西藏特产知识图谱的构建
2023-10-07郭凤郑慧敏刘菲洋
郭凤 郑慧敏 刘菲洋
西藏民族大学信息工程学院,陕西 咸阳 712000
非物质文化遗产是中国优秀传统文化的重要组成部分,是中华文明五千年来绵延传承的生动见证。观研报告网发布的报告显示,截至2021年末我国共有国家级非遗项目3610 项,国家级非遗代表性传承人3068人。可以看出,我国在少数民族非遗保护工作方面取得了比较显著的成就[1]。西藏人民在西藏这片土地上创造出了许多独特的民族文化,并形成了他们自己独有的饮食习惯和风俗。非遗文化往往因为不被人们熟识和缺乏传承人而难以被保护,为了让非遗文化被更多人所熟知,同时也为了让西藏特产被更多人所了解,本论文利用知识图谱技术将西藏特产可视化展现出来,通过知识图谱技术来向人们介绍西藏特产,让人们更好的了解西藏特产,了解西藏,能更好的传播西藏的非物质文化遗产,达到对西藏非物质文化遗产进行保护和传承的目的。
1 研究背景
经过多年的发展,知识图谱在人工智能的许多行业如语义搜索、地图解析、信息处理等获得了广泛的应用,成为了现代自然语言处理技术发展的技术中心和有力工具[2]。例如本论文所涉及的西藏特产相关知识整体利用知识图谱联系起来,简洁快速地回答复杂的业务问题,甚至知识图谱技术可以让AI更加高效。
