基于分类器链的多联机软故障水平辨识研究
2023-10-17何宇轩石靖峰周镇新陈焕新任兆亭夏兴祥程亨达
何宇轩 石靖峰 周镇新 陈焕新 任兆亭 夏兴祥 程亨达
(1 华中科技大学能源与动力工程学院 武汉 430074;2 青岛海信日立空调系统有限公司 青岛 266510)
多联机空调系统可以实现在不同的室内热负荷下良好运行[1-3],且因其所需空间更小、在建筑内安装和维护更方便等原因而被广泛应用[4-6]。在多联机系统的运行中,不可避免地会发生各种故障[7],而空调系统的故障会导致能源的严重浪费[8-10]。多联机故障中,诸如室外机脏污一类的故障是一种累积性的故障,可称之为“软故障”[11]。软故障形成的时间相对较长,具有明显的不同故障程度的区分,形成初期对系统影响较小,且形成时间不容易确定[12]。软故障一般不会使系统失效,但其逐步形成会使空调的运行参数逐渐偏离设定值,使用户的舒适感严重下降。此外,若要空调系统做到精确的自动控制,不仅需要优秀的控制系统,更要考虑到当前的故障程度对空调系统各个参数的影响。若能通过自动故障诊断与检测系统辨识出系统当前软故障水平,对用户热舒适性的优化、确定系统维护频率以及减少系统能耗均有重大作用。
Chen Jianli等[13]将暖通空调系统故障检测与诊断的计算方法分为三类:基于知识的方法、基于数据驱动的方法以及基于知识和数据驱动的混合方法。基于数据驱动的方法直接分析系统传感数据来识别空调系统的故障,主要特点是无需构造复杂精确的数学模型,也无需专家知识,对复杂系统的适用性良好,因此受到许多研究者的青睐。韩华[14]针对制冷系统的故障检测与诊断,利用基于互信息的过滤模型以及基于遗传算法的封装模型实现数据的特征选择,利用主成分分析法实现特征提取,与支持向量机算法相结合,构造了一个对制冷系统单发故障命中效果理想的顺序集成模型。与单纯的支持向量机模型相比,加入了基于遗传算法的集成模型在制冷剂泄漏以及制冷剂过量这两类故障上的诊断准确率有了较大提升。范波等[15]建立了多联机系统的动态仿真模型,并利用该模型生成正常运行数据以及制冷剂泄漏故障数据,构建并训练了一种基于XGboost算法和类随机森林算法的多联机故障诊断模型,模型对故障的检测准确率达到98.7%,并可以很大程度上避免误报。Zeng Yuke等[16]针对多联机系统的制冷剂充注量故障诊断,提出一种新型非神经网络的深度学习模型——基于树状结构的级联森林模型,准确率达到94.16%,高于BP神经网络、SVM等传统算法。