无人机载MiniSAR 实时成像处理GPU 异步优化
2023-09-06袁溆东雒梅逸香王智超谭佳伟
袁溆东,雒梅逸香,王智超,谭佳伟,王 峰
(1.复旦大学 信息科学与工程学院,上海 200433;2.32033 部队,海南 海口 570100;3.31453 部队,辽宁 沈阳 110000)
0 引言
合成 孔径 雷达(Synthetic Aperture Radar,SAR)有着全天候、全天时的工作特性以及分辨率不随平台高度变化的成像特性[1],是航天遥感、目标检测领域重要的传感器之一。SAR 系统的平台通常是卫星、飞机、导弹、工程车、热气球等。随着电子技术和航空技术的发展,无人机以其小型化、低功耗、灵活性强和隐蔽性强等特点倍受关注[2-4],常被用于雷达数据的采集。实时无人机载成像系统的研究前景广阔,实时性不仅有利于系统及时保存成像数据,且有利于无人机探测感知一体化的设计[5-6]。
庞大的计算量是实现实时无人机载MiniSAR的一大挑战,当前的研究分为基于成像原理的算法优化[1]和基于硬件结构的算法优化[7]。前者改变计算量和计算方法,可减少算法复杂度,但往往会伴随着成像质量下降的风险。后者不改变计算量和计算方式,在提高计算效率的同时可以保证成像质量。本文工作围绕后者进行展开。
硬件的选择需要结合算法特点,相比于中央处理单元(Central Processing Unit,CPU)与现场可编程门阵列(Field-Programmable Gate Array,FPGA),图形处理单元(Graphics Processing Unit,GPU)更适合用于SAR 成像算法。一方面,将CPU与GPU 进行对比[8],虽然CPU 中的单个核心频率要比GPU 高得多[9],逻辑预测的能力要比GPU 快得多,但核心数量远不及GPU,GPU 可并行执行的线程数量远超于CPU,使GPU 的并行计算能力大大优于CPU,对于并行度高的SAR 算法,使用GPU的计算方式进行优化,可以极大加快运算的速度,因此GPU 比CPU 更适合承担SAR 实时系统的计算任务;另一方面,将FPGA 与GPU 进行对比。FPGA 擅长处理通信密集型运算[10-11],GPU 擅长处理计算密集型运算[11-14],而SAR 属于计算密集型运算而非通信密集型运算,所以GPU 相比于FPGA更适合用于SAR 成像的处理。
GPU 擅长处理具备以下3 种特点的计算任务[15]:1)计算需求量大,其算法可以保证任务占满GPU 内部的计算资源,防止资源浪费;2)计算并行程度高,其算法可以保证GPU 开启更多的并发任务,提高GPU 各时刻计算核心的活跃度;3)吞吐量的重要性大于延迟,其算法可以降低GPU 对单线程处理速度的要求,而让GPU 着重于单位时间内的任务处理量。实时SAR 成像算法同时满足以上3 个条件。1975 年,英特尔(Intel)创始人Gordon Earle Moore 提出了摩尔定律[16]。1999 年,英伟达(NVIDIA)半导体公司首次提出了GPU 的概念[17]。近20年来,尽管面对诸多挑战,GPU 的发展仍旧突飞猛进,实时SAR 结合GPU 的研究前景辽阔。
算法的选择需要结合实际场景。1991 年,Cafforio 等[18]在处理地震信号时,根据信号时频域和频谱带宽的特点,采用了波数域的算法进行信号分析。目前,SAR 系统逐步微型化[19],可被搭载于无人机。为缓解无人机平台的计算压力[20],FMCW 波形逐步取代了LFM 波[21-22],距离徙动算法(Range Migration Algorithm,RMA)也随之被广泛使用[23]。相比于后向投影算法(Back Projection Algorithm,BPA)算法,RMA 精度相当且计算更快,适合用于无人机载的场景。因此,本文的核心算法选择RMA。
本文通过结合SAR 成像计算特点和GPU 硬件结构及其计算特性,设计出了一种无人机载MiniSAR 实时处理机,并针对该处理机提出了一种多CPU 线程的优化方案,可以在不改变算法原理和硬件结构的条件下缩短15%的计算时间,最后使用FUSAR-Ku 系统进行了实验验证。本文内容组织如下:第1 节介绍了FUSAR-Ku 成像算法原理以及运动补偿原理和GPU 异步系统结构;第2 节介绍了实验方法以及实验结果;第3 节对实验结果进行了总结。
1 FUSAR-Ku 系统与GPU 数据流
实验设备是复旦大学电磁波信息科学教育部重点实验室的FUSAR-Ku 系统[24-25]。综合考虑成像精度、设备性能,FUSAR-Ku 系统的核心算法折中选择RMA。
1.1 成像算法
FUSAR-Ku 系统成像部分是在RMA 基础上进行改进的,RMA 处理流程如图1 所示。RMA 要在波数域进行插值操作,具体步骤为脉冲压缩、二维快速傅里叶变换(Fast Fourier Transform,FFT)、运动补偿、距离徙动校正、方位向脉冲压缩、二维逆傅里叶变换(Inverse Fast Fourier Transform,IFFT)。

