结合协同训练的多视图加密恶意流量检测方法
2023-09-07霍跃华吴文昊赵法起
霍跃华,吴文昊,赵法起,王 强
(1.中国矿业大学(北京) 机电与信息工程学院,北京 100083;2.中国矿业大学(北京) 网络与信息中心,北京 100083;3.中国科学院 信息工程研究所,北京 100084;4.中国科学院大学 网络空间安全学院,北京 100049)
1 引 言
随着加密技术发展[1-2],网络加密流量呈现爆发式增长,各大网站和软件在流量传输中采用加密技术保护通信。Google透明度报告[3]指出,所有Google产品和服务中的加密流量占比已达95%;Chrome平台中加密网页占比从2016年的约50%增长到2022年的约99%。与此同时,越来越多的恶意流量也采用加密技术逃避检测,对网络安全构成严峻挑战。恶意流量主要由恶意软件产生[4],GALLAGHER在2021年5月的报告指出,约46%的恶意软件在Internet通信中采用传输层安全协议(Transport Layer Security,TLS)进行加密[5],而在2020年这个比例还是23%,同比增长了1倍。因此加密恶意流量检测研究具有重要意义。
现阶段,针对加密恶意流量检测主要有解密技术和非解密技术两种。解密技术开销大、安全性低、应用前景小。非解密技术主要包括JA3指纹技术、证书技术及机器学习(Machine Learning,ML)[6-8]技术。基于JA3技术和证书技术的加密恶意流量检测方法只采取少数特征进行检测,容易被恶意软件规避;基于机器学习的加密恶意流量检测方法依靠大量标注样本和多个特征进行训练,现有文献表明能够取得较好的检测效果[9-10],但是严重依赖于标注样本数量和质量[11],因此现实环境中由标注代价高引起的标注样本缺乏问题制约着基于机器学习方法的应用。在加密流量具有较高的概念漂移,恶意软件家族更新迭代较快等问题限制传统检测方法应用的情况下,基于半监督学习的方法能在小规模标注样本的条件下挖掘隐藏在大量无标注样本内部潜在的规律,实现无标注样本的有效利用,减少对标注样本的依赖。因此研究基于半监督学习的TLS加密恶意流量检测方法具有重要价值。
