结合噪声掩模训练和最近邻搜索机制的轻量级椒盐去噪
2023-09-14黄成强
黄成强,金 星
(遵义师范学院 物理与电子科学学院,贵州 遵义 563006)
1 引言
随着图像处理的应用渗透到各个领域,对输入图像的质量要求越来越苛刻。图像去雾[1]中输入图像的噪声将会降低去雾效果,语义分割[2]中图像的噪声会造成分割边界失真,车牌识别[3]和人脸识别[4]中噪声的存在会降低识别精度。然而,图像在传感器采集、存储和传输过程中不可避免地受到椒盐噪声的污染,目前实现高性能椒盐去噪仍具挑战性。业界早期主要基于对像素灰阶的判断和分析实现去噪,研究了中值滤波[5]、改善的中值滤波[6]、概率滤波[7]、权重滤波[8]和重复滤波[9]等方法,这些研究推动了椒盐去噪方法的发展。但是,由于在噪点标记步骤并未精确区分噪声像素和正常像素、在噪声去除步骤没有探索到高性能去噪机制等多方面的原因,这些方法尚未达到理想的去噪效果。近年来,随着计算机性能的大幅提升,尤其是图形处理器(GPU)在数据处理速度和吞吐量方面的突破性进展,以及互联网给图像大数据的获取提供的便利,基于图像大数据和人工神经网络的椒盐去噪方法成为研究的热点。最初,人工神经网络的研究是为了实现图像分类和识别,诸如LeNet5[10]、AlexNet[11]、Vgg-Net[12]、GoogLeNet[13]和ResNet[14]等网络在分类精度方面不断取得进步。由于图像处理的目的是对输入图像进行增强或复原,需要输出一张图像,而非如上述网络输出一个分类结果,因此,不能将这些网络直接套用于图像去噪。2016 年,文献[15]提出将卷积神经网络(CNN)应用到高斯噪声去除中,通过在正常图像中添加随机密度的噪声并成对地提取由正常图像块和噪声图像块构成的数据对,构建机器训练需要的大数据。接着,通过搭建深度卷积神经网络对人工构造的数据集进行机器训练,得到了超越传统方法的去噪效果。虽然该文献处理的对象是高斯噪声,但是这是一项将人工神经网络与图像去噪相结合的突破性工作,为卷积神经网络应用到椒盐去噪提供了可借鉴的方法和思路。在该项工作的基础上,文献[16]提出了实现椒盐噪声去除的深度卷积神经网络,采用17 个卷积层,配合对应的激活函数和批量标准化,采用对比输出图像与干净图像之间的差异性构造损失函数,得到了超越传统方法的椒盐去噪效果。该方法借鉴了文献[15]中构建数据集和搭建网络的思路,实现了基于CNN 的端到端椒盐噪声去除。文献[17]将中值滤波层嵌入到卷积神经网络层。它包含39 个各类层,总体上前半部分网络旨在通过多次重复的中值滤波消除椒盐噪声,后半部分网络旨在通过残差层的学习恢复图像细节。
上述基于卷积神经网络的深度学习几乎都通过网络权重参数对图像中所有像素单元进行加权求和操作。实质上,对于输入的噪声图像来说,不是所有像素单元都被噪声污染。因此,更加合理的处理方法应该是只针对噪声点进行处理,对正常点直接输出。为了改进卷积神经网络椒盐去噪方法的这一缺陷,首先需要对输入图像进行噪点标记。业界在噪点标定方面已开展了一定的研究。极点标定法[8]将图像中极值像素点标记为噪声点,对于8-bit 的数字图像,极值点就是灰阶为0 或255 的像素点。该方法的普适性弱,如果原图像自带很多的正常极值点,它们都将被误判为噪点。为了解决这个问题,业界提出了极值图像块标记[7],该方法通过比较以扫描点为中心的窗口中正常点和极值点的数量判断扫描点是否为噪点,该方法对于高密度噪声来说还存在较多误判。最后,业界提出了均值标定法[9],该方法通过窗口中像素的平均灰阶进行噪点判断,但是对于原图像中本身就存在较多极值点的情况,该方法将失效。