传统的非遗文化与新时代之间总存在摩擦,如何让非遗文化在融入当代社会的基础上更好地保留其自身的独特性,是非遗文化继承和保护的重点[1]。当前国内对于西藏特产知识图谱的整理、建模、数据分析和挖掘研究比较少。本论文研究通过建立西藏特产知识图谱,对西藏特产知识及其关系进行关系梳理、分类、整合和建模,为西藏特产的研究提供全方位、整体性、关系链的参考,同时为西藏特产文化传承保护及其研究提供数据来源和依据。
2 技术路线
2.1 技术简介
知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的技术方法,能够用概念、实体以及它们之间丰富的关联关系将知识进行结构化组织。知识图谱是包括实体(Entity)、概念(Concept)及其之间的各种语义关系的一种大规模语义网络,通常表示为典型的图结构,即三元组。基于这种图结构,能够将现实世界中所有的实体及实体间的关系,以一种统一的描述框架进行表示,如“实体-关系-实体”以及“实体-属性-属性值”的三元组组成[3]。这使得知识图谱相对于纯文本形式的知识而言对机器更友好。
Protégé 软件是Stanford 大学基于Java 语言开发的本体编辑和知识获取软件,属于开放源代码软件,主要用于语义网(Semantic Web)中本体的创建[4]。Protégé 提供了本体概念类、关系、属性以及实例的创建,并且屏蔽了具体的本体描述语言,用户只需在概念层次上进行领域本体模型的构建[4]。
Neo4j 图数据库是一种利用图形结构存储和查询数据的数据库系统,其基本组成结构是:节点、关系和属性[5]。Neo4j 图数据库是一种利用图形结构存储和查询数据的数据库系统,它具有图形结构数据存储和便利的功能,解决了关系型数据库存储图结构数据时出现的空间浪费等问题。
