基于残差注意力和半监督学习的图像去雾算法
2023-09-18于莲芝
孙 曦,于莲芝
(上海理工大学 光电信息与计算机工程学院,上海 200093)
自卷积神经网络面世以来,计算机视觉技术蓬勃发展,涌现出了目标检测/追踪、图像分割、图像去噪去雾等视觉任务。在图像领域,低级视觉任务影响了高级视觉任务的驱动。在无人驾驶技术上,一张干净的图片可以提高检测精度,从而提高乘客的安全系数。在雾霾天气下,由于在传播过程中光线被浑浊介质吸收和散射,导致空气中的悬浮颗粒物影响外景拍摄。在无雾条件下,场景元素反射来自光源的能量,到达成像系统时能量损失较小,成像系统把从场景元素反射进来的能量聚焦到成像平面上[1]。而在有雾的情况下,图像会出现对比度下降、颜色变暗和目标能见度降低等问题,从而影响目标识别和检测等高级视觉系统的性能。因此,视觉系统若要在生活中得到普及,就必须考虑到图像去雾技术。
近年来,随着图像去雾技术研究的不断深入,出现了大量单幅图像去雾算法,其中较为著名的有暗通道去雾算法、DehazeNet以及AOD-Net(All-in-One Dehazing Network)等。这些算法可以分成两类:基于传统先验的算法和基于深度学习的算法。
基于传统先验的算法主要是基于大气退化物理学模型,通过一些先验方法对模型的未知量进行估算,从而恢复出干净的图像,其中最经典的方法是暗通道先验算法。文献[2]在观察到干净无雾图像的暗通道比朦胧图像的暗通道稀疏的基础上提出了一种基于有雾图像来加强稀疏性图像恢复的方法,但该方法在图像景深处的细节易被忽略。文献[3]提出了一种通过矫正亮区域的透射率参数来改进暗通道先验的方法。文献[4]提出了颜色衰减先验方法,通过计算朦胧图像场景深度来估计大气光值,从而实现图像去雾。文献[5]以干净图像的不同彩色特性作为估计有雾图像对应无雾图像颜色的先验。文献[6]以一种全卷积的网络估计出了更准确的透射率。
基于深度学习算法通过搭建各种神经网络模型来训练大量的数据,从而让模型学习到图像的细节,以达到去雾的目的。文献[7]提出了一种端到端的网络模型DehazeNet来直接估计有雾图像与透射率之间的映射关系,并通过大气退化模型来重建干净图像,但是不准确的透射率会导致图像失真。文献[8]提出了一种轻量级的网络AOD-Net,其为端到端的网络,网络末端可以直接输出干净图像。随着GAN(Generative Adversarial Network)网络的蓬勃发展,基于GAN网络改进的一些网络也陆续被运用到图像领域中。文献[9]提出CycleDehaze的端到端网络,该网络利用不成对的雾图和真实图训练并加入循环和感知一致性损失来约束网络。文献[10]提出了GCANet(Gated Context Aggregation Network),其用平滑扩张卷积代替原来卷积层,有效解决了网格伪影的问题。
基于大气退化模型的去雾算法仅使用统计学估计透射率和大气光成分,因此该算法计算出的去雾图像亮度偏暗,部分图片出现了较为明显的失真。基于有监督网络学习模型使用的训练数据是成对的合成有雾图像,但是合成有雾图像与真实有雾图像存在域间隙,所以该方法在真实有雾的图像上呈现的效果并不理想。文献[11]针对此类问题提出了一种半监督图像去雾网络,通过不同分支使网络在训练时不仅能够学习到合成有雾图像的信息,还能学习到真实有雾图像的细节信息。文献[12]提出了一种域自适应算法,通过将图像从一种域转换到另一种域来弥补合成图像与真实图像之间的差距。