本文训练了一个卷积神经网络,用其生成的噪声掩模可以精准标记正常点和噪声点。接着,在更新像素单元的过程中直接输出标记为正常点的像素。对于被标记为噪声的像素,本文的处理方法是搜索最近邻的正常像素代替。本文的创新点主要包括:(1)提出了一种精简而高效的轻量级卷积神经网络,相比于传统网络,网络深度降低1/2。此外,在网络的中间层采用深度可分离卷积代替常规卷积,大幅降低了运算复杂度。(2)提出了一种选择性去噪方法,对标记为正常点的像素单元不做处理,应用相邻像素灰阶较为接近的性质,搜索与噪点空间距离最近的正常点用以更新噪点。该方法充分结合了卷积神经网络的智能识别优势和图像中相邻像素灰阶较为接近的性质,实现了高性能椒盐去噪。
2 相关技术
2.1 现有的噪声掩模生成机制
2.1.1 极点标定[8]
极点标定将输入噪声图像中灰阶为0 或255的点标记为噪点,其他点为正常点。该方法如式(1)所示:
其中:Mij为噪点标记输出,即噪声掩模,它是一个二值图像,噪声点标记为0,正常点为1。imgij表示输入图像中第i行、第j列的像素灰阶,该图像共计H行W列,因而i的取值是1~H之间的整数,j的取值是1~W之间的整数。
2.1.2 极值图像块标定[7]
极值图像块标定生成噪声掩模的原理是扫描图像中灰阶为0 或255 的像素,取以其为中心的k×k窗口,统计其中灰阶为0 以及灰阶为255 的像素数量,根据这些数量的大小关系输出标记值。
如果扫描到的像素灰阶为0,则统计滑动窗口中灰阶为0 的像素个数N0,窗口中灰阶为非0 的像素数量如式(2)所示:
其中k2为窗口总的像素数量。
如果扫描到的像素灰阶为255,计算灰阶为255和非255的像素数量方法与计算灰阶为0 与非0 的像素数量方法类似:
极值图像块标记法如式(3)所示。扫描图像中各个像素单元,当灰阶为0 时,如果滑动窗口中灰阶为0 的像素点很少,则判定为噪点。当灰阶为255 时,如果滑动窗口中灰阶为255 的像素点很少,则判定为噪点。其他情况下将扫描点判断为正常点。
2.1.3 均值标定[9]
均值标定法通过滑动窗口中的平均灰阶的大小生成噪声掩模。首先计算滑动窗口中像素的平均灰阶av。如式(4)所示:
当灰阶为0 时,如果滑动窗口中像素的平均灰阶相对较大则判定为噪点。当灰阶为255 时,如果滑动窗口中像素的平均灰阶相对较小则判定为噪点。其他情况下将扫描点判断为正常点。
2.2 应用卷积神经网络的椒盐去噪[16]
适用于图像分类的卷积神经网络一般在通过多个卷积充分地提取了图像特征之后,将通过全连接层、softmax 层给出分类结果,其采用的损失函数一般为交叉熵损失函数。不同于分类网络,图1 是一个典型的椒盐去噪卷积神经网络,在输入端通过1 个卷积层和激活函数初步提取图像特征,最后通过1 个卷积层恢复去噪图像。在首尾之间是10 多个重复的卷积、批量标准化和激活层。相比于图像分类网络,适用于椒盐去噪的卷积神经网络有下列特征:
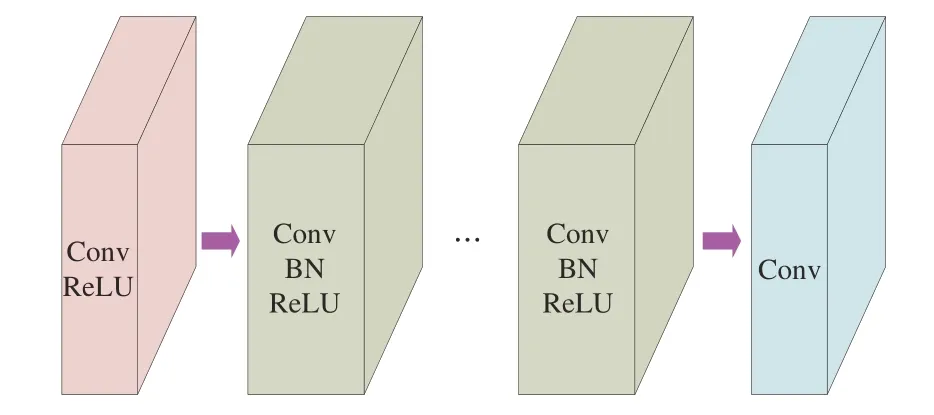
图1 用于椒盐去噪的卷积神经网络Fig.1 CNN for salt-and-pepper denoising
(1)网络输出是一幅图像。由于目的是实现椒盐噪声去除,网络的输出端是一幅图像而非分类结果。
(2)无需使用池化层。在使用卷积神经网络处理输入图像的过程中不再需要使用池化层来缩放图像,从始至终图像的分辨率不改变,以保证输出图像和输入图像分辨率相同。
