基于FA-SVR-LSTM组合模型的短期电力负荷预测
2023-09-18文彦飞王万雄
文彦飞,王万雄
(甘肃农业大学 理学院,甘肃 兰州 730070)
短期电力负荷预测是确保电网系统平稳高效运行的重要内容之一,是电力供需平衡的基础,在提高国家电力行业的经济效益和维持社会稳定发展等方面具有重要作用。电力负荷预测按周期长短可分为短期电力负荷预测、中期电力负荷预测和长期电力负荷预测。其中,短期电力负荷预测指天[1]、周和季节的系统变化,是热门的研究课题之一[2-4]。当前,对电力负荷研究的主流方法包括时间序列预测[5]、智能算法[6]和组合模型[7]等方法。其中,时间序列预测方法虽然对线性数据处理效果较好,但该类方法在处理非线性数据时的拟合效果不佳。智能算法主要包括机器学习方法和深度学习方法两个方面,主要包括随机森林算法[8]、BP(Back Propagation)神经网络[9]等。智能算法虽然能有效处理非线性问题,但在处理大样本数据时计算速度慢且计算效率低。组合模型的原理是结合不同单一模型的优点,在提高效率的同时提高预测精度[10]。此外,组合模型充分利用了单一模型的优势,提供了比单一模型更稳定和更可靠的预测结果,因而具有更重要的研究价值,在经济、工业等领域得到了广泛应用[11-12]。文献[13]利用粒子群优化(Particle Swarm Optimization,PSO)算法优化LSTM模型的参数,提高了预测精度。文献[14]结合LSTM模型处理长时间序列的优势和SVR模型处理非线性问题的优点,并利用果蝇优化算法优化参数建立组合模型,对短期卷烟销量与烟用白卡纸价格数据进行预测并取得了较好的成果。
在电力负荷预测中,SVR模型虽然具有预测精度高、速度快等优势,但该模型中的参数惩罚因子c和核参数g取值会影响预测效果[15]。LSTM模型不仅能够有效避免在运算过程中出现的梯度消失和梯度爆炸问题[16],还对非线性数据样本具有较强的拟合能力。本文结合了SVR模型和LSTM模型的优点,采用FA算法对SVR模型的惩罚因子c、核函数参数g和LSTM模型神经元个数m、学习率lr进行优化处理。在此基础上,建立FA算法优化的SVR-LSTM模型,即FA-SVR-LSTM组合模型,并同时建立LSTM、SVR、FA-SVR与FA-LSTM这4个参照模型共同对短期电力负荷时间序列进行预测。
