基于深度学习的无人机航拍视频多目标检测与跟踪研究进展
2023-10-17苑玉彬吴一全赵朗月陈金林赵其昌
苑玉彬,吴一全,赵朗月,陈金林,赵其昌
南京航空航天大学 电子信息工程学院,南京 211106
多目标检测与跟踪作为遥感领域的重要课题之一,广泛应用于智慧城市、环境监测、地质探测、精准农业和灾害预警等民用和军事领域[1-4]。传统的遥感数据获取主要基于卫星和载人飞机平台,这类平台运行在固定轨道上或遵循预定路径,其成本及飞行员的安全问题限制了应用范围。随着电子通信技术的发展,无人机(Unmanned Aerial Vehicle,UAV)以轻便 性、易操作、低成本等优势得到快速推广,弥补了传统手段受天气、时间等限制造成的部分信息缺失。同时,相比固定摄像头,UAV的高机动性可以使航拍范围更为灵活可变。UAV获取的视频数据无论在内容上还是在时间上信息量都极大,推动了无人机航拍视频在目标检测和跟踪多个领域中发挥着日益重要的作用[5-7]:① 智能交通流量监控与红绿灯配时控制,提升交通通行能力;② 对特定区域内的人群或车辆进行安防监控、跟踪及定位;③ 对水面舰船检测、识别与跟踪;④ 检测野生动物的数量并跟踪其运动轨迹;⑤ 分析体育运动员动作与轨迹,实现相应战术分析;⑥ 农业区域绘图,自动绘制飞行路线。但是,无人机航拍视频与普通视角视频中的多目标检测和跟踪任务相比,面临诸多挑战,例如图像退化、目标分布密度不均匀、目标尺寸小,以及实时性等问题,近年来引起学术界和工业界的广泛关注和大量研究。
作为计算机视觉的基本问题之一,多目标检测和跟踪经历了从传统方法阶段到基于深度学习方法阶段的演变。传统方法需要手动设计特征,过程繁琐且准确率低[8-9]。随着UAV与深度学习技术的发展,航拍视频的数据采集愈加便捷,易于获得海量数据,而深度神经网络能够学习到具有足够样本数据的分层特征[10]。自2015年以来,深度神经网络已成为多目标检测和跟踪的主流框架[11-12]。多目标检测和跟踪包括多目标检测和多目标跟踪2个部分。经典的深度目标检测网络分为2大类:双阶段网络和单阶段网络。其中,双阶段检测算法检测精度高,但运行速度慢;单阶段检测算法运行速度快,但误报率高。双阶段网络,如RCNN(Region-CNN)[13]、Fast R-CNN[14]、Faster R-CNN[15]和Cascade RCNN[16]等,首先需要生成候选区域,然后对候选区域进行分类和定位,适于具有更高检测精度要求的应用;单阶段网络,如SSD(Single Shot Multi Box Detector)[17]、YOLO(You Only Look Once)[18-22]系列和CenterNet[23],直接生成坐标位置和类概率,比双阶段网络更快。因此,更快的单阶段网络在具有高速要求的UAV实际应用中极具优势。
本文以无人机航拍视频的双阶段和单阶段目标检测算法为主线,回顾了2类算法的发展历程,总结了其代表性工作,重点介绍了应对无人机视角引起的小目标增多、目标尺度跨度大、数据集头尾分类不均衡等问题,以及提升检测精度,采取的网络结构优化、引入注意力机制、多种特征融合、多种网络综合等措施。将多目标检测从静态图像扩展到视频连续帧的范围时,延展到了多目标跟踪(Multiple Objects Tracking,MOT)课题。基于深度学习的MOT方法可分为基于检测的跟踪(Tracking Based Detection,TBD)和联合检测的跟踪(Joint Detection Tracking,JDT)2类[11]。TBD算法的多阶段设计结构清晰,容易优化,但多阶段的训练可能导致次优解;JDT 算法融合了检测模块和跟踪模块,达到了更快的推理速度,但存在各模块协同训练的问题。TBD策略可分别优化检测和跟踪,更加灵活,适用于复杂场景,但推理时间长。相反,JDT将检测与跟踪模型合并到一个统一的框架中,通过添加跟踪分支来修改检测器,并根据目标的共性实现检测和跟踪。在普通视角下的应用中,JDT在简单场景中比TBD表现得更好更快,但处理复杂的场景时效果不佳,因此UAV视角下的多目标跟踪多遵循TBD模式。本文以TBD模式为主要框架,阐述了基于目标特征建模、基于目标轨迹预测、基于单目标跟踪(Single Object Tracking,SOT)辅助、基于记忆网络增强等多目标跟踪算法。
除了针对具体问题对多目标检测与跟踪算法改进之外,基于无人机航拍视频的多目标检测与跟踪数据集的构建与挑战赛的举办也推动了其快速发展,其中数据集正向大规模、长时间、多样化的方向进一步发展。本文全面梳理和比较了近年来无人机航拍视频的多目标检测与跟踪任务的数据集,对面向无人机视角的多目标检测与跟踪的标杆挑战赛VisDrone Challenge的主要结果进行了对比与分析。尽管在无人机视角下多目标检测与跟踪算法在上述数据集上取得了较高的精度,但距离实际应用还存在一定的差距,为此本文最后从诸多方面详尽探讨了未来的发展趋势。
目前可查阅到的关于无人机视角下的多目标检测与跟踪的综述有文献[24-29]。文献[24]介绍了深度学习在无人机航拍图像中的目标检测、视频中的目标检测和视频中的目标跟踪3个方向的应用,并对一些先进的方法使用4个基准数据集进行了性能评估,但在对UAV视角下的算法介绍中糅杂了普通视角下的算法。文献[25]梳理了基于无人机的深度学习算法在环境监测、城市治理和农业管理不同领域中的应用。文献[26]总结了利用无人机航拍图像进行地面车辆检测的深度学习技术。文献[27]介绍了UAV视角下2D目标检测的最新进展,重点关注普通视角与UAV视角之间的差异。文献[28]综述了无人机视角下的基于相关滤波的跟踪算法和基于深度学习的跟踪算法研究现状。文献[29]综述了普通视角和无人机视角中目标检测的算法,发现YOLO系列是应用最广泛的网络。但现有文献仍然缺乏对多目标检测与跟踪最新进展的全面综述。本文以UAV航拍视频为研究对象,全面回顾了基于深度学习的无人机航拍视频多目标检测和跟踪算法,通过系统地总结最新公开的研究论文,讨论需要解决的关键问题和面临的难点,并展望了未来的发展方向。本文其余部分组织如下:第1节概述了普通视角下多目标检测与跟踪算法进展,第2节阐述了基于深度学习的无人机航拍视频的多目标检测算法,第3节总结了基于深度学习的无人机航拍视频的多目标跟踪算法,第4节介绍了无人机航拍视频多目标检测与跟踪常用数据集并对标杆挑战赛Vis-Drone Challenge的结果进行了分析,第5节指出了基于深度学习的无人机航拍视频多目标检测与跟踪面临的困难与挑战,第6节结合研究现状对后续的研究方向进行了展望。
1 多目标检测与跟踪方法基础
普通视角下的多目标检测与多目标跟踪之间存在诸多联系。多目标检测只需检测出所有指定类别的目标,无需关注多个目标之间的关系;多目标跟踪需要记录所有目标在时间序列图像中的关系,也就是目标的运动路径。本节对普通视角下多目标检测和多目标跟踪的主要发展路线与框架进行回顾,介绍了其主要联系与区别。
1.1 传统目标检测器与基于深度学习的目标检测器
多目标检测算法的发展脉络可划分为2个时期:传统目标检测算法时期和基于深度学习的目标检测算法时期。而基于深度学习的目标检测算法又分别沿着单阶段与双阶段算法2条主要技术路线发展。图1展示了从2001―2022年目标检测的发展路线图。
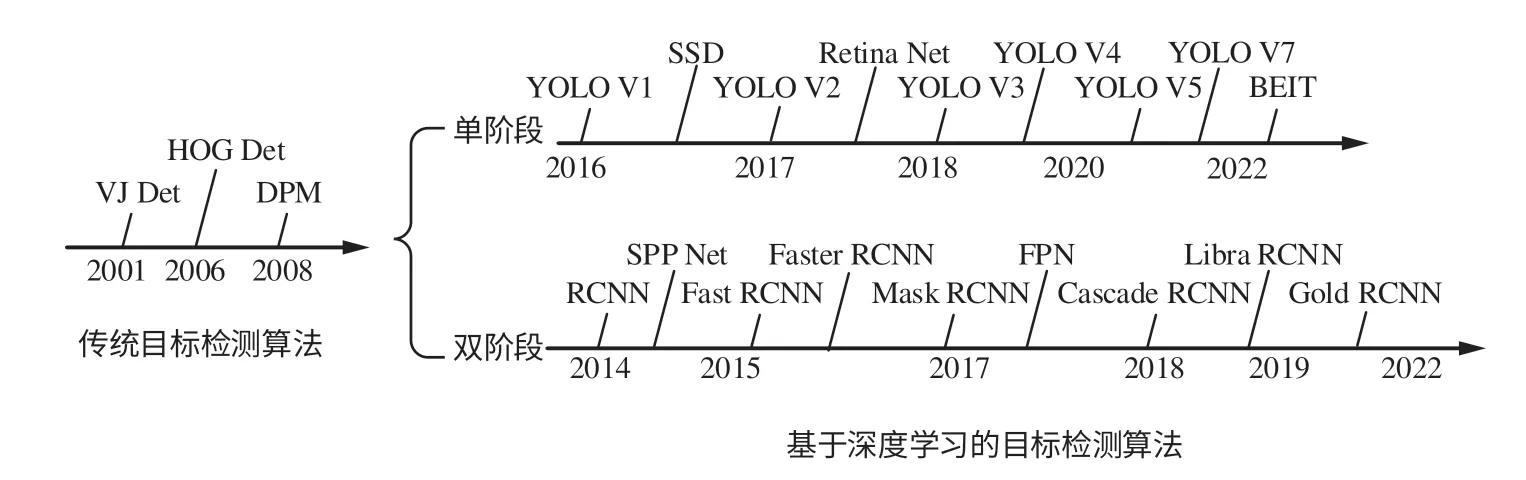
图1 目标检测发展路线Fig.1 Development route of target detection
1.1.1 传统目标检测器
以往的传统目标检测算法主要基于手工提取特征,代表性的检测器主要有VJ(Viola Jones)检测器[30]、HOG (Histogram of Oriented Gradients)检测器[31]、DPM (Deformable Parts Model)检测器[32]等。传统检测算法的流程通常为:选取感兴趣区域→定位包含目标的区域→对目标进行特征提取→检测分类。
基于自动提取特征的传统目标检测算法主要以帧差法为代表,通过对视频图像序列中相邻帧作差分运算来获得运动目标轮廓。Abughalieh等基于运动和颜色直方图投影滤波器找到目标,并使用帧差法检测运动目标,以便实现UAV视角下的目标跟踪[33]。Baykara等采用帧差法实现运动目标检测,对每个单独的目标应用形态学膨胀,提升检测精度[34]。Jiang等利用三帧差分法和中值背景减法相结合实现目标检测,达到检测响应和现有的轨迹假设之间有效关联的目的[35]。然而帧差法也存在明显的问题,其对环境稳定性要求较高,易造成目标范围内相邻帧差的目标重叠。
上述传统目标检测算法主要有以下3个缺点:准确率不高、运算速度慢、可能产生多个结果。
1.1.2 基于深度学习的目标检测器