针对现有基于机器学习的加密恶意流量检测方法对标注样本依赖度高的问题,文中提取TLS加密流量的流元数据特征和TLS证书特征,分别利用流元数据特征和TLS证书特征构建协同训练的两个视图,采用XGBoost分类器和随机森林(Random Forest,RF)分类器分别作为视图1和视图2的分类器,协同两个分类器构建基于半监督学习的多视图协同训练分类器(Multi-view Co-training Classifier,MCC)检测模型,通过随机抽取样本进行标注的方式得到小规模的标注样本,结合大量无标注样本实现高效的TLS加密恶意流量检测。
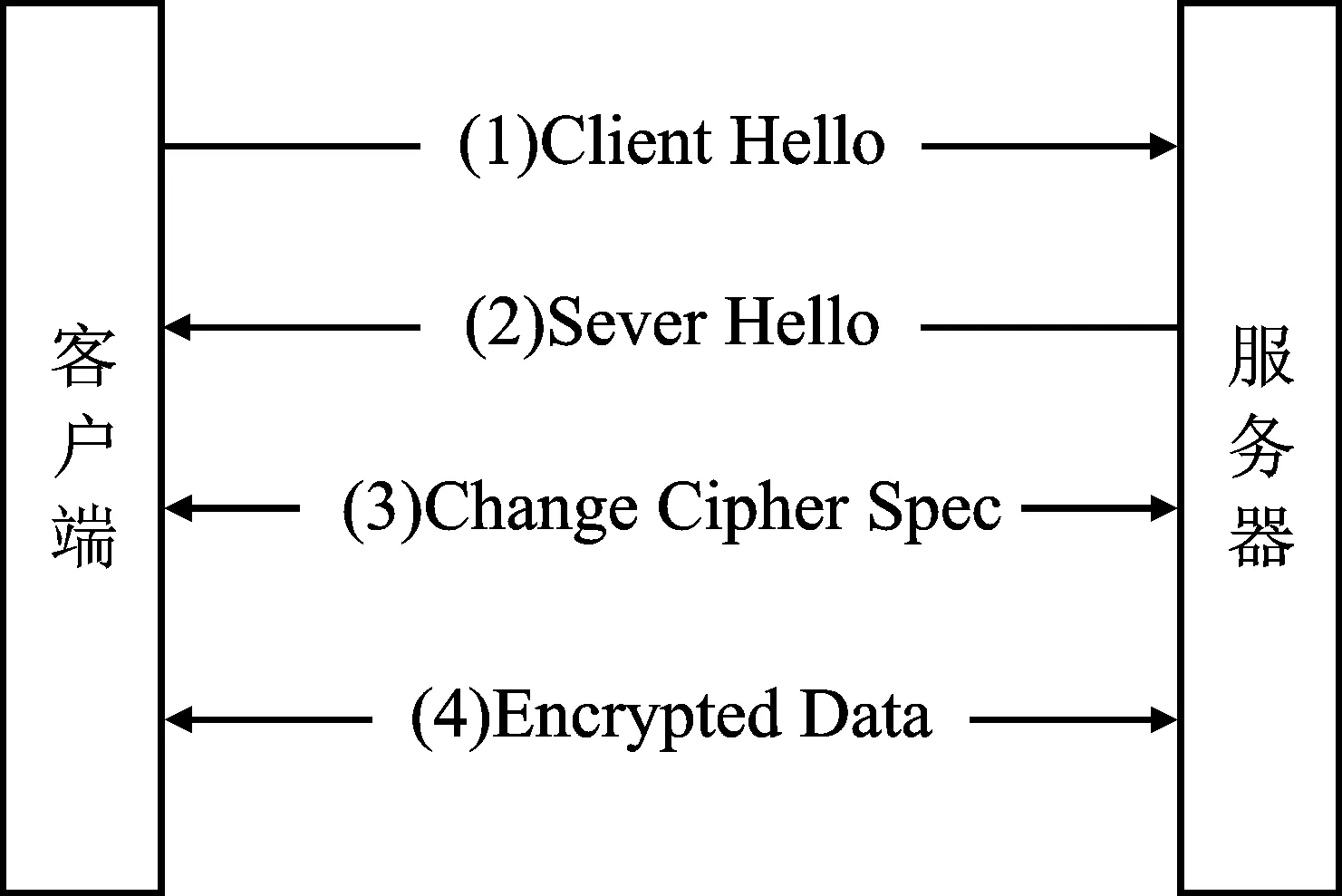
图1 TLS握手过程

图2 TLS加密恶意流量检测过程
2 相关工作
2.1 TLS握手过程和特征选择
TLS握手过程是客户端与服务端建立加密信道的过程,包含建立连接和交换验证信息两个部分。建立连接过程首先由客户端向服务端发送TLS版本、服务器名以及支持的拓展等;然后由服务端向客户端发送TLS证书链、密钥交换方法等。交换验证信息部分用于创建密钥算法和握手过程加密算法[12]。TLS握手过程如图1所示。邹洁等[13]采用C4.5决策树算法,通过选取加密流在网络中传输的流元数据特征实现了加密流量分类。TORROLEDO等[14]将TLS证书信息输入神经网络进行训练和检测,证明了证书信息的可用性。
2.2 特征选择
特征工程是针对特征属性值进行的处理,主要用于匹配模型输入要求和提升模型性能。YU等[15]对恶意软件进行的研究表明,特征工程能够有效提高分类模型检测性能。特征选择是特征工程的一部分,通过减少特征维度或数量的方式提高模型的性能。受HUO等[16]启发,人为选择的特征存在多重共线性,不能直接进行训练,需要通过特征工程避免特征共线性问题,进而提升检测模型性能。
2.3 基于半监督学习的加密恶意流量检测方法
半监督方法通过小规模标注样本和大量无标注样本进行训练,对标注样本需求量低,能够有效减少基于机器学习的加密恶意流量检测方法对标注样本的依赖性。
