基于LC3D的摔倒行为识别算法
2023-10-09查凯文朱华生李舒宁
查凯文 朱华生 李 伟 李舒宁
(南昌工程学院信息工程学院 江西 南昌 330099)
0 引 言
传统的行为识别方法大多是基于特征提取进行[1],由Wang等[2]提出的iDT算法是行为识别领域中非常经典的一种算法,也是在深度学习应用于该领域前效果最好的算法之一,但由于该算法是基于光流进行运算,所以受光照等环境因素影响较大。随着大数据时代的来临与计算机的发展,深度学习的方法逐渐进入大众的视野,由Simonyan等[3]提出的双流CNN首次将卷积神经网络使用在行为识别当中。而在基于视频分析[4-5]的问题上,二维卷积网络不能很好地捕获时序上的信息。因此,Ji等[6]提出了能够提取三维图像特征的三维卷积神经网络(C3D)。而传统的C3D网络框架在面对复杂环境时容易造成特征提取不明显的问题,特别在小批量数据集中的识别率不高并且存在训练时间过长会导致梯度消失的问题。上述方法仅使用视频数据作为训练集,但环境、光照等多方面因素会降低神经网络对于摔倒特征的提取准确度。而骨架数据能够更好地反映人体行为的变化,避免过多的干扰因素。骨架数据在行为识别中的应用最早可以追溯到1973年,Johansson[7]通过实验发现人体的运动可以通过一些主要关节点的移动来描述。OpenPose[8]是一种基于深度学习的实时骨架检测算法,但由于识别出的骨架数据为2D数据,一旦关节点重合就会造成数据丢失的情况。Kinect摄像机能够自动提取人体的骨架信息,从而达到骨架与视频数据之间的同步。但基于Kinect的行为识别算法[9-11]没有很好考虑到摔倒行为的时序性。由Hochreater[12]提出的LSTM网络,在处理时序方面的问题取得了很大的进步。基于LSTM的行为识别算法[13-15]在时序建模方面取得了很好的成果,但仍然缺少空间特征。由Donahue等[16]提出的LRCN网络同时兼顾了时间特征和空间特征,但由于视频中的无关因素对时间序列上的影响力过大,所以取得效果仍然不如传统C3D网络。