传统目标检测算法发展陷入瓶颈,性能低下。直到2012年卷积神经网络(Convolutional Neural Network,CNN)的兴起将目标检测领域推向了新的阶段。基于CNN的单阶段和双阶段检测算法,其优缺点对比如表1所示。

表1 单阶段和双阶段检测算法的优缺点对比Table 1 Comparison of algorithms for one-stage and two-stage detection
基于深度学习的目标检测算法最初以图像分类算法为基准,将图像进行切块分类,图像块的位置和类别作为检测结果。随着基于分类的算法出现了边界目标无法检测、定位不准确、目标多尺度等问题,相应地提出了滑动窗口、增加边界框回归任务、图像金字塔等解决方法,诞生了如图2所示的双阶段多目标检测框架,在一定程度上缓解了部分问题。由于待分类的图像较多,导致速度慢,难以满足实时检测的需求。随着具备层次结构的选择性搜索策略的引入,将空间相邻且特征相似的图像块逐步合并到一起,快速地生成可能包含目标的区域,RCNN随之问世。RCNN首先通过区域提议找出可能包含目标的框,对于每一个提议区域,将其拉伸或者缩放到固定的尺寸,送入卷积神经网络得到其特征,最后对边界框进行修正和分类。
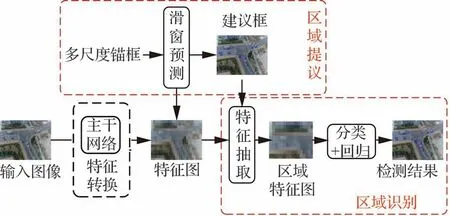
图2 双阶段多目标检测框架Fig.2 Two-stage multi-object detection framework
RCNN算法在提取特征操作中存在大量冗余,运行缓慢。Fast RCNN在RCNN的基础上加入了 ROI(Region of Interest)池化,将特征映射到每个输入ROI区域,提升了运行速度。由于使用了选择性搜索来预先提取候选区域,Fast RCNN并没有实现端到端模式。Faster RCNN使用区域生成网络(Region Proposal Networks,RPN)提取候选框,将候选区域生成、特征提取、分类器分类、回归全都交给深度神经网络来做,大幅提高了效率。在此基础上衍生出众多双阶段检测器。
由于双阶段检测器在第2阶段仅针对候选区域内容进行处理,造成了目标在整幅图像中位置信息的缺失。单阶段多目标检测器的提出弥补了这一缺陷,其流程框图如图3所示。单阶段目标检测算法无需区域提议阶段,直接产生目标的类别概率和位置坐标值,经过一个阶段即可直接得到最终的检测结果,因此有着更快的检测速度。
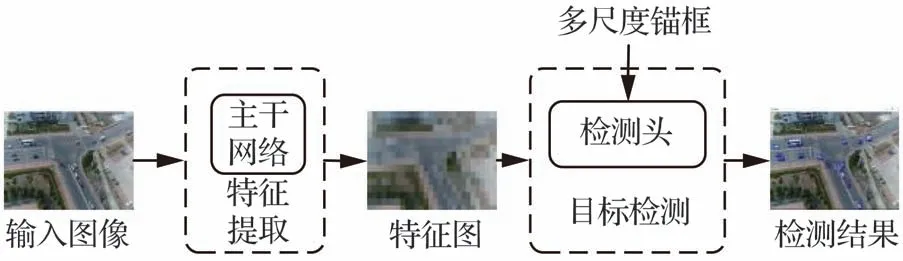
图3 单阶段多目标检测框架Fig.3 One-stage multi-object detection framework
将静态图像中的目标检测结果应用到多目标跟踪时,需要首先实现视频目标的精确检测。与静态图像目标检测不同的是,目标在视频中是动态变化的,即其自身属性诸如颜色、形状、尺寸、纹理等会动态地改变,检测过程中视频序列需要在时间和空间维度保持一致以防检测目标丢失,这成为视频目标检测任务的研究难点。
1.2 单目标跟踪与多目标跟踪
目标跟踪是给定目标的一个初始状态,然后在视频序列中估计目标每一时刻的状态。为了实现目标跟踪,对于初始帧,通过检测算法,得到一系列目标的位置坐标,在视频流中的后续帧之间进行目标关联。理想化的目标跟踪算法具有以下特点:仅在起始帧中进行目标检测处理;满足实时处理;在目标淡出或超出画面、重新进入视图、目标被遮挡等特殊情况下能够稳定跟踪。
目标跟踪又分为单目标跟踪与多目标跟踪,单目标跟踪旨在仅当目标的初始状态已知时,估计未知的视觉目标轨迹,不依赖于其他任何约束。跟踪方式有2种主流方向:第1种是判别式跟踪,通过在线刻画样本特征,属于基于参数的机制,能够非常好地区分前景与背景,并且可以在线随时更新;第2种是生成式跟踪,依据某种相似性度量离线构建一个泛化性较强的嵌入空间。这2种方式在元学习的框架下达到统一,前者可理解为参数回归;后者可视为无参的最近邻分类。
多目标跟踪是在目标数量与类别未知的情况下,对视频中的行人、汽车、动物等多个目标进行检测并赋予ID,实现后续的轨迹预测、精准查找等。多目标跟踪主要解决带有ID分类的目标跟踪中的数据关联问题,运动特征、外观特征等可用于辅助解决关联问题。多目标跟踪既要面对单目标跟踪存在的遮挡、变形、运动模糊、拥挤场景、快速运动、光照变化、尺度变化等挑战,又要面临如轨迹的初始化与终止、相似目标干扰等复杂问题。
在任务设定上,SOT、MOT、视频目标检测(Video Object Detection,VOD)都属于目标检测问题。VOD在目标检测上添加了时序信息的推广;单目标跟踪类似于视频层次的小样本目标检索任务,并在一个局部小区域上操作;而多目标跟踪则是视频层级的实例检测问题,可以理解为VOD加上帧间ID数据关联,并在视角全局进行操作。SOT领域近期效果较好的框架,均将单目标跟踪看作全局条件检测,未来关联会更加紧密。
1.3 无人机航拍视角下的区别
普通视角下的多目标检测与跟踪算法采用的数据集,大部分数据由人手持相机或固定机位拍摄,因此绝大多数图像为侧视图。而无人机航拍视频与普通视角视频相比,采集到的视频数据为俯瞰图,具有不同的特征,导致普通视角下的多目标检测与跟踪算法不能直接应用到无人机航拍视角,主要表现在以下几个方面。
首先,无人机航拍过程中,受限于设备的精度与稳定性以及环境的变化,获取的视频存在抖动、模糊增加、分辨率降低、光线干扰、画面畸变等问题,导致视频质量低,需要增加更多的预处理来提升检测与跟踪精度。
其次,航拍视角下的目标分布密度不均且尺寸小得多。行人、汽车之类的目标可能在普通视角下占据大量像素,但在航拍视角下可能仅有几个像素并且分布不均,导致目标失真,增加了多目标检测与跟踪的难度,需要设计针对性的网络模块进行特征提取。
最后,在普通视角和航拍视角下的遮挡不同。在普通视角下,目标可能被另一目标遮挡,例如汽车前面的人。但航拍视角中的遮挡多为环境遮挡,如树木、建筑物等。
综上,通过普通视角视频数据集训练得到的多目标检测和跟踪算法,无法直接应用到无人机航拍视频,需要针对无人机航拍视频的特点,设计相应的算法,以满足任务需求。
2 基于深度学习的无人机航拍视频多目标检测方法
UAV视角给多目标检测带来了小目标增多、单维度信息包含特征不足、目标类别分布稀疏及不均匀带来的检测效率低、目标检测干扰、尺度变化带来的目标漏检和误检、推理速度慢等问题。为了使检测器更好地适应UAV视角下的多目标检测,众多学者进行了诸多针对性的改进。本节将从双阶段检测器和单阶段检测器2个角度分别针对上述问题各学者提出的改进方式进行阐述。
2.1 双阶段无人机航拍视频多目标检测算法
双阶段目标检测算法在第1阶段就针对目标检测任务进行了独特设计,直接将常规视角下的算法迁移到无人机航拍视频的效果较差,需要根据无人机航拍视频的目标特点,进行优化。
1) 针对UAV造成的小目标增多问题。Avola等构建了一种多流结构,模拟多尺度图像分析。将此结构作为Fast R-CNN网络的主干,设计了MS-Faster R-CNN目标检测器,能够持续稳定地检测UAV视频序列中的目标[36]。Stadler 使用Cascade R-CNN网络作为目标检测器,将默认锚框的大小减半以考虑较小的目标,并将预估的目标数量增加了1倍[37]。Huang等提出HDHNet用于提取小目标特征,作为主干网络与HTC(Hybrid Task Cascade)、Cascade RCNN等方法相结合,在检测不同类型和规模的目标过程中提取到更为有效和全面的特征[38]。Zhang等采用多种特征融合方法构建目标特征,引入颜色直方图和HOG描述算子进行特征提取,同时充分利用ResNet-18中第1和第3卷积层的特征,缓解了UAV场景的复杂性和小目标带来的挑战[39]。Liu等提出一种高分辨率检测网络HRDNet,采用多分辨率输入,具有多种深度主干。同时,设计了多深度图像金字塔网络(Multi-Depth Image Pyramid Network,MD-IPN)和多尺度特征金字塔网络(Multi-Scale Feature Pyramid Network,MS-FPN)。MD-IPN使用多个深度主干维护多个位置信息,从高分辨率到低分辨率提取各种特征,解决了小目标上下文信息丢失的问题,并保持对中大型目标的检测性能[40]。Liu等提出多分支并行特征金字塔网络(Multi-branch Parallel Feature Pyramid Networks,MPFPN),旨在以较小的尺寸提取更丰富的目标特征信息,并行分支能够恢复深层中缺失的特征,同时采用监督空间注意力模块(Supervised Spatial Attention Module,SSAM)来削弱背景噪声推理和聚焦目标信息的影响[41]。
