邻居子图扰动下的k-度匿名隐私保护模型
2023-09-07丁红发唐明丽蒋合领傅培旺于莹莹
丁红发,唐明丽,刘 海 ,蒋合领,傅培旺,于莹莹
(1.贵州财经大学 信息学院 贵州省大数据统计分析重点实验室,贵州 贵阳 550025;2.贵安新区科创产业发展有限公司,贵州 贵阳 550025)
1 引 言
互联网、移动物联网的高速发展产生了社交网络、移动轨迹、引文网络、邮件网络等海量图结构数据,且被广泛应用于学术研究、数据挖掘、广告、商业决策支持、疾病传播研究等领域[1]。此类图数据在创造巨大社会价值和经济价值的同时,还涉及大量个人隐私(如身份信息、政治倾向、个人喜好、地理位置等敏感信息),在共享、分析及应用图数据过程中极易造成隐私泄露,引发了人们对隐私和安全的担忧。例如,2019年,美国社交媒体脸书(Facebook)超5亿用户的个人数据泄露,其中包括电话号码、电子邮件等;2022年7月,滴滴因个人轨迹信息、地图信息等数据安全问题被罚80亿人民币,再次警示从事数据搜集、存储、传输及使用的企业,应当增强数据隐私保护能力,直面图数据存储、使用中存在的安全问题,防范信息泄露风险。上述事件均表明社交网络、个人轨迹等图数据安全与隐私问题已成为当前社会一个亟待解决的重要问题。因此,研究图结构数据的隐私保护模型与算法变得尤为重要。
大规模图数据共享发布过程中,图数据节点属性和关系属性两类重要隐私信息易受到度信息攻击、子图攻击及链接攻击等结构化攻击。简单的匿名方法(例如,删除图数据节点的标识符)已经被认为是一种低效的匿名化机制[2],其无法可靠地保护节点的隐私。因此,隐私保护效果更好的各类匿名化隐私保护模型被相继提出[3-4],以防止图数据的隐私信息泄露,并防御针对图数据隐私的恶意分析和提取攻击。匿名化隐私保护模型通过将具有相同结构性质的节点数扩充至少k个,从而使得攻击者对图数据隐私节点的攻击命中率降低至1/k以下,并且匿名化模型可分别从节点的度、子图及节点标签等属性出发,对图数据进行隐私保护[5-6]。另一种比较流行的图数据隐私保护方法是差分隐私[7-10],其在实现过程中具有严格的数学理论证明。然而,差分隐私通常适用于发布图数据的统计信息,无法实现精确的子图模式匹配以及生成完整图数据。此外,差分隐私的隐私保护效果往往依赖于经验选择一个较优的隐私预算,在实际应用中效果通常难以控制。相比于差分隐私,匿名化由于算法简单、计算开销低、隐私保护效果易控制等特性,已被广泛用于各类商业应用中的图数据隐私保护[11]。因此,研究匿名化图数据隐私保护方法具有重要的理论和实践意义。目前,实现图数据匿名隐私保护的途径主要有两种:基于聚类的匿名化方法[12]和基于图修改的匿名化方法[13]。
基于聚类的方法[12]是通过对图的节点、边或对两者同时聚类,从而形成不可区分的匿名组。图数据同一匿名组中的节点泛化后可聚类构成超节点,同一匿名组中的边可聚类构成超边,通过超点和超边构成超图从而保护待共享发布图数据的隐私。YAZDANJUE等[14]提出了一种基于节点连接结构和属性值的属性图聚类匿名化方法,综合节点间的结构和属性相似度,将社交网络图数据所有节点聚类成一些包含节点个数不小于k的超点;LANGARI等[15]提出了一种基于k成员模糊聚类和萤火虫算法的组合匿名算法,使用模糊c均值来构建至少有k个成员的平衡聚类簇以保护匿名社交网络图数据不泄漏身份、属性和链接隐私,并能抵抗相似性攻击;HONG等[16]通过采用多维排序方案和基于贪婪分区的聚合技术设计了有向社交网络数据的k度匿名模型。综上所述,基于聚类的匿名方法通过聚类隐藏了超节点里面节点间的关系,能保护图数据中的隐私信息,但该方法将使超节点内部的数据效用急剧下降,因此仅适用于不需要公开数据内部结构的大规模图数据的场景。
