CPU-GPU 协同高性能卫星数传预处理方法
2023-09-06张鑫宇杨甲森陈志敏
张鑫宇,杨甲森,徐 聪,陈志敏,智 佳,陈 托
(1.中国科学院国家空间科学中心,北京 100190;2.中国科学院大学 计算机科学与技术学院,北京 100049)
0 引言
数传预处理是地面应用系统生产数据产品、获取探测成果的前提和基础[1],其处理内容包括传输帧同步、帧校验、分虚拟信道、源包同步、分应用过程、工程遥测参数提取与物理量转换、科学数据解压缩等。高分辨率、高灵敏度、多频段覆盖的载荷探测趋势下,Gbps 级数传预处理需求日益迫切。
我国航天器数传大多采用的空间数据系统咨询委员会(Consultative Committee for Space Data Systems,CCSDS)相关协议具有典型的分层特征[2],层间数据相互依赖,层内不同虚拟信道、应用过程数据相对独立。因此,目前国内外学者大多采用中央处理器(Central Processing Unit,CPU)单机、集群等同构平台,以虚拟信道、应用过程为任务划分依据,并行提高处理性能。包括基于消息传递接口(Message-Passing Interface,MPI)[3]、基于MPI+OpenMP[4]在分布式集群上实现卫星遥感数据处理;基于Storm 流式计算框架实现遥感卫星快视处理[5]、空间科学卫星数据处理[6-7]。CPU 适用于处理复杂控制逻辑、较小数据规模问题[8],限制了上述方法部分处理步骤性能提升。图形处理器(Graphics Processing Unit,GPU)以 其TFLOPS 量级的计算能力,在信号处理[9-10]、译码[11-12]、遥感图像处理[13-18]、卫星轨道计算[19-20]等并行程度较大的数据密集型领域应用中取得了良好的加速效果。
本文面向高性能数传预处理需求,在分析处理性能瓶颈的基础上,针对预处理步骤层间依赖、各虚拟信道保序并行的特点,提出一种层间流程CPU控制、层内瓶颈步骤GPU 加速的协同处理新方法。对数传数据预处理的CPU-GPU 协同任务划分、GPU 线程分配进行设计,实现基于GPU 的帧校验、工程参数提取与物理量转换的加速,为数传预处理性能的提升提供一种新的解决途径。
1 数传数据预处理分析
1.1 数传预处理内容说明
如图1 所示,在地面接收分系统完成译码后,数传预处理完成高级在轨系统(Advanced Orbiting Systems,AOS)帧处理、源包处理,将结果分发至后续环节。涉及到CCSDS 协议包括空间包协议[21]、AOS 空间数据链路协议[22]、遥测同步和信道编码协议[23]等,其中AOS 传输帧、空间包结构见表1和表2。

