每个模态上训练的单一模型以及表7 中典型的几个多教师知识蒸馏模型采用Grad-CAM[21]进行可视化,如图2 所示,图中F、S 和D 分别代表光流、骨骼和深度,P 代表模型对该动作的预测分数,每个动作的第1 行是对应模型的输入,对于知识蒸馏模型,输入为学生网络对应的RGB 模态数据,第2 行是模型响应的热力图。可以看出,对各模态单一模型,热力图覆盖的区域都有所不同,说明对于不同模态数据,网络聚焦于不同的区域。对于图中“读书”动作,RGB 和深度模型对行为的预测分数分别为0.026 3 和0.043 7,产生了错误的预测,而光流、骨骼和红外模型预测分数分别为0.579 5、0.788 3 和0.927 2,预测正确,在进行跨模态多教师知识蒸馏后,RGB+光流的预测分数为0.087 6,效果并未得到明显的改善,而同时采用光流和骨骼进行知识蒸馏后预测分数达到了0.821 2,获得了正确的预测;对于“刷牙”动作,RGB 和光流模型对行为产生了错误的预测,预测分数分别为0.003 3和0.092 7,进行跨模态多教师知识蒸馏后,RGB+光流的预测分数为0.093 9,效果并未得到明显的改善,而同时采用光流和骨骼进行知识蒸馏后,预测分数达到0.582 9,获得了正确的预测;在图中“头痛”动作中,单一的RGB、骨骼和红外模型预测分数分别为0.314 2、0.193 6 和0.091 7,对行为产生了错误的预测,进行跨模态多教师知识蒸馏后,RGB+光流对该类的预测分数提升到了0.684 3,RGB+光流+骨骼对该类的预测分数提升到0.993 8,且热力图覆盖效果较好。可视化结果表明,光流和骨骼模态的组合作为教师网络进行多教师知识蒸馏的效果最好。

图2 单模态模型与多模态知识蒸馏模型的可视化图Fig.2 Visualization charts of single-modality models and multi-modality models based on knowledge distillation
结合上述消融实验,本文提出的基于知识蒸馏的多模态融合行为识别方法采用MSE 损失函数在骨干网络的Layer4 层输出的特征上进行知识蒸馏,采用KL 散度在预测分数上进行知识蒸馏,同时采用光流和骨骼模态的组合作为多教师网络对RGB 模态学生网络进行多教师知识蒸馏。
2.4 主流数据集上多模态融合研究的实验对比
实验主要就本文提出的基于知识蒸馏的多模态融合行为识别方法在主流的多模态数据集NTU 60、UTD-MHAD 和N-UCLA 以及主流的单模态数据集HMDB51 中与其他多模态融合算法进行综合实验对比。其中,NTU 60 数据集中使用CS 和CV 指标,N-UCLA 数据集中使用最常用的View3 指标,HMDB51 数据集中使用3 个Split 的平均准确率指标。
