基于CEEMD能量熵与极限学习机的滚动轴承故障诊断方法
2023-09-03毛美姣肖文强陈小告王建涛王立超
毛美姣,肖文强,陈小告,王建涛,王立超
(1.湘潭大学 机械工程与力学学院, 湖南 湘潭 411105;2.湘潭大学 复杂轨迹加工工艺及装备教育部工程研究中心, 湖南 湘潭 411105;3.中国铁道科学研究院机车车辆研究所, 北京 100081)
0 引言
在现代化大生产的背景下,滚动轴承是旋转机器中不可或缺的机械元件,同时,它也是最易损坏的零件之一[1-4]。轴承一旦出现故障,轻则会对机械的性能产生一定程度的影响,重则会导致严重的机械事故,从而产生重大经济损失甚至危及到人身安全[5-6]。研究表明,滚动轴承故障占机械设备总故障的45%~55%[7],严重影响机械的运行效率,因此,研究滚动轴承的早期故障诊断方法对提高机械运行的安全性和提前预知故障规避风险有重大意义[8]。由于环境噪声的影响,加上滚动轴承的损伤情形比较多,导致反映轴承状况的能量比较微弱,并且传感器采集的振动加速度信号本身具有周期性、非平稳性、非线性,这些特征都增加了滚动轴承的故障诊断的难度[9]。
出于上述问题,从滚动轴承振动信号中分离出能够体现其运行状况信息的特征正成为轴承故障诊断领域的研究热点[10-11]。经验模态分解(EMD)适合处理非平稳、非线性信号,能把信号按频率由高到低一步一步分解成多个线性本征模态函数的组合,然而,信号的非线性会导致部分高频信号分解不完整,未分离出来的部分被保留到其他频率中,当在其他频段再次分解时则会造成模态混叠的现象。