基于图修改的方法是通过修改图数据中的部分节点和边,实现对图数据中隐私信息进行保护的匿名化技术。LIU等[13]提出了一种运用贪心策略增加边和噪声节点的方式来实现图结构数据的k度匿名算法,使得任何节点均至少与其余k-1个节点度数相同,该方法在能够抵御节点度攻击的同时严重改变了图数据的关系结构和连通性;随后,LIU等[17]设计了一种基于新的度序列划分算法的社交网络数据发布隐私保护算法,该方法仅通过增边和添加节点实现了k度匿名,但其信息损失过大; BAZGAN等[18]证明了利用不改变顶点/边数的边旋转实现图的k度匿名问题是非确定多项式(Non-deter ministic Pdynomido,NP)困难的; ZHOU等[19]提出了一种比k度匿名保护效果更强的隐私保护模型k邻居匿名,除了对节点度数实现了k匿名,还对节点的邻居结构实现了k匿名,但该方法不能抵抗子图攻击;CHENG等[20]提出了一种通过实现子图间同构的图数据k同构匿名方法,可抵御子图匹配攻击;此外,ZOU等[21]提出了基于图自身同构的图数据k同构匿名方法,也能抵御子图匹配攻击。k同构和k自同构方式实现了更强的隐私保护效果[22-23],但因其破坏图数据的关系结构会造成巨大的信息损失,显著降低了匿名后的数据效用。为了提高数据效用,LIANG等[24]将k匿名性定义为数学优化问题,试图实现图数据k匿名的同时最大化数据效用;SHAKEEL等[25]使用一种贪婪算法,在原始图中插入最少数量的虚拟连接来实现防止共同朋友攻击的k度匿名方法。综上所述,基于图修改的匿名方法使用增、删节点和同构的方式实现k匿名,一定程度上增强了隐私保护效果,但存在信息损失较大和图结构特性改变较大的问题。
为解决现有图数据匿名隐私保护方法存在的隐私保护强度不足和信息损失较大的问题,文中提出一种基于邻居子图扰动的k度匿名隐私保护模型(k-Degree anonymity privacy protection model based on Neighborhood subgraph Disturbance,NDKD)。该模型利用最小化边扰动机制实现每个节点的1-邻居子图扰动,提高该模型的抗隐私攻击能力;采用分治法优化匿名组划分,以减少对图数据结构的改变从而提高数据效用;此外,该模型引入两种新的图匿名修改方法:边缘添加和边缘删除,实现不增删节点而生成k度匿名图。通过上述措施,该模型能有效抵御1-邻居子图和节点度背景知识攻击,仍然具有较好的数据效用和图数据结构特性。具体而言,主要贡献有:
(1) 提出了一种邻居扰动后的k度匿名模型,通过改进邻居匿名和度匿名算法,实现对1-邻居子图和节点度的背景知识攻击的抵御。
(2) 改进了k度匿名算法,采用分治法优化匿名组的划分,减少匿名过程中节点的信息损失。引入了新的图匿名化操作方式:边缘添加和边缘删除,在保持原始图的节点数量条件下将图数据重构成完全满足k度匿名的匿名图。
(3) 在Stanford Network Analysis Project(SNAP)真实数据集上对所提方案及相关k匿名方案进行实验对比。结果表明,相较于传统k匿名方案,文中所提匿名模型具有更优的数据效用,且图结构特性改变更小。
2 相关定义
文中将图数据建模为无向、无标签、无加权的简单图G=(V,E),V表示图G中所有节点的集合,E表示图G中节点之间的关系集合,即边的集合,且E=V×V。本节介绍图数据发布匿名化隐私保护相关的概念和定义。
2.1 k度匿名
定义1(图的k度匿名模型) 给定图G=(V,E),∀vi∈V,在V中至少存在k-1个不同于vi且与节点vi拥有相同度数的节点,则图G满足k度匿名。
k度匿名的图G,满足图中任意节点与拥有相同度的其它节点,在度上不可区分,故节点的度攻击对于k度匿名图的命中率小于等于1/k。
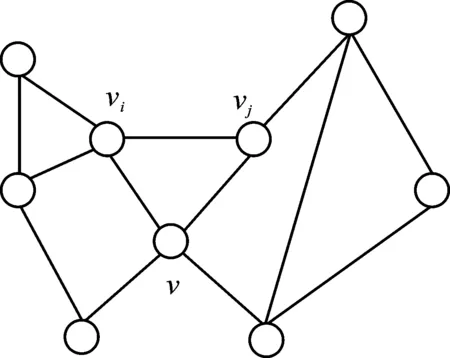
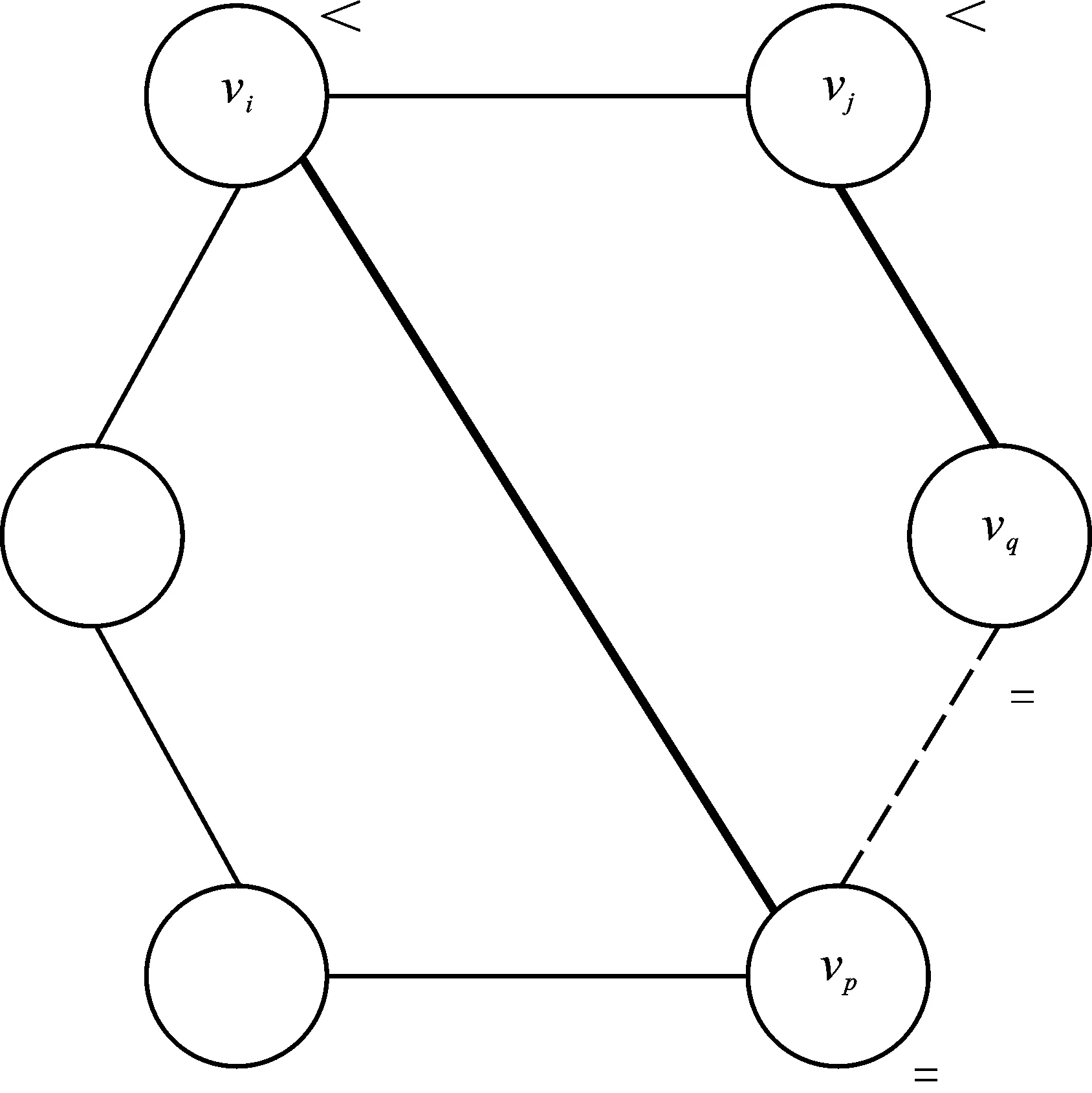
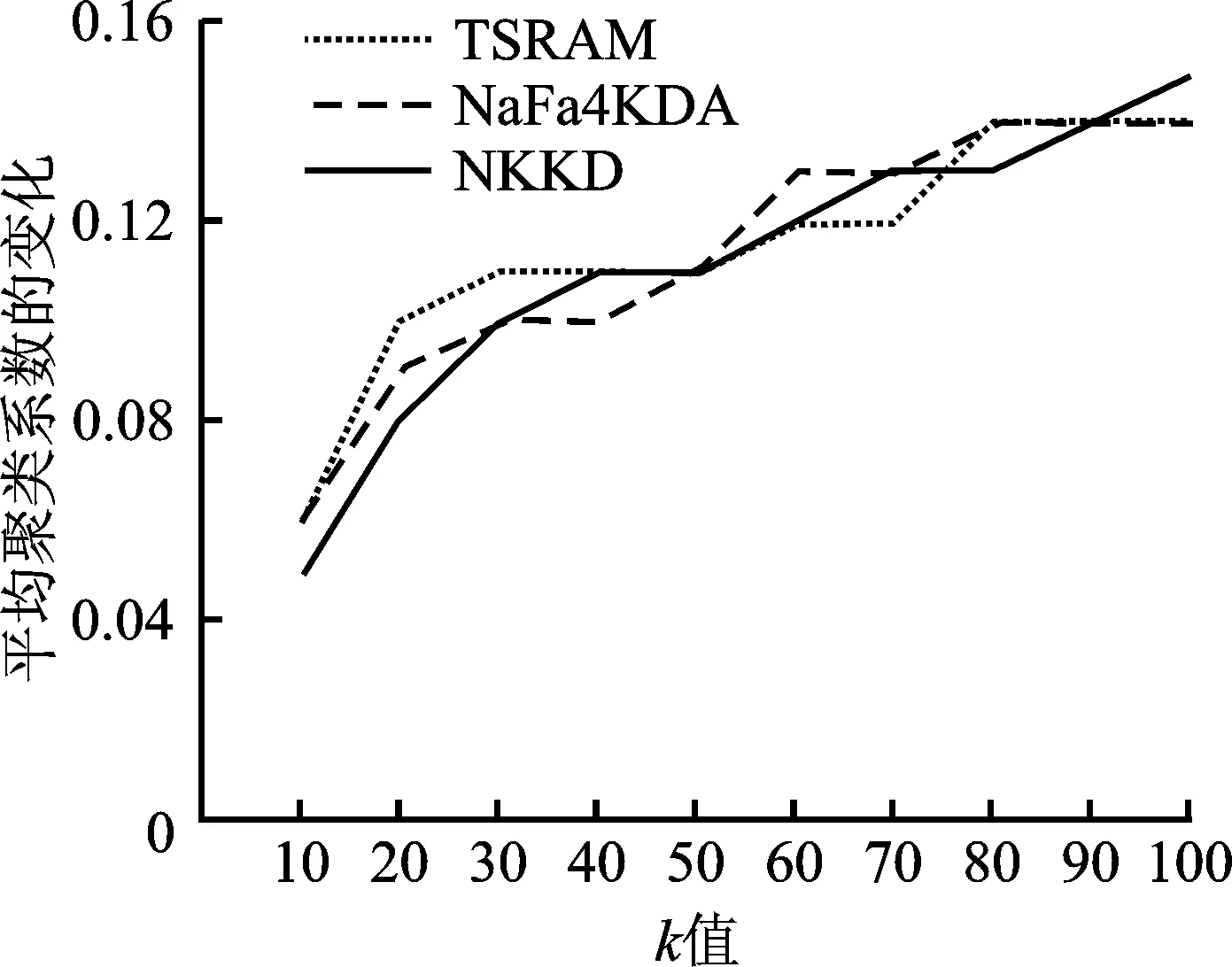
