基于多模型融合Stacking 集成学习保险欺诈预测
2023-09-05缪智伟韦才敏
缪智伟,韦才敏
(汕头大学数学系,广东 汕头 515063)
0 引 言
顾客购买保险产品的最终目的是通过转移风险来增强自身面对未来不确定事件的能力.现今,我国大部分公民都具有通过购买保险来防范未来不确定事件风险的意识,比如我们看病会用医疗险,在购买车之后往往会投保车险等.这些在我们真正遇到相应事故的时候,都可以帮助我们将风险转嫁给保险公司,降低自身的经济压力,是一种很好的提前预防的保险方式.任何一种从大众中筹集的巨额资金,然后通过一定的规则重新分配到部分人的金融机制,在这个过程很容易出现信用、道德危机.保险也不例外.
保险欺诈行为识别面临较大挑战.传统保险公司主要依靠内部定性判别方式和专家的经验判断进行保险欺诈行为的识别.但是由于保险欺诈手段多样化、数据量大且复杂等原因,如果单靠以往传统的保险欺诈识别方法进行识别,不仅难以精准地识别出骗保行为,而且还会产生大量的人工成本.
现今,在精准识别保险欺诈行为的问题上,许多保险公司通过搜集、整理被保人的个人信息以及理赔事故信息,形成一套属于自己公司的数据库,并且聘请高级数据工程师来构建属于自己公司的保险骗保行为的检测系统.虽然使用大数据手段进行保险欺诈行为的识别,可以提高检测的准确性和效率,但是也面临一些问题.首先是数据不平衡:保险欺诈行为在数据中的比例相对较小,这导致了数据的不平衡.因此,在训练深度学习模型时,需要采取一些措施来平衡数据,以避免模型对少数类别的识别性能下降.其次,可解释性:深度学习模型通常被视为黑盒模型,难以解释其预测结果的原因.在保险欺诈行为的识别中,可解释性是非常重要的,因为保险公司需要知道模型是如何判断被保人是否存在欺诈行为的,以便更好地制定反欺诈策略.最后是,模型选择和优化:在深度学习中,模型的选择和优化是关键,但是不同的模型需要不同的参数设置和训练方式,需要耗费大量的时间和计算资源.
因此,针对以上保险欺诈识别系统的不足,本文提出基于XGBoost 与LightGBM的Stacking 模型融合集成学习模型.文章第一部分对LightGBM、XGBoost 进行算法机理的介绍与推导,第二部分将详细描述基于多模型融合Stacking 集成学习方式的保险欺诈识别模型的原理和构建方法,第三部分用阿里云天池保险欺诈行为数据集对构建的模型进行实证检验,第四部分是结论.
XGBoost 和LightGBM 都是目前应用较为广泛的集成学习算法,它们的主要特点是具有高效性、准确性和可扩展性.这些特性使得它们在数据挖掘、预测分析、自然语言处理、图像识别等领域得到广泛应用.
本文选择了基于XGBoost 与LightGBM 的Stacking 模型融合集成学习模型,主要是因为这两个模型具有以下特点:1.XGBoost 和LightGBM 是当前最流行和最优秀的梯度提升树模型,能够高效地处理大规模的高维数据,并具有很好的预测性能. 2. 在Stacking 模型融合中,XGBoost 和LightGBM 作为基础模型可以很好地利用其优点,如高准确性、良好的鲁棒性、高效性等,同时通过融合可以进一步提高模型的预测性能.3.XGBoost 和LightGBM 模型都具有很好的可解释性和可视化性,能够帮助分析人员更好地理解模型的预测结果和特征重要性.
1 算法理论介绍
1.1 LightGBM 算法机理
LightGBM(Light Gradient Boosting Machine)是一种以高效率的并行训练计算的方式实现GBDT 算法,总结其优点:训练的速度比初始训练框架要快,占用的内存空间更小,获得更高的精确度,可以以较快的速度处理海量的数据.
