基于CS及ECS索引的后向链式流推理
2023-10-09韩裕镥顾进广李奇缘
韩裕镥 顾进广 李奇缘
(武汉科技大学计算机科学与技术学院 湖北 武汉 430065)
(湖北省智能信息处理与实时工业系统重点实验室 湖北 武汉 430065)
(武汉科技大学大数据科学与工程研究院 湖北 武汉 430065)
(国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室 湖北 武汉 430065)
0 引 言
在当前的大数据时代,实时的语义数据不断增长,如何处理这种不断到达的数据仍然是一个挑战,特别是针对语义Web的实时流处理,一方面语义Web的表示有相对固定的标准及格式,但是流处理方面目前并没有统一的标准,因此设计整个流系统的架构十分困难。另一方面,当前在静态RDF图上有很多关于RDFS的推理方法,但是在RDF数据流上很少见,传统的流处理是将输入的数据流转换为特定的关系后执行临时查询及推理来处理此类语义流数据,由于数据转换和基于磁盘的存储可能会非常昂贵,因此该方法通常假定数据不会频繁更改,而且它在实时性处理方面有很多不足。其次,诸如无处不在的物联网场景通过在人与对象、人与人、对象与对象之间生成大量流数据来重新定义信息的价值。通过实时应用人工智能、机器学习、优化技术,以及将传统数据处理和数据分析应用于历史数据,这些数据具有转化为即时知识并最终提供服务的巨大潜力[1]。流推理结合了推理和流处理技术,这种结合使得能够处理从大量源连续产生的动态和异构数据,动态处理多个流,并实现实时服务。但是目前已经提供的流推理服务是相当昂贵的,而且标准的数据流管理系统并不支持流推理服务。
在近几年中,RDF流处理(RDF Stream Processing,RSP)社区为解决上述问题做出了一些贡献。但总体来看,大多数工作要么忽略数据量可能庞大的情况,要么忽略RDF数据流的推理能力。目前关于静态RDF图的RDFS推理有很多方法,但是在RDF流上很少,RDF流推理系统需要解决对非常动态的输入进行推理的问题,同时也要在推理准确性及推理效率之间权衡,有可能一分钟前推理的知识在这一刻已经不成立,因此流推理系统需要很强的时效性,而且研究表明,流推理中平均推理延迟占整体处理时间的45%到65%,远高于传输和其他数据处理时间[2]。
针对以上难题,本文在实时流数据处理引擎Esper的基础上,设计一个基于CS及ECS索引的后向链式流处理方法。Esper可以使用类似于SQL的EPL语言来处理持续的流数据,它并不是先存储数据再注册一个查询语句,而是先注册查询后去检索持续的流数据,类似一个关系数据库的颠倒。目前基于ECS的静态查询具有较好的性能,但是并不支持推理,本文将CS及ECS索引与后向链式流推理相结合。
1 相关工作
本节首先介绍RDF数据流和RDFS流推理的基本概念,然后对与本文工作方向相近的研究进行介绍和分析。资源描述框架(RDF)和SPARQL是W3C关于在网络上表示和查询图数据的建议,RDF基本组成为三元组,基本结构是t∈
RDFS是在RDF的基础上定义了一系列规则,它是一种可扩展的知识表示语言,可以用来创建描述类、子类和RDF资源属性的词汇,以便于进行推理,如表1的RDFS推理规则集。而推理则是一个产生新知识、挖掘隐含知识的过程,在RDF表示中表现为从已有的RDF图中利用一系列规则产生更大的RDF图的过程。
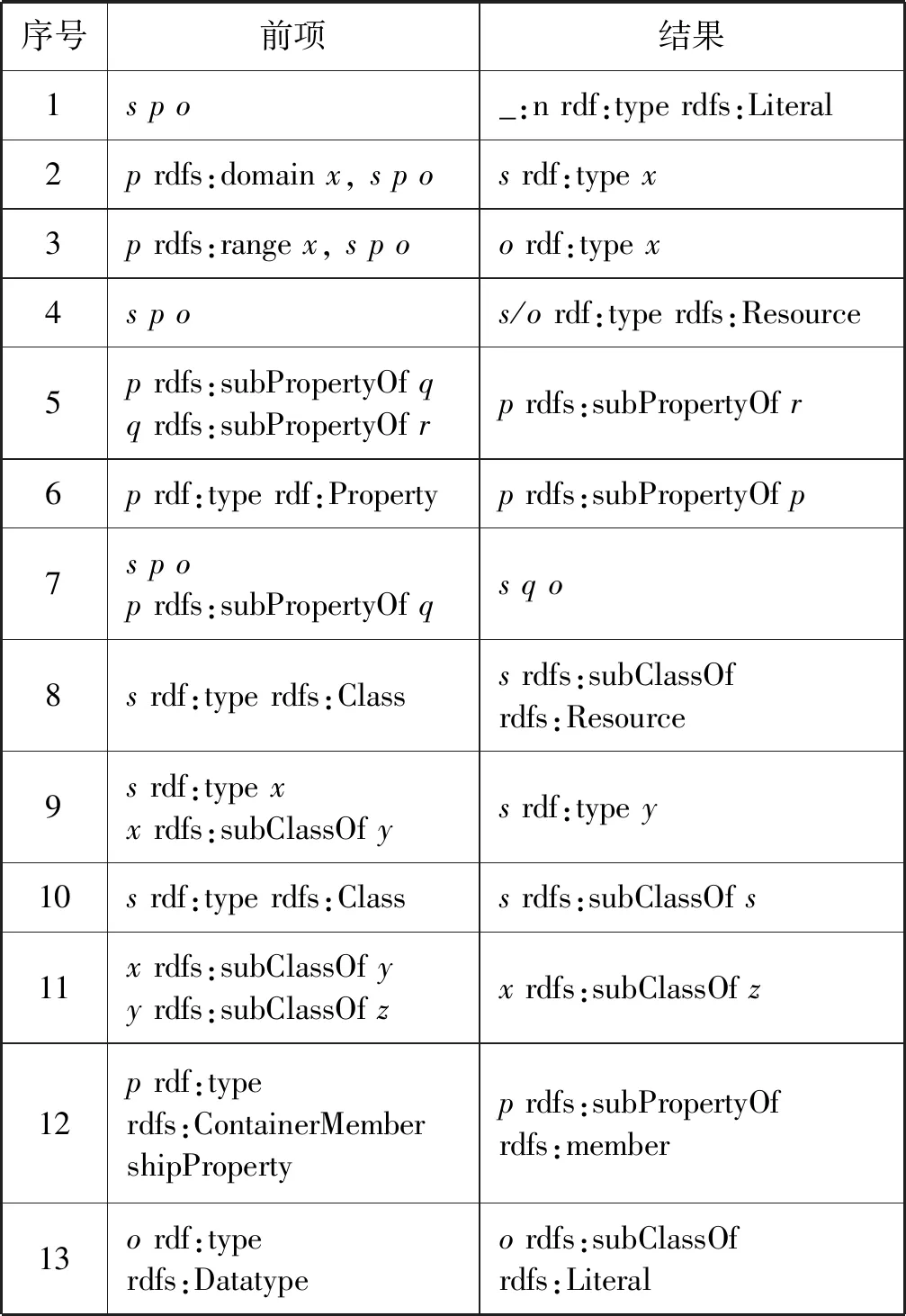
表1 RDFS规则集
