图像感知引导CycleGAN 网络的背景虚化方法
2023-09-14叶武剑林振溢刘怡俊刘成民
叶武剑,林振溢,刘怡俊,刘成民
(1. 广东工业大学 集成电路学院,广东 广州 510006;2. 广东工业大学 信息工程学院,广东 广州 510006)
1 引言
背景虚化技术也称为浅景深技术[1],是一种常用的摄影表现手法。在早期智能移动设备硬件条件较为落后的情况下,常常需要通过单反相机来获得背景虚化图像,但由于其操作性强、价格高昂,许多人难以获得令人满意的背景虚化图像,因此人们依赖图像后处理技术来满足需求。现代智能移动设备的硬件和性能得到了显著的提升和改善,例如光场相机通过一次曝光即可获得当前场景的四维光场信息[2],从而实现图像的重聚焦,即可对不同主体进行背景虚化处理。尽管与传统的单反相机相比,光场相机降低了用户的操作难度,但由于在图像的后处理过程中需要储存具有不同光线信息的图像,导致其处理效率不高。而对于诸如嵌入式小型移动设备、智能手机、平板电脑等,其前置单目摄像头难以获取多种图像感知信息,导致这些设备无法实现有效的背景虚化处理。基于上述问题,图像背景虚化技术具有较大的研究价值。
随着科学技术的发展,光学计量学已成为制造业、基础研究和工程应用中解决问题的有效手段之一。[3]自1981 年Potmesil 等人[4]发表第一篇有关景深效果绘制的研究论文以来,图像背景虚化愈来愈引起了诸多研究学者的关注。在传统的背景虚化方法中,Lee 等人[5]利用针孔成像的光学原理构建适合虚拟现实的背景虚化效果。Xie 等人[6]利用二次光线的相干性聚类方案,实现不同自由度的背景虚化。由于在背景虚化的过程中存在效率低下的问题,Xin 等人[7]通过透镜的光学中心以及分布在镜头上的几个外围视点来绘制一组稀疏视图,从而高性能地合成具有不同自由度的高质量背景虚化图像。为了完成高质量画面的渲染,通常需要用到高端的计算设备,因此对计算资源有较高的要求,运行效率也显得不足。Li 等人[8]基于单目深度估计的方法,提出分层虚化技术,利用深度信息实现图像分层,以实现有效的背景虚化。
近年来,随着深度学习算法的不断改进,利用卷积神经网络(Convolutional Neural Networks,CNN)实现的背景虚化处理技术也在不断提升。早期Shen 等人[9]在探索基于CNN 的背景虚化处理技术中,提出一种高性能的自动人像分割图像方法,创新性地引入位置和形状两种输入通道,以提升全卷积网络(Fully Convolutional Network,FCN)的性能,从而将人像区域精确地抠取出来。Mok 等人[10]利用基于残差网络Resnet[11]的图像分割技术和高斯模糊应用于单目移动设备上,从而实现实时背景虚化。遗憾的是,这些工作关注于人像照片,先用卷积神经网络将人从图像中分割出来,然后处理剩余的图像背景,导致最终效果不够丰富且缺乏场景应用性。
为了解决上述工作存在的弊端,Wadhwa 等人[12]提出一个可在手机上计算合成的背景虚化图像处理系统,通过结合人像分割网络和自动定焦技术,实现对人像的背景虚化处理,并将仅限于人物的场景扩展到宠物、食物等其他的场景中。此外,在对背景的景深处理中,该系统结合图像的深度信息,以丰富生成的背景虚化效果。Purohit 等人[13]提出一种用于景深效果渲染的深度引导密集动态滤波网络方法,由具有金字塔池化模块的高效密连编解码骨干结构组成,在空间感知模糊过程中,利用了联合强度估计和动态滤波合成的特定任务效能。在2020 年的Advanced Intelligent Mechatronics 挑战赛中,Ignatov等人[14]提出直接从高端单反相机的照片中学习一种真实的背景虚化方法,能够在多目标的情况下呈现出自然真实的背景虚化效果。