CEEMD是在EMD的基础上进行了一些改进,使其不仅非常适合处理非平稳、非线性信号,而且能有效抑制EMD方法产生的模态混淆,相比集成经验模态分解(EEMD),其运算时间有所缩短[12]。经过CEEMD处理后,信号被分解成一定数量的平稳的本征模态函数(IMF),IMF分量从高频到低频排布[13]。滚动轴承不同部位出现故障时,由其分解出的IMF分量所包含的能量值也会相应发生改变,Yu等[14]于2006年提出能量熵的概念,用以表征机械运行状态,并根据不同频段能量分布的差异来诊断滚动轴承故障信息。本文中通过CEEMD对原始振动信号进行分解,得到蕴含着重要故障信息的重组信号,提取其能量作为特征,构成特征向量矩阵,并将其输入极限学习机中,对轴承的故障特征进行学习来识别轴承的故障状态,并与以往多采用的一些故障诊断方法进行了对比。实验结果表明:该方法能够有效应用于滚动轴承的故障诊断,对诊断滚动轴承的振动特征信号具有一定优势。
1 基本理论
1.1 CEEMD方法
CEEMD是在EMD和EEMD基础上改进而来,该方法对信号的处理过程为[12]:
用2种不同的方式为原始信号添加噪声信号,得到两新信号
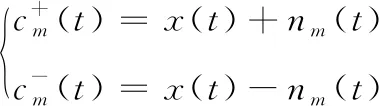
(1)
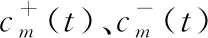
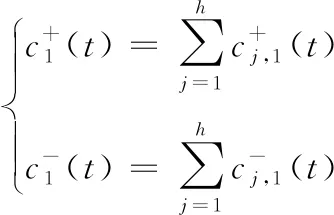
(2)
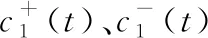
将包含加性和减性噪声的信号分解后的IMF分量集合获取的IMF为:
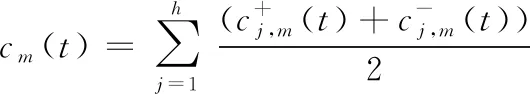
(3)
滚动轴承提取的振动信号x(t)可表示为各IMF分量与余量r(t)之和:
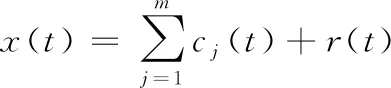
(4)
1.2 极限学习机
极限学习机(extreme learning machine,ELM)本质是一种单隐层前向神经网络(single-hidden layer feedforward network,SLFN)。经典的SLFN结构包括输入层、隐藏层以及输出层3部分。与传统的训练算法不同,ELM第一步对输入层的权值及偏置进行任意赋值,第二步通过求Moore-Penrose广义逆矩阵的方式求解得出隐层到输出层的权值。
从输入层到输出层的隐层结点,其数目的确定需要根据具体问题来分析。网络中还包含一些待定参数:层中结点数、层偏置和层到层的权值,其数值由网络随机生成。生成的w、b和xn一同输入到激活函数中,求得隐层输出。其过程如图1所示。
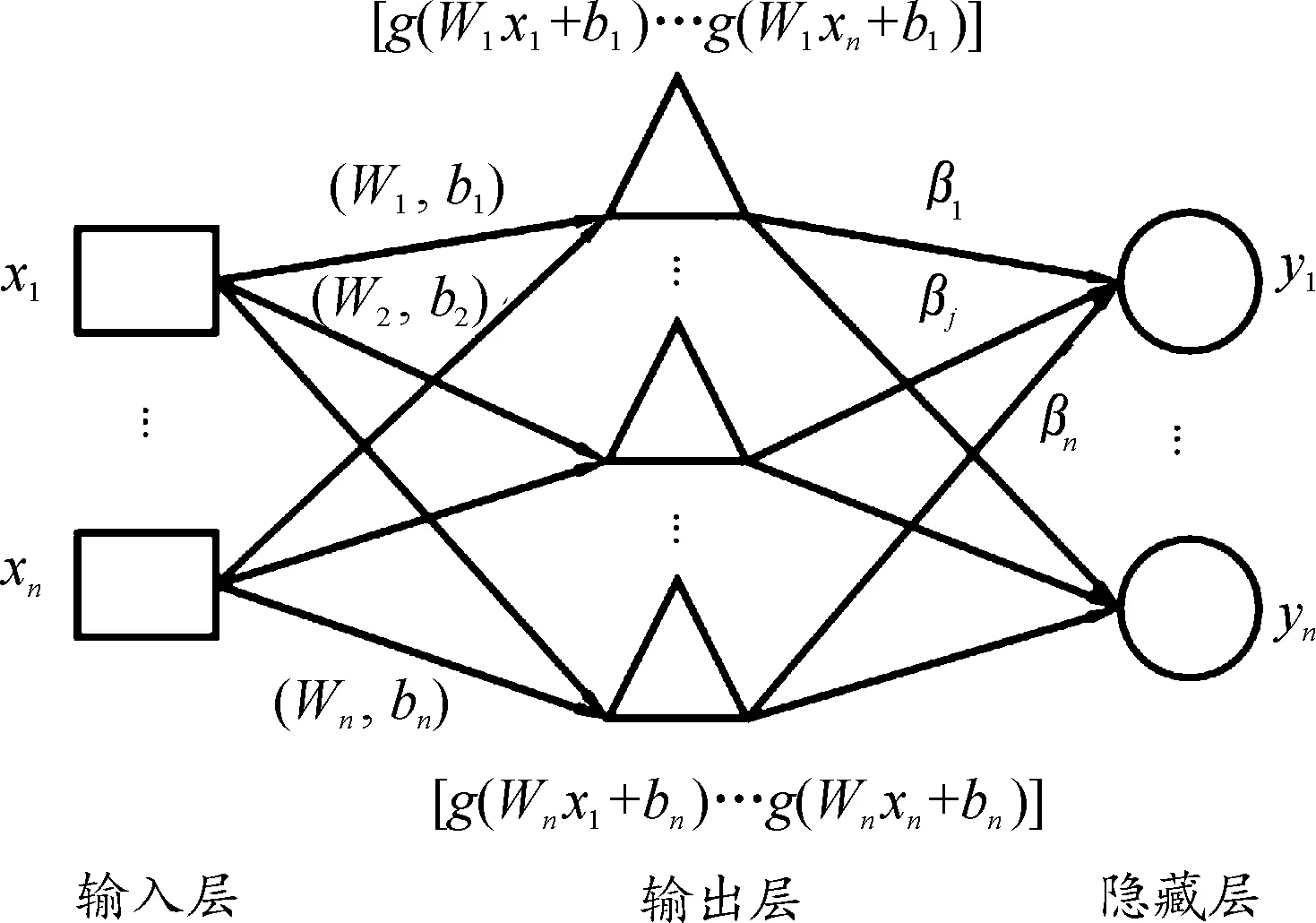
图1 ELM示意图
ELM的输出可以由式得到
Y=[y1y2…yQ]m×Q
(5)
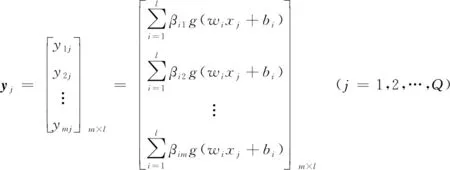
(6)
式中:n为特征的数量;Q为训练样本的数量;m为类的数量;l为隐藏神经元的数量;xj为输入jth样本;β为输出权重;g(x)为激活函数;w为输入层与隐藏层之间的输入权重;b为偏置,它们都是随机获得的。
