融合显著性图像语义特征的人体相似动作识别
2023-09-26白忠玉丁其川徐红丽吴成东
白忠玉,丁其川,徐红丽,吴成东
东北大学机器人科学与工程学院,沈阳 110819
0 引言
基于视觉的人体动作识别技术在安全监控、智能监护、人机交互及虚拟现实等领域有着广泛的应用(冉宪宇 等,2018)。基于骨骼的动作识别方法首先从视频或图像中提取人体的关节点与骨骼连接数据,然后用于动作识别,可以在动态环境、复杂背景和遮挡等情况下实现对运动的鲁棒识别,已成为当前人体动作识别的主要途径(Fernando等,2015)。
在实际应用中,从视频或图像中提取骨架数据会屏蔽图像中与人交互的物体信息,仅保留人体关节点的连接及运动信息,而相似动作的关节运动特征差异较小,基于骨架的动作识别方法难以分辨,易导致识别混乱。例如,识别“喝水”和“吃东西”等相似动作时,仅能提取“嘴”和“手”等相关关节的运动特征,而缺乏“水杯”、“食物”等关键语义信息提示,仅利用关节/骨骼数据难以准确区分“喝水”和“吃东西”这类相似动作,为基于骨架的动作识别带来了挑战。
早期动作识别方法需要从骨架序列数据中手动提取特征,用于动作识别建模(Sánchez等,2013),但是这类方法操作烦琐,提取的特征缺乏多样性,泛化能力较差。得益于深度学习模型强大的特征自动提取能力,基于深度学习的方法已经成为目前动作识别的主流方法(成科扬 等,2021)。传统深度学习方法通常将骨架数据构造为关节坐标向量或伪图像,然后直接输入到递归神经网络(recurrent neural network,RNN)(Liu等,2016)或卷积神经网络(convolutional neural network,CNN)(Ke 等,2017)进行动作分类。该类方法由于受欧氏数据结构的限制,会丢失骨架的空间结构信息,无法体现人体关节点之间的自然关联性,对相似动作间关节运动特征的细微差异难以分辨。实际上,人体骨架更自然地构造为非欧氏空间中的图结构。近年来,图卷积网络(graph convolutional network,GCN)将卷积操作从图像推广到图结构,并成功应用到基于骨架的动作识别中,取得了良好的效果(Yan 等,2018)。目前,基于GCN 的动作识别方法普遍关注图网络拓扑结构的设计与改进,缺乏针对相似动作识别混乱问题的探讨。
相似动作难以区分已成为影响模型动作识别效果的重要因素。Du 等人(2015)提出一种端到端分层RNN 网络用于动作识别,发现错误分类主要发生在几个非常相似的动作间。随后,进一步发现错误分类动作具有相似的时空变化特征,并指出若不增加动作背景信息,仅依靠骨骼数据很难区分这些动作(Du 等,2016)。Lee 等人(2017)提出一种时间滑动长短时记忆网络模型(temporal sliding long shortterm memory,TS-LSTM)进行动作分类,发现错误分类动作的骨骼序列在时空间存在高度重叠。Gao 等人(2019)提出一种基于图回归的动作识别方法(graph regression based graph convolutional network,GR-GCN),用于捕获骨架数据的时空变化信息,但仍未解决高度相似动作的识别问题。Si等人(2019)提出一种注意力增强图卷积LSTM 网络用于动作识别,发现对相似动作的误识别导致模型识别效果差,并提出有效区分细微动作是实现相似动作识别的关键。Liang 等人(2020)认为共享子动作(sub-actions sharing)是导致相似动作识别性能差的重要原因,并提出一种利用子动作关系,融合深度信息和骨骼特征的分段识别模式。然而,该方法的识别效果依赖于对子动作的划分,难以区分子动作高度相似的动作类别。