魏文天等[17]同样针对多联机系统的制冷剂充注量故障,改进了传统的Boosting算法,将其模型中的基分类器换成了5个各不相同的基分类器,提出了一种可用于水平辨识的集成模型。结果表明,基于Boosting算法的集成模型对制冷剂充注量故障的水平辨识能力较好,故障诊断准确率可达到96.8%,且高于任何一种基分类器单独使用的效果。
上述研究结果均存在一定的局限性。部分研究数据是通过仿真模型获得,与实际运行情况可能存在偏差,而在使用故障实验数据的水平辨识研究中,大部分研究均以制冷剂充注量故障为训练数据的来源或主要研究对象,以换热器脏污故障为研究对象的相对较少。此外,大多数研究未探究所使用的故障诊断模型中的模型参数以及数据标签对于诊断结果的影响。针对上述问题,本文提出一种基于一维卷积神经网络的故障诊断模型,并使用分类器链算法,以室外脏污故障数据为样本,实现多联机系统中软故障的水平辨识。该模型能够较好地辨识多联机软故障的各个水平,且在优化参数以及调整编码方式后,诊断准确率有进一步提升。
1 故障实验和数据分析
本研究以室外机换热器脏污故障为研究范例,建立多联机系统软故障的水平辨识模型。涉及的数据均在某多联机空调系统下实验获得,按标准进行性能实验,以进行故障诊断模型的训练与验证。相关多联机系统结构如图1所示。多联机系统采用R410A为制冷剂,额定充注量为9.9 kg。系统可分为室外部分以及室内部分,室外部分包括全封闭式涡旋压缩机、油分离器、四通换向阀、室外机换热器、气液分离器以及电子膨胀阀等设备。室内部分设置5台室内机,每台室内机均带有1个电子膨胀阀。

图1 实验用多联机系统结构
室内机换热器脏污故障主要形成原因为老化或被灰尘覆盖导致的换热器散热或通风受阻,换热性能降低[18]。因此实验采用减少室外机进风口面积的方法模拟因换热器脏污造成的进风口风量减小,将堵塞面积与进风口原面积之比定义为室外脏污强度[19]。实验分别在0(即正常运行)、20%、40%、60%、80%脏污5种不同的室外机脏污水平下采集了多联机系统的运行数据。实验在制冷及制热两种模式下均采集了数据,实验工况如表1所示,实验中不同开机台数所对应的脏污程度如表2所示。实验包含3种室内机的运行模式,分别为全开、三开和单开,全开指5台室内机均开启,三开指5台室内机只开启3台,单开指5台室内机只开启1台。获得运行数据之后,经整理作为后续搭建的卷积神经网络的输入数据。
