基于CE-YOLOX 的导盲系统障碍物检测方法
2023-09-14张荣芬刘宇红程娜娜刘昕斐
刘 源,张荣芬,刘宇红,程娜娜,刘昕斐,杨 双
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
1 引言
世界卫生组织WHO 世界视力报告资料显示,全球范围内约有22 亿人患有视力损伤和盲症,中国盲人数量位列世界第一[1-2]。出行是盲人生活的一个难题,盲人出行的辅助工具主要有盲仗、导盲犬以及盲道。但盲杖的探测范围有限、速度慢;导盲犬训练周期长、数量少且有些场合对于犬类有出入限制;现实中盲道更是存在不连贯、有障碍物、触感圆点被磨平以及砖块受损等诸多问题[3-4]。传统的盲人辅助手段实际上都不能满足当前盲人的实际出行需求,但随着深度学习的快速发展,基于计算机视觉的目标障碍物检测方法带来了新的机遇和发展方向。
自2012年Alex Krizhevsky等[5]提出了AlexNet模型,卷积神经网络(CNN)开始迅猛发展并在计算机视觉领域广泛应用[6],对目标物进行检测的算法逐一被提出。2014 年,Ross Girshick 等提出R-CNN,首次利用CNN 进行目标检测。2015 年,Ross Girshick 等人在提出fast RCNN 之后又与Kaiming He 团队提出faster RCNN,之后Mask R-CNN 等一些网络也相继被提出[7-10]。这些基于区域提名的检测网络能达到很好的准确度,但是计算量较大,若应用于盲人出行时,不能满足实时监测的要求。
2016 年YOLOv1 检测算法被提出,同年SSD检测算法被相继提出以及2018 年Tsung-Yi Lin 的RetinaNet 检测算法的发表,YOLO 系列以及SSD系列等一些单目标实时检测算法得以发展[11-13],并广泛应用于不同场景下的实时检测任务中。户外的目标检测任务常常伴随着光照强度的变化、采集图像的失真等问题使得目标检测的精度不高。2019 年,马永杰等[14]基于原始的YOLOv2 模型和嵌入式系统实现了车辆自动跟踪、车流量的实时检测任务,由于未考虑光照原因对户外检测任务精度的影响,在车辆自动跟踪、车流量的实时检测任务上所取得的检测精度并不理想。光学重建图像、应用于深度学习图像处理的光学计量等方法有效地减少了由于图像失真曝光或噪点等光学因素造成的检测精度的丢失[15-17]。随着关注像素重要特征的注意力机制开始应用于神经网络,注意力机制为单目标检测算法在不同应用背景下的障碍物检测的准确率带来了巨大提升。2020 年,李文涛[18]改进了YOLOv3-tiny算法,融合浅层特征并使用SE-Net[19]通道注意力机制和CBAM[20]空间注意力机制作为混合注意力模块,实现了农机田间作业时行人和农机障碍物的改进检测模型,使得农机障碍物的检测准确率得到了巨大提升。