表1 AOS 传输帧格式Tab.1 AOS transfer frame format

表2 空间包结构Tab.2 Structural components of the space packet
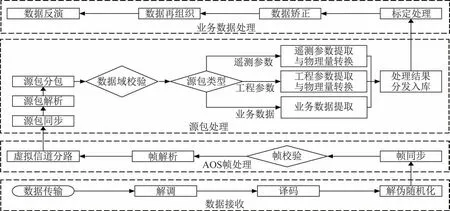
图1 地面端数据处理的一般过程Fig.1 General process of ground data processing
1.2 性能处理瓶颈及可并行性分析
利用文件回放模拟数据输入,测试CPU 单线程模式下预处理各操作速率见表3。
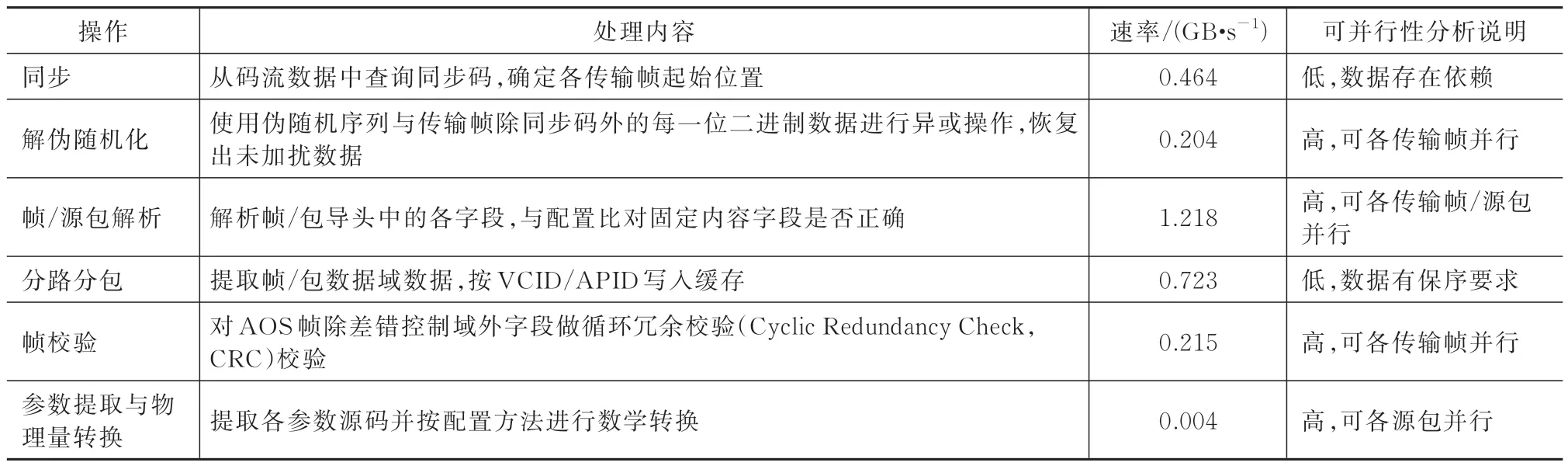
表3 CPU 单线程热点测试Tab.3 Hotpot test of the CPU single-threaded program
其中帧校验和参数提取与物理量转换计算量大,是处理瓶颈且可并行性高,作为本文主要研究对象。
基于CCSDS 协议的分层模型和多路复用机制,预处理过程中数据结构变化如图2 所示。处理存在如下特点:
1)分层模型使各层数据的处理可任务并行;
2)上层协议数据处理依赖下层输出,不同层级数据间存在关联;
3)多路复用机制使同一物理信道中分属不同虚拟信道数据帧间、同一虚拟信道分属不同应用过程的源包间无依赖关系,可完全并行;
4)存在保序约束,须保持各虚拟信道、各应用过程内数据的顺序,发挥计数字段检测数据丢失、重复、失序的作用,可保证源包及应用过程数据正确拼接。
2 CPU-GPU协同数传数据预处理方法
依据预处理步骤层间依赖、各虚拟信道保序并行的特点,设计AOS 帧、源包处理步骤的CPU、GPU任务分划,并基于GPU 统一计算设备架构(Compute Unified Device Architecture,CUDA),实现帧校验、工程参数提取与物理量转换步骤的加速。
2.1 CPU-GPU 协同任务划分
GPU 含有上千个CUDA 核心,一次可支持几万个线程并发。GPU 的寄存器带宽为TB·s-1量级,远高于GB·s-1量级的GPU 显存带宽。CPU 与GPU间传输数据的高速串行计算机扩展总线(Peripheral Component Interconnect Express,PCIe)带宽远又小于GPU 显存带宽。因此使用GPU 获得良好加速效果,CPU、GPU 任务分划要遵循以下原则[24]:
1)增大核函数并行规模,避免核心空闲;
2)提高GPU 中核函数算数强度,降低GPU 内存读写占比;
3)降低CPU-GPU 间数据传输量。
2.1.1 AOS 帧处理流程设计
分路分包前码速率较高,而帧校验又为计算量较大的瓶颈步骤;各AOS 帧独立校验,帧间无依赖关系;高码速率同时降低了等待数据积累到较大规模供GPU 处理的时延,基于上述考虑,如图3 所示,设计GPU 加速帧校验与解析。使用CPU 对解扰后的码流数据同步,得到AOS 帧写入帧缓存,经过PCIe 总线传输至GPU 全局内存。GPU 处理完毕后不再向CPU 端传回完整AOS 帧,而是传回8 bit/帧的后续处理必须信息,数据传输量降低99.1%。传回信息包括:帧格式符合性、VCID、虚拟信道帧计数、数据域有效数据结束地址。CPU 端异常帧报警器在检测到帧格式不符合时,重新解析该帧,生成异常帧报告;帧数据域提取处理器提取数据,按VCID 写入各源包码流数据环形队列存储器,同步处理后得到源包(空间包)。
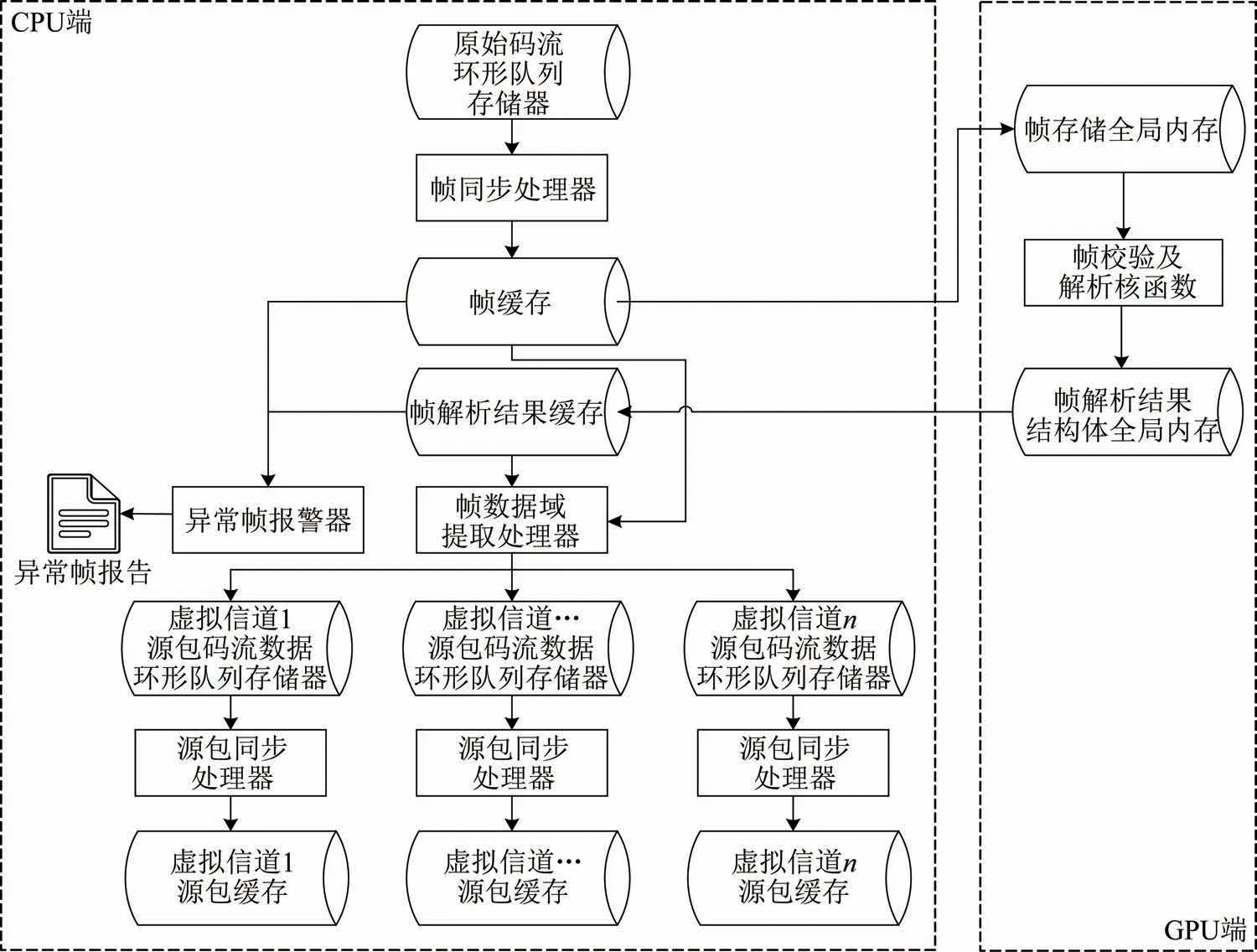
图3 CPU-GPU 协同的AOS 帧处理流程Fig.3 Processing flow of AOS frame parsing based on the CPU-GPU collaboration
2.1.2 源包处理流程设计
源包按装载的数据类型,可分为业务数据源包、遥测参数源包、工程参数源包。空间科学卫星的科学数据、遥感卫星的图像数据等业务数据,数据量大、处理方法复杂、不同业务处理差异大。遥测数据是与航天器工作状态有关的测量数据(如电压、电流、温度、压力等),反映航天器的工作过程、工作结果和健康状态[25],实时性要求高,数据量较小。工程参数主要是有效载荷的工作状态数据,相比遥测参数,种类更多、数据量更大。
根据不同类型的源包特点,设计源包处理任务流程如图4 所示。CPU 解析源包后生成异常源包报告,根据APID 将格式符合的源包写入相应的环形队列存储器。业务数据在预处理阶段只做拼接处理,由CPU 完成。参数配置信息处理器读取含有参数位置、源数据长度、物理量转换方法的配置文件,计算掩码,在程序启动时向GPU 全局内存传输一次。遥测参数数据量较小,为降低时延,由CPU完成提取与物理量转换。工程参数由GPU 完成提取与物理量转换。
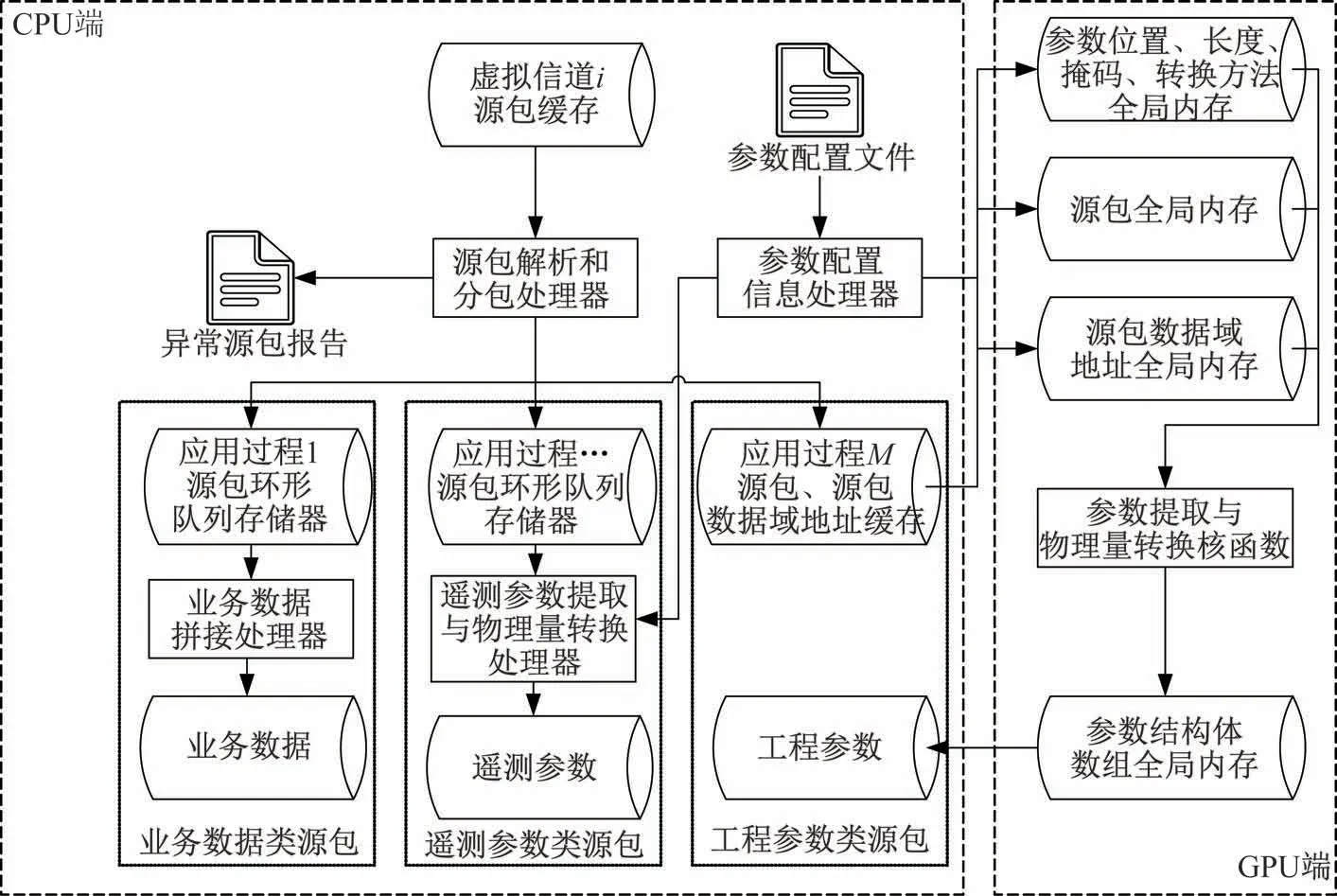
图4 CPU-GPU 协同的源包处理流程Fig.4 Processing flow of space packet parsing based on the CPU-GPU collaboration