本文提出了一种半监督框架的去雾网络,由成对的合成图像和真实有雾图像共同组成输入数据。在残差块中,通道注意力和像素注意力相结合的方式可以更好地处理不同类型图片的雾浓度信息。编码器使用SOS(Strengthen-Operate-Subtract)策略将多个尺度的特征增强拼接到解码器中,增强了图像的特征恢复能力。整个网络使用两类损失函数分别进行监督,其中使用暗通道损失和全变分损失来约束真实有雾图像。
1 半监督去雾算法
去雾算法发展至今,已出现了大量基于深度学习的网络模型。由于真实生活中很难取到同一场景下干净和有雾的图像,所以大多数网络都是通过成对的合成图像来进行训练,合成图像大多数是由设置大气光率生成。然而合成图像和真实图像存在一些细节方面的较大差异,故有监督学习的去雾算法对真实雾图的泛化能力普遍较差。如图1所示,左边合成雾图中雾的浓度较为均匀,而真实有雾图像的雾浓度分布不均,根据景深而变化。本文将网络应用在有监督分支和无监督分支这两个分支,本文的数据集分为成对的合成有雾图像、干净图像的组合和单张现实生活中的有雾图像,不同的分支对应不同的图像输入,同时分别使用不同的损失函数对两个分支进行约束训练。最终训练后的网络既可以应用在合成数据集中,也可在真实数据集上取得较好的效果。

图1 合成雾图与真实雾图之间的差异Figure 1. Differences between synthetic and real fog maps
2 本文模型结构
2.1 多尺度残差生成器
生成器由编码器和解码器组成,具体结构如图2所示。编码器意在逐渐减少特征图的维度并捕获细节和更高级的图像特征,解码器则能够恢复提取到的对象特征和维度[13]。网络结构的编码器部分包含3个尺度的注意力残差块和下采样层(卷积层)。卷积层输入通道分别是3、64、128,输出通道数为64、128和256,卷积核使用的是7×7、5×5和3×3。受到FFA-Net(Fusion Feature Attention Network)的启发[14],本文将通道注意和像素注意融合的方式自适应地学习特征权重,让网络更加关注厚雾区、色彩纹理等有效信息。注意力残差块如图3所示,其中通道注意使用1×1尺寸的卷积核,像素注意采用3×3尺寸的卷积核。该网络在残差块中没有应用批量归一化层,而是采用ReLU(Rectified Linear Unit)作为全局的激活函数。为了缓解随网络加深而出现的梯度消失情况,本文采用残差连接嵌入在每个残差块中。为了更好地融合之前特征,解码器采用SOS增强合并[15]的方式来确保网络更细腻地恢复特征,SOS增强结构如图4所示。编码完成后进入由6个注意力残差块组成的恢复模块。解码器的主干部分由3个尺度的注意力残差模块和由转置卷积组成的上采样层构成。在解码器中,输入输出通道数与编码器中相对应,使用4×4、4×4和7×7的卷积核。该结构通过带步长卷积层来实现对中间过程特征图的下采样,通过该操作使特征图的宽高尺寸变成原来的一半。解码器使用了转置卷积层来使输入特征图的宽高变成原来的两倍。
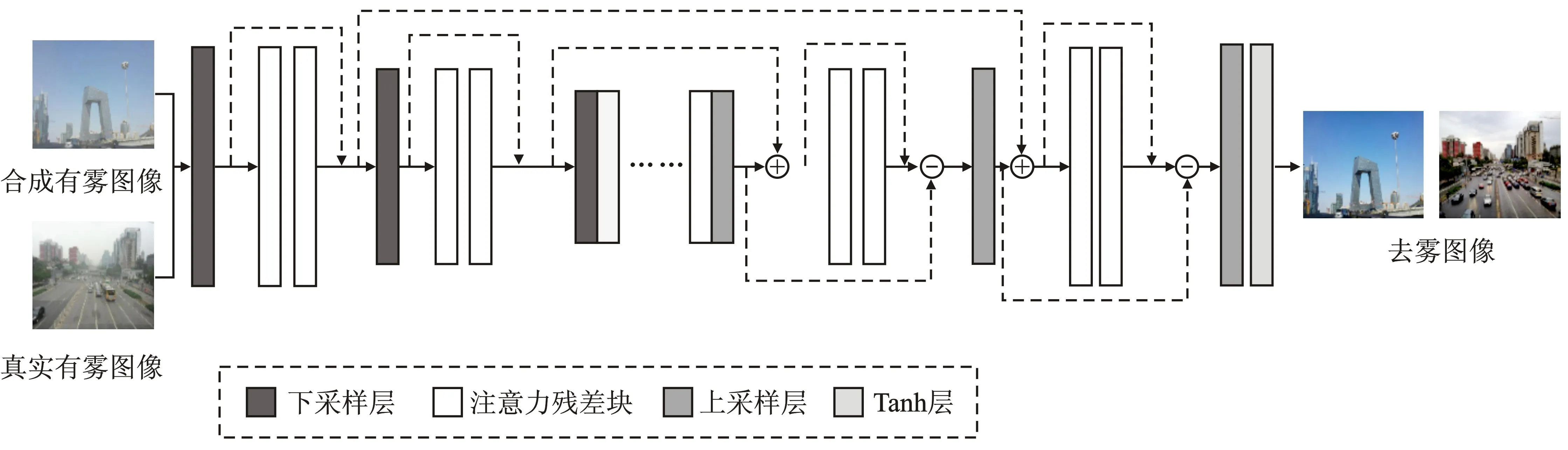
图2 生成器网络框架Figure 2. Generator network framework

图3 注意力残差块结构Figure 3. Structure of attention residual block