定义2(递减度序列) 若图G=(V,E)中的节点集V=(v0,v1,…,vn-1)中所有节点按照递减度的偏序关系排列,即dseq={d(vi)≥d(vi+1)|vi∈V,0≤i 定义4(1-邻居子图) 图G中节点v的1-邻居子图,定义为G中包括v在内的所有与v直接相连的节点,以及这些节点之间的所有边构成的子图,如图1所示。图1(b)为节点v在图1(a)的1-邻居子图。 (a) 图G 定义5(k邻居匿名) 若图G的任意一个节点vi∈V,在节点集V中至少存在k-1个不同于vi且与vi拥有相同1-邻居子图的节点,则图G满足k邻居匿名。 定义6(边的邻接点) 给定图G=(V,E),vi∈V,vj∈V。若V中存在节点v,使得e 针对图结构数据发布场景的隐私保护,文中提出了一种基于邻居扰动的k度匿名的隐私保护模型NDKD。为便于理解,首先在节3.1描述所提NDKD隐私保护模型的具体框架,其次在节3.2阐述该模型框架中各步骤的算法原理。 所提NDKD隐私保护模型由邻居扰动、度序列匿名和重构图3个模块构成,具体框架如图2所示。在图2中,NDKD隐私保护模型的3个模块即匿名化隐私保护的3个核心环节,按照邻居扰动、度序列匿名和重构图的顺序对原始图数据进行处理。 图2 NDKD匿名化隐私保护模型框架 (a) 原始图数据 NDKD模型的基本思想是:① 对原始图数据中的节点进行邻居扰动,使得扰动后的图数据不能被基于1-邻居子图的背景知识准确识别。同时,邻居扰动保留了原始图数据中大量节点的度值,即图数据中的绝大多数节点的度值未发生变化,但是这也使邻居扰动后的图数据依然无法抵御节点度攻击。基于此问题,对邻居扰动的图数据进行基于最大邻居差划分的k度匿名,结合匿名参数k,对邻居扰动后的图数据节点的递减度序列进行处理,生成节点集的匿名组。② 按照匿名组中节点度对邻居扰动后的图数据进行图修改操作,重构成k度匿名的图数据,使得重构后的图数据不能被基于节点度的背景知识准确识别。③ 将匿名后的图数据进行共享发布。 该模型的3个模块又分为若干个具体的步骤。邻居扰动模块首先将原始图数据的节点集映射到节点的递减度序列,遍历递减度序列中的节点,并找到与遍历的节点有最多邻居节点的另一节点;然后,改变两个节点之间边的状态。重复上述操作,直至原始图数据中每个节点的1-邻居子图都进行了扰动。度序列匿名模块首先根据参数k的值,采用分治思想,找到每个度序列之间的最大邻居差,用最大邻居差值将节点度序列划分为长度更小的度序列,直到所有的度序列的长度介于k-1至2k之间;其次,根据度序列匿名的信息损失,在最小信息损失的约束下,为每个度序列设置目标度,实现节点度序列的匿名化。重构图模块在增、删和移边操作的基础上,进行边缘添加和边缘删除操作,重构成匿名化的图数据。 为了进一步提高对图2所示的NDKD匿名化隐私保护模型框架的理解,图3以一个具体的简单图为例,结合所提出的隐私保护模型框架,阐述实现匿名参数k为3时的匿名化隐私保护过程。 第1步,对原始图数据进行邻居扰动。首先,将原始图数据(如图3(a))节点的度按照递减排序,递减度序列为dseq=[6,5,4,4,4,3,2,2,2,1,1,0,0,0]。其次,对所有节点按照递减度序列的顺序进行邻居扰动。最大度节点10的边e<2,10>拥有3个邻居节点,因此删除边e<2,10>。此时,1-邻居子图发生扰动的节点有5个,即节点2、节点4、节点5、节点7和节点10。排除这5个节点,继续对剩下的节点进行扰动。扰动后,最终得到图3(b),其中虚线代表删除边,粗线代表增加边。由于度为0的节点仅能通过节点度进行匹配,因此邻居扰动过程不对度为0的节点做处理。 第2步,对节点度序列进行匿名化。首先,采用分治法对图3(b)的递减度序列dseq=[5,5,4,4,3,3,3,3,2,2,2,0,0,0]进行划分。具体而言,在递减度序列的第3个数和倒数第3个数之间找到最大邻居差值,并在最大邻居差为2处对递减度序列进行划分,得到两个度序列[5,5,4,4,3,3,3,3,2,2,2],[0,0,0]。对序列长度大于2×3-1的序列继续进行上述操作,直至所有度序列均符合长度大于等于k且小于等于2k-1的条件,最后划分的度序列为[5,5,4,4],[3,3,3,3],[2,2,2],[0,0,0]。