为实现对相似动作的正确分类识别,本文结合图像语义信息,提出一种基于显著性图像特征强化的中心连接图卷积网络(saliency image feature enhancement based center-connected graph convolutional network,SIFE-CGCN)。首先,针对相似动作中细微运动差异难以捕获的问题,设计一种骨架中心连接拓扑结构,建立人体所有关节点到骨架中心的连接,以捕捉运动中所有关节间潜在的协同依赖关系,进而提取关节运动的细微差异特征;其次,针对图像语义特征缺失问题,利用高斯混合背景建模法从运动视频中提取显著性图像,再采用VGG-Net(Visual Geometry Group network)(Simonyan 和Zisserman,2014)提取图像特征图,并进行动作语义特征匹配分类;最后,将分类结果按照一定的融合比例对中心连接图卷积网络的识别结果强化修正,提高网络对相似动作的识别能力。此外,提出了一种针对骨架数据的动作相似度计算方法,并据此建立相似动作数据集。实验结果表明,本文方法可实现对相似动作的准确有效分类,且模型的整体识别性能及鲁棒性也得以提升。
1 图卷积网络
本文方法以图卷积网络为基础,下面简要介绍图的构造、图卷积网络以及动作识别的具体实施。
1.1 图的构造
基于骨架的动作识别方法通过深度传感器或位姿估计算法提取每一帧图像中人体的骨架数据,并用矢量序列表示,其中每个关节的2D 或3D 坐标设置为对应的向量。本文使用时空图来模拟关节沿着空间维度(spatial dimension)和时间维度(temporal dimension)的结构化信息(Yan 等,2018),定义时空图G=(V,E),如图1 所示,其中图的节点表示人体关节点,定义节点集合V={vti|t=1,…,T,i=1,…,N},其中,t表示骨骼序列的帧数,i表示关节点数,T和N分别表示总帧数和总关节点数。人体骨骼自然连接可表示为空间边缘ES(连接实线),而在时间维度上,两个相邻帧间的对应关节点连接表示为时间边缘EF={vtiv(t+1)i}(虚线),ES和EF构成了图的边集合E。
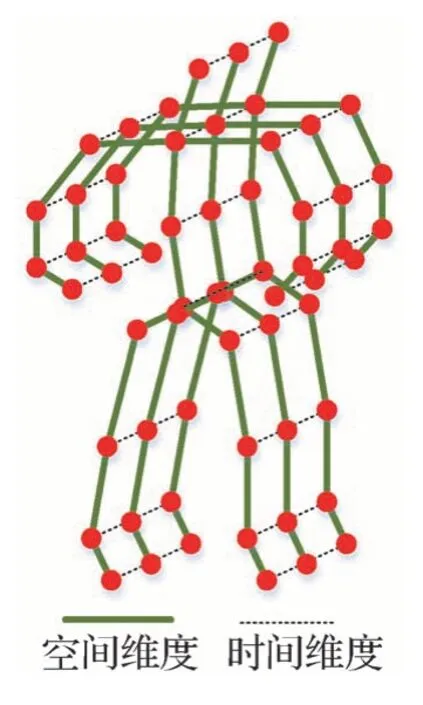
图1 骨架时空图结构Fig.1 Skeleton spatiotemporal diagram structure
通常,每个关节点的特征向量只包含关节的2D或3D 坐标,可看做骨骼数据的1 阶信息,而两个关节点之间的骨骼长度和方向特征可看做骨骼数据的2 阶信息,针对动作识别,2 阶信息可以帮助模型更好地捕获动作的多角度特征。本文参考Shi 等人(2019)的方法,提取骨骼的2 阶信息。以3D 骨骼数据为例,人体骨架中心定义为人体腹部的关节点,每个骨骼都连接两个关节点,靠近骨骼中心的关节为源关节,远离中心的关节是目标关节。每个骨骼表示为从源关节指向目标关节的向量。例如,给定源关节j1=(x1,y1,z1)与目标关节j2=(x2,y2,z2),则相应的骨骼矢量为=(x2-x1,y2-y1,z2-z1)。
1.2 图卷积网络
图卷积神经网络(GCN)是处理图结构化数据表示的有效框架。给定预定义的图结构,则图节点vi在空间维度上的图卷积为
式中,fin(·)和fout(·)分别表示网络训练过程中节点的输入与输出特征值。B(vi)为节点vi的采样区域,定义为人体骨架的物理连接中与关节点vi相邻的节点区域集合。w(·)是权重函数,用于提供权重向量。卷积的权重向量的数量是固定的,而邻域中的关节点数量是变化的,按照映射策略设计对应的映射函数li(·),将采样区域内的关节点分割到多个固定的子集中,每个子集都与一个唯一的权重向量相关联,因此,映射策略直接影响模型的特征提取效果。ST-GCN(spatio-temporal graph convolutional network)模型(Yan 等,2018)的映射策略如图2 所示,以图中黑色曲线中红色的点为例,曲线所包围的区域为该节点的采样区域B。图中“×”表示人体骨架重心。该策略按照骨骼物理连接结构将B分成3个子集:Si1是顶点本身(圈中红色点);Si2是向心子集,包含比顶点本身更靠近重心的相邻顶点(黄色点)集合;Si3是离心子集,包含离重心更远的相邻顶点(蓝色点)集合。Zij表示包含vj的子集数量,用于平衡各个子集对输出的贡献。
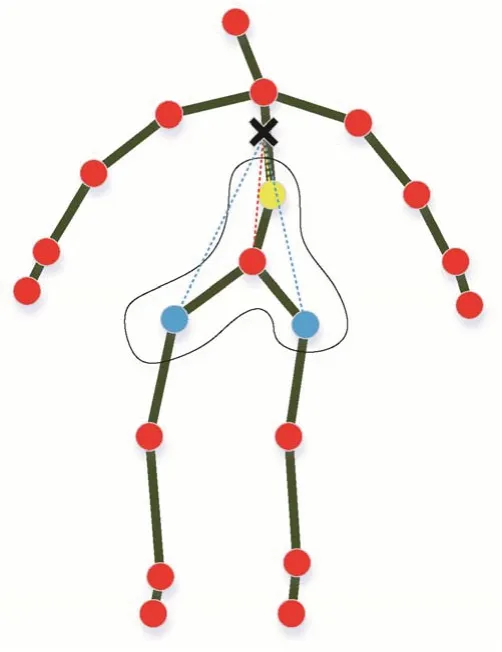
图2 映射策略示意图Fig.2 Illustration of the mapping strategy
1.3 具体实施
网络的特征图本质上是一个三维向量,即f∈RC×T×N,其中,N表示顶点的数量,T表示时间的长度,C表示特征图的特征维度。通过邻接矩阵Ak可以判断关节是否连接。因此,为实现空间图卷积,将式(1)转化为