ELM算法较传统的基于梯度的算法有诸多优势,其优势主要就在于w、b的随机获取,这就使其在效率方面较优于传统的神经网络。在求出隐层输出之后,可以得到目标函数为:
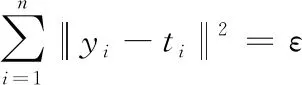
(7)
式中:ti为期望输出值;yi为实际输出值。通过训练获取使目标函数最小的参数β,这时对应的值即是最优解。
2 CEEMD能量熵与ELM相结合的滚动轴承故障诊断方法
2.1 基于CEEMD能量熵的特征向量的提取
当滚动轴承的不同部位出现故障时,在采集到的振动信号中其频率分布也会相应地发生改变,同时,故障振动信号的能量分布也会随之变化。因此,可以对滚动轴承的振动信号进行CEEMD分解后,计算各个IMF分量的能量熵,作为判断滚动轴承是否出现故障的特征向量。
任意选取一组正常状态、内圈故障、滚动体故障和外圈故障4种滚动轴承振动加速度信号进行分析。通过对滚动轴承振动加速度信号x(t)进行CEEMD分解可以得到多个IMF分量,如图2所示。
然后按式(8)和式(9)分别计算出各个IMF分量的能量Ei(i= 1,…,n)及能量熵值HEN[17],如表1所示。

表1 熵值表
(8)
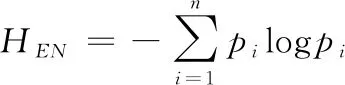
(9)
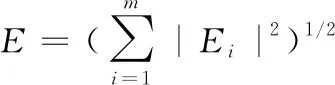
从表1中可以看出在正常状态下,滚动轴承的CEEMD能量熵值大于其他3种情况,原因在于当滚动轴承处于正常状态,振动信号的能量分布相对比较平均,具有很明显的不确定性。