为了从RDF数据流中获得更多的信息,目前的方法是在现有RSP引擎中添加推理功能。受智能城市的物联网用例的影响,本文首先提出了将推理技术与数据流相结合的理论。尽管RDF流推理的最初思想是在十年前提出的,但是RDF流推理的发展仍处于起步阶段。像C-SPARQL或StriderR[4]这样的系统允许通过RDF流进行RDFS++的推理,但是对时间逻辑运算符的表达仍然存在局限性。
TrOWL[5-6]是最早开发RDF流推理的系统之一,TrOWL能够即时计算并维持推断结果的合理性。开源 ELK推理程序的目标是支持OWL到EL的配置文件,它是ConDOR项目的一部分,该项目主要研究基于“结果驱动”的推理程序。尽管ELK最初不是为RDF流推理量身定制的,但仍然认为LiteMat可以依靠ELK的TBox分类工具。StreamRule[7]及其并行化版本StreamRuleP[8]都使用RSP引擎进行数据流预过滤,使用Clingo[9]作为ASP 求解器。BigSR[10]中BSP实现的表达能力可以完全涵盖StreamRule和StreamRuleP。此外,对StreamRule/StreamRuleP的评估表明,平均吞吐量约为C-SPARQL 和CQELS的2倍,具有秒级别的延迟,但是集中式方法限制了StreamRule和StreamRuleP的性能。
Laser[11]和Ticker[12]都是基于LARS[13]框架的流处理系统,但是由于引入了外部的ASP引擎Clingo而使得性能下降,同时Laser也不能进行分布式的流处理,因此BigSR在Laser的基础上解决了这一问题。
Cichlid[14]是基于Spark大数据处理框架的分布式语义网推理机,有着较高的推理性能,EMSR[15]是在 Cichlid的基础上加入了基于变量的优化联接算法,减少了联接的时间。表2总结了各RSP引擎和流推理系统的性能和特点。
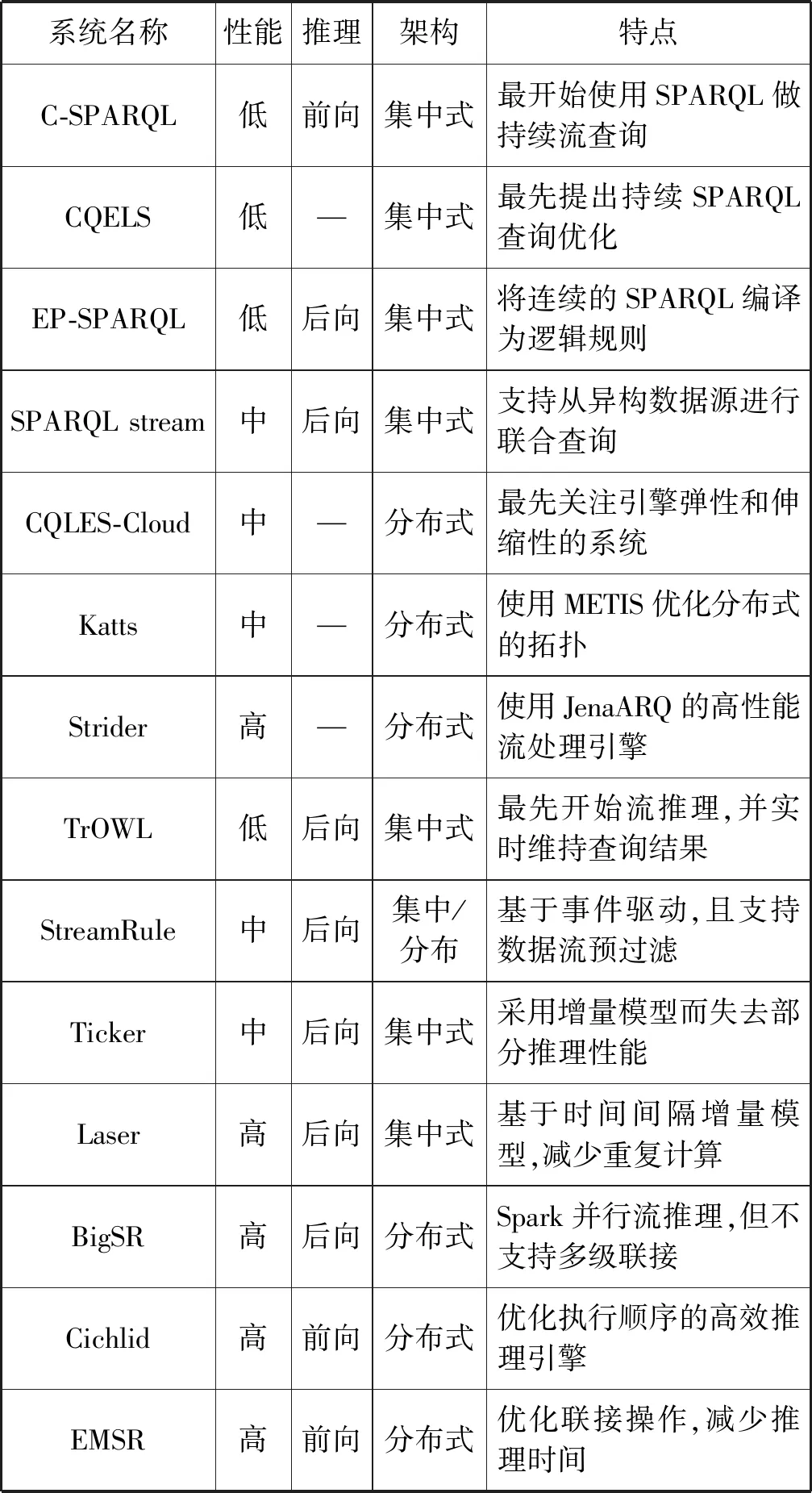
表2 RDF流处理引擎现状
2 基于CS及ECS索引的后向链式流推理
2.1 RDF流查询总体系统架构
如图1展示的是基于CS及ECS的RDF流查询的总体结构,本文在利用扩展特征集的基础上,加入了基于查询语句的语义数据流后向推理方案,描述了整个架构的设计,提出了ECS索引算法及查询过程中的图匹配算法,构建了一个高效的语义数据流后向查询引擎。本文共有三个核心模块,首先是加载新的RDF数据集并提取三元组特征集(CS)索引和扩展特征集(ECS)索引,其次是基于ECS索引的后向推理,最后是处理SPARQL查询并获取结果。

图1 RDF流查询总体架构
2.2 RDF数据载入
为了减少RDF数据内存占用,本节采用Triplebit[16]中的存储结构,将三元组作为连续的4字节大小的整数存储在内存中,其中每个三元组的主语、谓语和宾语分别被分配一个自增的不重复ID。在加载阶段,将每个三元组的结构设定为大小为4的向量,前三个向量分别对应主语、谓语和宾语的ID,最后一个位置指向其主语的CS索引,在数据载入阶段,都初始化为默认值-1,如图2所示。
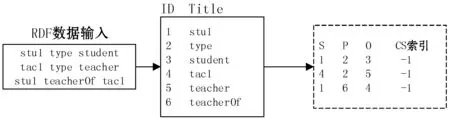
图2 数据载入
对每个RDF保留4个字节,并根据主语和CS索引进行排序,按照这种思路即使10亿个三元组也最多只需要4 GB的内存空间,因此在一定程度上减少了内存占用。另外,本文也按照ECS中数据载入的方法,将三元组中IRI前缀进行压缩,生成对应的映射词典,减少在后续操作中字符串解析的时间,并为最后输出的标识查询结果进行拼接,返回可读的字符串数据。