针对上述问题,本文提出一种新的基于时序三维卷积网络(LC3D)的摔倒识别算法,即同步获取视频和骨架两组数据,将视频数据输入到改进后的C3D网络进行训练后提取摔倒行为的C3D模型;同时将骨架数据输入至LSTM网络进行训练并提取摔倒行为的LSTM模型;最后通过Stacking算法将两个模型进行融合得到LC3D模型。本文的主要贡献有两点:一是对C3D网络进行了改进,降低了C3D网络的时间和空间复杂度,解决了梯度消失的问题。二是将C3D模型和LSTM模型进行融合,得到的LC3D模型在摔倒行为识别时,具有更高的准确率。
1 算法实现
1.1 算法总体结构
基于LC3D的摔倒行为识别算法主要分为数据采集、数据预处理、LC3D模型训练和基于LC3D网络的摔倒识别四个部分。首先将采集到的视频与骨架数据进行预处理,并同时在数据集上训练出基于LC3D网络的摔倒识别模型,最后将训练好的模型与处理好的数据再次输入至LC3D网络进行识别。该算法整体流程如图1所示。
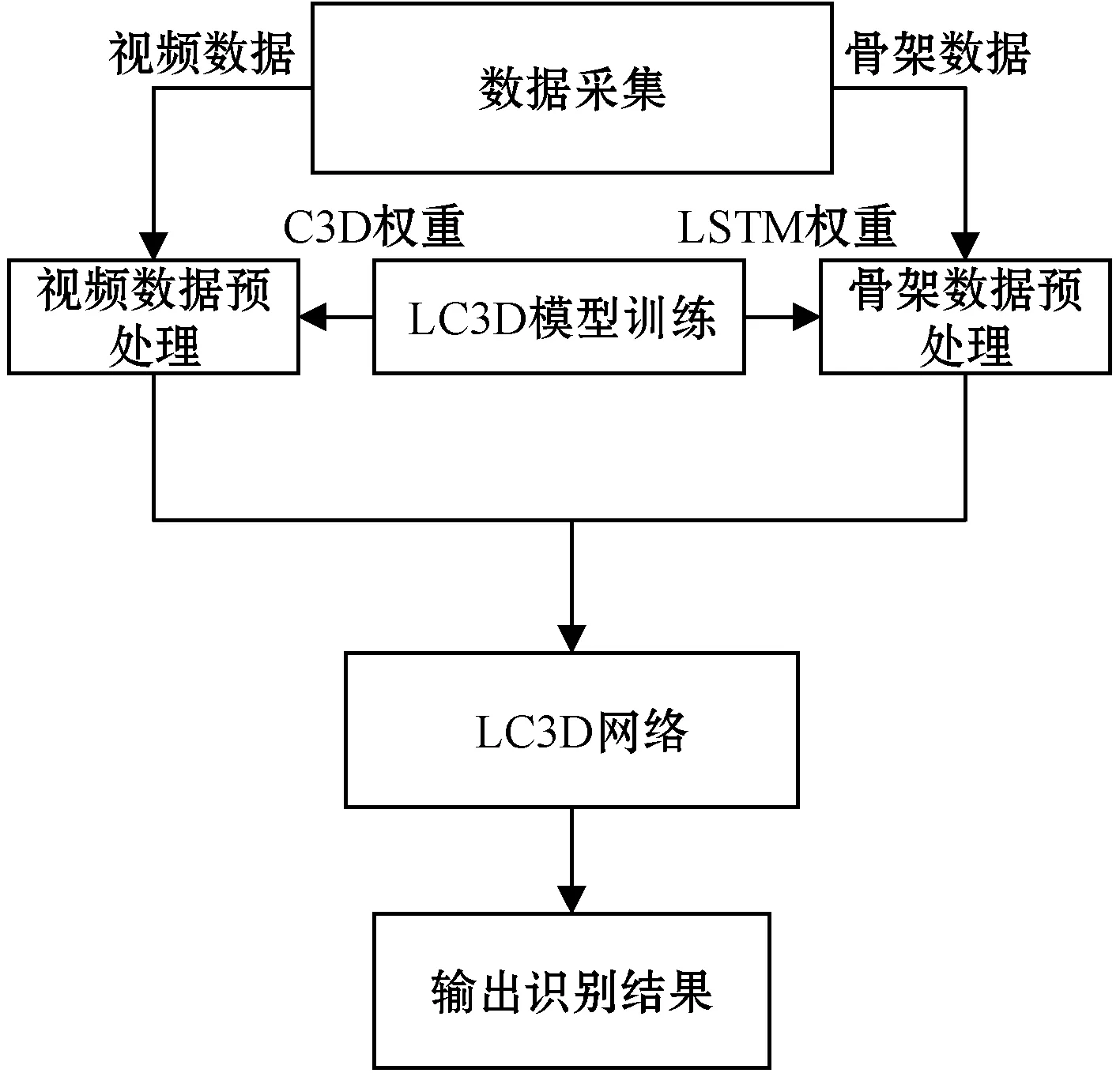
图1 基于LC3D的摔倒行为识别算法流程
1.2 数据预处理
在数据采集方面本文使用Kinect感应器进行采集,该设备能够同步获取视频与骨架数据。同时,在训练模型与进行摔倒识别之前,需要对视频与骨架数据进行预处理,以达到更好的识别效果。
1.2.1视频数据预处理