2) 针对单维度信息包含特征不足问题。Azimi等使用Siamese网络提取视觉特征,并与LSTM(Long Short-Term Memory)和图卷积神经网络进行配合,融合了目标的外观、时间和图形信息[42]。Du等提出基于HTC网络的检测器DetectorRS,引入递归特征金字塔,代替原来的特征金字塔网络[43]。Tøttrup等提出Track R-CNN网络,结合检测、跟踪和分割的思想,扩展了具有3D卷积的Mask R-CNN,将目标检测的分辨率提升到了像素级[44]。Albaba等为了解决UAV引起的目标变化及纹理特征差异的问题,在Cascade RCNN中引入CenterNet,降低了误报率,提高了检测质量[45]。Cao等提出D2Det网络,同时实现了精确定位和分类,设计了一种密集局部回归网络,不限制固定区域的关键点集,用于预测目标提议的多个密集盒偏移,实现精确定位[46]。
3) 针对无人机视角下目标类别分布稀疏及不均匀带来的检测效率低的问题。Yang等将聚类思想引入目标检测,提出ClusDet网络,先由聚类网络CPNet生成目标簇区域,使用ScaleNet网络估计这些区域的目标比例,最后再将聚类区域送入DetecNet网络进行目标检测,减少了检测运算量,提升了检测效率[47]。Zhang等提出GDF-Net (Global Density Fused convolutional Network )网络,由FPN (Feature Pyramid Network)主干网络、全局密度模型(Global Density Model,GDM)和目标检测网络组成。GDM通过应用扩展卷积网络来细化密度特征,提供更大的感受野并生成全局密度融合特征[48]。Yu等 提 出DSHNet(Dual Sampler and Head detection Network)网络,包括类偏置采样器(Class-Biased Samplers,CBS)和 双 边 箱 头(Bilateral Box Heads,BBH),以双路方式处理尾类和头类目标,显著提高了尾类的检测性能[49]。
4) 针对无人机视角下目标的视角变化、光线变化、目标遮挡等带来的检测干扰问题。Zhang等设计了Cascade ResNet50网络,在ResNet网络加入可变形卷积层(Deformable Convolution Layer,DCN)进行特征提取,结合FPN组合不同尺度的特征,同时集成RPN以提取感兴趣区域,在VisDrone 2019数据集中达到了22.61的平均精度[50]。Yang等提出一种针对UAV视角的车辆检测体系结构,包括相邻连接模块(Adjacent Connection Module,ACM)、锚点细化模块(Anchor Refinement Module,ARM)和目标检测模块(Object Detection Module,ODM)。ACM提供了有效的上下文信息并减少干扰,ARM实现二分类和默认框粗略回归,ODM则细化选定的框以执行分类,能够准确实时地检测小型车辆[51]。Wu等采用对抗式学习框架,提出滋扰分离特征变换(Nuisance Disentangled Feature Transform,NDFT)框架,无需任何额外的领域适配或采样/标记,并与Faster-RCNN网络相结合,有效地降低了因无人机高度变化、天气变化、角度变化等对目标检测带来的影响[52]。Zhang等设计多尺度和遮挡感知网 络(Multi-Scale and Occlusion Aware Network,MSOA-Net),该网络包括多尺度特征自适应融合网络(Multi-Scale Feature Adaptive Fusion Network,MSFAF-Net)和基于区域注意力的三头网络(Regional Attention based Triple Head Network,RATH-Net)。MSFAF-Net从多个层次自适应地聚合层次特征图,以帮助FPN处理目标的比例变化;RATH-Net引导位置敏感子网络增强感兴趣的车辆,并抑制遮挡引起的背景干扰[53]。
5) 针对无人机平台上因尺度变化带来的目标漏检和误检问题。Chen等提出Ada Resampling增强策略,将图像输入预训练的语义分割网络,并与Hour Glass模块相结合,设计了RRNet网络,在VisDrone2019 Challenge中,达到AP50、AR10和AR100的 最 优 性 能[54]。Wang等以FPN网络为基础,提出空间优化模块(Spatial-Refinement Module,SRM)和感受野扩 展 模 块(Receptive Field Expansion Block,RFEB)来细化多尺度特征。RFEB增加高级语义特征的感受野大小,并将生成的特征通过SRM修复多尺度目标的空间细节,将模块与Cascade RCNN网络相结合,验证了有效性[55]。Tang等提出点估计网络(Points Estimated Network,PENet),使 用 掩 码 重 采 样 模 块(Mask Resampling Module,MRM)来增强不平衡数据集,使用粗检测器来有效预测目标簇的中心点,使用精细检测器来精确定位小目标[56]。Dike等对Faster RCNN框架进行改进,包括关键参数的校准、多尺度训练、使用线性单元卷积来挖掘空间-光谱特征[57]。Lin等在Cascade RCNN的基础上设计ECascade RCNN(Enhanced Cascade RCNN),提出Trident-FPN网络用来提取多尺度特征并进行特征融合,同时设计双头注意机制来提高检测器的性能,在处理UAV目标检测任务中的多尺度问题上取得较好效果[58]。Youssef等采用FPN生成多尺度特征表示,结合Cascade RCNN网络,产生了更稳健的区域建议,实现了在不同的空间分辨率下目标的检测和分类[59]。
6) 为了缓解由于特征提取与目标检测分开执行导致推理速度较低的问题。Lee等开发了同时执行目标检测和嵌入提取的单次激发方法,以EfficientDet-D0网络作为特征网络,使用BiFPN作为特征嵌入网络,在保持较高推理速度的同时,拥有较高的准确性[60]。
表2展示了基于双阶段的UAV视角下多目标检测主要方法对比。
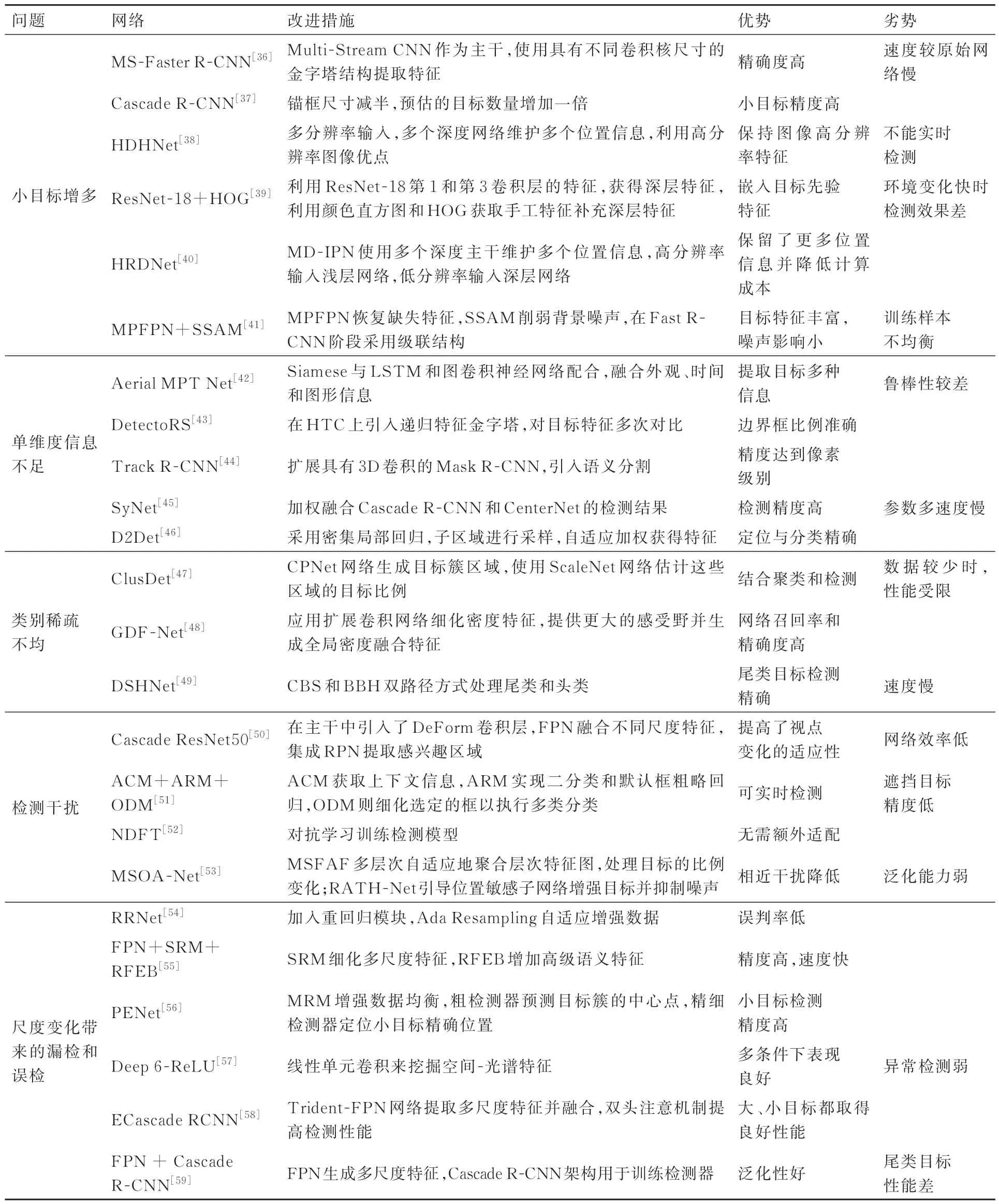
表2 基于双阶段的UAV视角下多目标检测主要算法对比Table 2 Comparison of main multi-object detection algorithms for UAV based on two-stage detection
2.2 单阶段无人机航拍视频多目标检测算法
在UAV视角下的多目标检测,单阶段检测器YOLO系列和SSD系列因优势明显得到了广泛的应用。Makarov等采用YOLO V2网络,实现了UAV视角下汽车、大型车辆、建筑物、飞机、直升机和船舶等6类物体的识别[61]。Hossain等将YOLO V3与SSD迁移到边缘端板载GPU Jetson TX2、Jetson Xavier上实现了UAV对地目标的检测,提供了精确的目标位置及类别信息[62]。Li等利用YOLO V3检测UAV视角中的车辆,通过光流法获取匹配特征点,精确计算单应矩阵[63]。Emiyah等使用YOLO V4实现了UAV视角下的人员与车辆检测[64]。Yang等以YOLO V3-608网络实现目标检测,并使用NMS算法过滤多个检测边界框得到最优检测结果[65]。
除了将原始的单阶段检测器直接应用到UAV视角下的多目标检测以外,还有不少学者针对UAV视角引入的各项问题,从网络模型优化、引入注意力机制、多尺度特征融合、多种网络综合等多个方面进行改进。
1) 针对UAV造成的小目标增多问题。Liu等使用Res Unit_2对YOLO中的ResNet单元和主干网络进行改进,连接Darknet的Resblock中具有相同宽度和高度的2个ResNet单元,提出UAV-YOLO网络,同时预测多个边界框和这些框的类概率,减少了因感受野受限导致的小目标漏检问题[66]。Ning等提出YOLO V5m-opt网络,通过将小目标检测分支的通道尺寸加倍,并减少大目标检测分支的一半通道来优化YOLO V5m网络,实现了精度与速度的平衡[67]。Kapania等联合YOLO V3和RetinaNet,利用RetinaNet网络在处理小目标拥挤情况下的优良性能,提升了UAV视角下的检测精度[68]。Tian等借鉴双阶段设计理念,提出一种DNOD方法,利用VGG网络提取UAV图像的特征图,和疑似区域的位置信息结合起来进行二次识别,降低了小目标的漏检率,分别与YOLO V4和EfficientDet-D7相结合,验证了算法的可靠性和有效性[69]。引入其他网络的方法能够对无人机航拍视频多目标检测的不同场景特点,选择不同的结构。但此类方法在处理包含多场景的任务时,迁移能力与泛化性较差。