图1 RMA 处理流程Fig.1 Processing flow of the RMA
但RMA 的STOLT 插值无法满足无人机平台运动补偿的要求,为此,对其进行改进得到了分段孔径成像(Segment Aperture Imaging,SAI)算法[23]。该算法基于RMA 在波数域实现RCMC 与运动补偿,将原算法分段处理,并且分解为级数相乘的滤波器以完成成像。
1.2 GPU 异构数据流
英伟达公司针对GPU 提出了统一计算设备架构(Compute Unified Device Architecture,CUDA)。CUDA 是由CPU 和GPU 组成 的异构平 台,CPU 为主机端(Host),适合处理逻辑运算,GPU 为设备端(Device),适合处理并行化运算。CPU 和GPU 之间依靠PCIE(Peripheral Component Interconnect Express)总线通信。CUDA 编程的异步执流程如图2 所示,具体流程如下:1)CPU 和GPU 两端分别分配内存;2)将CPU 端的数据拷贝到GPU 端;3)CPU 呼叫核函数,GPU 执行核函数;4)将结果拷贝回CPU 端。在核函数N处理阶段和CPU 处理阶段N+1 之间,可选择同步处理或者异步处理。
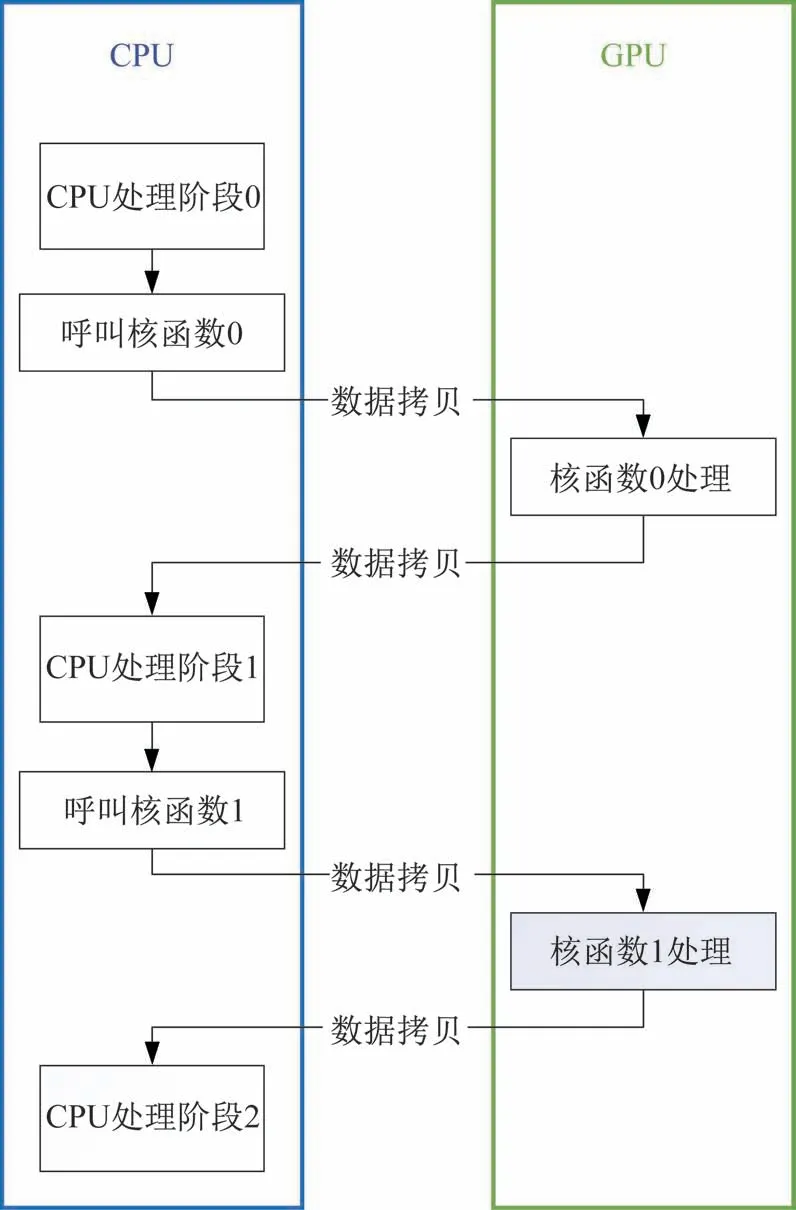
图2 CUDA 异步执行流程Fig.2 Asynchronous execution flow of the CUDA
2 FUSAR-Ku 实时处理机
无人机载SAR 实时成像系统难以在保证其成像质量的同时保证实时性,使得雷达成像的实时性依赖于硬件的性能。为充分发挥GPU 硬件性能,本文根据异步处理时序的特点,在FUSAR-Ku 系统的基础上,设计并优化了FUSAR-Ku 实时处理机。FUSAR-Ku 实时处理机如图3 所示。