2021 年,刘力等也提出一种基于YOLOv4 的铁道侵限障碍物检测方法,在锚框选择上对K-means 算法聚类中心的选取方法进行改进并引入了注意力机制,使得检测速度和精度都有所提升[21]。2022 年,王海军[22]基于YOLOv5 算法对铁路的轨道障碍物进行检测。虽然引入注意力机制为算法在识别目标的准确度带来了一定程度的提升,然而上述方法都没有很好地利用通道信息以及网络主干提取的各个尺度的语义信息,且预测框位置回归没有很贴近检测目标,预测框的回归精度和速度都有待提升。
针对上述问题,本文出于对盲人出行中需要实时且精确地检测各种可能会造成阻碍的目标类别的考虑,采用YOLOX[23]作为本文的基础模型进行算法改进,主要贡献在于:
(1)将原特征融合网络改进为CE-PAFPN,以亚像素跳变融合模块(Sub-pixel Skip Fusion,SSF)和亚像素上下文增强模块(Sub-pixel Context Enhancement,SCE)来充分利用通道信息和不同尺度的语义信息,通道注意力引导模块(Illustration of Channel Attention Guided Module,CAG)来减少混叠效应,有效地提升了的检测模型的精度。
(2)在预测网络之前引入全局注意力机制GAM,减少信息弥散和无用信息的干扰,并放大全局交互表示来提高模型性能,使网络模型更加聚焦在障碍物的检测上。
(3)将原有的位置回归损失函数替换为SIOU-LOSS,解决了预测框与真实框之间方向不匹配的问题,也考虑到了预测框和真实框距离、形状和交并比(Intersection-over-Union,IOU),对目标的定位更加精准,速度更快。
2 YOLOX 网络
YOLOX 网络结构由Input、Backbone、Neck、Prediction 4 个部分组成,如图1 所示。
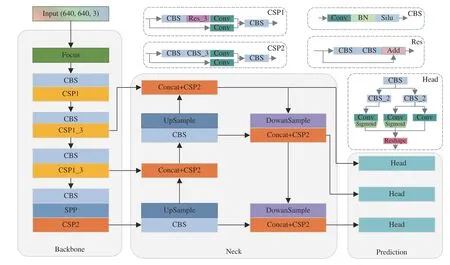
图1 YOLOX 网络结构图Fig.1 YOLOX network structure
Input 输入端采用Mocsicp 和Mixup 数据增强,丰富了检测图片的背景以及目标个数,对小目标的检测效果有所提升。Backbon 主要采用了Focus模块、残差组件以及跨阶段局部融合网络CSPNet[24]。Focus 采用切片重组操作把高分辨率的图片拆分成多个低分辨率的图片,有效减少了下采样带来的信息损失。残差组件由1×1卷积和3×3 卷积组成主干与不做任何处理的残差边构成,使模型更易优化,通过增加网络的深度也提高了模型的准确率。Neck 部分采用FPN 结构和PAN 结构构成的路径聚合网络PANet[25],自上而下将高层的特征信息与不同层的CSP 模块输出的特征进行融合,再通过至下而上的路径聚合结构聚合浅层特征,从而充分融合了不同层的图像特征。Prediction 预测部分采用了解耦头,由一个公共卷积、两个分支的额外卷积和3 个单独任务(Reg、Obj、Cls)的卷积构成,将3 个预测结果进行堆叠后进行解码操作,通过无锚点的方式减少预测结果,完成初步的筛选,再利用SimOTA 算法对预测结果进行精细化的筛选,得到最终的预测结果。