协同训练方法是半监督方法的一种,又称基于分歧的方法[17],能够综合考虑同一对象不同视图的特征,通过多次迭代减少不同视图分类器分类结果的不一致性,得到更优的训练模型参数来提升性能。当两个视图具有较强独立性时,采用协同训练方法能够有效利用无标注样本信息提升分类效果。卢宛芝等[18]提出了一种半监督协同训练模型,利用协同训练策略组合了原始字节流特征和网络流统计特征实现了恶意流量分类,但该方法采用同质的极端随机树分类器,对不同视图适配性差,并且没有针对加密流量,应用于加密流量检测会造成准确性下降。ABDELGAYED等[19]提出一种SSML(Semi-Supervised Machine Learning)模型,采用异质的决策树分类器和K近邻分类器进行协同,构造检测模型进行检测。ILIYASU等[20]提出一种DCGAN(Deep Convolutional Generative Adversarial Network)模型,利用DCGAN模型生成的样本以及无标注的样本提高在小规模标注样本下训练的分类器的性能。
3 模型及方法
3.1 数据集
网络中的信息是以流的形式传输的,网络流量数量庞大,特征多样,而且具有较高的概念漂移。因此对基于机器学习的方法而言,数据集的质量决定着模型在真实环境下的性能。半监督学习可以在小规模标注样本的条件下实现高效的检测效果。为了验证MCC检测模型的性能,文中使用CTU-13[21]数据集,该数据集包含单独运行13种恶意软件所产生并捕获的恶意流量和正常情况下捕获的良性流量,并以pcap流量包的形式进行存储。选择数据集中具有单一类别恶意软件的恶意流量包6个和良性流量包1个,并筛选出其中的TLS加密流量构成样本集,如表1所示。
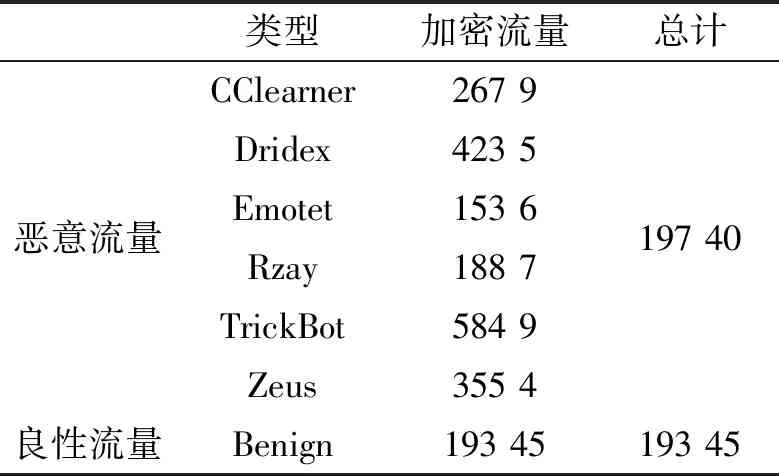
表1 CTU-13数据集 条
3.2 协同训练视图构建
