基于文献计量的多种热点识别方法研究
2023-10-09张茜晴
张茜晴
(厦门医学院图书馆,福建 厦门 361001)
1 引言
研究热点(Hot Topic)这一概念由普赖斯(Price)在1965年提出,是指在某段时间段内有突出发展潜力的研究主题。科技文献呈现出指数级增长的趋势,有针对性地挖掘科技信息中的有效情报,快速了解研究领域的热点话题,有助于把握研究动向,节约科研成本。文献计量学是在对大量文献进行定量化研究需求的基础上应运而生的,利用文献计量手段识别研究领域热点,分析主题演进已成为研究主题分析的基本方法。目前,经过较长时间的探索与发展已形成多种基于文献计量的热点识别方法。
早期关于热点识别的研究多集中在西方国家,20世纪90年代起逐渐受到我国学者的关注、研究与应用,并产生了丰硕的研究成果。笔者在调研国内相关文献中的各个分析环节指标的基础上进行研究,旨在梳理基于文献计量的热点识别方法及分析路径,比较不同方法的特征,以期为研究人员提供借鉴和参考。
2 文献回顾
研究热点通常源于某时间段研究领域内受到广泛关注的研究话题或进展,且常伴随着文献发表数量增加、某些主题词数量及涨幅突增、引文网络突变等计量学特征。针对这些计量指标,衍生出多种识别研究热点的方法和技术。关键词作为最能表征文献主题内容的要素之一,将其用于分析识别领域热点由来已久,例如词频分析、共词分析等方法。另外,文献之间的引证关系可以理解为是科学对话的一种形式,基于引文的研究可定量分析科学研究的传播途径和发展脉络,对主题发展和热点趋势都有重要的揭示作用。同时,以文献数据之间的内在关联为纽带,借助计算机图像处理技术将数据转换成图像并进行交互处理的新兴可视化技术为研究热点的识别和呈现提供了更加多样且灵活的途径。通过对国内外相关文献进行梳理和分析,热点识别方法研究可分为以下几类。
2.1 基于词汇的热点识别
2.1.1 基于词频的热点识别
词频分析以词汇为分析对象,词汇作为表达文献主题内容的最小单位,因其概括性、统计性、链接性等特性,常用于研究热点的识别[1]。词频分析法由Luhn于1958年首次提出并应用于自动文摘的研究,该方法基于研究内容的集中与分散性可由关键词的频次与个数的关系加以判断这一原理,研究内容的集中性越强,则表征该内容的关键词所代表的内容在该领域越可能起关键作用[2]。除了以词频累积数量为分析依据外,2002年Kleinberg提出了一种突破监测算法,在分析词频时考虑其变化密度,从而识别文献中具有高密度特性的词,即有突然增长特性的词[3]。
2.1.2 基于词共现的热点识别