3 YOLOX 的算法改进策略
基于YOLOX 算法,本文提出了融合多尺度的注意力加权检测算法CE-YOLOX。较原模型主要改进部分为特征融合网络Neck,采用CE-FPN[26]的融合思想,以亚像素跳变融合模块SSF 和亚像素上下文增强模块SEC 来充分利用通道信息,充分考虑各个尺度的特征进行融合,并采取轻量的通道注意力引导模块CAG 减轻多尺度融合带来的混叠效应,引入全局注意力机制GAM 来聚焦有效信息。预测部份Prediction 采用SIOU-LOSS来加快边框回归的精度和速度。总体结构如图2所示。
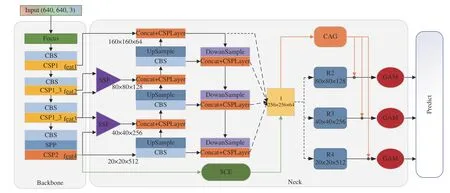
图2 CE-YOLOX 网络结构图Fig.2 Structure of CE-YOLOX network
3.1 改进的特征融合网络CE-PAFPN
传统的特征融合网络大多存在通道缩减的内在缺陷,这导致语义信息的丢失,且各尺度融合的特征图可能会导致严重的混叠效应。2021 年,华中科技大学提出了一种通道增强的特征金字塔CE-FPN。CE-FPN 受亚像素卷积的启发,提出了SSF 和SCE 两种新的通道增强方法,扩展了亚像素卷积固有的上采样功能,将丰富的通道信息集成到模块I 中,以轻量级的通道注意引导模块(CAG)减少各个尺度融合产生的混叠效应混淆定位和检测目标。
SSF 模块主要将低分辨率的特征采用亚像素卷积作为上采样的方式与临近的高分辨率特征进行通道融合,主干提取出的后3 个特征具有丰富的通道信息,SSF 模块将临近的特征图两两连接,有效利用了高层特征丰富的通道信息来增加特征融合网络的表征能力。SSF 结构如图3所示。
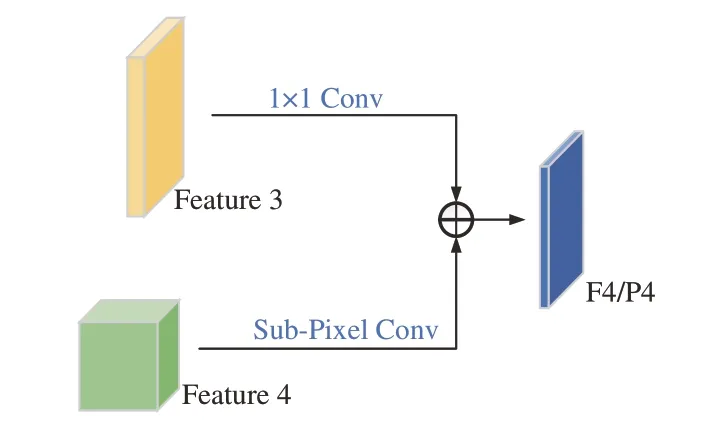
图3 SSF 模块Fig.3 Sub-pixel skip fusion (SSF) module
PAFPN 虽然融合了不同尺度的特征信息,但高级语义特征没有很好地作用到更大的感受野。为了更好地解决高分辨率的特征图只具有单一的上下文信息且需要更大的感受野获取更多语义信息的问题,本文采用集成的特征图I 的框架,并且采用SCE 模块利用feature4 丰富的通道信息。SCE 的核心思想是融合大范围的局部信息和全局的上下文信息来生成更具有辨识力的特征,假设本文输入的特征为2w×2h×8C,输出集成特征图I 为4w×4h×C,本文模型C设定为64。SCE 模块如图4 所示。3 条路径的作用分别为提取局部的特征信息、为更大的感受野获取丰富的上下文信息以及获取全局上下文信息,最后将3个特征映射聚合为集成映射I。