当出现内圈、滚动体或外圈故障后,在相应的频带内便会出现对应的共振频率,进而能量就会集中在该频带,使得能量分布的不确定性减少,导致熵值减小。因为内圈、滚动体、外圈3个部件离轴的距离为:内圈最近,滚动体其次,外圈最远。当3个部位出现故障时,故障点对信号产生的干扰与轴的振动信号发生共振解调,从而对3种故障状态下的振动加速度信号的稳定性产生不同程度的影响,随着距离的增大,对稳定性的影响随之减弱,体现在能量熵值上表现为内圈故障>滚动体故障>外圈故障。
通过以上分析可知,滚动轴承的工作状态和故障类型不同,其CEEMD能量熵也会有显著差异,因此可以根据CEEMD能量熵值来判断滚动轴承的工作状况以及故障类型。
2.2 CEEMD能量熵与ELM相结合的滚动轴承故障诊断流程
选取各个IMF的能量特征作为极限学习机的特征向量,送入极限学习机进行故障诊断,其诊断流程如图3所示。
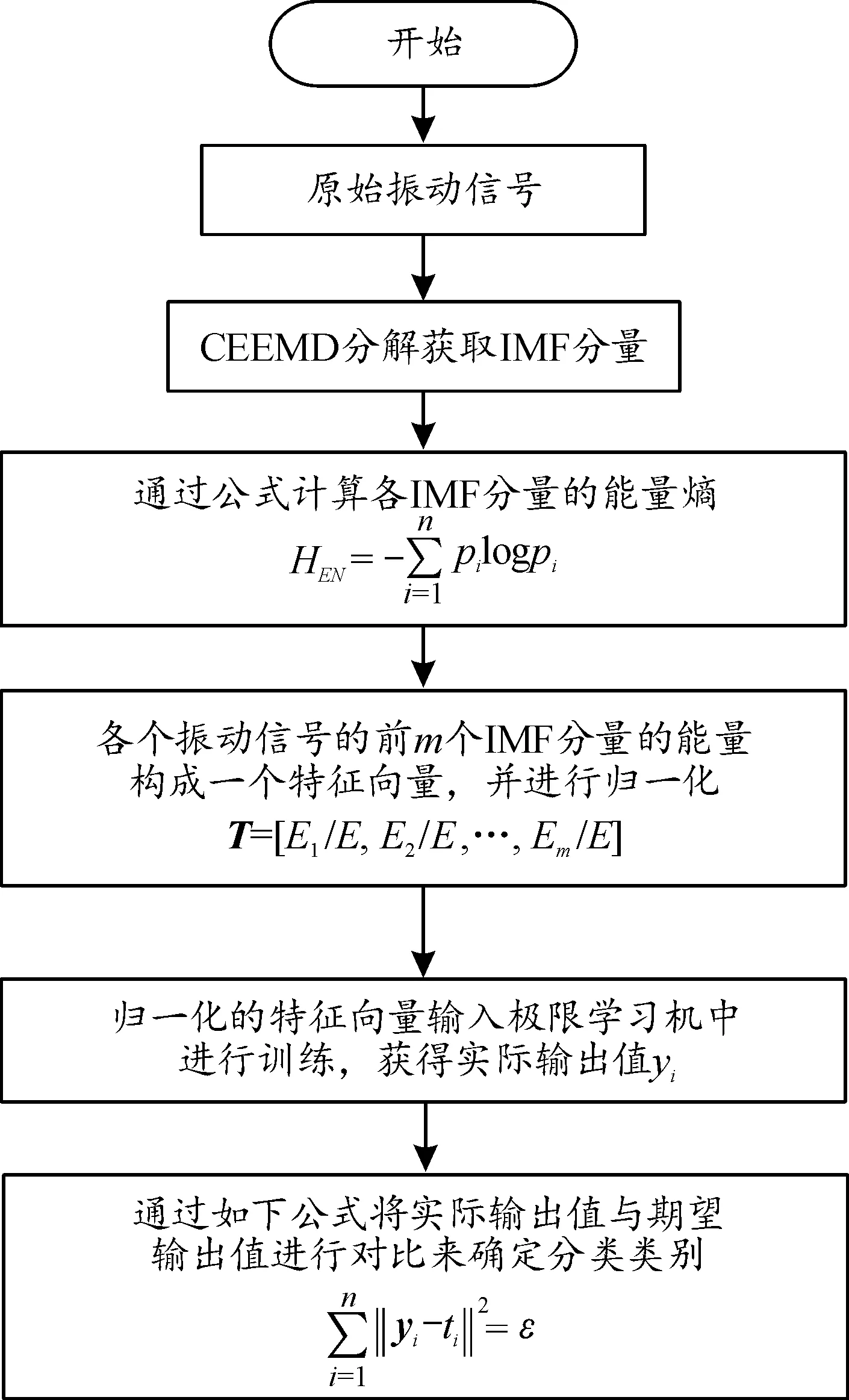
图3 故障诊断流程
其具体步骤如下:
1) 在滚动轴承正常、内圈故障、滚动体故障和外圈故障状态下,通过加速度传感器按照固定采样频率fs各自进行采样。
2) 对每种状态下的各个振动信号进行CEEMD分解,得到一定数量的IMF分量,对于不同的振动信号,其IMF分量的数目并不相同,选取前m个蕴含重要故障信息的IMF分量当作研究对象。
3) 由式(7)计算前m个IMF的能量。
4) 构建能量特征向量:
T=[E1,E2,…,Em]
5) 因能量熵值较大,为便于对其分析和处理,对T进行归一化得到T′。
T′=[E1/E,E2/E,…,Em/E]