由于采用到的视频数据可能存在分辨率、帧的长度等参数不一致的问题,而这些问题可能影响训练时间、识别效率等,为此需要对视频数据做预处理。预处理的主要工作是将视频数据调整为统一大小的训练样本,如:将每一段视频大小统一调整为h×w×f的样本,其中:h和w分别表示图像的高和宽,f表示视频的帧数。另外,为了获得更多的训练样本,本文将每个样本做镜面翻转,得到另一个样本。
1.2.2骨架数据预处理
骨架数据与视频数据由Kinect感应器同步获取,因此将骨架数据部分所使用的帧数范围与视频数据保持一致。同时为了缩短训练时间,提高识别准确率,我们需要对骨架数据进行一定的筛选。对骨架数据的筛选主要包括对关节点部位、坐标值和分类行为的选择三部分。
1) 关节点的部位选择。人体的骨架包括躯干、手臂、腿部三个部分,共有25个关节点构成,如图2所示。
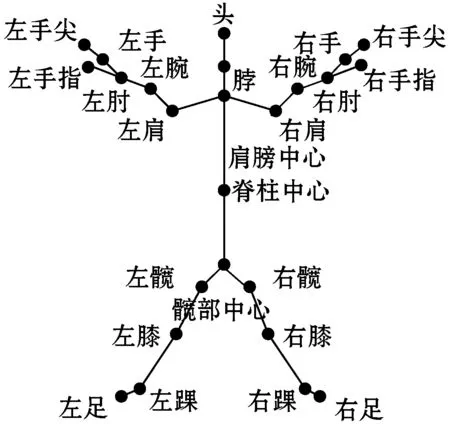
图2 骨架数据示意图
当跌倒行为发生时,由于跌倒姿势的不同,腰部以上的关节点变化差异较大,而腰部以下的关节点的变化大致相同,因此本文只提取腰部(包含髋部中心)以下共9个关节点作为训练数据。
2) 关节点的坐标值选择。骨架数据均为三维数据,即每个关节点都有x、y、z三个轴的坐标值。由于摔倒行为是一个序列动作,在摔倒途中z轴坐标值会发生很大幅度的下降变化,而其他轴的坐标值变化存在不确定性,因此只提取关节点的z轴坐标值作为训练数据。
3) 分类行为的选择。摔倒行为的一个显著特征是z轴坐标值的下降变化,而大部分动作的坐标值并没有下降变化。本文将一些常见行为的关键帧的骨架关节点绘制成图像,结果如图3所示。
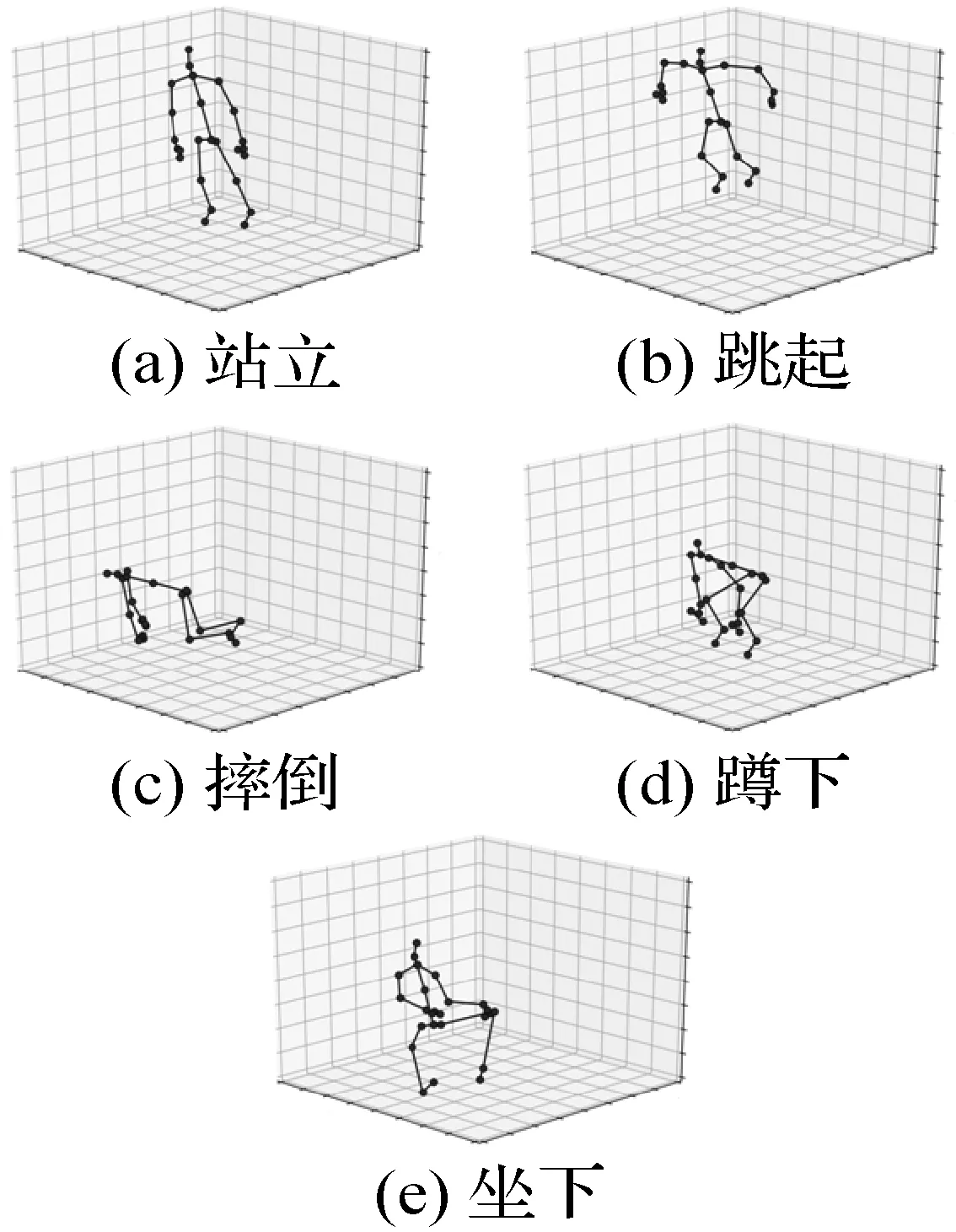
图3 关键帧骨架示意图
由图3可以看出站立与跳起行为腰部以下的关节点的z轴坐标并没有下降的趋势,且部分关节点的坐标值明显高于摔倒时的坐标值。而坐下和蹲下也具有z轴坐标值下降变化的特征。因此,本文选择摔倒、坐下和蹲下这3种相近动作进行训练。