通常,一个研究主题包含不止一两个词汇,相互关联的一系列词汇凝聚在一起能更全面地表征主题。共词分析法即为典型代表。该方法由法国文献计量学家在20世纪70年代中后期提出,以文献计量和统计聚类为研究手段,按照词间的紧密程度对共同出现的词进行聚类,为定量分析大数据量的文献信息,探究知识演化、热点话题和学科演进提供了一种新的思路[4]。此外,在共词分析的基础上,利用各种统计学分析方法,结合可视化软件,可将研究热点更加直观地展现出来。如,徐晓华等人利用共词聚类和多维尺度分析方法对艾滋病预防医学领域的文献进行分析,获得了2013—2015年的4大热点研究领域[5];周丽英等人以SCI收录的3种国际植物营养学期刊为数据源,将共词分析与社会网络分析方法相结合进行了主题领域划分,并研究各领域的发展变化趋势[6]。
2.2 基于引文的热点识别
Small将引文关系划分为文献耦合(Bibliographic Coupling)、文献同被引(Co-catation)以及直接引用(Direct Citation)这3种类型。文献耦合分析由麻省理工学院的Kessler教授于1963年提出,其原理是两篇及两篇以上的文献因引用同一篇文献可发生互相关联[7],共同引用的文献越多,说明这几篇施引文献之间的联系越为紧密。以此理念为基础,肖明等人以引文耦合为分析方法,在国内首次探讨了学科结构和知识基础,并辅以可视化工具描绘了数字图书馆领域具有相同主题的文献间关系[8]。同被引分析由美国情报学家Small于1973年提出,反映的是被引证文献之间的关系,他采用同被引的分析方法,对有机薄膜晶体管领域进行了分析,并揭示了该领域主题演化过程中的发展、消亡过程[9]。引文关系的最后一种类型直接引用则是文献引用的一种基本形态,在对文献进行直接引用分析时无需厘清他们之间的耦合或同被引关系[10]。
已有研究采用不同的研究方法对各研究领域的热点话题进行识别和展现,为当前研究提供了重要的参考。识别方法的多样性和灵活性在为主题研究提供多种途径的同时,也带来不同方法在过程分析和结果展现方面的差异以及方法选择上的困惑。目前国内尚缺乏较为全面的研究,因此,笔者采用内容分析法,通过文献调研梳理出现有研究中较为常用的热点识别方法,并从各流程角度比较不同方法之间的差异。
3 热点识别方法应用研究调查
3.1 相关文献获取
笔者主要采用内容分析法,以中国知网(CNKI)数据库中收录的CSSCI、中文核心以及CSCD索引的期刊为数据来源,以“研究热点”为检索词在题名中进行检索,又以“SU='研究热点'ANDSU='文献计量'”为检索式在CNKI全文数据库中进行检索,剔除重复文献后共获取2059篇相关文献,经过快速阅读文献题录信息,删除与本研究无关的文献共556条,最后纳入内容分析的样本文献1211条。
3.2 调研过程
笔者以热点识别过程的每一个环节为分析要素,共构建文献调研指标4个,分别为数据来源、计量要素、计量方法以及热点呈现方法与采用工具。其中,数据来源是指该篇文献所研究的目标文献来源;计量要素是指该篇文献依据何种文献要素进行研究热点的识别;计量方法是指该文献采用何种计量方法进行研究热点的识别;热点呈现方法与采用工具即该文献将分析出的研究热点以何种形式呈现,以及采用了何种工具对研究热点进行可视化表达。
3.2.1 数据来源统计结果