2.3 索引提取与建立
2.3.1CS索引
CS索引是特征集合[17],是表示从一组主语集合都拥有的一组公共属性p1,p2,…,pn,通过对数据集的三元组进行线性扫描,可以检索所有CS的集合[18]。首先按主语对三元组进行排序,并在主语中找到新的属性组合时构造新的CS,换句话说,当我们对具有同一主语的三元组进行遍历时,我们将聚合这些三元组的属性。并且当迭代继续进行时,对于下一个主语,我们对聚合属性的位图进行哈希处理,并检查其是否已经存在,如果没有,我们将使用这些属性创建一个新的CS,每个CS被分配一个唯一的整数标识符,并保存定义它的属性的位图,其中每个位对应于位图中是否存在此属性。在此迭代过程中,我们通过将三元组向量的第四个元素设置为分配给CS的整数标识符,根据主语节点的CS将三元组与CS关联,即图2中CS索引位置。
然后,我们按三元组的CS对其进行排序,将主语保留为第二排序键,并在SPO表中构造一个大的三元组表以进行一个查询周期的持续存储。CS索引在此表的顶部构造为B+树,其中的键由CS的ID定义,通过维护SPO表中每个CS的开始和结束索引,我们可以使用此索引来获取与特定CS相关的三元组。这样,CS索引可以根据对象的CS对所有三元组进行划分,并允许我们通过简单的范围扫描轻松评估给定节点或变量周围的属性。CS索引构造过程如图3所示。
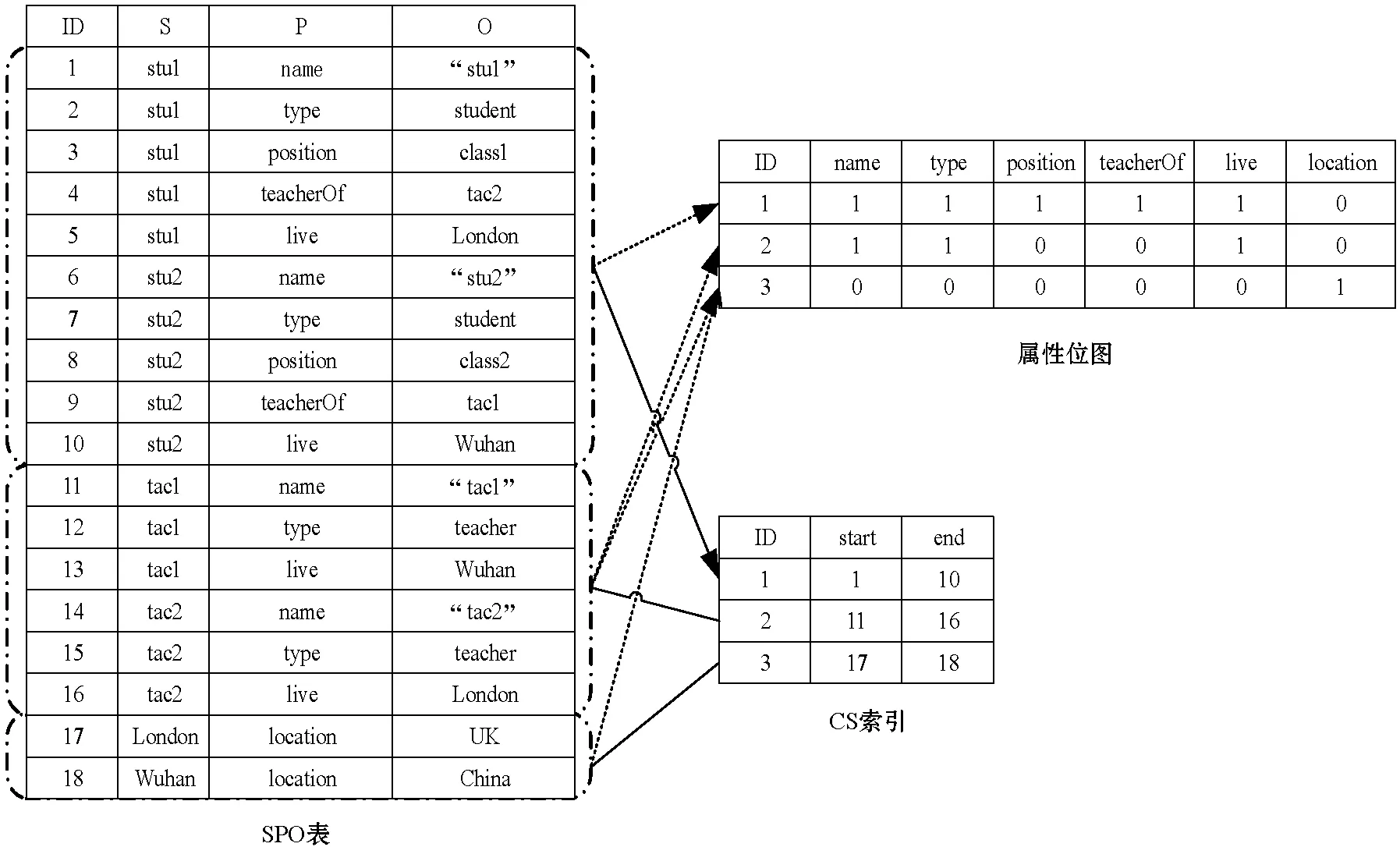
图3 CS索引构造过程
2.3.2ECS索引
ECS是扩展特征集,建立CS索引后,下一步是提取ECS,并建立ECS索引。提取ECS的一种简单方法是对整个数据集执行宾语和主语联接,扫描结果行,并为主语和宾语的CS的每种不同组合创建一个新的ECS,但是有一种更有效的方法是利用先前计算的CS索引。具体来说我们利用CS索引并遍历所有CS对,其中CS对是一组CS映射表,用于保存三元组的主语和宾语联接。如图3中的CS索引S1(ID为1)、S2(ID为2)和S3(ID为3),当S1、S2和S3的三元组之间的联接结果不为空时,我们将根据三元组主语的CS构造一个新的ECS,如S1和S2联接得到2个联接结果(stu1和tac2,stu2和tac1),S1和S3联接得到2个联接结果(stu1和London,stu2和Wuhan),S2和S3联接得到2个联接结果(tac1和Wuhan,tac2和London),总共表示6个新的ECS。
然后,我们可以存储ECS以及对其主语和宾语CS的ID标识符的引用,以及其中包含的三元组。与CS一样,每个ECS都分配有唯一的整数标识符。但是与CS索引对数据集中的所有三元组进行分区相比,ECS索引仅对与有效ECS有关的三元组进行分区,即其主语和宾语联接具有非空CS的三元组,这些是描述资源之间路径的三元组。我们将这些三元组存储为PSO表,并在此表的顶部将ECS索引构建为B+树,其中每个ECS定义了属于它的一系列连续三元组。图4所示为ECS索引结构。之后,获取特定ECS的三元组只需要对PSO表进行简单的范围扫描即可。事实上,PSO表的大小远小于SPO表的大小,因为后者包含所有三元组输入数据,而许多三元组不属于有效的ECS,这些要么是其宾语是带有文字描述表示的三元组,要么其节点是单一无相连的三元组,因此用空CS来描述。

图4 ECS索引结构
2.4 基于CS及ECS的后向推理