(3)损失函数变化。在图像分类中多采用交叉熵损失函数,但是该损失函数不再适用于椒盐去噪网络。为了正确地指导权重参数的优化,去噪网络中多采用输出的去噪结果图像和原始干净图像之间的均方差(mse)作为损失函数:
其中:W和H分别为图像的横向和纵向分辨率,img 为原始干净图像,img'为卷积神经网络输出的去噪图像。mse 高效地描述了处理所得图像与原始干净图像的差异,将有效指导网络权重的优化。
3 噪声掩模训练
3.1 训练数据准备
3.1.1 图像块截取
截取图像块的方法如图2 所示。在一张干净图像中以20 的步长从图像的左上角开始截取分辨率为70×70的图像块。对于分辨率为200×200的图像,横向和纵向上各截取5 次,从左到右、从上到下扫描,得到25 个70×70 的图像块。为了能够完整表征图像特征,图像块的分辨率不宜太小;为了避免训练参数量过大,图像块的分辨率不宜太大。因此,本文选用70×70 的图像块分辨率。

图2 图像块截取方法示意图Fig.2 Schematic diagram of image block interception method
3.1.2 生成噪声图像-噪声掩模的数据对
为了训练出噪声掩模,需要给卷积神经网络输入噪声图像。网络的输出将与原噪声掩模进行对比,生成损失函数,通过损失函数的迭代优化训练不断改善输出。因此,训练网络的噪声图像-噪声掩模对数据至关重要。本文在上述生成的70×70 图像块基础上,添加随机密度的椒盐噪声,生成噪声图像。与此同时,将每次添加噪声的位置标记为1,而将图像中未添加噪声的像素标记为0,从而生成噪声掩模。值得注意的是,噪声图像和噪声掩模一一对应,构成“噪声图像-噪声掩模”对。此外,为了增强数据集的鲁棒性,给每个图像块添加噪声的密度是随机确定的,噪声密度取值是0.1~0.9 之间的随机数。图3 是几个图像块对应的噪声图像-噪声掩模对,从中可以看出噪声图像是在图像块的基础上添加噪声所得,噪声掩模将添加噪声的位置标记为白点,正常像素标记为黑点。

图3 噪声图像-噪声掩模对Fig.3 “Noise image”-“noise mask” pairs
3.1.3 构建噪声图像-噪声掩模对数据集
在上述图像块截取和生成噪声掩模的基础上,噪声图像-噪声掩模对数据集的构建方法如图4 所示。本文选用91images 数据集作为原数据,将彩色图像转换为黑白并调整分辨率。以20的步长从每张图像中截取出25 个图像块,对这些图像块添加随机密度的椒盐噪声得到噪声图像块。与此同时,将添加噪声的位置标记为1,其他位置为0,生成与噪声图像所对应的真实噪声掩模。最后,将噪声图像块和噪声掩模块组合在一起构成一一对应的噪声图像-噪声掩模对。
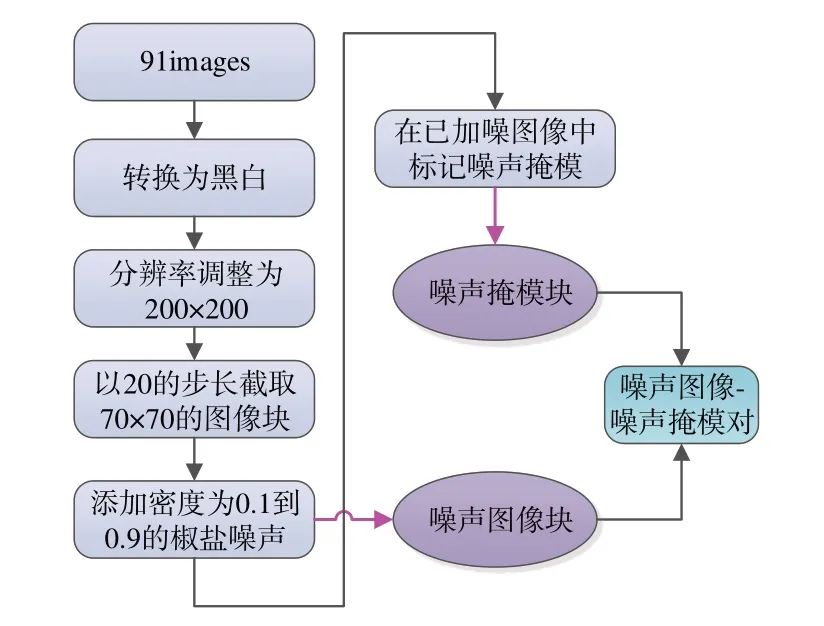
图4 噪声图像-噪声掩模对数据集的构建方法Fig.4 Construction method for noise “noise image”-“noise mask” pairs dataset
3.2 卷积神经网络模型
3.2.1 模型结构
图5 为本文采用的卷积神经网络模型。本文将噪声图像-噪声掩模对数据集作为训练数据,将网络输出图像与理想噪声掩模之间的mse 作为损失函数。网络模型包括9 个卷积层,其中第一个卷积包含卷积和激活操作,对输入的噪声图像生成64个卷积张量。最后一个卷积层对输入的64个张量生成1 张噪声掩模。首尾之间是7 个重复的深度可分离卷积,如图6 所示。MobileNet-v1[18]已经证实深度可分离卷积的复杂度比常规卷积降低了8~9 倍。如图6 所示,先采用3×3 的卷积核处理64 个输入通道,随后执行批量标准化和ReLU 激活。依次采用1×1 的卷积核处理所有通道,得到64 个处理后的通道,这步称为点卷积。最后,经过批量标准化和激活之后输出64 个通道。该网络模型的创新之处在于:(1)相比于传统网络模型,网络深度降低1 倍;(2)在中间层采用深度可分离卷积代替常规卷积,大幅降低了运算复杂度。该方法采用更小的网络深度和更加简单的卷积结构,达到了很好的噪声掩模复原效果。