其次,分别计算各划分后的度序列的目标度,并赋值给各度序列,得到匿名组[4,4,4,4],[3,3,3,3],[2,2,2],[0,0,0]。 第3步,根据匿名组对扰动后的图进行图重构。根据前一步所得到的匿名组度数,对第1步所得到的扰动图进行重构。具体而言,对图3(b)中两个度数为5的节点4和10减少其度数。如图3(c)所示,这两个度为5的节点之间存在边,采用删边操作删除边e<4,10>,得到符合匿名组度数要求的图,如图3(d)所示。 经过上述基于邻居子图扰动的3度匿名化过程,图3(a)中任意节点的1-邻居子图都无法在图3(d)中进行匹配;匿名后的图数据(如图3(d))中的任意节点度都至少与其它2个节点度数相同,节点度的攻击命中率降低到1/3以下。 基于图2中匿名隐私保护模型的3个模块,设计实现核心功能的具体算法。节3.2.1提出邻居扰动模块中的节点1-邻居子图扰动算法,该算法确保每次扰动的边所涉及的1-邻居子图包含尽可能多的节点,从而在满足原始图数据节点1-邻居子图扰动的前提下使得图中扰动边的数量最少。节3.2.2首先提出度序列匿名模块中最大邻居差划分度序列步骤的算法和计算度序列的目标度步骤的计算公式,最大邻居差划分度序列算法通过分治法查找度序列的最大邻居差来划分度序列,避免同一度序列出现节点度的差值较大的情况。其次,对匿名组度数之和不为偶数时的操作进行了说明。节3.2.3提出重构图模块中的图数据边修改算法,利用增、删和移边以及边缘添加、边缘删除生成匿名图数据。 3.2.1 节点1-邻居子图扰动的算法 在对图数据进行k度匿名之前,若存在图数据或图中大部分节点原本就满足k度匿名的情况,则k度匿名后的图数据的大部分节点会保留原始图数据中的结构信息。根据定义1,k度匿名后的图数据可以使攻击者不能根据节点的度信息对某个节点进行唯一识别,但是攻击者若掌握了某节点的1-邻居子图信息,则依然可以根据节点的1-邻居子图唯一识别该节点。因此,文中在k度匿名之前,对图数据进行1-邻居子图的扰动,使得任意情况的图数据在匿名之后,均无法被攻击者所掌握的1-邻居子图信息唯一识别。 由定义4和定义6可知,若某条边e在节点v的1-邻居子图中,那么节点v一定在边e的邻接点中。图中的任意一条边e 算法1节点1-邻居子图扰动的算法。 输入:原始图数据G 输出:邻居扰动后的图数据G′ ① forviindseq://dseq为图G的节点集的递减度序列 ②vj=Search_Max_NNeighbor(vi)//vj为与节点vi有最多邻居节点的节点,且i≠j ③ ife ④ deletee ⑤ else: ⑥ adde ⑦ ife ⑧ deleteNNeighbor[vi],NNeighbor[vj],NNeighbor[vm] //NNeighbor为G未修改1-邻接子图节点的邻接矩阵 ⑨ returnG′ 算法1按图G的递减度序列进行遍历,对所有节点的1-邻居子图的至少1条边进行修改,直至所有V中所有节点的1-邻居子图都进行了修改。由于度为0的节点不具有1-邻居子图,因此此步骤中不考虑度为0的节点。在扰动完成后的图中,原始图数据中任意节点的1-邻居子图都无法进行匹配。算法1在进行邻居扰动过程中会使部分节点的度值发生变化,造成图数据的部分信息损失,但是该算法保证了进行扰动的边尽可能地少,所以对算法2的匿名过程中数据效用损失的影响非常小。 对图数据进行1-邻居子图扰动的过程中,若每次计算全图中边邻接点数量,则会造成O(n3)的时间开销比较大。考虑到边e 在算法1中,NNeighbor的大小从2m跳跃式地递减,递减速度受图数据结构的影响,其中m为图G=(V,E)中边的数量。若NNeighbor从2m跳跃式地递减到0需要a次,则遍历次数为a,所以遍历次数取决于NNeighbor的递减速度。因此算法1的时间复杂度最好的情况为O(m),最坏的情况为O(m2),平均情况为O(m)。算法1的空间复杂度为O(m)。 3.2.2 最大邻居差划分度序列算法和计算度序列的目标度的方法 1) 最大邻居差划分度序列算法 在划分匿名组的过程中,度序列的两个邻居之间的差异会影响划分结果。