2) 针对单维度信息包含特征不足问题。Zhang等在YOLO V3网络的3个检测头前的第5和第6卷积层之间,插入3个空间金字塔池化(Spatial Pyramid Pooling,SPP)模 块,设 计 出SlimYOLO V3-SPP3网络,丰 富深层特征[70]。刘芳等设计了TA-ResNet,添加卷积注意力模块的主干网络。提取了目标在多个维度上的注意力信息,精简了网络参数并有效融合了卷积核不同位置的注意力信息[71]。Saetchnikov等通过改进YOLO V4网络提出YOLO V4eff网络,使用4组Cross-stage-partial进行主干网络与颈部网络的连接,使用Swish函数作为激活函数,Letterbox 设为1以保持使用效率[72]。注意力机制通过不同的权重分配学习通道间的特征信息,加强特征的提取能力。但如何合理地使用注意力机制仍值得研究。
3) 针对无人机视角下目标类别分布稀疏及不均匀带来的检测效率低的问题。Li等提出DS YOLO V3,增加了连接到主干网络不同层的多个检测头来检测不同规模的目标,并设计了一个多尺度通道注意力融合模块,利用通道信息互补[73]。
4) 针对无人机视角下目标的视角变化、光线变化、目标遮挡等带来的检测干扰问题。Liang等在F-SSD的基础上添加反卷积模块的额外分支和平均池化来调整特征融合模块,反卷积模块为网络引入非线性,增强了网络的表示能力;平均池化抑制了因减少参数总数和背景信息带来的网络过拟合[74]。Wang等设计SPB(Strip Bottleneck Module)模块,可以更好地捕捉目标的宽度-高度依赖关系,达到特征增强的目的,并将其嵌入到YOLO V5网络,得到SPBYOLO网络,具有较好的检测多尺度目标的能力[75]。
5) 针对无人机平台上因尺度变化带来的目标漏检和误检问题。Liu等提出扩展卷积和注意力机制相结合的D-A-FS SSD。在特征提取主干网络中使用扩展卷积,增强了网络对目标分布的特征表达;将负责检测小目标的低级特征图与包含更多语义信息的高阶特征图相结合,提高了小目标的检测精度[76]。Zhang等在YOLO V3的基础上进行改进提出DAGN网络,通过注意力模块与特征连接相结合,以区分2个尺度上重要和不重要的特征。将一些标准卷积替换为深度可分离卷积,以抵消注意力模块带来的额外计算,并提出联合引导Gaussian NMS来提高密集区域的性能[77]。Jadhav等提出DAN网络,将RetinaNet每个阶段的最后一个残差块的特征通过SE(Squeeze and Excitation)模块传递,自适应地校准信道响应,然后将其送到特征金字塔网络,产生更好的检测结果[78]。Pi等利用FCOS模型在检测小目标方面的出色性能,并将多尺度特征融合技术应用于原始SSD,设计了F-SSD网络。分别从不同层的多个特征图中生成目标位置信息并识别目标类别,通过多尺度特征融合模块,融合了包含精细细节的浅层特征和具有语义信息的深层特征[79]。Liang等设计了特征对齐注意网络(Feature-aligned Attention Network,FAANet),以RepVGG网络作为主网络,融合空间注意力模块和特征对齐聚合模块,集成了多尺度特征[80]。Zhang等以RetinaNet50网络为基准,在FPN的P3和P4中添加一个CONV层,将高层特征添加到低层特征,实现了特征融合[81]。Wu等将YOLO V3网络的输入图像分辨率从224更改为320、416和608这3个可选比例,同时使用金字塔方法检测3个尺度的目标[82]。多尺度特征融合能够结合各多层级特征信息,最大限度地利用了多尺度输出,但在融合过程中常采用串联操作,并未客观地反映各层级之间的信息相关性,缺少信息交互。如何高效地进行特征融合仍是未来的研究方向。
6) 为了缓解由于计算量大导致推理速度较低的问题。Kyrkou等设计DroNet网络,以Tiny-YOLO网络为基准,减少了网络层数和每层滤波器的数量,以提升检测速度,并随着网络加深,逐渐增加滤波器的数量,以保持计算需求[83]。Balamuralidhar等提出MultiEYE 网络,将YOLO V4网络的主干网络替换为CSPDarkNet53(Lite),参数量降为原始的1/4,选用ENet做分割头,增加3组跳跃连接,在减少参数量的同时提取足够多的特征[84]。为了减少模型参数和计算成本,Li等提出ComNet,删除MobileNetv2中的平均池化层和最后一个卷积层,用改进的Mobile-Netv2替 换YOLO V3网络中的DarkNet53[85]。Zhang等在SSD网络之前加入PeleNet,以较少的层数降低了计算量,设定更宽的网络层补偿检测精度,并在最终预测层之前加入残差块,有助于主干网络获得更强的表示能力。残差块中使用1×1卷积核替代3×3卷积核减少了21.5%的计算成本,从而加快了模型的推理过程[86]。Wu等以YOLO V5为基准网络,与宽残差CNN网络相结合,只使用YOLO V5检测的目标斑块作为目标特征提取的输入,在提取到足够多的目标特征的同时,降低了参数量[87]。
表3展示了基于单阶段的UAV视角下多目标检测算法对比。
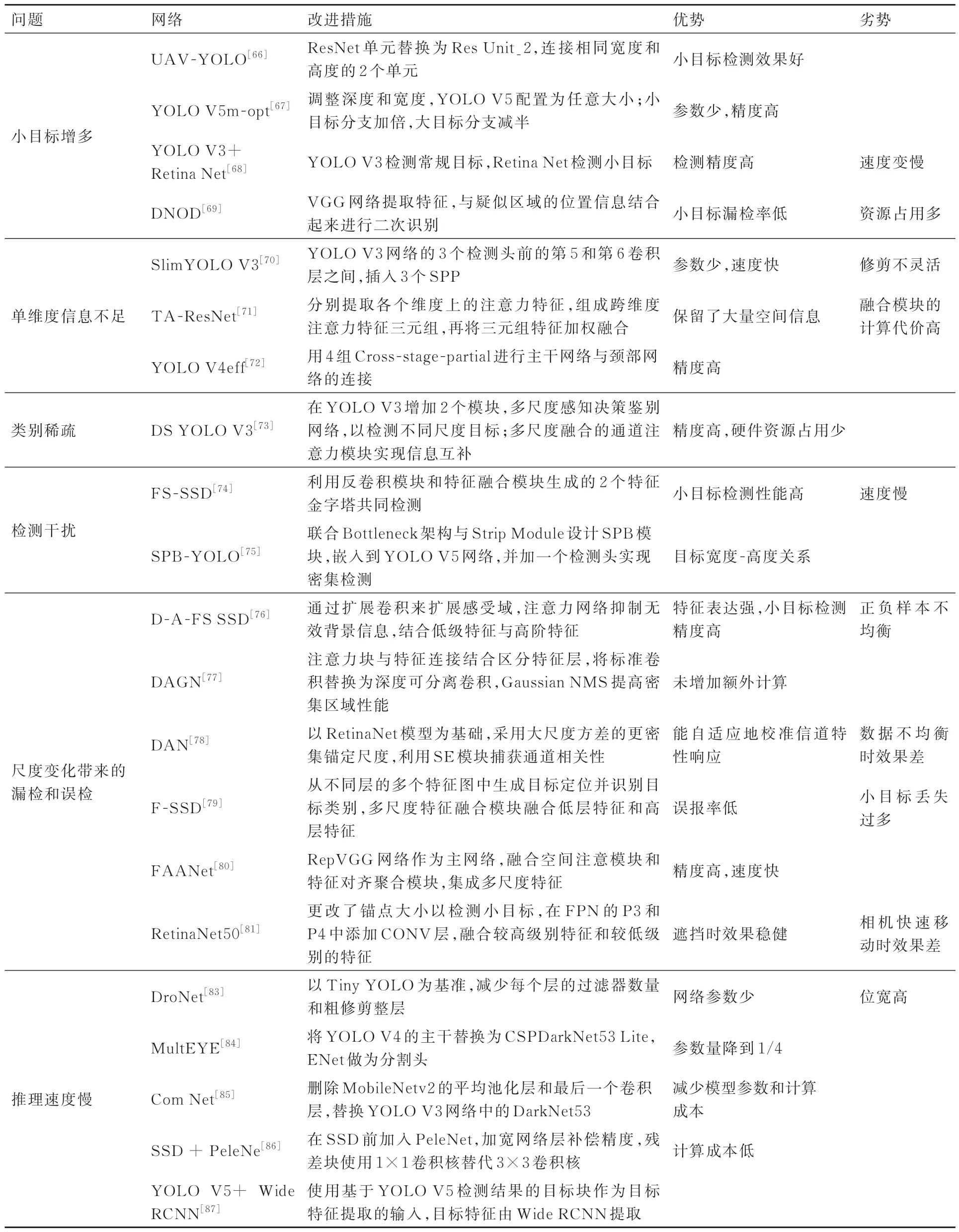
表3 基于单阶段的UAV视角下多目标检测算法对比Table 3 Comparison of main multi-object detection algorithms for UAV based on one-stage detection
2.3 多目标检测算法进展小结
回顾近年来UAV视角下基于深度学习的多目标检测算法进展,可以总结得到以下几点:
1) 双阶段目标检测算法发展迅速,检测精度也在不断提高,但是自身体系结构的问题限制了检测速度。单阶段目标检测算法没有候选区域推荐阶段,训练过程也相对简单,可以在一个阶段直接确定目标类别并得到位置检测框。
2) 针对UAV视角,进行的改进措施:① 修改网络结构,扩大感受野;②网络轻量化设计,减少参数量,提升检测速度;③ 引入注意力机制,加强特征提取;④ 多尺度特征融合,结合浅层与深层的特征信息。
3) 发展趋势:更多新的方法技巧,如注意力机制、无锚框策略、上下文关系等,开始应用于无人机航拍视频的多目标检测任务,但并未形成完整体系,主流方法仍然是以基于双阶段和基于单阶段的算法。在后续的研究中,双阶段目标检测算法一是要实现参数共享以提升运行速度,另一方面是提出新的训练策略使得算法走向端到端的演化。单阶段的多目标检测算法需构建具有更强表征能力的主干网络以提升算法的精度,以及解决目标检测过程中遇到的样本不均衡等问题。此外,2类网络都无法完全有效解决UAV视角带来的小目标问题,因此研究面向UAV视角的小目标检测的深度学习算法框架具有重要意义。
3 基于深度学习的无人机航拍视频多目标跟踪方法
多目标跟踪已成为近年来计算机视觉的研究热点,基于无人机航拍视频的多目标跟踪(Multi Object Tracking Based on UAV Aerial Video, MOT-UAV) 技术也得到迅速发展,目前,TBD已成为MOT-UAV任务最有效的框架。TBD的跟踪步骤通常由2个主要部分组成:① 运动模型和状态估计,用于预测后续帧中轨迹的边界框;② 将新的帧检测结果与当前轨迹相关联。处理关联任务的主要思想有2种:① 目标的外观模型和解决重新识别任务;② 目标定位,主要是预测轨迹边界框和检测边界框之间的交并比。这2种方法都将关联内容量化为距离,并将关联任务作为全局分配问题进行求解。本节分别对基于目标特征建模、基于目标轨迹预测、以及其他方法对无人机视角下的多目标跟踪的研究进展进行综述。
基于检测的MOT-UAV其基本流程如图4所示,TBD通过检测器获得目标检测结果后,将其进行关联,分配与前一帧检测目标相关数据的ID。该类型算法能够联合最新的高性能检测算法,跟踪部分则被视为数据关联问题,旨在提高关联过程的质量。
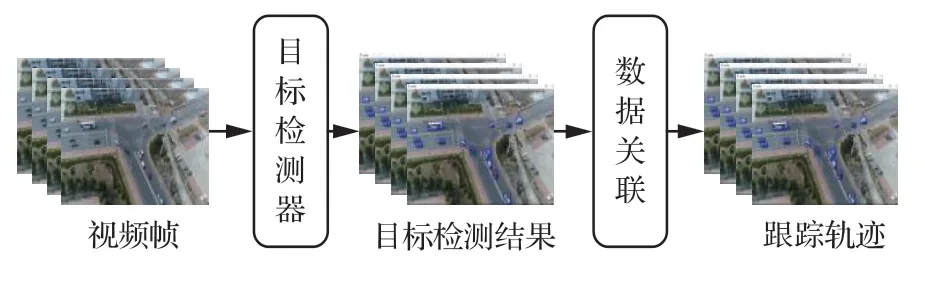
图4 基于检测的MOT-UAV框架Fig.4 MOT-UAV framework based on detection
3.1 基于目标特征建模的多目标跟踪
基于目标特征建模的多目标跟踪算法是在UAV视角下应用最广泛的TBD方法,通过提取目标的颜色、纹理、光流等特征,实现多目标跟踪。提取的这些特征必须是唯一的,以便在特征空间中区分目标。一旦提取出特征,即可利用相似性准则,在下一帧中找到最相似的目标。
1) 基于外观特征的目标建模