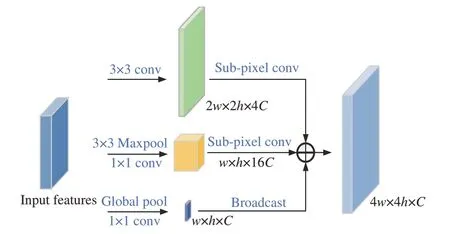
图4 SCE 模块Fig.4 Illustration of sub-pixel context enhancement (SCE)
对于特征融合网络的改进,SSF 和SCE 模块融合了更多的跨尺度的特征映射,因此混叠效应较原模型更为严重,这会影响模型的定位和识别任务。为了减轻锯齿效应产生的负面影响,加入了受CBAM 启发的通道注意力引导模块(CAG),如图5 所示。首先采用全局平均池化和全局最大池化来聚合两个不同空间的上下文信息,分别通过全连接层后进行元素求和,最后通过sigmoid函数对输出特征向量进行合并。该过程可用公式(1)表述为:
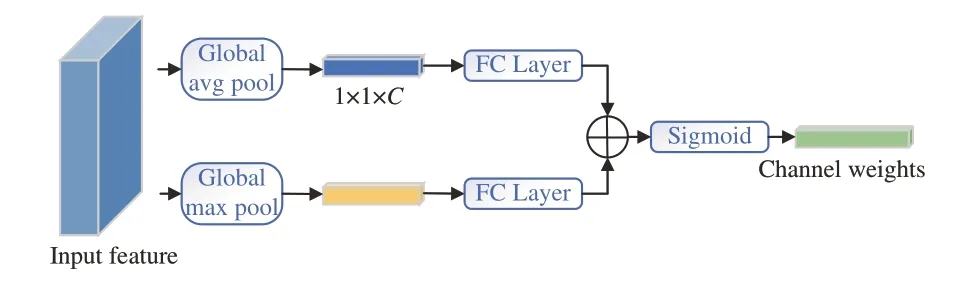
图5 通道注意力引导模块示意图Fig.5 Illustration of channel attention guided module(CAG)
3.2 GAM 全局注意力机制
注意力机制能更加关注特征图中的有效信息,抑制无效信息,同时也能减轻在特征融合网络中由于跨尺度特征融合产生的混叠效应,有效地提升网络特征提取的性能。各种注意力机制在卷积神经网络中的应用为计算机视觉任务的性能带来了显著提高。Woo等人提出的CBAM 注意力机制结合空间注意力机制和通道注意力机制相较于SE-Net 有效地解决了抑制特征图中不重要的信息效率低的问题,但也忽略了通道与空间的相互作用,从而丢失了跨维信息。Misra 等[27]人在2021 年提出的三元注意模块(TAM)通过对每一对三维空间(通道、空间宽度和空间高度)之间的注意力来提升效率,但每次只应用在其中的2 个维度,并不是3 个维度。为了减少信息弥散和放大跨维度的交互作用捕捉所有3 个维度的重要特征,2021年,YIchao Liu 等人在CBAM 的基础上进行改进,提出全局注意力机制(GAM)。
GAM 采用CBAM 中的顺序通道-空间注意力机制,并对子模块进行重新设计。GAM 的基本结构如图6 所示。
通道注意力子模块如图7 所示,使用三维排列在3 个维度上保留信息,再用双层MLP(多层感知机MLP 是一种编码-解码结构,与BAM 相同,其压缩比为r)放大跨维通道-空间的依赖性。

图7 通道注意力子模块Fig.7 Channel attention submodule
空间注意力子模块如图8 所示。为了关注空间信息,使用两个卷积层进行空间信息的融合,还从通道注意力子模块中使用了与BAM 相同的缩减比r。同时,由于最大池化操作会减少信息的使用,产生消极的影响,在该子模块中去除了池化操作以进一步保留特性映射。
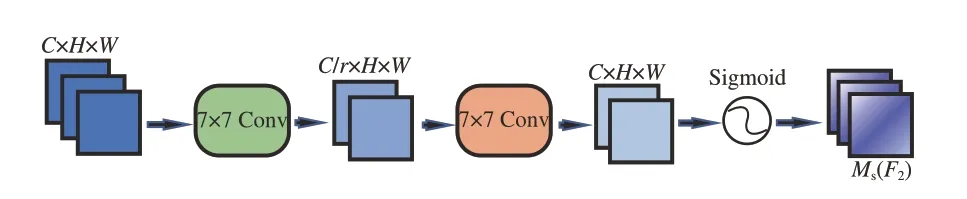