图3 FUSAR-Ku 实时处理机Fig.3 FUSAR-Ku real-time processor
2.1 实时处理机硬件框架
FUSAR-Ku 实时处理机硬件内部结构和数据处理流程如图3 所示。DSP 表示数字信号处理器(Digital Signal Processor);DDS 表示直接数字式频率合成器(Direct Digital Synthesizer);SSD 表示固态硬盘(Solid State Disk);SMA 表示SMA 接口(SubMiniature Version A);V 表示垂直方向极化(Vertical);H 表示水平方向极化(Horizontal);DA表示数字信号转模拟信号(Digital-to-Analog);AD表示模拟信号转数字信号(Analog-to-Digital);RF表示射频(Radio Frequency);RTK 表示实时动态差分(Real-Time Kinematic)。MiniSAR 数据采集系统主要由FUSAR-Ku 系统、惯性导航系统和地面全球导航卫星系统(Global Navigation Satellite System,GNSS)基站3 部分构成,其中FUSAR-Ku MiniSAR 参数见表1。

表1 FUSAR-Ku MiniSAR 参数Tab.1 Parameters of the USAR-Ku MiniSAR
无人机载MiniSAR 数据采集场景如图4 所示,它的原始回波数据往往接近TB 级别,难以被实时地传输至地面站,这也是该系统的受限之处。在MiniSAR 数据采集系统上增加信号处理机,即可完成FUSAR-Ku 实时处理机的硬件设计。FUSARKu 实时处理机可将TB 级别的雷达原始回波数据转化为MB 级别的SAR 成像数据,大大降低了地面站实时收取的难度。成像数据被传输到地面站后,设备不易受到质量和尺寸的限制,算力问题得以解决,各种后处理得以实时实现。