按照热点识别所依据的论文要素,将调研指标分为基于词汇的热点识别文献和基于引文的热点识别文献两部分分别进行指标统计结果的解读,数据来源见图1,从上图可见,CNKI是以词汇进行热点识别文献分析对象的主要来源,占比高达49%,其次是科睿唯安的Web of Science(WoS)数据库和中文CSSCI索引,占比分别为28%和12%。下图所示基于引文进行热点识别的文献分析对象来源中,Web of Science数据库占比最大,高达75%,其次是CNKI以及CSSCI来源文献。
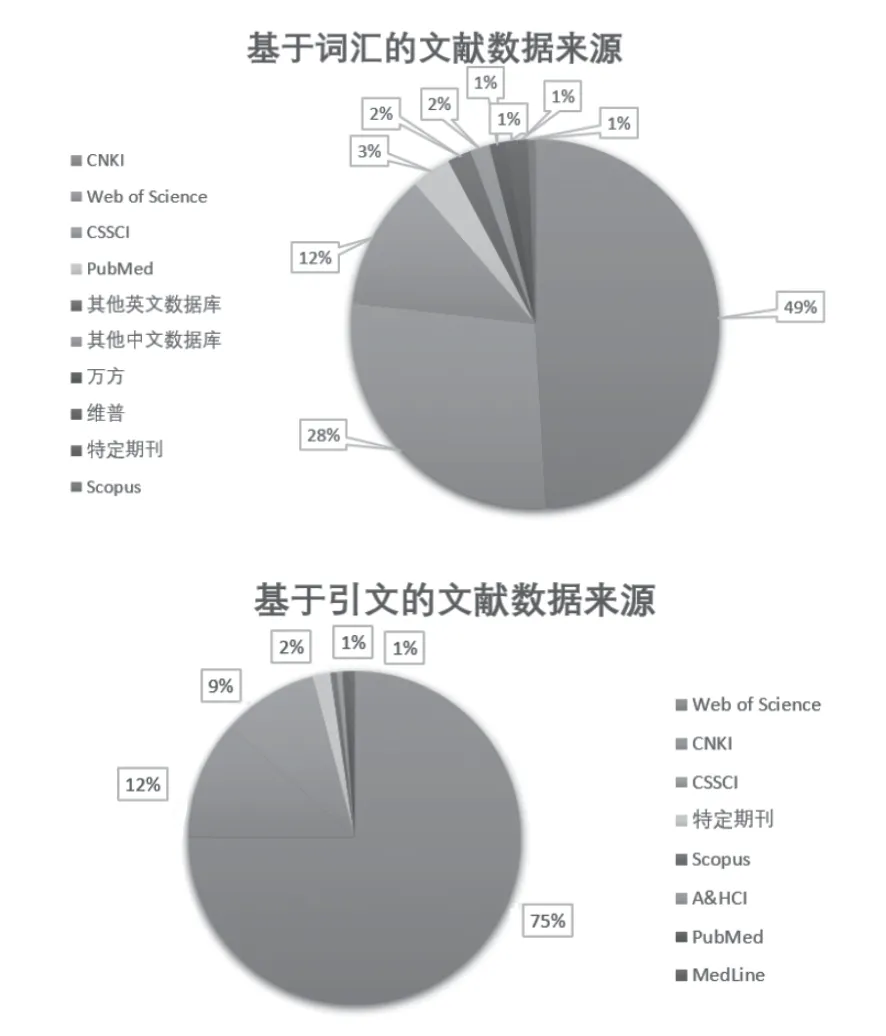
图1 调研结果——数据来源统计
3.2.2 识别方法统计结果
笔者将全部调研样本分为基于词汇的识别方法与基于引文关系的识别方法两类,其中,基于词汇的识别方法又可分为基于词频和基于词共现两种,基于引文关系的识别方法又可分为基于高被引文献和基于文献共被引的分析方法两种,具体到每一种方法的使用情况详见表1。
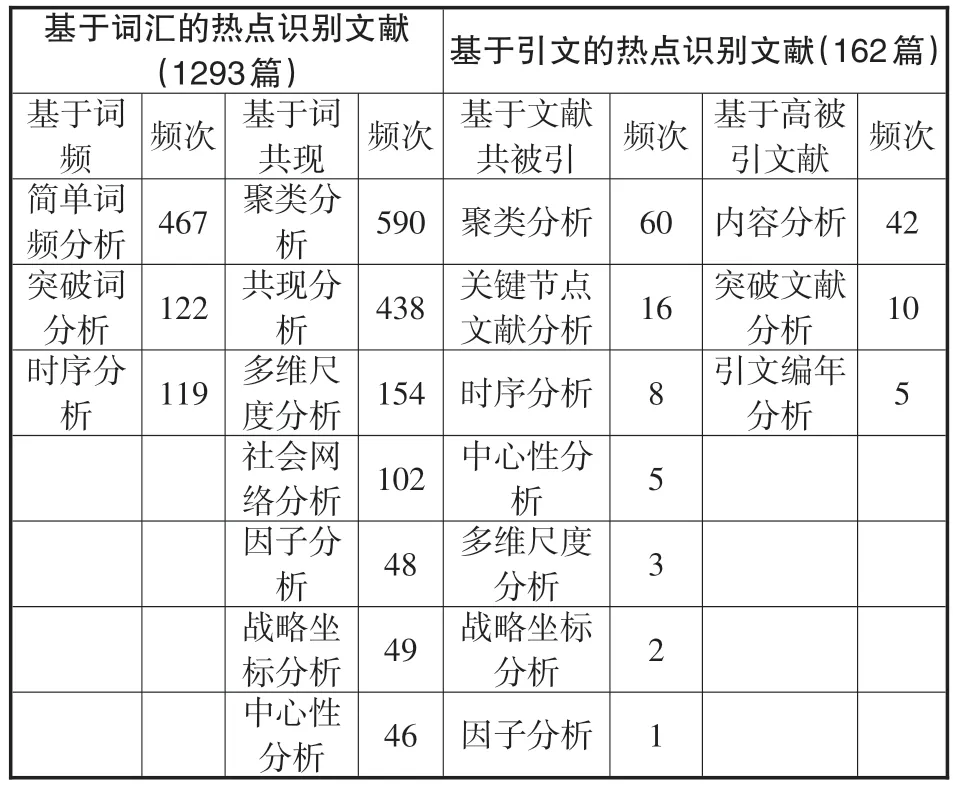
表1 调研结果——方法统计
3.3 基于调研样本的热点识别路径剖析
基于本研究调研的全部文献,建立起“文献来源—分析要素—计量方法—分析工具”的一一对应关系,从多维度剖析当前常用研究热点的分析路径,如图2所示。图2中圈的大小表示使用频次的高低,如,就“文献来源”这一指标来看,WoS及CNKI是目前国内进行热点识别研究中使用频次最高的数据库;就“分析要素”指标来看,基于词汇的分析方法使用频次要高于基于引文的分析方法;就“计量方法”指标来看,基于词共现的计量方法使用频次最高,而基于文献共被引的计量方法则是引文分析中最常用的。图2中连线的粗细表示共现频次的高低,例如,在以CNKI为文献来源的热点识别文献中,基于词汇的分析方法使用频次要远高于基于引文的分析方法,以WOS为文献来源的文献中,基于词汇与基于引文的分析方法使用频次相差不大;在基于词汇的分析方法中,词频分析与词共现分析的使用频次都较高,而基于引文的分析方法中,文献共被引分析的使用频次则远高于基于高被引文献及基于关键节点文献的使用频次;在基于词共现的分析方法中,聚类分析、多维尺度分析及共词分析的使用频次较高,在基于文献共被引分析方法中,聚类分析、内容分析、时序分析等使用频次较高;聚类分析以SPSS及CiteSpace为主要分析工具,共词分析则主要依靠CiteSpace、SPSS及Ucinet等分析工具。
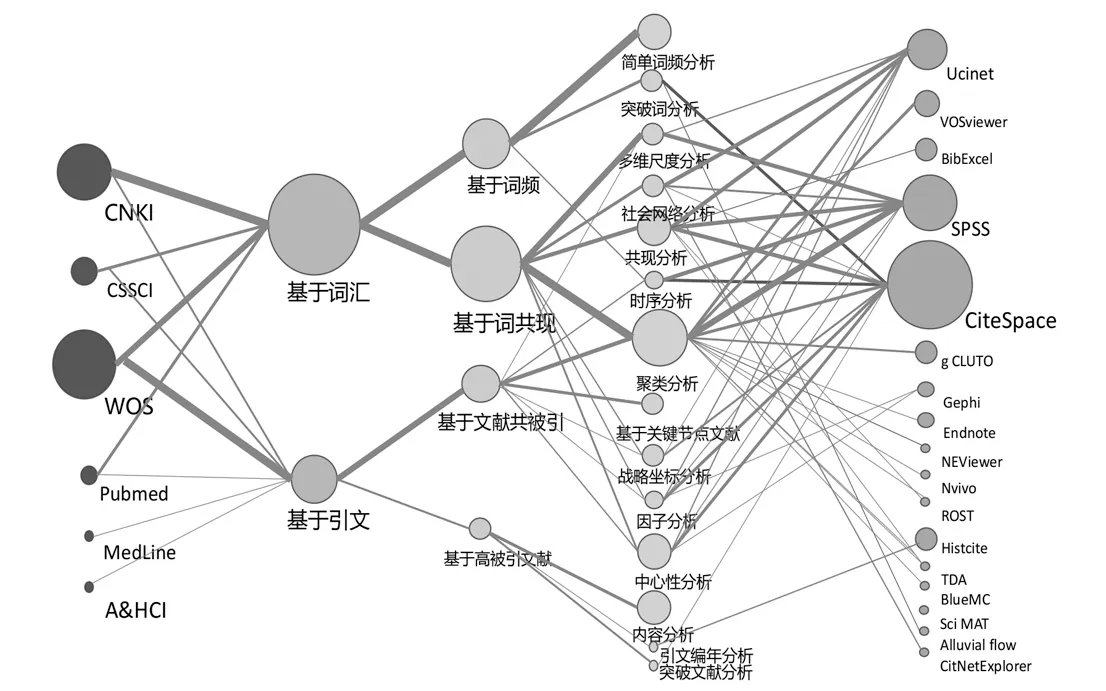
图2 研究热点识别路径
4 基于调研结果的常用热点识别方法分析
4.1 基于词频的热点分析方法