GBDT 二元分类算法基本步骤:
对于二元分类GBDT,如果用类似于Logistic 回归的对数损失函数,则损失函数为:
其中y∈{-1,+1}.则此时的负梯度误差为
对于新生成的决策树,计算各个叶子节点处的最优残差拟合值为
由于上述方程比较难进行计算,一般我们采用近似值来代替
1.2 XGBoost 算法机理
XGBoost 的Gradient Boosting 方法是通过对损失函数、正则化处理、切分点搜索和并行化结构设计等进行改进,从而加快了模型的训练计算速度.举例,在传统的GBDT算法实现的时候,模型在训练计算第n 棵决策树的时候需要使用到前面n-1 棵树的残值计算值,这一步骤需要较大的算力和内存空间,从而导致面对海量数据的时候,该算法难以实现并行.而XGBoost 通过将求解的目标函数进行二阶泰勒展开,这样模型在计算求解的时候每一个数据点上的损失函数只需要计算出一阶导和二阶导,进而可以提高算法并行的速率.
与传统GBDT 相比,XGBoost 算法在推导中以一种新的方式进行构造新树.这里主要介绍XGBoost 构造新树的方法.将ft和Ω 的表达式带入近似求解的目标函数中,忽略与ft无关的常量,可以得到:
最后一式中的Gj和Hj定义为:
因为求解目标函数可以看做一个是关于N 个相互独立的变量ωj的二次目标函数,可以直接通过计算求解得到极小值点:
然后将极小值点带入到目标函数,求解出目标函数值.
紧接着,开始构造新树的结构.上面式子中Obj*表示当我们确定了一颗树的时候,可以在其目标函数上确定最多可以减去多少值,因子我们可以把它们叫做树的结构得分.Obj*越小说明新树的结构就越好,然后应用贪心算法列举出不同的新树结构,筛选出结构得数最小的树.
在每一次进行计算的时候,都要对已有新树的叶子引入分割计算,都要通过下面的计算式子.
采用分割计算并不会影响目标函数的值,因为在对新的叶子进行分割计算的时候,会对新的叶子进行一定惩罚,这个操作可以对树的减枝进行优化.若引入分割计算所产生的增益效果小于一个给定的阈值时,我们可以去除掉这个分割.通过这样的方式就可以重新确定了新树的结构.
2 基于多模型融合Stacking 集成学习方式的保险欺诈识别模型
2.1 基于Stacking 的集成学习原理
Stacking 是近几年在人工智能领域比较流行的集成学习的框架.通常,Stacking 的大框架是一个多层嵌套的模型,第一层我们可以称做特征学习层,里面包含了n 个不同类型的模型,可以是支持向量机、多元回归模型、神经网络等,将不同模型预测结果整理合并成一个新的特征集,并作为最后一层模型输入,最后一层模型再根据所给的数据标签,进行训练计算,这样就得到一个基础Stacking 集成学习框架.[16-17]
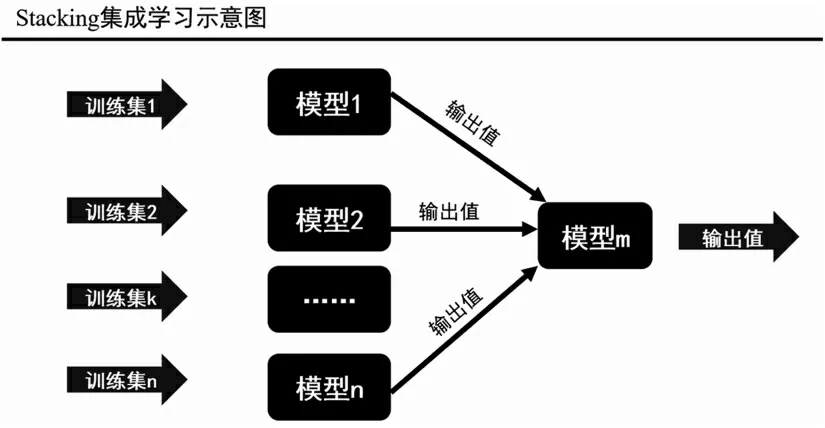
图1 Stacking 集成学习示意图
为使训练出来的新的特征集充分代表原始训练数据的特征,我们会在第一层的模型里面采用拟合度较高的训练模型,例如XGBoost、神经网络、SVM 等.值得注意的是,第一层的模型框架里面涵盖了许多不同模型,不同模型计算原理有所差别,第一层模型的主要目的是自动有效地提取出原始数据的非线性变化的特征,但是这样很容易出现过拟合的问题.