图4 鉴别器网络结构Figure 4.Structure of discriminator network
2.2 鉴别器
对于对抗学习,本文仿照CycleGAN[16]中的PatchGAN,采用了一个简单的5层分类器的结构,其由卷积层、LeakyReLU激活函数和BN(Batch Normalization)层构成,具体结构如图4所示。鉴别器首先将图像分割成N×N的Patch,每个分割后的感受野在整幅图片进行滑动,最后输出所有Patch的平均值。为防止发生因学习率偏大导致部分神经元不能被激活的情况,本文采用LeakyReLU激活函数来代替ReLU函数。BN层的应用则是为了对中间过程提取到的特征图进行归一化处理。本文在网络的最后一层之后加入了Sigmoid函数,使概率得分分布在[0,1]。
2.3 SOS增强模块
为了更好地完善卷积提取到的信息特征,在解码器部分中加入SOS增强模块,模块结构如图5所示。SOS增强策略已被应用到了图像去噪方面,可以用来提升峰值信噪比。文献[15]在此基础上扩展出了5种用于增强解码的模块。为了采集到更多的结构和空间信息,在解码器部分设置了SOS增强策略

图5 SOS策略Figure 5.SOS strategy
(1)
2.4 损失函数
对于送入网络的合成图像和真实图像的差异,本文采用两个分支不同的损失函数来约束网络。
2.4.1 有监督损失函数
均方差损失函数:给定有雾图像I,δ(·)为本文所应用的网络结构,δ(I)为经过网络输出的去雾后的图像。该损失利用预测值和标签值之间的差值平方和的均值来约束网络,计算式如下
(2)
式中,n表示一次送入网络的批量;i表示第i张图像。均方差损失意在让去雾图像逐渐逼近真实无雾图像J。
VGG(Visual Geometry Group)损失(又称感知损失):该损失基于VGG-19预训练模型输出的特征图。该特征图是通过VGG-19网络结构的Conv3-3层之后输出的。VGG-19预训练模型由ImageNet数据集训练而来[17],计算式如下
(3)
式中,φ(·)表示VGG-19的预训练网络。感知损失是将生成后的去雾图像经过VGG-19提取到的特征与真实无雾图像的特征作对比,使它们的高层细节结构信息接近,用来增强细节处理。
生成对抗损失:本文设计的生成对抗网络由生成器和鉴别器构成。生成器输入一张有雾图像,得到一张去雾后图像,鉴别器分辨出送入图像来自于生成器输出还是真实图像。因此在定义损失函数时,需要约束生成器生成可以迷惑鉴别器的“假”图像,约束鉴别器可以正确区分去雾后的图像与真实无雾图像。生成器和鉴别器的损失函数分别定义为
La=Eδ(I)[log(1-D(δ(I)))]
(4)
Ld=EJ[log(D(J))]+Eδ(I)[log(1-D(δ(I)))]
(5)
式中,D代表鉴别器。在应用损失函数时,理想情况是在训练鉴别器时,使目标函数越来越大,训练生成器时,使目标函数越来越小。在具体的训练过程中,通常在优化鉴别器n次的基础上才会优化生成器一次,这样能使鉴别器的损失快速达到最优。
SSIM(Structural Similarity)损失函数:为了生成与真实图像更加相似的细节,本文应用SSIM损失函数,该函数又称结构相似性损失。该损失可以约束生成的无雾图像与对应的真实无雾图像的结构相似性。SSIM由3部分组成,分别是亮度、对比度和结构,分别为
