基于文本增强的共注意机制的多模态标签推荐
2023-09-18冯皓楠何智勇马良荔
冯皓楠,何智勇,马良荔
(海军工程大学 电子工程学院, 湖北 武汉 430000)
社交网络是产生于大数据时代的一类重要的互联网应用,新型社交媒体平台(如Twitter、Instagram、微博等)已经快速发展成为影响力广泛的新媒体平台。在此平台上,用户可以通过上传简短的文字和图片来记录生活或表达情感并将其分享给好友。此类社交平台还包含一种特定形式的元数据标签(hashtag),它是一串以“#”为前缀的字符,用于标记博文中的关键字或主题,标签在方便用户与其他人进行互动的同时也可以增强帖子的话题度。例如,在Instagram上,有至少一个标签的帖子比没有任何标签的帖子的用户参与度高出12.6%。同时,hashtag已经被证明在许多任务中都是十分有帮助的,包括情感分析[1]、信息检索[2]和主题提取[3]等。为了方便平台对标签的维护与管理,防止用户随意给博文添加标签造成海量标签数据冗余,在社交媒体平台上进行标签推荐是十分必要的。
在一篇博文的文本和图片的多模态信息中,文本模态占有主导地位,包含了用户想要表达的意思的主要描述信息,这也是许多标签推荐任务只使用文本内容进行推荐的原因,但同时图片模态中也包含了细微的附加信息。所以在对帖子的内容进行建模时,要更注重分析文本模态的信息,全面提取文本的语义信息。并且,图像和文本的相关性建模以及两者之间的交互作用对于更好地了解帖子的语义信息也至关重要,而这也会影响标签推荐的性能。
另外,由于马太效应的影响,多数用户的喜好会在多次迭代后逐渐成为所有用户的“喜好”,导致推荐结果可能丧失了对不同用户的个性化推荐,所以根据用户的特有属性(历史行为、相关偏好等)来给用户推荐可能感兴趣的标签也是本文的研究重点。由于年龄、性别等社会背景的影响,不同用户对相似的多模态内容可能有不同的想法与观点。换言之,面对同一个话题的讨论,不同的用户可能偏好使用不同的标签,这使得个人偏好是标签推荐任务中非常大的影响因素。