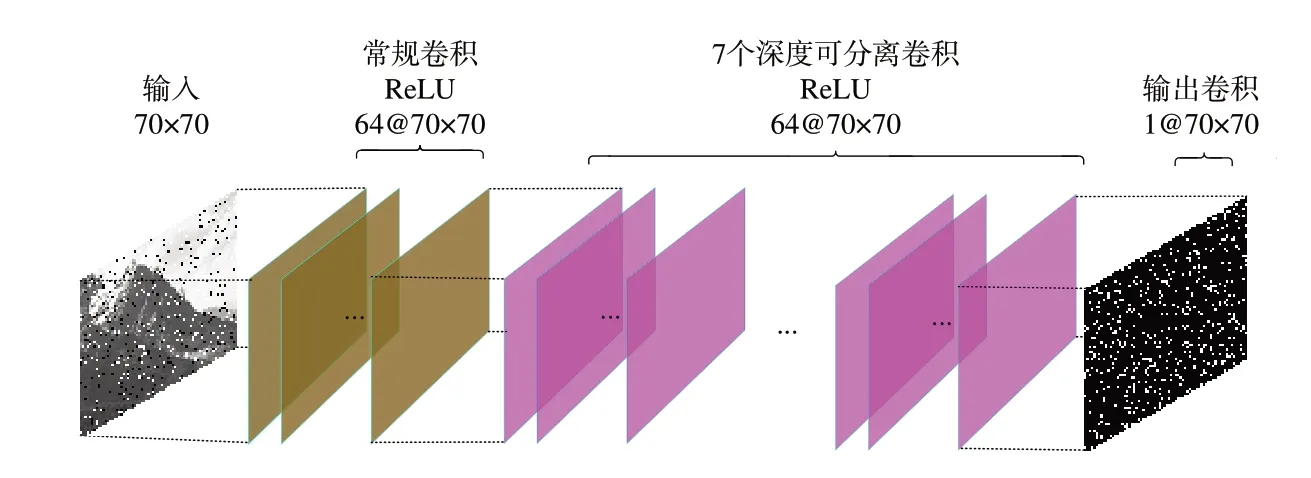
图5 轻量级卷积神经网络Fig.5 Lightweight CNN
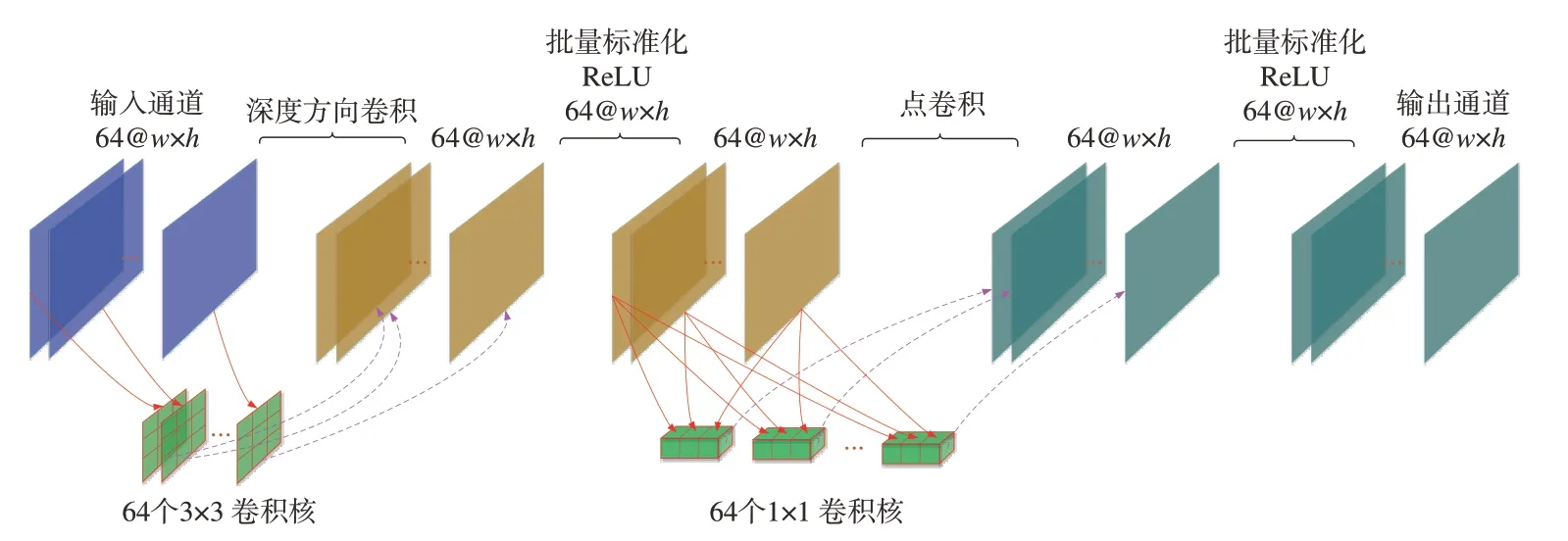
图6 深度可分类卷积Fig.6 Depth separable convolution
3.2.2 各层功能
对于输入噪声图像,通过图5 所示的网络预测其噪声掩模,图7 为各个卷积层的功能说明。首先,首端常规卷积神经网络将提取出输入噪声图像的轮廓信息。接着,通过7 个深度可分离卷积全面地提取噪点信息。从图7 可以看出,从第1 到第7 个深度可分离卷积层,随着深度的增加,图像细节逐渐被忽略,噪点信息逐渐被凸显。从第1 到第3 个深度可分离卷积的输出中可以看到诸如马匹等图像细节,第4 到第7 个网络的输出中图像细节已被黑点代替,图中零星可见的白点为噪点。值得注意的是,7 层深度可分离卷积神经网络的输出实际上有64 张图,图中所展示的仅为64 个中的1 张图。最后将第7 层的64 张图通过1 个常规卷积层合并到尾端常规卷积层的输出,得到噪声掩模。

图7 各个卷积层的功能Fig.7 Function of each convolution layer
首端常规卷积输出的64 个张量将输入深度可分离卷积进行抽象特征的提取,深度可分离卷积内部各层的功能如图8 所示。首先,通过深度方向的卷积处理64 个张量,得到深度方向卷积输出。接着,通过批量标准化对输出所得数据进行微调,使得这些数据仍然服从正态分布。由于调整的数据数值变化幅度较小,批量标准化步骤的输出图像几乎与输入一致。批量标准化能够解决训练过程中的梯度消散问题,让数据的分布一致,使得模型的训练更加稳定。批量标准化的下一步是激活,通过ReLU 函数来抑制均值以下的图像细节,激活函数输出如图8 所示。激活函数的主要作用是加入非线性因素,以解决线性模型表达能力不足的缺陷。随后,通过点卷积继续处理64 个张量,再依次通过批量标准化和激活函数处理。

图8 深度可分离卷积内部各层的功能Fig.8 Function of each layer in depth separable convolution
4 最近邻搜索机制
4.1 理论根据
数字图像多采用互补金属-氧化物-半导体(CMOS)图像传感器[19]获取,它是一种典型的固态传感器,其结构如图9 所示,由光敏像素阵列、行驱动器、列驱动器、时序控制逻辑、模拟到数字(AD)转换器、数据总线输出接口和控制接口等几部分组成,各个组成部分通常都被集成在同一块硅片上。每个像素单元通过光敏二极管采集信号,光敏二极管随入射光的强弱产生对应强度的电信号,通过行控制线和列控制线的配合采集各个像素单元的电信号,最后通过AD 转换器输出数字信号,将数字图像存储。由于相邻像素接收的曝光量十分接近,而且图像分辨率越大,单个像素所表征的颗粒尺寸就越小,相邻像素感知到的光强越接近,使得AD 转换器输出的对应数值十分接近。因此,像素之间的空间距离越近,灰阶就越相近。