(6)
(7)
(8)
式中,u、σ和σ2分别代表图像之间的均值、标准差和方差。最终的损失函数表示如式(9)所示。
LSSIM=1-L(δ(I),J)×C(δ(I),J)×S(δ(I),J)
(9)
2.4.2 无监督损失函数
暗通道损失函数:文献[2]根据多张室外无雾图像统计规律提出暗通道先验理论,该理论在去雾领域取得了较好的应用效果。暗通道理论就是在大多数的室外无雾图像中(除天空区域)的每个区域都至少存在一个灰度值较低的通道。根据这一理论,暗通道计算式如下
(10)
式中,x和y分别表示图像I的像素坐标;Ic表示第c个颜色通道;N(x)表示以像素x为中心的局部区域。根据暗通道的定义,得出的暗通道图像的像素强度应接近于0。暗通道损失是在所有输出去雾图像的暗通道上求其L1范数的均值,该函数具体定义如式(11)所示。
(11)
全变分损失函数:全变分损失在图像领域多用于去噪复原。总变分定义为梯度幅值的微分,可以用来限制噪声和平滑图像。本文通过限制有雾图像的像素点的梯度来约束网络,计算式为
(12)
其中,∇x和∇y分别为图像矩阵在水平和竖直方向上的微分,利用L1范数使两个梯度接近于0。
本文一共结合了两个分支的6个损失函数组成,总损失可以表示为
L=αLmse+βLper+γLa+εLSSIM+ιLdark+ηLtv
(13)
式中,α、β、γ、ε、ι、η为各个损失函数的权重。
3 实验与结果分析
3.1 数据集和标价指标
本文采用RESIDE(REalistic Single Image Dehazing)数据集[18]训练合成有雾图像。该数据集包括合成有雾图像和真实有雾图像,具体分为5个子集,分别是室内训练集(Indoor Training Set,ITS)、室外训练集(Outdoor Training Set, OTS)、合成的客观测试集(Synthetic Objective Testing Set,SOTS)、混合的主观测试集(Hybrid Subjecive Testing Set,HSTS)和真实的任务驱动测试集(Real-world Task-driven Testing Set,RTTS)。
本文训练时选用RESIDE数据集中的室内数据集和室外训练集,从中随机选取4 000对作为有标签数据集。本文还在未注释的真实朦胧图像中选取3 000幅真实有雾图像作为无标签数据集。在每一个epoch中,从两个数据集中分别随机选择6 000幅成对图像和3 000张真实有雾图像共同组成本次epoch的训练数据。本文将图片随机截取成256×256的图像块作为网络的输入。
选用PSNR(Peak Signal to Noise Ratio)和SSIM作为评价指标。PSNR又称峰值信噪比,是一种客观评价标准。PSNR基于对应像素点间的误差,是一种基于误差敏感的图像质量评价指标,其数值越大表示图像失真越小。SSIM又称结构相似性,是一种衡量两幅图像相似度的指标。SSIM分别从结构、对比度和亮度3个方面来度量图像的相似性,其取值范围为[0,1],数值越接近于1表示图像越相似。
3.2 训练细节
本文采用NVIDIA GeForce RTX 3090显卡,共设置了200个epoch,其中前100个epoch采用初始学习率1×10-4,后学习率线性衰减直到降到1×10-6。本文将batchsize设为8,使用Pytorch中的Adam优化器来有优化本文网络。为了让鉴别器更快地收敛,采用每一次迭代更新1次生成器的同时更新5次鉴别器的方法在Pytorch框架上完成实现。