对于时间维度,骨骼序列中每一帧与前后两帧相关联,因此每帧中节点相邻的节点数固定为2,可以执行类似于经典卷积来代替图卷积。即对式(2)计算得到的输出特征图执行Kt× 1 卷积,其中Kt为时间维度的卷积核大小。
经过上述空间和时间图卷积操作提取高维特征后,通过池化层和softmax 分类器可实现对动作的分类识别。
2 SIFE-CGCN模型
2.1 骨架中心连接拓扑结构
人体运动需要多关节甚至是全部关节的协同参与。基于此,为更全面地捕捉动作中关节点的细微运动特征,设计了一种骨架中心连接拓扑结构(图3),在人体关节点物理连接的基础上添加了中心连接,将所有关节点与骨架中心建立连接(虚拟连接),以获取所有关节点相对骨架中心的位移变化,增强模型对细微运动特征的捕捉能力。同时,进一步考虑到各关节点在不同动作中的作用不同(例如“喝水”动作,“手”、“肘”和“嘴”部关节点起到主要作用),模型添加了注意图以重点关注主要运动关节,具体为
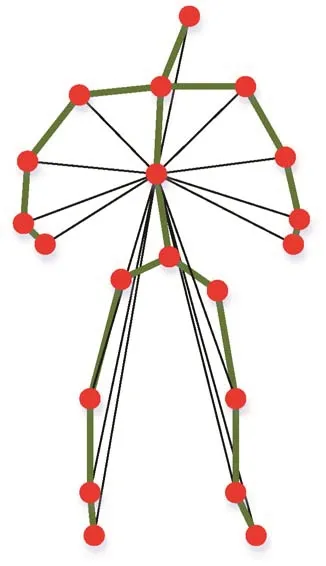
图3 骨架中心连接拓扑结构Fig.3 Illustration of the topology of skeleton-center connection
式中,邻接矩阵Ak分为4 部分。Aroot、Aoff和Aen对应图2 中的映射策略,分别代表根节点、离心和向心的邻接矩阵,均为N×N,这3 个邻接矩阵仅表达了人体关节的自然物理连接,但是对于动作而言,可能并非仅由物理连接的关节运动产生,比如“拍手”,双手关节点没有物理连接,但是需要协同运动。因此,为了更全面地描述运动中所有关节点的潜在协同依赖关系,在式(3)中添加了表征所有关节点与骨架中心连接的邻接矩阵Acc∈RN×N。以人体腹部关节点作为中心节点,可以兼顾人体所有关节的动态特征,且该连接是虚拟的连接,可以克服因物理连接联动干扰导致的关节点细微运动难以分辨问题,利于获取相似动作间的细微运动差异。此外,Mk∈RN×N是可学习的注意力图,它决定了关节点之间连接强度,可以使模型更关注主要运动关节点。⊙表示对应元素乘积操作。由于中心连接邻接矩阵的添加,卷积核大小Kv=4。Wk(·)是参照式(1)中的w(·)引入的加权函数。
按照式(3)构建中心连接图卷积网络(CGCN)的空间图卷积模块,而时间图卷积模型仍采用经典卷积的操作方式。一个基本的中心连接图卷积单元包括一个空间图卷积(Convs)、一个时间图卷积(Convt)和一个丢失层(dropout),如图4(a)所示。Convt和Convs之后都是批量归一化层(batch normalization,BN)和ReLU(rectified linear unit)层。为了训练稳定,为每个单元添加残差连接(residual connection)。

图4 CGCN模型结构图Fig.4 The structure of CGCN((a)graph convolutional unit;(b)graph convolutional network structure)
如图4(b)所示,中心连接图卷积网络是由9 个中心连接图卷积基本单元堆叠而成,每个单元输出通道数分别为64、64、64、128、128、128、256、256 和256;在网络开始处前添加BN层,使输入的数据标准化,结尾处添加全局平均池化层,统一特征维度;最后,将处理的特征图输入softmax 分类器,获得预测结果。
为充分利用骨架数据的1阶和2阶信息,提出的CGCN 总体框架如图5 所示,J-CGCN(joint centerconnected graph convolutional network)和B-CGCN(bone center-connected graph convolutional network)分别代表关节点和骨骼矢量的图网络。对于给定的人体运动骨架数据,首先通过计算得到1 阶关节数据和2 阶骨骼矢量,然后将关节数据和骨骼矢量分别输送到J流和B流中,最后将两个流的预测结果融合相加,通过softmax分类器获得最终的预测结果。
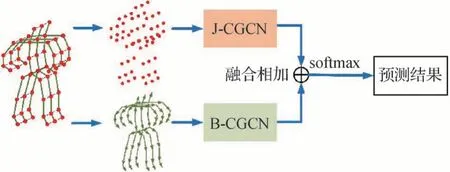
