基于Mask R-CNN的试管-支架系统Data Matrix码识别方法
2023-10-11刘石坚林锦嘉陈梓灿邹峥
刘石坚,林锦嘉,陈梓灿,邹峥
(1. 福建省大数据挖掘与应用技术重点实验室,福建 福州 350118;2. 福建师范大学 计算机与网络空间安全学院,福建 福州 350117)
生物实验室常需要采集大量样本,并保存到试管中、放置于支架槽内。为方便快速管理和分析,装有样本的试管底部往往会印刷一种名为Data Matrix(DM)[1]码的矩阵式二维码,作为样本唯一标识。相较其他条码,DM码具有尺寸小、存储信息量大、纠错能力和抗干扰能力强等特点,被广泛应用于集成电路、机械磨具、精密生物器械等小件物品上。深度学习技术在过去几年发展迅速,已被广泛用于各领域,将其应用于DM码识别和信息读取,有利于实验室自动化[2]。
1 相关工作
DM码的传统识别方法主要利用其所具有L形状几何边界的特点来实现。例如,王等人[3]采用Hough变换[4]来实现DM码的检测定位。然而在实际应用中,输入数据中往往存在多个条码,且条码周围通常存在较多干扰。虽然许多方法[5~6]试图解决上述问题,但在面对复杂情况时,方法的稳定性仍然难以保证。相较而言,基于深度学习的方法因不依赖人工特征,具有更好的准确性和泛化能力,成为目前的研究趋势。
1.1 目标识别策略
基于深度学习的方法在实现条码定位时可分为目标识别策略和实例分割策略。
目标识别策略的思路是先通过YOLO[7]、Faster R-CNN[8]等目标识别方法找到输入图片中包含条码的局部矩形区域(即粗定位),再结合上述传统方法完成条码的最终定位。例如,易等人[9]提出一种级联多尺度特征融合网络快速检测算法实现对识别物流包裹的条形码。谢等人[10]基于Faster R-CNN框架提出一种香烟条码识别方法。针对复杂背景下的多条码检测问题,文献[11][12]提出不同的基于改进YOLO模型的条码检测方法。
1.2 实例分割策略
目标识别策略的局限性在于需要两个阶段来实现条码的定位,其深度学习的优势仅体现在第一阶段。实例分割策略则直接基于条码的实例分割结果进行定位,更简洁高效。例如,Zharkov等人[13]使用基于实例分割的深度学习方法识别一维条形码。胡等人[14]提出基于SegNet的DM码定位方法。分割策略的关键问题在于构建准确的分割模型,来获取可靠的DM码边界。
本课题提出的DeepDMCode方法与已有深度学习方法的主要差别在于处理对象和应用领域的不同。已有相关研究多处理一维条形码和QR码识别,面向多DM码的文献较少,讨论试管-支架系统中DM码识别的文献更加寥寥无几。其次,本课题虽采用基于Mask R-CNN[15]模型的实例分割路线,但针对提升准确性所提出的数据合成方法、标注方法及旋转矫正方法是普适性的策略,与特定分割模型的选取无关。
2 研究内容及挑战
课题以包含96个试管槽的一套固定支架为环境,在支架底部放置相机获取拍摄图像,以自动识别如图1所示图像中所有试管DM码为研究目标。