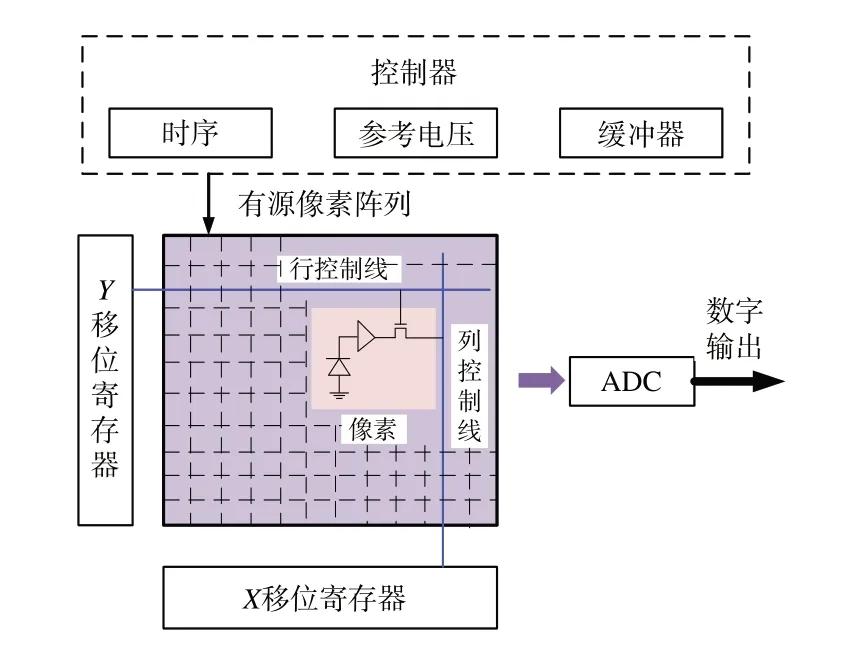
图9 CMOS 图像传感器结构图Fig.9 Structure chart of CMOS image sensor
4.2 实现方法
式(6)是基于最近邻搜索机制的去噪方法:
其中:img 为输入图像,img'为输出图像,M为已训练的噪声掩模,L表示搜索到的最近邻正常像素的点集,L(R,k)表示搜索半径为R的圈层中第k个正常像素的灰阶。扫描图像中各个像素单元,其中i和j分别表示扫描点的行号和列号,其取值范围分别是[1,H]和[1,W],H和W分别是输入图像的纵向分辨率和横向分辨率。对于噪声掩模中标记的正常像素,直接输出灰阶;对于噪声掩模中标记的噪声像素,取搜索到的最近邻正常点的平均灰阶代替扫描点的灰阶。
图10 为实现最近邻搜索机制的示意图,其中蓝点表示正常像素,红点代表噪声像素。噪点标记的精确度对最近邻搜索机制的正常实现有着非常关键的影响。最近邻搜索机制就是搜索与噪声像素距离最近的正常点,生成代替噪声点的新灰阶。如图10(a)所示,与噪声像素a0最相邻的正常像素是b1=20、b2=19、b3=20 和b8=21,因此采用这4 个灰阶的平均值20 作为a0的新灰阶。由于在最内层窗口中就能够搜索到正常像素,此时的搜索半径R=1。对于无法在最内层窗口中搜索到正常像素的情况,将放大窗口尺寸,直到搜索到至少存在1 个正常像素的外围层。如图10(b)所示,当搜索半径为2 时,第2 层上的正常像素c2=104、c6=105、c7=103、c11=103 和c12=105 的平均值104 将作为噪点a0的新灰阶。如果还未搜索到正常点,搜索半径将进一步增大。如图10(c)所示,当搜索半径为3 时,第3 层上的正常像素d3=212、d9=201、d10=201、d16=206 和d17=215 的平均值将作为噪点a0的新灰阶,以此类推。
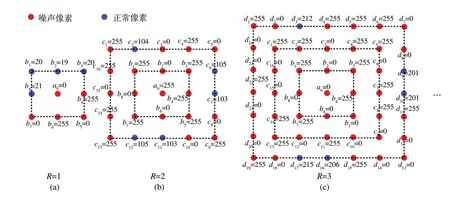
图10 最近邻搜索机制示例Fig.10 Example of the nearest searching mechanism
该方法的优点如下:(1)使用最近邻正常像素的平均灰阶更新噪点,提升鲁棒性。与噪点空间距离相等的像素往往不止1 个,例如搜索半径为1 时,最多可以存在8 个正常点;搜索半径为2时,最多可以存在16 个正常点。采用多个最近邻的正常像素的平均灰阶更新噪点,可以达到综合考虑噪点周边各个方向的效果,从而提高鲁棒性。(2)通过半径自适应扩展搜索最近邻的正常像素。在最近邻搜索机制中,优先搜索与噪点距离最近的正常像素单元,搜索半径R的初始值为1。在最近层未搜索到正常点的情况下才会扩展搜索半径,直到寻找到至少1 个正常像素。
5 实验结果与分析
5.1 模型训练
本文在Tensorflow 平台调用keras 组件搭建如图5 所示的轻量级卷积神经网络。该训练采用mse 作为损失函数。在训练开始前,设置初始学习率为0.001,如果训练过程中损失值在20 个周期内没有降低,学习率将以0.2 的因子衰减,学习率下限为0.000 000 01。调用RTX3080 型GPU训练50 个周期,批量为8,训练耗时107 min。训练曲线如图11 所示,可以看出损失值和准确率均快速收敛。
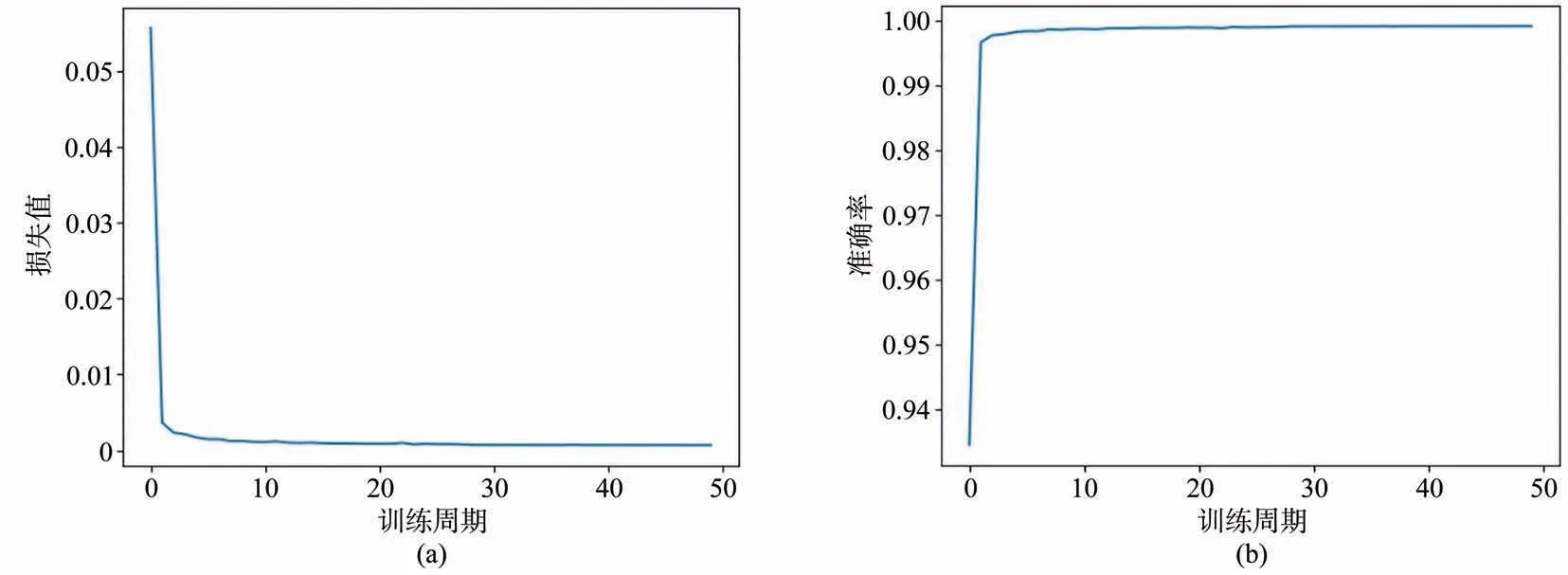
图11 训练曲线。(a)损失值曲线;(b)准确率曲线。Fig.11 Training curves. (a) Loss curve;(b) Accuracy curve.