Al-Shakarji等提出SCTrack目标跟踪系统,使用三阶段数据关联方案,基于目标外观模型,结合空间距离以及显式遮挡处理单元。不仅依赖于被跟踪目标的运动模式,还取决于环境约束,在处理遮挡目标上取得较好效果[88]。Wang等设计了OSIM网络,通过VeRi数据集训练宽残差网络,提取目标外观特征。使用检测到的边界框马氏距离作为运动度量;计算边界框内的像素最小余弦距离作为外观相似性度量。将2个度量指标加权融合,使用级联匹配进行数据关联,实现了多目标的稳健跟踪[89]。Yu等为了解决外观和运动之间的融合比例常由主观设置的问题,提出融合外观相似性和运动一致性的自适应方法,在最新一帧中,计算目标与其周围目标之间的外观相似性,利用Social LSTM网络预测目标的运动,使用加权外观相似性和运动预测生成当前目标和前帧目标的关联[90]。Makarov等将Kuhn-Munkres算法用于建立帧间目标一对一的对应关系,算法中矩阵的元素是2个连续帧上目标边界框之间的欧氏距离,并比较目标的颜色直方图来处理目标在视野中消失和出现的情况。若直方图的Bhattacharya距离度量低于某个阈值,则判定此目标重新进入视野[61]。Dike等为了解决目标物体外观信息获取不稳定的问题,应用深度四元组网络(Deep Quadruplet Network,DQN)来跟踪从拥挤环境中捕获的目标轨迹。基于四元组损失函数来研究特征空间,使用具有6层连接的深度CNN来挖掘空间-光谱特征[57]。
2) 基于光流特征的目标建模
光流是图像中亮度模式的表观运动,光流算法计算亮度模式在相邻帧之间的位移,估计图像中特定像素的位移张力。一些研究人员基于光流进行目标建模。Ahn等将CNN和光流相结合,CNN进行特征提取和分类,同时计算像素的光流矢量,其与运动目标对应,使用KLT(Kanade Lucas-Tomasi)特征实现多目标跟踪[91]。Li等通过光流法获取匹配特征点,消除检测目标时带来的误差,精确计算单应矩阵,确定当前帧中的真实运动轨迹[63]。Lusk等使用KLT跟踪算法提取光流特征,生成目标的测量值;采用基于单应性的图像配准方法,将测量值映射到同一坐标系中,允许检测独立移动的物体;引入R-RANSAC算法使用视觉测量提取杂波中的目标[92]。Li等为了解决因摄像机运动导致的检测精度降低的问题,融合光流信息,设计了Flowtracker跟踪器。使用光流网络降低摄像机运动干扰,采用辅助跟踪器处理检测缺失的问题,同时融合外观和运动信息来提高匹配精度[93]。Yang等为了解决在目标位置变化过大的低帧速率情况下引起的跟踪丢失问题,提出基于密集轨迹投票的方法,将问题建模为密集光流轨迹到目标ID的投票问题,计算相邻帧中的密集光流,根据每个检测边界框中光流轨迹的结果测量相邻帧中目标之间的相似性,并通过数据关联获得跟踪结果[65]。Ardö将多目标跟踪问题模拟为网络流优化问题,引入广义图差(Generalized Graph Differences,GGD),从数据中有效地学习此类问题的权重,使用稀疏光流特征点生成KLT轨迹,将目标锚点与目标框连接起来,通过加入上述长连接将完整的跟踪分解为单个跟踪,解决了因遮挡导致的特征点跳跃问题[94]。
3) 基于多维特征的目标特征建模
除了将单独维度特征应用于多目标跟踪,同时应用外观特征、位置信息、时间信息等进行多目标跟踪也是一条技术途径。Fu等提出一种多车辆跟踪模型,使用改进的ResNet-18网络提取车辆的重识别特征,结合轨迹信息和位置信息构建相似矩阵,获得帧间车辆目标的最佳匹配[95]。Zhang等提出Tracklet Net多目标跟踪算法,利用时间和外观信息来跟踪地面目标。基于多视图立体技术估计的组平面来定位跟踪的地面目标,最大限度地减少跨帧间的光度误差,生成准确平滑的运动轨迹[81]。He等受注意力机制的启发,利用语境注意、维度注意和时空注意等多级视觉注意力,将上下文信息合并到滤波器训练阶段,同时感知目标和环境的外观变化,利用响应图的维度和时空注意力来增强特征,以更好地抑制噪声[96]。Stadler等设计了PAS跟踪器,考虑了目标的位置、外观和大小信息,计算所有检测结果和预测轨迹之间的相似性度量,并将其收集在成本矩阵中,用匈牙利方法求解分配问题[97]。
4) 相关滤波器
相关滤波源自信号处理领域,相关性用于表示2个信号的相似程度。通过对下一帧的图像与指定滤波模板做卷积操作,将响应最大的区域判定为预测的目标,实现多目标跟踪。其流程为:候选样本获取→特征提取→目标定位→模型更新。
Li等设计了一种基于时隙的跟踪算法,将跟踪过程划分为多个时隙。为了利用真实背景信息,采用背景感知相关滤波器(Backgroundaware Correlation Filter,BACF)扩大搜索区域,从背景中提取真实的负训练样本[98]。Li等以BACF作为基准滤波器,融合上下文学习策略,提出基于相关滤波器的Keyfilter感知跟踪器,利用上下文信息赋予滤波器更强的识别能力,有效地缓解了背景杂波、描述不足、遮挡、光照变化等问题。从周期性关键帧中生成Keyfilter,抑制了当前滤波器的损坏变化,充分提高了跟踪效率[99]。Balamuralidhar等使用相关滤波器以较高的计算速度和精度估计被跟踪目标的位置,将最小输出平方误差和(Minimum Output Sum of Squared Error,MOSSE)算法用于目标跟踪[84]。使用前2帧进行初始化,检测边界框裁剪自序列的第1帧,使用自然对数变换和离散傅里叶变换对其实现对比度的增强并转至频域表示,此后生成一个合成目标用于初始化跟踪器并在跟踪过程中更新滤波器[70]。
基于目标特征建模的多目标跟踪算法在无人机航拍视频上取得了稳健的跟踪,但在处理长时跟踪、消失又重现的特殊目标时仍存在问题。
表4展示了基于目标特征建模的UAV视角下多目标跟踪主要算法对比。

表4 基于目标特征建模的UAV视角下多目标跟踪主要算法对比Table 4 Comparison of main algorithms for multi-object tracking for UAV based on target feature modeling
3.2 基于目标轨迹预测的多目标跟踪
基于目标轨迹预测的方法将跟踪描述为估计问题,通过目标的位置状态向量描述目标的动态行为。其一般框架取自贝叶斯滤波器,包含预测和更新2步。预测步骤使用状态模型估计目标在下一帧中的位置,而更新步骤基于观测模型由当前观测值更新目标的位置。常用的基于目标轨迹的方法主要有卡尔曼滤波与DeepSORT框架。
1) 基于卡尔曼滤波的目标轨迹预测
卡尔曼滤波是递归贝叶斯估计在误差为高斯分布时的一种特例,通过卡尔曼滤波(Kalman Filter,KF)预测下一帧中的目标轨迹边界框,再将其与检测边界框相关联实现跟踪。Baykara等采用Squeeze Net网络检测目标,使用卡尔曼滤波进行目标跟踪,实现了UAV视角下多目标的跟踪与分类[34]。Xu等在概率数据关联的基础上联合卡尔曼滤波,提出JPDA(Joint Probabilistic Data Association)方案。估计每个目标所有可能的匹配情况,基于联合概率数据关联似然方法,将更新后的状态作为下一帧的前一个目标状态,但未建模运动可能导致目标虚假跟踪[100]。Lee等将移动目标的质心作为跟踪的输入,采用卡尔曼滤波估计目标的动态状态[101]。王旭辰等使用 Car-Reid数据集训练残差网络提取目标外观信息,使用卡尔曼滤波提取目标运动信息,2种信息经整合得到成本矩阵,最后由匈牙利匹配算法得到跟踪结果[102]。Luo等将YOLO V5用于特征提取,卡尔曼滤波器提取目标运动信息并更新预测,利用匈牙利匹配算法得到跟踪结果[103]。
除了将卡尔曼滤波直接应用到目标轨迹预测之外,也有不少学者对其进行了改进或融合其他方法。Wu等为了解决因UAV导致的目标偏移,基于卡尔曼滤波和单应性变换(Kalman Filter and Homography Transformation,KFHT) 设计了运动补偿模型,预测目标位置并补偿位置偏移。利用目标的特征相似性和位置关联匹配完成目标识别,减少了目标ID交换的数量[87]。Khalkhali等提出SAIKF(Situation Assessment Interactive Kalman Filter),利用从同一环境的交通历史中提取的态势评估信息,来提高跟踪性能[104]。
2) 基于DeepSORT的目标轨迹预测