例如,1个度序列dseq=[9,9,8,7,7,3,3,2,2],包含9个节点的度。邻居差是指节点度的差值。若匿名参数k为4,则度数为7与度数为3的两个相邻节点的度差异最大为4。在最小信息变化量和匿名参数k的约束下,最优的匿名划分为[9,9,8,7]和[3,3,2,2]。 度序列最大邻居差的划分采用了分治的思想,同时为了避免采用递归方法造成空间复杂度开销过大的问题,算法2采用非递归方法实现,在O(n2)的时间复杂度内解决节点子序列的划分问题。对整个节点集合V′子序列的划分,等价于节点度递减序列的划分,将递减度序列邻居差异的划分问题,分解为几个匿名子序列划分的问题。对于每个长度大于2k-1的匿名子序列,都可以划分为两个或两个以上的子序列。因此,每次查找最大邻居差需要在匿名序列的第k个元素和2k-1个元素内寻找。具体如算法2所示。 算法2最大邻居差划分度序列算法。 输入:匿名参数k和图G′的递减度序列dseq 输出:匿名序列划分的最大邻居差下标Neig_diff ①i=Max_Neig_Division(dseq,k)//k为匿名参数,i为dseq最大邻居差节点的下标 ② Neig_diff.append(0,i,n)//将最大邻居差的节点的下标以及0,n添加到Neig_diff ③ while flag==True: //flag记录下标之间是否还存在距离大于2k的情况 ④ flag=False ⑤ forp,qin Neig_diff: //p,q为已记录的最大邻居差下标的两个相邻下标 ⑥ ifq-p+1≥2k: ⑦i=Max_Neig_Division(p,q,k) ⑧ Neig_diff.append(i),flag=True ⑨ return Neig_diff 算法2中,首先将邻居扰动之后的图数据,按定义2进行节点度序列的降序排序。然后根据匿名化参数k和最大邻居差,将图G′划分为满足k匿名的度序列。该算法的划分从全图的度序列开始,避免了将邻居差过大的节点划分到同一匿名组,从而造成信息损失过大的问题。其次,该算法采用了非递归的算法,避免了递归方法中空间复杂度开销过大的问题。 2) 计算度序列的目标度的方法 由于使用遍历搜索来选择匿名节点的目标度数对于大规模图数据时间复杂度的开销过大,因此文中使用一种贪婪的方法[28]来降低搜索的复杂性。该方法将度序列的节点平均值作为该序列的目标度,但是度序列的节点平均值可能不是整数,因此引入两个值mj1,mj2。其中,mj1是节点集gj的度序列与属于该组的所有节点度的平均值的差值的总和,使用下取整函数将平均值四舍五入。mj2以同样的方式计算,但使用了上取整函数。mj1与mj2的计算方法由式(1)、式(2)给出: (1) (2) 然后,使用Pj1,Pj2分别来计算gj的目标度为〈gj〉下取整和上取整的概率。概率值越大,信息损失就越小,该值作为该节点集gj的目标度就越优。Pj1,Pj2的计算方法由公式(3)、式(4)给出: (3) (4) 其中,Pj1为匿名组gj使用均值下界作为目标度的概率,Pj2为匿名组gj使用均值上界作为目标度的概率。 为划分好的度序列赋值目标度后得到匿名组。匿名后所有节点目标度的和必须是偶数,因为每条边在度序列中被计数两次。在匿名度序列划分以及计算出各匿名组的目标度之后,如果出现图的节点目标度之和为奇数的情况,则对划分的匿名组进行回溯,找到拥有最小奇数差值的邻居差值的匿名组gi,gj。在两个匿名满足式(5)的条件下,更改匿名组gi的最后一个节点放入gj中,或者将gj第1个节点放入gi中,实现最小信息损失的满足匿名图中节点度数必须为偶数的要求: Min_Diff={min(d(vi)-d(vj))|i ((|gi|>k)∩|gj|<(2k-1))∪(|gi|<(2k-1)∩|gj|>k)} , (5) 其中,|gj|为匿名组gj的节点个数。 