基于Scrapy的高性能网站状态批量采集系统
2023-09-17赵鹏苏楠于慧霞
赵鹏 苏楠 于慧霞
关键词:Scrapy;高性能;网站状态;批量采集
一、引言
目前网络中的服务多以7×24 小时的方式进行不间断工作,由于在网站建设中主要侧重点放在了功能的实现上[1],往往忽略了网络安全问题,导致网站在运营过程中对各类网络攻击行为的防护较差。在日常监测过程中,需要实时掌握的系统状态信息包括但不限于网站是否可用、域名解析是否正常、网页内容是否被篡改、挂马等方面。在管理较少的网站时,尚可采用人工的方式进行手动监测,而当网站或者网页数量数以千计时,如何能在短时间内及时准确地批量采集网站状态信息是一个亟须解决的问题。
二、相关技术介绍
(一)Scrapy
Scrapy 是一个用Python 编写的自由且开源的网络爬虫框架。其设计初衷是用于爬取网络[2],但也可用作爬取API 数据的网络爬虫。该框架目前由Scrapinghub公司维护。Scrapy 项目围绕“蜘蛛”(Spiders)构建,Spider 是提供一套指令的自包含的爬网程序。允许开发者重用代码将便于构建和拓展大型的爬虫项目[3]。
1.Twisted
Twisted 是用Python 实现的基于事件驱动的网络引擎框架,Twisted 支持许多常见的传输及应用层协议[5],包括TCP、UDP、SSL/TLS、HTTP、IMAP、SSH、IRC及FTP。就像Python 一样,Twisted 也具有“内置电池”(Batteries-included)的特点。Twisted 对于其支持的所有协议都带有客户端和服务器实现,同时附带有基于命令行的工具,使得配置和部署产品级的Twisted 应用变得非常方便[6]。
2.Splash
Splash 是一个JavaScript 渲染服务,同时也是一个带有HTTP API 的轻量级Web 浏览器,使用Twisted 和QT5 在Python3 中实现。QT Reactor 用于使服务完全异步,从而允许通过QT 主循环利用Webkit 提高并发性。Splash 的主要功能有:并行处理多个网页;获取HTML结果和/ 或截图;关闭图像或使用Adblock Plus 规则来加快渲染速度;在页面上下文中执行自定义JavaScript;编写Lua 浏览脚本; 在Splash-Jupyter 笔记本中开发Splash Lua 脚本;获取 HAR 格式的详细渲染信息。
三、系统功能概述
本文设计并实现的高性能批量网站状态信息采集系统基于Scrapy 框架实现。在该框架基础上自身结合自身需求设计了数据预处理、网站可用性采集、域名解析和网站首页信息采集、数据持久化存储共五个功能模块。
(一)数据预处理
为了避免因为待采集的网站URL 不规范引起的请求错误,需要对待采集网站域名进行检查、清洗及规整工作。具体功能包括但不限于处理待爬取网站列表中有些URL 没有协议头、一条记录包含多个使用分隔符分隔的多个URL 等情况。