图5 基于CGCN的动作识别模型Fig.5 CGCN-based action recognition model
2.2 显著性图像提取
上述方法仅利用人体的骨架数据进行动作识别,如前所述,对于一些相似动作,其骨架数据特征的差异不明显,而人体运动中涉及的交互物却有显著差异,比如“喝水”和“吃东西”两种动作,骨架序列数据非常接近,但是“水杯”和“食物”的图像语义特征有显著性差异。因此,若能从视频或图像中提取有显著差异的特征,用于强化CGCN 的识别结果,能够进一步提升模型对相似动作的识别效果。
视频帧间人体形态变化大的区域往往具有显著的特征信息。对视频中显著性图像的选取旨在提取视频中运动区域的图像信息,同时消除视频中冗余背景信息。高斯混合模型背景建模法是一种基于像素的建模方法(蔡念 等,2011),可以表示多模分布的背景,将每一帧与实时更新的背景模型相比较,分割出显著性变化的图像区域,同时消除背景干扰,且具有存储数据量小及自适应学习的优点。本文利用该方法构造时空背景模型,以提取视频中的显著性图像。
高斯混合模型以高斯分布为基础,将每个像素点的取值建模为K个独立的高斯分布,并对高斯分布的均值和方差在线更新。Xt表示像素点在t时刻的观测值,一般为(R,G,B)颜色分量。t时刻视频帧中像素点Xt的概率密度表示为
式中,K是高斯分布组元数,本文取值为5;ωk,t为t时刻的第k个高斯分布的权重,μk,t为均值,Σk,t为协方差矩阵,η(·)为高斯概率密度函数。为了简化计算,假设各个颜色通道独立且具有相同的方差,即
式中,σk,t为标准差,I为单位阵。对于t+1 时刻视频帧,将其中的每个像素值依次与K个高斯分布匹配检验,若满足
则说明当前像素点Xt+1和该高斯分布相匹配,反之则不匹配。式中,λ为常量,本文取值为2.5。对于匹配的第k个高斯分布,更新为
式中,β为更新速率,本文取值为0.01;ρ为参数学习率。若匹配,Mk,t+1取1,否则取0。不匹配的高斯分布权重依旧按式(6)更新,但其均值和方差保持不变。若所有高斯分布均不匹配,则更新权值最小的高斯分布的均值和方差,并对所有权值作归一化处理。
按ωk,t/σk,t由大到小的顺序排列每个高斯分布,选择上述序列中前L个高斯分布作为背景模型,则
式中,D为预定的权重阈值,本文取值为0.5。将每个像素值与背景模型匹配测试,若匹配,则该像素点为背景点,否则该像素点为前景点。具体流程图如图6所示。获得所需前景、后景后,对图像进行形态学运算,包括核为3 × 3的开运算去噪,以及核为8 × 3的闭运算,以连通相邻区域。最后根据设定的像素阈值获得需要的显著性图像。
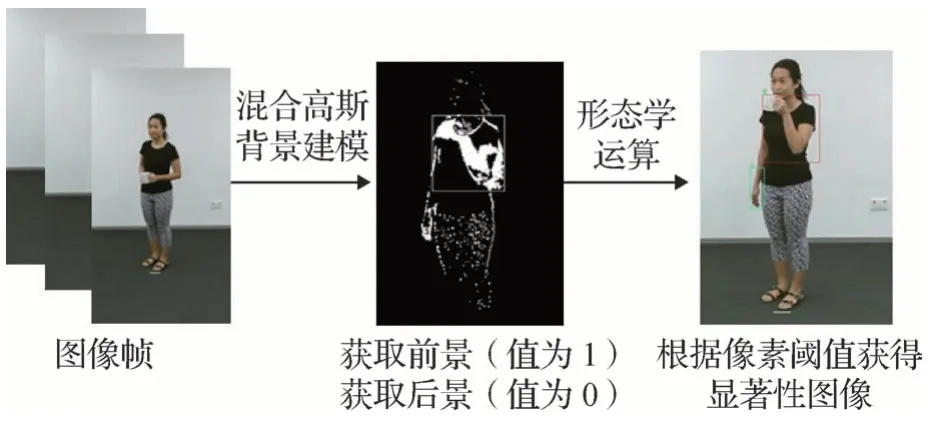
图6 显著性图像提取流程图Fig.6 Saliency image extraction flowchart
2.3 图像特征提取
从显著性图像中提取出语义特征图是后续区分相似动作的关键。本文选用预训练的VGG-Net作为特征图提取网络,前期研究已证实VGG-Net 能够有效地从图像中提取物体的空间结构特征(Simonyan和Zisserman,2014)。图7 给出了特征图提取过程,其中VGG-Net多次使用3 × 3小型卷积核和2 × 2的最大池化层,构建了16~19 层深的卷积神经网络。特征图尺寸(Wf×Hf)与原始图像尺寸(W×H)及卷积层参数关系为
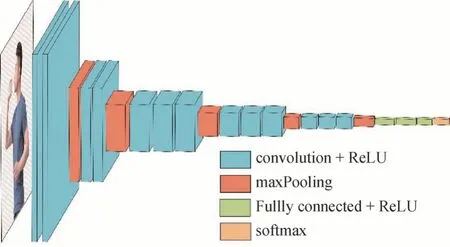
图7 图像特征提取过程Fig.7 The process of the image-feature extraction
式中,F为卷积核大小,P为网络的填充数,S为网络移动步长。
如图7 所示,每个卷积层后对应一个激活层(convolution+ReLU),激活层不改变图像大小,所以原始图像经过卷积层和激活层后的特征图大小均不会改变。采用5 个最大池化层(maxPooling)对激活层输出进行2 × 2 不重叠最大值降采样,于是VGGNet 输出的特征图的长和宽都为原始输入图像长和宽的1/32,特征图的维度为512。本文先利用VGG-19 预训练模型对显著性图像特征提取,再采用神经元个数分别为25 088、4 096 和N(动作种类数)的3 个全连接层(fully connected)对特征图进行动作语义匹配分类。