在全部调研样本中,基于词频的分析方法共使用708次,其中,简单词频分析法,即单纯累计关键词或主题词出现频次来判断研究热点的文献有467篇;另外,突现词分析方法共使用122次,该方法利用Kleinberg的突现词算法,借助CiteSpace可视化分析软件可运行计算得出某段时间内具有高突现率的关键词,通过分析这些关键词所表达的研究主题,从而获取该时间段内的研究热点;除了简单词频及突现词分析法,还有119篇文献使用了时序分析方法,利用分析软件对文献进行处理绘制主题热点演变时区视图,以时间线为横轴,以热点关键词节点之间的连线表达研究热点的演变。
4.2 基于词共现的热点分析方法
笔者通过内容分析对全部调研样本进行了细化分析,基于词共现分析方法共使用1427次(由于一篇文献可使用多种分析方法,因此分析方法的使用总次数可能大于调研样本数)。具体到每一种方法,聚类分析使用频次最高,达590次,聚类分析是一种研究“物以类聚”的多元统计方法[11],根据关键词(主题词)之间关联强度的大小聚集成簇,把联系紧密、代表相似主题的关键词聚集在一起,从而达到分析热点话题、研究趋势的目的。聚类分析通常需要借助分析工具来完成,调研样本中聚类分析常使用的工具有SPSS(251次)、CiteSpace(202次)、Bibcomb(36次)、Ucinet(33次)、VOSviewer(31次)等。SPSS(Statistical Package of the Social Science)是目前社会科学领域使用最广泛的一套模块化的统计分析软件,功能包括因子分析、回归分析、相关分析、聚类分析等;CiteSpace是在科学计量学、数据可视化背景下逐渐发展起来的引文可视化图谱软件,以可视化手段呈现科学知识结构、规律和分布情况[12]。共现分析方法共使用438次,这种研究方法以关键词共现网络图谱锁定核心研究领域[13],结合关键词词频统计及关键词之间的共现关系厘清研究热点,以CiteSpace的共现图谱为例,每个节点代表一个研究热点,节点的大小表示该关键词出现的频次高低,节点越大则话题越热,节点之间的连线表示热点之间的共现情况,连线越粗则热点间关联越紧密。在共词分析中,分析软件的使用频次依次为:CiteSpace(211次)、Ucinet(92次)、SPSS(26次)等。多维尺度分析方法使用频次为154次,主要借助软件SPSS(107次)以及Ucinet(6次)。该方法将观测对象定位到二维或三维空间中一个特定位置,通过测定观测量之间的距离发现各观测量之间的结构[14]。社会网络分析方法(SNA)的使用频次为102次,它是一种社会学的研究方法,与统计学和心理学等学科联系紧密[15],常用的分析工具分别为Ucinet(78次)、SPSS(10次)、CiNetExplorer(3次)、CiteSpace(1次)以及Thomson Data Analyzer(1次)。战略坐标分析方法使用频次为49次,该方法是一个二维坐标图,横轴代表向心度(Centrality),纵轴代表密度(Density),使用这两个指标衡量主题类团内部的发展状况和类团之间的互相影响状况[16],调研样本中使用的工具主要包括SPSS(22次)、CiteSpace(4次)、Ucinet(1)次。