6) 将特征向量T′作为ELM极限学习机的输入,以极限学习机的输出来确定滚动轴承的工作状态以及故障类型。
3 滚动轴承故障诊断实例
3.1 数据来源
为了验证所提方法的可行性,以下对其进行实例分析。采用的数据来自于美国凯斯西储大学(CWRU)实验室的公开数据[18],试验台如图4所示。试验采用2马力的电机进行驱动,在电机驱动轴上装有扭矩传感器以及编码器,通过测功机和电子控制系统将扭矩施加到轴上。在驱动端和风扇端安装有SKF深沟球轴承,通过电火花加工技术在轴承不同部位设置故障,来模拟滚动轴承的不同运行状态。

图4 凯斯西储大学轴承试验台
3.2 实例分析设计
设计的实验方案如下:实验轴承选择驱动端轴承,选取0.007 in、0.014 in、0.021 in三种故障直径将故障程度划分为轻度、中度和重度,采样频率为12 kHz,电机转速1 797 r/min,10种状态数据样本集共400个,每种运行状态有40 个样本集,运行状态用数据编号表示,详情见表2。每个样本集包含2 048个原始数据点,每种运行状态前30个样本集作为训练集,后10个样本集作为测试集,并将极限学习机的分类结果与支持向量机(SVM)、k近邻算法(KNN)、随机森林(RF)、朴素贝叶斯(NB)、决策树(DT)等进行对比。
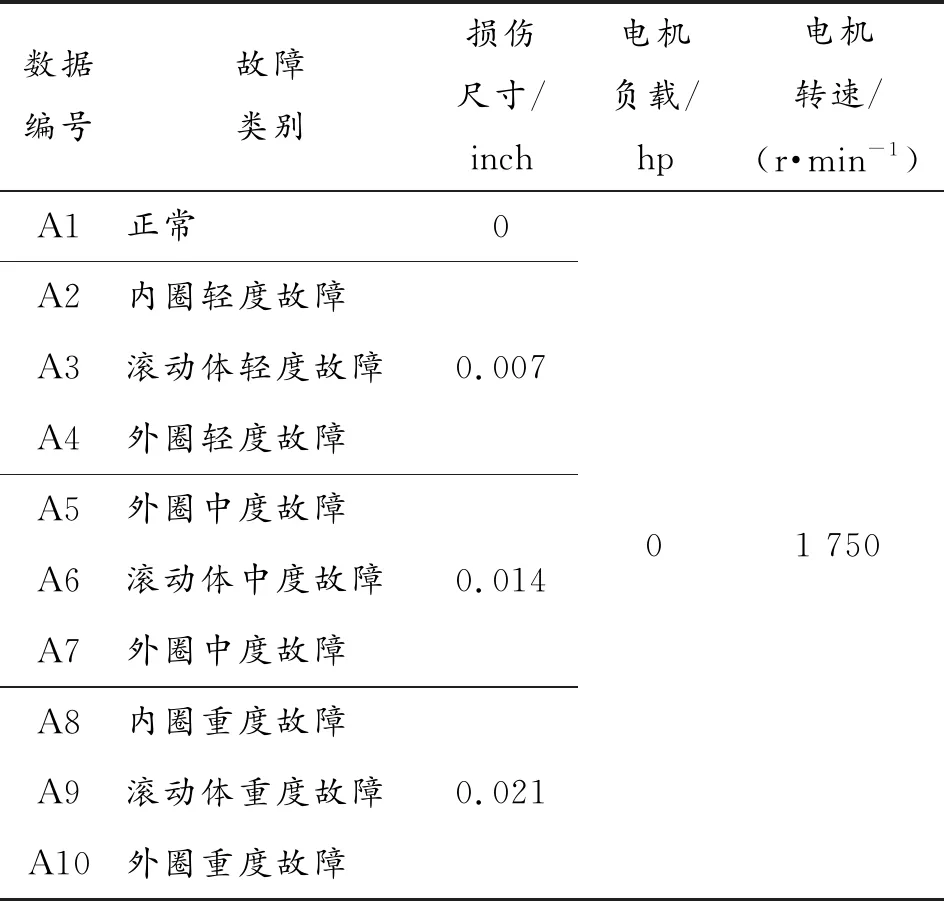
表2 振动信号数据
3.3 CEEMD能量熵特征提取