将原始pcap流量包进行合并与清洗后,使用Zeek工具[22]进行特征提取,得到流特征、连接特征及TLS证书特征。流特征与连接特征同属流元数据特征[23],表征的是流的建立与传输过程,描述的是流的行为侧的交互特征,独立性较弱;TLS证书特征表征的是认证过程中握手行为和报头的属性,与流元数据特征间具有较强独立性。采用具有较强独立性的视图进行协同训练能够增强特征对加密流量的表示能力,从而辅助增强检测效果。同时,采用加密流量中独立性强的特征能够解决特征多重共线性问题,进而降低对检测模型的影响。
(1) 流元数据特征由流特征和连接特征组合而成,包含数据传输过程中的数据包大小、字节分布和上下文等80个统计特征,能够表示通信建立连接的过程和连接后的流量行为。
(2) TLS证书特征包含TLS握手过程和相关证书特征,文中选取了certificate issuer,certificate subject,cipher[24]。其中,certificate issuer表示证书签名的签发者,certificate subject表示证书的主体,cipher表示采用的加密算法套件。
3.3 视图构建
(1) 视图1。流元数据特征中特征的属性值为数值型,为消除数据量纲不同对分类结果造成的影响,对其进行标准化处理:
(1)
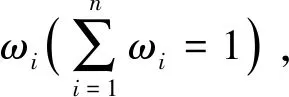
(2) 视图2。TLS证书特征中特征的属性值重复性比较高,直接编码容易造成维度灾难。因此采用词频-逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)编码[25]。TF-IDF编码是一种根据词频数进行编码的方法,认为词频越小的单词区分能力越大,该方法能够提取关键词,更好地处理重复性高的特征。此外,由于编码后的数据是原来数据的高维映射,维度的提升会造成计算资源的浪费。主成分分析(Principal Component Analysis,PCA)法[26]是一种无监督的降维方法,通过投影找出全新的相互正交的特征,快速实现对原特征的降维。因此,选择PCA法对编码后的特征进行降维,根据特征贡献率选择前58个主成分,进而构建视图2。
3.4 多视图分类器构建