基于NTU 60 数据集的多模态融合方法识别准确率对比如表8 所示,其中,第1 行3D-ResNeXt-101是RGB 单模态网络的识别准确率,作为多模态识别准确率提升的对比基准。本文方法对应的CS、CV指标分别为90.09%和94.00%,相比于基准分别提升3.49 和1.13 个百分点,与其他方法相比也达到了较高的识别准确率。值得注意的是,表格中对比的其他方法[19,22-25]都是采用多流融合的方法,即在测试阶段同时输入多个模态数据,计算并融合多个模态网络的特征或预测分数,而本文所提出的基于知识蒸馏的多模态融合行为识别方法,在测试阶段只需要使用RGB 模态数据,不但降低了测试阶段的计算复杂度,而且获得了较高的识别准确率。准确率对比证明了本文提出的基于知识蒸馏的多模态融合行为识别方法能够很好地将多模态特征的互补优势融合到RGB 模态网络中。
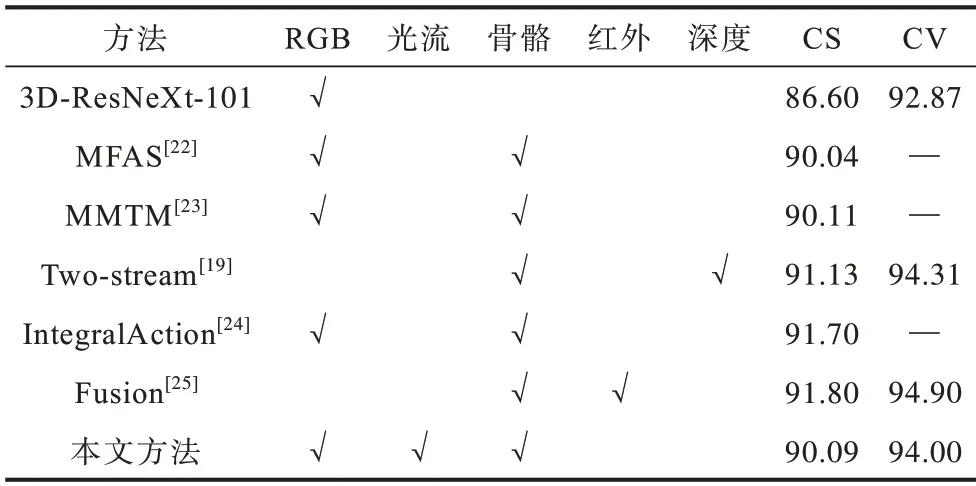
表8 NTU 60 数据集上多模态融合方法识别准确率对比Table 8 Comparison of accuracy by the multi-modality fusion methods on NTU 60 dataset %
基于HMDB51 数据集的多模态融合方法识别准确率对比如表9 所示,其中,第1 行3D-ResNeXt-101是RGB 单模态网络的识别准确率,第2 行LGD-3D[26]使用ResNet-101 作为骨干网络,并采用RGB 和光流融合的方法,它们作为多模态知识蒸馏方法实验的对比基准。表格中的数据对比采用常用的3 个Split准确率的平均来表示,例如本文方法3 个Split 指标的准确率分别为80.39%、82.03%和81.37%,平均准确率为81.26%,相比于基准提升了7.34 个百分点。表9 中MARS[7]和D3D[8]网络都是研究RGB 和光流的多模态融合,MARS[7]在特征上通过MSE损失函数进行知识蒸馏;D3D[8]在预测分数上通过MSE 损失函数进行知识蒸馏。本文方法同时在特征上使用MSE 损失函数,在预测分数上使用KL 散度进行知识蒸馏,并取得了优于MARS[7]和D3D[8]网络的性能,准确率与之相比分别提升了1.96 和2.56 个百分点。本文方法在HMDB51 上通过Openpose[17]将RGB 模态转换成相应的骨骼模态,而PERF-Net[9]通过PoseNet[10]从RGB 图像中提取骨骼信息,然后叠加在RGB 模态上作为姿势模态数据,采用多教师知识蒸馏结构将姿势和光流模态同时作为教师网络,在预测分数上通过MSE 损失函数对RGB 学生网络进行知识蒸馏。相比于使用的原始骨骼信息,姿势模态保留了RGB 外观信息,本文方法得到了与PERF-Net[9]相近的结果。
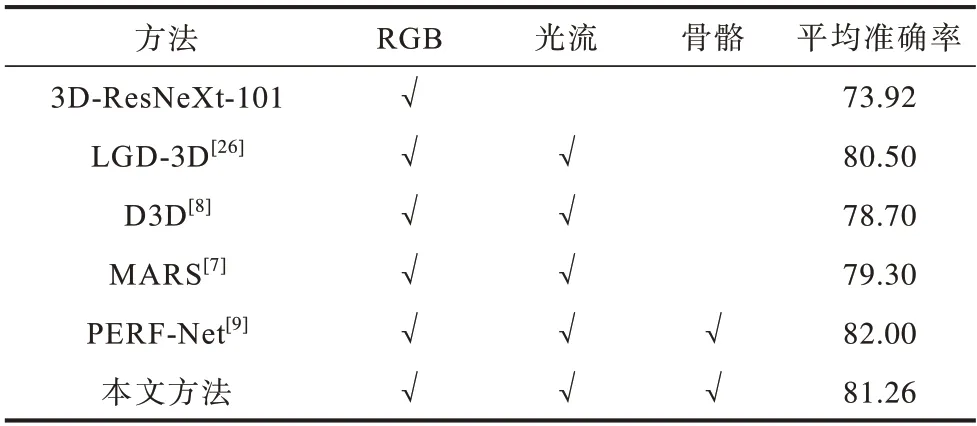
表9 HMDB51 数据集上多模态融合方法识别准确率对比Table 9 Comparison of recognition accuracy by the multi-modality fusion methods on HMBD51 dataset %