这部分工作不再只关注人像,在扩展应用场景多样性的同时,也增强了深度方面的感知。在非人脸方面的相关工作也在不断发展。Dutta 等人[15]采用堆叠深层多尺度分层网络,提高了背景虚化感知质量。Liu 等人[16]利用图片感知信息分割得到的辅助图,实现不同区域的深度计算,以完成自动背景虚化。Zheng 等人[17]设计了一个用于单图像景深渲染的多尺度预测滤波网络,引入了约束预测滤波器来保持显著区域,得到了视觉效果更佳的背景虚化图像。Jeong 等人[18]使用光栅化对强高光进行密集采样,而使用常规散焦模糊渲染对规则对象进行稀疏采样,兼顾了动态可见性和精确性。Luo 等人[19]提出了一个散焦到聚焦(D2F)框架,通过将散焦先验和全聚焦图像融合并在分层融合中实现辐射先验,学习真实的物体渲染。
对于基于生成对抗网络的背景虚化方法,其处理过程颇为简便,在场景应用上也不会受到任何约束。Isola 等人[20]提供了通用的框架以完成图像到图像间的转换,无需特定的算法和损失函数,通过U-Net 网络将图像的特征进行细化提取,使生成的图像质量更高。通常情况下,在缺乏相互匹配数据集组的情况下,是无法对GAN 网络进行训练的,因此Zhu 等人[21]通过引入循环一致性损失,完成非匹配的图像转换任务,包括背景虚化、季节转换、风格迁移、光增强调节等多个任务。Qian 等人[22]利用级联式双U 型网络结构并结合基于GAN 网络和感知损失的方法,以逼近真实的景深渲染效果。Pizzati 等人[23]引入了一个新的功能实例归一化层和残差机制,采用模型引导的方式,将图像转换连续化,得到在视觉上独特的背景虚化图像。
一些未应用于背景虚化但专注图像处理的工作也值得关注。Wang 等人[24]提出了一种基于双焦点透镜阵列的深度增强积分成像显示器,能够生成两个中心深度平面并在深度上缝合两个重建3D 图像,极大地提高了景深。Xie 等人[25]设计了能在整个深度范围内平衡显示质量的光学衍射元件并构建了预滤波卷积神经网络,在不严重降低图像清晰度的情况下有效扩展深度范围。Situ[26]详细讨论了全息影像技术的先进成果及其与神经网络的有机结合。Luo 等人[27]提出了一种无需计算机、各向异性的图像重建方法,可以以光速穿透随机漫射器。
虽然基于生成对抗网络的图像间转换方法已经在端到端的网络优化上表现相当出色,但仍有一定的不足:当景深中的物体颜色与周围背景颜色相似时,该网络无法很好地工作,出现这种现象的原因可能在于模型没有获得足够的感知信息,导致在主体的识别定焦上容易出错。
针对上述工作存在的问题,本文提出了一种图像感知引导CycleGAN 网络(Cycle-Consistent Generative Adversarial Network)的背景虚化方法。本文创新性地将注意力信息和景深信息引入CycleGAN 网络,能够更好地区分前后景并减少图像失真。实验结果表明,本文方法能实现更好的背景虚化效果,相比现有的SOTA 方法,本文方法更具优越性。
2 基本原理
2.1 系统框架
为减少制作样本数据带来的困难,本文选用循环一致性生成对抗网络(CycleGAN)作为基础框架,使得在无配对数据集的情况下,也可以完成不同图像域之间的转换。受文献[28]的启发,结合图像感知设计了一个性能更优的CycleGAN网络。其中,图像感知包括注意力模块[29]与景深模块[30],注意力模块包括CBAM(Convolutional Block Attention Module)注意力机制和CAM(Channel Attention Module)注意力机制。前者引导生成器更好地关注图像需要凸显的区域,后者引导鉴别器关注两组图像间特征差异最大的区域,以区分前后景区域。景深模块用于增强整体网络的性能,使图像前景目标的感知信息得以增加,以提升生成的背景虚化效果。