1 模型简介
1.1 LSTM的基本理论
LSTM模型是在循环神经网络(Recurrent Neural Network,RNN)的基础上改进的一种特殊循环网络类型,该模型可以较好地解决长期依赖的问题,所以LSTM神经网络模型更适用于长期非线性时间序列预测。相比于单一循环体结构,LSTM模型是具有3个“门”结构(遗忘门、输入门和输出门)的特殊网络模型。
LSTM模型的网络结构如图1所示。在LSTM模型中,xt是t时刻的输入数据,ct-1表示在t-1时刻的网络细胞的记忆值,ht-1则为t-1时刻LSTM模型的输出值,t时刻模型的分别为输出值ct和ht。
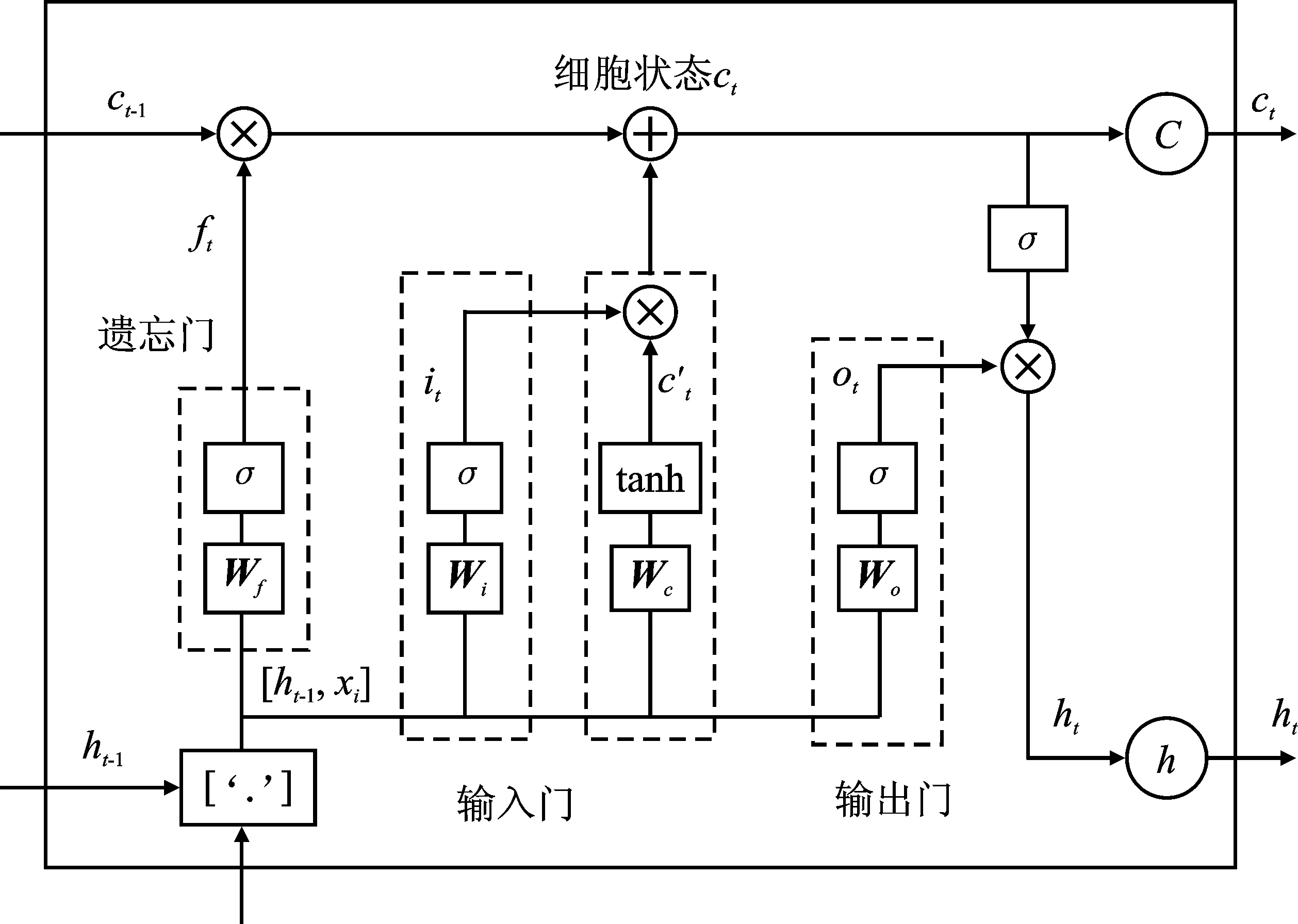
图1 LSTM网络结构Figure 1. LSTM model network structure
遗忘门(Forget Gate)决定上一时刻的单元状态ct-1保留到当前时刻的单元状态ct的数量,计算式如下
ft=σ(Wf×[ht-1,xt]+bf)
(1)
其中,Wf为遗忘门的权重矩阵;[ht-1,ct]表示把两个向量连接成一个更长的向量;bf是遗忘门的偏置项;σ为Sigmoid函数。
输入门(Input Gate)决定当前时刻网络的输入xt保存到单元状态ct的数量,计算式如下
it=σ(Wi×[ht-1,xt]+bi)
(2)
式中,Wi表示输入门的权重矩阵;bi为遗忘门的偏置项。
上一次的输出和本次输入决定当前输入的单元状态c′t,计算式如下
c′t=tanh(Wc×[ht-1,xt]+bc)
(3)
其中,ct表示当前时刻的单元状态,由上一次单元状态ct-1乘以遗忘门ft与当前输入的单元状态c′t乘以输入门it后,两者相加得到。
ct=ft×ct-1+it×c′t
(4)
输出门(Output Gate)控制长时记忆对当前输出的影响
ot=σ(Wo×[ht-1,xt]+bo)
(5)
输出门和单元状态将共同决定网络模型最终的输出结果。
ht=ot×tanh(ct)
(6)
1.2 SVR的基本理论