以卡尔曼滤波为基础的DeepSORT框架是现阶段在UAV视角下多目标跟踪中应用最多的框架,其假设目标运动为匀速状态,如图5所示[105]。Kapania等在MARS数据集上预训练CNN模型生成深度关联矩阵,结合外观特征和运动信息,通过减少ID交换的数量,提高轨迹准确性,在DeepSort框 架 中 实 现 多 目 标 跟 踪[68]。Emiyah等使用YOLO V4进行目标检测,在DeepSORT框架下实现了UAV视角下的目标跟踪[64]。Ning等采用YOLO V5获得目标实时位置,联合DeepSORT框架实现了目标的速度测量[67]。Jadhav等设计深度关联网络,根据深度特征相似性对目标评分,同时跟踪相似类的多个目标,将检测器提供的置信度与深度关联度量融合,传递到DeepSORT网络中,生成目标轨迹,提升了对目标置信度较高但深度关联较低的目标的跟踪准确率[78]。Avola等利用从边界框得到的视觉外观,结合Deep SORT描述UAV航拍视频序列中的目标轨迹[36]。
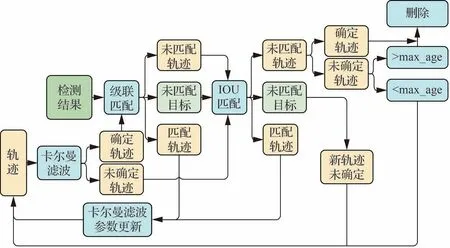
图5 DeepSORT框架[105]Fig.5 DeepSORT framework[105]
除了将DeepSORT直接应用于UAVMOT,众多学者针对UAV视角下多目标跟踪出现的问题做出了各种相应改进。Huang等通过不同的预测网络生成目标边界框,对所有轨迹和检测结果进行级联匹配,通过GIOU匹配进行未匹配跟踪和检测,生成最终轨迹[38]。Du等以Deep-SORT为基础框架,采用全局信息和一些优化策略,设计了GIAO Tracker。用OSNet替换Deep-SORT中的简单特征提取器,利用全局线索将其关联到轨迹中,并提出EMA(Exponential Moving Average)策略,实现小轨迹和检测结果之间更精确的关联[43]。Wu等针对DeepSORT预训练的外观提取模型未包含车辆外观信息的问题,利用轻型ShuffleNet V2网络对VeRi数据进行车辆重识别训练,提取外观信息,加入到DeepSORT中[106]。Wu等将YOLO V4 Tiny与DeepSORT网络相结合,设计了SORT-YM网络,利用目标在被遮挡前的信息,通过多帧信息来预测目标的位置,一定程度上解决了目标遮挡的问题[107]。
表5展示了基于目标轨迹预测的UAV视角下多目标跟踪主要算法对比。
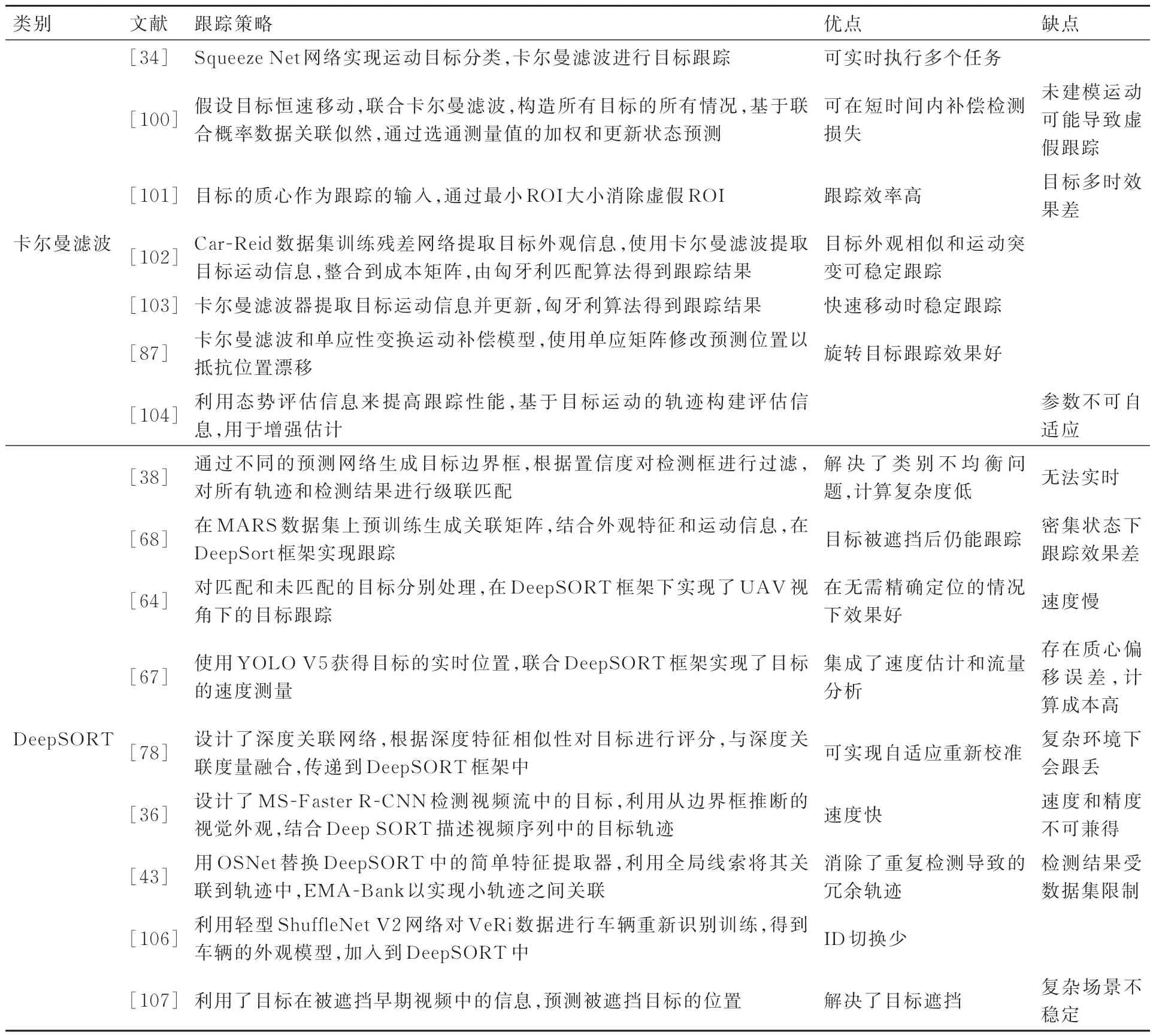
表5 基于目标轨迹预测的UAV视角下多目标跟踪算法对比Table 5 Comparison of multi-object tracking algorithms for UAV based on target trajectory prediction
3.3 其他基于深度学习的多目标跟踪
除了上述基于目标特征与轨迹预测的多目标跟踪算法以外,基于单目标跟踪辅助、记忆网络增强、交并比(Intersection over Union,IOU)、联合检测与跟踪等方法也被应用于无人机航拍视频的多目标跟踪。
1) 基于单目标跟踪辅助的UAV-MOT
基于单目标跟踪辅助的算法分别对单个目标实行完整的跟踪策略,相对于检测类算法,SOT使用的跟踪器包含了当前目标外观特征和位置等时序更新的信息,已成功应用于多种场景。Chen等提出四阶段级联框架用于UAV航拍视角下的多目标跟踪,将基于数据关联与使用压缩的多目标跟踪算法相结合。在每个关联阶段,将不同的轨迹集合和检测结果关联起来,同时单目标跟踪与假设匹配结合后,用于目标重识别,在处理小目标跟踪、目标遮挡时取得较好效果[108]。Yu等将目标和UAV运动分别视为个体运动和全局运动。利用Social LSTM网络来估计个体运动,构建连体网络来生成全局运动,利用Siamese网络提取相邻帧的视图变化进行全局运动分析,个体运动与全局运动信息输入生成对抗网络,获得了稳健的MOT性能[109]。Pan等结合SOT和卡尔曼滤波提出HMTT (Hierarchical Multi Target Tracker)方法,使用具有学习全尺度特征能力的OSNet网络提取ReID特征以表示边界框,计算每对边界框与两条轨迹的欧氏特征距离。尽管缓解了遮挡问题,但在目标长期消失的情况下跟踪效果差[110]。Bahmanyar等提出基于卷积神经网络的方法SMSOT-CNN来跟踪UAV航拍视频中的多个车辆和行人,利用Micro CNNs负责单个目标跟踪任务,使用双流CNN从每个目标的连续帧中提取特征,预测目标在当前帧中的位置[111]。
2) 基于记忆网络增强的UAV-MOT
MOT可以通过历史轨迹信息判断新的目标状态。因此,可以设计一个能够记忆历史信息的网络结构,并基于该历史信息学习匹配相似性度量,从而提高MOT的性能。在所有RNN中,LSTM网络在处理序列问题上表现出了可靠的性能。LSTM的特殊结构使其能够长时间保留信息,并且可以克服传统RNN的梯度消失和爆炸问题。Azimi等设计AerialMPTNet网络,使用LSTM获取时间信息,通过信道自适应加权,采用GSD自适应欧氏距离进行连续帧中的目标关联[42]。Saetchnikov等为了能够同时保留目标的特征信息和轨迹的长时信息,设计了双向LSTM,分别用于前向序列和后向序列,能够更好地理解视频序列。将LSTM中的完全连接层替换为卷积层,解决了标准LSTM网络通过全连接层进行矢量化和编码造成的空间信息丢失的问题[72]。
3) 基于IOU的TBD的方法
除了上述2类基于检测的UAV-MOT方法,也有应用IOU扩展的方法。Marvasti-Zadeh等为了解决小目标的问题,引入一种上下文感知IOU引导跟踪器,利用多任务双流网络和离线参考建议生成策略,网络仅从ResNet-50的block3和block4中提取特征,以利用空间和语义特征,同时减少了参数数量,通过多尺度特征学习和注意力模块充分利用目标相关信息[112]。Youssef等使用匈牙利算法生成最优轨迹,替代原始使用的贪婪方法进行轨迹分配,并使用特定阈值筛选假阳性轨迹,但没有利用到目标检测器提取的丰富图像特征,在最终的跟踪效果上有一点劣势[59]。
4) 基于联合检测与跟踪的UAV-MOT
JDT框架以及计算机硬件发展迅速,其受到了UAV视角下多目标跟踪研究者的重视,并得到了推广应用。Zhang等将目标跟踪中关注的特定实例替换为同类目标,设计了BES(Boundingbox Estimation State)网络,含2个子网络:实例感知注意力网络用于对给定目标基于实例的先验知识进行建模,实例感知IOU网络则根据不同提议估计IOU分数。跟踪过程中通过梯度上升使得分值最大化来获得最终的限定框[39]。Lee等以FairMOT网络为基础设计了能够同时执行目标检测和特征提取的Single-Shot MOT网络,提高了推理速度,以EfficientNet作为主干生成3个多尺度特征图,特征通过双向特征金字塔网络进行特征融合,完成目标的匹配[60]。Liang等设计了特征对齐注意网络(Feature Aligned Attention Network,FAANet),以RepVGG网络为主网络,融合空间注意模块和特征对齐聚合模块,集成了多尺度特征,同时采用JDT框架和结构重参数化技术提升了实时性[80]。
表6展示了其他UAV视角下多目标跟踪算法对比。
表6 其他UAV视角下多目标跟踪算法对比Table 6 Comparison of other multi-object tracking algorithms for UAV
3.4 多目标跟踪算法进展小结
回顾近年来UAV视角下基于深度学习的多目标跟踪进展,经分析总结得到以下几点:
1) TBD框架的优点:检测器与特征提取应用深度学习对多目标跟踪效果提升明显。基于深度学习的特征提取器提取到了更加精确的外观特征,在处理目标遮挡、目标重现、背景干扰等问题上表现良好,获得了稳定的多目标跟踪性能。
2) TBD框架的缺点:运行效率低。TBD模式不能同时执行目标检测和特征提取,导致基于TBD模式的多目标跟踪算法难以实现精度和速度的均衡。
3) TBD框架的改进方法:① 进一步发挥深度特征的优势,将更有效的特征与TBD框架相结合;② 融合多种特征,提取更多的有效信息,包括外观、时间、图形等特征;③ 与LSTM相结合,借助其能够长时间保留信息的能力。
4) UAV视角下基于深度学习的多目标跟踪发展趋势:近年来的主流框架仍然为TBD框架。JDT框架、循环神经网络、动态记忆网络等更多新的网络结构和注意力机制、无锚点策略、上下文关系等方法技巧,开始应用于UAV视角下多目标跟踪任务。此外,无论是早期的算法还是后来的网络,都无法有效应对长时间多目标跟踪任务, 因此面向长时间多目标跟踪的深度学习算法框架将对多目标跟踪领域具有重要意义。
4 数据集与结果评估
4.1 数据集
随着基于数据驱动的深度学习方法的发展,研究人员为数据集的构建做出了巨大贡献,促进了相关课题的算法验证与性能对比。