图1 试管支架底部成像图片Fig.1 Image captured at the bottom of a tube rack
DM码识别具体可分为码定位(第3章)和矫正解码(第4章)两部分,即首先找到DM码所在位置,然后将其旋转至标准朝向进行解码。其中码定位是识别的前提基础,旋转矫正使得通过标准解码库实现解码成为可能。
本课题面临以下挑战:
(1)DM码为小目标。单个试管DM码约占整副图像面积的1/1 200,如图1所示,定位和识别时容易对误差敏感。
(2)位置和旋转角度分布不均。如图1所示,单个DM码的位置和方向是随机分布的,这种差异和变化增加码识别难度。
(3)目标边界模糊。相对如图2(a)所示的标准DM码,在实际应用中,当照片受到光照不均或噪声影响时,DM码边界常常呈现模糊甚至消失的情况,如图2(b)所示。

图2 DM码展示Fig.2 Demonstration of data matrix codes
(4)存在相似性干扰。如图2(c)所示,在试管槽孔连接处以及镂空槽孔处存在与DM码边界相似的特征,这类相似性干扰会降低识别区分能力。
(5)数据量不足。深度学习方法依赖大规模数据进行模型训练,但试管支架图片数据来源有限,且没有公开的数据集作为补充。
本课题以支架试管图片作为输入,将单张图片中多个DM码作为检测对象,在无法获取大量学习样本的前提下,以减少繁琐的小目标手工标注和提高识别精度为目标,实现多目标码的识别。
3 码字区域精定位
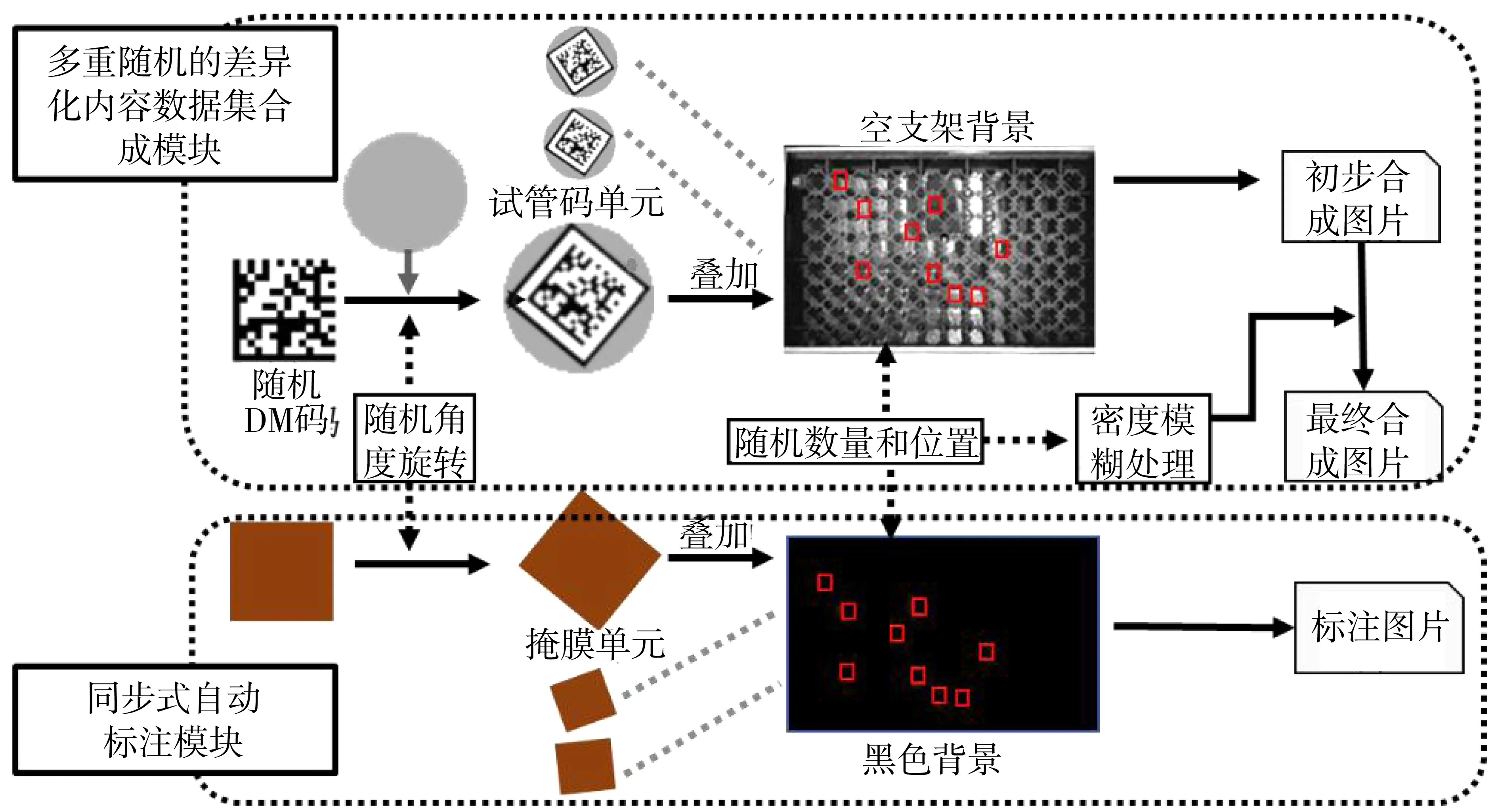
在DM码字区域定位环节,首先针对训练样本数量有限的问题,采用多层随机方式来生成人工合成数据,在保证多样性的前提下,最大程度地扩展数据规模;其次,为解决样本数量增加所导致的标注工作量剧增问题,使用同步式策略在合成数据时同步产生标注,提高标注效率。
3.1 多重随机的内容差异化数据合成
数据增强是一种广泛应用于深度学习中的技术,旨在提升模型性能[16]。通过对现有训练数据进行各种变换和扩充,有效增加样本的多样性,从而提供更丰富、更全面的训练数据集。传统数据增强方法通常通过图片翻转、调整明暗等来扩充数据,此类调整属于浅层调整,没有对关键特征即DM码内容进行变换,导致数据只是在数量上增大,而不能在内容上进行实质性的扩充,无法真正为深度识别提供多样性。
为了在增加图片集规模的同时保证图片集的差异化和丰富性,本课题提出通过多层随机构建内容差异的数据增强方案,从光照、位置、内容、方向多层次地模拟真实场景,提高识别的鲁棒性,降低识别时对位置和数量因素的敏感性。
3.1.1 合成数据背景设计
合成数据可分为含DM码的试管底部前景数据和其余含支架的背景数据。可以分别对前景和背景数据进行设计,再将两者叠加起来生成新的数据。
当支架未满载时,光线会穿过未放置试管的孔洞区域,导致成像光照不均。为模拟和复现这种真实光照环境,在背景设计时,对顶部光源打开状态下的全空支架进行成像,获取背景数据(即图1中没有试管DM码时的状态)。
3.1.2 内容差异化的前景设计