SVR模型是SVM(Support Vector Machine)模型的一种衍生方法,其作为一种回归预测方法,主要应用于分析有限样本情况。该方法遵循实现结构风险最小化的基本原则,在对给定的数据逼近精度和逼近函数的复杂性之间寻求折中,以期得到最好的推广能力[17]。该模型的基本理论是在处理样本数据时将实际问题通过映射转换到高维特征空间,通过在高维特征空间中构造出的线性决策函数从而得到预测值[18],其中线性函数计算式为
f(x)=ωTφ(x)+b
(7)
其中,ω表示权值向量;φ(x)则表示映射函数;b为偏执项。在对实际问题做回归预测时,由于偏差不可避免,故引入不敏感损失函数
L[y,f(x)]=max{0,[y-f(x)|-ε}
(8)
式中,L[y,f(x)]为ε损失函数,若预测偏差小于ε,则损失为0,否则将偏差减去ε。
在训练SVR模型时,遵循结构风险最小化的原则,可以将问题转换为凸二次规划问题,形式如下
(9)
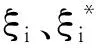
(10)
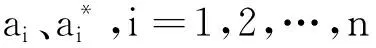
1.3 萤火虫算法[19]的基本理论
在萤火虫的群聚生活中,每只萤火虫都会通过分泌荧光素来和同伴进行觅食、求偶等信息交流。一般来说,荧光素越亮的萤火虫具有更强的吸引力,荧光素越亮周围会聚集越多的萤火虫[20]。该算法是一种启发式算法,受启发于晚上萤火虫发光的行为。萤火虫闪光的主要作用是作为信号系统,以吸引其他萤火虫[21]。算法的基本假设为:
1)对实验中的所有萤火虫不考虑性别,且更亮的萤火虫将会吸引荧光度较弱的萤火虫向自身靠近;
2)吸引力和荧光亮度成正比,且每只萤火虫都会向着比它自身亮度更高的一只移动,但随着距离越来越长,荧光亮度会慢慢减少;
3)当设定的一只萤火虫没有找到一只比它更亮的萤火虫之前,该萤火虫将随机移动。
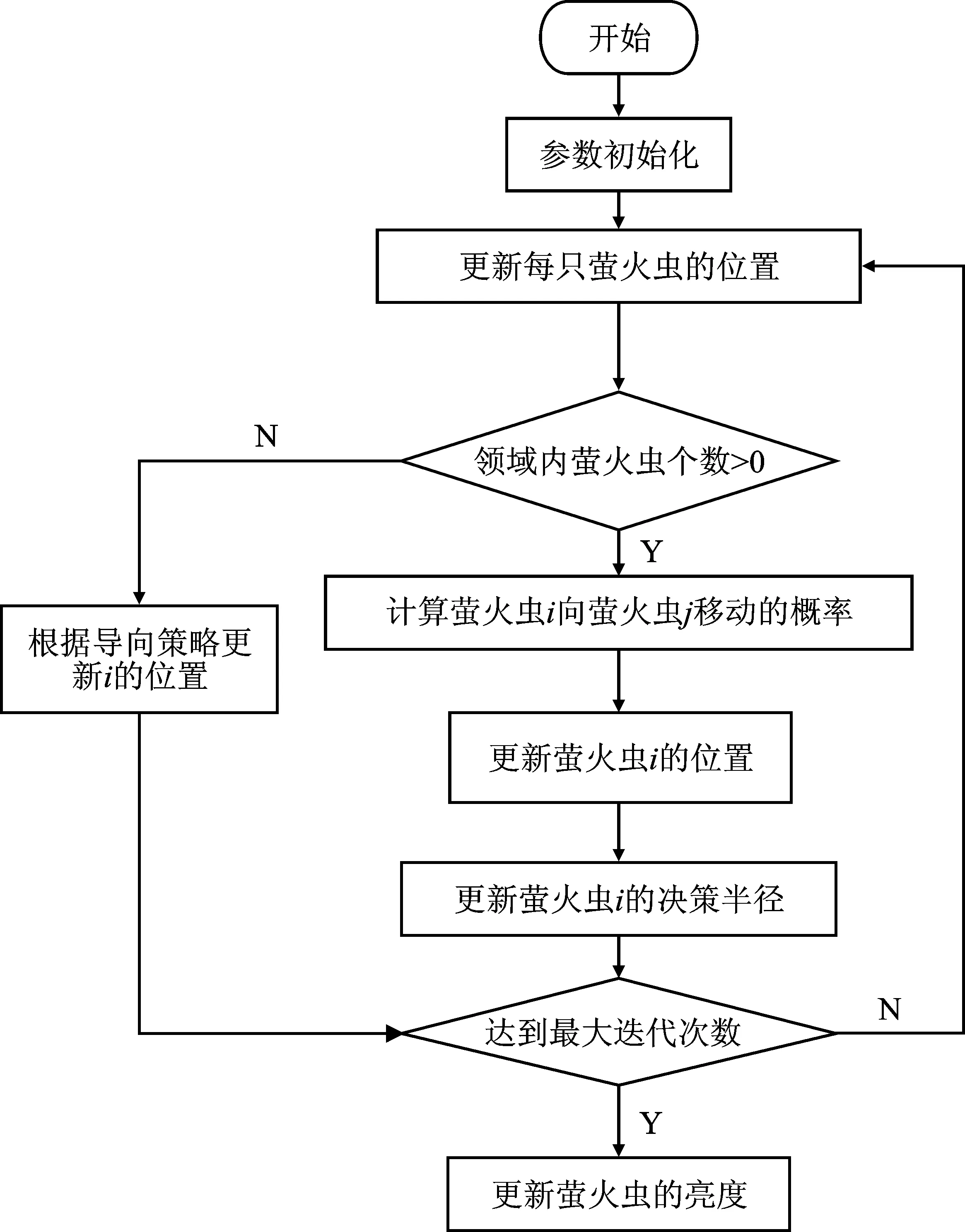
图2萤火虫算法流程Figure 2. Flow of FA
萤火虫的相对荧光亮度为
I=I0e-γr2
(11)
式中,I0表示该萤火虫在r=0处时的荧光亮度;r为两只萤火虫之间的距离,rij表示萤火虫i与萤火虫j之间的距离;γ为光吸收系数,荧光亮度随着距离的增加和传播媒介的吸收变得越来越小,从而设置光强吸收系数来显示荧光亮度的特点,本文将其设置为常数;e为欧拉数。荧光亮度与目标函数值的大小成正比,当目标函数组越优时,该萤火虫自身的荧光亮度越高。