本节在CS及ECS索引的基础上,描述如何进行后向链式推理。为了便于理解,本文根据上述的RDF流数据建立了一个简单的查询语句,如图5所示,表示居住在同一个城市的两个人中,一个是学生一个是老师,并且是师生关系。

图5 查询语句示例
结合背景知识发现,学生的种类有很多,例如本科生和毕业生都是学生的子类,例如查询中的学生x;同理老师也有数学老师和化学老师等多种类型,如老师y。在进行查询的时候,需要将所有学生x和老师y的子类三元组全部包含进去,才是所有满足查询条件的三元组。因此,需要进行后向链式推理得到所有x和y的隐含信息。
推理的第一步是根据查询条件和背景知识进行反向迭代。背景知识中三元组的数量是相对较少的,其中定义了数据集各个实体和属性之间的关系,在LUBM数据集中约为170个。在查询条件{?x type student}下,根据规则9,满足条件{?s type ?t,?t subClassOf student}的三元组也是满足上述查询要求的,然后在背景知识中匹配是否有满足的实体t,如果存在则继续向上递归寻找。在进行向上寻找的过程中,可以根据条件直接筛选出满足条件的结果,但是本文并没有这么做,因为筛选出合适的结果需要遍历输入三元组,对于多次迭代这种开销是非常巨大的。本文采用了与前向推理相反的后向推理链,得到满足背景知识和查询条件的实体。其次是将满足查询条件和背景知识的实体进行合并。由于一个查询条件有多个满足的实体,例如本科生和毕业生都是学生的实体,因此需要将这些实体进行合并。根据之前关于特征集的介绍,特征集是关于一组具有相同谓语属性的RDF三元组,通过后向推理得到的实体必然也要具有同样的谓语属性,因此将推理得到的实体进行合并。后向推理过程如图6所示。
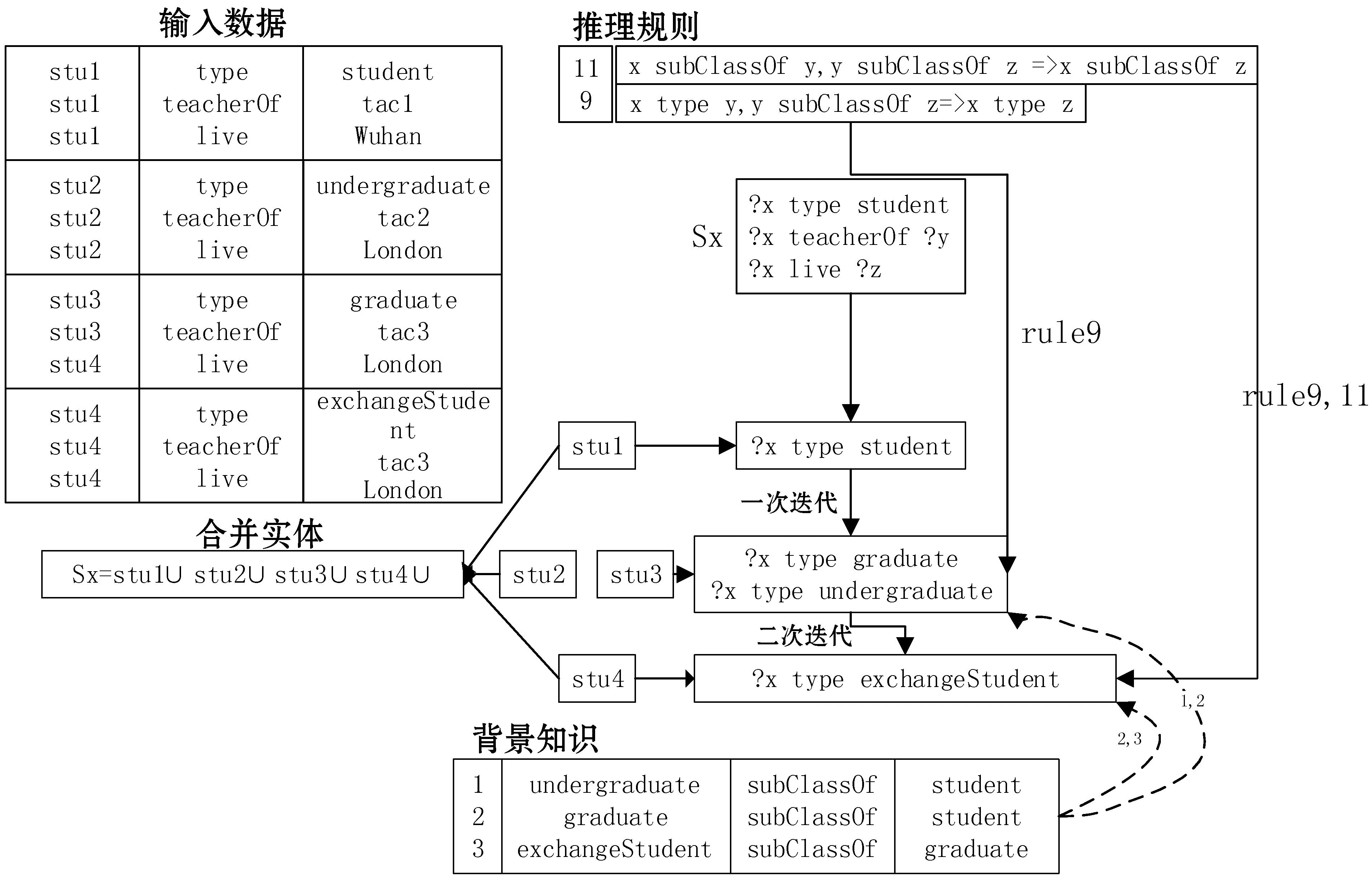
图6 后向链式推理
可以发现,每次的迭代是利用上层推理结果、背景知识和推理规则共同推理完成的。只将上层推理结果和背景知识作为推理的前项,而不遍历整个输入数据,一方面是因为这两个部分的数据量很小,迭代较快,减少性能开销,另一方面是因为可以利用CS索引结构的特点,如果知道三元组的谓语就可以快速得到所有满足该谓语的三元组。
2.5 查询处理
本节在ECS索引的基础上,描述如何进行RDF流查询。为了便于理解,本文根据上述的RDF流数据建立了一个如图5所示的简单的查询语句,表示居住在同一个城市的两个人中,一个是学生一个是老师,并且是师生关系。
本节将在这个查询的基础上,分别从查询语句解析和提取ECS查询图、ECS查询图和ECS索引的匹配、查询计划和执行三个步骤讲述RDF流查询的过程。
2.5.1查询解析和提取索引
首先,查询解析器会将传入的查询语句转换为ECS查询图。因此,第一步要提取查询节点的特征集CS,如2.3.1节中描述的CS索引建立方法,然后根据2.3.2节中ECS索引建立的方法,在查询模式下找到ECS,并在查询ECS之间创建邻接表。此过程与加载RDF流数据时的ECS提取相同,但是这次是对查询的三元组执行。确定了查询ECS及其之间的联接后,我们按它们出现的顺序遍历这些联接,以便在ECS查询图中标识这些联接链,即一系列宾语和主语的联接。因为查询语句和ECS索引中的数据都是非常少的,所以这个查询解析步骤效率很高。
查询解析过程如图7所示,根据图5的查询示例,首先将查询语句表示成BGP,如图7中的4个节点x、y、z、w表示查询语句中的未知参数,student和teacher表示已知的节点参数,节点与节点之间的边表示已知属性。通过BGP中的相连的未知节点和已知参数,转换成对应的CS索引图,在转换过程中,每个节点是由多个推理得到的实体合并而成,如图7中Sx、Sy和Sz表示对未知节点的CS索引。通过查询语句中的谓语需求和属性位图,将需要查询CS索引和CS索引表联立起来。