视图1在构建过程中存在部分关键属性值缺失的问题。XGBoost分类器能够自动处理缺失数据,并能通过双向剪枝,降低模型过拟合风险。因此,选择XGBoost分类器作为视图1的分类器。
针对视图2,在TF-IDF编码和PCA降维的过程中会生成新的特征映射关系,但这种映射会导致原有信息缺失。由于随机森林分类器对缺失数据不敏感,且能够对模型的误差产生无偏估计。因此,选择随机森林分类器作为视图2的分类器。
3.5 MCC检测模型的算法思想
利用视图1和视图2独立性强、相关性低的特点,通过协同训练策略构建MCC检测模型对TLS加密恶意流量进行检测。MCC检测模型的算法思想如算法1所示。
算法1MCC检测模型算法思想。
输入:标注样本集L;无标注样本集U
输出:flag
① 从U中选择u个未标注的样本构成样本池U′
② 迭代k次:
使用L中第一视图训练分类器C1
使用L中第二视图训练分类器C2
C1从U′中标注p个正样本和n个负样本
C2从U′中标注p个正样本和n个负样本
添加2p+2n个标注样本至L
随机从U中抽2p+2n个样本到U′
③ 将待检测加密流量样本输入到模型中进行预测,得到每一个样本的标签值flag
④ 判断flag值,1表示恶意流量,0表示良性流量
其中,MCC检测模型工作过程为:先根据标注样本进行模型预训练,进一步根据预训练的模型对未标注样本进行预测,并输出每个未标注样本被预测为良性或恶意标签的概率;预测概率值越大的样本置信度越高。从协同分类器标注的样本中挑选出置信度高的2p+2n个样本进行标注,将已标注样本添加至L中,为保证样本池U′中样本量与初始样本量一致,从U中补充2p+2n个样本至样本池U′中,参与下一轮迭代。最后将测试集样本输入模型进行分类。笔者所提出的基于MCC检测模型的TLS加密恶意流量检测过程如图2所示。
4 实验验证
4.1 实验设置
4.1.1 实验环境
研究基于Python3.9搭建了实验环境,实验所使用的硬件设备为64位Windows 10操作系统,采用Inter© Xeno© Gold 5210 CPU @2.20 GHz 2.19 GHz 双处理器,内存32 GB。
4.1.2 评价指标