2.2 知识图谱的构建
互联网上的数据大多都是结构化、非结构化和半结构化的。非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。比如对特产的描述,可能是一段文本或是一张图片,这就是非结构化数据,但这些数据里面已经存储了一些信息,反映出知识图谱里西藏特产的一些属性,所以需要对数据里面的信息进行抽取。本论文中的数据几乎为非结构化数据,故对其它两种数据类型不再进行过多的赘述。
从数据里需要抽取的信息是实体、属性、关系。例如,在一段信息里面,提取出牛琼以及易贡藏刀这两个实体,然后再进行一个关系提取。经过分析,会产生一个对应关系,牛琼是易贡藏刀的传承人。另外还有属性提取,比如易贡藏刀的产地是西藏自治区林芝市。在这些提取完成之后获取的数据信息都是比较零散的,我们需要对获得的信息做一个整合。
整个构建过程中需要运用知识抽取、实体对齐和实体消歧[6]。关于实体对齐,举例来说,珞巴柳叶刀藏刀是中文名称,Lhoba Lancet 是它的英文名称,但其实这两个指的是同一个实体。由于文本的不一样,开始的时候导致这是两个实体,这就需要我们对它进行实体对齐,把它统一化。在本项目中,针对这两个实体,我们将英文名称设置为实体的一个属性。同理,实体消歧也是如此。