5.2 噪声掩模性能测试
图12 为不同方法生成的噪声掩模图像。实验选择具有代表性的3 张图像,其中kodim18 中有大量偏黑的像素和少量高亮像素,kodim20 中的图像细节中存在大量的高亮像素以及少量偏黑像素,而kodim24 中存在少量高亮像素和大量灰阶居中的像素。为了检测不同噪声密度下的掩模质量,分别给kodim20、kodim24 和kodim18添加低、中和高密度的椒盐噪声。在图12 的噪声掩模图像中,噪点用黑点标记,正常点用白点标记。值得注意的是,原噪声图像中噪点均匀分布,不受图像自有像素的影响。图12 所示的噪声掩模图像中黑点分布越均匀,就越符合客观事实,噪声掩模的质量就越高。从图12 可以看出,极点标定法由于将极值像素点标记为噪点,当图像中本身存在较多极值点时容易造成误判,如图12(b3)和图12(c3)所示,大量的天空像素被标记为噪点,噪声掩模图像严重受到原图像中的极值像素的影响而产生大面积误判。此外,均值标定法根据窗口中像素的平均灰阶与极值的差异判断噪点,当图像某些区域中极值像素的分布较为集中时,该方法容易失效。因此,图12(b5)和图12(c5)中存在大量的误判点。极值图像块标定法通过对比窗口中极值像素和正常像素的数量判断噪点,相比于上面两种方法,它更好地运用了噪点分布的特征,生成的掩模几乎不再受到原图像中极值像素的影响,达到了相对理想的效果,如图12(b4)和图12(c4)所示。相比于这些传统方法,本文提出的CNN 标定方法通过机器学习掌握噪点分布的特征,是一种智能噪声掩模生成方法。如图12(a6)、图12(b6)和图12(c6)所示,噪声掩模图像几乎不再受到原图像中极值像素的影响,尤其是图12(a6)呈现了完美的均匀噪点分布,与理想噪点分布已经十分接近,更加说明了该方法具有较强的鲁棒性。此外,图12(c2)中的屋檐线条不再出现在图12(c6)中,说明该方法不再受到图像边缘的影响而产生误判。
从主观视觉效果上,已经看出CNN 噪声掩模质量更高。如式(7)所示,本文采用误判率MR客观评估各种方法生成噪声掩模的质量:
其中:MR 为误判率,N1为原图中实际存在的噪点数量,N2是通过标定算法标定出的噪点数量。误判率越低,说明噪点标定的精确度越高。
本文对kodim 图像添加各种级别的噪声,噪声密度从0.1~0.9。对比数据如表1 所示。与上述分析一致,极点标记法由于容易将极值点标记为噪点,误判率较高。均值标定方法容易在大片极值点的图像区域失效,因此误判率较高。相比于前两者,极值图像块标记根据窗口中极值点和正常点数量的关系标记噪点,更好地把握了噪点分布的特征,因此误判率得到改善。本文提出的深度CNN 标记方法通过机器学习全面提取噪点分布的特征,达到了最佳噪声掩模质量。表1 显示,本文方法生成噪声掩模的误判率分别比极点标记、均值标记和极值图像块标记降低了94.79%、94.79%和83.65%。
5.3 最近邻搜索机制消融实验及分析
通过峰值信噪比(PSNR)评估椒盐去噪的性能。在每次实验中,不同密度的椒盐噪声随机地添加到原始图像中,sij表示去噪后的图像,xij表示原始图像:
此外,采用信息损失度(MSE)评估椒盐去噪算法的信息损失:
其中:xij为原图像,sij为滤波后的图像,W、H为分辨率。MSE 越小越好。
为了验证最近邻搜索机制对去噪性能的改善,进行了如下消融实验。在噪点标记步骤一律采用CNN 标记,在噪点去除步骤分别采用中值滤波、三权重因子、自适应概率滤波、改善的中值滤波、均值标定重复滤波和最近邻搜索方法,对比PSNR和MSE。分别对kodim20、kodim24 和kodim18 添加低、中和高密度椒盐噪声,同样采用CNN 标记,不同去噪方法进行处理的结果如表2 所示。值得注意的是,为了单纯验证去噪方法的性能,表中所有方法都预先采用上述CNN 方法进行噪点标记。例如,在执行中值滤波前先采用CNN 方法对噪点进行标记,对于标记为正常的像素不做处理,对于标记为噪点的像素通过中值滤波去噪。从表2 可以看出,最近邻搜索方法的PSNR 最大且MSE 最小,说明其去噪效果优于其他方法。