图1 是本文提出方法的系统框架图。为了实现不同图像景深域之间的转换,本网络基于GAN 网络的原理设置两组完全对称的生成器和鉴别器,第一组由CBAM 注意力引导的生成器G将X域的图像(深景深x)转换成Y域的图像(浅景深G(x)),而由CAM 注意力引导的鉴别器DY则将生成器生成Y域的图像(浅景深G(x))与真实Y域的图像(浅景深y)区分开。同样地,第二组由CBAM 注意力引导的生成器F将Y域的图像(浅景深y)转换成X域的图像(深景深F(y)),而由CAM 注意力引导的鉴别器则负责将生成X域的图像(深景深F(y))与真实X域的图像(深景深x)区分开。

图1 整体网络结构图Fig.1 Structure diagram of overall network
为了使不同图像景深域间的转换变得有意义并提升生成效果质量,本网络遵循CycleGAN的原理,引入两个循环一致性损失,分别为图像循环一致性损失和景深循环一致性损失。前者防止网络出现X域(Y域)中的多张图像只与Y域(X域)的同一张图像形成多对一的映射关系;为了凸显前景目标,后者通过增强原有图像前景目标的感知信息,以加强生成图像效果的真实感。其中,循环一致性为:原图x(X域)经生成器G转换为图像G(x)(Y域),再经生成器F复原为图像F(G(x))(X域),该过程中同属于X域的原图x和图像F(G(x))应保持一致。
2.2 生成器网络结构
本文设计的生成器网络结构如图2 所示,主要分为3 个模块:(1)特征编码模块,由3 个负责特征初步提取的下采样层组成;(2)特征转换模块,由9 个负责提取深层次特征信息的残差块拼接而成;(3)特征解码模块,由3 个与下采样层对应的上采样层组成。

图2 生成器网络结构图Fig.2 Network structure diagram of generator
2.2.1 特征编码模块
特征编码模块通过融入CBAM 模块以达到更好的特征提取效果。CBAM 是一个轻量级通用模块,如图3 所示,其包括通道注意力模块及空间注意力模块两部分,从通道和空间两个维度推理注意力图,并将注意力图乘以输入特征图以进行自适应特征细化,可提高CNN 的表征能力。

图3 CBAM 结构图Fig.3 Structure diagram of CBAM
生成器的工作过程为:首先,输入的深景深图进入特征编码模块进行初步的特征提取。如图4 所示,该模块中将卷积、CBAM 模块、实例归一化、ReLU 激活函数依次组合,作为下采样层的结构。为了更好地提取图像特征,在第一个下采样层进行卷积操作前,没有选择传统的0 填充方式,而是采用镜像对称填充的方式对特征图进行处理。接着在卷积提取完特征后,利用CBAM模块从通道和空间两个维度对特征进一步提取,使网络从最开始就关注到图像中较为显著的区域;而实例归一化仅从通道维度对特征做归一化操作,可以加速训练时模型的收敛进程。最后经过ReLU 激活函数对数据进行激活,从而过滤上一层输出特征矩阵中的负值,以减少网络的运算量并提高网络的表达能力。

图4 特征编码模块结构图Fig.4 Structure diagram of feature coding module
在上述特征编码模块中,每个下采样层对应的具体结构及参数如图4 所示,其中k表示卷积核大小,s表示步长,p表示填充尺寸,i表示输入通道数,o表示输出通道数,若结构层的某个参数为空则不标注(下面采取同样的标注方式)。