信息抽取结束后,进行本体抽取。如之前提到的易贡藏刀和珞巴柳叶刀,它们的本体是藏刀。从文本里面可能无法直接提取出来,需要一些方法对他们进行抽取。然后搭建出本体库,比如藏刀是特产中的一个类别,它是有上下流关系的。对于同一级别的实体也需要计算他们的相识度,比如易贡藏刀和珞巴柳叶刀在实体层面,它们是比较相似的,它们都属于藏刀这个本体。
一个知识图谱可以视作三元组的集合。构建知识图谱是一个迭代更新的过程。本论文“西藏特产关系知识图谱”采用自顶向下的构建方式,并使用Protégé 建模工具构建模型,其主要关键技术构架如图1所示。

图1 知识图谱的关键技术构架图
3 构建基于Neo4j的西藏特产知识图谱
3.1 数据获取
利用网络爬虫技术在百度百科、谷歌浏览器、知网等多处网站搜集需要的西藏特产的数据资料,将需要的数据保存成.csv 文件。本研究的数据内容包括每个特产的名称、类别、用途、藏文表示等,这些数据都为文本内容信息。
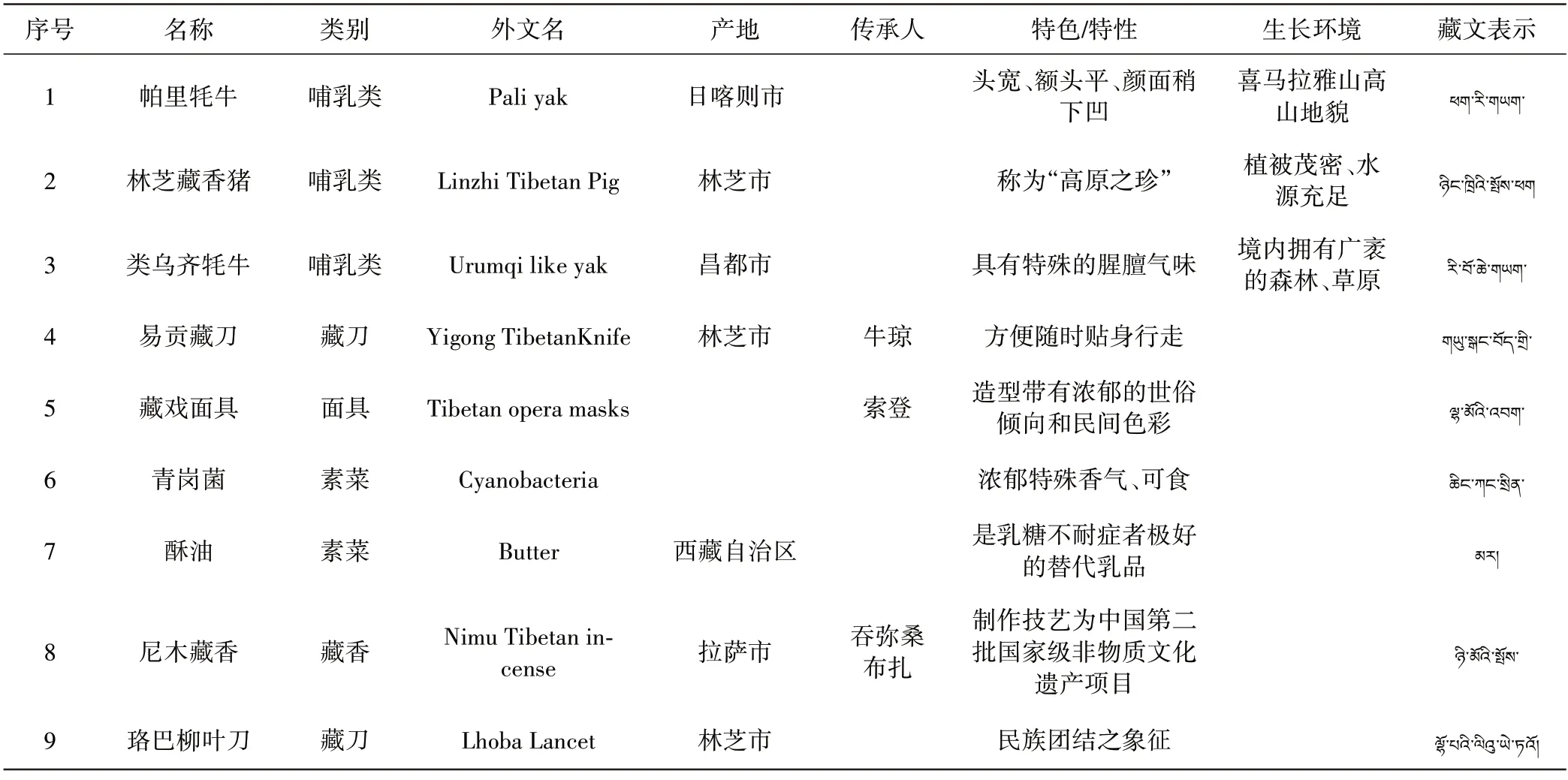
表1 西藏特产搜集的数据(部分)
3.2 信息抽取
3.2.1 实体抽取。实体抽取是一项非常常见的NLP任务,实体抽取也就是命名实体识别,包括实体的检测和分类[7]。本研究依据特产的特定特征,采用人工预定义实体分类体系的方式,输出该领域的高质量词语。本论文将实体分为三类,分别是特产、人物、地区。