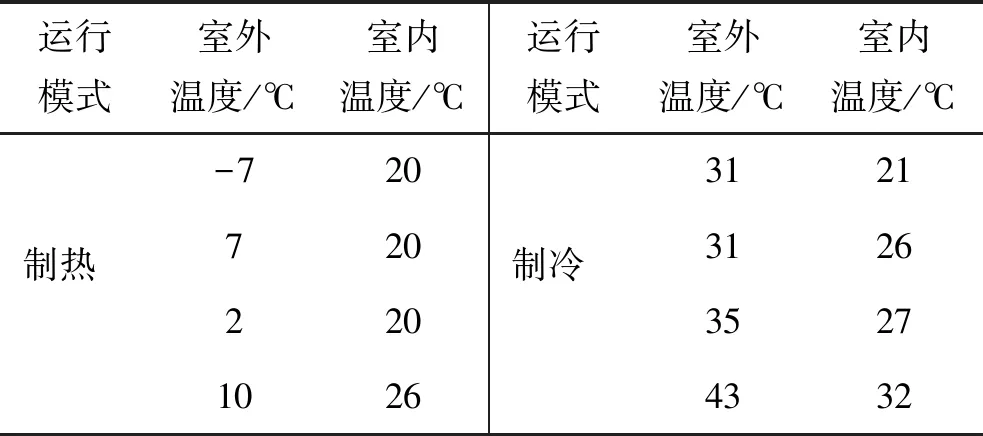
表1 数据采集实验工况

表2 实验中不同开机台数所对应的脏污程度
采集到的各工况各脏污情况下的多联机系统运行参数共52 740条,其中发生室外脏污故障的数据47 388条,正常情况下的数据5 352条,20%脏污的数据11 579条,40%脏污的数据11 579条,60%脏污的数据12 286条,80%脏污的数据11 944条。在脏污工况数据中,选取70%的数据为训练集,用作神经网络的输入,起到训练神经网络模型的作用,使其可以通过这些训练数据提取出正常数据与故障数据的隐含特征;剩余30%的数据为测试集,在神经网络模型训练完成之后将其作为模型的输入,将模型的检测结果与实际情况进行对比,以此评价神经网络故障检测模型的性能。每条数据对应在一个时间点机组的运行状况,包含压缩机吸排气温度、室内机出回风温度等56个参数。
2 分类器链模型的构建
2.1 一维卷积神经网络及分类器链
卷积神经网络与BP神经网络类似,是一种从输入到输出的非线性映射,在解决非线性问题方面表现出十分优秀的性能[20]。卷积神经网络的主要组成部分有数据输入层、卷积层、池化层、全连接层和数据输出层。根据数据输入层的数据维度主要可以分为一维卷积神经网络、二维神经网络以及更高维度的神经网络。一维神经网络能够有效处理序列数据的模式识别、分类问题,因所采集的多联机数据每条均可视为一维序列数据,所以本文采用一维卷积神经网络进行模型的构建。
在需要被分类的样本数据中,每个数据有多种类别标签,在每种类别标签上均要对样本数据进行分类,即多分类问题。分类器链算法是解决多标签分类问题的一种算法,其核心思想是将多标签分类问题转化为多个二分类问题,建立多个二分类器,其中后执行的二分类器会将之前的二分类器的分类预测结果视作输入数据的一部分,并在此基础上做出分类判断,形成一个链状形式的分类器。分类器链方法的这种特点可以考虑到标签之间的相关性,在各个标签非独立的多标签分类问题下给出更为准确的预测。分类器链方法与非分类器方法的对比如表3所示。
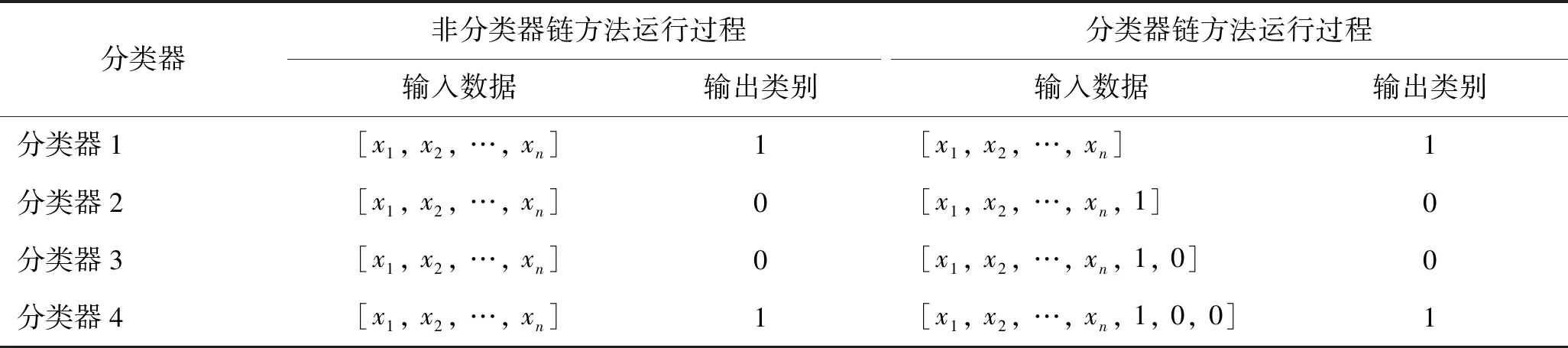
表3 非分类器链方法与分类器链方法的对比