2.4 总体框架
应用SIFE-CGCN 模型进行动作识别的整体框架如图8 所示,其中主体包括CGCN 网络(上分支)和显著性特征强化(SIFE)模块(下分支)两部分。针对动作视频输入,首先提取骨架数据,构造关节点时空矢量图,输入CGCN 网络,获得基于骨架数据的动作预测结果,同时利用高斯混合模型背景建模法从视频图像帧中提取显著性图像,而后将显著性图像输入VGG-Net 提取特征图,再采用全连接网络对特征图进行动作语义匹配分类,最后将匹配结果与CGCN 预测结果按给定的比例α(0 ≤α≤1)融合,将融合结果输入到softmax 分类器,获得最终强化修正的动作识别结果,即

图8 基于SIFE-CGCN的动作识别整体框架Fig.8 Overall framework of action recognition based on SIFE-CGCN
式中,fCGCN、fSIFT和fout分别为CGCN 网络、SIFE 模块和整体模型最终的输出结果。
3 实验与结果分析
3.1 数据集
NTU RGB+D 60(Nanyang Technological University RGB+D 60 )是目前使用最广泛的针对室内动作识别的视频数据集(Shahroudy 等,2016),数据通过Microsoft Kinect v2 相机捕获,是40 名10~35 岁的志愿者的动作视频剪辑,共有56 880个视频片段,涵盖60 种动作类别,包括单人及双人动作,其中单人动作包括“喝水”、“吃饭”等40 种日常动作。由Kinect v2 深度数据,可以获得人体的25 个关节点的3D 坐标,形成骨骼/关节数据。数据集采用cross-subject(X-Sub)和cross-view(X-View)两种评估方式。在X-Sub评估中,训练集包含来自20个动作类的40 320个视频,其余的16 560 个视频用于测试;在X-View评估中,从2号和3号相机捕获的视频(包含37 920个视频)用于训练,而从1 号相机捕获的视频(包含18 960个视频)用于测试。实验中,两个基准都报告了Top-1的准确率。
NTU RGB+D 120(Liu等,2020)是目前最大的具有3D 关节标注的人体动作识别数据集,是NTU RGB+D 60 数据集的扩展。该数据集包含120 个动作类别,共有114 480 个动作样本。样本由106 名志愿者利用不同设置的3 个摄像头拍摄采集。摄像头的设置方式共有32 种,每种设置表示一个特定的位置和背景。该数据集包含两种评估方式。其中,跨自愿者评估(X-Sub)共有106 个志愿者,分为训练组和测试组,每组包括53 名志愿者。跨摄像头设置评估(cross-setup,X-Set)的训练数据来自设置标号为偶数的样本,测试数据来自设置标号为奇数的样本。
为了验证提出的方法对相似动作识别的有效性,挑选关节点坐标相近的3 组动作构建相似动作数据集,用于实验验证。具体方法为:
首先,从每个动作的骨架序列中平均采样20帧,计算每个动作后19帧中关节点坐标相对第1帧对应关节点坐标的欧氏距离,即
然后,计算两个动作对应帧关节点位置变化值差的绝对值和,即
式中,Sact1-2是动作act1与动作act2的相似度指标,该值越小,说明这两个动作差异越小,相似度越高。
利用式(15)和(16),选择8 种动作,包括喝水(drink water)、吃饭(eat meal)、刷牙(brush teeth)、打电话(phone call)、读书(reading)、写字(writing)、穿鞋(put on a shoe)和脱鞋(take off a shoe),其中,前4种动作为第1组相似动作,“读书”和“写字”为第2组相似动作,“穿鞋”和“脱鞋”为第3组相似动作。
3.2 实验设置和预处理
实验均在同一实验环境下完成,实验平台为一台CPU 为英特尔i7-600K、GPU 为NVIDIA GeForce TITAN XP(显存为12 GB)的计算机,操作系统为Ubuntu16.04。所有实验均使用PyTorch深度学习框架。模型损失函数采用交叉熵(cross entropy)损失函数,采用小批量随机梯度下降法(stochastic gradient descent,SGD)训练模型,动量为0.9。对于NTU RGB+D 60 数据,初始学习率设为0.1,在第30、40、50 个epoch 除以10,共训练60 个epoch。对于NTU RGB+D 120 数据,初始学习率设为0.1,在第60、70、80 个epoch 除以10,共训练100 个epoch。数据的批量大小均为64。