基于UTD-MHAD 和N-UCLA 数据集的多模态融合方法识别准确率对比如表10 和表11 所示,其中第1 行3D-ResNeXt-101 是RGB 单模态网络的识别准确率,作为多模态识别准确率提升的对比基准。本文提出的基于知识蒸馏的多模态融合行为识别方法在UTD-MHAD 和N-UCLA 数据集上的识别准确率分别达到95.12%和97.82%,相比于基准提升了2.54 和3.21 个百分点。与表中的其他主流多模态融合方法相比,本文方法在UTD-MHAD 数据集上获得了最高的准确率,在N-UCLA 数据集上获得了第二高的准确率,仅次于Hierarchical[16]的98.92%。需要指出的是,Hierarchical[16]在测试阶段需要同时输入RGB 和骨骼2 种模态的数据进行推理。相对而言,本文采用基于知识蒸馏的多模态融合行为识别方法,通过知识蒸馏在训练阶段将其余模态知识转移到RGB 模态网络中,因此在推理阶段仅需要提供RGB 模态数据。通过在UTD-MHAD 和N-UCLA 数据集上与近年来其他先进的多模态融合行为识别算法的对比,验证了本文方法的有效性。

表10 UTD-MHAD 数据集上多模态融合方法识别准确率对比Table 10 Comparison of recognition accuracy by the multi-modality fusion methods on UTD-MHAD dataset%
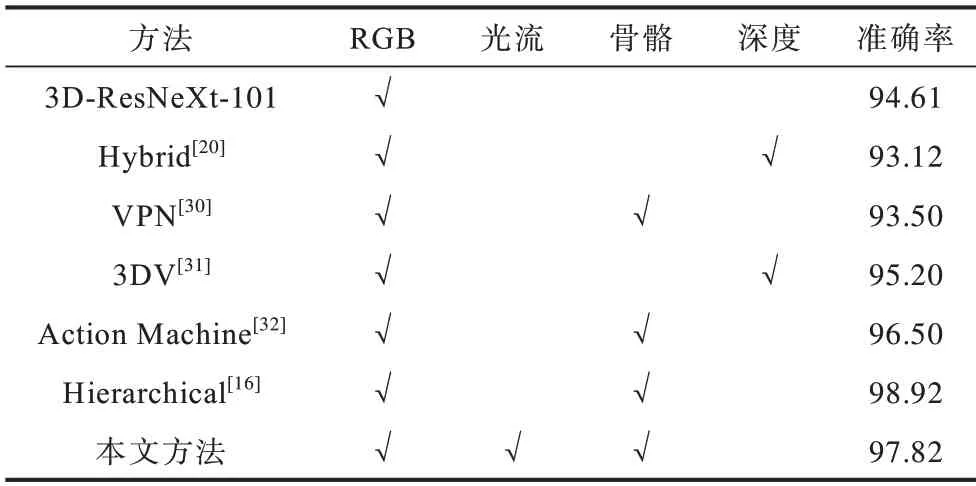
表11 N-UCLA数据集上多模态融合方法识别准确率对比Table 11 Comparison of recognition accuracy by the multi-modality fusion methods on N-UCLA dataset %
3 结束语
本文提出一种基于知识蒸馏的多模态融合行为识别方法,通过实验和可视化分析表明在特征上采用MSE 损失函数并在预测分数上采用KL 散度进行知识蒸馏可以有效提升行为识别准确率,此外,将骨骼和光流模态的组合同时作为教师网络对RGB 模态学生网络进行知识蒸馏可以获得最高的行为识别准确率。在NTU RGB+D 60、UTD-MHAD 和Northwestern-UCLA Multiview Action 3D 以及HMDB51数据集上进行测试,结果表明,所提出的方法分别达到了90.09%、95.12%、97.82%和81.26%的识别准确率,其中UTD-MHAD 数据集上的识别准确率相比于单模态RGB 数据获得了3.49、2.54、3.21 和7.34 个百分点的提升。后续研究可以考虑在知识蒸馏的过程中通过自注意力网络将多模态教师网络的特征语义信息与RGB 学生网络的特征语义信息对齐,从而进一步优化多模态融合的性能。