图7 查询解析过程
转换成CS图后,将相连的两个CS和有向边转换成一个ECS,例如Sx和Sy转换成Qxy;将CS中所有的节点转换成ECS后,相邻的ECS节点之间通过相同的CS索引进行联接操作,例如Qxy和Qxz之间,通过相同的Sx进行联接。根据ECS索引结构是由主语和宾语组成的,因此联接一般有以下几种情况,ss、so、os、oo,表示起始节点的主语或宾语和终止节点的主语和宾语相联接,例如os表示起始节点的宾语和终止节点的主语进行联接。ECS索引算法如算法1所示。
算法1ECS索引算法设计
输入:Feature set CS and triples mapping table CSMap。
输出:Extended feature set ECS and Adjacency lists between ECS ecsLinks。
begin
var ecsMap=Map
var subjectCSMap=Map
var objectCSMap=Map
for(SiinCSMap)
for(SjinCSMap)
if(triples.size()>0)
ecs=newECS(Si,Sj)
ecsMap.put(ecs,sort(triples))
subjectCSMap.get(Si).add(ecs)
objectCSMap.get(Sj).add(ecs)
ecsLinks=newMap()
for(Si in objectCSMap.keys)
if(Si ∉ subjectCSMap.keys)
continue
for(ECSleftinobjectCSMap.get(Si))
for(ECSrightinsubjectCSMap.get(Si))
ecsLinks.get(ECSleft).add(ECSright)
returnecsMap, ecsLinks
end
2.5.2ECS查询图和ECS索引匹配
从图7中可以看出,每一个查询ECS即图中的Qxy等,都可以与ECS索引中的0到多个ECS匹配,因此对于查询ECS和ECS索引之间必然存在一个匹配机制,我们用Query={CSqleft,CSqright}表示一个查询ECS,用Ecs={CSleft,CSright}表示一个ECS索引,其中参数CS都表示组成ECS的两个CS索引,则式(1)必然成立。
CSqleft⊆CSleft,CSqright⊆CSright
(1)
并且对于组成查询ECS和ECS索引的主语和宾语的CS,其属性位图必然也存在对应的关系。例如查询语句中对于x变量需要3个属性type、live和teacherOf,但是在属性位图3中,该CS是拥有5个属性的,并且包含需要查询的3个,因此有:
pQ⊆pE
(2)
在此基础上,制定了对查询Query的评估方法,对于所有满足该查询的ECS的三元组,用m(Query)表示,tp(En)表示与该ECS有关的所有三元组,则评估如下:
Query=tp(E1)∪tp(E2)∪…∪tp(En),Ei∈m(Query)
(3)
通过对ECS图进行深度优先遍历,可以将查询ECS与ECS索引进行匹配。本文在带有ECS图的邻接列表上进行迭代,并以每个ECS为起点,搜索匹配的ECS。图模式匹配算法通过递归实现,如算法2所示。