因此,为了更好地解决过拟合的问题,我们通常会在第二层使用一些比较简单的预测模型.如果第二层模型在使用复杂的神经网络训练模型,极大概率会加大预测结果出现过拟合的嫌疑.
从上述的分析可以得出,一个优秀的Stacking 预测模型的关键在于第一层的训练模型是否能够有效地提取出原始数据之间的非线性变化的关系,然后在通过最后一层的简单学习,能够在第一层的基础上,结合简单模型结构,使得模型在预测的时候具有一定的泛化能力和准确率.
2.2 从传统的Stacking 到改进的Stacking
2.2.1 传统的Stacking
首先,如图2 所示,是一个传统的Stacking 集成学习模型结构示意图.图中,第一次模型结构中分别使用不同类型的预测模型去训练同一批次的训练集数据,这样做可以有助于模型能够利用不同基础学习器的优点然后去训练出不同特征之间的非线性关系,得到具有代表性的新生成的特征值.其次,再通过第二层模型结构中简单的预测模型——逻辑回归,训练预测得到最终的预测值.

图2 传统Stacking 集成学习示意图
2.2.2 改进的Stacking
本文使用的是一种改进的集成学习框架,如图3 所示,框架的第一层不仅使用不同的模型,还使用有差异的训练数据,这进一步增大了模型输出值之间的差异性(相关性低),这样的差异性往往适用于训练数据和预测数据不是同分布的领域,可以增强预测的稳定性.

图3 改进Stacking 集成学习示意图
并且我们将第一层Stacking 生成的新的特征和原有的特征进行合并作为第二层的输入,这样做可以有效地防止出现过拟合.在第二层框架中选择采用多种分类预测算法,包括逻辑回归、K 近邻、高斯贝叶斯、决策树、集成学习分类模型,其中集成学习分类模型有随机森林、Bagging、LightGBM、XGBoost.
2.2.3 改进Stacking 模型的构建过程
下面举例进一步说明:
1)首先将数据集划分为训练集和测试集两组数据,并将训练集随机分成5 份train1到train5 这五个部分.
2)选定基础学习模型.本文示例中选择了XGBoost,LightGBM,随机森林作为基础学习模型.以随机森林解释例子,依次选用划分后5 份训练集中的四份作为训练集,然后使用5 折交叉验证的方法进行模型训练,最后在测试集上进行预测结果. 这样会得到在训练集上由随机森林模型训练出来的5 份预测结果和在测试集上的1 份预测值B1,然后将5 份预测结果纵向重叠拼接成新的A1 特征.LightGBM 模型和随机森林模型部分也采用相同的方法进行模型预测,生成新的预测特征.如图4 所示.
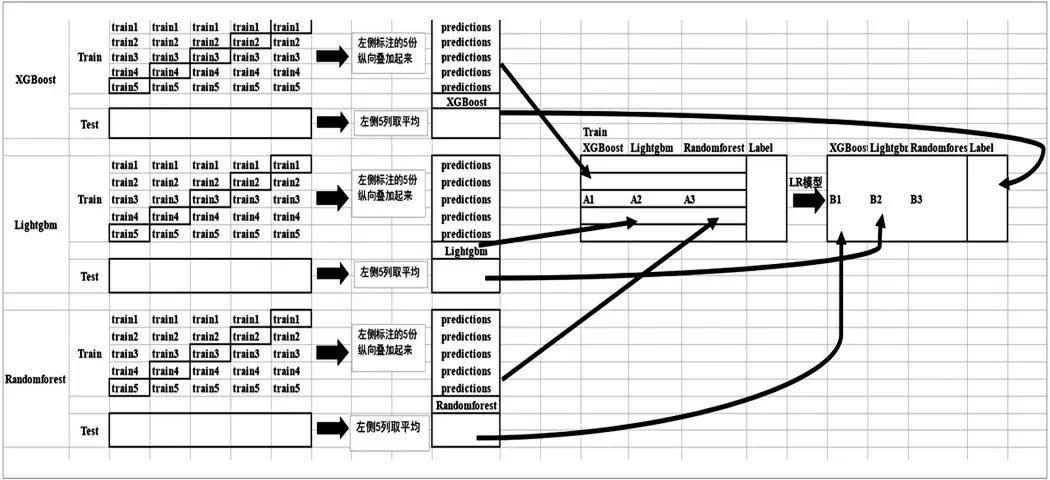
图4 改进Stacking 集成学习模型构建示意图
3)在三个基础模型训练完毕后,将其在训练集上的预测值分别作为3 个“特征”A1,A2,A3,然后使用LR 模型进行训练并建立LR 模型.