为了防止显著性图像特征提取过程中出现过拟合,对图像进行预处理,将图像尺寸统一裁剪为224 × 224 像素,并进行平移、旋转和归一化处理。对骨架数据的预处理包括基于骨架标识符的骨架对齐、基于骨架置信度过滤误检的物体、坐标归一化和视角归一化。
3.3 实验结果与分析
首先,测试CGCN 模型中的注意力图和双流框架的有效性。对于注意力图,缺少注意力图的CGCN 模型(CGCN(without attention))与添加了注意力图的CGCN 模型在相似动作数据集上的识别精度如表1 所示。对比的方法包括ST-GCN(spatiotemporal graph convolutional network)(Yan等,2018)、2s-AGCN(two-stream adaptive graph convolutional network)(Shi 等,2019)以 及JB-AAGCN(joints and bones attention-enhanced adaptive graph convolutional network)(Shi等,2020)算法。可以看出,添加了注意力图后,模型的识别精度在X-Sub 和X-View 基准上分别提升了1.4%和0.8%。表明注意力图的添加能够增加模型的灵活性,自适应关注重点运动的关节点,提高对细微动作的识别性能。对于CGCN 模型中的双流网络,表1 中的CGCN(J)、CGCN(B)和CGCN(J+B)分别代表CGCN 模型利用关节点流、骨骼流和双流数据在相似动作数据集X-Sub和X-View两个基准上的动作识别准确率。可以看出,利用双流数据的模型识别精度均高于仅利用单流数据的模型识别精度。其中,CGCN(J+B)达到了最高的识别精度,在不同的基准上,精度达到了76.1%(X-Sub)和86.8%(X-View),较次优的单流模型CGCN(B)分别提升了2.8%和1.1%。表明双流网络能够通过充分利用骨架数据的多角度特征,提高模型的识别能力。
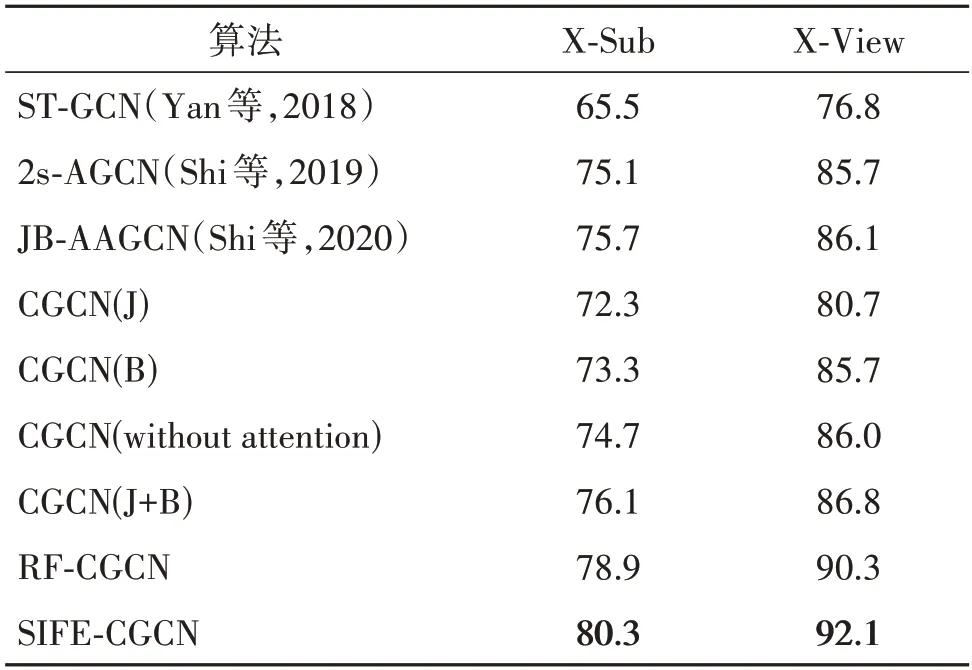
表1 相似动作数据集上与其他方法的识别精度对比Table 1 Comparison of accuracy with other methods on the similar action dataset/%
图9 显示了“喝水”动作在不同网络层中注意力图,其中红色圆点的大小代表关节的运动参与度,点越大,参与度高。可以看出,在第1 层网络(layer1)中,模型对关节点的关注较均匀,在四肢处均有较高的关注度。随着网络层数的增加(layer3—layer9),模型更加关注手部、肘部及颈部关节点,说明这些关节主要参与执行了“喝水”动作,与事实相符;另外,重点关注手部、肘部等关节运动,也利于网络捕捉与“喝水”相似的动作间的运动特征差异。表明本文采用的可学习注意力图在低层网络能够提取人体全身关节的运动特征,而随着网络层数的增加,使模型更关注主要参与运动的关节点,捕获主要关节点的运动特征,也有助于提高对相似动作的分辨能力。
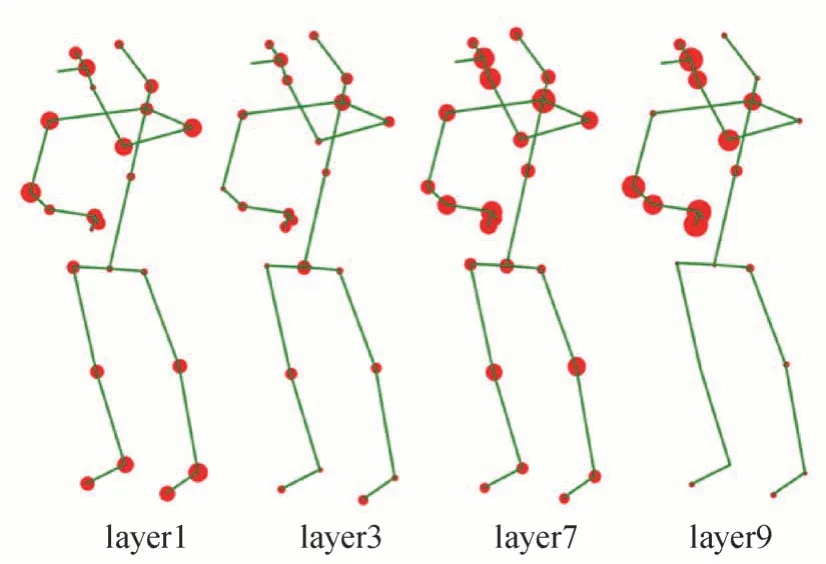
图9 针对“喝水”动作的可学习注意力图变化Fig.9 Changes of learnable attention map for the action of drinking water