算法2ECS图模式匹配算法
输入:Adjacency lists between ECS ecsLinks, A chain of query ECSs c(q0…qn-1)。
输出:A linked list of ECS sets that match the ECSs ecsMatches。
begin
var ecsMatches=Map
for(einecsLinks.keySet())
matchData(e, ecsLinks, c(q0…qn-1), ecsMatches)
returnecsMatches
matchData(e, ecsLinks, c(q0…qn-1), ecsMatches)
begin
if(q0.subjectCS.bitmape.subjectCS.bitmap OR
q0.property∉e.properties)
returnnull
if(visited(e) OR c.size==1)
returnecsMatches
visited.add(e)
ecsMatches.get(q0).add(e)
forechildin ecsLinks.get(e)
matchData(echild, ecsLinks, c(q0…qn-1), ecsMatches)
end
end
通过在ECS图上执行深度优先遍历,可以确保查询中连续匹配的ECS已链接到数据中,此过程的输出是ECS索引中与ECS查询链匹配的一组ECS链。
在图7的示例中,定义了3个查询ECS,分别是Qxy、Qxz和Qyz,该算法会将E1(ID为1的ECS索引)匹配到对应的Qxy,因为E1是其子集,表示所有x是y的学生的关系;其次,将E2匹配到Qxz,表示所有学生x居住在地点z的关系;最后将E3匹配到Qyz,表示所有老师y居住在地点z的关系。
2.5.3查询计划和执行
查询计划为匹配ECS链相对应的三元组的各个集合决定联接执行顺序,查询计划根据查询链有两种排序策略,第一种是根据不同查询链之间的公共属性,尽早滤除无关三元组,称为外部排序;第二种是根据特定查询链减少ECS之间的宾语和主语联接的中间结果,这些中间结果对最终结果无关,称为内部排序。首先为了获取整个查询链的外部排序,需要根据链中的每一个项的执行成本进行计算,让整个查询链的成本最小。一般情况下根据升序成本对链进行排序,即对于链中任何一项都有如下状态:
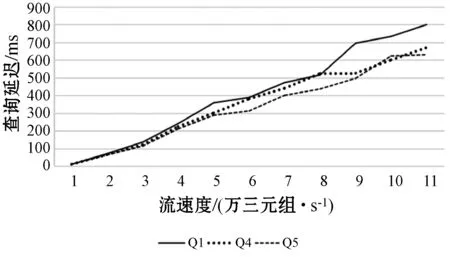
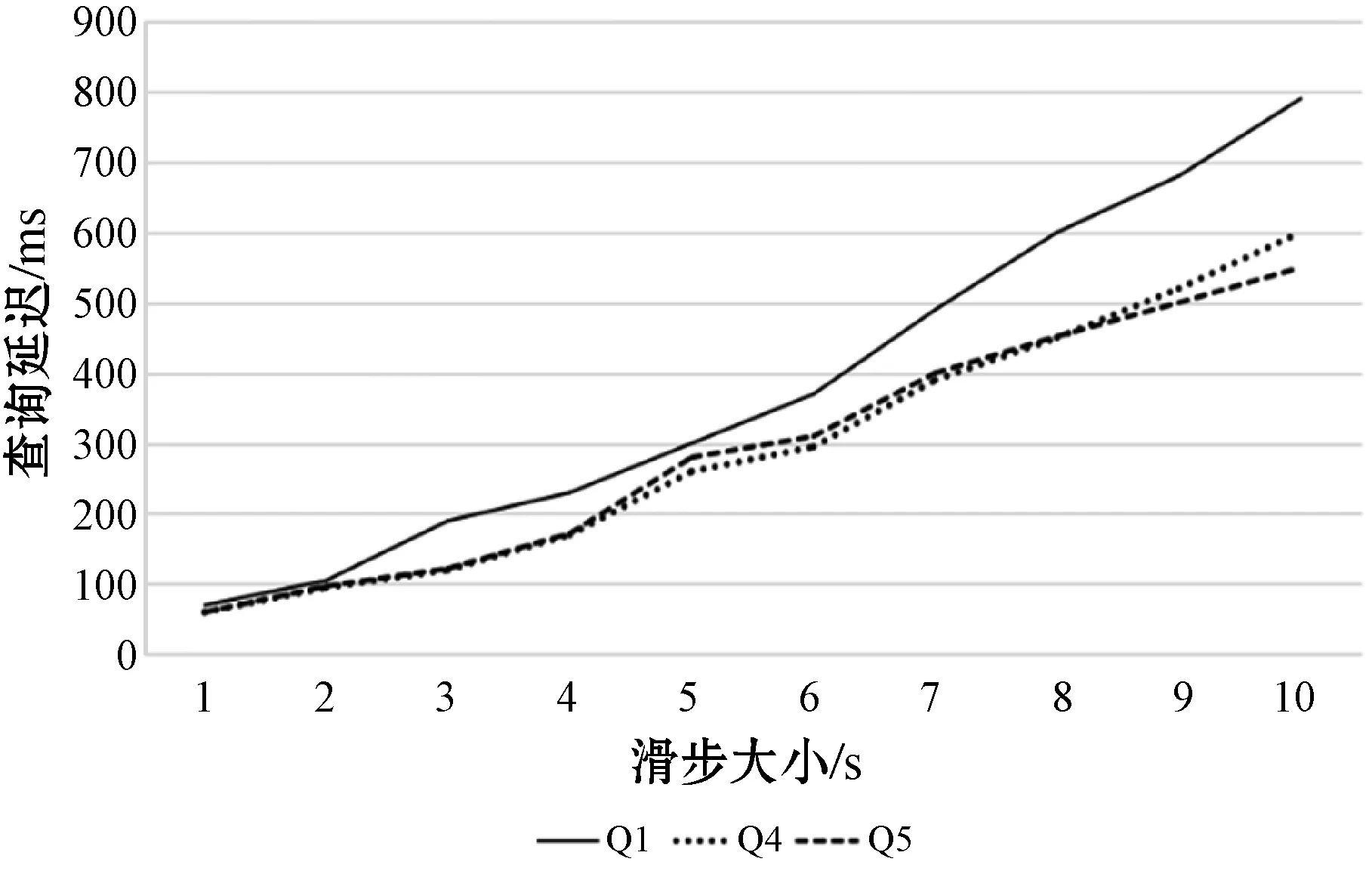
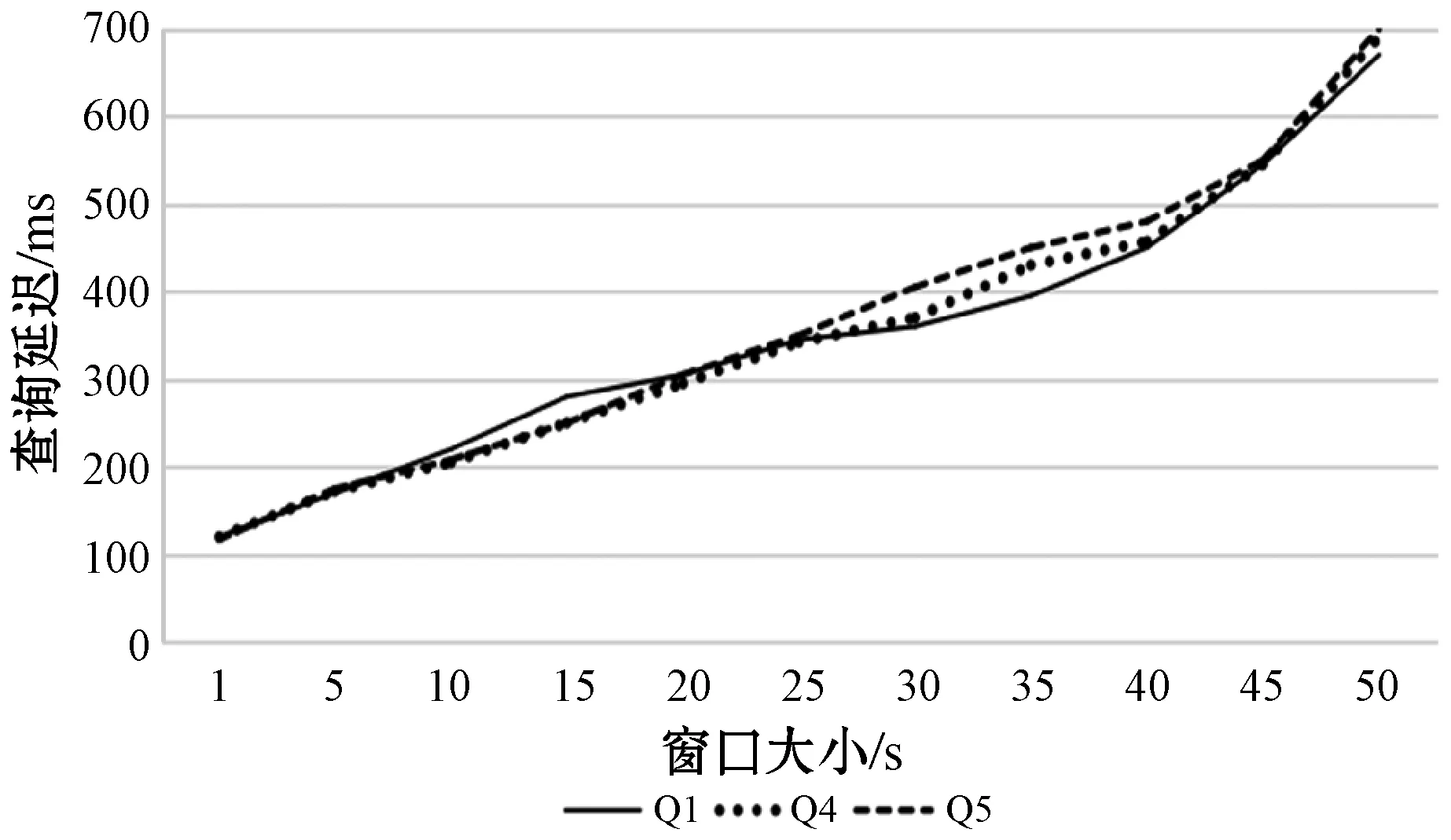
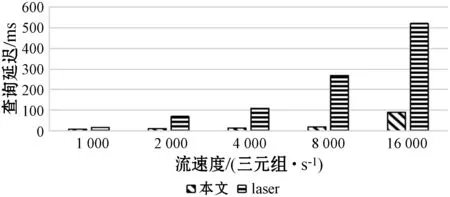
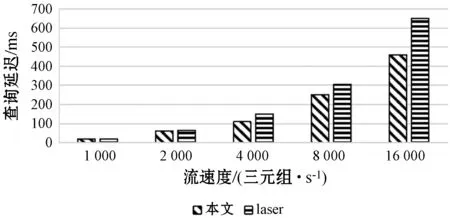
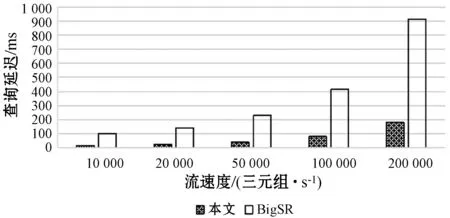
