融合注意力机制与轻量化网络的桥梁裂缝分类
2023-10-11庄永强
庄永强
(1. 福州市交通建设集团有限公司,福建 福州 350001;2. 福建路信交通建设监理有限公司,福建 福州 350001)
随着计算机技术的高速发展,深度学习网络在计算机视觉等领域表现出良好的性能,在桥梁裂缝检测上取得了一定的成果,但大部分网络模型较复杂,计算量庞大,导致网络的推理时间过长。为了减少运算参数、提高检测效率,深度学习网络开始向高效轻量的方向发展。
张振海等[1]基于 MobileNetv2[2]提出了BC-MobileNet 模型,该模型参数量少,但识别时会出现漏检误检。蔡逢煌等[3]为了减少网络参数量,在 YOLOv3网络中引入深度可分离卷积,并利用倒残差结构和注意力机制来减小精度略微下降的问题。王超等[4]搭建了轻量化全卷积神经网络,解决了卷积神经网络中训练参数过多的问题。
更高的裂缝识别分类精度总是伴随着模型参量的增长,因此本文提出了一种融合注意力机制与轻量化网络的桥梁裂缝分类方法,其在保证模型精准度的基础上,进一步减少模型参数量和复杂度。
1 基于注意力机制融合轻量化卷积神经网络模型
1.1 轻量化卷积神经网络EfficientNetv2
在深度学习网络中,随着网络深度的增加,获得的信息更丰富,但存在梯度消失的现象;网络宽度的增加不仅获得更高的细粒度同时也更容易训练,但是存在难以学到深层次信息的问题;网络图像分辨率的增加可以获得较多的信息,但会带来较大的计算量。针对以上问题,EfficientNet 系列网络应运而生[5]。该系列网络在准确以及速度上具有优势,但是该网络在浅层中使用了 DW 卷积导致训练的速度较慢,并且同等放大每一层网络中的深度以及宽度并不是最优的。鉴于此,该团队在 2021 年提出了一个新的网络——EfficientNetv2[6],其网络结构如图1所示。
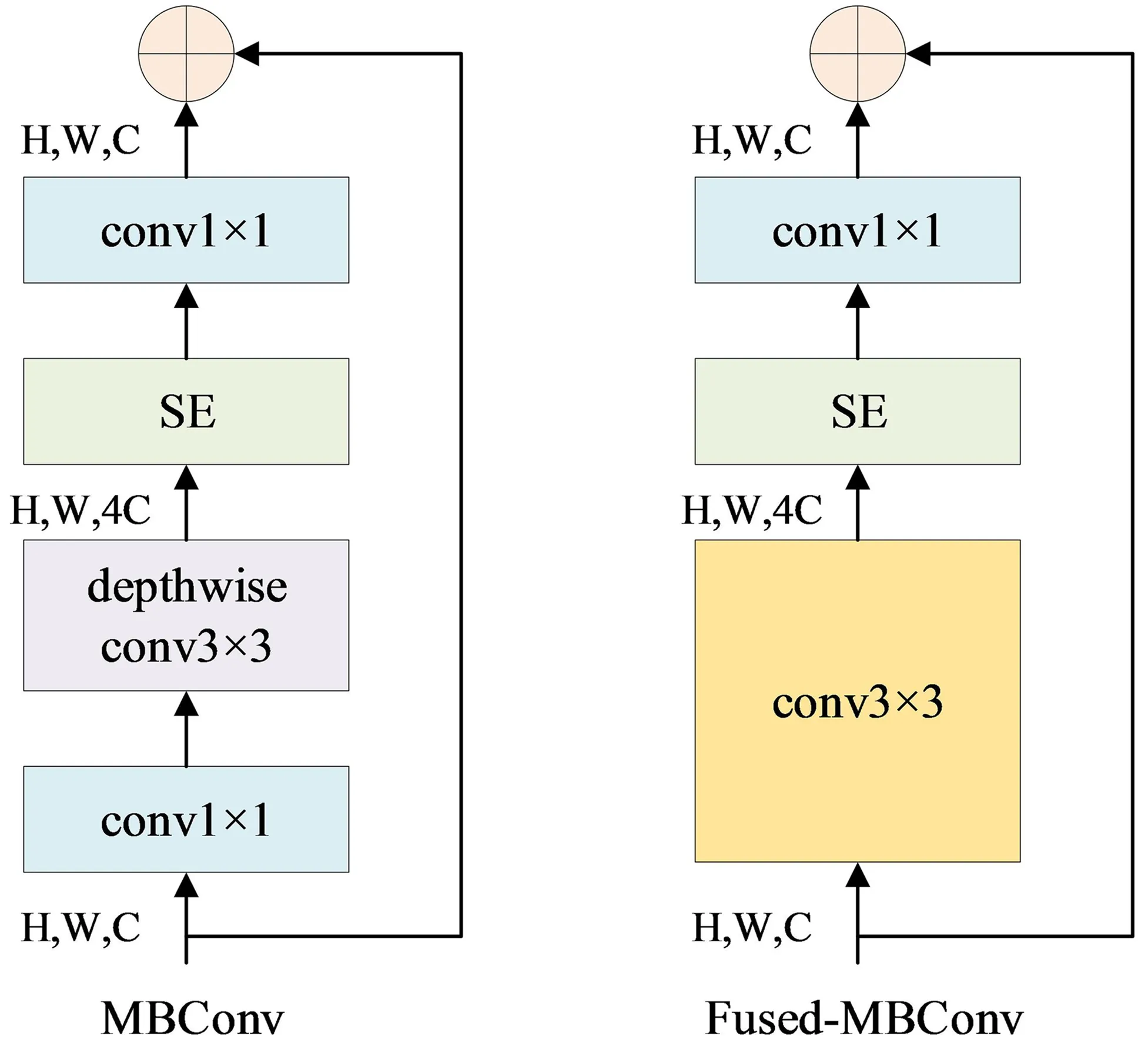
图1 EfficientNetv2网络结构图Fig.1 EfficientNetv2 network structure diagram
从图1可见,该网络在浅层中使用了普通的卷积而非 DW 卷积,将MBConv模块的1×1和DW conv融合为一个3×3的卷积。实验发现,在网络前期使用Fused MBConv会更优,在使用NAS技术搜索后,发现将前3个MBConv进行替换效果最好。当前,该网络无论是在速度还是参数量方面都优于其它网络。
1.2 注意力机制CBAM
将空间与通道注意力机制[7]串联得到CBAM[8]模型,这一过程输入的是在通道维度上得到的特征图,通过平均值池化及最大池化处理通道维度中输出的特征图,然后利用卷积进行降维操作,利用 Sigmoid 函数激活,通过以上操作获得空间注意力特征图。再将该特征图与输入到该模块的特征图的对应元素相乘,得到最终的结果,计算公式如(1)所示:
(1)