1.3 LC3D模型训练
LC3D模型训练主要由训练数据预处理、C3D模型训练、LSTM模型训练和模型融合共四个部分组成:
1) 训练数据预处理的主要任务是将数据集中的数据通过1.2节所描述的预处理方法进行处理。
2) C3D模型训练包括改进型C3D网络和C3D模型两部分。这部分的重点工作是对C3D网络的改进。
3) LSTM模型训练包括LSTM网络和LSTM模型两部分。这部分的重点工作是使用LSTM网络对骨架数据进行训练得到LSTM模型。
4) 模型融合的主要任务是选择一个合适的融合算法,并利用该算法将两个模型融合成一个模型。
LC3D模型训练模块的主要结构如图4所示。
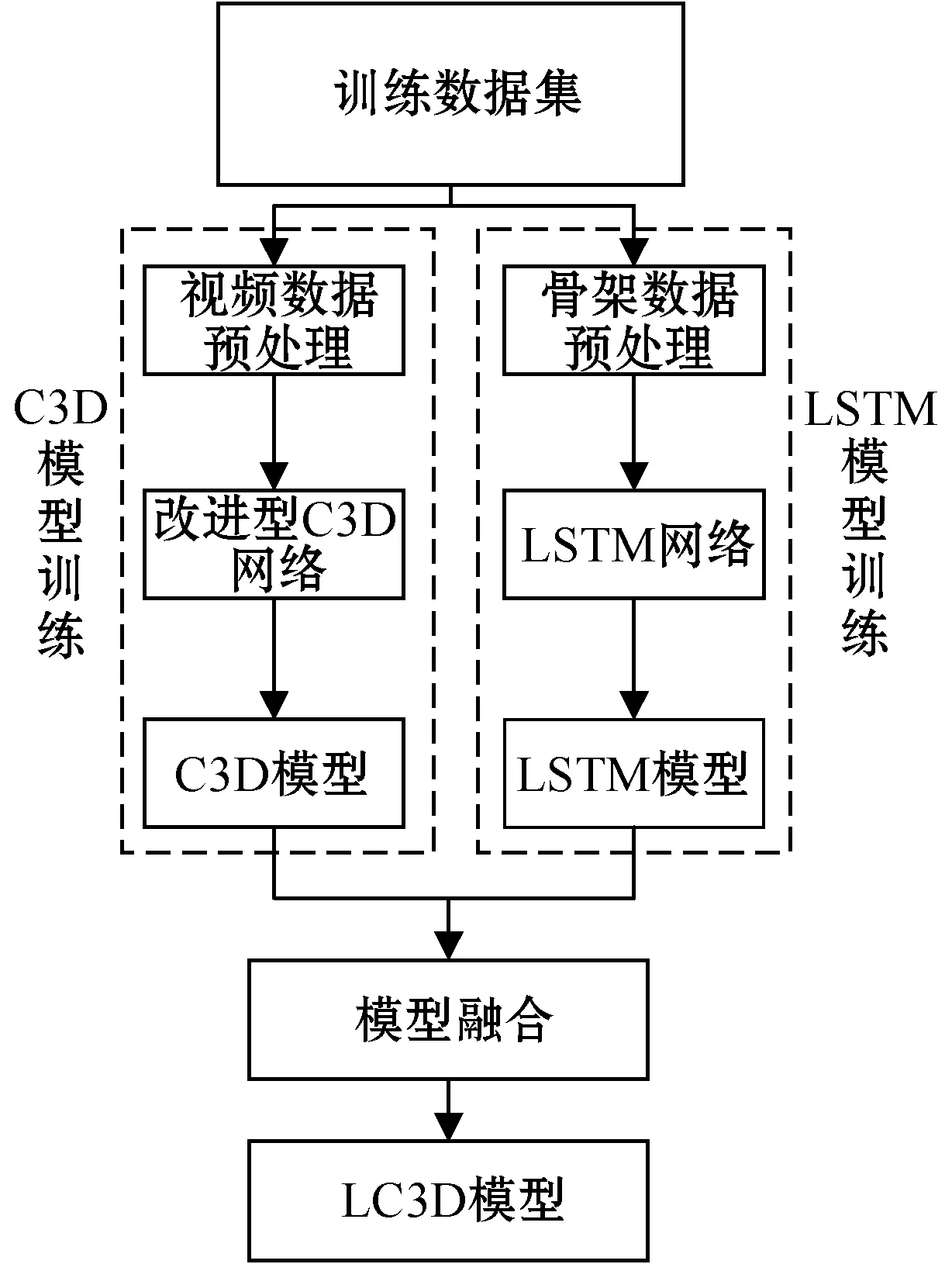
图4 LC3D模型训练模块结构
1.3.1C3D模型训练
C3D模型训练首先对采集到的视频数据进行预处理,然后将处理好的数据送到改进型C3D网络进行训练,最后得到C3D模型。
针对传统的C3D网络时间和空间复杂度过大且容易造成梯度消失的问题,本文对传统C3D网络进行修改。改进后的网络共有4个卷积层,4个池化层和两个全连接层。其中4个卷积层的神经元个数分别为64、128、256、256。较传统C3D网络结构而言,将8层卷积精简为4层,能够有效防止梯度消失并降低时间复杂度与空间复杂度。卷积神经网络的整体时间复杂度和空间复杂度可表示为:
(1)
(2)
式中:输出特征图的体积为M2、卷积核体积为K2,l为神经网络的第l层,Cl-1为输入通道数,Cl为神经网络第l个卷积层的输出通道数即该层的卷积层个数,D为网络的深度。通过式(1)-式(2)可算得传统C3D网络的时间复杂度为6.535 41×1 012,空间复杂度为3.256 24×107。