通过人工清洗的方法,依据百度词条的词条分类,将特产分为哺乳类、藏刀、藏毯、藏香、藏鞋、藏族服饰、藏族药膳、茶类、豆类、蜂蜜类、服饰材料、干果类、糕点、哈达、荤菜类、酒类、面具、奶制品、鸟类、其它、食材、饰品、水果、素菜、唐卡、小吃、鱼类、中药材类、主食共29 大类,每一类的特产具体到了产地、特征/特色、英文名、藏文表示等,并将“地区”类细分为“省/区级地区”和“市县地区”两大类。
3.2.2 关系抽取。关系抽取主要用于从非结构化文本数据中识别实体对象及实体间语义关系,将非结构化的文本数据转化为结构化的知识。本项目采用基于规则的方法依赖人工编写关系规则,在文本中匹配符合关系规则的信息,从而实现实体关系的抽取。本论文创建两个不同类之间的关系为“产自”“传承人”,即一种特产产自哪一地区,特产的传承人是谁,论文中没有设置人物和地区之间的关系。例如:拉孜藏刀产自日喀则市,它的传承人是次旦旺加、琼巴拉、普达瓦、普布。
3.2.3 属性抽取。属性抽取是给定一个实体以及该实体的描述文本,从文本中抽取出与该实体相关的属性及其属性值[8]。结合所构建的西藏特产关系知识模型,抽取特产名称,藏文表示,类别,英文名,特色等关键属性数据。
3.3 构建模型
本项目模型的构建使用的是Protégé。依据确定的特产本体核心类,利用Protégé 工具对特产本体类与关系属性进行创建,创建“特产”“传承人”“地区”三个大类,再在“特产”类下将其细分为“藏刀类”“藏毯类”“藏鞋类”等29大类,将“地区”类细分为“省/区级地区”和“市县地区”两大类。创建类之间的关系“产自”“传承人”,创建特产类的属性“外文名”“特色/特性”和“别称”。将获取到的属性导入,形成西藏特产关系应用本体,其构建本体的部分截图2~5。