图1展示了Instagram的一个示例,文本中提到的bunny只在图片中占了很小的一部分,但是标签中却有#easterbunny,表明文本中常常会指出在图片中占比不重、但用户却十分关心的事物,所以对文本模态的着重分析和对用户的个性化建模十分有必要。同时,图片和文本中都能找到对标签#dog的描述和只能从图片中找到对标签#flower的描述,这也证明了图片模态对此任务也有一定作用。

图1 Instagram的一个示例Fig.1 An example of Instagram
为了给新型社交媒体平台设计一种完整而有效的标签推荐方法,本文提出一个文本增强的共注意机制个性化标签推荐模型,该模型可以同时考虑到帖子中不同模态的信息和不同用户的个性化信息。
1 相关工作
近年来,有许多基于文本内容进行标签推荐的研究,随着BERT[4]在自然语言处理方面的成功,Kaviani等[5]将其应用于生成博文文本的嵌入向量中。Zhang等[6]注意到标签只与博文图像的特定区域相关。因此,他们提出了一个联合注意网络,结合文本和视觉信息来推荐标签。该网络能够同时利用图片和文本信息作为多模态特征,通过注意力机制融合图片注意力和文本注意力,产生图片注意力时,利用文本信息来进行指导;产生文本注意力时,利用图片信息进行指导,以达到提升精度的目的。这个方法明显的优点在于可以考虑到不同模态的数据信息。张素威[7]提出了一个基于异质注意力的图文融合标签推荐模型,既强化了跨模态的共性信息,也考虑了不同模态差异信息间的互补性。Ma等[8]也提出了共注意记忆网络(CoA-MN),合并标签的历史博文来表示这些标签,CoA-MN的结果优于基于分类的方法。
Peng等[9]提出了自适应神经记忆网络,使用卷积层编码博文,使用递归神经网络编码标签,并对用户过去的推文历史进行建模。Kou等[10]结合内容相似度、与使用相似标签的用户的协同过滤和话题兴趣3个特征的权重推荐标签。Javari等[11]从不同角度研究了话题标签推荐,建立了一个基于图表的具有代表性的用户和标签模型,利用神经网络协同过滤方法广义矩阵分解,将具有代表性的用户和标签投影到潜在空间中,并且设置一个关注权重来优化矩阵。Zhang等[12]将图像、文本以及用户习惯的影响集成到一个单一模型进行标签推荐。Alsini等[13]概述了社区检测算法,这些算法用于对志同道合的用户进行分组。文献[14]研究了基于标签使用、话题、关注者和提及率的4种关系对社区话题标签推荐绩效的影响,发现社会关系水平会影响话题标签推荐的效果。