而改进型C3D网络的时间复杂度为1.563 45×1 012,空间复杂度为7.789 82×106。可见改进型C3D网络在时间复杂度和空间复杂度上有明显的降低。改进后的C3D网络结构如图5所示。
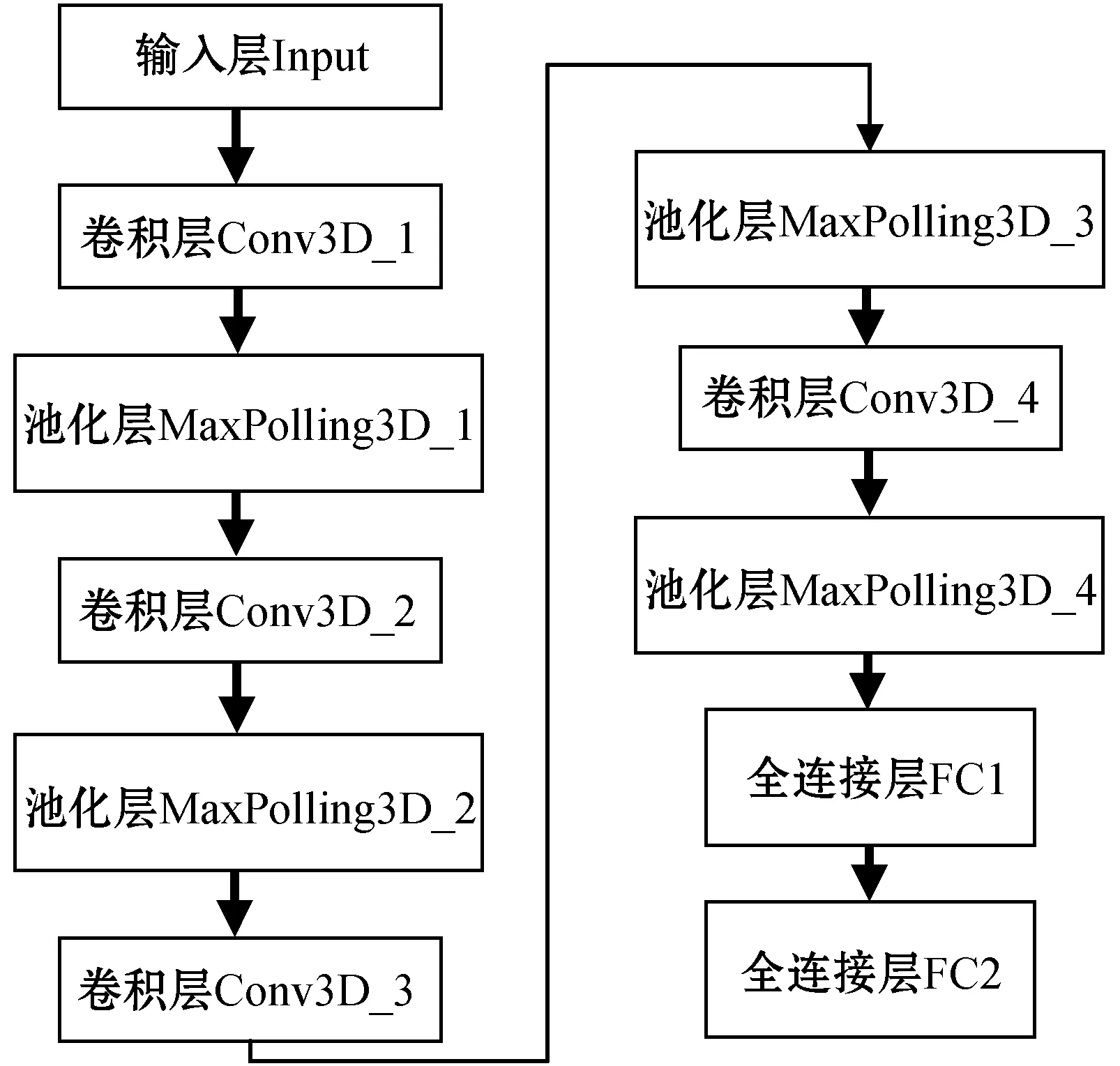
图5 改进型C3D网络结构
1.3.2LSTM模型训练
LSTM模型训练首先对采集到的骨架数据进行预处理,然后将处理好的数据送到LSTM网络进行训练,最后得到LSTM模型。
循环神经网络(RNN)在处理时序数据上具有优势,但普通RNN网络存在网络层数较深时感知力下降的问题。而LSTM网络作为RNN网络的改进,具有长时记忆功能,能够很好地解决普通RNN网络在训练过程中感知力下降的问题。因此,本文使用LSTM网络对骨架数据进行训练。本文所使用的LSTM网络结构如图6所示。
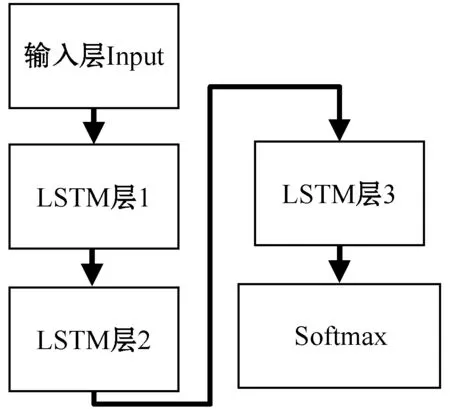
图6 LSTM网络结构
LSTM网络使用每一个视频所对应的骨架坐标值作为输入,经过3层数量均为32个神经元的LSTM层,最后再使用Softmax进行分类,得到一个基于骨架数据的分类模型。
1.3.3基于Stacking算法的模型融合
对于神经网络训练后的模型,单个模型往往存在过拟合、预测能力不够等问题。而Stacking算法不仅可以提高模型的范化能力,还可以分别对过大或过小的数据集进行划分和有放回的操作从而产生不同的数据子集,然后通过数据子集训练不同的分类模型,最终将各个分类模型合并成一个大的分类器从而提高预测能力。
Stacking融合算法原理[17]是将多个分类器的识别结果再进行训练学习,以得到最终的识别结果。其算法原理如图7所示。