相互吸引度β为
β(r)=β0e-γT2ij
(12)
其中,β0表示最大吸引度,即光源处(r=0)的吸引度。
最优目标迭代为
(13)
其中,xi与xj分别为萤火虫i与萤火虫j的空间位置;α为步长因子;rand表示在[0,1]上服从均匀分布的随机因子。
2 数据采集
本文实验使用的数据来自美国国家航空和宇宙航空局(NASA,http://www.eia.doe.gov)发布的佛罗里达州电力负荷历史数据。本文选取该地2021年9月16日~ 2021年11月14日,共计1 778组数据,间隔1 h采样。其中,选取2021年9月16日~2021年11月12日的负荷数据作为训练数据,选取2021年11月12日~2021年11月30日的负荷数据作为测试数据,预测当地2021年10月31日~2021年11月14日共计15天的实际电力负荷,且与真实电力负荷进行对比。
3 FA-LSTM-SVR组合预测模型
3.1 萤火虫算法优化SVR和LSTM
由于SVR模型的惩罚因子c以及核参数的g取值会影响该模型对样本的预测效果,所以c和g的取值对SVR模型的预测效果具有重大影响。虽然LSTM模型在长时序列建模上有较好优势,具备长期记忆功能,且实现简单。但是LSTM模型的不足之处在于计算过于复杂且冗长。另外,在模型训练过程中传统的LSTM经常出现较强的不稳定性,甚至出现梯度消失现象[22]。
本文通过FA对SVR模型的惩罚因子c、核函数参数g以及LSTM模型的神经元个数m、学习率lr进行自动迭代寻优,并利用均方根误差作为萤火虫算法的返回误差评判标准,最后采用RMSE最小的萤火虫位置作为模型最佳参数。
3.2 模型原理
本文通过FA算法分别优化LSTM和SVR:将SVR模型的两个参数作为FA算法的初始萤火虫位置,SVR模型训练返回误差决定萤火虫的亮度。误差最小的萤火虫位置即为最优的参数对应值。带入最佳参数确立FA-SVR模型并对测试集数据进行预测,输出预测值。同理,利用FA算法寻求对LSTM模型最优的参数神经元个数m、学习率lr,确立FA-LSTM模型并对测试集数据进行预测。将该模型输出的预测值与FA-SVR模型预测值按比例组合,建立组合模型FA-SVR-LSTM。