St=Orderi (4) 根据式(4)可以通过链中每一项的成本得到排序结果,对于每一项的成本,根据式(1)所示的每一个查询都可能有约束条件,定义了如下对成本的评估规则,对于查询中没有约束条件的,如图7中的Qxy,其成本是查询其所有三元组的成本,如式(3)所示,查询Query的评估方法是与该ECS有关的所有三元组,因此其成本就是查询所有三元组的查询成本,进一步地,一个查询Query的成本公式如下: (5) 对于查询中有一个或者两个约束条件的,例如Qxy有一个,而Qyz有两个,其成本为固定值1。对于链中连续的ECS相互联接的成本,本文利用递归的方式定义了如下方法: cost(chain1~n)=cost(chain1~n-1)×fos(Queryn) (6) 式中:fos(Queryn)是第n个查询进行os联接的乘数。递归开始的首项是由一个ECS组成的链,其成本为该ECS的成本;对于一个Query={CSleft,CSright},其中:CSleft表示主语特征集;CSright表示宾语特征集。其乘数fos取决于其宾语和主语联接操作产生的联接数据行数,并且定义为Query中每个主语的不同宾语的比率,因此fos(Query)的计算公式如下: fos(Query)=|OQuery|/|SQuery| (7) 式中:OQuery表示查询Query中的宾语特征集CSright的不同主语个数,SQuery表示查询Query中的主语特征集CSleft的不同主语个数。通常递归函数开销都比较大,之所以采用这种评估标准的依据是因为第一个ECS的绑定的三元组都远小于数据集,因此递归成本很小。 为了获得内部排序,本文考虑到链中的所有ECS都通过宾语和主语联接链的,可以向左或向右一次扩展一个ECS的现有节点或子链。基于此,本文采用一种简单的试探法,该试探法从成本最低的ECS开始,并从左或右选择成本最小的ECS来扩展链。虽然其他方法使用动态规划算法来根据所采用的统计信息找到最佳的连接顺序,以减少中间结果,但在图模式匹配阶段已经执行了大量的三元组过滤,因此,顺序不会严重影响查询处理器的性能。 通过外部排序和内部排序可以很明确地找到一条成本最小的执行计划。通过查询ECS索引并加入匹配链的每个ECS的三元组,可以单独执行每个查询链。在执行的最后步骤中,使用公共属性的散列联接来联接多个查询链,并且在评估单个链时动态创建联接表。当从内存中检索ECS时,将来自于ECS的三元组和来自于CS的三元组之间执行合并联接,可以实现ECS的主语和宾语的属性的检索,获取所有主语和宾语后,即可获取对应的联接结果。 实验代码基于Java8,数据集使用的是标准LUBM。实验使用的操作系统是Windows 10,CPU是Intel(R) Core(TM) i7-6700U,主频3.40 GHz,内存16 GB。实验采用LUBM标准数据集,并从流数据大小、传入窗口大小和滑步大小几个方面测试系统的整体性能,主要测试整个查询的延迟及单位时间内处理查询的数量。 针对整个后向链式查询,本文将与目前比较流行的基于后向链式推理的Laser和BigSR做对比实验,后向推理过程是和查询语句相关联的,因此本文设计在推理结果相同的前提下,对比整个系统延迟。查询语句中,Q1用来查询少量的直接关联实体;Q2用来查询大量的直接关联实体;Q3用来查询间接关联实体;Q4用来查询大量的需要推理的实体;Q5用来查询少量的需要推理的实体。 流数据大小对该策略的影响如图8所示,其中窗口大小和滑步大小都是1 s,可以发现,随着流数据的增大,系统的延迟和吞吐量也相应增大,整个系统的推理性能会逐渐降低,这也体现了本文在处理瞬时数据流极大的情况会存在一定的缺陷。 图8 流速度变化 如图9所示的滑步大小对该策略的影响,其中窗口大小和滑步大小保持一致,流数据每秒2万,从结果可以发现,随着滑步逐渐增大,系统的延迟和吞吐量也相应增大,与图8结果很相似,对于处理滑步极大的情况在存在一定的缺陷。 