2.2.2 特征转换模块
经过特征编码模块的初步特征提取后,为进一步提取更深层次的特征,必须加深网络的深度。但随着网络的加深,容易造成诸多不可逆的信息损失,即网络拥有的恒等映射能力变差。为了在网络不出现退化的情况下提取深层次的特征,本文在生成器的特征转换模块中利用He 等人[11]所提出的残差块进行组合设计。该模块由9 个结构及参数完全一致的残差块拼接而成以提高生成器网络的深度,同时可以保证网络的恒等映射能力。其中每个残差块由两个“卷积-实例归一化-ReLU 激活函数”组合块组成,其结构及参数如图5 所示。
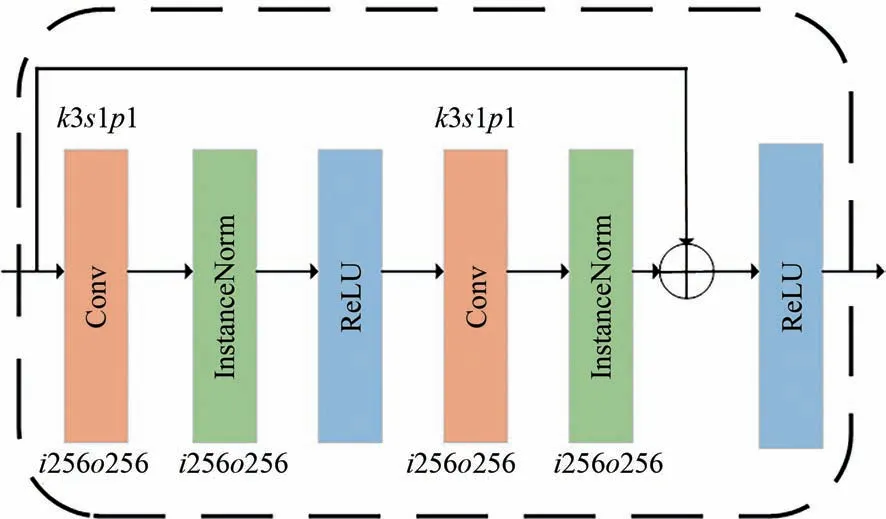
图5 特征转换模块的残差结构块结构图Fig.5 Structure diagram of residual block in feature conversion module
2.2.3 特征解码模块
为了恢复特征的原有尺寸并输出高分辨率的效果图,在特征转换模块后进行特征解码操作。特征解码模块与特征编码模块相互对应,通过设置3 个上采样层实现生成器网络的对称性。特征解码模块的结构及参数如图6 所示。

图6 特征解码模块的结构图Fig.6 Structure diagram of feature decoding module
2.3 鉴别器网络结构
对于鉴别器,本文借鉴U-GAT-IT 鉴别器[28]的结构,但与U-GAT-IT 不同的是:本文没有采用“全局+局部”的双分支模式,而是在全局鉴别器中仅引入CAM 注意力机制进行辅助鉴别,使网络基于CAM 辅助模块输出的辅助判别权值矩阵对全局特征进行判别,判别权值越大的区域越可能被判别为重点前景区域,从而实现前后景的区分,并解决了由于局部鉴别器导致模型量变大的问题。其网络结构包括参数共享模块、CAM 辅助模块、判别矩阵模块3 部分,如图7所示。
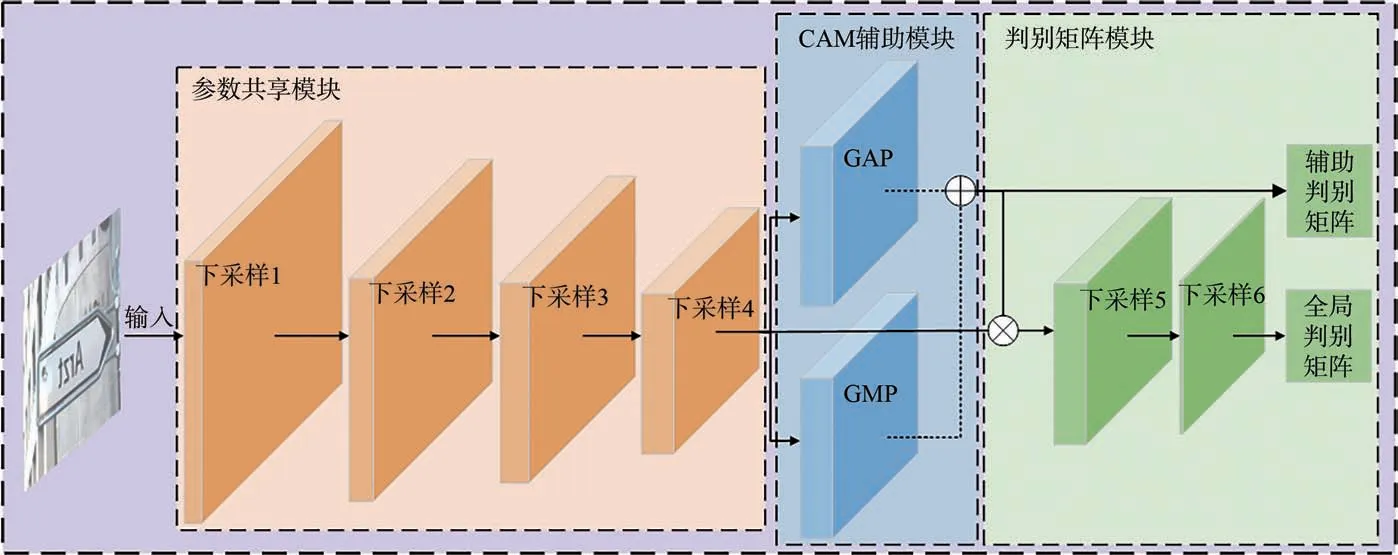
图7 鉴别器网络结构图Fig.7 Network structure diagram of discriminator
2.3.1 参数共享模块
参数共享模块由4个下采样层组成,每个下采样层由卷积、实例归一化、LeakyReLU 激活函数依次组成,通过下采样对特征逐次提取,并将提取的特征供CAM 辅助模块使用,可实现网络的参数共享。由于GAN 网络的原理是通过生成器与鉴别器之间的动态博弈,两者的性能更迭提升,因此鉴别器的性能也将影响到生成器的性能。而通过将常用的ReLU 激活函数替换成LeakyReLU激活函数可解决部分“神经元死亡”的问题,从而提升鉴别器网络的性能,但同时也导致网络运算量变大。由于本文设计的鉴别器没有采用“全局+局部”的模式,在模型参数量上具有一定的优势,因此下采样层选用LeakyReLU 激活函数对神经元进行激活操作也不会增加过多的计算量。参数共享模块的结构及参数如图8 所示。

图8 参数共享模块结构图Fig.8 Structure diagram of shared parameter module
2.3.2 CAM 辅助模块
CAM 辅助模块借鉴CBAM 注意力机制中的通道注意力,该模块有GAP 和GMP 两个分支:GAP 分支由自适应平均池化层、全连接层、实例归一化组成;GMP 则将GAP 中的自适应平均池化层替换为自适应最大池化层。其中,GMP帮助鉴别器网络找到图像的重点区域,GAP 则更精确地将区域定位在一定范围内。该模块通过将参数共享模块提取的特征分别送入GAP 和GMP 两个分支,从空间维度对特征图进行压缩。经过逐元素求和操作,得到两个不同的辅助判别权值矩阵。接着将两个矩阵进行拼接并输出,送入后续的下采样层进行特征提取,使鉴别器关注到权值更大的重点前景区域,从而有效分辨整体图像的前后景。CAM 辅助模块的结构及参数如图9 所示。