2.2 基于GPU 的并行加速实现
2.2.1 帧校验的CUDA 加速
AOS 协议的差错控制使用生成多项式为C(x)=x16+x12+x5+1 的CRC 校 验,CRC 校 验的基本思想是接收端的数据无误码则能被给定的生成多项式C(x)整除。CRC 校验以帧为基本单位,各帧之间不影响,设计每个GPU 线程校验一帧。从主机端缓存每次读取N个长度均为L字节的AOS 帧至GPU 全局内存中线性存储。将网格内的线程块和线程块内的线程均组织成一维,线程块数量为Nb;每个网格中线程数量Ng为
每个线程在核函数中的唯一身份标识idx为
式 中:Tx∈[0,Db-1]为各线程在其线程块中的索引。
第idx个线程处理第i个传输帧,该帧的数据在全局内存地址为:[idx⋅L,(idx+1)⋅L-1],每个线程完成校验后,解析帧主导头各字段,提取所需信息写入帧解析结果结构体。所有线程计算完毕,使用cudaMemcpy()函数将帧解析结果结构体数组传输至CPU 端内存。
2.2.2 工程参数提取与物理量转换的CUDA 加速
参数在源包中以二进制信号形式存在,需要将参数提取、编码、转换后,才能直观地用于载荷状态监视、参数判读等任务,可分为以下3 个步骤:
步骤一参数提取。提取源包数据域码流中各参数的二进制信号源码。
参数位置由参数开始的字节地址Ab、开始字节的位地址Ab、比特长度Lb唯一确定。某参数在源包中所占字节长度Lb为
将帧中第Ab至Ab+Lb-1 字节数据与位掩码做按位与运算并位移后得到参数源码。
步骤二参数编码。将各参数的二进制信号源码编码为实际数字或字符串。
步骤三物理量转换。参数经某种方法的运算后,转换为直观表达真实物理含义的值。常用的物理量转换方法有源码显示、进制转换、含义映射、多项式变换、热敏电阻分压值转换为温度等。
从CPU 端缓存每次读取特定种类长度为L字节,含M个参数的工程参数源包N个,每个参数的处理结果使用R字节保存。将网格内的线程块和线程块内的线程均组织成一维,线程块数量为Nb。设计了每个线程处理一个参数、每个线程处理一个源包2 种线程分配方案,通过实验分析2 种方案的特性。
方案一每个线程处理一个参数。
每个网格中x方向线程数量Ng为
第idx个线程处理第个源包的第(idx%M)个参数,将结果写入GPU 全局内存,内存地址为[idx*R,(idx+1)*R-1]。
方案二每个线程处理一个源包。