为了验证所提利用协同训练的多视图加密恶意流量检测方法的有效性,采用准确度(Acc),召回率(Rec)和误报率(FPR)3个指标对检测结果进行评估:
(2)
(3)
(4)
其中,TP表示恶意样本被正确识别为恶意样本的数量,TN表示良性样本被正确识别为良性样本的数量,FP表示恶意样本被错误识别为良性样本的数量,FN表示良性样本被错误识别为恶意样本的数量。
4.2 特征选择与结果分析
4.2.1 视图1和XGBoost分类器
选取了特征重要性值最大的前6个特征构成视图1,如表2所示。将视图1输入XGBoost分类器中,采用网格搜索法,确定分类器参数:树的最大深度为4,迭代次数为100。

表2 特征重要性最大的前6个特征
4.2.2 视图2和RF分类器
选取特征贡献率阈值为0.9[26],保留前58个主成分,构成视图2。并通过网格搜索法确定RF分类器参数:树的最大深度为9,森林中树的数量为30。
在保证恶意流量与良性流量样本数量比例一致的前提下,将样本集按照7∶3的比例划分为训练集与测试集。训练集用于训练模型,包括随机挑选训练集中小规模样本进行标注构成的标注样本集,训练集剩余样本构成的无标注样本集;测试集用于检验所检测算法的性能。
4.3 MCC检测模型实验与对比实验结果分析
4.3.1 与单视图模型的检测结果对比
为了探究MCC检测模型在小规模标注样本下的检测效果,在全标注条件下,针对单视图分别进行对比试验,每组实验重复10次,取其平均值如表3所示,其中,MCC/100指的是MCC检测模型在100个标注样本条件下的性能。

表3 与单视图模型对比的性能 %
在单视图条件下,XGBoost分类器在视图1下的分类平均准确率达到了99.90%,平均召回率达到了99.86%,平均误报率低于0.07%。RF分类器在视图2 下的分类平均准确率达到了98.70%,平均召回率达到了99.28%,平均误报率则低于1.9%。相比之下,MCC检测模型在100个标注样本情况下的平均准确率为99.17%,平均召回率为98.54%,平均误报率为0.04%。