F=aF1+(1-a)F2
(14)
式中,F为组合模型输出的预测值;F1为FA-LSTM模型输出预测值;F2为FA-SVR模型输出预测值;a为组合模型不断迭代寻求的最优权重参数,是位于(0,1)之间的数。
3.3 模型设置
3.3.1 数据预处理
对样本数据采取归一化的目的是使数据具有相同尺度的量纲以减少误差,增强模型的收敛速度和预测精度,故在模型进行预测之前,需对数据进行归一化处理
(15)
其中,xstd表示归一化后的值;xmin和xmax分别为样本数据的最小值和最大值。
3.3.2 整体流程
如图3所示为组合模型的具体流程,其步骤如下所示:
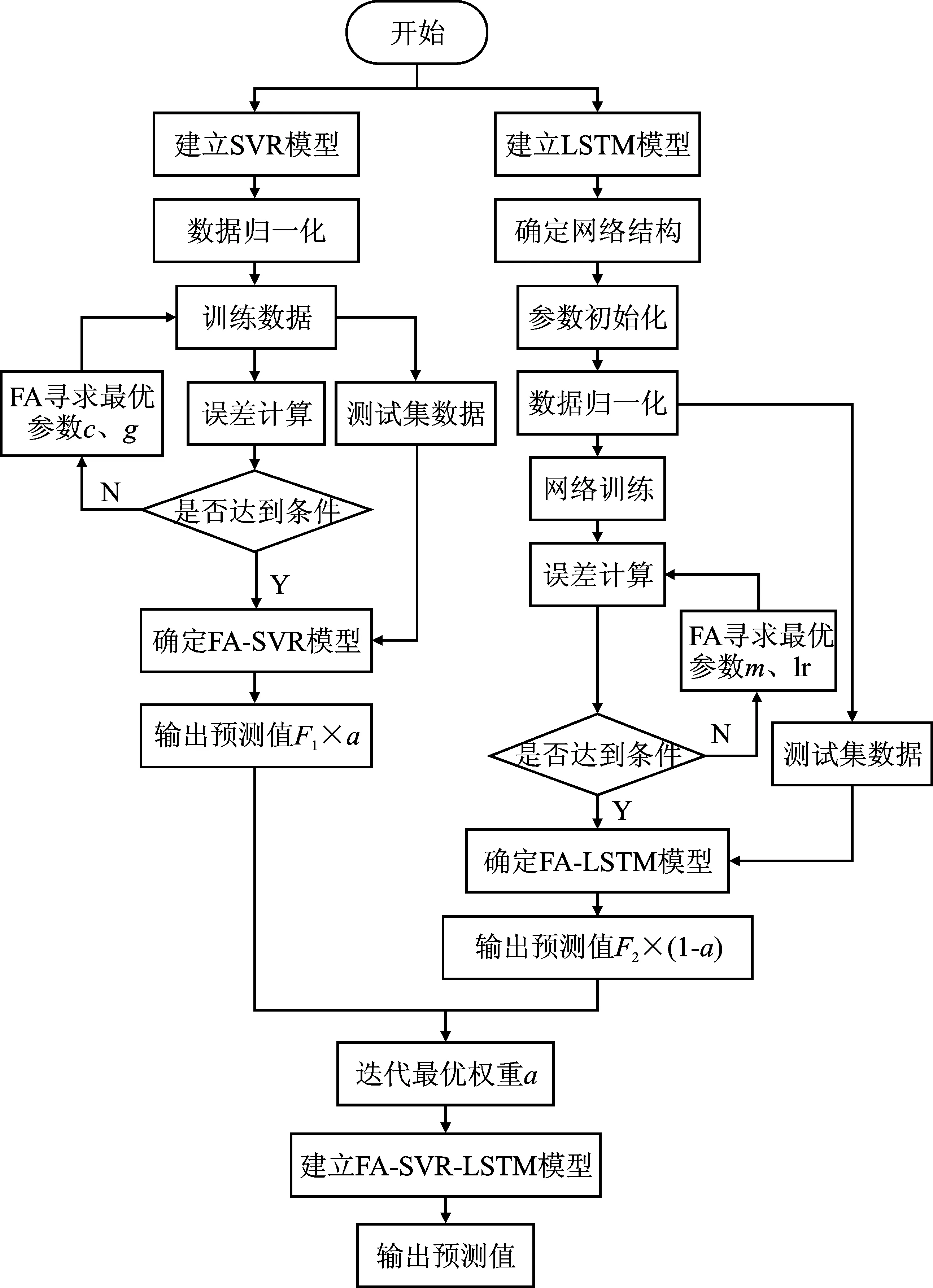
图3 FA-SVR-LSTM模型流程Figure 3. Flow of FA-SVR-LSTM model
步骤1建立SVR模型,将进行归一化处理数据进行模型训练,将c、g作为FA算法萤火虫算法初始位置,计算误差寻求最优参数;
步骤2利用优化算法寻求的最优参数c、g建立FA-SVR模型,并对样本测试集数据进行预测,输出预测值;
步骤3建立LSTM模型,确定该模型网络结构并进行参数初始化,同样将m、lr作为FA算法萤火虫算法初始位置,寻求最优参数;
步骤4利用最优参数建立FA-LSTM模型,对测试集数据进行预测输出预测值;
步骤5令FA- SVR模型的权重为a,FA-LSTM模型权重参数为(1-a),建立组合模型FA -SVR-LSTM,组合模型的计算式见式(14);
步骤6利用FA算法进行迭代寻求最优参数a,并输出组合模型预测值。
4 实验设置及结果分析
4.1 实验设置
本文所有实验基于Windows10 64位操作系统,设备采用Intel Corei7-7500U CPU @ 2.70 GHz处理器,显卡为RTX2080Ti,内存为8 GB。程序仿真环境为Python3.6,集成开发环境为Anaconda。LSTM模型采用Kears框架,程序由tensorflow_gpu1.5.0,scikit_learn1.0.2版本实现。以佛罗里达州电力负荷数据例,建立LSTM、SVR、FA-LSTM、FA-SVR、FA-SVR-LSTM共5种预测模型,分别对样本进行预测。