图9 CAM 辅助模块结构图Fig.9 Structure diagram of CAM auxiliary module
2.3.3 判别矩阵模块
判别矩阵模块由两个下采样层组成,其中第一个下采样层结合了卷积和LeakyReLU 激活函数,第二个下采样层则在卷积和LeakyReLU 激活函数之间加入了实例归一化,目的是进一步对特征进行提取,并扩大最终输出特征的感受野。
所谓的感受野也就是特征图上的每一个像素点能在输入图像上映射的范围,如图10 所示。假设原图为7×7 的矩阵,经过3×3 的卷积核以0填充和步长为1 的逐次卷积处理之后,其感受野逐次递增。
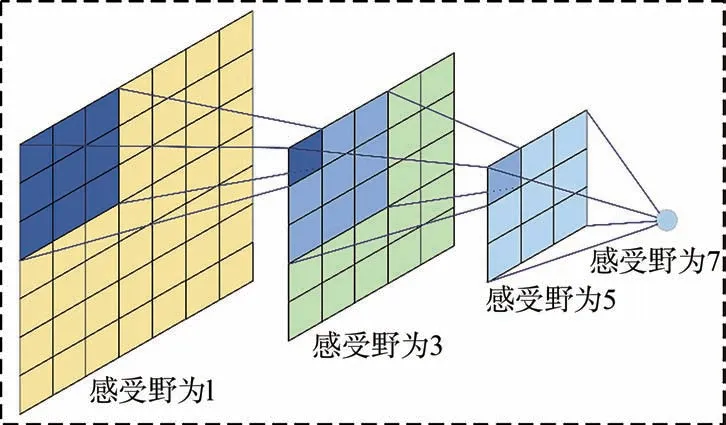
图10 感受野示意图Fig.10 Diagram of receptive field
该模块通过将辅助判别权值矩阵与参数共享模块提取的特征矩阵进行加权计算,接着进行两次下采样操作得到深层特征图,使最终鉴别器网络判断重点前景区域的能力得到加强,进而间接令生成器生成图像的质量得到提升。判别矩阵模块的结构及参数如图11 所示。

图11 判别矩阵模块结构图Fig.11 Structure diagram of discrimination
2.4 图像转换网络损失及优化目标
本文所提出的图像转换网络的损失分为两类:生成对抗损失及循环一致性损失。其中生成对抗损失包括X域→Y域(Y域→X域)的全局鉴别器生成对抗损失和Y域→X域(X域→Y域)的辅助鉴别器生成对抗损失,而循环一致性损失包括图像循环一致性损失和景深循环一致性损失。通过优化这6 个损失可使网络模型得到最优的转换映射路径。
2.4.1 生成对抗损失
为了使网络模型从不同图像景深域中获取不同的样本分布,需要生成对抗损失对该网络进行约束。由图7 可知,由于鉴别器最终输出的判别矩阵有全局判别矩阵和辅助判别矩阵,因此两者构成的生成对抗损失分别如下:
(1)全局判别矩阵构成的全局鉴别器生成对抗损失有两部分:X域→Y域的前向映射损失和Y域→X域的反向映射损失,计算公式见式(1)和式(2):
其中:Pdata(x)和Pdata(y)分别表示和的样本分布,x~Pdata(x)和y~Pdata(y)表示随机从和中取出的样本数据,E表示数学期望。
该网络的性能是通过生成器和鉴别器之间的博弈得到提升的,其中鉴别器DX(DY)应尽可能地将X域(Y域)的真实图像与生成器F(G)生成的虚假图像区分开,即DY(G(x))和DX(F(y))的值要趋于0,DY(y)和DX(x)的值要趋于1,也就是LGAN(G,DY,X,Y) 和LGAN(F,DX,X,Y) 越大越好;而生成器则应尽可能地生成与X域(Y域)样本分布相近的虚假图像,从而使鉴别器无法辨别真假,LGAN(G,DY,X,Y)和LGAN(F,DX,X,Y)越小越好。
(2)辅助判别矩阵构成的辅助鉴别器生成对抗损失的计算公式见式(3)和式(4),因与全局鉴别器生成对抗损失的原理相同,故不再赘述。
2.4.2 循环一致性损失
循环一致性损失的提出是为了避免网络在训练过程中出现X域(Y域)中的多张图像只与Y域(X域)的同一张图像形成多对一映射关系的情况,导致不同图像景深域间的转换失去实质性意义的问题,同时可提升生成效果质量。本文借鉴CycleGAN 的思想,引入图像循环一致性损失和景深循环一致性损失以解决上述问题。