图4 条带式SAR 成像模式Fig.4 Imaging mode of the stripmap SAR
无人机载重上限大约7 kg,硬件选择应优先考虑体积小、质量小、计算性能好、功耗低的设备。英伟达Jetson 系列边缘计算机符合体积和质量小的要求。Jetson AGX Xavier 如图5 所示,其功耗范围为10~30 W,相比于Jetson TX2 其计算性能更好,相比于Jetson AGX Orin 其功耗更低,因此被用作为实时处理机核心计算设备。数据流时序的设计需要对Jetson AGX Xavier 的计算能力和算法复杂度进行评估。

图5 Jetson AGX Xavier[26](图片来源:NVIDIA)Fig.5 Jetson AGX Xavier[26](Image source:NVIDIA)
Jetson AGX Xavier 官方参数见表2。硬件的测试结果见表3。由表2 可知,乘、加、减、乘加融合和赋值操作所消耗的时间相近,除法运算所需时间大约为乘法运算的5 倍。乘、加、减和乘加融合皆为一次浮点运算。SAI 算法复杂度见表4。

表2 Jetson AGX Xavier 硬件参数Tab.2 Parameters of the Jetson AGX Xavier

表3 Jetson AGX Xavier 各类单操作平均所需时间Tab.3 Average time required for each operation of the Jetson AGX Xavier
由表4 中可见,浮点运算复杂度可用ANa、Nr表示,A表示浮点运算复杂度的系数,其数值约为1 170。
2.2 实时处理机软件框架
实时单CPU 线程数据流如图6 所示。图中流程分为3 个部分:1)数据准备;2)数据预处理;3)主干计算。

图6 实时成像单CPU 线程数据流Fig.6 Data streams of the real-time imaging on a single CPU
数据准备包括惯性导航系统和雷达主机的数据解包、排序以及存储,该部分由CPU 负责;数据预处理包括数据和接口的匹配,该部分由CPU 负责;主干计算是指SAI 成像处理,该部分由GPU 负责。
在数据预处理之前,CPU 需要耗费较多时间用于文件数据读取和存储,而此时GPU 处于闲置状态,CPU 与GPU 的并行工作效率几乎为零。为降低CPU 数据准备和数据预处理开销,充分提高两者并行效率,可根据CPU 与GPU 异步处理流程,提出一种多CPU 线程的异步优化方案。
多CPU 线程实时成像数据流如图7 所示。当前进程分3 个线程并发执行,采用时间片轮转调度策略。线程0 查询磁盘文件中是否存在与雷达数据相匹配的惯导数据;线程2 通过PCIe 串口解包雷达主机数据;线程1 完成数据预处理,并呼叫GPU 进行成像。为提高系统效率,雷达数据解包后会被暂时存放于内存中的暂存区,暂存区内数据在成像完成后被销毁;为维持内存使用稳定,解包后的惯导数据不停留于内存中,将立即以二进制文件的形式保存于磁盘中以等待数据匹配,数据匹配使用二分查找策略。为保证线程安全,互斥锁被用于临界区数据同步。

图7 实时成像多CPU 线程数据流Fig.7 Data streams of real-time imaging on multiple CPUs
该系统参考多流处理的加速思想,并设置了多个暂存区,当其中一个暂存区内的雷达原始数据被用于成像时,另一个暂存区会加载下一帧所需的雷达原始数据,可掩盖原始数据从磁盘到内存的拷贝延时。惯导系统无法保证时钟与雷达主机完全同步,其数据不能存放于暂存区,只能由其他进程通过以太网口收取数据并存放于磁盘中。
软件所需内存大约为原始数据的5 倍。Jetson设备中的GPU 与CPU 共用一块16 GB 的内存,其中约2 GB 用于保证软件以外的环境运行,因此软件在一个处理周期中最多能处理2.5~3.0 GB 的原始数据。
成像时序会产生一帧图像的时延,如图8 所示。软件在成像启动前会开辟好输入数据、计算中间变量和结果所有所需的内存空间,并在程序终止时进行统一销毁。因此,在“主干计算”的循环阶段,软件不会有任何开辟内存的行为,同时避免了内存泄漏问题。