4.2 实验参数设置
定义FA算法的参数:种群规模为50,最大迭代次数为10次,变量维度为2,参数上界lb=[0.010, 0.001],参数下界ub=[1 000, 20],吸收系数pr=0.03。SVR模型的参数取值范围:惩罚因子c=[0,1 000],核参数g=[0.001 00, 0.000 01]。LSTM参数取值范围:m=[0, 100],lr=[0.000 01, 0.001 00]。
4.3 实验结果及分析
首先对种群初始化,根据lb、ub建立一个50×2的初始种群,种群中有50个萤火虫个体,每个个体具有2个变量,分别表示SVR算法中的c和g。当迭代次数小于最大迭代代数时,通过目标函数对萤火虫种群中的个体计算光照强度(即目标评估),评估过程则是对种群中的个体参数,根据数据进行训练SVR模型,并对训练得到的SVR模型在测试机中进行测试,将测试集上的误差作为该个体的光照强度,然后根据计算得到的光照强度对萤火虫进行排名,找到当前最佳萤火虫的位置。根据萤火虫算法的更新计算式来更新萤火虫的位置,亮度较低的萤火虫飞向亮度较高的萤火虫,亮度最亮的萤火虫随机移动。
迭代结束后,输出最优个体的值作为测试误差最小的参数c和g即为SVR模型的最优参数。同理,FA寻求LSTM最优参数,最终的寻优结果如表1所示。

表1 FA算法寻优的最佳参数Table 1. Best parameters searched by FA algorithm
由表1可知SVR模型的最优参数为c=385,g=0.001 2;LSTM模型最优参数为m=35,lr=0.009 1。利用得到的最佳参数建立模型FA-LSTM、FA-SVR模型,分别对测试集数据进行预测,并利用式(16)和式 (17)计算模型误差大小。
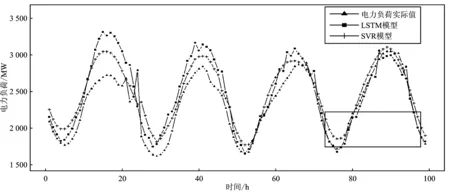