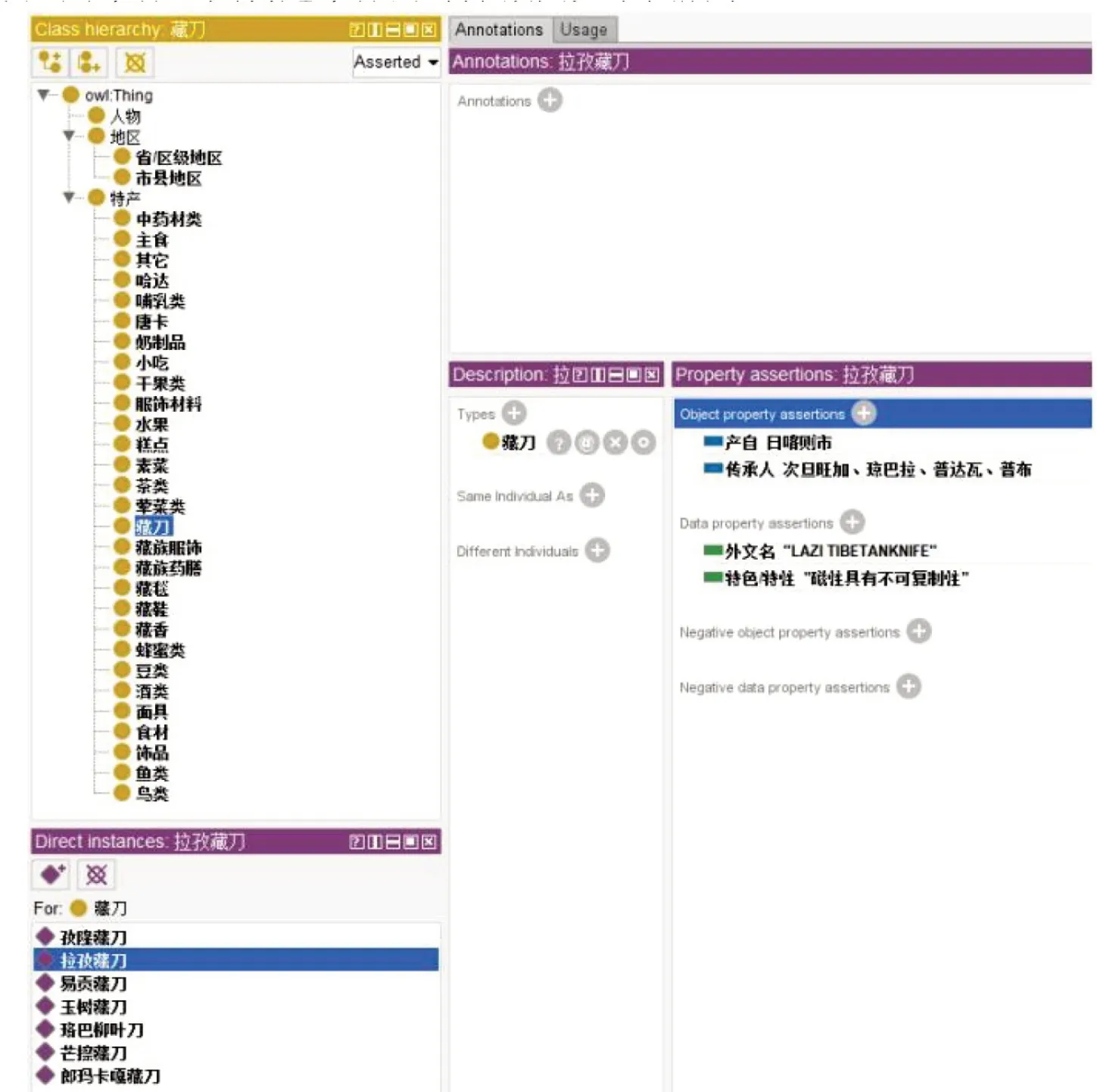
图2 构建实体属性

图3 地区实体

图4 人物实体
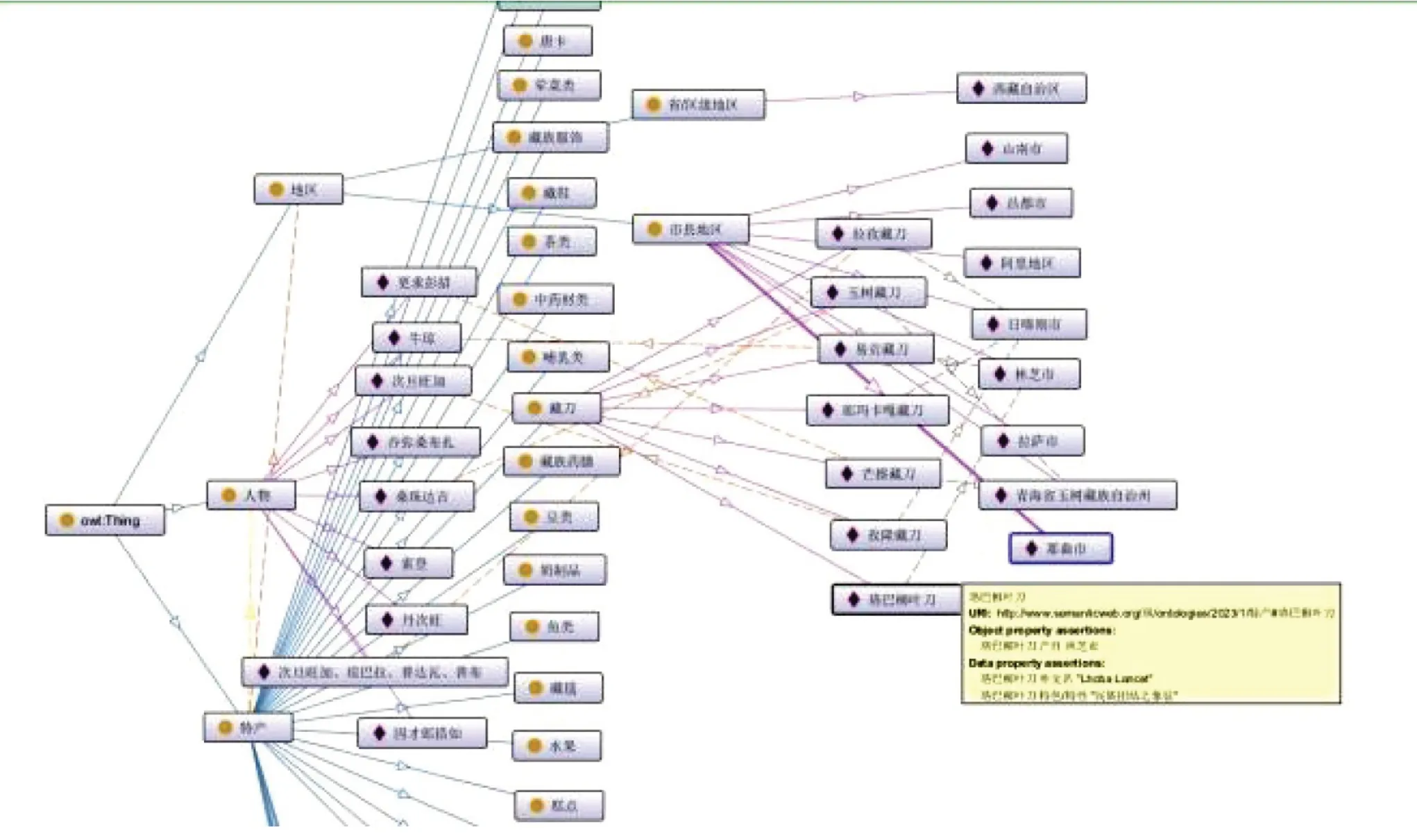
图5 构建本体展示(部分)
3.4 知识存储
Neo4j有多种数据导入的方法,本论文使用将.csv数据导入Neo4j中进行存储。将所获取的实体、关系存放到.csv 文件中,通过对数据的分析,创建了三个.csv文件,分别为s.csv、tt.csv、kk.csv。其中s.csv和tt.csv为实体文件,kk.csv 为关系文件,将搜集的.csv 文件存入Neo4j/import文件夹下后启动Neo4j,把数据导入Neo4j中,形成项目所需的数据库。如下表2~4,图6~7。
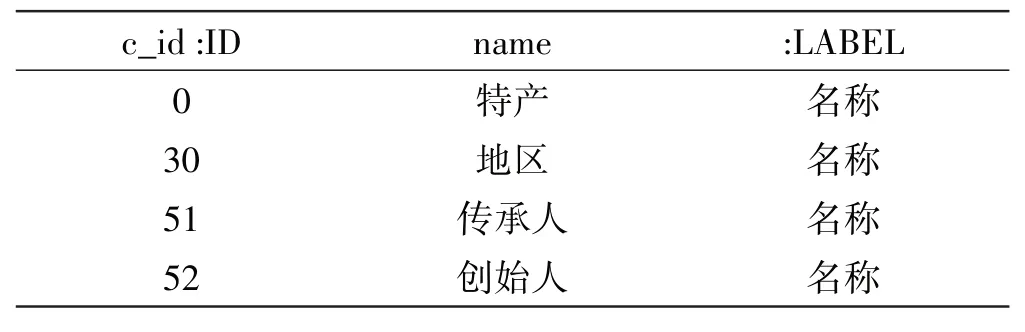
表2 实体文件s.csv

表3 实体文件tt.csv
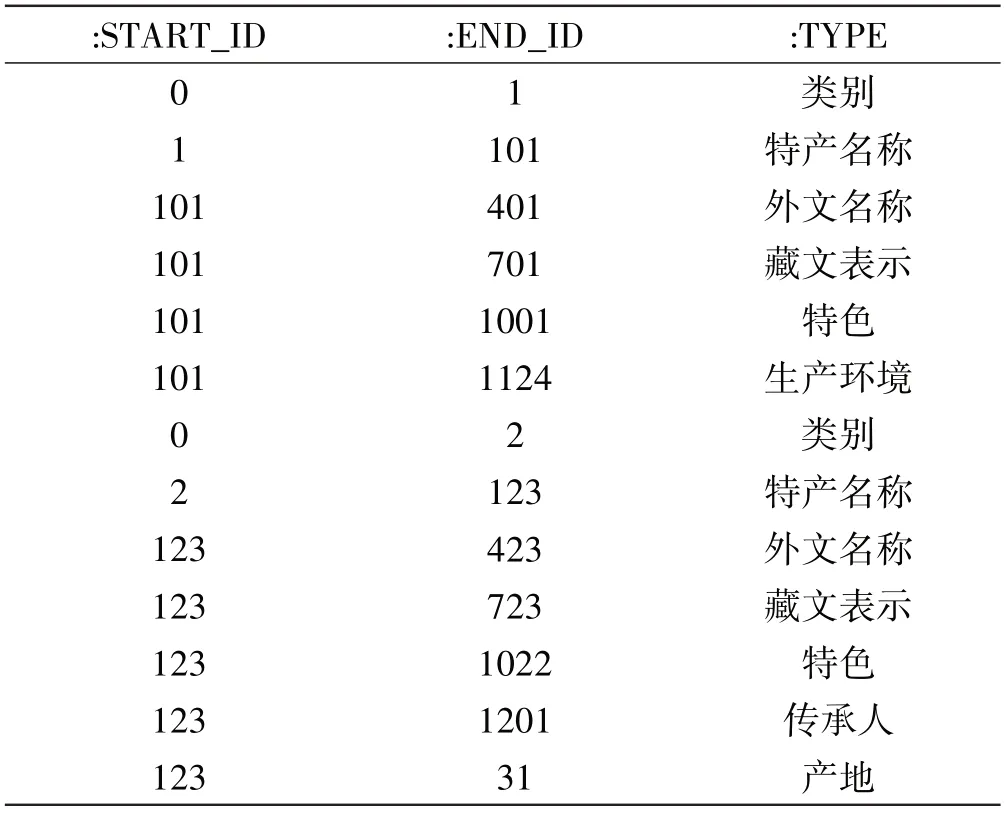
表4 关系文件kk.csv文件
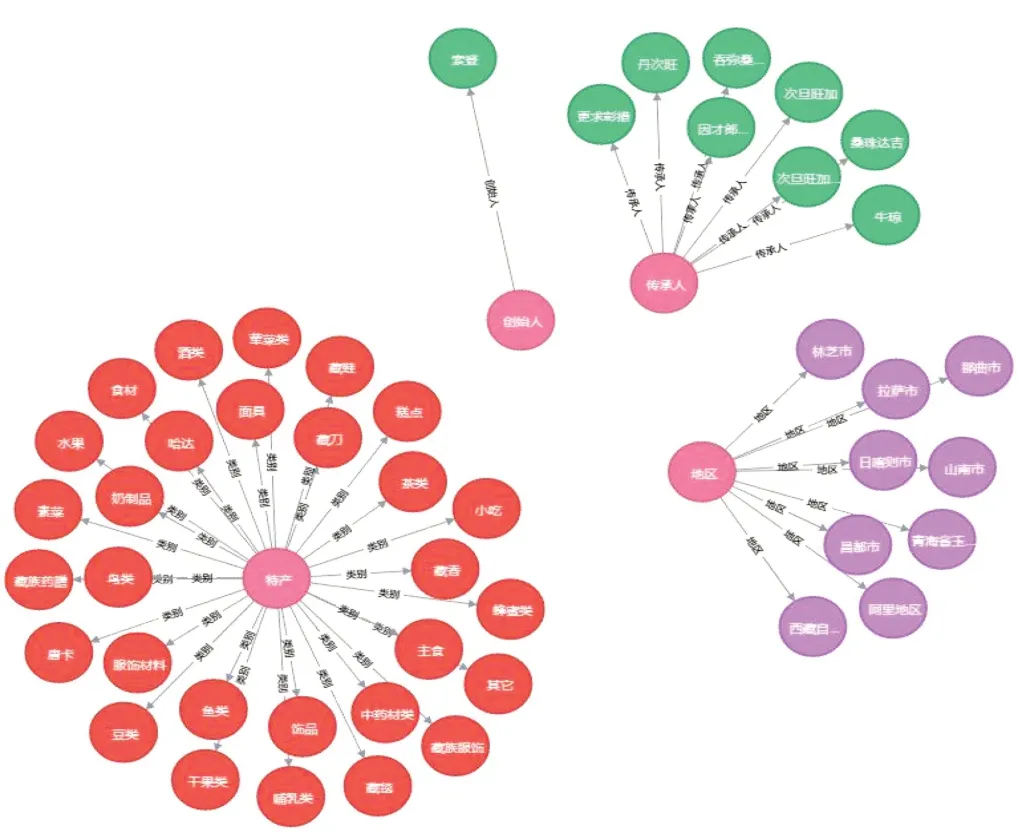
图6 数据本体
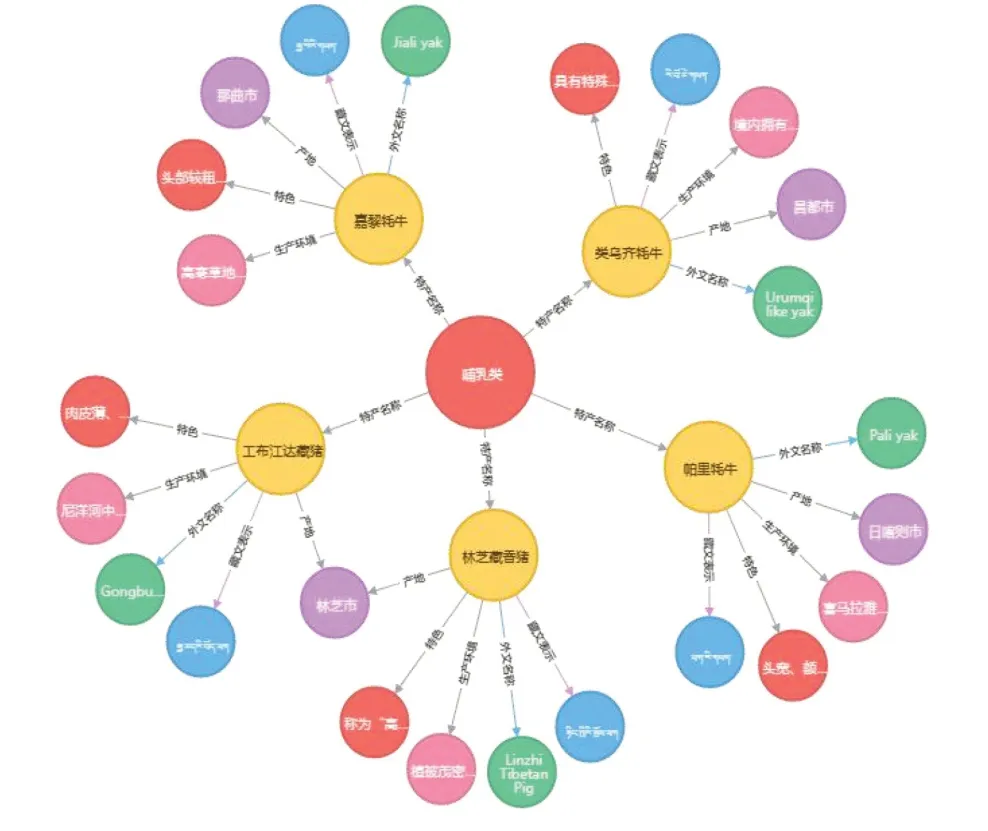
图7 特产属性(部分)
4 可视化研究