2 模型
本文将任务定义为多标签分类问题。考虑到社交媒体平台数据的特殊性,我们首先提取帖子多模态内容的语义信息,采用层级结构从单词、短语和句子3个层次提取文本特征信息,再将每个层次的特征信息都通过文本汇总注意机制汇总为一个语义特征向量,然后将每个层级的语义特征向量与提取的图像特征向量融合,即文本增强的共注意机制。使用多层感知器(multi-layer perceptron,MLP)递归编码这3个层次的共注意特征,得到总的多模态内容的语义特征向量。另外,用户的个性化推荐模块中外部存储单元使用用户id进行索引,在用户的历史记录中随机采样一部分存储在外部存储单元。计算历史帖子与待推荐帖子之间的相似度影响向量。连接2个模块的输出向量可得全部的特征向量。进行归一化操作后,就可预测出模型推荐的标签。总体模型如图2所示。
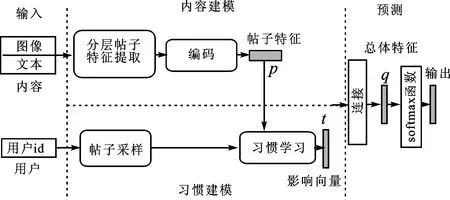
图2 模型总体结构Fig.2 The overall structure of the model
2.1 博文内容的特征提取

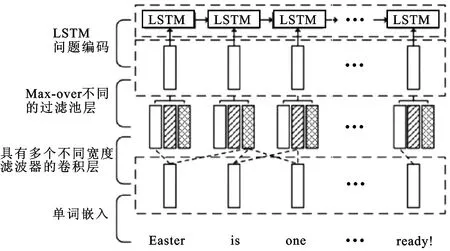
图3 文本层次特征提取Fig.3 Text hierarchical feature extraction
为了计算短语特征,对单词嵌入向量进行一维卷积,在每个词的位置用一字、两字和三字3种窗口大小的滤波器来计算单词向量的内积。对于第t个单词,其窗口大小为s的卷积输出为
(1)
在得到卷积结果后,在每个单词位置的不同多元语言模型上应用最大池化方法来获得短语级特征
(2)
式中t∈{1,2,…,N}。再使用池化方法在每个时间步自适应地选择不同的语法特征,同时保持原始序列的长度和顺序。


2.2 文本增强的注意机制模型
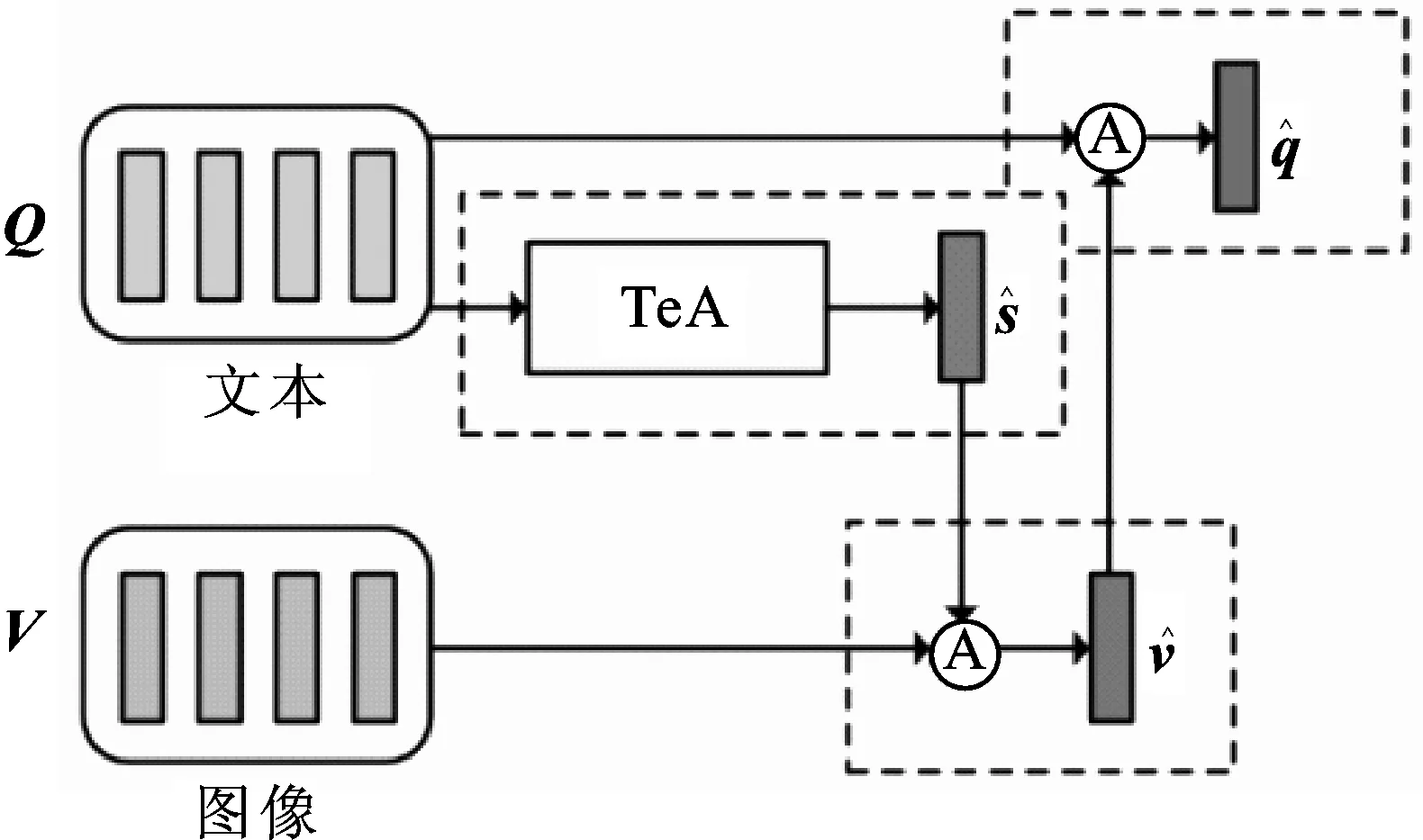