1.3 CBAM- EfficientNetv2网络模型
为了能够获得更多的图像信息、学习到更多的特征,对EfficientNetv2[9-10]网络的浅层Fused-MBConv使用CBAM注意力机制训练。在使用 CBAM-MBConv模块替代EfficientNetv2模型原有浅层模块的基础上,本文构建了基于注意力机制融合EfficientNetv2轻量化网络模型,如图2所示。
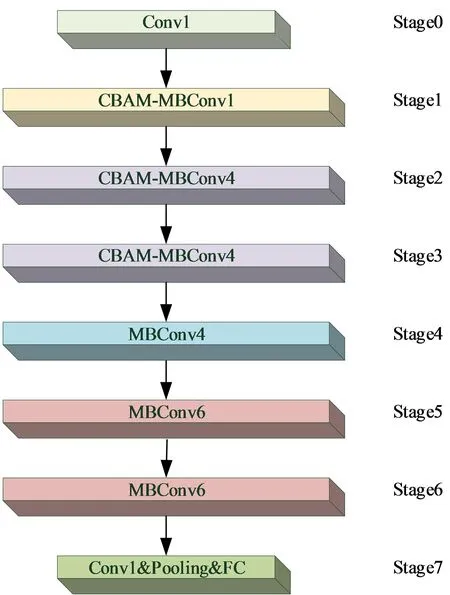
图2 CBAM- EfficientNetv2 模块结构图Fig.2 CBAM-EfficientNetv2 module structure diagram
所建立的网络模型在浅层考虑了通道上的重要特征,捕获到大量的空间特征信息。实验证明,使用混合注意力策略能够提高分类准确率,与其他主流网络的性能相比更有竞争力[11]。
2 桥梁裂缝图像数据获取与预处理
2.1 图像数据的获取
使用无人机在桥梁上人工采集图像,结合网上的开源数据集,共获取像素为1 024×1 024的含有桥梁裂缝的图像2 000张。
2.2 图像数据的预处理
对收集到的图像裁剪、增广、归一化处理。将裁剪后的图像做进一步的删减处理,删除既不包含裂缝也不包含背景的图像,再把这些图像分为横向、竖向、斜向3种裂缝类型。经图像预处理后,将裂缝图像由初始2 000张扩增到17 500张。
用于模型训练和测试的裂缝样本数据集共35 000张,其中扩增的17 500张裂缝图像包含5 500张横向裂缝、5 500张纵向裂缝以及6 500张斜向裂缝,另外在开源数据中收集制作背景17 500张。最终数据集的构成如表1所示。