3.3 实验结果及对比分析
本文所提算法基于合成客观测试集上的定量评估。室内和室外分别随机抽取150幅图像组成本文的测试集,并与国内几种先进且具有代表性的单图像去雾方法进行比较。如表1所示,采用4种不同的先进的定量评价方法:DCP(Dark Channel Prior)、AOD-Net、GCANet、SSID(Semi-Supervised Image Dehazing)。其中,暗通道算法是基于传统先验的方法,对于绝大多数的非天空区域,在R、G、B这3个通道中总有一个通道的像素值非常低,从而估计出透射率。后3种是基于网络学习的方法。K-estimating模块是AOD-Net的重要部分,模型中使用5个卷积层,每个卷积层只使用3个卷积核[8],并通过融合不同的卷积核来形成多尺度特征。GCANet模型由3个卷积块作为编码器,且最后一个卷积选择了下采样。本文利用7个平滑扩张组成的残差块,并通过门限融合子网络来融合上下文特征,最后使用1个反卷积块和两个卷积块来得到最终的残差图[10]。SSID用来对比半监督的去雾框架,使用带有跳跃连接编码解码架构,中间由残差卷积块组成[11]。测试结果如表1所示,可以看出本文所提算法在一定程度上优于之前所有去雾方法。基于网络学习的方法均超过了基于先验的算法。由结果可知,本文提出的方法在两个指标上均取得了最高的数值,本文方法性能比SSID半监督方法的PSNR和SSIM分别高了3.387 dB和0.068。
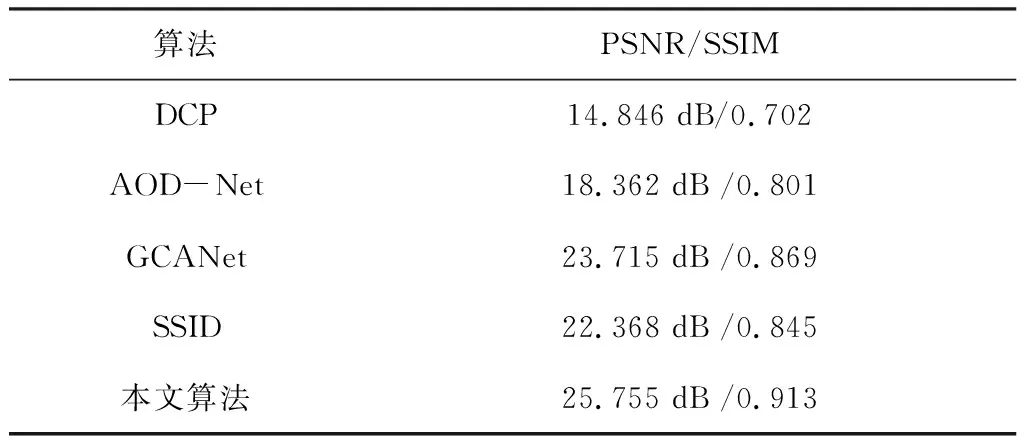
表1 不同算法在测试集上去雾指标对比Table 1. Index comparison of different algorithms in the test set fog
由于人眼对亮度比对颜色更加敏感,故通常需要将RGB通道转换为YCbCr通道。表2展示了不同算法在测试集上仅计算Y分量的PSNR值,其中在对比算法上加入了有关Transformer的算法。

表2 不同算法在测试集上去雾指标对比(Y通道)Table 2. Index comparison of different algorithms in the test set fog (Y channel)
DehazeFormer的框架基于Swin Transformer,其改进了归一化层、激活函数和信息聚合方案,还提出了SK(Selective Kernel)融合层和软重建模块来代替串联融合和全局残差学习[19]。从整体上看,本文算法的PSNR指标在仅计算Y通道的实验中达到了最优,其PSNR指标比位于第二的DehazeFormer-t高出0.63 dB,且大幅度高于其余算法,这进一步证明本文设计的算法能够有效解决去雾时亮度失真的问题。本文从测试集中随机选取100幅有雾图像,并且统一在一台带有NVIDIA GeForce RTX3090显卡的计算机上执行。如表3所示,本文提出的模型在处理图片上速度最快,去雾时间明显短于其余算法。

表3 不同算法处理图像的平均运行时间 Table 3. The average running time of different algorithms processing images