图8 空间注意力子模块Fig.8 Spatial attention submodule
3.3 损失函数的改进
3.3.1 目标框回归损失函数
传统的目标检测损失函数依赖于边框回归度量的聚合,如预测框与真实框中心点之间的距离、重叠面积和长宽比(GIOU、CIOU、DIOU等)[28-29],却没有一种方法考虑到真实框与预测框之间的方向不匹配问题,这会导致模型在收敛过程中的速度较慢。本文选用SIOU-LOSS[30]替换原模型中的IOU-LOSS 来计算位置回归损失函数。SIOU 具体由4 个部分组成,分别是角度损失(Angle cost)、距离损失(Distance cost)、形状损失(Shape cost)和IoU 损失。
角度损失的公式如式(2)所示:
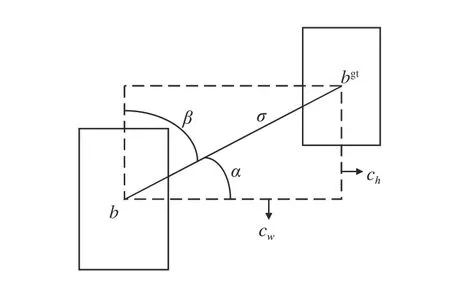
图9 角度损失对损失函数的贡献Fig.9 Scheme for calculation of angle cost contribution to the loss function
考虑角度损失,重新定义距离损失,公式如式(3)所示:
就全国范围而言,较之人均转移支付额,人均GDP对中国教育水平提高的贡献率要更高,为2.7%;而人均转移支付额对中国教育水平提高的贡献率为0.96%,仅为人均GDP贡献率的35.6%。可见较之财政转移支付资金的支持,地方经济实力的提升更能有效地推动中国地区间教育水平的趋同。
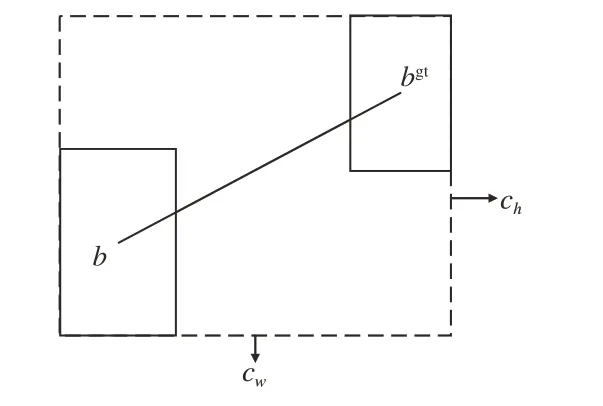
图10 真实框与预测框之间距离的计算方案Fig.10 Scheme for calculation of the distance between the ground truth bounding box and the prediction of it
形状损失定义为:
3.3.2 分类置信度损失函数
VarifocalLOSS[31]新型焦变损失是基于交叉熵损失函数进行的改进,用加权方法解决类别不平衡的问题,但对于正负样本处理策略是不对等的。定义为:
其中:α是用来平衡正负样本的权重,pγ为调背景类的调制因子,p为预测的分类得分。对于正样本,q是预测框与真实框之间的IOU;对于负样本,q为0。对负样本进行衰减,对正样本q进行加权,可以使训练更聚焦于正样本,避免大量的负样本对训练时损失函数的影响。
4 实验与结果分析
4.1 数据集
对于本文在盲人出行时常见的可能会对其造成阻碍的目标数据集的制作,从路面上凸出(如fire hydrant、road-cone 等)、路面凹陷(如puddle、pothole 等)以及步行中突然出现的物体(如cat、dog 等)这3 种情况考虑,收集VOC、ImageNet 等公共数据集以及在不同光照、天气及角度采集拍摄的图片。拍摄图片使用labeling 图形图像注释工具进行数据的标注。本实验数据集将检测障碍物分为20 类,共计15 805 张图片。表1 所示为各类别的具体数量。训练集和验证集按9∶1 的比例随机进行划分。