每个网格中x方向线程数量Ng计算方法与公式(1)相同,第idx个线程处理第idx个源包的所有参数,将结果写入GPU 全局内存,内存地址为[idx*M*R,(idx+1)*M*R-1]。
2.2.3 基于CUDA 流并发执行核函数和数据传输
CUDA 流是从主机发出在GPU 中执行的一系列异步CUDA 操作,不同CUDA 流中的操作可能并发或交错执行[14]。由于数据传输、计算分别通过GPU 的读写单元和流处理器进行,如图5 所示,主机向一个流发出数据传输命令后可立即获得控制权,到另一个流调用核函数,从而重叠数据传输与核函数执行[15]。在CUDA 操作完全并行执行的理想情况下,数据传输时间可完全隐藏,随着流数量增加,加速比趋近3。

图5 CUDA 流并发示意Fig.5 CUDA stream concurrency
CUDA 流实现异步数据传输,需要在程序运行期间将主机端数据缓存定义为不可分页内存,保持内存物理地址不变。设创建NS个CUDA 流,将每次从缓存中读取的N个AOS 帧或源包划分NS个子集,平均分配到各个流中,使用cudaMemcpyAsync()函数异步传输数据,使用循环调度各个流的数据传输和计算。
3 实验验证与分析
3.1 实验环境
CPU 使用AMD Ryzen 5 2600X,基频3.6 GHz。GPU 使用NVIDIA GeForce RTX 2080ti,显卡为 图灵架构,有68 个流多处理器,4 352 个CUDA 核心,11 GB GDDR6 显存,显存带宽616 GB·s-1,单精度浮点数运算峰值13TFLOPS,CUDA 版本10.1。CPU 与GPU 之间使用PCIe3.0 x16 总线连接,理 论带宽15.754 GB·s-1。内存使用48GB DDR4 双通道内存。硬盘使用512 GB NVMe 固态硬盘。
由于不同型号CPU 物理核心数的差距,实践中评价加速效果常使用CPU 单核与GPU 比较[9]。
3.2 帧校验实验结果与分析
传输帧帧长898 字节,前4 字节为同步码,帧差错控制域2 字节。Nb设为256。如图6 所示,使用单个CUDA 流,一次处理215个帧时达到最高处理速 率8.053 6 GB·s-1,加速比38.003;使 用16 个CUDA 流,一次处理219个帧时达到最高处理速率11.449 6 GB·s-1,加速比53.866。CPU 单线程方式,最高处理速率0.214 7 GB·s-1,串行计算性能基本与帧数量无关。

图6 速率随AOS 帧个数的变化-CRCFig.6 Variation of the processing speed with the AOS frame number-CRC