图4 文本增强的共注意机制(CoAtt)Fig.4 Text-enhanced co-attention mechanism
文本内容在经过不同层级的特征提取后,可以通过一个文本汇总注意机制TeA将每个层级特征表示为一个特征向量。例如,单词级的文本汇总注意向量如(3)式所示:
Ht=tanh(WtQw),
(3)

hI=tanh(WvIvI⊙WvTvT),
pI=softmax(WpIhI+bpI)。
(4)
其中:vI∈Rd×m;vT∈Rd;WvI、WvT∈Rk×d;WpI∈R1×k;bpI是参数;m=49;d是特征表示的维度,对应于每个区域的注意概率pI∈Rm是m维向量。另外,使用⊙表示图像特征矩阵和文本特征向量的组合,是将矩阵的每一列用向量连接而得。
基于每个图像区域i的注意概率pi,新的图像表示为图像向量的加权和,如式(5)所示:
(5)
pT=softmax(WpThT+bpT),
(6)

最后,使用多层感知器对3个层级的共注意特征进行递归编码,得到总的帖子特征。如图5所示。
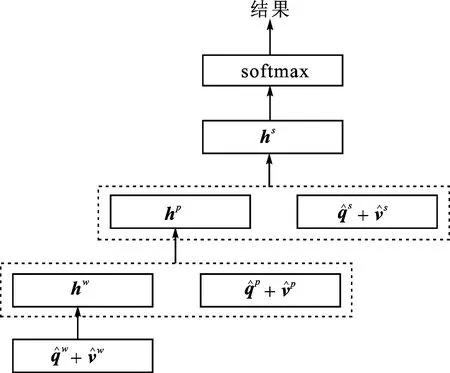
图5 共注意特征编码Fig.5 Co-attention feature encoding
p=softmax(Whhs)
(7)
式中:Ww、Wp、Ws和Wh是权重参数;[·]是对2个向量的串联运算。
2.3 用户的个性化推荐
第一步是随机抽取少量用户的历史帖子。首先分配一个内存单元来存储每个用户的习惯,这个内存单元可以使用用户id进行索引,相应的标签作为外部存储。在对每个用户采样L篇历史文章及其标签时,应将L限制为相对较小的数量,因为用户可能只发布了少量的博文。第二步是学习这些历史博文中用户使用标签的习惯。用户个性化建模的主要流程如图6所示。
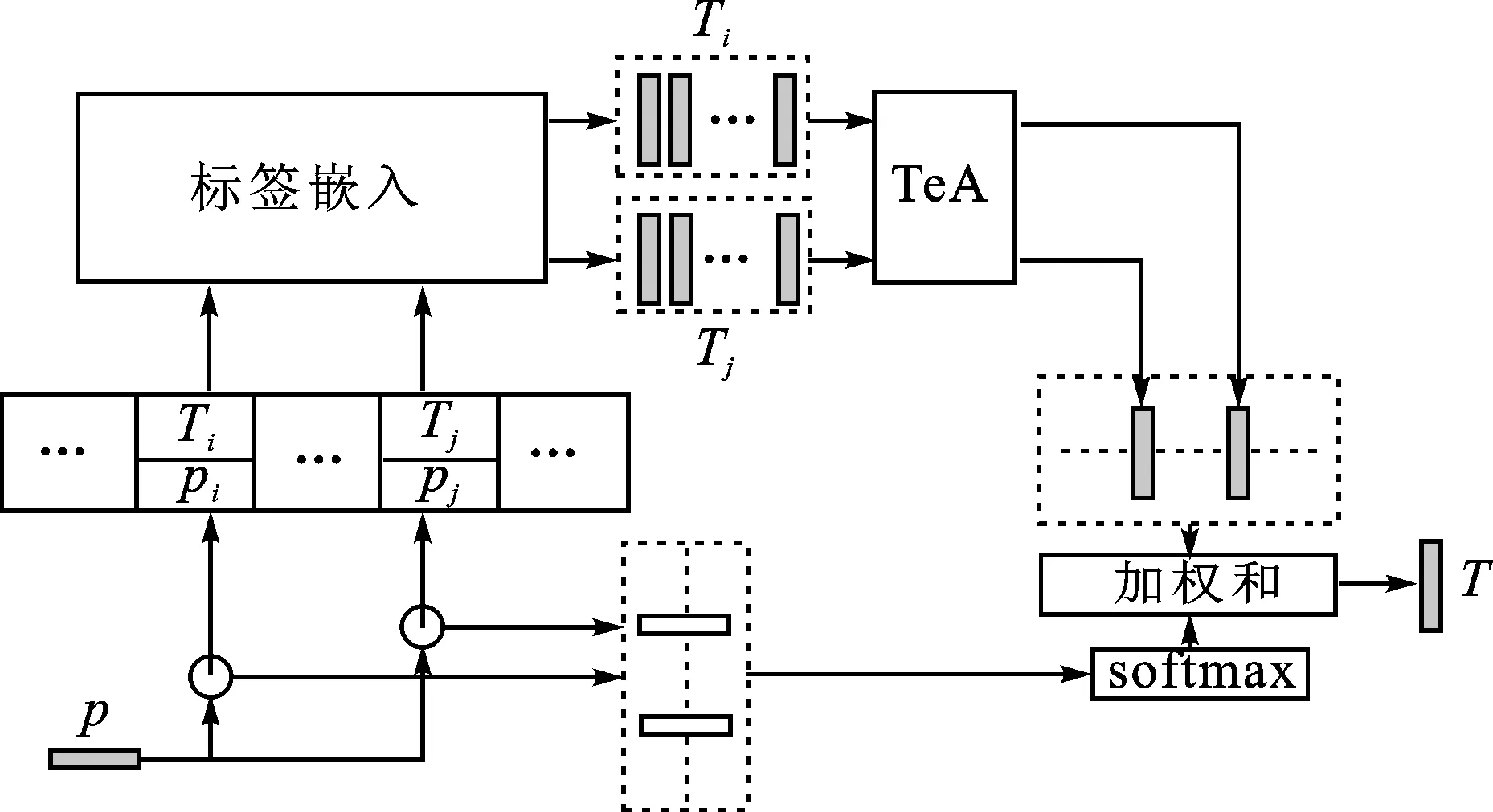
图6 用户个性化建模Fig.6 User personalized modeling

(8)
式中:⊙表示元素的乘法;ri表示当前查询帖子与第i个历史帖子的相关向量。结合所有相关向量,可得相似度矩阵r=[r1,r2,…,rL],进而可以计算出每个历史博文的权重