因子分析方法共使用48次,这是将多个实测变量转换为几个不相关的综合指标的一种多元分析方法[17],通过分析多个原始变量,找出对原始变量有潜在支配作用、数量相对较少的因子[14]。调研样本中在进行因子分析时主要使用SPSS(32次)、Ucinet(2次)等。中心性分析方法的使用次数为46次,中心性是指一个点在网络中居于核心地位的程度,是判定网络中节点重要性的指标,调研样本中中心性分析的工具主要包括CiteSpace(23次)、Ucinet(7次)、SPSS(6次)和Gephi(1次)。
4.3 基于引文的热点分析方法
基于引文的热点分析方法以引文类型的不同分为两类,首先是基于文献共被引的分析方法,文献共被引分析是Citespace最具特色的功能,利用Citespace对文献进行共引分析可以提炼该领域的知识基础、研究热点以及新兴趋势[18]。在调研样本文献中,基于文献共被引的分析方法共使用77次,其中,聚类分析使用60次,通过对共现网络进行聚类,可将文献根据研究内容的相似程度划分到不同的聚类中进行分门别类分析,分析工具为Citespace(39次)、VOSviewer(1次);关键节点文献分析是对网络中的关键节点的文献进行内容分析,借此了解领域研究热点,在调研样本中共使用16次;时序分析的视图显示方式能突出共引网络节点随时间变化的结构关系[19],在调研样本中共使用8次;中心性分析通过分析一篇文献在共引网络中与其他文献连接的紧密程度,从而判断其核心程度,中心性越高的文献,其在网络中的影响力越大,调研样本中中心性分析共使用5次,分析工具均为Citespace;多维尺度分析方法使用3次;战略坐标分析方法使用两次。除了基于文献共被引的分析方法外,高被引论文作为被引用频次最高的那部分文献,往往具有较高的影响力,且数量较少的论文较大程度覆盖了某一研究领域的热点主题,调研样本中基于高被引论文进行的分析共使用57次,其中,对高被引论文的内容进行阅读分析研究热点的方法使用42次;另外,与突破词分析类似,Citespace同样可对在某一时间段内引用频次突增的文献进行探测,具有高突破性的文献所反映的内容在某段时间内受到了较多关注,因此,突破文献分析可快速了解某领域学者们所共同关注的话题,找到研究热点,这种分析方法使用了10次;最后,引文编年分析是利用HistCite软件进行的一种基于高被引论文的分析方法,可直观得到引文之间引用与被引的关系,从而反映文献间的关联[20],样本文献中该方法的使用频次为5次。
5 结论
笔者对国内有关热点识别共1211篇研究文献进行内容分析,建立各个分析环节的调研字段,通过对调研结果的统计分析,梳理出使用频次高且具有代表性的热点识别分析路径,得出以下结论。