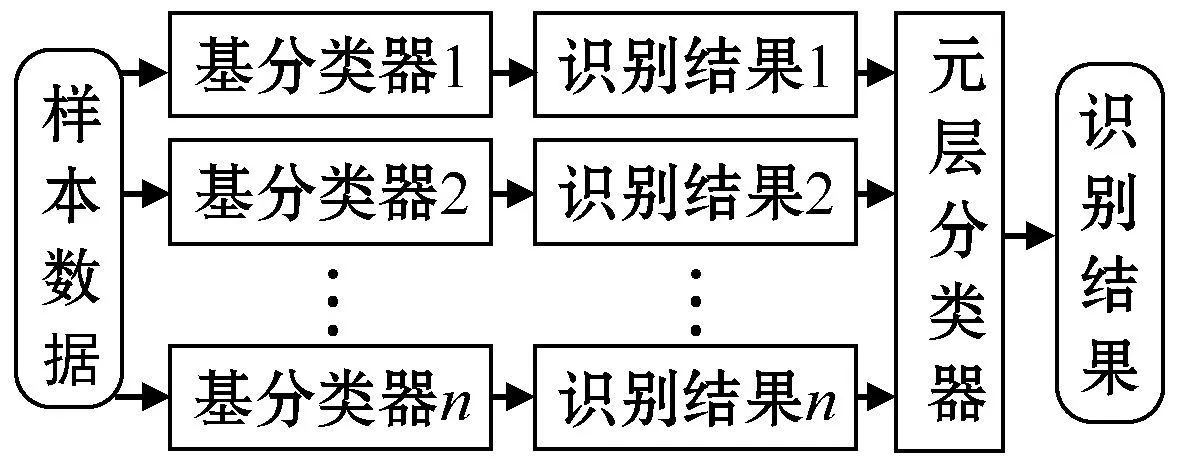
图7 Stacinking算法原理示意图
Stacking算法框架包含两层:基层(base-level)和元层(mate-level)。基层由多个分类器组成,对原始给定数据进行初次分类。
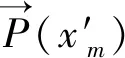
(3)
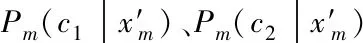
(4)
在获得输入向量xmeta后将其作为元分类器的输入并继续学习。元层只有一个分类器,我们使用Stacking作为元方法将基分类器的输出作为元特征,并作为输入训练得到新的元分类器。经过此分类器的学习训练,得到融合后的分类结果。本文所使用的Stacking模型融合算法的伪代码如算法1所示。
算法1Stacking模型融合算法
输入:初始训练集T=(x1,s1,x2,s2,…,xh,sh),基分类器C3D,LSTM,元分类器Stacking,交叉检验子集数目k。
输出:基分类器C3DModel,LSTMModel与元分类器StackingModel。
Tl,T2…,ITk=CV(T,k)
Y={}
FOR EACH TJ in Tl,T2,…,Tk:
C3DModelj=C3DT-Tj
LSTMModelj=LSTMT-Tj
FOR EACH xi in Tj:
yil=C3DModelj.predict(xi)
yi2=LSTMModelj.predict(xi)
Y.append(yil,yi2,si)
END FOR
END FOR
StackingModel=Stacking(Y)
1.4 LC3D网络结构