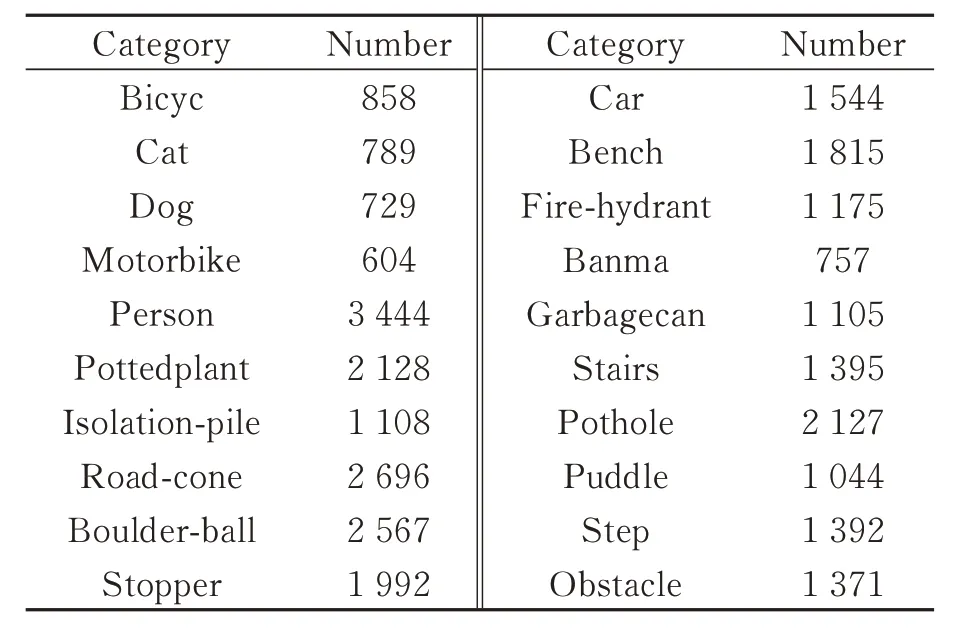
表1 数据集中各类别检测物的数量Tab.1 Number of each type of test in the dataset
4.2 实验环境及训练过程
如表2 所示,本文实验均在服务器Ubuntu 16.04操作系统下运行,计算机处理器型号为AMD 3900X,显卡型号为NVIDIA GTX 3090,内存为32G。采用Pytorch 1.6.1 框架,所使用的编程语言为Python 3.6,加速环境为CUDA 11.4。
表2 实验条件Tab.2 Experimental conditions
本文采用迁移学习的思想,前50 轮冻结模型主干,加快训练速度,迭代批次为64;50 轮之后解冻训练,迭代批次为32。共训练113 轮。具体训练参数如表3 所示。
表3 实验参数设置Tab.3 Experimental parameter setting
本文采用准确率(Precision)和召回率(Recall)计算所有障碍物类别的平均精度mAP(mean Average Precision)来评估模型的整体性能,用平均精度AP(Average Precision)对每一类障碍物的检测结果进行评估。P、R、AP 和mAP 计算公式如式(7)~(10)所示:
其中:n表示为检测目标的类别数,TP 表示预测正确的正样本数,FN 为预测错误的正样本数,FP表示为预测错误的正样本数,TP+FN 为全部正样本数量,TP+FP 为全部被分为正样本的数量。
4.3 实验结果分析与分析
4.3.1 不同模块分析效果
为了检验本文改进算法的检测性能,以YOLOX原模型为参照,通过多个模块组合的方式进行5 组实验,验证各个模块的有效性,如表4 所示。
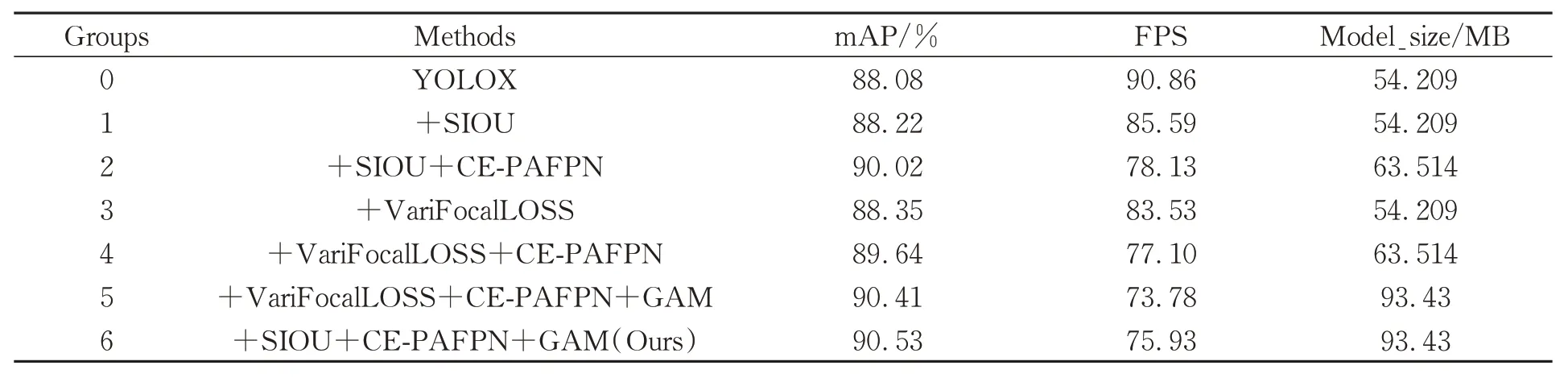
表4 消融实验结果Tab.4 Results of ablation experiment
在第一组实验中,将原模型的损失函数更改为SIOU-LOSS 之后,mAP 从88.08%提升至88.22%。在第二组实验中,在第一组实验的基础上将特征增强网络PAFPN 改进为CE-PAFPN后,特征融合网络在减少丢失通道信息的同时充分利用了主干网络产生的4 个尺度的特征进行特征融合,增加了模型检测的准确性,降低了漏检率,使检测模型整体的mAP 从88.22%提升至90.02%。