3.2.3 重构图算法 图G′的节点与其在匿名组中的关系有3种:① 节点vi小于其在匿名组v′i度数,即d(vi) 对于原图中边的两端节点度数同时大于或小于其在匿名序列中节点目标度的情况,采用删边和增边,使其边两端节点度接近或达到其在匿名序列中的目标度,如图4(a)所示。而对于边的两端节点d(vi) (a) 增边、删边 需要注意的是,在重构简单图过程中,单个节点不能单独增加边;已存在边的两个节点不能再增加边;不存在边的两个节点不能删除边。仅依靠增边、删边和移边3种方式,并不能保证图G′能够完全重构成满足匿名序列节点的图。例如,当图重构过程中,可能出现仅剩的节点vi和vj之间不存在边e 为了解决上述问题,在重构图的过程中,引入另外两个不同于节点vi和vj的节点vp和vq,并采用边缘添加和边缘删除策略,如图5所示。 (a) 边缘添加 在采用边缘添加和边缘删除时,需要避免某个节点匿名前后的度变化过大。因此,创建一个序列Change_d记录每个节点匿名前后的度值变化的大小,并将序列按度值变化大小递减排序。 算法3重构图算法。 输入:邻居扰乱后的图G′=(V′,E′)和匿名后度发生变化的节点集合Change_d 输出:满足邻居子图扰动下的k度匿名的图G″=(V″,E″) ① forvi,vjin Change_d: ② ifd(vi)>d(v′i) andd(vj)>d(v′j): ③ deletee ④ ifd(vi) ⑤ adde ⑥ ifd(vi)>d(v′i) andd(vj) ⑦ deletee ⑧ forvi,vjin Change_d: ⑨ ifd(vi)>d(v′i) andd(vj)>d(v′j): ⑩ ife 算法3中,步骤①对节点集合Change_d进行遍历,按照匿名前后节点度改变量大小的顺序对节点进行步骤②~⑦的增、删和移边的操作,消除了匿名前后度变化过大的节点,从而保证边缘添加和边缘删除的匿名操作方式能生成完全满足k匿名的图。步骤⑧遍历未达到匿名目标度的节点,步骤⑨~采用边缘添加和边缘删除,对这些节点进行操作,在图数据G′节点的数量上,完全重构成符合k度匿名的图数据。 首先将所提出的NDKD隐私模型与TSRAM[26]、NaFa4KDA[27]模型进行分析对比,从理论层面分析不同图数据匿名隐私保护模型的差异;其次,利用Facebook、Wiki和Github真实数据集进行实验,从匿名隐私保护算法对图数据的边变化、信息损失、节点平均度和聚类系数的影响进行对比,量化对比不同匿名隐私保护算法的效用与隐私影响。 所提NDKD模型主要的空间开销在邻居扰动阶段。该阶段的时间开销受图数据边的稀疏程度的影响,时间复杂度在最好情况下为O(m),在最坏情况下为O(m2),空间复杂度为O(m)。在度序列匿名阶段和重构图阶段时间复杂度均为O(n2),空间复杂度为O(n)。 相较于传统的k度匿名,文中所提出的NDKD模型增加了1个邻居扰动模块。该模块会增加一定的时间开销和空间开销,但能进一步增加模型的抗隐私攻击能力。此外,在度序列匿名阶段和重构图阶段,所提模型采用的方法与另外两种匿名模型均存在差异。在度序列匿名阶段,NDKD采用最大邻居差划分匿名组;在重构图阶段,则引入两种匿名化操作方式。具体对比如表1所示。 表1 不同k度匿名模型对比 由表1可知,NDKD、TSRAM和NaFa4KDA此3个不同的匿名隐私保护模型均实现了图数据的度匿名隐私保护。然而,在时间和空间复杂度等计算开销、度序列匿名和重构图操作等匿名原理以及安全性方面,3个模型各有不同。 在计算开销方面,NDKD模型相比于NaFa4KDA模型,时间复杂度从O(n2+mlogm)降低至O(m+n2);NDKD模型相比于TSRAM和NaFa4KDA模型,空间复杂度从O(l+n2)和O(n2)降低至O(m+n)。时间复杂度降低的主要原因是,NDKD模型采用分治法在O(n2)的时间内进行匿名组的划分;空间复杂度降低的主要原因是,TSRAM和NaFa4KDA的主要开销在图重构阶段,二者都采用了计算边缘得分的方式来进行边的修改,每次图修改都要对两个节点之间的边缘的分进行计算,为了降低对图数据结构特性的改变而增加了空间复杂度开销;而NDKD模型采用了两类图修改操作模式来进行重构图,不计算节点间的边缘得分,降低了空间复杂度的开销。