(1)文献计量方法是识别研究热点最主要的分析方法,且基于文献计量的热点分析方法呈现多样化趋势,可分为基于词汇的分析方法和基于引文的分析方法两大类。其中,基于词汇的分析方法以能表征研究主题的词汇为对象、以词频或词间共现关系为基础,具有分析数据易获取、分析方法简单多样、分析工具种类多等特点,其使用率远高于基于引文的方法,在调研样本中的文献占比约为88.8%;基于引文的分析方法由于对数据库提供的可计量数据有较高要求、分析过程中算法较为复杂、分析工具单一(绝大多数使用CiteSpace),且对分析工具的依赖性较大,因此使用频次较小,在调研样本中的文献占比仅为11.2%。
(2)借助可视化分析软件进行热点识别是目前国内应用研究的主要趋势。调研样本中65.7%的文献借助可视化软件进行研究热点的识别与呈现,软件种类多达27种,且不同分析方法常用工具差异明显。例如,SPSS作为一款功能强大的统计分析软件,在基于词共现的聚类分析、多维尺度分析、因子分析、中心性分析等分析中应用广泛;CiteSpace是陈超美教授用Java语言开发的基于引文分析理论的可视化软件,调研样本中的文献共被引分析、突破词分析、共现网络分析等,有61%都是借助CiteSpace进行的,可视化分析软件的多样性为研究热点的识别和呈现提供了更多的途径和更丰富的结果呈现方式。
(3)不同识别方法的分析侧重点差异明显,应根据数据特征及具体需求选择合适的分析方法。在分析对象选择方面,词汇具有较强的解读性,而引文分析通常需要耗费较多的精力对高被引文献、关键节点文献进行解读,因此词汇的分析结果会更加直观、易读;但文献间的引用关系代表着知识的流动和传承,以引文为对象可探测研究领域的知识基础和研究前沿,相较于词汇能更好地表达研究主题的演进。在计量方法和分析工具的选择上,聚类分析在主题表达方面更为直观,且分析工具多样,但由于算法不同,导致聚类类团也不同,因此在分析主题时仍需人工判断、调试;多维尺度分析图谱中,点与点之间的位置关系以及与中心位置的距离远近反映研究对象间的相似性及其核心程度,但通常仍需要综合其他分析方法进行区域划分,且研究者本身需对研究领域有一定了解,SPSS是多维尺度分析中最常用的工具。社会网络分析方法依据中心性指标判断对象在图谱中的地位,Ucinet中的NetDraw绘制的网络图可清晰看到对象间的亲疏关系,是社会网络分析中应用最为广泛的软件。突破词分析基于CiteSpace的突破算法识别出短时间内具有高增长率的关键词,在生成的图谱中使用红色标注并形成突破词检测报告,运算速度快且易于解读,是识别新型热点话题的一种高效途径,但同时也存在着缺乏词间关联、分布较为分散等弊端,需研究人员结合其他网络进行更为宏观的分析。此外,利用CiteSpace进行基于引文共被引的聚类分析,以参考文献为节点,节点文献一般是本领域内被引用频次较高且在引文网络中中心性较高的文献,通过对节点文献的阅读和分析,找出领域内的热点研究话题,这种方法通常用于探测知识基础,但在图谱的解读中较为费时费力,要同时结合节点附近的其他文献对领域内的研究主题进行解读。