在第三组实验中,尝试将原模型的分类置信度损失替换为VariFocalLOSS,与第一组实验中单独替换为SIOU 相比,整体mAP 提高了0.13%,但VariFocalLOSS 在加入CE-PAFPN、GAM 后的第四、五组实验中并没有比SIOU 加入CE-PAFPN、GAM 后的第二、六组实验表现更好。第六组实验在第二组实验的基础上加入GAM注意力机制后,mAP 从90.02%提升至90.53%,增加了0.51%,构成本文模型。原模型与本文模型的各类目标精度如图11 所示。比较各个类别检测的精度,CE-YOLOX 的检测效果都有不同程度的提升。在YOLOX 模型上表现不好的类别,如bench、pottedplant 的精度也分别提升了0.6%及0.7%。
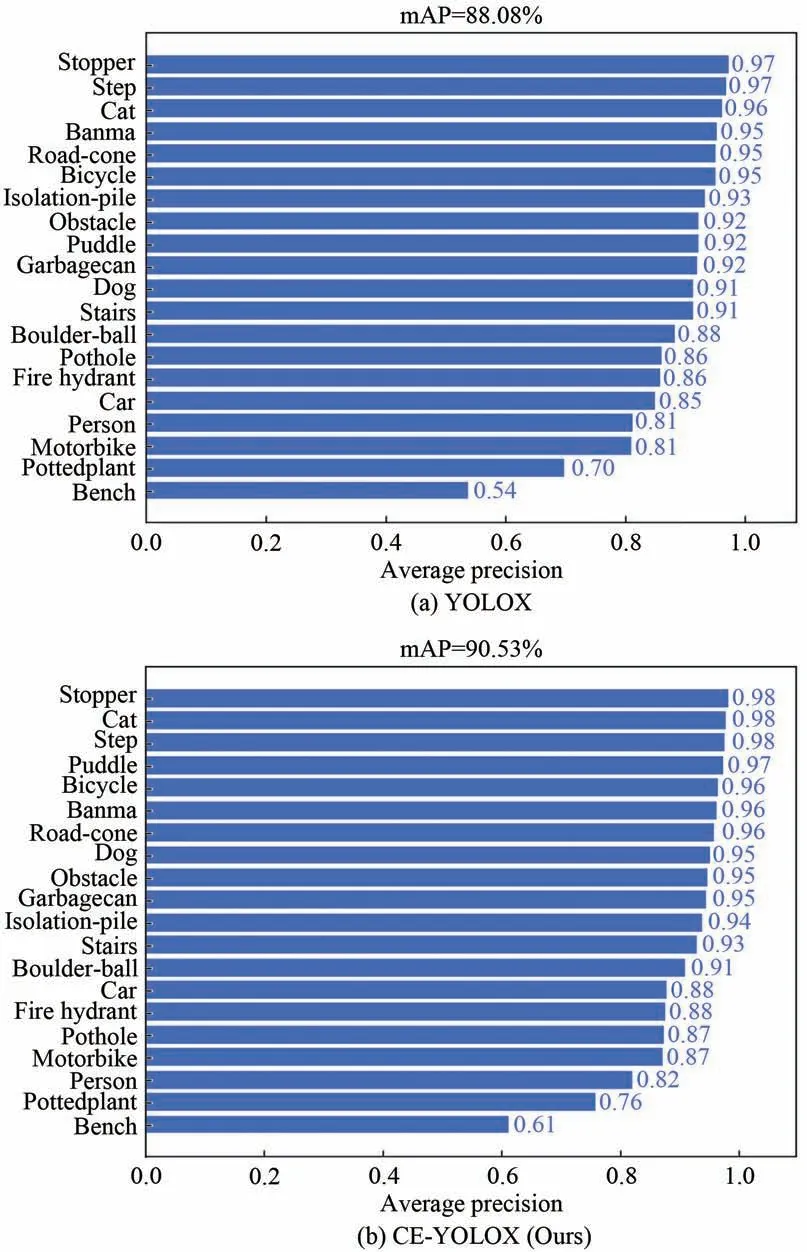
图11 YOLOX 与CE-YOLOX 测试结果对比图Fig.11 Comparison of YOLOX and CE-YOLOX test results
注意力机制在网络中添加的位置不同,模型的检测效果也会有差异。在第二组实验的基础上,进行了两组对比实验,最终确定注意力机制在模型中的添加位置,组成本文最后的网络结构。
由此可见,由于特征增强网络融合了多尺度信息,导致网络产生了混叠效应,GAM 注意力机制添加在特征增强网络之前并不合适,对网络的整体检测效果提升有限。GAM 注意力机制添加在特征增强网络之后就很好地缓解了在特征增强网络部分产生的混叠效应问题。
4.3.2 不同模型效果对比
为了验证本文改进算法的有效性,本文将RetineNet、Efficiented、SSD、YOLOv5 和本文基础算法YOLOX 在同一数据集下进行对比实验,结果如表5 所示。
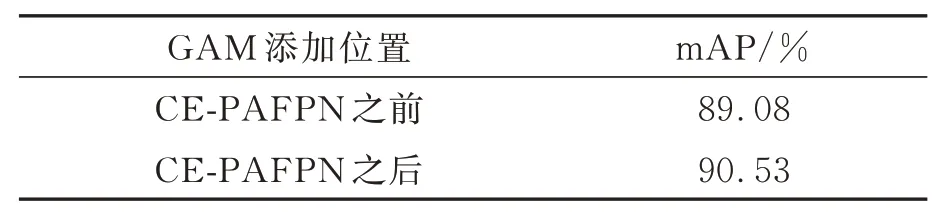
表5 不同位置GAM 注意力机制效果对比Tab.5 Comparison of the effects of different position GAM
由表6可知,对于盲人出行道路障碍物检测的整体mAP,本文模型优于RetineNet、Efficiented、SSD、YOLOv5、YOLOX。在单张图片的检测速度上,YOLOX 原型最快。虽然本文模型单张图片的检测速度低于原模型,但依然满足实时目标检测的需求,达到了模型精度与速度的平衡。
图12 为本文所提改进模型及YOLOX 和YOLOv5 三种检测模型对几类在出行过程中会对盲人造成阻碍的障碍物的检测效果。从图12 可以看出,所提的改进模型CE-YOLOX 的预测框与真实框的重合度更高,对于目标的定位更准确,对检测目标的准确率更高。

图12 3 种模型检测对比图Fig.12 Comparison of three model checks
5 系统设计与平台移植验证