(1)图像循环一致性损失主要针对图像景深转换过程中的映射关系问题,其计算方式见
式(5)。其中‖F(G(x))-x‖1表示在X域中,输入的真实图像x经由生成器G和生成器F两次图像转换后,得到X域的虚假图像F(G(x))与输入的真实图像x进行L1 范数求解得到的值,即虚假图像与真实图像之间的差异性。同理,‖G(F(y))-y‖1表示Y域中虚假图像与真实图像的差异性。
(2)景深循环一致性损失主要用于提升生成图像的质量,通过增强原有图像前景目标的感知信息以加强生成图像效果的真实感,其原理与图像循环一致性损失相似,计算公式见式(6):
2.4.3 优化目标
将各损失进行加权之后,可得到本文所提出网络的总损失,其表达式见式(7)。其中,φ=10,ω=1。
由于在不同图像景深域之间的转换过程中需通过生成器与鉴别器之间的动态博弈来学习两个域之间的样本分布,因此本文希望全局鉴别器DX、DY和辅助鉴别器μDX、μDY对真假图像的分辨能力得以最大化,而生成器则应生成更加逼真的虚假图像,使鉴别器的分辨能力得以最小化,即最小化虚假样本分布与真实样本分布之间的JS 散度。同时,为避免转换过程中丢失过多的景深信息导致生成图像效果质量降低,也需将循环一致性损失最小化。因此,本文的整体目标损失可优化为式(8):
3 实验结果与分析
3.1 实验平台与基准数据集
由于本文提出的图像转换网络在训练过程中涉及大量的矩阵运算且需要对网络参数进行迭代更新,因此本文实验使用型号为NVIDIA Tesla V100、显存为32G 的GPU 对网络进行迭代训练以提高训练效率。为进一步加速网络计算效率,本文在CentOS 7 的操作系统上选择Pytorch 1.7.1 作为网络的计算框架,并结合Pytorch 内置的自动混合精度对网络的计算效率进行提升。
与现有的大多数背景虚化处理研究工作一样,本文选用2020 年的Advanced Intelligent Mechatronics 挑战赛中采用的Everything is Better with Bokeh (EBB)数据集[14]对本文提出的背景虚化处理网络进行训练。该数据集由佳能7D 数码单反相机在不同光线、不同场景、不同天气条件下进行拍摄得到,其包含4 694 组用于模型训练的图像对(深景深↔浅景深),深景深图像由窄光圈(f/16)拍摄得到,浅景深图像则用最高光圈(f/1.8)进行拍摄。此外还包含200 张用于评估模型的图像及200 张用于测试最终模型的图像(深景深)。在训练过程中,我们将数据集中的图像对随机打乱,使之成为非配对的图像集,并裁剪为256×256 的尺寸作为网络的输入,同时在训练过程中将学习率设置为0.000 2。
3.2 消融实验
为证明本文所设计的网络框架能够有效提升背景虚化处理的质量,本文进行了消融实验。其实验对比如图12 所示,其中:

图12 消融实验对比实验图Fig.12 Comparative experimental diagram of ablation experiment
①Cycle 表示原生CycleGAN 网络得到的背景虚化图像;
②Cycle+CAM 表示在原生CycleGAN 网络的基础上,将CAM 注意力机制引入到鉴别器中;
③Cycle+CAM+CBAM 表示在原生Cycle-GAN 网络的基础上,将CAM 注意力机制引入到鉴别器中以及将CBAM 注意力机制引入到生成器中;
④Cycle+CAM+CBAM+Depth 表示在③的基础上,引入前向景深循环一致性损失。