4)利用训练好的Logistic 分类模型来预测测试集,在模型的第一部分的三个基础学习模型上会生成新的三个特征,Logistic 在进行预测的时候通过利用新生成的三个特征以及原始数据的特征,通过训练得出分类预测结果.
5)在做Stacking 的过程中,如果将第一层模型的预测值和原始特征合并加入第二层模型的训练中,则可以使模型的效果更好,还可以防止模型的过拟合嫌疑.
3 算例验证与分析
3.1 算例数据
为验证本文所构建模型的科学性和可靠性,本文实验使用基于阿里云天池保险反欺诈公开信息作为数据集.数据集中标签——是否存在欺诈行为(fraud),若该被保人的理赔事件存在欺诈行为取1,否则取0.
本文的特征工程包括以下三类(共43 个特征,仅列出部分重要特征,见表1):项目基本信息包括年龄、每年的保费、保险责任上限.被保人基本信息包括被保人学历、被保人职业、被保人兴趣爱好、资本收益、资本损失.被保人理赔事故基本信息包括碰撞类型、出险类型、目击证人、是否有警察记录的报告、整体索赔金额等.

表1 特征工程汇总
3.2 评价指标
查准率(precision):模型对保险事件的信息进行预测,预测结果中存在保险欺诈行为的样本有N 个,样本中真实存在保险欺诈行为的样本有M 个,即precision=M/N.
3.3 Stacking 模型融合
3.3.1 基于遗传算法的模型融合参数优化
以XGBoost 模型为例,此处使用遗传算法,在有限的数值空间内搜索最优的学习率ε 与树的最大深度Z 参数使训练得到的模型具有较强的泛化能力和准确率.
3.3.2 预测结果对比分析
本节对比所提方法与传统机器学习模型及其模型融合系统的预测性能.首先,测试单一分类预测模型,包括逻辑回归、高斯贝叶斯、决策树、集成学习分类模型,其中集成学习分类模型有Bagging、LightGBM、XGBoost. 其次,分别设置两组,一组是XGBoost 算法与LightGBM,另一组是随机森林与支持向量机,两组进行Stacking 模型融合生成新的两个特征,新生成的两个特征和原有的40 个特征合并作为第二层Stacking训练模型的输入,在Stacking 的第二层中选择使用多种分类学习模型,包括Bagging、LightGBM、XGBoost 等,以检验改进的Stacking 模型融合方法的预测性能.各模型的参数均由遗传算法优化得到.最终预测结果如表2 所示.

表2 预测结果对比 %
根据表2 的预测结果可得如下结论.
(1)总体而言,基于XGBoost 模型与LightGBM 的Stacking 模型融合预测精度高于未进行模型融合的预测精度.主要是因为XGBoost 和LightGBM 在第一层的模型中有效地提取了保险欺诈数据集中不同特征之间的非线性关系,然后再通过最后一层简单模型训练,使得集成学习器的错误率呈指数级下降,最终趋于零.通过融合可以达到“取长补短”的效果,综合个体学习器的优势是能降低预测误差、优化整体模型性能. 而且,如果单个基学习器对非线性关系的捕捉、预测的精度越高、模型的多样性越大,Stacking 模型融合预测效果就会越好.