在确立最佳参数的基础上,利用式(14)通过程序迭代寻求最优权重a,建立FA-SVR-LSTM组合模型,对测试集数据进行预测,并与其他4种参照模型进行对比。图4为该地区电力负荷实际值与SVR、LSTM、FA-SVR、FA-LSTM、 FA-SVR-LSTM预测模型趋势对比。由图4可以看出,FA-SVR-LSTM模型部分预测值与实际值走势大体相同,表明该组合模型具有良好的预测效果,且FA-SVR-LSTM相较于其它4种模型的预测值更加接近实际值,说明本文所提的FA-SVR-LSTM组合模型提高了预测效果。SVR和LSTM两种单一模型的预测值和实际值趋势相差较远,预测效果也远低于FA-SVR、FA-LSTM两种组合模型,说明本文所提模型对单一模型的优化效果显著。
(a)
4.4 实验误差对比
为更好地观察模型的预测效果,本文采取平均绝对MAPE、RMSE这两种误差评价指标对结果进行评价。
(16)
(17)
其中,N表示样本个数;xt为真实值;t为预测值。
由表2中的5种模型的预测误差可以看出,组合模型FA-SVR-LSTM与 单一模型LSTM相比,预测精度提高了33.184 9%; FA-SVR-LSTM模型与SVR模型相比,预测精度提高了30.326 5%。同时,FA-SVR-LSTM模型的MAPE和RMSE误差指标评价值均小于其他4个模型。从模型实验计算时长来看,虽然本文所提模型相比于单一模型计算时长有所增加,但在可控范围之内,未造成额外的计算开销。误差评价及计算时长结果表明,组合模型FA-SVR-LSTM的预测效果最好。
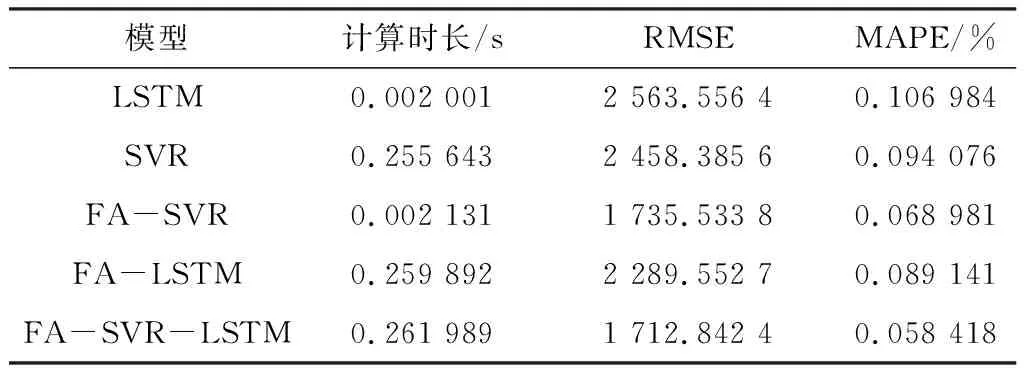
表2 5种模型的预测误差及计算时长Table 2. Forecasting error and calculation time of five models
5 结束语
为进一步提高电力负荷的预测精度,本文基于FA算法对SVR模型以及LSTM模型的参数进行优化,在寻求最优参数的基础上建立了FA-SVR-LSTM组合预测模型。实验结果表明,FA-SVR-LSTM组合预测模型的预测效果优于SVR、LSTM、FA-SVR、FA-LSTM等参照模型。实验研究表明,本文提出的FA-SVR-LSTM组合模型与单一预测模型相比,能有效降低预测误差。但该组合模型在预测时未将气候、工作日等影响因素纳入研究,且对两种单一模型的参数优化算法的选择还有提升空间。在后续的研究中,将纳入影响电力负荷的因素进行预测分析,并对优化算法做进一步改进,以便进一步提高预测精度。