由结果可知,MCC检测模型在平均准确率和平均召回率上基本达到全标注条件下的性能;在平均误报率上优于单视图模型所取得的效果。实验结果表明,基于MCC检测模型的TLS加密流量检测算法能够有效利用小规模标注样本实现全监督学习下的检测效果,能够有效对加密恶意流量进行识别,减少基于机器学习的检测方法对标注样本的依赖。
4.3.2 MCC检测模型检测结果分析
为了进一步探究所提的MCC检测模型在不同标注样本数量下的性能,并探寻样本标注代价与检测性能的平衡,文中在其他条件相同的情况下,在20~100的标注样本区间上设置了9组实验对标注代价与检测性能的平衡进行了检验。实验结果如表4所示。
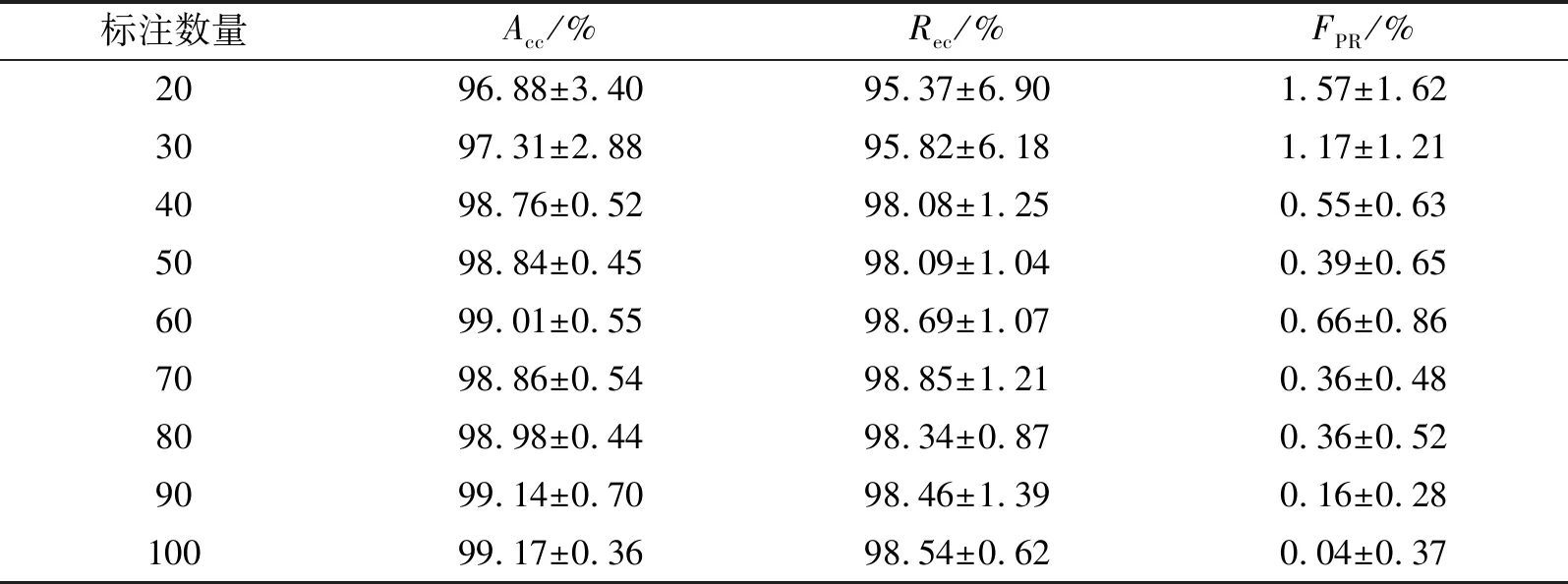
表4 不同标注样本下MCC检测模型性能
由表4可得,在仅有20个标注样本的条件下,MCC检测模型的平均准确率和平均召回率分别为96.88%和95.37%,平均误报率低于1.57%。而将标注样本的数量增加至100个后,MCC检测模型的平均准确率和平均召回率分别达到99.17%和98.54%,较20个标注样本的条件有2.29%和3.17%的提升,平均误报率降至0.04%。如图3和图4所示,随着标注样本数量的逐步增加,MCC检测模型的平均准确率和平均召回率呈上升趋势,平均误报率呈下降趋势。但是,在标注样本数量达到60个以后,随着标注样本数量的增加,MCC检测模型的性能没有明显的提升。该结果说明在一定标注样本数量的范围内,随着标注样本数量的增加,检测模型性能提升效果显著,但当标注样本达到一定数量时,再增加标注样本数量,对检测模型性能的提升效果不再显著。
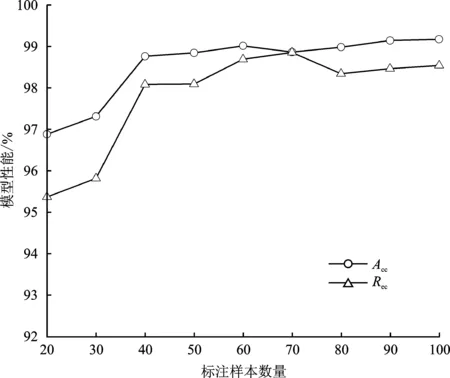
图3 MCC检测模型Acc和Rec变化图
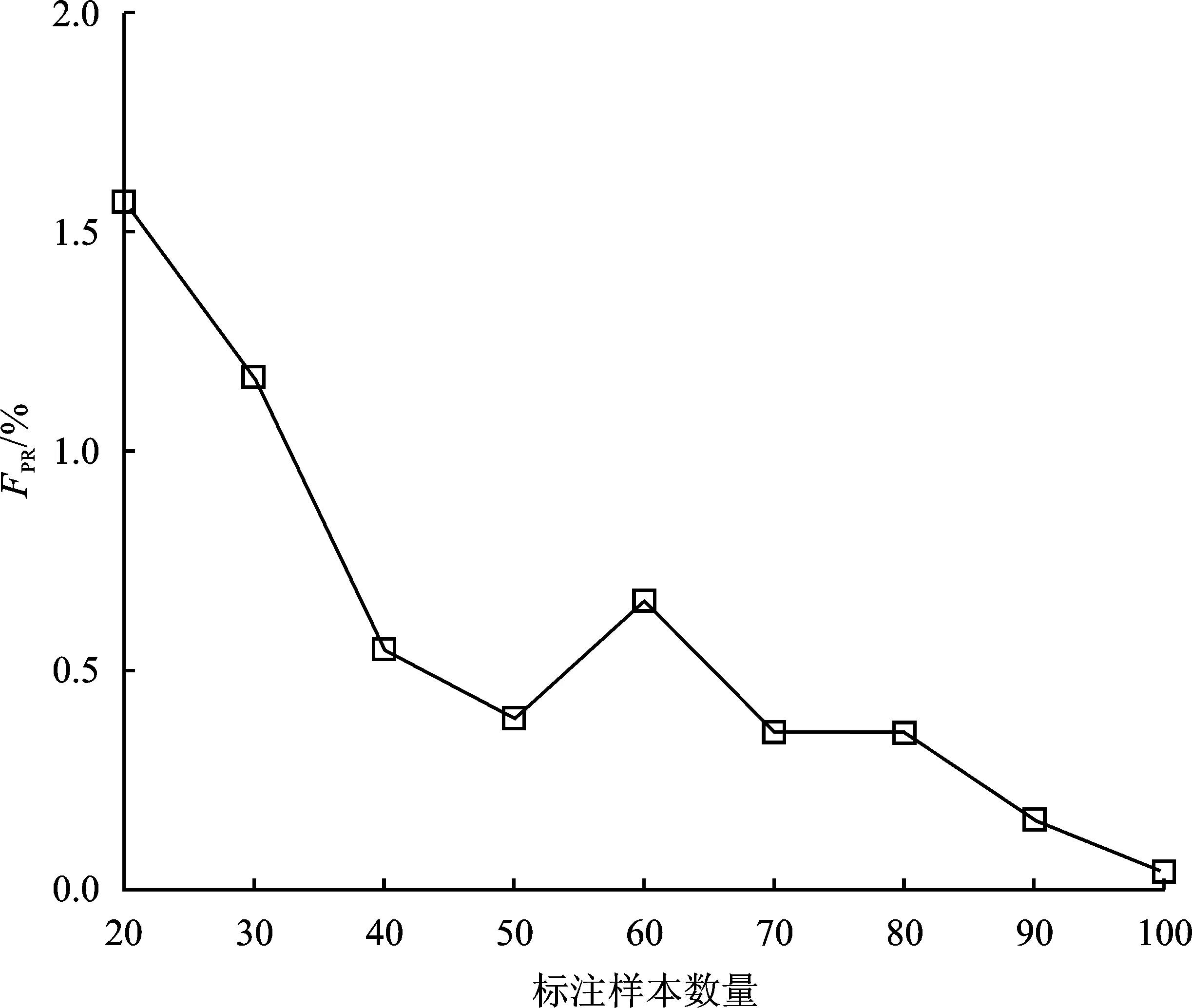
图4 MCC检测模型FPR变化图
4.3.3 与先进算法对比