本文在SOTS数据集上选取4幅图像用于主观质量的定性比较。如图6所示,上面两行为室内图像的去雾结果,下面两行为室外图像的结果。从视觉结果上来看,DCP算法去雾后的图像颜色偏暗,室外图像的天空区域失真明显存在色差。AODNet在景深区域存在去雾不彻底的情况,天空高亮区域的颜色发暗,这导致去雾后的室内图像过亮而室外却过暗。GCANet的第4幅去雾图像在天空区域出现明显失真,深处的建筑物有灰暗色模糊块。SSID算法的缺点是在天空区域有一些颜色偏暗的部分(第3幅),但整体的色彩分布和真实图像差别不大。DehazeFormer-t模型去雾后的室内图像在远处仍然会产生一些模糊的灰色伪影(第2幅右上角),去雾后的室外图像效果较好。本文所提方法在去雾后的图像可以有效去除近景和远景的雾霾并且保证图像色泽更加自然,恢复后的图像能够保留更好的纹理和颜色信息。
本文在主观测试集上进行了现实世界中真实有雾图像的去雾处理,结果如图7所示。在面对雾浓度不均匀的真实图像时,DCP去雾后的图像颜色整体失真严重且出现局部过亮的情况。AODNet方法可以去除部分雾,但存在去雾不彻底的现象,部分的建筑物颜色加深。GCANet出现了与DCP一样的问题,远处建筑雾的细节模糊发亮,并且建筑物的颜色明显失真。SSID恢复的图像在天空高亮区域存在色块不均匀且底部纹理变得模糊发暗。DehazeFormer-t对图像中远处的雾无法彻底清除且出现模糊块(例如第2幅的立交桥),图像中间的大楼也出现了小的失真块。本文所提方法不存在色彩不均匀的情况,但仍存在去雾不彻底的情况。

图7 不同去雾方法在真实数据集上的比较(a)Hazy (b)DCP (c)AODNet (d)GCANet (e)SSID (f)DehazeFormer-t (g)本文算法Figure 7. Comparsion of deffierent dehazing methods on real data sets(a)Hazy (b)DCP (c)AODNet(d)GCANet (e)SSID (f)DehazeFormer-t (g)The proposed algorithm
3.4 消融实验
为了验证本文提出的残差注意力模块、SOS融合策略和SSIM损失函数的有效性,在SOTS数据集上进行定量分析。其中包括模型1(仅使用SSIM损失)、模型2(在模型1基础上加入残差注意力)和模型3(最终模型)。上述实验的峰值信噪比指标如表4所示。向模型加入SSIM损失后可以更好地约束网络从而提升图像质量,且本文引入的残差注意力模块对提升图像质量分数具有明显效果,证明了本文使用模块的有效性。
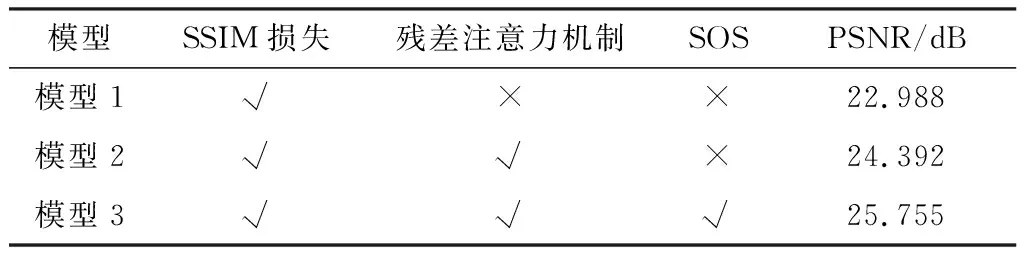
表4 模型结构消融实验结果Table 4. Experimental results of model structure ablation experiment
4 结束语
本文提出了一种端到端半监督学习框架的单幅图像去雾网络。该网络基于编码-解码结构,其中的残差注意力模块提升了网络的重要特征提取能力,SOS策略使多特征融合能够更好地恢复细节信息。本文将合成数据和真实数据分别送入不同分支进行训练,两个分支共享权重,两种损失函数分别监督不同分支,使模型具有较好的鲁棒性。实验结果证明,本文所提方法相比于对比方法在合成数据和真实数据上具有更高的定量指标和更好的视觉效果。