其次,测试显著性图像的提取效果。表2 列出了随机帧图像和显著性图像在X-Sub和X-View两种基准上的实验结果。在表2 显示的利用4 种预训练模型提取特征图计算分类精度的结果中,Google-Net模型(Szegedy 等,2015)提取特征的分类精度最低,该模型采用大量1 × 1卷积核降维,会丢失较多低维信息,特征提取效果较差;Restnet50 模型(He 等,2016)设计了一种残差模块以训练更深层的网络,其特征提取效果优于Google-Net,但较多的网络层引入更多参数,易产生过拟合,导致特征提取的一致性差;VGG-Net 包含5 组卷积,模型深度适中,每组卷积都使用了3 × 3 卷积核,保证网络的感受视野,同时增强对低维信息的捕获能力,由该网络提取的特征图的匹配分类精度较高,其中,本文采用的VGG-19 模型提取的特征图,在X-Sub 和X-View 上的分类精度分别达到58.11%和60.03%,比采用VGG-16模型获得的精度提高了1.95%和1.54%。可以看出,对于4 种不同的预训练模型,显著性图像的语义匹配分类结果均高于随机帧图像。表明提出的显著性图像提取方法能够有效捕获图像中的动态信息,增强动作相关的语义特征。
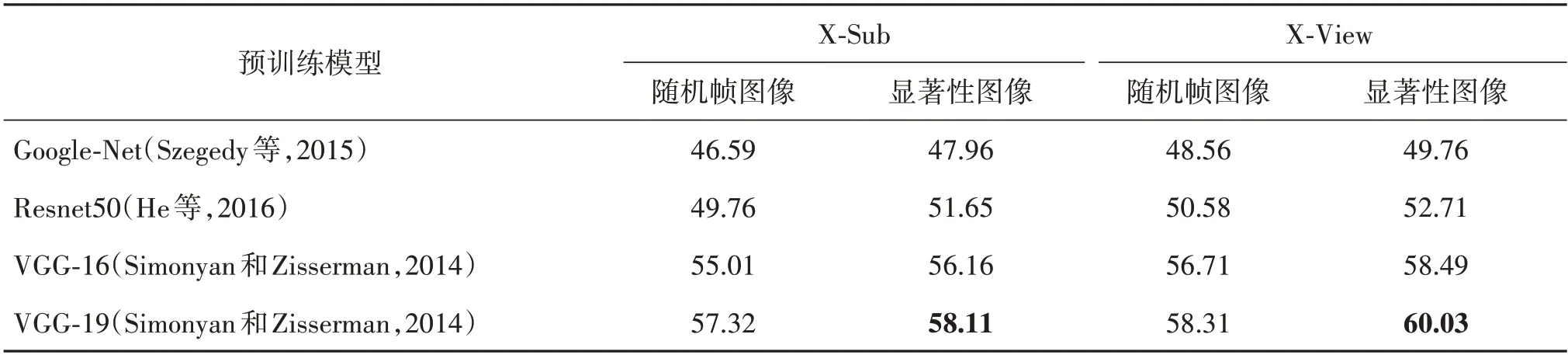
表2 利用4种模型提取特征图计算的分类精度Table 2 Matching classification accuracy by using the feature maps extracted by four models/%
进一步,将提出的SIFE-CGCN 与随机帧图像特征强化的中心连接图卷积网络(random-frame enhancement based CGCN,RF-CGCN)对 比,其 中RF-CGCN 从视频中随机选择图像帧,提取特征图,其余部分与提出的方法完全一致。这两种模型的相似动作识别结果也列于表1,其中SIFE-CGCN 在X-sub 和X-View 两个基准上识别精度分别达到80.3%和92.1%,比RF-CGCN 的识别精度分别高了1.4%和1.8%。可见,利用高斯混合模型得到的显著性图像特征对识别结果强化修正效果更优越,能更好地区分相似动作。
图10 显示了CGCN 和SIFE-CGCN 模型在X-Sub评估基准下,针对相似动作数据集的动作识别精度对比图。可以看出,使用显著性图像特征强化修正后,模型对相似动作的识别精度均有了一定的提升。其中对第2 组动作的识别精度提高最明显,准确率分别提高了12%和17%。对第3 组动作识别精度提升效果较差,准确率仅提高了4%和2%。可见,对于显著性图像特征差异明显的动作,识别精度提升更显著;而对于如“穿鞋”和“脱鞋”等有相同显著性图像特征(“鞋”)的动作,识别精度提升减小。

图10 CGCN模型和SIFE-CGCN模型在相似动作数据集X-Sub基准上的识别精度对比图Fig.10 Comparison of recognition accuracy between CGCN model and SIFE-CGCN model on the X-Sub benchmark of similar action datasets
利用SIFE-CGCN 进行动作识别,式(14)中的融合比例α是一个重要参数。为了验证不同融合方法的效果,图11 给出了使用不同α时模型的动作识别精度。由于视频图像中存在背景干扰,且并非所有图像特征信息对动作识别结果都有正向强化修正作用,需要按照一定的融合比例α对识别结果强化修正。实验中将α从0~1 每次递增0.1,从图中可以看出,α值为0.4 时,识别准确率最高,两个基准的折线均达到峰值,因此本文融合比例α值设为0.4。在峰值两侧随着α值的变化,识别精度均下降。α值在0.1~1之间均得到了比α=0(仅使用CGCN模型)更高的识别精度,可见,显著性图像特征能够对CGCN模型的识别结果强化修正,提升动作识别精度。

图11 NTU RGB+D 60 数据集上显著性图像特征融合比例实验折线图Fig.11 Changes of learnable attention map for the action of drinking water on NTU RGB+D 60 dataset
最后,将提出的算法与现有方法进行比较。表1 显示了本文方法与现有方法在相似动作数据集上的识别精度对比,由于对比方法没有结合图像语义,无法有效提取相似动作中的细微语义特征,识别精度较低。提出的SIFE-CGCN获得的识别准确率最高,在两个基准上比仅采用局部关节连接的JBAAGCN(双流网络)分别提高了4.6%和6.0%,比仅采用物理连接的ST-GCN 分别提升了14.8% 和15.3%。可见,显著性语义强化以及骨架中心连接结构能够使模型更好地学习相似动作间的关节运动细微差异,一定程度上提升对相似动作的识别能力。