(二)网站响应状态码采集
网站的响应状态码可以体现出网站是否正常可用,因此可采集网站响应状态码作为网站是否可用的判断依据。由于网站的状态是复杂多样的,甚至是动态变化的。因此若要得到更准确的状态码,必须处理那些表示网站状态异常的响应状态码,比如301、302、400、404、501 等。同时还需要处理由于网络原因引起的请求超时等异常情况。
(三)域名解析信息采集
域名解析信息包括域名、对应IP 地址、归属地等。这些信息是通过查询特定的API 獲取,这也正是Scrapy框架的主要功能之一。
(四)网站首页信息采集
网站首页信息具体包括网站标题、网站首页文本和全屏截图三类信息。由于目前大量网站都采取了动态网页的设计模式,使用Scrapy 直接采集无法获取最终的网站页面状态。因此本模块使用Scrapy-splash 插件与Splash 服务器相配合,由Scrapy-splash 负责发起请求,Splash 负责渲染网页并将渲染后的完整网页返回给Scrapy。
(五)数据持久化存储
由于Scrapy 最终解析出的数据以字典形式呈现,而MongoDB 的操作接口均是以字典作为参数,再借助Scrapy 自身提供的管道中间件无需编写SQL 语句就可以完成数据的存储工作,更加简洁高效。
四、系统功能架构设计
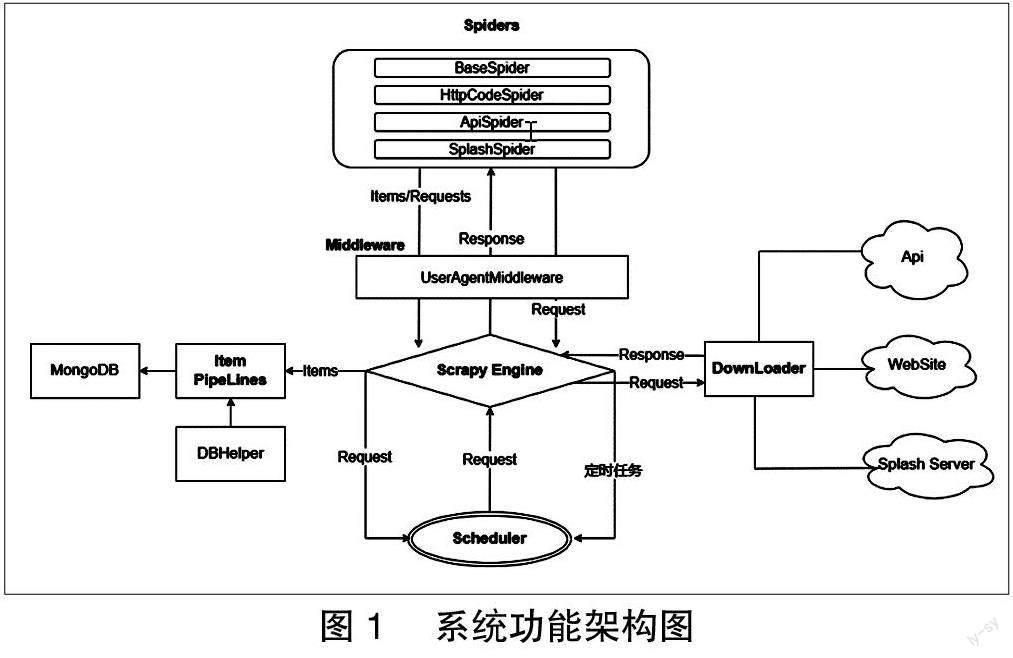
系统功能架构如图1 所示。
(一)系统功能实现
1. 数据预处理
BaseSpider 模块负责待采集网站列表的清洗及规整工作,可以根据实际需求动态添加处理逻辑。本文主要实现了两类清洗工作:一是对网站URL 的检查和规整,二是对一个网站包含多个URL 时进行拆分和填充形成多条记录。关键实现代码如下:
For domain in [domain.strip().replace(‘ ‘, ‘) for domain in line.split(‘;) if domain]:
L i n e . u p d a t e ( { ‘ i d x : s e l f . g e t _ i d x ( ) , d o m a i n :domain,sk_ip: self.get_ip(domain)})
2. 网站响应状态采集
HttpCodeSpider 模块通过Scrapy.ScrapyRequest 发起Get 请求后,正常状态下ScrapyResponse 中Status 即可作为网站响应状态信息。但当网站状态异常时网站响应状态信息需从异常捕获函数中收集。关键代码实现如下所示:
Def errback(self, failure):
Cb_kwargs = failure.request.cb_kwargs
I t e m = I n s p e c t o r I t e m ( { ‘ d o m a i n : c b _kwargs[‘domain],idx: cb_kwargs[‘idx],})