网页布局是网页设计开发工作的重要组成部分,通过合理的网页布局能够实现网页功能的精准定位,增强网页展示效果,使用户能够在较短的时间内找到目标元素[9]。本项目主要通过使用HTML5 和D3.js 来实现知识图谱在网页中的可视化。D3.js 是一个开源Java Script 库,用于浏览器中创建交互式可视化[10]。D3.js 可视化库将力导向图的绘制功能封装在库包之中,有效地调用相关工具可以将相应的实体和关系导入即可实现网络关系的可视化。
本文将.csv 文件中的西藏特产数据导为后缀名为.json 的文件,并对.json 文件进行一定的修改,便于网页前端的使用。利用HBuilder 建立了名为Tibetan Specialties 的项目,在此文件夹下放置多个目录文件,再将.json 文件放入data 目录下,在项目文件下创建.html文件,并创建后缀名为.css 的文件设置网站格式。前端和后端的数据利用.json 文件进行传输交互,将Neo4j中的数据引入在.html文件中,在.html文件中编写搭建网页的前端代码,让前后端进行联系。而后运行代码,使.json文件中连接的数据库里面的数据直观的在网页里显示出来,实现知识图谱的可视化。用户可以通过网页右端的粉红色搜索框中根据左端的类别进行相关搜索,同时也可以点击左端图例查看不同类别下的特产,找到用户所需的信息,从而更加深入地了解西藏特产。展示效果如下图8~9所示。

图8 西藏特产类别展示

图9 西藏特产中药材类网页展示
5 结论