非分类器链方法的诊断策略是:将每一个标签当做独立的来看待,互不影响或同时对各个标签进行判断。本研究以多联机软故障的不同水平作为不同的数据标签,因为软故障不同水平之间并非独立,导致标签与标签之间存在相互影响的隐含关系。分类器链方法对各个标签按顺序进行诊断,且每次诊断会将上一个标签的诊断结果纳入此次的考虑范围之内,更适用于水平辨识问题。因此,本研究使用一维卷积神经网络作为分类器链中的基分类器,每一个基分类器对应不同的软故障水平,建立基于分类器链的多联机软故障水平辨识模型。
2.2 基分类器的参数设置
建立神经网络分类器模型需要设置的参数较多,但由于神经网络模型的结构多样,随着具体问题的变化而不同,并且各参数对模型最终效果的影响机制复杂,截至目前针对神经网络中各参数的选取仍没有一个较好的通用原则。为得到水平辨识模型中基分类器的较佳参数设置,本研究以正常数据与故障数据作为输入数据,训练一个可用于故障检测的二分类模型。在该模型中将各个参数分离调整,并以模型预测准确率达到较高水平时的网络结构和参数设置作为水平辨识模型中基分类器的网络结构和参数设置。最终确定的网络结构如图2所示,各参数如表4所示,表中还列出了在调整过程中各参数的选择范围以及各参数对模型准确率的影响程度,便于后续模型的再调参。
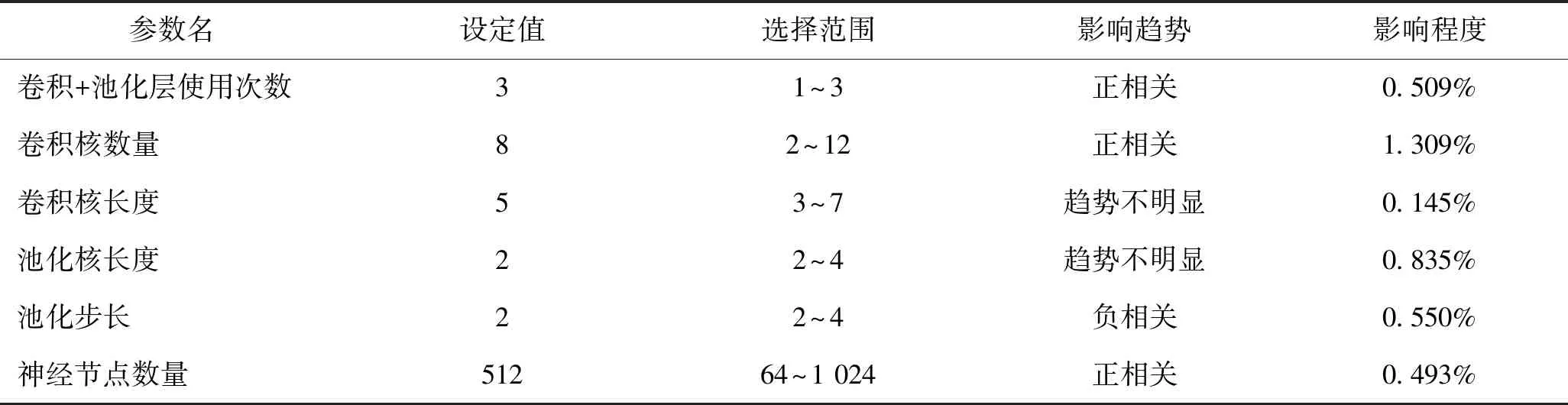
表4 基分类器参数设置

图2 基分类器网络结构
在该参数设置下,故障检测模型达到99.24%的预测准确率,混淆矩阵如表5所示,且后续的参数调整对模型准确率的影响已无明显提高。因此,将此参数设置定为分类器链中基分类器的初始参数设置。
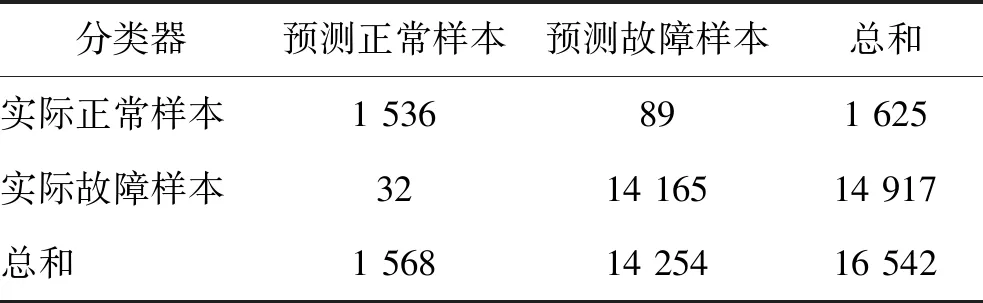
表5 故障检测结果
2.3 数据标签的编码方式
数据标签一般使用独热编码表示。独热编码主要是采用N位状态寄存器对N个状态进行编码,每个状态都有独立的寄存器位,且任意时候只有一位有效。为了在数据标签层面同样考虑到各个水平之间的相关性,使编码方式与分类器链模型的特点相配合,本文仿照独热编码提出了两种新的编码方式,从标签上体现出脏污水平的变化,如表6所示。

表6 本文提出的编码方式与独热编码方式的对比
可以看出,若只用4位编码,独热编码无法表示5种脏污状态(包括正常工况),必须采用5位编码来表示。而本文提出的编码方式均可以做到只用4位编码表示5种脏污状态,节省了数据储存空间与计算量,同时1或0值随着脏污水平逐增的编码方式也与分类器链方法的内含逻辑较为匹配。
2.4 分类器链水平辨识模型的建立
本文以一维卷积神经网络分类器作为分类器链模型中的基分类器,建立了多联机系统室外脏污故障水平辨识模型,模型的训练和验证流程如图3所示,具体步骤如下。