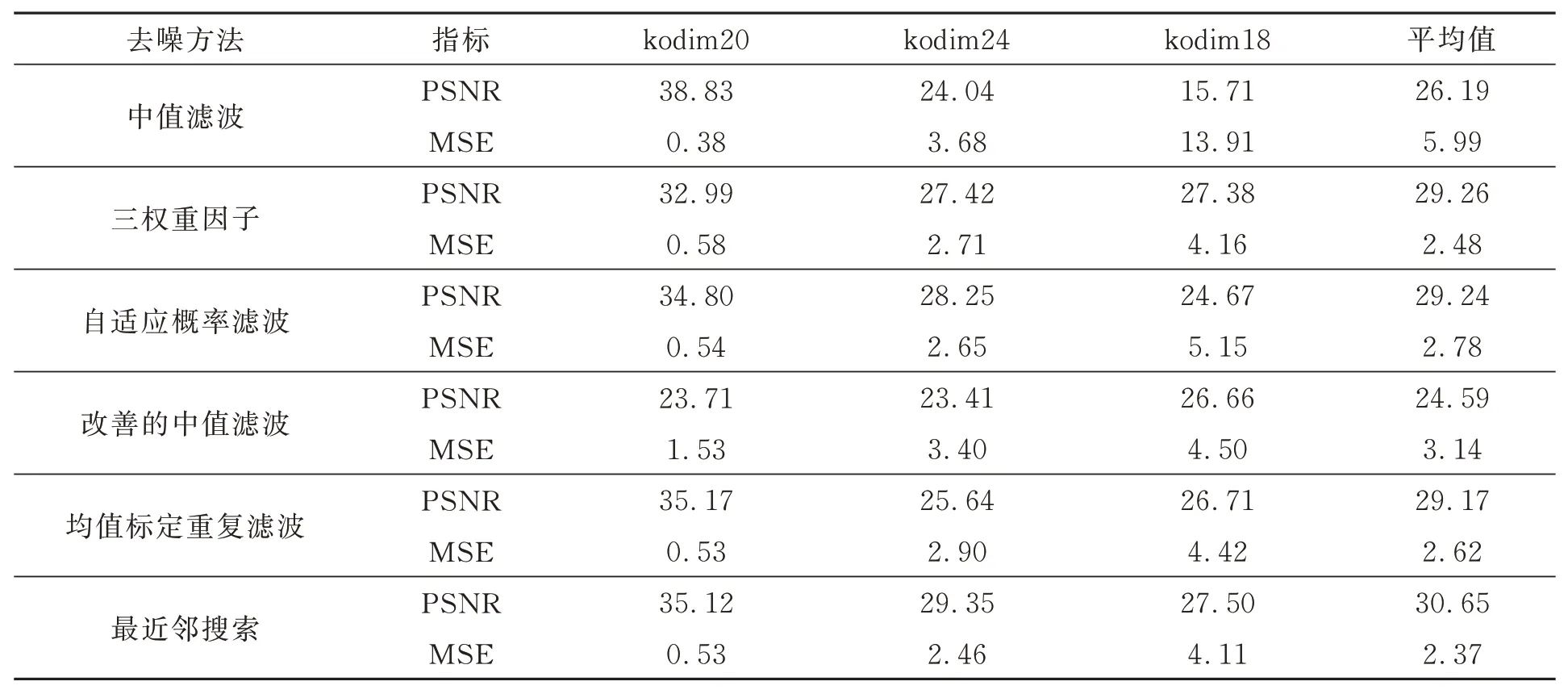
表2 相同噪点标记下的去噪性能对比Tab.2 Comparison of denoising performance with the same noise marking
最近邻搜索的机理是搜索与噪点在空间上最邻近的正常点代替噪点。该机理从两个方面提升去噪性能:(1)代替噪点的是正常点。传统的去噪方法中代替噪点的不一定是正常点,例如中值滤波及其改善版本中噪点周围几个像素灰阶的中值点不一定就是正常像素。此外,如果选用了一些噪点,三权重因子生成的像素灰阶将不是正常像素的灰阶。(2)最近邻原则。从图像生成的角度,最近邻正常像素点是代替噪点的最佳选择。然而,传统方法没有较好地将这一性质应用到去噪中。
5.4 椒盐去噪性能测试
5.4.1 代表性图片的椒盐去噪性能测试
不同噪声密度下的椒盐去噪图像视觉效果对比如图13 所示,分别对kodim05、kodim24 和kodim23 图像添加20%、50%和80%的噪声,再分别采用各种方法去噪。本文提出的方法将与7 个传统方法进行对比,其中包括5 个基于像素灰阶的方法和2 个基于CNN 的方法。基于像素灰阶的去噪方法中,中值滤波将所有像素单元的灰阶无选择性地采用3×3 滑动窗口的中值代替,虽然流程简单,但是由于缺少噪点标定步骤,对所有像素单元进行无差别滤波,该方法将造成较大的信息损失,如图13(a3)、图13(b3)和图13(c3)所示。概率滤波采用具有最大概率的相邻像素灰阶代替噪点灰阶,但是该方法在处理高密度噪声时容易失效,如图13(b5)和图13(c5)所示。

图13 不同去噪方法的处理效果对比Fig.13 Comparison of visual effect for image processed by different denoising method
由于采用的噪点标记方法误判率较高,改善的中值滤波方法和均值标定重复滤波方法处理高密度噪声图像存在残留噪点,如图13(b6)、图13(c6)和图13(b7)所示。三权重因子算法通过可调窗口搜索噪点周边的正常点,确保重构噪点的信息是正常像素灰阶,再采用这些正常像素单元灰阶的权重之和代替噪声像素单元的灰阶,充分利用了噪点周边的正常点,达到了良好的去噪效果。因此,在基于像素灰阶的方法中三权重因子算法表现相对优异,如图13(a4)和图13(c4)。但是,该方法由于噪点标记方法采用极点标记,在高密度下处理所得图像存在一些噪点残留,如图13(b4)所示。
在基于CNN 的去噪方法中,Liang CNN 采用多达39 层的深度残差网络进行去噪。Xing CNN中采用17 层卷积神经网络进行去噪,训练50 个周期快速达到收敛。实质上,在去噪过程中不应该对原图像中的正常像素做任何改变。然而,该方法对原图像中包括正常像素在内的所有像素均进行CNN 去噪,使得该方法的信息损失较大。本文采用9 层的深度卷积神经网络模型生成噪声掩模,经过50 个周期达到收敛,获得了一个误判率极低的高质量噪声掩模,对标记为正常点的像素单元不做任何处理。接着,基于相邻像素灰阶较为接近的性质,本文采用最近邻搜索机制,利用噪点周边最近的正常点代替噪点。由于本文提出的方法充分地结合了CNN 方法能够精确识别噪点的优势和相邻像素灰阶接近的性质,达到了理想的去噪效果,如图13(a10)、图13(b10)和图13(c10)所示。表3 中,本文提出的去噪方法所得图像的PSNR 和MSE 的平均值分别为28.40 和3.23,相比于传统方法达到了最佳。