图12 中有4 组效果对比图,每组对比图中的每张图像有2 个细节区域,区域1 用于展示前景目标区域、区域2 用于展示背景区域的效果及状态。对于前景目标区域,从A 组和B 组对比图的细节区域1 中可以清晰地看到,在前景目标颜色较为艳丽的情况下,方法①和方法②会极大地改变前景目标的颜色,方法③对颜色影响较小,而方法④则基本不会对颜色产生影响。从C 组和D 组对比图中的细节区域1 中可以看到,4 种方法在清晰度上均不会导致前景目标发生失真。对于背景区域,从A、B 组对比图的细节区域2 可以看到,背景虚化效果的程度为:①<②<③≈④;在C、D 组对比图的细节区域2 中可以看到,背景虚化效果的程度为:①<②<③<④,程度越高,则越能凸显图像的主体,即前景目标越显眼。
3.3 图像感知信息对比实验
为验证本文所提的图像转换网络在背景虚化处理的过程中,模型能增强原有图像前景目标的感知信息,使生成图像效果的真实感得到进一步提升,本实验从可视化图像的注意力信息、景深信息以及边缘信息3 个维度对生成图像进行测试评估。其中注意力信息、景深信息、边缘信息分别由注意力可视化算法[31]、单目视觉景深估计算法[30]、边缘检测算法[32]得到,实验对比如图13 所示。
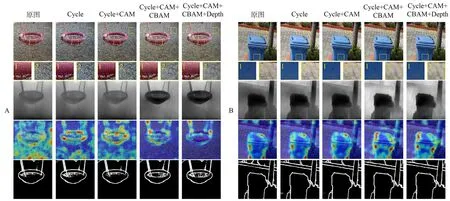
图13 感知信息对比实验图Fig.13 Experimental diagram of perceptual information comparison
图13 展示了2 组实验对比,其中每组的第一行为使用不同方法得到的背景虚化图像;第二、三、四行为背景虚化图像的感知信息图像,分别为表示景深信息的景深图像、表示注意力信息的显著图像、表示图像主体轮廓信息的边缘信息图像。从A、B 两组实验的第二行景深图像可以看到,方法③和方法④能弱化背景区域的景深信息并增强前景目标的景深信息,从而凸显前景目标,使处理后的背景虚化效果更加显著;同样地,从两组实验中的第三行显著图像中可以看到,方法③和方法④能更好地注意到图像主体,有利于在图像转换过程中区分前后景;而对于第四行的边缘信息图像,方法③和方法④仍然优于其他方法。
由于上述的定性分析无法对比方法③、④的性能高低,为了进一步对比方法③和方法④的性能,本实验选用结构相似性SSIM 指标进行定量比较。
结合图13 和图14,一方面,由于背景虚化处理过程中弱化了占比较大的背景区域的感知信息,虚化后图像背景部分的景深信息更少,即虚化图像呈现出了较好的效果,因此,虚化后的感知信息图与原始感知信息图差异较大,导致所有方法的平均SSIM 较低;另一方面,本文方法也同时强化了前景目标区域的感知信息,虚化图像对于前景目标的关注更多,使前景区域在结构上也与原图保持了更多的相似性。所以,与其他方法相比,本文方法④的SSIM 较高,呈现出的虚化效果更富有层次感。

图14 平均SSIM 对比数据Fig.14 Average SSIM comparison data
3.4 与现有工作的对比
3.4.1 图像转换方法对比
为了展示本文所提出方法的优势,本实验与当前在图像转换领域表现出色的方法进行了比较,其中包括AGGAN[33]、Dual-SAG-CycleGAN[34]、Pix2Pix[20]等生成对抗式网络。各方法的效果图如图15 所示。

图15 不同方法效果对比图。(a)老妇;(b)禁止左转标志;(c)滑板车;(d)树。Fig.15 Effect comparison diagram of different method. (a) Old woman;(b) No left turn sign;(c) Scooter;(d) Tree.