为了验证改进的检测算法CE-YOLOX 在实际工程中的应用,将其在服务器上训练完成后部署在边缘计算平台进行实验。实验所设计的主从式的视障人群出行监测系统包括高性能NVIDIA Xavier NX边缘计算板(导盲系统)、基于LD3320的语音交互模块、蓝牙模块、双目摄像头、基于香橙派Range Pi 实现的定点导肮等工具、Ubuntu18.04操作系统、OpenCV3.4、TensorFlow1.15 等工具与框架。图13 为导盲系统流程框图。
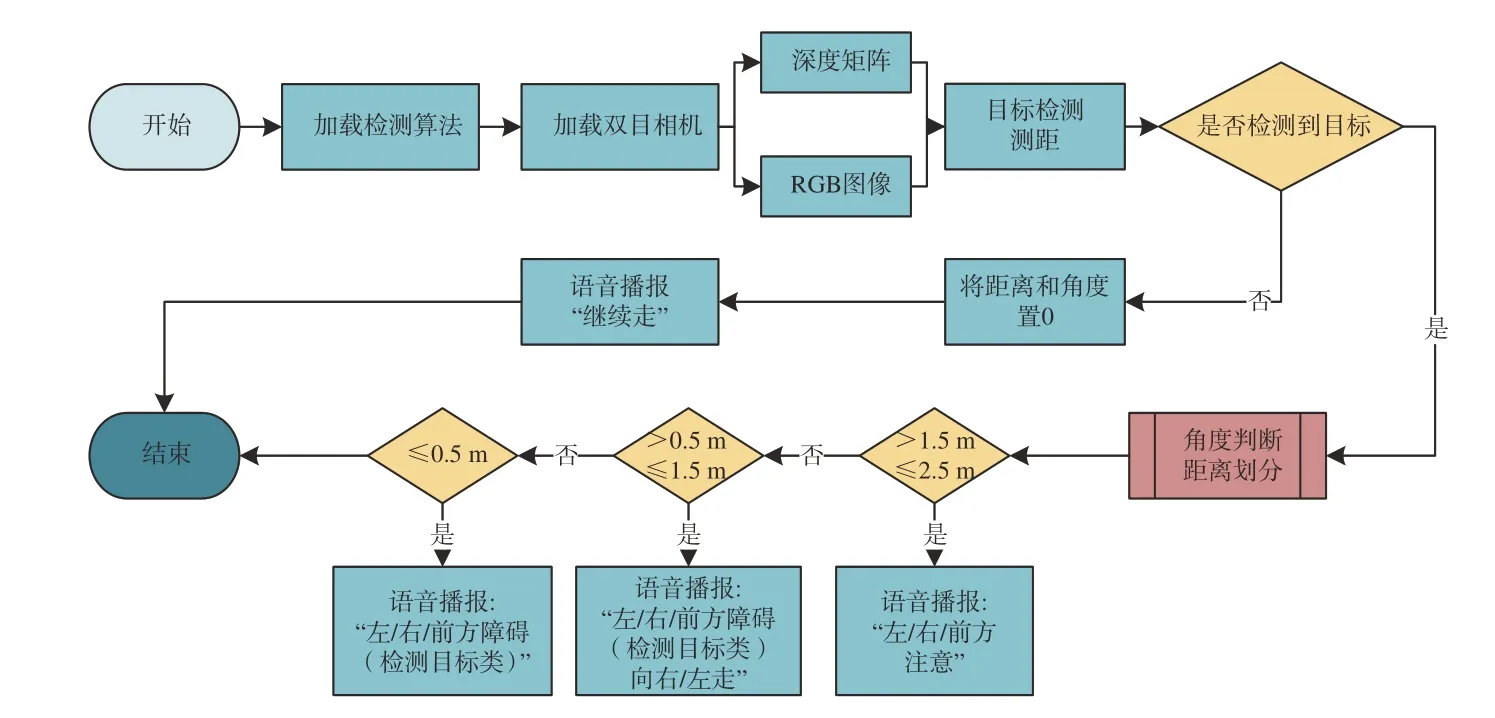
图13 导盲系统流程框图Fig.13 Flow diagram of guide system
将CE-YOLOX 以及YOLOv5、YOLOX 移植到导盲系统实物平台中进行对比实验,其检测效果如表7 所示。在NVIDIA Xavier NX 边缘计算板上,各算法检测的准确度与表5 相同。YO-LOv5、YOLOX 的检测速度虽略高于本文所提出的CE-YOLOX,但CE-YOLOX 对目标识别的准确度要优于YOLOv5、YOLOX,同时也满足了盲人出行检测所要求的实时性,在实际应用中更符合对盲人出行可能造成障碍的物体目标的检测实时性和准确度的要求。
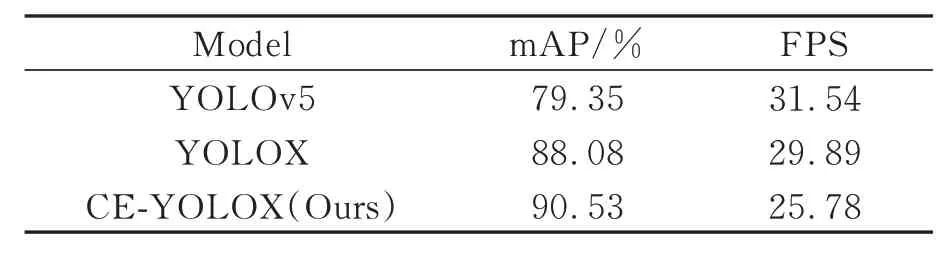
表7 3 种算法在Nvidia Xavir NX 上的检测效果对比Tab.7 Comparison of detection effects of the three algorithms on Nvidia Xavir NX
6 结论
为了解决盲人出行难的问题,本文提出了一种基于YOLOX 的改进模型CE-YOLOX 用来检测对盲人出行造成阻碍的目标。通过将特征融合网络PAFPN 改进为CE-PAFPN,以亚像素跳变融合模块SSF 和亚像素上下文增强模块SCE 来充分利用通道信息和不同尺度的语义信息,通道注意力引导模块CAG 来减少混叠效应,有效提升了检测模型的精度。通过加入GAM 全局注意力机制,使模型在训练过程中更关注有效信息,抑制无效信息,同时也有效缓解了多尺度特征融合产生的混叠效应。采用SIOU 损失函数,SIOU 引入的角度损失解决了预测框与真实框之间方向不匹配的问题,也考虑到了预测框和真实框距离、形状和IOU,使得对目标的定位更加精准,也加快了训练过程中模型的收敛。实验结果表明,本文算法在速度上满足了实时检测的需求,检测目标的准确率也优于现有的YOLOv5、YOLOX 等其他算法,mAP 达到了90.53%,单张检测速度达到了75.93 FPS,部署在边缘检测设备上的NVIDIA Xavier NX 也满足盲人出行实时检测的要求。后续工作需要考虑模型在检测精度不下降太多的情况下对模型进行轻量化的改进,从而提升模型的检测速度,使模型部署在边缘计算设备上拥有更好的实时性,使盲人日常出行能够快速准确识别障碍物。