如图7 所示,一次处理的帧数量少时,GPU 没有满负荷工作,有空闲的计算资源,增加一次处理的帧数量,GPU 核函数耗时基本不变;当一次处理的帧个数较大时,GPU 满负荷工作,GPU 核函数的耗时正比于一次处理的帧个数。可根据不同GPU性能,配置单次计算规模,达到最佳性能。

图7 GPU 核函数计算与数据传输耗时-CRCFig.7 Time of the kernel function and data transmission by GPU-CRC
3.3 工程参数提取与物理量转换实验结果与分析
工程参数源包包长390 字节,含467 个参数,每个参数转换结果8 字节保存。Nb设为256。如图8所 示,CPU 最高速 率0.004 4 GB·s-1。使用单 个CUDA 流,最高速率0.506 GB·s-1,加速比115.98;使用16 个CUDA 流,最高速率可达0.902 4 GB·s-1,加速比211.021。
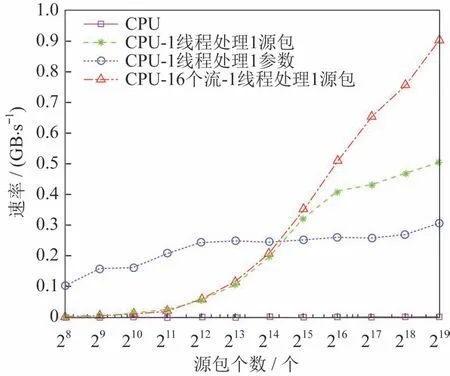
图8 速率随源包个数的变化Fig.8 Variation of the processing speed with the packet number
如图9 和图10 所示,一次处理的源包个数小于215时,每个线程处理一个源包的方案并行规模较小,速率比每个线程处理一个参数的方案低;源包个数大于215时,两方案均能使GPU 满负荷工作,每个线程处理一个源包的算数强度更大,速率更高。在实际应用中,可根据数据的时延性要求,配置一次处理的源包个数,进而确定线程分配方案。

图10 GPU 核函数计算与数据传输耗时-1 线程处理1 参数Fig.10 Time of the kernel function and data transmission by GPU-1 parameter for 1 thread
4 结束语
数传数据预处理是卫星数据处理的前置必须环节,本文提出的CPU-GPU 协同的卫星数传数据预处理方法,利用GPU 并行计算加速处理过程的帧校验、参数提取与物理量转换等耗时瓶颈步骤,实验结果表明,该方法可满足Gbps 的卫星数传数据预处理需求。后续可开展的工作如下。
1)增加处理深度,引入基于GPU 的数据解压缩、科学数据快视、数据判读,进一步加速数据处理过程。
2)研究适用于数传数据处理的多CPU、多GPU 场景中有硬件和任务优先级约束下的多目标优化调度算法。