图3 模型训练和验证流程图
1)构建4个基分类器,分类器层数以及每层超参数参照3.1节表4设置。输入数据按7∶3的比例分为训练集和测试集,每条数据由两部分组成,分别为室外脏污的数据样本x1=[x1,x2,x3,…,xn]T和对应其脏污程度的数据标签y1=[y1,y2,y3,y4]。
2)将训练集中数据样本x1作为第一个二分类模型的输入数据,数据标签的第一项y1作为目标类别,训练一个二分类模型。
3)将x1与y1结合,得到新的数据样本x2=[x1,x2,x3,…,xn,y1]T作为第二个二分类模型的输入数据,数据标签的第二项y2作为目标类别,训练第二个二分类模型。
4)以此类推,第三个二分类模型的输入数据为x3=[x1,x2,x3,…,xn,y1,y2]T,目标类别为y3;第四个二分类模型的输入数据为x4=[x1,x2,x3,…,xn,y1,y2,y3]T,目标类别为y4,完成所有四个二分类模型的训练。
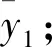

3 多联机脏污故障水平辨识结果
建立了基于分类器链的室外机脏污故障水平辨识模型之后,即可将测试集输入模型并评估模型效果,根据模型实际的诊断效果进行参数的优化。除了整体诊断准确率之外,使用精确率和召回率作为评价指标,以判断水平辨识模型在故障的每个具体水平上的诊断能力,精确率和召回率的表达式如式(1)、式(2)所示。
(1)
(2)
式中:i为数据类别;NTT为被模型正确判断为i类的i类样本数量;NTF为被模型错误判断为i类的非i类样本数量;NFT为被模型错误判断为非i类的i类样本数量。
3.1 水平辨识初步诊断结果


图4 水平辨识模型初步诊断结果
而使用编码方式1与编码方式2的分类器链模型整体诊断效果相似,且误诊为无故障的样本数量均为0。由召回率和精确率的分布可知,这两个模型对于较低水平和较高水平的诊断效果较好,两个模型在20%脏污水平和80%脏污水平的精确率均超过了95%。但在脏污故障处于中等水平时,模型诊断效果并不理想,在40%和60%脏污水平下,召回率和精确率都很低,两个模型均仅有约90%。由混淆矩阵也可以看出,模型在中等水平脏污下预测错误的样本数量较多。从诊断准确率来看,三种编码方式的总体诊断准确率差异较小,均在93%~94%之间。但在实际应用中应避免将故障工况诊断为正常工况的漏诊情况,因此本文提出的编码方式在诊断效果上要稍优于独热编码模型。