(9)
式中:Ws∈Rd;bs∈R是参数;as∈RL是一个包含历史文章权重的向量。最后,影响向量
(10)
3 实验
在实验环节,实验设置为Ubuntu 20.04、CPU i9-10900X、64 GB内存、NVIDIA GeForce RTX 3090,实验所需环境为Python3.6、TensorFlow1.4、Keras版本为2.1.5、Numpy版本为1.19、H5py、Scipy。
3.1 数据集
本实验使用文献[12]中从Instagram上收集的数据集。首先,随机选择15 000多名用户并抓取他们所有的帖子;其次,删除一些低频的标签和单词,并保留包含图像和文本以及至少一个标签的帖子,其中少于5个单词的帖子也会被删除;最后,如果用户在数据集中的文章少于20篇,删除该用户及其文章。最终的数据集包含7 497个用户的624 520条帖子,有3 896个独特的话题标签和212 000个不同的单词。
3.2 实验设置
模型训练使用随机梯度下降,优化函数使用Adam优化算法,dropout设置为0.75,batch_size设置为512,embedding_size设置为300,博文文本序列的最大长度为30,博文图片尺寸为224×224,并使用预先训练的VGG-16网络进行训练,博文标签的最大长度为48,外部存储的内存大小L=2。数据集中随机选取90%的数据作为训练集,剩下的10%作为测试集。
采用的评价指标包括精度(precision,记作Pr)、召回率(recall,记作Rc)和F1分数(记作F1)。例如,Prk表示每个帖子推荐使用K个标签时的精度值,其中K={1,3,5,7,9}。这3个指标的数值越高越好。
3.3 对比模型
CoA (Co-Attention)[6]是目前最先进的针对多模态帖子(包含文本和图像)的话题标签推荐方法。该模型提取帖子特征后利用协同注意机制进行跨模态融合,然后通过分类方法预测出推荐的标签。
MaCon[12]是一种结合了共注意力网络和用户个性化信息的多模态标签推荐方法。它采用并行协同注意的方法理解多模态帖子特征,并学习用户喜好习惯等信息以获得更好的推荐结果。