Try:
Response = failure.value.response
Item.update({‘status: response.status,})
Except AttributeError:
Item.update({‘status: 700,title: failure.value})
Yield item
3. 域名解析信息采集
ApiSpider 模塊采集的数据需要通过第三方的查询API 获取,该API 返回JSON 格式的数据结果。发起请求时需在请求头中指定API code 作为认证标识,在处理返回的数据时需要记录查询成功和失败的数据。具体实现如下:
If api_ret.setdefault(‘api_msg).startswith(‘success):
Wanted_vals = [api_data.setdefault(key) for key in wanted_keys]
Api_ret.update(dict(zip(wanted_keys, wanted_vals)))
Yield InspectorItem(api_ret)
else:
Yield InspectorItem(api_ret)
4. 网站首页信息采集
当目标网站为动态网站时, 普通的Scrapy.ScrapyRequest 无法获取准确的网站首页信息,SplashSpider 统一借助Scrapy-Splash 的SplashRequest 接口向Splash 服务器发起请求。由Splash 完成目标网站的渲染并返回渲染后的网站首页Html 和截图信息。由于需要获取网站首页的全屏截图,因此需要在发起请求时指定Render_all 参数的值为1。
5. 数据持久化存储
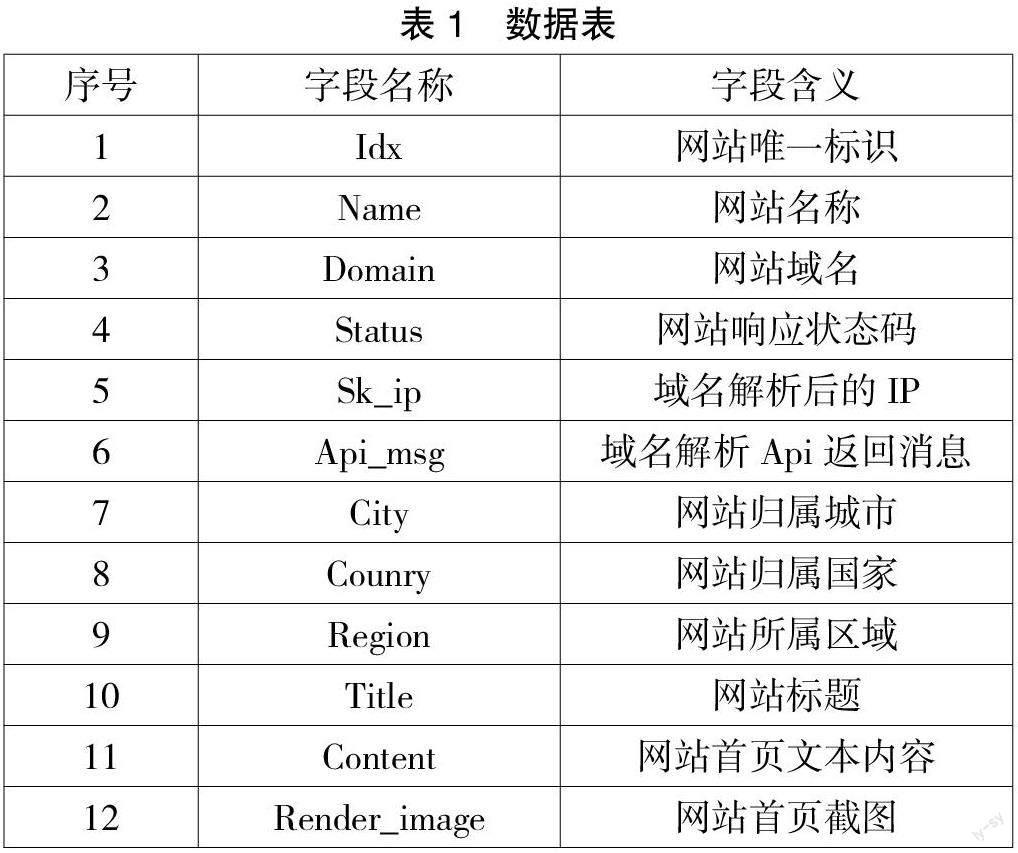
DBhelper 模块存储到数据库中的字段信息如表1所示。
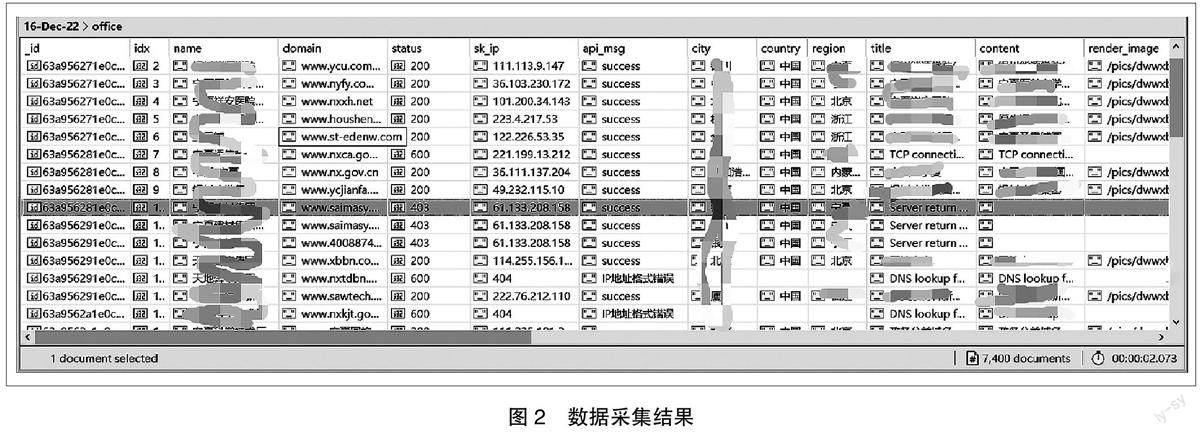
五、数据采集结果
本次测试中采集的网站数量为7400 个。其中网站响应状态码为200 的共计4892 个,即以最为耗时的网站首页信息采集模块为例,对网站状态该模块从启动到最终结束共耗时5603 秒。累计采集了4892 个的网站首页标题、首页文本以及首页全屏截图。
六、结束语
不同于一般针对某个网站进行深度的数据采集,本文所提出的采集系统主要是解决如何批量采集网站状态信息的问题。其难点在于待监测的网站数量庞大、采集的数据来源较为分散、动态网站的数据无法直接通过一次网络请求就完成采集。本文在Scrapy 的基础上结合Scrapy-splash、Splash 等技术手段实现对多个网站状态信息的批量采集和动态网站首页信息的精确采集,能够为后续网站的日常监测和状态分析提供有效支撑。
作者单位:赵鹏 苏楠 于慧霞 国家计算机网络与信息安全管理中心宁夏分中心