图8 SAR 成像时序Fig.8 Time sequence of SAR imaging
2.3 实验评估指标
为直观展现出多CPU 线程优化在无人机载MiniSAR 实时成像中的优势,本实验设计了几种实验评估指标。实验评估指标有SAR 单帧加速比αSAR、多CPU 线 程压缩率μmcg、多CPU 线程 开销比例γref、异步计算并行率εhet。μmcg可以显示出,多CPU 线程优化后实时处理机成像时间缩短的时间比例;γref可以显示出,多CPU 线程切换开销占据成像周期的比例;εhet可以显示出,CPU 与GPU 同时工作的时间占据成像周期的比例。
各评估指标如式(1)~式(4)所示。
式中:Tacg为实时处理机完成一帧SAR 成像平均用时;Tasc为单核心CPU 系统完成一帧SAR 成像平均用时。
式中:Tascg为单CPU 线程实时处理机完成一帧SAR成像平均用时;Tamcg为多CPU 线程实时处理机完成一帧SAR 成像平均用时。
式中:Tawait为图7 中线程1 完成一帧SAR 成像等待互斥锁平均用时。
式 中:Tah为GPU 和CPU 在多CPU 线程实时处理机中共同主干计算所花总时间。
2.4 实时成像结果及分析
成像结果如图9 所示,该伪彩图由多通道(HH、VH、HV、VV)SAR 成像结果经过极化定标和极化分解得到,成像区域为复旦大学邯郸校区,图中右侧为校内标志性建筑物光华楼。红色部分表示偶次散射,该散射分量主要由建筑物与地面构成的二面角贡献;绿色部分表示多次散射,主要由地表植被、树林等目标贡献。距离向分辨率为0.08 m,方位向分辨率为0.06 m,行高8 199 个像素(655.92 m),行宽10 047 个像素(602.82 m)。

图9 成像结果Fig.9 Imaging result
与CPU 计算相比较,GPU 成像双精度平均误差约为-70 dB,单精度平均误差约为-30 dB。单精度计算效率高,但大大降低了成像质量。因此,实验均使用双精度进行成像处理。
本研究设计了多组实验对比,以下均为离线双精度成像的实验结果。考虑到GPU 热启动计算效率要比冷启动高,实验只取5 帧SAR 成像后的结果。多CPU 线程实验还考虑了线程块大小、数据量大小的影响。实验结果见表5 与表6。为使线程利用率为100%,表5 中线程块的线程数被设置为32的整数倍,1024 线程/块为Jetson AGX Xavier 的软件上限。