与LC3D模型训练所使用的结构相似,首先将视频数据与C3D权重一组、骨架数据与LSTM权重为另一组分别通过改进型C3D网络和LSTM网络,然后使用concatenate层对各个网络的识别结果进行合并,最后通过Softmax层对识别结果进行分类。LC3D网络结构如图8所示。
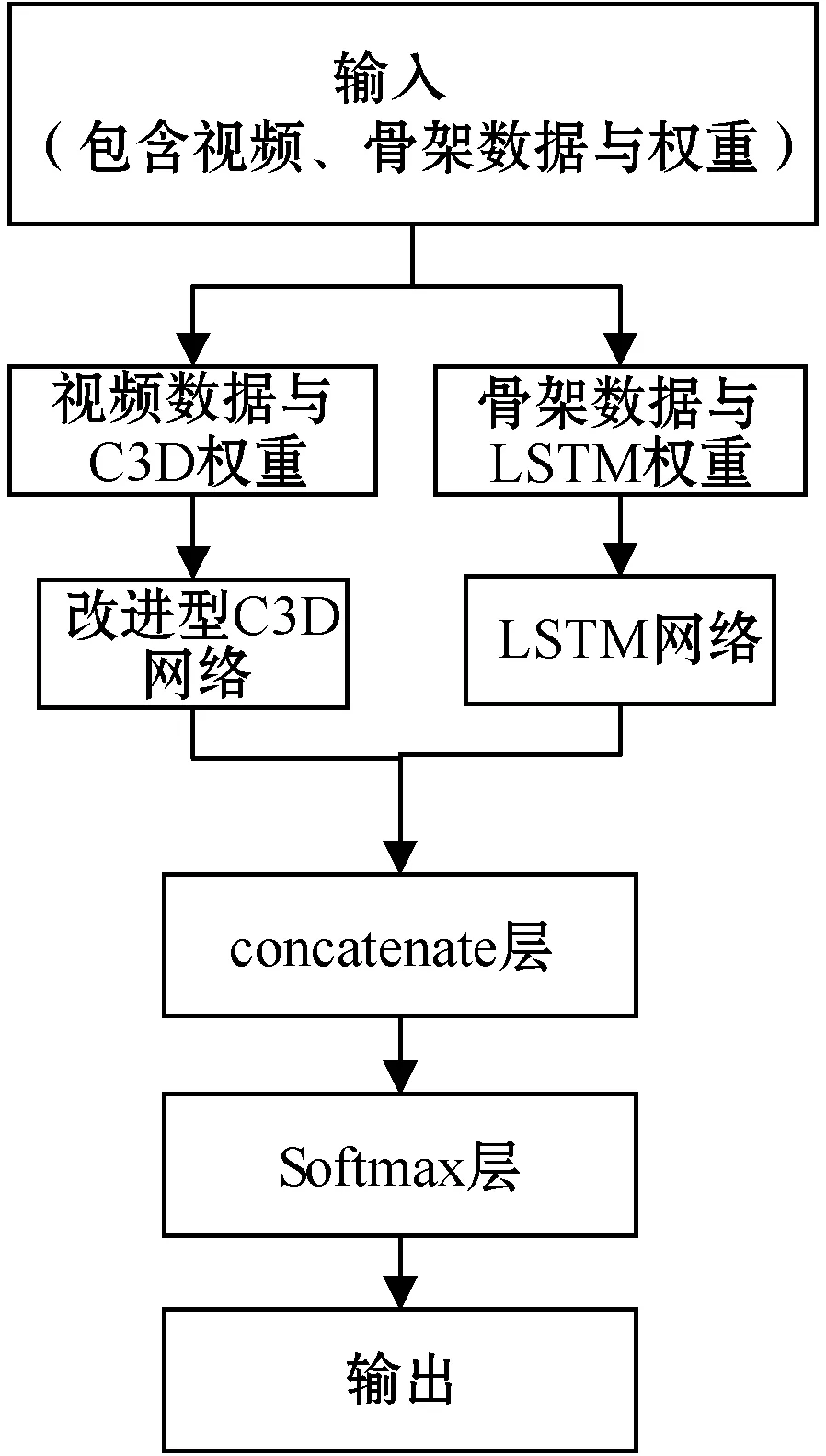
图8 LC3D网络结构示意图
2 实 验
2.1 实验环境与数据集
本文使用Python作为编程语言,并使用Keras对网络框架进行搭建,所使用的环境如表1所示。

表1 实验运行环境
模型训练使用NTU-RGB+D[18-19]作为数据集,该数据集由新加坡南洋理工大学博云搜索实验室建立。该数据集包含56 880个示例动作,包含120个动作类别。内容有RGB视频和3D骨骼数据。每段视频大小为1 920×1 080,每秒30帧,骨架数据记录了对应视频中人体25个关节点的坐标位置。图9显示了摔倒、坐下和蹲下三种行为图在不同人物角度的视频图像。

图9 摔倒、坐下、蹲下视频图像
2.2 实验结果分析
本文对摔倒、坐下和蹲下三种行为总共2 844个视频及相应的骨架数据进行训练。其中骨架数据记录了对应视频数据中所有关节点每一帧的坐标值。但由于原数据集每一段视频的帧数不尽相同,因此为了训练数据的统一,本文只针对每一段视频的前50帧进行预处理。此外,视频图像的大小与神经网络的参数设置均与传统C3D网络[6]中的参数保持一致。
对于视频数据,在训练过程中先将每一个视频段中的每一帧图像的大小调整为112×112。为了加快训练速度并使神经网络更注重于关键帧动作,因此在每个视频数据的前50帧中仅提取16帧作为关键帧,即一个112×112×16大小的视频段作为C3D模型训练的输入。C3D网络中所有神经元大小均为3×3×3;除第一个池化层大小为1×2×2以外,其他均为2×2×2。