3.2 参数及编码方式的优化调整
因为分类器链模型是由多个基分类器组成,而此处的基分类器中的各种超参数是以3.1节中建立的故障检测模型为基准设置的,可能对水平辨识模型适配性有所降低,因此应对超参数再加调整,进一步优化模型。由表3可知,对模型整体诊断准确率影响较大且趋势明显的参数有卷积层与池化层的交替使用次数和卷积核的数量。现在所用的模型中,卷积层与池化层已经交替使用了3次,为了不使模型结果过于复杂,对其不做调整,本文对卷积层中卷积核数量进行调整,调整结果如图5所示。
由图5可知,在增加了卷积核数量之后,3种模型的诊断准确率均显著提升。对于使用编码方式2的模型,卷积核数量的增加对诊断准确率的影响较小,当卷积核数量由8提升至18时,使用编码方式2的模型的准确率增加了2.57%,而使用编码方式1和独热编码的模型的准确率分别增加了1.59%和1.82%。卷积核数量达到18时,三种模型的诊断准确率分别为95.44%、95.47%与95.99%,混淆矩阵如图6所示。在增加了卷积核数量之后,使用独热编码的模型的特殊误诊情况有所缓解,但仍有较多数量的故障数据样本被识别为了正常样本。使用编码方式1与编码方式2的模型误诊为无故障的样本数量仍保持为0。

图6 增加卷积核数量后模型诊断结果
分别针对不同的脏污水平来看模型的结果,可以发现,模型对不同的脏污水平有着不同的识别能力。对于较低水平的脏污故障,模型并未表现出明显的趋势。但对于80%脏污水平的数据,无论是召回率还是精确率,分类器链模型的表现均较为优秀。说明分类器链模型对于严重脏污的水平辨识能力较高,辨识轻度脏污的能力较差。对比调整卷积核数量之前的结果,可以发现模型在中等水平脏污下的召回率和精确率均有一定的提升。
考虑到采集到的数据样本x中各参数是多联机的各运行参数,如温度、压力等,其中的数据xn取值跨度较大,最大值达到60以上,最小值达到-10以下,而在分类器链模型的训练过程中,直接将基分类器的预测结果,即0或1附在x末尾,由于1的值过小,附加之后对于数据的特征改变不明显,可能导致后续的基分类模型不能很好的识别上次预测结果这个附加的数据特征。因此,对模型编码方式作出如下改变:当上一个基分类器输出为1时,将其放大k倍再附加在x末尾。经过多次实验,发现k值对3种编码方式的模型预测准确率的影响如图7所示。
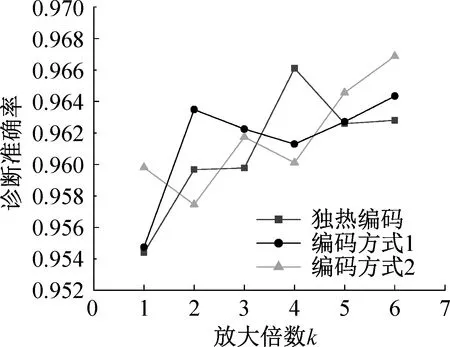