为了验证所提模型的优越性,将提出的MCC检测模型与基于协同训练策略的文献[18]、SSML[19]检测模型和基于生成对抗网络的DCGAN[20]检测模型进行对比。在节3.1.1所述实验环境下,MCC检测模型的参数如节3.2所述;文献[18]检测模型中的极端随机树分类器采用默认参数;SSML检测模型中的决策树分类器和K近邻分类器均采用默认参数;按照节3.3.2所述的标注样本数量设置进行实验,DCGAN模型参数设置为源文献中参数。实验结果如图5和图6所示。
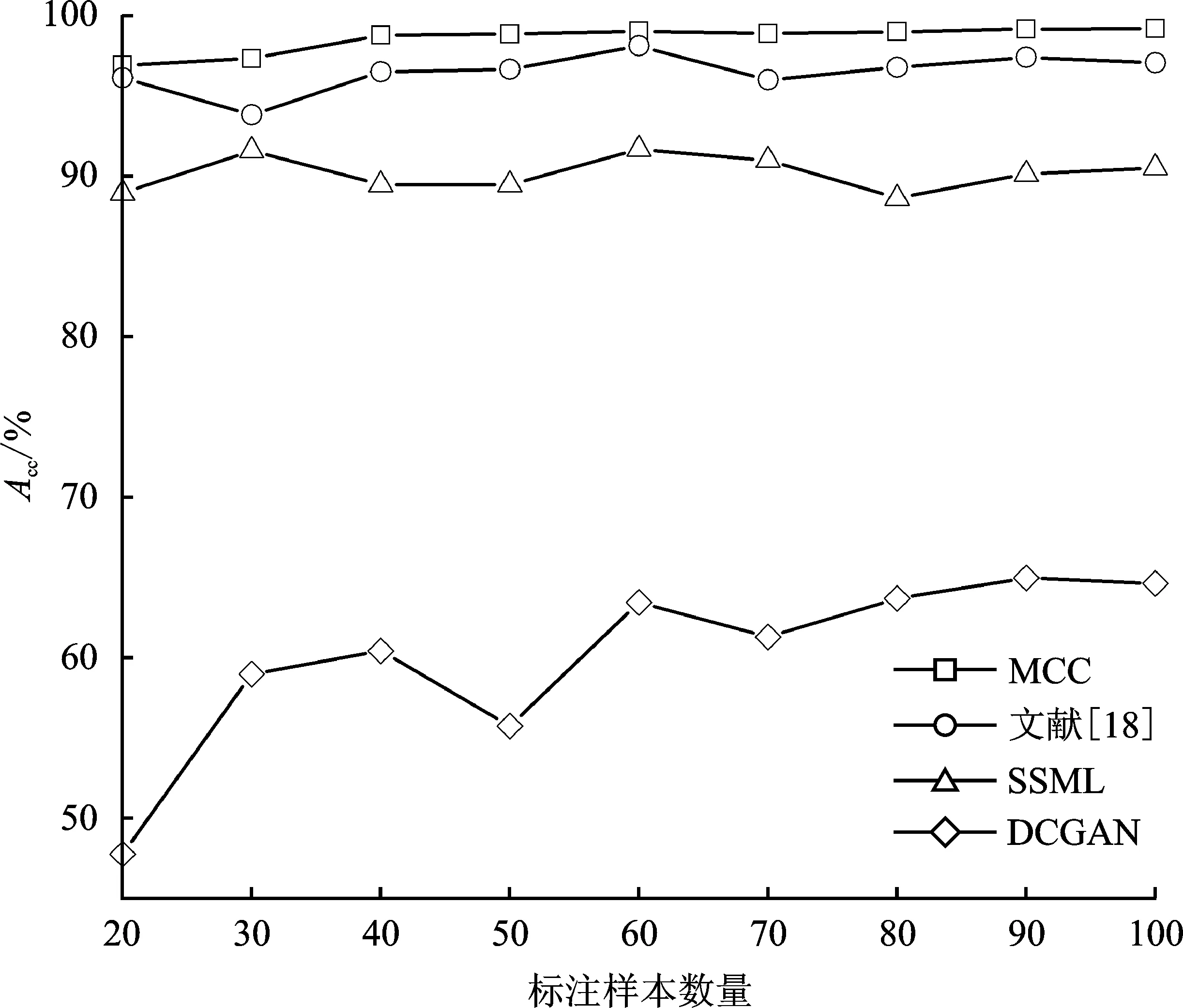
图5 4种模型Acc结果对比
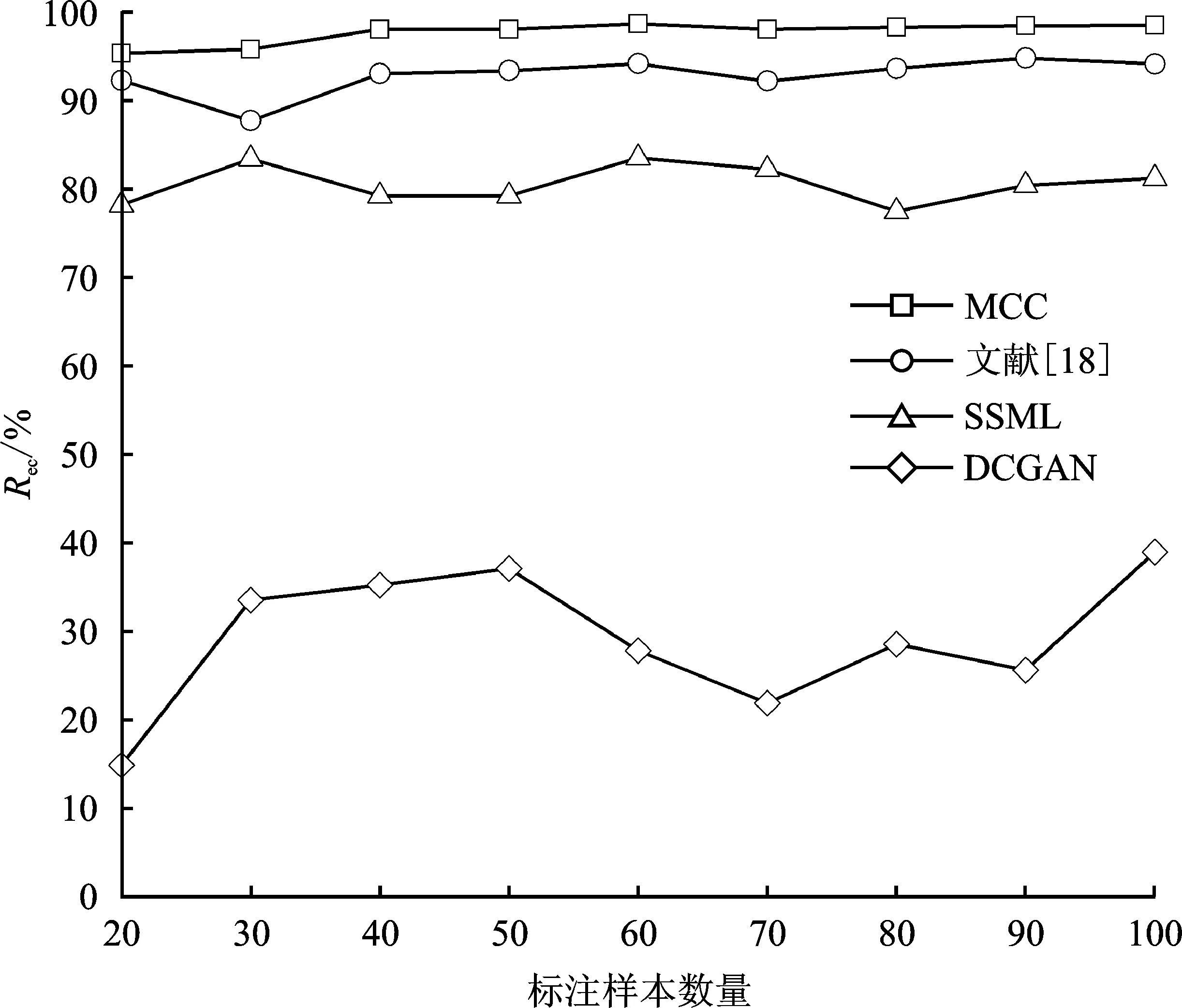
图6 4种模型Rec结果对比
文中所提出的MCC检测模型效果在平均准确率和平均误报率上均优于其他3种检测模型。相较于文献[18]和SSML两个检测模型,在平均准确率上分别提升了约2.08%和8.40%,在平均召回率上分别提升了约4.87%和17.16%。相较于DCGAN检测模型,在平均准确率上提高了约38.42%,在平均召回率上提高了约68.46%。实验结果表明,文中所提出的MCC检测模型不仅较现有基于协同训练的模型具有较大的性能提升,相较于基于生成对抗网络的模型具有更大的性能提升,验证了MCC检测模型的优越性。
5 结束语
研究针对现有加密恶意流量机器学习检测方法高度依赖标注样本的问题,提出了一种使用半监督学习的加密恶意流量识别的多视图协同训练方法,建立了基于协同训练的高效分类器,结合加密流量的流量行为元数据特征和流量交互初始的证书特征,利用少量标注样本和大规模无标注样本对所提模型进行训练。实验结果表明,该检测模型以少量标注代价达到全标注条件下的恶意流量识别效能,能够有效缓解流量识别任务的标签数据依赖困难;通过试验得到标注样本的需求规模,结合人机协同的工程设计方案,提升了恶意流量检测模型泛化性和迭代速率。实验表明,文中提出的方案优于现有半监督学习流量检测方法。本文提出多视图加密恶意流量检测方法能够以少量的标注代价实现TLS加密恶意流量的高效检测,有效缓解了加密流量领域恶意样本演进迅速、人工安全知识依赖的现状,能够投入实际的工业界实际检测任务应用。下一步将就检测模型的鲁棒性进行多场景验证和改进。