骨架数据的数据量较视频数据更小,因此在LSTM网络中使用每个视频中前50帧所对应的骨架数据作为输入训练。
整体神经网络使用SGD作为优化方法,学习率设为0.003,epoch设置为16,为了加快学习速度以及减小震荡将动量参数momentum设置为0.9,为了防止过拟合将Dropout率设置为0.5。使用传统C3D网络、LSTM网络和LC3D网络所得到的训练结果分别如图10-图12所示。
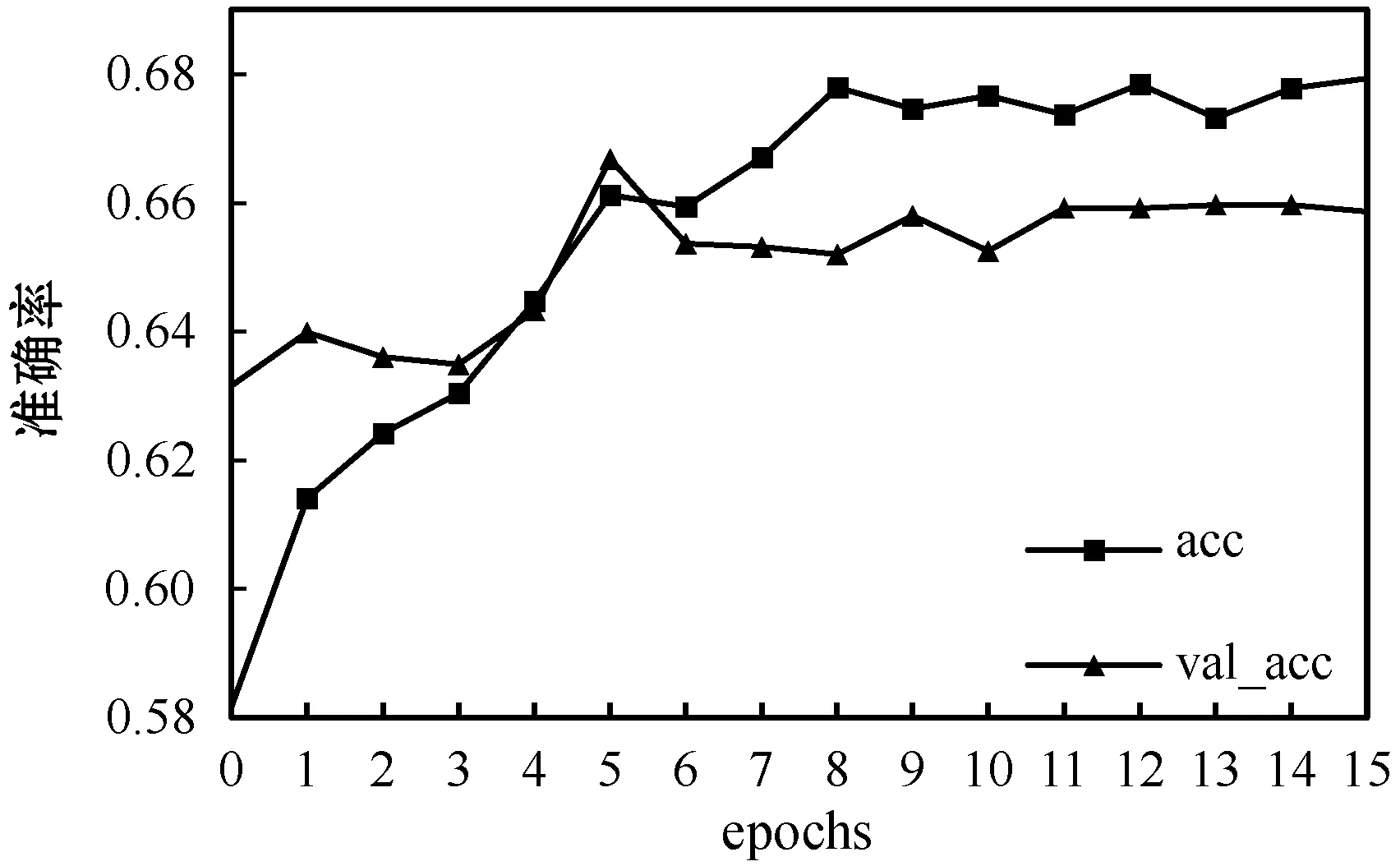
图10 传统C3D网络准确率变化图
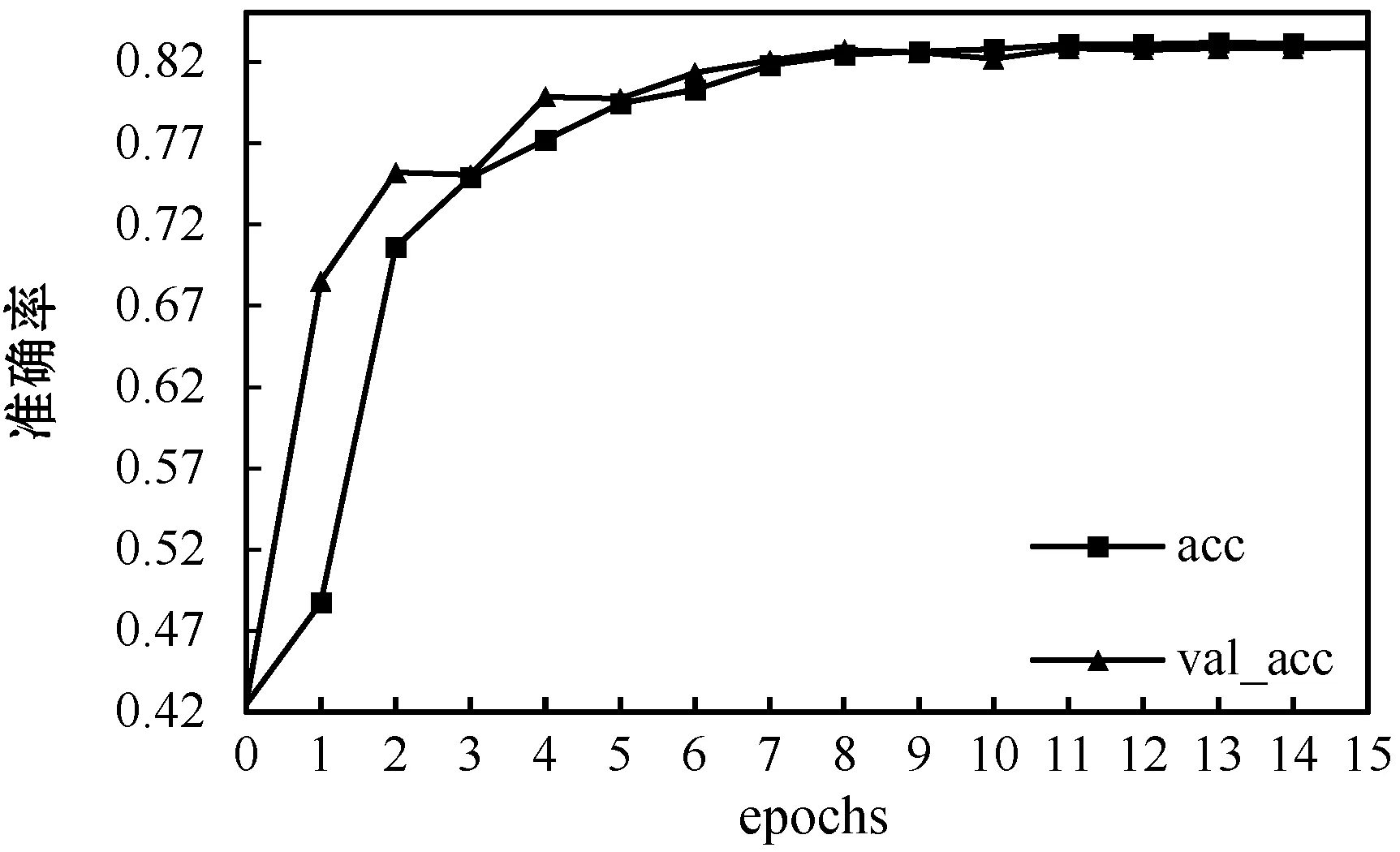
图12 LC3D网络准确率变化图
可以看出,传统C3D网络和LSTM网络的训练集与验证集准确率差距很大,说明使用单个网络训练出来的模型泛化能力较差且容易出现过拟合的情况。而LC3D网络的训练集与验证集的准确率大致相同且网络收敛速度更快,训练出来的模型更加准确。不同算法准确率比较如表2所示。
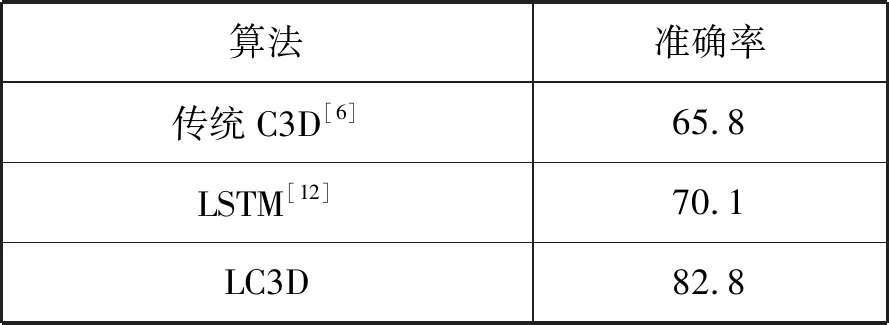
表2 不同算法准确率对比结果(%)
由表2可知本文方法达到了82.8%的准确率,较传统的C3D网络提升了17%,较LSTM网络提升了12.7%。
3 结 语
本文提出了基于LC3D的摔倒行为识别算法,该方法使用改进C3D网络和LSTM网络分别对视频和骨架数据进行训练,最后将训练后的模型进行融合得到最终的摔倒识别模型。该模型在NTU-RGB+D数据集上进行验证,相较传统的C3D和LSTM网络拥有更高的识别准确率。本算法适用于家庭、养老院和医院等多种看护场景,能够准确并及时地发现摔倒行为,且该算法能够广泛地应用于监控设备之中,对于目前日益增加的精准看护需求具有重大意义。