差异化前景试管码构建是数据合成的重点部分,本课题对前景从局部到整体进行分层构建,即先构建单个试管码单元;后将多个码单元组成码目标群。因此前景设计根据这种层次分为以下几个阶段。
(1)构建试管码单元阶段。为保证编码内容多样性,随机生8位随机字符r(C)作为内容,其中r均代表随机生成器,C代表字符,结合libdmtx库编码生成DM码图像g,该图像与圆形试管底部叠加,形成试管码单元图片。考虑到实现场景中试管摆放方向完全随机,因此需要对试管码单元施加一个随机旋转角度r(α)如公式(1),进行旋转得到试管码单元m。
(1)
(2)构建码目标群阶段。目标群设计主要包含目标总数的设计和各个目标在支架的空间位置设计。为模拟实际操作中支架上试管数量和位置会因实验任务不同而存在较大差别,为此针对数量和位置设计如下:
首先,为了模拟不同目标总数差异性,假定支架试管总数设置为r(N)(1≤r(N)≤N0),值域为1到N0之间,N0为支架能承载的最大试管数,试管总数用随机生成器生成,而k个试管对应的目标单元mj组成的集合M{m1,m2,…,mj,…,mk|k≤r(N)}形成一个目标群,其中单元总数k不超过实际试管总数r(N);其次,为确保目标位置随机,考虑到支架大小统一,槽孔排列规则,视觉上类似矩阵,因此为每个目标单元mk(xi,yj)生成一个随机空间位置r(i,j),i和j分别代表mk所在行序号和列序号。这样目标码群内的每个目标单元可以随机获取一个二维行列位置,分配到具体的槽孔位置。
3.1.3 背景叠加与空间密度模糊
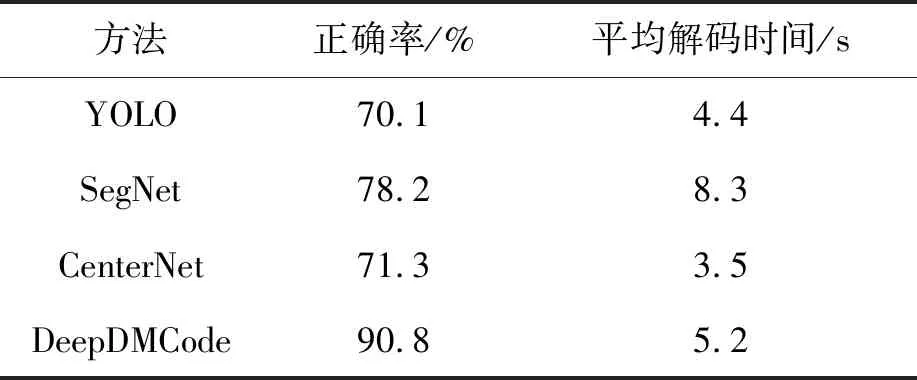
对支架背景和前景进行叠加,即将码单元图片在背景图片中进行逐一对齐,对齐的两个对象为:码单元图片中心点,和被分配槽孔的中心点。假设第1行第1列试管槽中心点(支架左上角位置)为(x1,y1),则其第i(1 (2) 为模拟真实光照不均造成的图像模糊,通过统计目标群在支架中的分布位置,计算目标群放置的空间密度,来设置相应的模糊度。 (1)构建n行m列槽孔矩阵G。矩阵元素代表每个槽孔是否放置了试管,元素值为1代表有试管,为0则无试管。 (2)统计槽孔矩阵内的试管密度。针对G施加卷积操作⊗,设置卷积核h(t×t)大小为t,用卷积核在G中逐行逐列滑动并统计固定区域内放置试管总数,获得大小为(n-t+1,m-t+1)大小的矩阵结果。 (3)计算试管空间密度。将结果展开成一维向量即F向量,分别计算其均值mean(F)和标准差std(F)如公式(3)所示,将标准差除以均值便可以得到试管密度ρ。ρ为大于0小于1的值,数值越大,代表试管摆放越不均匀,应施加的模糊度越高,反之数值越小,代表光照越均匀,应施加的模糊度越低。 (4)施加模糊效果。使用高斯低通滤波,假设滤波的截止频率范围为(D0,D1),截止频率是影响模糊关键因子,截止频率越高,图片越清晰,因此结合试管密度,截止频率应设置为d如公式(3),这样的设计根据实际目标群分布,设置对应的模糊度。 (3) 通过多重随机合成方案能有效扩充训练数据,但随之引发了新增数据的标注工作量过大的问题。使用人工分割方形码字区域(即掩膜)作为标注,耗时费力又容易出现差错。