图9 滑步大小变化 窗口大小对该策略的影响如图10所示,其中滑步为1 s,流数据每秒10万,可以发现,随着窗口的逐渐增大,系统的吞吐量呈线性增大,但是延迟却增幅很小,平均每增大50万吞吐量,延迟增大60 ms,并且在上述条件下,极限性能能达到接近500万三元组每秒的吞吐量。 图10 窗口大小变化 综上所述,本文提出的后向流处理系统在处理瞬时数据流特别大的情况下存在一定的性能缺陷,例如每秒都会产生百万流数据并且需要在短时间得到查询结果的场景;但是需要处理窗口很大,但是滑步很小的场景,比如城市交通监管、天气检测等一段时间内的实时监测系统,本文有很大优势。 由于Laser目前没有合适的公共数据集作测试,因此本文采用了与Laser相同的数据生成器作为数据流。本文设计的查询语句主要测试数据联接的性能,这也是Laser架构中性能比较出众的一个。实验分为了两组,分别是窗口大小为1 s和5 s,流数据相同并逐渐增大,实验结果如下。从图11和图12的实验结果可以看出,在窗口为1时,本文的后向推理的性能更高,随着数据流的增大,查询延迟也在增加,但是增幅不大。在窗口为5时,本文方法相对而言延迟增幅较大,但是仍然比Laser有一定的优势,上升的主要原因是数据流只有一个特征集,因此进行联接操作会产生大量的耗时,也从另一个方面说明了,对于查询特征集单一的查询语句,本文方法在数据大的时候延迟上升加快。综上所述,本文的后向推理方案在对比Laser在窗口和滑步相同时,有着很大的性能优势;但是随着窗口的增大,本文方法性能下降相对较快,是因为Laser采用了基于时间段增量模型来减少重复计算。 图11 窗口为1时对比结果 图12 窗口为5时对比结果 在与BigSR的对比实验中,因为BigSR不支持多级联接,因此本文设计了相对应的多组查询,并选取了其中一个有代表性查询Q3的结果进行了对比。本文根据目前提出的方法设计了流速度和窗口大小作为主要的变量指标,分别为保持窗口大小为1不变,改变流速度和保持流速度为1万个三元组不变,改变窗口大小,并将查询延迟和吞吐量作为主要的衡量指标。 从图13中的实验结果可以发现,在窗口不变时,随着流速度的增大,吞吐量也增大,同时查询延迟也增大,增幅与BigSR的增幅类似,基本呈线性增长,主要是因为目前的并行推理机还存在一定的优化空间。从图14中的实验结果可以发现,在流速度不变时,随着窗口的增大,BigSR的查询延迟也呈线性增长,但是本文方法并没有明显上升,是因为本文提出的基于后向链式的流推理极大程度地减少了无关结果,并且本文的扩展特征集在数量联接数量较少时,其性能非常高。 图13 流速度变化对比结果 图14 窗口变化对比结果 本文针对现有的后向链式流推理在查询数据效率低的问题,通过有效地利用CS和ECS索引,并结合查询语句提出一个高效的后向链式流推理方法。首先描述了整个架构图;其次详细描述了CS索引和ECS索引的提取和建立过程;然后根据查询语句建立查询ECS图,通过图匹配算法将查询ECS图和ECS索引联接起来获取查询ECS链;进一步根据ECS查询链中每个ECS的成本使用递归策略得到最小成本执行计划。并和Laser、BigSR进行了对比实验,实验表明本文方法有一定的性能优势,但是仍然存在一些不足,例如大规模RDF流的CS及ECS构建效率问题。另外,本文在与Laser的对比实验中,在窗口逐渐增大时,其性能降低相对较快,而Laser则比较平稳,因此下一步可以考虑将Laser中减少重复计算的增模型相结合,进一步提升后向推理的性能。3 实验与结果分析
3.1 实验配置
3.2 实验场景设置
3.3 实验结果分析

4 结 语