表5 不同线程块实验对比Tab.5 Experimental comparison of different thread block sizes

表6 不同数据量实验对比Tab.6 Experimental comparison of different amounts of data
在表5 中:所有实验中数据Na为12 500,Nr为10 000;μmcg、γref、εhet是多CPU 线程实验组与单CPU线程实验组对照后得到的评估指标,不用于单CPU线程实验组性能评估;各组实验在编译期间并未分配任何本地内存;单CPU 线程与多CPU 线程实验在惯导数据存取、雷达原始数据存取、雷达成像阶段都有16.67%的概率出现1 s 左右的波动,可能与各线程的波动相关,但不会在单线程上累加,成像周期也只存在1 s 左右的波动。
在表6中:所有实验中线程块大小为32 线程/块;实验中各处理阶段会1 s 左右的波动。
根据硬件参数,假设CPU 只使用单核心处理,可得到αSAR的上限为305.182 3,其式如下:
式中:Fg为GPU 最大 核心频率;Ng为GPU 核心 数量;Fc为CPU 最大核心频率;Nc为CPU 核心数量。
如图9所示,成像结果虽存在一定的运动模糊,但建筑物、道路、植被的轮廓依然清晰,符合成像要求。GPU 双精度计算得到的成像结果误差为-70 dB。可见,其成像质量与CPU 双精度计算基本无异。因此,GPU 代替CPU 承担SAR 成像计算是完全可靠的。
多CPU 线程实时处理机线程块大小的对比实验结果见表5。从μmcg和εhet的实验结果中可以看到,多CPU 线程优化可在GPU 并行加速的基础上掩盖磁盘文件的存取开销,提高CPU 与GPU 之间的异步并行效率,将处理机整体性能提升了15%。纵观不同线程块实验,各组实验未使用本地内存,且线程块大小为32 线程/块时,成像效率最高;线程块大小大于256 线程/块时,成像效率也会有略微提升。线程块为32 线程/块时,成像算法Warp 活跃度较高,虽然块中线程少,但是Warp 切换次数较少,单线程占有的资源较多,所以成像效率更高;线程块增大到256 线程/块时,任务调度的开销减轻,所以成像效率会有略微提升。因为存取缓存机制不稳定,各处理阶段存在1 s 的波动。在运算资源方面,实验表明,系统在连续处理100 帧成像数据时,并未发生实时内存占用增大的现象,表明该系统有效解决了内存泄漏问题。
表6 展示了多CPU 线程实时处理机不同数据量的对比实验结果。分析可知,处理机在处理小数据量时αSAR最高可达到33.345 9,符合式(5)加速比最大理论。随着Nr数值的增加,αSAR会呈现下降趋势,数据量增大时,下降速度会减慢,而Na数值增加时并不会出现这种状况。αSAR随Nr减小是因为插值中的二分查找和累加使Nr方向的数据局部性降低,且处理逻辑分支增多;数据量越大,下降速度越慢,这是因为小数据量的并行计算成分较低,计算效率主要受数据准备和数据预处理的影响。在处理机中,成像开销最大,其次是雷达原始数据的存取,多CPU 线程实时处理机的效率提升主要得益于雷达原始数据存取的隐藏。如果多CPU 线程实时处理机的工作效率与单CPU 线程相同,εhet的值将与μmcg相近。实验结果显示,小数据量受到1 s 波动的影响,不易看出εhet与μmcg之间的关系,但当数据为Na为12 500,Nr为10 000 时,εhet大约为μmcg的2倍,多CPU 实验中雷达存取开销要比单CPU 线程实验大整整一倍。说明各线程竞争CPU 计算资源,工作分时段进行,符合时间片轮转调度策略特点,进一步证明了多CPU 线程实时处理机未使用CPU多物理核心进行计算。
3 结束语
本文提出了一种FUSAR-Ku 实时处理机的多CPU 线程优化方案。该方案解决了实时成像中的内存泄漏问题,确保了成像稳定性。在实时处理机中,GPU 的成像效率是CPU 成像效率的12 倍左右,使用该方案后,成像效率还可以继续提升15%。由此可见,GPU 异构系统相比于单核CPU 系统具有更大的优势。在此基础上,实时处理机的多CPU 线程工作模式相较于单CPU 线程工作模式也有着明显优势。本文还详细介绍了该项工作的硬件框架和软件框架。硬件部分介绍了核心雷达主机的内部结构,测试分析了核心计算设备NVIDIA Jetson AGX Xavier 的性能;软件部分分析了系统数据流,提供了一种提高CPU 与GPU 并行效率的方案。为后续实时处理机的开发奠定了基础,GPU 与SAR相结合的前景依旧广阔。由GPU 理论最大加速比可知,处理机的加速性能还有着一定的提升空间。未来的工作不仅会着重于实时处理机系统的开发,也会在GPU 算法层面继续研究。