由于合成图片集的过程,和相关随机系数都是已知,这代表决定码字区域的大小、位置、方向都可知,因此可以重用合成流程,共享相关参数,来生成最终的标注,为此提出一种同步自动标注方法,生成对应的标注数据。如图3所示,该流程衍生自合成过程,可分为3部分:构建掩膜单元前景、构建掩膜群前景、叠加纯色背景。 图3 同步合成与标注方法示意图Fig.3 Demonstration of simultaneous synthesis and annotation method (1)构建掩膜单元。当前DM码单元生成并旋转后,其码字区域的尺寸以及旋转角度r(α)便确定。同步生成大小、角度一致的方块区域,即掩膜单元图片。单元图片中像素值设为随机标签值l(1≤l≤255),其余区域设置为0。 (2)构建掩膜群。为保证标注目标与合成图片中的目标一致,根据当前图片合成时的试管总数r(N),以及码目标群分配的槽孔行列位置r(i,j),同步生成同数目和分布的掩膜群。 (3)背景叠加。共享合成背景尺寸,但与合成背景不同,创建全0像素图片即黑色掩膜背景,而非支架背景图片,按照公式(2)准确计算槽孔位置,将掩膜图片叠加至黑色背景上。 图4展示了使用DeepDMCode法实现的一组合成图像及其标注数据样例。 图4 使用同步合同与标注方法所生成的合成图像及其同步式标注结果展示Fig.4 Demonstration of the synthesis and annotation result by the proposed method 旋转矫正的目标是将图5(a)所示的DM码修正为图5(b)所示状态,以便调用标准解码库进行编码信息的读取。 图5 旋转矫正方法示意图Fig.5 Demonstration of the rotation correction method 具体来说,图5(a)中彩色掩膜所示为上述方法所得分割结果,在掩膜图片中将y值最小点作为角点a:(xa,yb=ymin),以a为原点构建坐标系,此时DM码与X轴的夹角为θ可以按照公式(4)计算获得。根据得到的角度,以逆时针方向对码单元进行旋转,即可得到矫正后结果。最后使用第三方解码库,对其进行规范解码便可提取最终字符内容。 (4) 实验均运行于一台显卡为NVIDIA GeForce RTX 3060(12 GB),CPU为Intel Core i7-11700(2.50 GHz)的台式计算机上。输入数据分辨率为1 600×1 200,训练数据集包括两部分:第一类是原始采集图片集,由uEye UI-3013XC series摄像机拍摄,共516张,使用手工标注;第二类是通过2.1节方法合成的新增数据,共3 000张,使用2.2节方法进行自动标注。验证集和测试集均为上述第一类数据,三者比例约为8∶1∶1。 图6展示为应用DeepDMCode进行DM码精定位的典型结果,其中各DM码实例均能够被正确识别(见图中彩色掩膜区域)。 