NDKD模型的整体空间复杂度为O(m+n)。 在安全性方面,TSRAM和NaFa4KDA仅能抵抗节点度攻击,而NDKD模型能同时抗节点度攻击和1-邻居子图攻击。这是由于NDKD模型采用了基于1-邻居子图扰动的边扰动模式,扰乱了图中节点的1-邻居子图,使得原始图数据节点的1-邻居子图无法在邻居扰动后的图数据中进行匹配,同时对扰动后的图数据进行了k度匿名隐私保护,提高了去匿名化攻击的难度,增强了模型的隐私安全性。 为了评价所提NDKD模型的数据效用,将所提NDKD模型与TSRAM、 NaFa4KDA模型在真实图数据集上进行实验来对比算法性能。实验数据集选取SNAP上3个公开数据集,分别是Facebook、Wiki和Github,3者均为无向无权简单图。表2中给出了所选数据集的主要特征。将分别在k取值为10、20、30、40、50、60、70、80、90和100时[13,28-29],对比所提NDKD模型与TSRAM、NaFa4KDA模型的度量效用。文中实验均在11th Gen Intel(R) Core(TM) i5-11400H @ 2.70 GHz 2.69 GHz、16 GB RAM和Windows 11上进行测试,通过Python3.10实现。 表2 数据集特征 4.2.1 图属性度量实验分析 从边数变化的百分比、图中节点的信息损失量和图中节点平均度的变化这3个图数据属性指标对NDKD模型与TSRAM和NaFa4KDA模型进行效用对比。其中,边变化百分比反映了匿名过程中原始图数据中任意两个节点之间的结构变化;信息损失量通过计算各个节点匿名前后度的差值,衡量了对原始图数据的影响程度;网络节点平均度衡量了匿名前后图的整体节点度的变化程度。从数据效用方面看,匿名隐私保护模型对图数据的这3个属性指标的影响越小,隐私保护模型的数据效用越高。 不同匿名隐私保护模型作用在图数据上,边数变化百分比的对比结果如图6所示。由图6可知,在Facebook数据集中,TSRAM模型使得匿名隐私保护后的图数据边变化百分比最大,NaFa4KDA模型其次,NDKD模型的边数变化百分比最小。特别是,当k值在10~60区间时,NDKD模型具有明显的数据效用优势,相比于TSRAM和NaFa4KDA模型的边数变化百分比分别降低了26.84%和5.60%。同样地,在Wiki数据集中,边数变化分别降低30.21%和32.11%;在Github数据集中,NDKD模型的边数变化百分比同样最小,边数变化分别降低8.37%、9.46%。 (a) Facebook图数据 不同匿名隐私保护模型作用在图数据上,信息损失的对比结果如图7所示。由图7可知,对比结果与图6保持一致。在Facebook数据集中,TSRAM模型的信息损失最大,NDKD模型的信息损失最小,NDKD模型与TSRAM和NaFa4KDA模型相比,信息损失分别降低了29.24%和6.60%;在Wiki数据集中,NDKD模型与TSRAM和NaFa4KDA模型相比,信息损失分别降低34.14%和39.72%;在Github数据集上的实验结果也相对一致,NDKD模型的信息损失最小,与TSRAM和NaFa4KDA模型相比分别降低了 4.74% 和11.85%的信息损失。图8与图7的结果保持一致的原因是,图数据的信息损失是基于边的变化量计算得到的,两个属性值相关性较高。 (a) Facebook图数据 (a) Facebook图数据 在图6和图7中,NDKD模型能够保持较小的边数变化量和信息损失,是因为基于最大邻居差值的匿名序列划分避免了拥有较大差值的节点分到同一个匿名组,而造成过大信息损失的问题。TSRAM算法通过度序列构建树划分匿名组,在不断合并最佳邻居分组时,会产生额外的信息损失,而导致发生变化边的数量增多。在Wiki数据集中,节点度数的差异更大,导致NDKD的优势更加明显。在Github数据集中,由于数据集的节点平均度数较小,导致NDKD中邻居扰动步骤的边数变化和信息损失有所增加,这导致NDKD在边数变化和信息损失方面的优势有所降低。 