(2)单一模型预测结果里面XGBoost 的准确率最高,其次是GBDT. 结合前文XGBoost 的推导内容,可以知道传统GBDT 在优化时只计算了损失函数的一阶导数,而XGBoost 通过将求解的目标函数进行二阶泰勒展开,这样模型在计算求解的时候每一个数据点上的损失函数只需要计算出一阶导和二阶导,进而可以提高算法并行的速率.为了更好地降低模型预测结果的方差和控制模型的复杂程度,XGBoost 在损失函数里加入了正则项.正则项降低了模型预测结果的方差,使训练得出的模型更加简单,能很好地防止过拟合,这也是XGBoost优于传统GBDT 的一个特性.
(3)通过对比有无模型融合预测准确率,可以发现在Stacking 的第二层模型训练中使用决策树分类器的准确率是最高的,其次是XGBoost,并且也可以得出不同基础分类器,得到预测准确率有明显的差异.
(4)通过对比XGBoost 算法与LightGBM、随机森林与支持向量机两组实验结果,可以发现,XGBoost 算法与LightGBM 大部分的实验具有较高的预测准确率,这说明了在Stacking 模型第一层中使用XGBoost 算法与LightGBM 可以很好提取数据特征的非线性关系,进而提高模型的预测性能.相比之下,支持向量机和随机森林也是常用的分类算法,但相对于XGBoost 和LightGBM,在处理大规模数据和非线性问题时可能会存在一些瓶颈,对于参数调节和特征处理等方面的要求也更高一些.同时,XGBoost 和LightGBM 都是基于梯度提升的算法,能够自适应地学习到数据中的复杂关系,相对于支持向量机和随机森林更具有优势.
3.4 特征重要性
特征重要性(Feature Importance)的核心思想是计算依据某个特征进行决策树分裂时分裂前后的信息增益,信息增益越大,该特征越重要.通过计算出模型中特征的重要性可以直观得出具体哪一个特征对于预测结果具有较大的影响力,可以从定量的角度去解释机器学习的预测结果.下面打印出最高准确率的Stacking 模型的特征重要性,其模型结构为在第一层模型中使用XGBoost 模型与LightGBM 来预测新特征,然后在第二层中采用决策树分类器.如图5.

图5 最优Staking 集成学习模型特征重要性
观察图3,可以知道Stacking 模型融合下,被保人的职业、发生保险事故的城市、发生保险事故的地区、资本收益、资本亏损是比较重要的分类特征.根据此结果,本文向保险行业建议在对被保人保险欺诈行为核查的时候重点关注这些重要的特征,并且通过海量的大数据挖掘出保险欺诈行为在这些特征的潜在规律.
4 结语
保险行业中,被保人通过欺诈进行骗保,不仅对保险行业造成巨大损失,更会制约我国保险业的发展.长期来看,如果我国能够构建一个信息可信度高、数据库范围广、信息层次更丰富的征信体系,这将会为我国的保险行业提供一个更加有保障、有活力的生态空间.短期而言,最有效的方法是保险公司基于海量的用户数据,构建识别准确、性能稳定的保险欺诈行为识别模型.本文结合人工智能的前沿理论研究,提出一种基于改进XGBoost 与LightGBM 模型融合的Stacking 集成学习方式的保险欺诈行为预测模型,对保险公司被保人保险欺诈行为的识别具有启示意义,有助于保险公司更好地识别被保人的骗保行为,强化自身风控体系.经过对阿里云天池挑战赛公开的保险欺诈数据集的验证与测试,结果表明,相比传统机器分类模型,本文提出的基于XGBoost 与LightGBM 模型融合的Stacking 集成学习模型在欺诈行为识别方面具有更高的预测性能与准确性,这得益于本文所提出的特征工程和模型融合方法,以及使用多种分类学习模型进行训练和参数优化的策略.同时,本研究通过计算并可视化出最优分类模型不同特征的重要性结果,发现被保人的职业、发生保险事故的城市、发生保险事故的地区、资本收益、资本亏损是识别保险欺诈行为的重要特征.这些结果不仅对保险公司提供了重要的参考和指导,也为相关研究提供了宝贵的经验和启示.