从图15 中细节区域1、2 可以看到,AGGAN方法在部分图像中难以分辨前后景,从而导致前景目标也进行了模糊处理,并在生成的背景虚化图像中存在失真现象;Dual-SAG-CycleGAN 方法同样存在难以分辨前后景和图像失真的现象,并且在背景区域的虚化效果不够明显,难以凸显前景目标;对于Pix2Pix 方法,虽然生成的图像不会失真,但是与前两者一样存在难以分辨前后景的现象,如从图15(a)、(d)图像可以看出,前后景都进行了背景虚化处理;而从图15(b)、(c)图像可以看出,在前景目标是清晰状态的同时,背景区域模糊程度较低。对于本文所提出的方法,其分辨前后景的能力与背景虚化处理效果的质量都是最优的,并且图像不会产生失真的现象。
为了进一步验证前述的实验结果分析的合理性,本实验欲采用定量数据进行分析。由于现有大部分工作主要是基于主观评价指标对背景虚化效果进行评价分析[1,21],因此本实验以调查问卷的形式,让多名调查对象比较现有SOTA 方法与本文所提方法的视觉效果差异,并在1~10 分的区间内进行评分。此次共有49 名对象参与实验,其中硕士研究生35 名,本科生14 名,男女比例约为2∶1,参与者以主观的审美意识评判图像的背景虚化效果,给的分值越高表示效果越好,然后将参与者的评分结果进行汇总统计,获得每个方法的意见平均分,其统计数据如图16 所示。从图16 可以看到,本文所提方法获得的平均意见分是最高的,说明上述针对实验结果的分析较为合理。

图16 调查问卷数据Fig.16 Questionnaire data
此外,本实验通过对比不同方法的模型大小和背景虚化图像(分辨率为256×256)生成的时间,验证了本文所设计的图像转换网络在模型量和生成效率上的优势。其中Dual-SAG-CycleGAN、Pix2Pix 以及本文方法包括生成器模型和鉴别器模型2 部分,AGGAN 则包括注意力模型、生成器模型、鉴别器模型3 部分。各方法模型大小数据如表1 所示。从表1 可以看出,本文方法在模型量上优于其他方法。

表1 各方法模型大小与图像生成时间Tab.1 Model size and image generation time of each method
3.4.2 背景虚化方法对比
为了进一步验证本文所提方法的有效性,本文选取专注于背景虚化工作的BGGAN[22]以及Stack_DMSHN[15]作为比较对象,各方法在同一副图片上的背景虚化效果如图17 所示。

图17 不同背景虚化方法效果对比图。A:栅栏;B:池塘。Fig.17 Effect comparison diagram of different method for background defocus. A: Fence;B: Pond.
从图17 A 组可以看出,3 种方法对于中心物体的聚焦能力比较接近,但本文方法所生成的前景色泽及纹理最接近原图,且从细节区域1 可以看出,BGGAN、Stack_DMSHN 所生成图像会造成部分前景失真;从细节区域2 可以看出,本文方法虚化程度也更高。从B 组细节区域2 可以看出,相比其他两种方法,本文方法对微小前景的聚焦程度更高,即区分前后景的能力更强。
为进一步比较3 种方法的有效虚化程度,同样引入注意力可视化算法分别展示各方法在背景虚化方面的性能。从A 组的注意力可视化图可以看出,本文方法最大程度地保持了对于前景目标的聚焦,有利于实现更有效的背景虚化。在B 组的对比中,BGGAN、Stack_DMSHN 两种方法无法注意到微小的前景目标,即凸显微小前景目标的能力不强,因此虚化效果不佳。通过注意力可视化图的对比可知,本文方法对于前景目标的感知更加突出,即区分前后景的能力更强。
4 结论
现有生成对抗网络在背景虚化处理过程中,往往是无差别地提取整张输入图像的特征,因此生成器在生成图像时也容易丢失图像原有的细节特征,导致图像失真。为了解决这些问题并减少制作样本数据带来的困难,本文选用CycleGAN作为基础网络框架,通过引入景深循环一致性损失对网络框架进行重新设计,同时结合CBAM注意力模块和CAM 注意力模块分别对生成器和鉴别器的结构进行改进,使其在背景虚化处理过程中能着重关注于前景目标,并在增强前景目标区域的感知信息的同时,提升网络区分前后景的能力和生成图像效果的质量。同其他方法相比,本文方法的背景虚化效果更佳且失真度更低,模型大小为56.10 MB,图像生成时间为47 ms,相比现有模型也具有更大优势。