不同匿名隐私保护模型作用在图数据上,平均节点度变化的对比结果如图8所示。由图8可知,在Facebook、Wiki和Github这3个数据集中,相同的k值情况下,NDKD模型的平均节点度变化值都要显著低于TSRAM和NaFa4KDA模型,说明NDKD模型作用于图数据上时,保留了原始图数据更多的节点度信息相关的数据效用。具体而言,在Facebook数据集中,NDKD模型与TSRAM和NaFa4KDA模型相比,节点平均度的变化分别降低77.74%和79.67%;在Wiki数据集中,节点平均度的变化分别降低86.53%和88.12%;在Github数据集中,节点平均度的变化分别降低29.67%和52.27%。 在图8中,NDKD模型能够保留更多原始图数据的节点度数据效用的原因是,NDKD模型在匿名组划分的过程中利用最大邻居差划分度序列的方法,避免了同一匿名组出现较大的度差值,进而在图数据重构阶段进行的图修改过程对节点度的影响降低,使得图数据节点保持较低的节点平均度数变化。 4.2.2 平均聚类系数度量实验分析 为了进一步分析不同匿名隐私保护模型对图数据结构数据效用的影响,本节通过对比匿名模型作用于图数据前后对图数据聚类系数的变化影响,以分析不同匿名隐私保护算法的数据效用。 不同匿名隐私保护模型作用在图数据上,平均聚类系数变化的对比结果如图9所示。由图9可知,在Facebook数据集中,当k值在10~30之间时,NDKD模型的平均聚类系数变化量小,当k值大于30,3种匿名方法所造成的聚类系数变化趋向于相同,都保持了较小的平均聚类系数的变化;在Wiki数据集和Github数据集中,由于数据集的规模的增大,NDKD模型在保持图数据结构数据效用方面的优势显著,相比于TSRAM和NaFa4KDA模型,该模型的平均聚类系数变化显著降低。总体而言,NDKD模型保留图数据的结构性数据效用显著提升。与TSRAM和NaFa4KDA模型相比,在Facebook数据集中,NDKD模型的平均聚类系数变化分别降低了3.45%和1.75%;在Wiki数据集中,分别降低2.86%和62.64%;在Github数据集中,分别降低了38.46%和38.46%。 (a) Facebook图数据 NDKD模型能显著提升图数据的结构性数据效用的原因是,文中提出的匿名组划分方式比TSRAM的度序列构建树和NaFa4KDA的匿名组划分方式造成的信息损失更小,从而保留了更多的数据效用。在此基础上,NDKD进行的边缘添加和边缘删除的匿名操作方式相比增加噪音节点图修改的方式,对图数据结构关系造成的影响更小。 匿名隐私保护模型在图数据共享发布场景中有着广泛的应用。而现有的匿名隐私保护模型无法均衡图数据的隐私保护和数据效用冲突。文中基于邻居子图扰动提出一种高安全强度的k度匿名隐私保护模型,该模型通过邻居子图扰动算法以及度序列的匿名化算法,实现了对基于1-邻居子图和节点度的背景知识攻击的防御。同时,该模型采用最大邻居差划分匿名组并利用图修改操作重构图数据,降低了匿名化图数据的信息损失,提升了匿名图数据的数据效用。相比于已有的图数据k度匿名隐私保护模型,所提模型计算效率和安全性方面有了大幅度提升,同时在图数据的属性效用和结构效用方面也有了显著提升。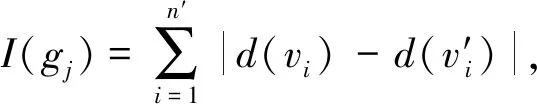
2.2 k邻居匿名
3 NDKD隐私保护模型和算法设计
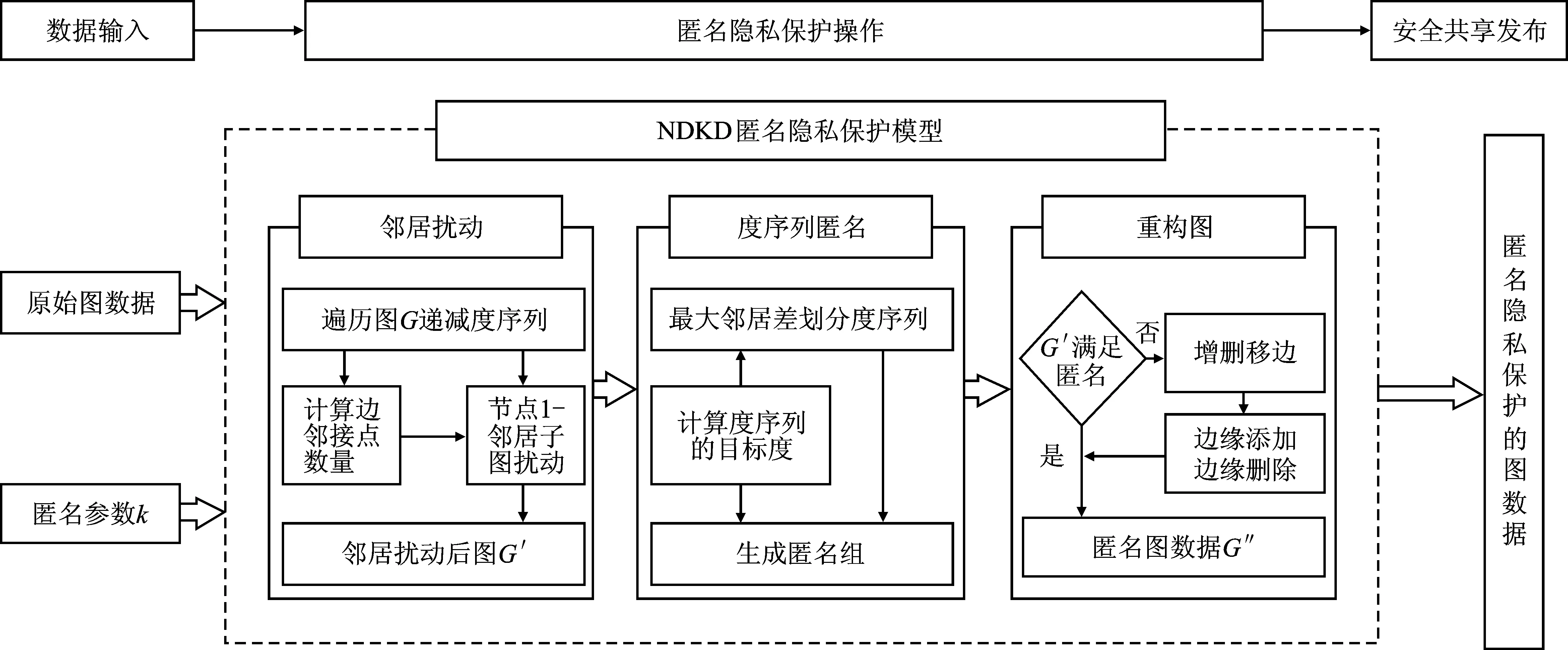
3.1 NDKD隐私保护模型框架
3.2 NDKD隐私保护模型的算法设计
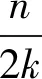



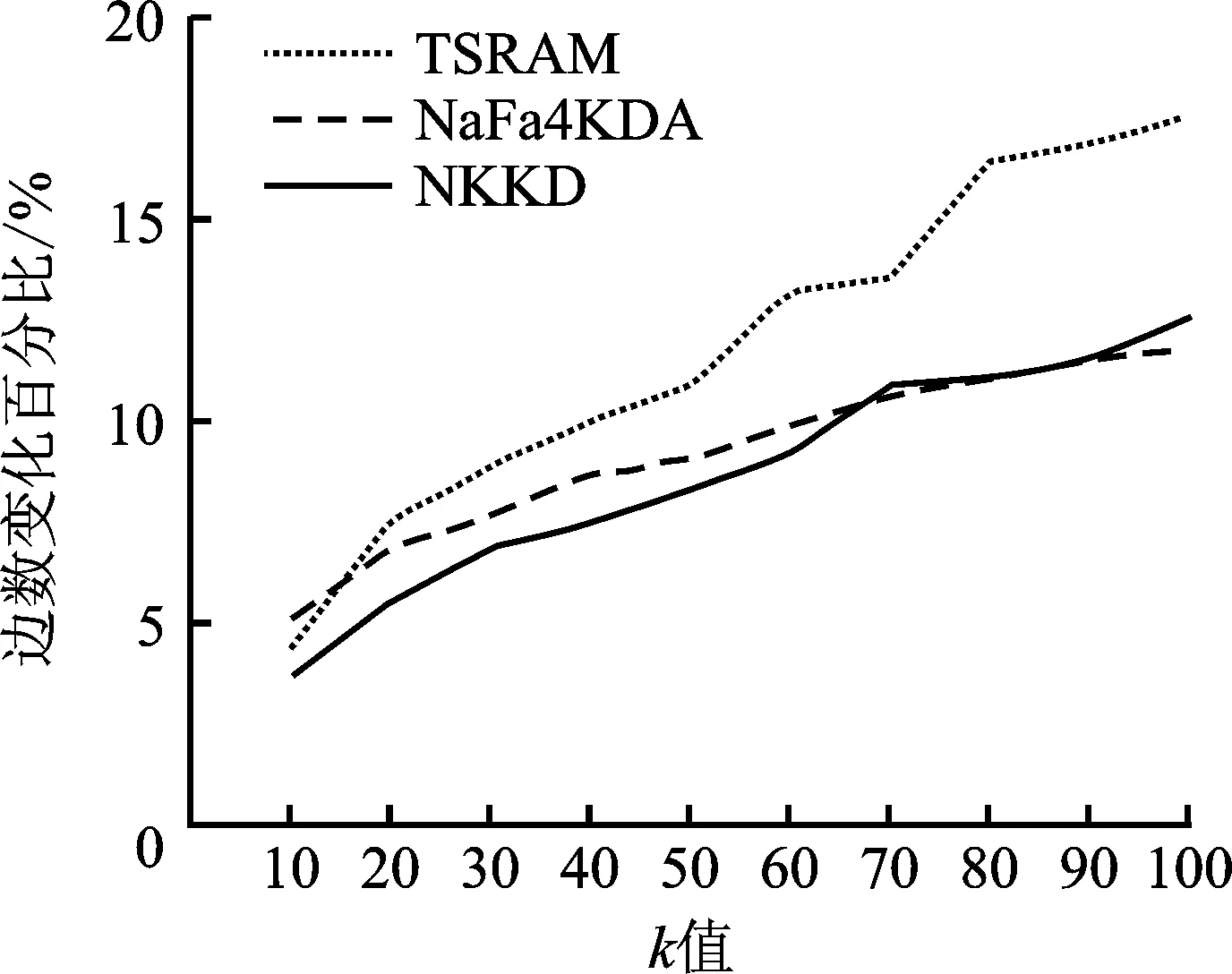
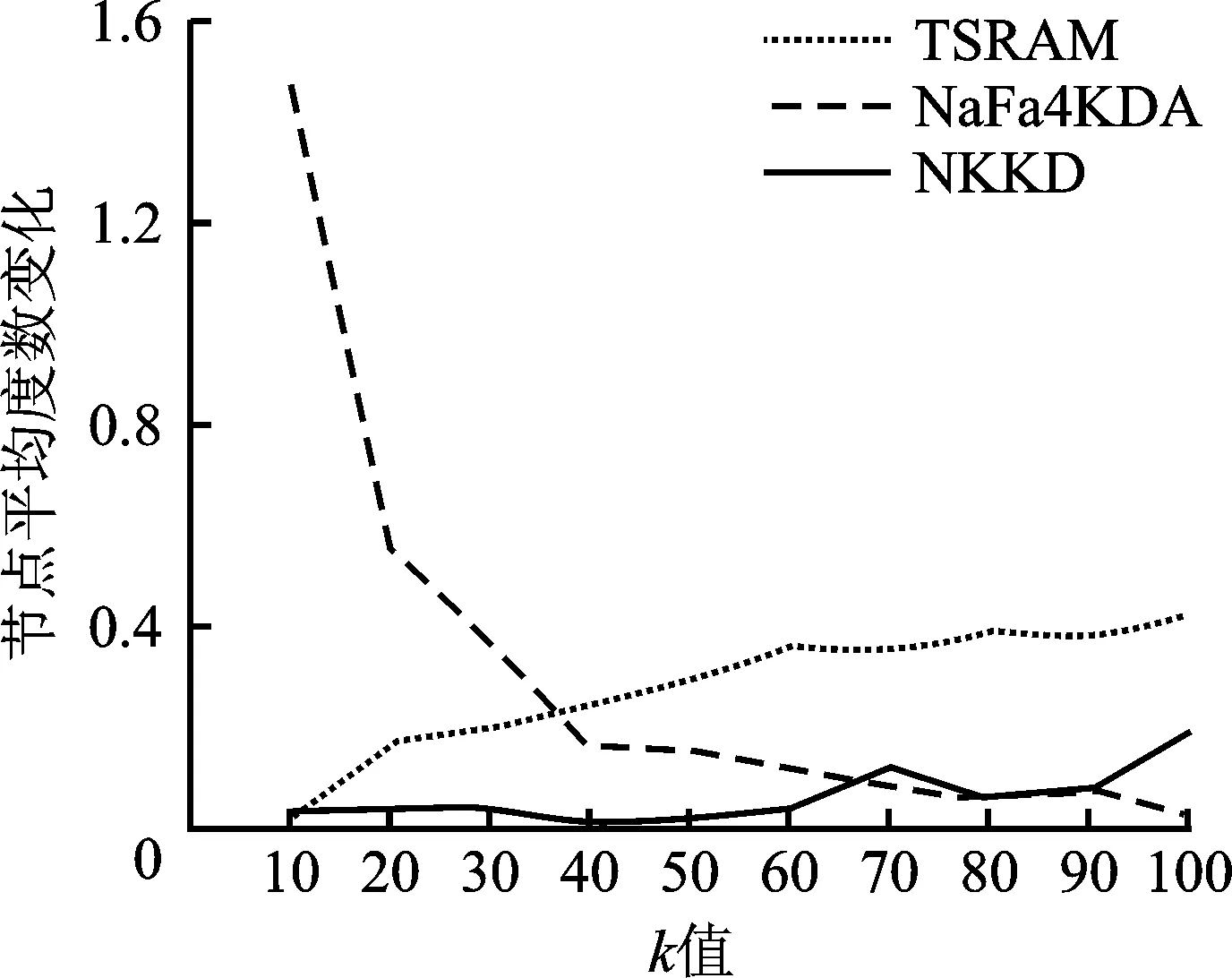
4 模型分析与实验对比
4.1 模型分析

4.2 实验对比


5 结束语