3.4 实验结果
从表1中观察到,本文所提方法在所有3个评估指标上都明显优于其他对比模型。与CoA模型相比,当K在1到9之间变化时,本文方法在精度、召回率和F1分数方面分别可以提高12.6%~23.1%,9.6%~23.7%和11.6%~14.6%。与MaCon模型相比,当K在1到9之间变化时,本文方法在精度、召回率和F1分数方面分别可以提高4.6%~8.1%,4.0%~9.6%和4.7%~7.3%。这些显著的改进证明了本文方法的有效性。
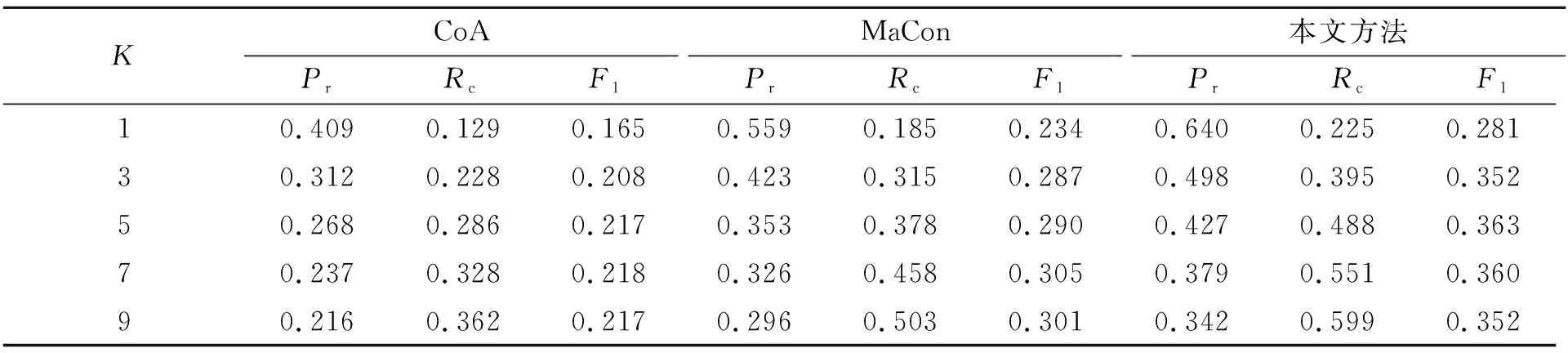
表1 实验结果Tab.1 Experimental results
在比较方法中,MaCon方法比CoA方法的效果要好,这可能是由于MaCon方法对用户进行了个性化建模,说明了对用户个性化推荐的有效性。而在同样都有用户个性化建模的本文方法和MaCon方法中,本文方法的效果也有所提升,这主要是由于我们将文本内容进行了3个层级的提取,在每个层级上都进行了文本注意汇总,并与图片特征进行了文本增强的共注意特征融合,多方位地关注了图像的各个区域。总体来说,本文提出的文本汇总注意机制和文本增强的注意机制方法在帖子内容信息的提取方面非常有效,并且用户的个性化建模也对实验结果有所帮助。
4 结语
本文提出了一种文本增强的共注意机制,在社交媒体平台上进行多模态主题标签推荐任务。由于博文和图片在此任务中并不是同等重要的,文本在多模态内容中起主导作用,因此我们使用了文本层级特征提取。在每个层级都构建了文本内容汇总注意机制,以汇总文本在不同层级的语义特征。并且构建了文本增强的共注意机制,在3个层级上与图片特征进行融合。同时,还加入了用户的个性化建模,对用户历史数据随机采样并存入外部存储单元,计算待推荐帖子与历史帖子的相似度影响向量。实验结果表明,在采用的3个评价指标下,本文模型的性能优于现有2种对比模型(CoA和MaCon),这说明文本汇总机制中使用文本层级特征提取和在不同层级与图片特征融合的方法都对提取多模态特征起到了重要作用,同时用户的个性化模态也取得了很好的效果。