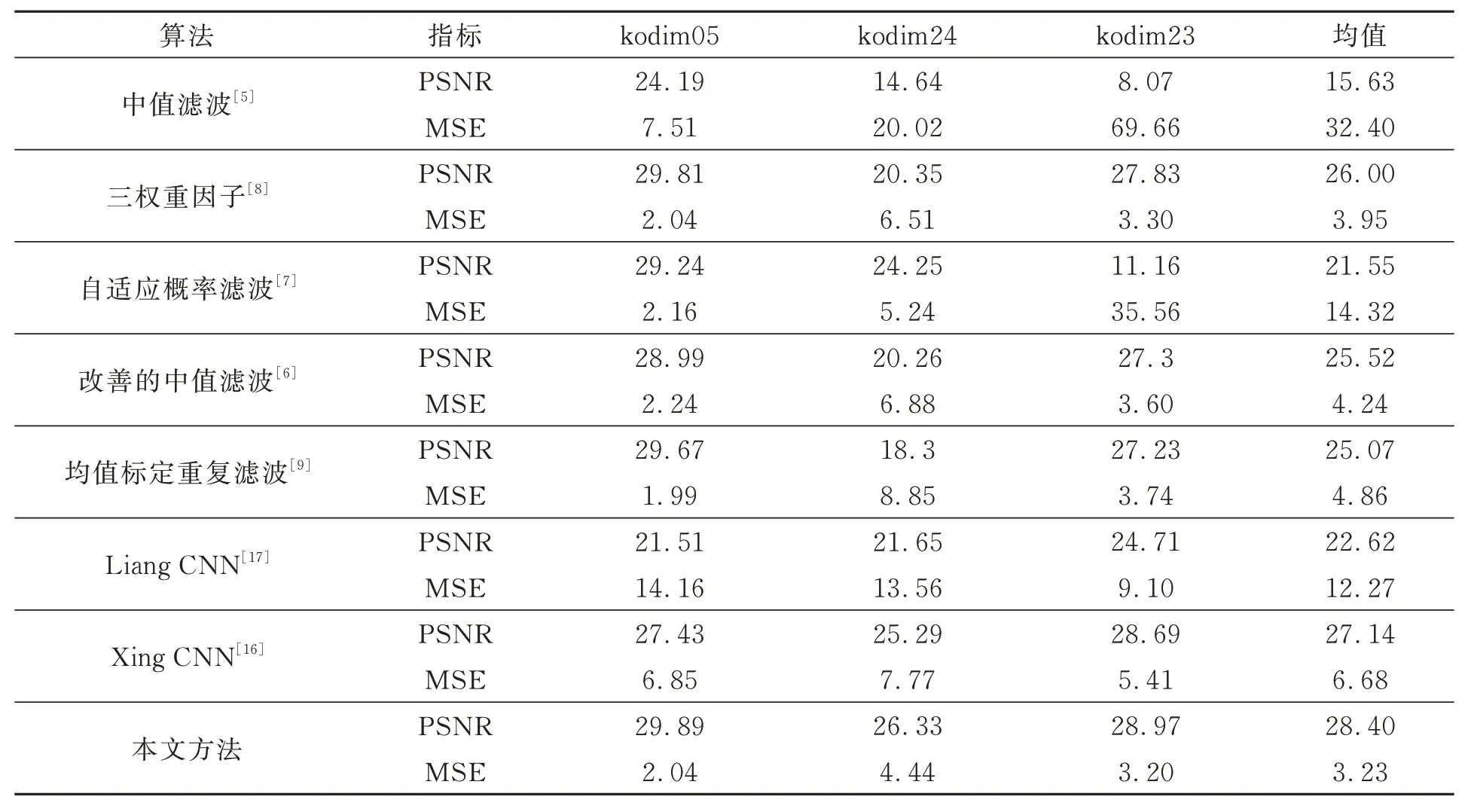
表3 各种方法的去噪性能对比Tab.3 Comparison of denoising performance of various methods
5.4.2 BSD300 数据集上的椒盐去噪性能测试为了更加深入地验证所提去噪方法的鲁棒性,本文对BSD300 数据集的300 张图片添加密度为0.01~0.9 之间随机密度的椒盐噪声,并对比不同方法所得的PSNR 和MSE 的平均值。从表4 可以看出,本文方法的PSNR 最高,MSE 最低,说明本文方法的去噪性能优于传统方法。相比于基于像素灰阶去噪方法即三权重因子方法,本文提出方法的PSNR 提升了2.53%,MSE 降低了6.76%。相比于传统CNN 去噪方法即Xing CNN,本文提出方法的PSNR 提升了8.96%,MSE 降低了45.24%。
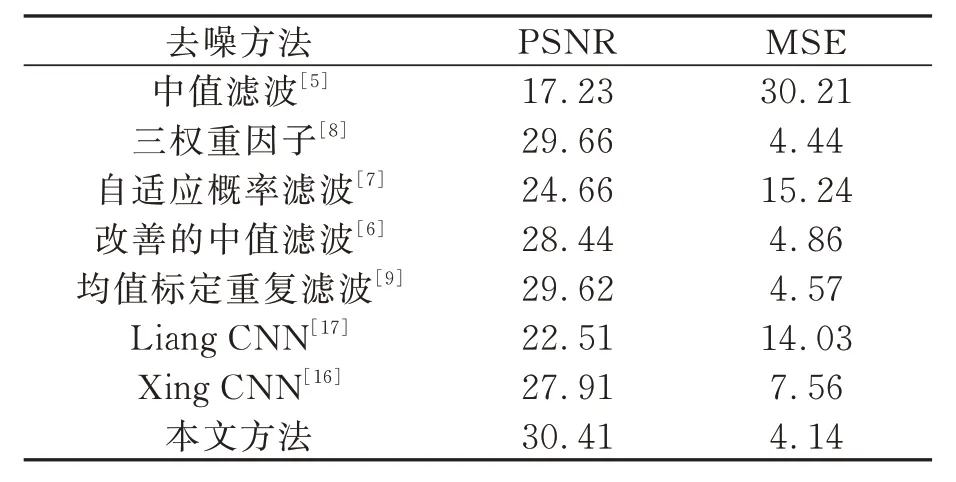
表4 BSD300 数据集上的去噪性能对比Tab.4 Comparison of denoising performance on BSD300 dataset
本文从噪点标记和噪声去除两方面改善去噪性能,在噪点标记步骤采用轻量级CNN 实现了极高精度的噪点标记,使得系统能够精准地鉴别噪声点和正常点。接着,在噪声去除步骤以上述精准噪点标记为基础,对于正常点不做处理。对于噪点,搜索在空间上与该噪点最为邻近的正常点作为代替点。表1的结果说明CNN 标记提升了噪点标记精度,表2 的结果说明最近邻搜索机制提升了峰值信噪比并降低了信息损失。从表4 可以看出,结合CNN 噪点标记和最近邻搜索机制的椒盐去噪方法实现了椒盐去噪性能的提升。
5.5 网络复杂度对比
Liang CNN 中存在多达32 个残差层和中值滤波层,使得运算复杂度和参数量极大。Xing CNN 中存在17 个常规卷积层,运算复杂度和参数及仍然很大。相比于传统的椒盐去噪卷积神经网络,本文减小了网络深度,并且在中间层采用深度可分离卷积代替常规卷积,这两个因素使得网络复杂度大幅降低。业界用MFLOPS[20](每秒兆次浮点型运算的数量)来评估卷积神经网络的运算复杂度。如表5 所示,本文所提出的网络模型的运算复杂度比Xing CNN 降低了15 倍。此外,该网络的参数数量和.h5 文件的大小都在传统网络的基础上得到数量级的降低。
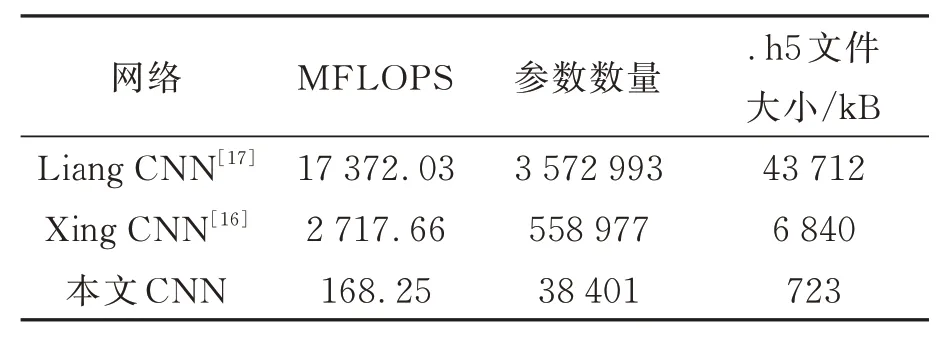
表5 网络复杂度对比Tab. 5 Comparison of network complexity
6 结论
本文提出的椒盐去噪方法充分利用了卷积神经网络的智能识别优势和相邻像素灰阶接近的性质,达到了超越传统方法的去噪性能。该方法不同于传统基于像素灰阶的去噪方法,通过轻量级卷积神经网络训练了一个高质量噪声掩模生成器,实现了精确的噪点标定。此外,该方法不同于现有的卷积神经网络去噪方法对全体像素进行卷积处理,而是将原图像中的正常点直接输出,将其中的噪点进行针对性的处理,从而减少了信息损失。在处理这些噪点的过程中,根据最近邻搜索机制寻找到与噪点距离最近的正常点。实验结果表明,神经网络的复杂度得到数量级的降低,噪点标定的误判率比传统最佳方法降低了83.65%。在去噪方面,该方法的PSNR 和MSE 均优于传统的像素灰阶方法和CNN 方法。本文提出的方法深化了轻量级卷积神经网络在椒盐去噪领域的应用,改善了去噪性能。