本论文首先介绍知识图谱项目构建背景,然后介绍知识图谱、Protégé、图数据库Neo4j 的定义,根据西藏特产知识图谱的构建流程,对获取到的数据进行筛选清洗预处理,完成数据的存储。利用Protégé本体建模工具进行语义网络的模型构建,利用Neo4j图形数据库存储西藏特产知识图谱。在制作好的知识图谱中包含了有关西藏特产的藏文名、产地、特色等等,形成较为完善的知识图谱。构建的知识图谱具备一定的搜索功能,让西藏特产分类一目了然,从图谱中我们可以清楚的了解到西藏地区的特产,帮助人们快速寻找信息从而了解有关西藏特产的信息资料。同时该图谱可以给需要西藏特产的买家提供便利,用知识图谱的方式呈现出较为方便完善的西藏特产信息资料,便于买家查找了解,从而购买适合的西藏特产。我们通过创新的方式利用知识图谱将西藏特产推广给大众,让人们进一步了解西藏特产,了解西藏。
6 不足
当前知识图谱技术已经被广泛用于处理结构化数据和文本数据,但本项目在构建和实施过程中对人工的依赖程度还较高,导致构建成本高、效率低,在相对通用的知识图谱中自动化、大规模、高质量的构建技术扔有待探索。
本项目研究还存在一些不足,项目数据大多来自互联网搜索,并没有去西藏实地考察,特产种类没有足够齐全。搜集并发现更多的西藏特产,完善和拓展知识图谱,找到更多详细的特产特征,增加其它多种节点和关系的属性展示是进一步要完成的工作。在有一定条件的基础上去西藏地区实地考察,这一方法对本项目研究西藏特产知识图谱有重要意义和一定的促进作用。