表3 显示了本文方法与现有方法在NTU RGB+D 60 数据集上对60 种动作识别的结果对比。用于比较的方法包括基于手工特征的方法、基于RNN 的方法、基于CNN的方法和基于GCN的方法。

表3 NTU RGB+D 60数据集上与其他方法识别精度对比Table 3 Comparison of accuracy with other methods on the NTU RGB+D 60 dataset/%
由表3 可见,基于手工特征的方法提取特征单一,无法体现动作的多样性特点,识别精度较低;基于深度学习的方法可以自动提取相对丰富的动作特征信息,用于动作识别整体效果较好,其中基于RNN 的方法侧重于对时间域中的动作特征提取,但忽略了空间域中的特征;基于CNN 的方法受限于欧氏数据,对骨骼的空间连接结构提取较差;两种方法在X-Sub 基准上的识别精度未超过85%,在X-View基准上的识别精度未超过93%。传统基于GCN 的方法,采用连接的邻接矩阵进行空间特征提取,而CGCN 在空间域中增加了骨架中心连接,在空间域的特征提取能力更强。本文提出的SIFE-CGCN 模型结合了显著性图像特征,能够实现对动作识别的修正优化,识别精度在两个基准上较次优模型FGCN(feedback graph convdutional network)分别提高了1.4%和0.6%,证明了本文方法的优越性。图12 显示了SIFE-CGCN 模型在NTURGB+D 60 数据集上的识别精度混淆矩阵。可以看出,模型的识别精度总体较高,仅相似动作中的吃饭、穿鞋、读书和写字4 个动作类别识别准确率低于80%。这些动作的骨架序列与其他动作相似且图像语义特征不显著,导致识别过程中易出现误识别。

图12 SIFE-CGCN模型在NTU RGB+D 60数据集上的识别精度混淆矩阵Fig.12 Confusion matrix of recognition accuracy of SIFE-CGCN model on NTU RGB+D 60 dataset
NTU RGB+D 120 数据集涉及更多动作样本和类别,因此更具挑战性。表4 显示了本文方法与目前先进的方法在NTU RGB+D 120 数据集上的比较结果。比较方法包括基于手工特征的方法(Hu 等,2015)、基于RNN 的方法(Liu等,2018)、基于CNN 的方法(Ke等,2017)以及当前效果最好的基于GCN 的方法。可以看出,本文模型在X-Sub 和X-Set 基准分别达到了87.1% 和88.5%。相较次优的FGCN(Yang 等,2022)分别提高了1.7%和1.1%。由此可见,结合图像语义特征后,模型的整体识别性能及鲁棒性也得以提升。
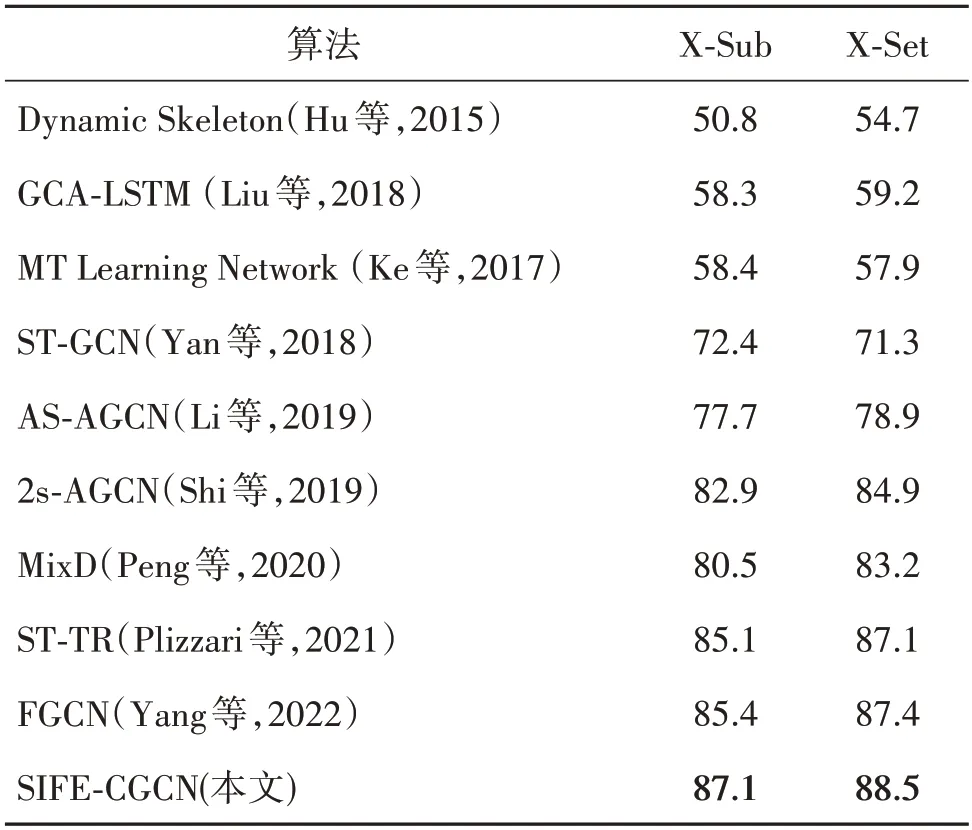
表4 NTU RGB+D 120 数据集上与其他方法识别精度对比Table 4 Comparison of accuracy with other methods on the NTU RGB+D 120 dataset/%
4 结论
针对基于骨架的动作识别方法在识别相似动作时容易出现识别混乱的问题,本文提出一种基于显著性图像语义特征强化的动作识别方法。通过建模人体所有关节与骨架中心的特征依赖,使模型能够更好地学习相似动作间的细微差异;通过高斯混合背景建模法获取显著性图像,采用VGG-19 模型提取图像中动作语义特征,用于优化动作识别结果,提升模型对相似动作的识别能力。在相似动作数据集和NTU RGB+D60/120 数据集上与最新的方法进行比较,实验结果表明,本文算法提高了相似动作识别的准确性,识别准确率高于现有的方法,具有一定的优势性。但是,从实验结果来看,尽管本文提出的模型取得了更高的识别精度,误识别情况仍然存在,而这些动作具有相似图像语义的动作。因此,后续的工作会继续优化显著性语义特征提取流程,融合多类型数据进行动作识别,进一步提高对相似动作中显著差异特征的提取能力。另外,本文实验部分仅使用了室内数据集,将提出的模型应用于户外复杂场景中的动作识别也是未来的主要研究工作。