Stanford Drone 数据集[113]:Stanford大学于2016年公布的大规模目标跟踪数据集,使用无人机在校园拥挤的时间段以俯视的方式收集了8个不同的场景下20 000个物体的轨迹交互信息,每个物体的轨迹都标注唯一的 ID,包含10种目标类型,19 000多个对象,包括112 000名行人、64 000辆自行车、13 000辆汽车、33 000名滑板手、22 000辆高尔夫球车和11 000辆公共汽车,均可用于多目标检测与跟踪。数据集重点关注了目标与目标之间、目标与环境之间的交互信息。当2个目标有交集时,目标的轨迹将发生变化,标注了185 000个目标之间的交互信息。当目标在其周围没有其他目标的情况下轨迹偏离线性轨迹时,目标会与空间发生交互作用,标注了大约40 000个目标与环境的交互。
UAVDT (UAV Detection and Tracking)数据集[114]:中国科学院大学于2018年设计的大型车辆检测和跟踪数据集,包含100段视频和80 000个视频帧,大约2 700辆车和84万个边界框,图像分辨率为1 080×540,包括广场、主干道、收费站、高速公路、路口等场景,可用于车辆目标检测、单车跟踪、多车跟踪等任务。针对MOT数据集涵盖了各种天气条件(白天、夜晚和雾)、目标遮挡和距地高度。特别的,在日光下拍摄的视频会引入阴影的干扰,夜景下几乎没有任何纹理信息,在雾中拍摄的帧缺少清晰的细节,因此目标的轮廓在背景中消失。在高海拔视角下,大量的目标则不太清晰。针对多目标检测还标记了另外3个属性,包括车辆类别、车辆遮挡率和截断率。遮挡率表示目标被遮挡部分的占比,截断率表示目标出现在帧外部分的占比。车辆类别包括轿车、卡车和公共汽车;车辆遮挡率分为无遮挡(0%)、小遮挡(1%~30%)、中等遮挡(30%~70%)和大遮挡(70%~100%)4档;车辆在视野边缘的截断率分为无截断(0%)、小截断(1%~30%)和中等截断(30%~50%)3档,当视野外占比>50%时,目标将被丢弃。
VisDrone2018数据集[115]: 天津大学、GE全球研究院和天普大学于2018提出的大型视觉目标检测和跟踪数据集,包含263段视频,共计179 264个视频帧和10 209个静态图像,标注有超过250万个目标信息,涵盖行人、汽车、自行车和三轮车等多个目标。图像分辨达到了3 840×2 166,能够应用于目标检测、单目标跟踪和多目标跟踪等任务。删除了目标较少区域的标注
VisDrone 2019数 据 集[116]:与VisDrone2018相比,VisDrone 2019增加了25段长跟踪视频,共82 644帧,12个视频采集与白天,其余在晚上采集,提升了数据集小目标数量和背景干扰。Vis-Drone2019共计包含了288段视频,共计261 908个代表帧和10 209个静态图像。数据集还提供了遮挡率和截断率,如果目标的截断率>50%,则在评估期间跳过该目标。
BIRDSAI数据集[117]:哈佛大学于2020年使用TIR摄像头在多个非洲保护区采集的数据集,包含48段TIR视频和124段由AirSim-W生成的合成航空TIR视频,分辨率为640×480。该数据集包含具有尺度变化、背景杂波、角度旋转和运动模糊等变化,目标类别包括人和动物(狮子、大象、鳄鱼、河马、斑马和犀牛)。如果图像中存在伪影,则将对象标记为包含噪声。若目标完全无法区分(例如,多个人类或动物靠近在一起,在热成像中无法区分),则不标记它们。同时,目标超过50%的部分不在帧中,则不会对其进行标记。
CARPK(Car Parking Lot Dataset)数 据集[118]:台湾大学于2017年提出的大规模车辆检测和计数数据集,是无人机视角的第1个停车场数据集,覆盖了4个不同停车场的近90 000辆汽车。单帧图像中的最大车辆尺寸≫64×64,单个场景中的最大车辆数为188,所有标记的边界框都采用左上角点和右下角点进行标注。只要确定目标是1辆车,包括位于图像边缘的汽车,均对其进行标注。
DAC-SDC(Design Automation Conference-System Design Contest)数 据 集[119]:University of Notre Dame于2018年提出的目标检测数据集,它包含95个类别和150 000个不同视角拍摄的图像,分辨率640×360,大多数目标大小占比图像的1%~2%。在该数据集中,图像亮度和信息量仍然保持良好的平衡,大多数图像具有中等亮度/信息量,小部分图像包含太大或太小的亮度/信息,类似于高斯分布。
MOR-UAV(Moving Object Recognition in UAV Videos)数 据 集[120]:Malaviya National Institute of Technology Jaipur于2020年提出的用于运动目标检测的大型视频数据集,包含30段视频,10 948个代表帧,标注了约89 783个运动目标,分辨率从1 280×720到1 920×1 080不等。收集场景包括大量车辆出现的立交桥、停车场和交通信号交叉口的目标稠密地区以及森林、农业和其他背景复杂的目标稀少地区。数据集涵盖了各种场景,包括遮挡、夜间、天气变化、相机运动、变化的高度、不同的相机视图和角度等各种具有挑战性的场景,可用于多目标检测与跟踪任务。目标最小标注框为6×6,最大为181×106。
Drone Vehicle数据集[121]:天津大学于2020年提出的目标检测和计数数据集,由配备摄像头的无人机捕获RGB和热红外图像,包含15 532对图像,涵盖照明、遮挡和比例变化,分辨率为840×712,拍摄范围包括城市道路、住宅区、停车场、高速公路等。
AU-AIR (A Multi-modal Unmanned Aerial Vehicle)数据集[122]:Aarhus University于2020年通过多模式传感器(即视觉、时间、位置、高度、IMU、速度)进行采集到的数据集,包含8段视频,共计32 823个提取帧,分辨率1 920×1 080。数据集8种目标类型,包括人、汽车、公共汽车、面包车、卡车、自行车、摩托车和拖车,均可用于静态或视频目标检测。数据集涵盖了一天中所有时间段和天气条件(阳光充足、部分阳光充足、多云)导致的各种照明条件。飞行高度在10、20和30 m之间变化,相机角度从45°调整到90°(垂直于地球)。同时在注释时将边界框重叠超过75%的目标进行合并。
MOHR (Multi-Scale Object Detection in High Resolution UAV Images)数 据 集[123]:该数据集在郊区、山区、雪地和沙漠地区采集。包括3 048幅分辨率为5 482×3 078的图像、5 192幅分辨率为7 360×4 912的图像和2 390幅分辨率为8 688×5 792的图像。标注了90 014个带有标签和边界框的目标,其中包括25 575辆汽车、12 957辆卡车、41 468栋建筑、7 718处洪水破坏和2 296处坍塌,包含了目标的尺度变化。建筑类别注释侧重于临时建筑,这些建筑可能是未经批准的建筑项目,通常有颜色鲜艳、高度较低的铁屋顶。洪水破坏的阴影总是小于崩塌图像中的。数据集将覆盖0.05%或更少像素的目标定义为微小目标,低于0.5%的目标定义为小目标。数据集中97.08%的汽车、77.10%的卡车、31.21%的建筑、86.93%的坍塌和62.37%的洪水破坏为小目标。
UVSD (UAV based Vehicle Segmentation Dataset)数据集[53]:基于UAV的车辆分割数据集,该数据集包括5 874幅图像,具有多个格式注释,其中98 600个目标实例具有高质量的实例级语义注释。图像分辨率从960×540到5 280×2 970像素不等。目标包含视点变化、大规模变化、局部遮挡、密集分布、照明变化等特点。数据集除了常规的像素级实例注释和水平方向边界框的注释格式外,还增加了OBB(Orientated Bounding Box)格式的标注,其边界框为相对于坐标轴方向任意的最小的长方形,方向具有任意性,可以根据被包围目标的形状特点尽可能紧密地包围目标。若车辆目标的截断率超过80%,则无需对该车辆进行标记和测试。
表7列举了面向UAV视角的多目标检测与跟踪的主流数据集。部分数据集样例如图6所示,MTD代表多目标检测任务,MOT代表多目标跟踪任务。
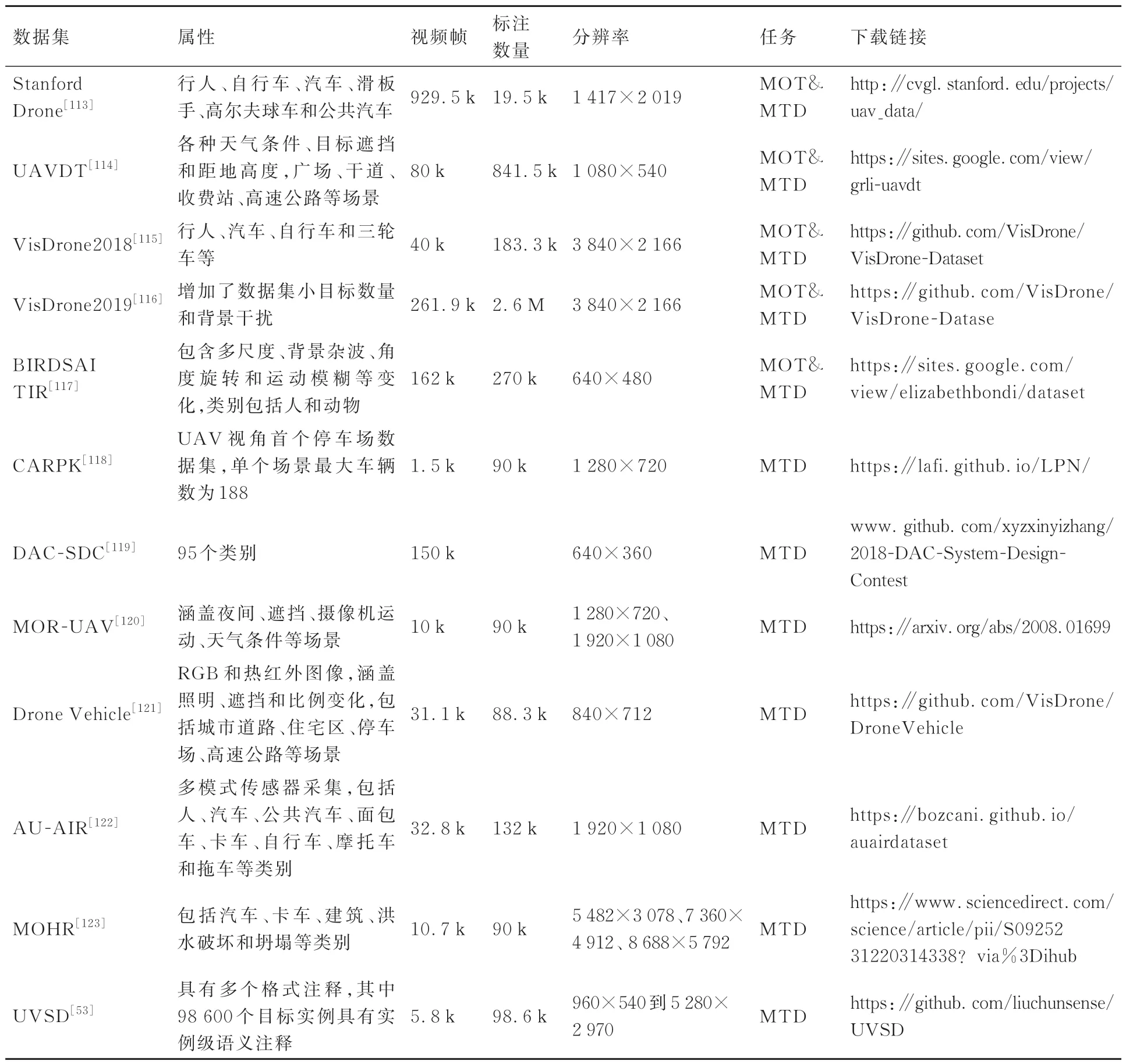
表7 面向UAV视角的多目标检测与跟踪的主流数据集Table 7 Main data set of multi object detection and tracking for UAV