表1 数据集构成情况表Tab.1 Composition of data set
3 实验分析
在Windows10 系统下采用 Python 语言编写程序,使用Pytorch 框架,所使用的虚拟环境为 Anaconda,实验均在同一台设备上进行,其配置为:Window10的计算机系统、Intel®CoreTMi9-9820X的CPU和NVIDIA GeForce RTX2080Ti的GPU。
使用 CBAM- EfficientNetv2和VGG16、ResNet34 三种模型在保证其他参数都相同的情况下,训练网络模型,并通过准确率、精确率、损失值、召回率等来验证训练效果。VGG16和ResNet34均为图像识别领域较为经典的大型分类网络,因此CBAM- EfficientNetv2模型与这两个模型对比具有参考价值。
3.1 图形对比
图3与图4是两个模型与CBAM-EfficientNetv2模型在验证集上的准确率及训练集上的损失值对比图像。由图可见,CBAM-EfficientNetv2模型在准确率以及损失值方面都优于其它两个模型,且网络的收敛更快,这表明在同一数据下使用CBAM-EfficientNetv2模型鲁棒性及泛化能力更强,更适用于裂缝检测。

图3 VGG16与CBAM-EfficientNetv2对比图Fig.3 Comparison between VGG16 and CBAM-EfficientNetv2

图4 ResNet34与CBAM-EfficientNetv2 对比图Fig.4 Comparison between ResNet34 and CBAM-EfficientNetv2
3.2 数据对比
准确率是分类模型中常用的一个指标,能够直观表现出该网络的优劣;迭代次数及运行时间能够反映出模型运行的速度,具体统计结果如表2所示。
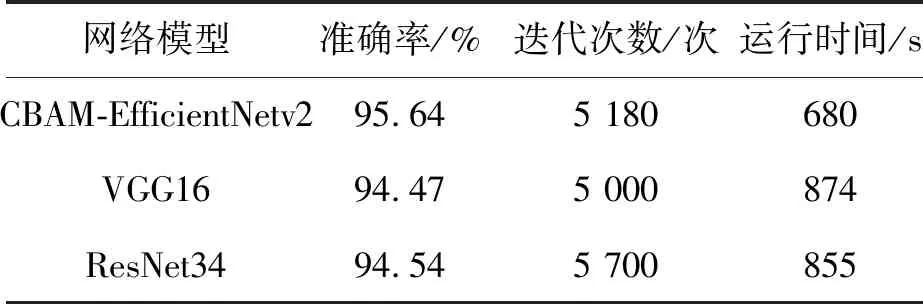
表2 模型数据对比Tab.2 Model data comparison
由表2可知,注意力机制中融合 EfficientNetv2网络模型的训练准确率最高,达95.64%,高于模型ResNet34和VGG16均超过1个百分点。由此可见,CBAM-EfficientNetv2模型应用于裂缝图像分类,能够有效提高准确率。
另外,训练一个epoch,CBAM-EfficientNetv2模型耗时680 s,远少于ResNet34和VGG16模型;其收敛速度也较快,收敛时迭代5 180次,略高于VGG16而明显低于ResNet34。综上,CBAM-EfficientNetv2模型在整体运行速度上具有明显优势。
表3为各类型裂缝与背景对应的分类精度指标统计结果。

表3 分类精度指标统计结果Tab.3 Statistical results of precision indicators
由表3可知,使用CBAM-EfficientNetv2模型训练后不同类型裂缝的精确率、召回率及F1值均大于90%,且竖向裂缝的召回率达到100%。由此可见,CBAM-EfficientNetv2模型对不同类型的裂缝均有较好的检测效果。
对不同类型裂缝进行多次分类的综合评价,采用平均精确率、平均召回率及平均F1值衡量指标,表4给出了3种模型综合评价指标的统计结果。

表4 平均精确率、平均召回率、平均F1值的统计结果Tab.4 Statistical results of average accuracy,average recall and average F1-value
由表4可知,对于不同模型,CBAM-EfficientNetv2模型的平均精确率、平均召回率、平均F1值结果均为最优,说明该网络在裂缝图像分类中具有较明显优势。
4 结论
1)对于不同深度学习网络模型,本文构建的CBAM-EfficientNetv2模型在各种精度指标中表现最佳,表明了所提模型在桥梁裂缝图像分类识别领域具有可行性和有效性。
2)与VGG16和ResNet34等传统大型分类网络相比较,CBAM-EfficientNetv2模型在整体运行速度方面具有较明显优势。因此,所提方法可有效减少计算量,提高桥梁裂缝检测的效率。
3)未来的研究将集中于快速构建更大型桥梁裂缝数据集,以自动检测多种桥梁病害类型。