图7 放大倍数k对模型诊断准确率的影响
在将基分类器输出放大了k倍之后,3种编码方式的整体诊断准确率略有上升。当k值取为6时,此时3种编码方式诊断结果的混淆矩阵如图8所示。
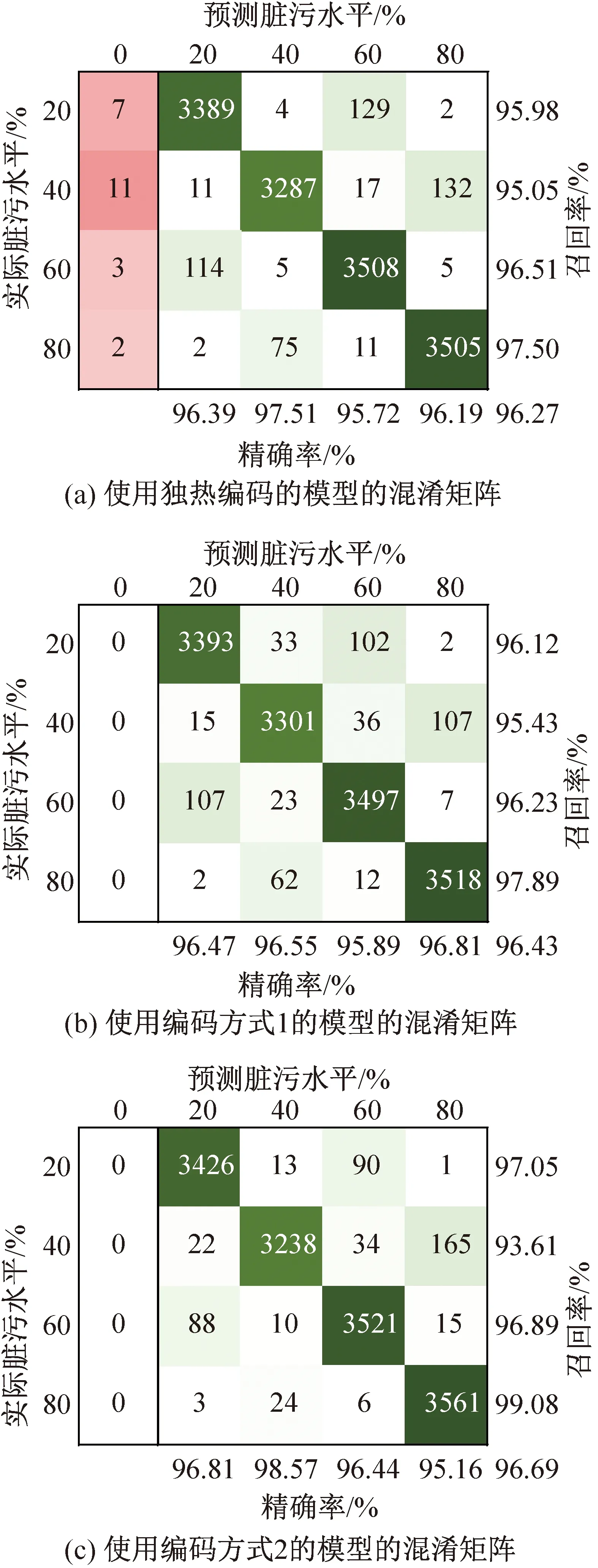
图8 放大分类器输出后模型诊断结果
对照图6可知,采用放大输出的方法可以避免独热编码的误诊率,相比于k值取1时的情况,独热编码模型将故障数据检测成为正常数据的概率下降很多,由3.4%降至0.16%。对于使用另外两种编码方式的模型,诊断准确率分别上升0.96%和0.70%,精确率和召回率也稍有改善。
综合上述研究结果可知,基于分类器链的软故障水平辨识模型在经过进一步调参之后可以达到较好的效果,对室外脏污故障的水平辨识可以达到96%以上的故障诊断准确率。3种编码方式的诊断准确率相差较小,但相比于传统的独热编码,本文提出的两种编码方式能更好地解决模型将故障数据诊断为正常工况的情况。还可采用把基分类器的输出放大再与下一个基分类器的输入数据结合的方法来进一步提升模型诊断效果,该方法可以减少独热编码模型漏诊的概率,也能提高其他模型的诊断准确率。
4 结论
本文提出一种基于一维卷积神经网络的多联机系统故障诊断模型,该模型可以实现软故障的水平辨识。模型使用分类器链算法,将基分类器链式连接,对每个故障水平进行分类。通过故障检测实验确定了基分类器中重要参数的取值及其对诊断准确率的影响,并提出了新的编码方式以适应分类器链模型。建立分类器链模型之后,针对初步诊断结果的不足进行了调整。得到结论如下:
1)分类器链方法能较好地解决多联机软故障的水平辨识。使用分类器链模型对室外机脏污故障进行诊断,准确率可达96%以上,最高达到96.69%。模型对于脏污水平较高的情况较为敏感,对于80%脏污水平的召回率最高可达99.08%。
2)相比于传统的独热编码方式,使用本文提出的编码方式来处理数据标签并训练模型,能够有效防止将故障工况诊断为正常工况的情况,更适合在分类器链模型中使用。
3)改进了基分类器输入数据的编码方式,提出了放大基分类器输出的方法,即将分类器链模型中较前端的分类器输出放大后再进行下一步操作。使用该方法可以较好解决独热编码模型的误诊问题,且使3种编码方式的准确率均上升了0.7%~0.96%。
综上所述,基于一维卷积神经网络的分类器链模型可以有效地实现多联机系统的软故障水平辨识,对数据标签的编码方式优化可以使分类器链模型的诊断效果提升。