图6 常用数据集示例Fig.6 Example of common datasets
4.2 评价指标
混淆矩阵是深度学习模型问题的评价基础,可更全面地评价预测结果,统计正确和不正确预测的数量,并按照类别进行细分。混淆矩阵在进行预测结果判定时不仅能展示模型的缺点,还能了解发生错误的类型,降低仅使用分类准确率所带来的制约。混淆矩阵如图7所示。
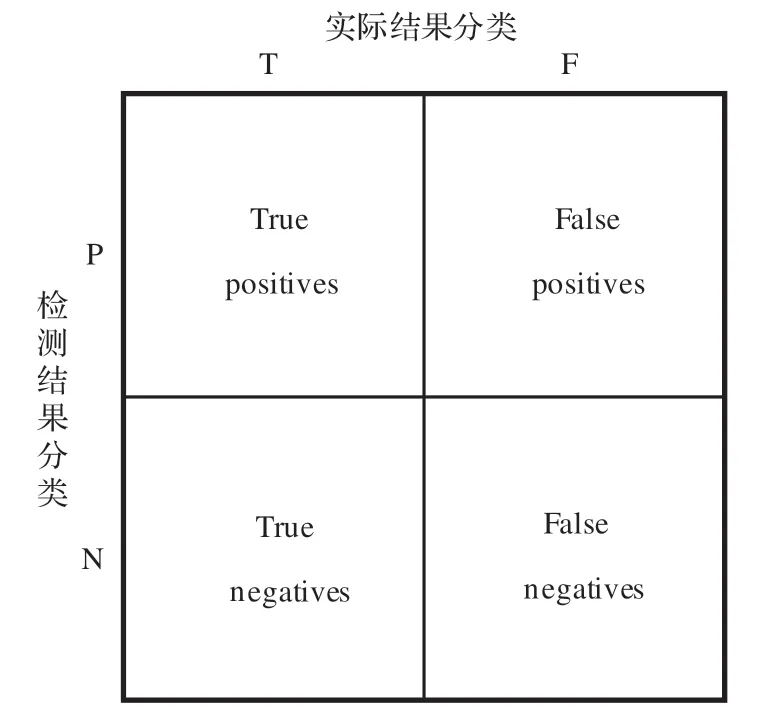
图7 混淆矩阵Fig.7 Confusion matrix
TP:检测值与真实值相同,均为正样本;TN:检测值与真实值相同,均为负样本;FP:检测值与真实值不同,检测值为正样本;FN:检测值与真实值不同,检测值为负样本。在混淆矩阵的基础上,针对多目标检测与多目标跟踪的具体问题,衍生出了多种更高级的评价指标。
4.2.1 多目标检测评价指标
评价多目标检测算法的优劣时,主要遵循2个原则,一是能否正确地预测框内目标的类别,二是预测的框和人工标注框的重叠比例。在此基础上设计的评价指标如表8所示,所有指标均是值越大,效果越好。

表8 多目标检测评价指标Table 8 Multi object detection evaluation index
4.2.2 多目标跟踪指标
多目标跟踪的主要目的是在所有视频帧中找到正确数量的目标,并尽可能精确地估计每个目标的位置,还应该随着时间的推移保持对每个目标的一致跟踪:应该为每个目标分配一个唯一的跟踪ID,该ID在整个序列中保持不变。因此多目标跟踪的评价指标主要遵循以下设计标准:
1) 判断跟踪器在确定精确目标位置时的精度。
2) 反映出其随时间一致跟踪目标配置的能力,即正确跟踪目标轨迹,每个目标只产生一条轨迹。
针对此标准,Bernardin等提出MOTP、MOTA指标[124]。为了判断跟踪器是否能够长时间地对某个目标进行准确地跟踪,Ristani等引入IDF1、IDP和IDR指标,以衡量跟踪器的ID维持能力[125]。Luiten等基于Jaccard相似系数设计了HOTA,将精确检测、关联和定位的效果综合到统一的度量中,同时分解为一系列子度量,能够单独评估多种基本错误类型[126]。多目标跟踪评价指标对比如表9所示,带有“↑”的指标表示数值越大效果越好,带有“↓”的指标表示数值越小效果越好。

表9 多目标跟踪评价指标Table 9 Multi object tracking evaluation indicators
4.3 VisDrone Challenge挑战赛
VisDrone Challenge挑战赛由计算机视觉会议ICCV(International Conference on Computer Vision)与ECCV(European Conference on Computer Vision)举办,数据集由天津大学机器学习与数据挖掘实验室的AISKYEYE团队收集,设置了针对无人机视角下的目标检测与跟踪的多条赛道,VisDrone数据集也成为无人机领域标杆数据集,业界多篇论文也采用此数据集进行实验验证与性能对比。VisDrone挑战赛侧重于不同特点的无人机目标检测与跟踪问题。包括:① 基于图像的目标检测,旨在从无人机拍摄的单幅图像中检测预定类别的目标;② 基于视频的目标检测,该任务与基于图像的目标检测类似,但需从视频中检测目标;③ 单目标跟踪,估计单个目标在后续视频帧中的状态;④ 多目标跟踪,旨在恢复每个视频帧中目标的轨迹。表10和表11分别展示了VisDrone挑战赛2018―2021年多目标检测与多目标跟踪赛道排名前5的算法与评估结果。
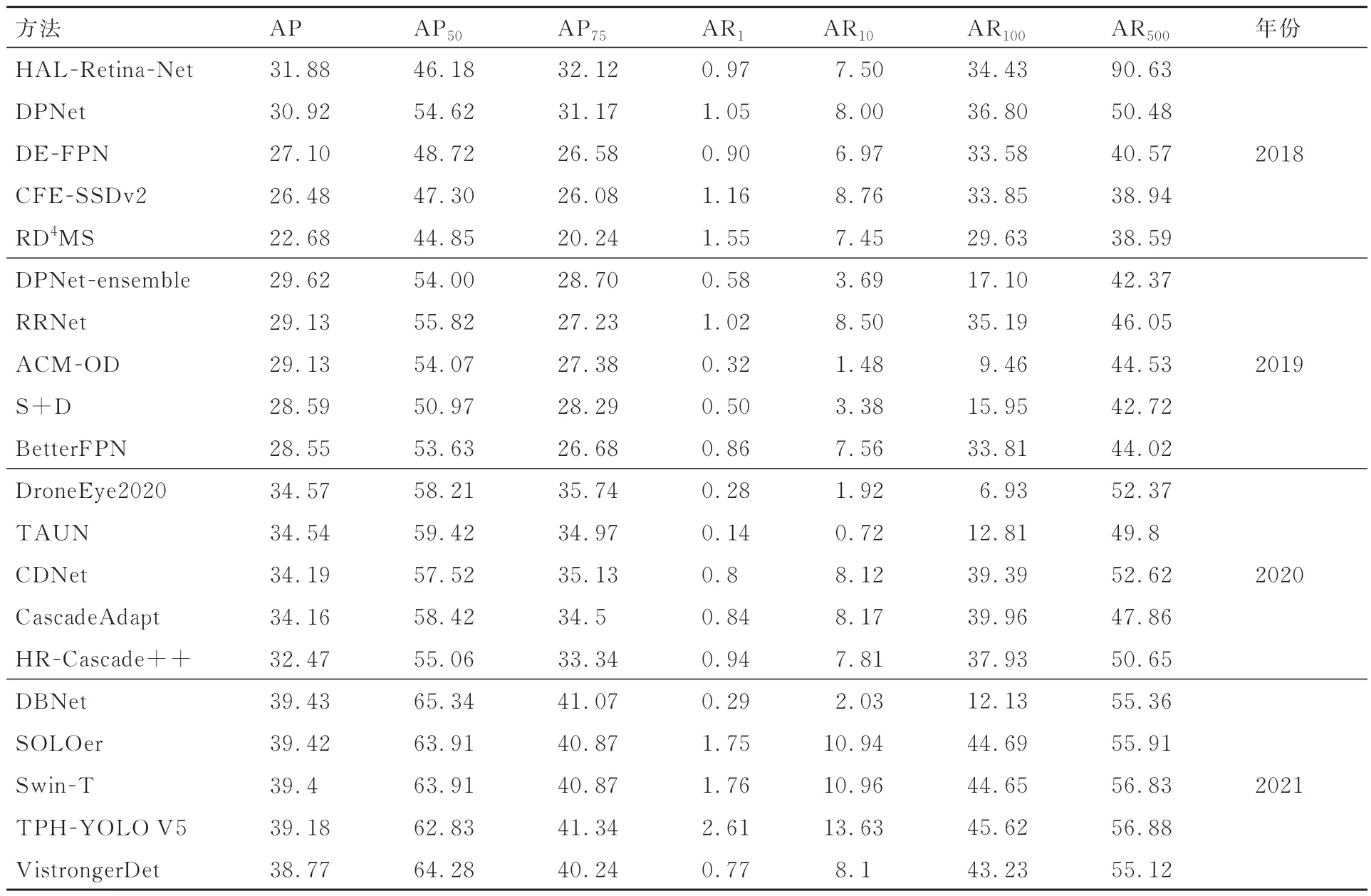
表10 VisDrone挑战赛多目标检测竞赛结果评估Table 10 Evaluation of multi object detection competition results of VisDrone Challenge
多目标检测竞赛结果表明,多个网络的组合可有效提高目标检测的准确性。Cascade RCNN和YOLO V5分别成为双阶段和单阶段的最优检测框架。在此基础上采用了一些有效的策略来获得更好的精确度,如注意机制、双头网络、分层设计等。精确度最高的检测网络基于Cascade R-CNN实现,通过级联细化框获得更好的定位性能。此外,将卷积替换成Transformer的TPH-YOLO V5与Swin-T网络也取得了不错的成绩。但mAP的最佳分数仍低于40%,在实际应用中要取得优异的性能还任重道远。此外,由于无人机平台上的资源有限,需进一步考虑网络的计算复杂度。
多目标跟踪竞赛提交的结果显示,成绩最好的跟踪框架都是以TBD框架,并对特征处理进行了一些修改。成绩最优的目标检测器都是基于双阶段检测器Cascade R-CNN的检测结果。为了适应具有众多小目标的VisDrone数据,不仅利用了目标的外观特征表示,还利用了单个目标跟踪器或其他低级运动模式的时间一致性信息。因此,基于相似性计算的重识别结果对于开发高性能MOT算法至关重要。同时由于TBD框架的性能在很大程度上受检测器的影响,构建一个性能优异的检测器非常重要。
5 面临的问题与挑战
近年来,随着深度学习及计算机硬件的发展,基于无人机航拍视频的多目标检测与跟踪取得了长足进步,但仍面临着多种挑战:
1) 原始视频中的噪声干扰。UAV视角下的视频容易因目标交互、UAV移动、环境变化等原因引入大量噪声,视频中的噪声可能会严重影响目标检测过程或MOT以及视频处理的其他阶段。
2) 目标形状及运动复杂。由于形状和位置的不同,目标可能会根据其在现实世界中的规则进行不同的运动或呈现多种姿态。例如,行人可以走、跑、站或坐。同时UAV的高度变化,易造成相同的目标在视觉画面中尺度的变化,对目标的检测与跟踪造成干扰。
3) 光照阴影。当目标受到来自照明源的直射光的阻碍时,阴影会出现,阴影也可能会由于交互或其他目标而产生,提升了目标的识别难度。
4) 光照强度与视点变化。在像素级别上,亮度的变化会对目标的识别造成干扰,目标在各种光照条件下显示各种颜色,将会导致检测错误并降低模型的性能。此外,从不同视点看到的目标可能看起来完全不同。
5) 目标遮挡。在复杂场景和拥挤的环境中,单个目标有可能会被完全遮挡,或者被背景的一部分遮挡,对目标的检测与跟踪造成干扰,尤其是在长时跟踪过程中,目标有可能重新进入视野,对模型的长时跟踪带来更大挑战。
6) 网络复杂度高,实时性差。在UAV平台上为了满足视频处理的实时性需求,多目标检测和跟踪算法需要有较高的处理速度,对网络的参数量和计算复杂度有了更加严苛的要求。
7) 数据集受限。当前可用于UAV视角的多目标检测与跟踪的带注释数据集较少,成为限制网络性能的一大瓶颈。
6 总结与展望
本文通过总结及对比分析,梳理了近年来UAV视角下多目标检测与跟踪领域的研究成果,梳理了近年来在多目标检测与跟踪领域的主要技术路线及最新方法,对比了各类方法在UAV视角下的应用优势及缺点,并介绍了该领域的数据集及评估方法。通过以上总结和分析,对后续的发展趋势和进一步研究方向进行展望,期望可以提供有价值的参考。
目前面向UAV视角的多目标检测与跟踪效果良莠不齐,在将传统视角的优秀算法迁移到UAV视角时仍存在较多有待改进之处,在性能提升上仍有较大空间。后续的研究工作可以多关注以下几个方面:
1) 依托无监督或半监督训练模式。现有的面向UAV视角的多目标检测与跟踪数据集较少,标注成本大。基于无监督学习与半监督的深度学习网络训练模式取得了较快发展,其网络训练方式对标注数据集需求较少,在处理缺少对应数据集的UAV多目标检测与跟踪问题上,此方向值得深入研究。
2) 设计有效的跨帧传播信息机制。无论是多目标检测还是跟踪算法,跨帧传播信息都是提高它们性能的一个有效策略。对跟踪场景内的各目标进行编码标注,并在帧间传递这些物体的信息,可以与更新策略有效联合,进一步避免引入噪声。研究跨帧传播信息机制是克服长时目标检测与跟踪困难挑战的一个未来研究方向。
3) 引入对算力要求较低的模型。基于Anchor-free的检测算法与JDT多目标跟踪算法拥有更少的模型参数,能够在硬件资源较少的移动端与边缘端取得较好效果,更适用于算力受限的UAV平台,如何将其更好地应用到UAV平台值得深入研究。
4) 搭建轻量级高效的目标特征提取网络。在进行多目标跟踪时,如何在提取到尽可能多的目标特征的同时,降低网络的复杂度,将是高效准确地实现多目标跟踪数据关联的重要环节。
5) 借助多模态数据。在进行无人机航拍视频的多目标检测与跟踪时,对于数据的类别选择上,除了使用常规的视觉单模态视频数据之外,可以借助UAV平台能够搭载的惯性处理单元、红外相机、景深相机等多模态传感器,实现多模态数据的采集与应用,获取到更多的数据信息,提升检测与跟踪精度。