图6 DeepDMCode的DM码检测结果展示Fig.6 Demonstration of DM code detection result by DeepDMCode 选择目前条码识别主流的3种模型:YOLO[12]、SegNet[14]以及CenterNet[17]和DeepDMCode进行对比。针对码识别中码定位和码内容提取两个阶段的结果进行对比,同时针对本课题数据合成模块设计消融实验,来验证其贡献。 5.2.1 检测结果对比 分别使用3种方法对模糊图像中的目标进行定位,选择相同局部区域展示图片结果如图7所示,可见,YOLO无法识别码的方向,且存在误检,将具有相似直角和强边缘的背景错认为目标码;SegNet检测到的区域边界较粗糙,且大于真实码区域范围;DeepDMCode可较为准确的检测出模糊图片中对象边界,且不会受到相似性背景干扰,这得益于所提出的同步式差异性数据增强方法。 图7 检测结果对比Fig.7 Comparison of detection results 将定位结果与真实码字区域进行对照,使用mIoU[20]作为准确性指标,对4种方法进行数值评估。由于YOLO和CenterNet只适用于粗定位,无法精确反应码字区域,故用基于L型特征方法进行再处理,保证可比性,结果如表1所示。DeepDMCode的mIoU值为0.92,优于其他3种方法。 表1 准确性对比Tab.1 Accuracy comparison 5.2.2 DM码内容提取结果对比 针对3种方法的定位结果,选择libdmtx进行解码,与真实结果进行对照,分别计算正确率和平均解码时间两个指标,统计结果如表2所示,DeepDMCode正确率90.8%,平均解码时间为5.2 s;CenterNet和YOLO目标检测虽然更快,但正确率较低。 表2 DM码解码结果对比Tab.2 Comparison of DM code decoding results 5.2.3 消融实验 为验证本课题数据集合成模块对码定位的贡献,使用仅改变对比度和明暗的传统数据增强方法进行DM码定位,与内容差异化增强后定位结果进行对比,计算其mIoU指标。从表3中可知,在传统增强数据集上运行结果的准确性较Deep-DMCode约低10%,这证明内容差异化合成模块的嵌入,能很好地改善条码定位结果,进而提高后续码字内容提取的精确度。 表3 消融实验结果Tab.3 Ablation results 以试管-支架系统作为研究对象,基于分割策略对输入图像中的所有DM码进行定位和旋转矫正,实现编码信息的读取。本研究的主要贡献包括:(1)提出一种多重随机的内容差异化数据合成方法DeepDMCode。(2)部分重用合成流程,提出一种同步式的自动标注方法,共享随机参数,提高标注效率。(3)利用分割结果,提出一种旋转矫正方法,使得通过标准解码库对DM码编码信息进行提取成为可能。实验表明,该方法能有效克服图片分辨率低、目标数量和分布不确定、光照条件动态变化等因素所造成的识别困难,减少不必要的人工干预。后续工作将专注于提升方法的速度,以实现DM码的实时读取。3.2 数据同步自动化标注

4 旋转矫正及解码


5 实验及结果
5.1 检测结果

5.2 对比实验



6 结语