对正常、内圈故障、滚动体故障和外圈故障4种状态下的振动信号各自采样,分别得到40组数据。在4类数据中将前30组数据作为训练样本数据,将其余的10组数据作为测试样本。第一步采用CEEMD方法对训练数据进行处理,因为CEEMD方法具有主成分分析的效果,主要的故障信息集中在首要几个IMF分量中(试验得到的滚动轴承振动信号是非平稳信号而且幅值变动很大,其CEEMD分解次数均大于6)。对4种状态信号的前6个IMF分量分别计算出能量熵,然后对其进行归一化操作,构成特征向量矩阵。表2中只列出了滚动轴承不同工作状态下首个取样信号的特征向量(限于文章篇幅,特征向量仅列出一部分,且每个特征值的有效数字取3位)。表3滚动轴承不同工作状态下的前6个分量的特征向量。
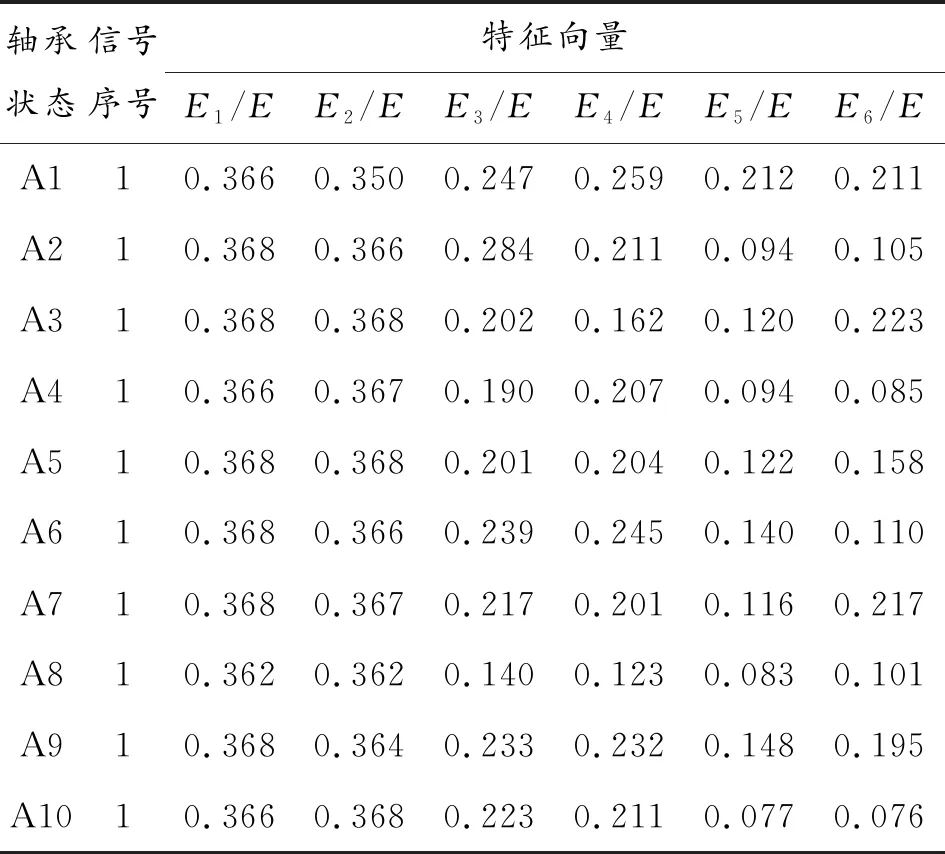
表3 特征向量表
单纯地观察表3,很难发现这些特征向量与滚动轴承各种状态的联系,为进一步体现出这些特征向量在表征滚动轴承运动状态方面的效果,特将根据表2中特征向量创建的特征矩阵作为输入,对其进行聚类可视化分析。聚类方法采用Tsne(T分布随机邻接嵌入)[19],聚类后所得结果如图5所示。
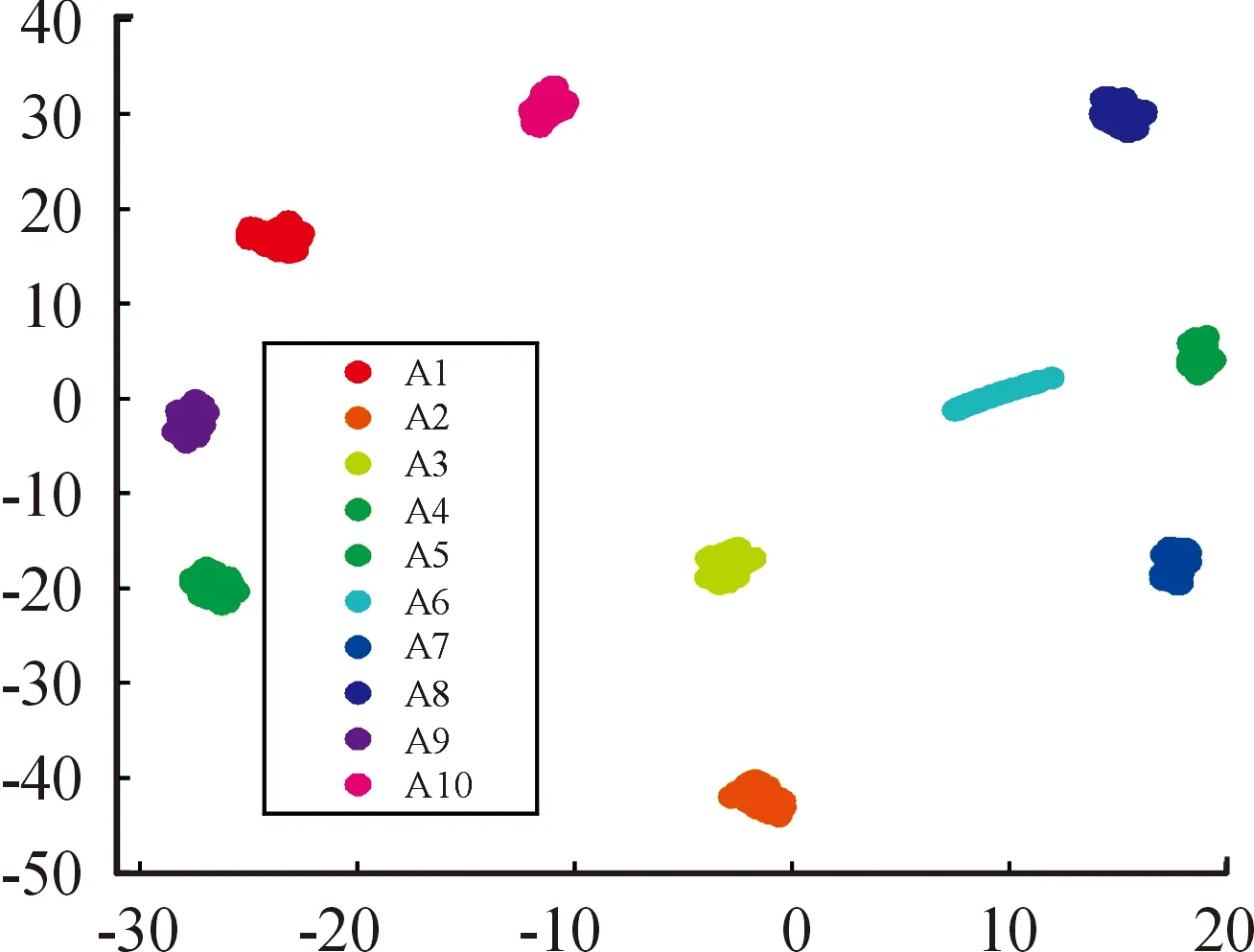
图5 Tsne状态聚类图
由图5可以明显看出,滚动轴承10种状态类间距离较远,除了状态A6,其余九种状态类内距离紧凑,分类效果较好。这说明经过CEEMD分解后,滚动轴承4种运动状态的内在特征得到了很好地体现,将表2中的特征向量作为特征矩阵输入极限学习机进行识别,具备了一定的可行性。
3.4 极限学习机故障识别
将每种状态所提取特征向量的前30组输入到极限学习机分类器中进行训练,剩余10组输入已经训练好的极限学习机进行故障识别,其结果如图6所示。
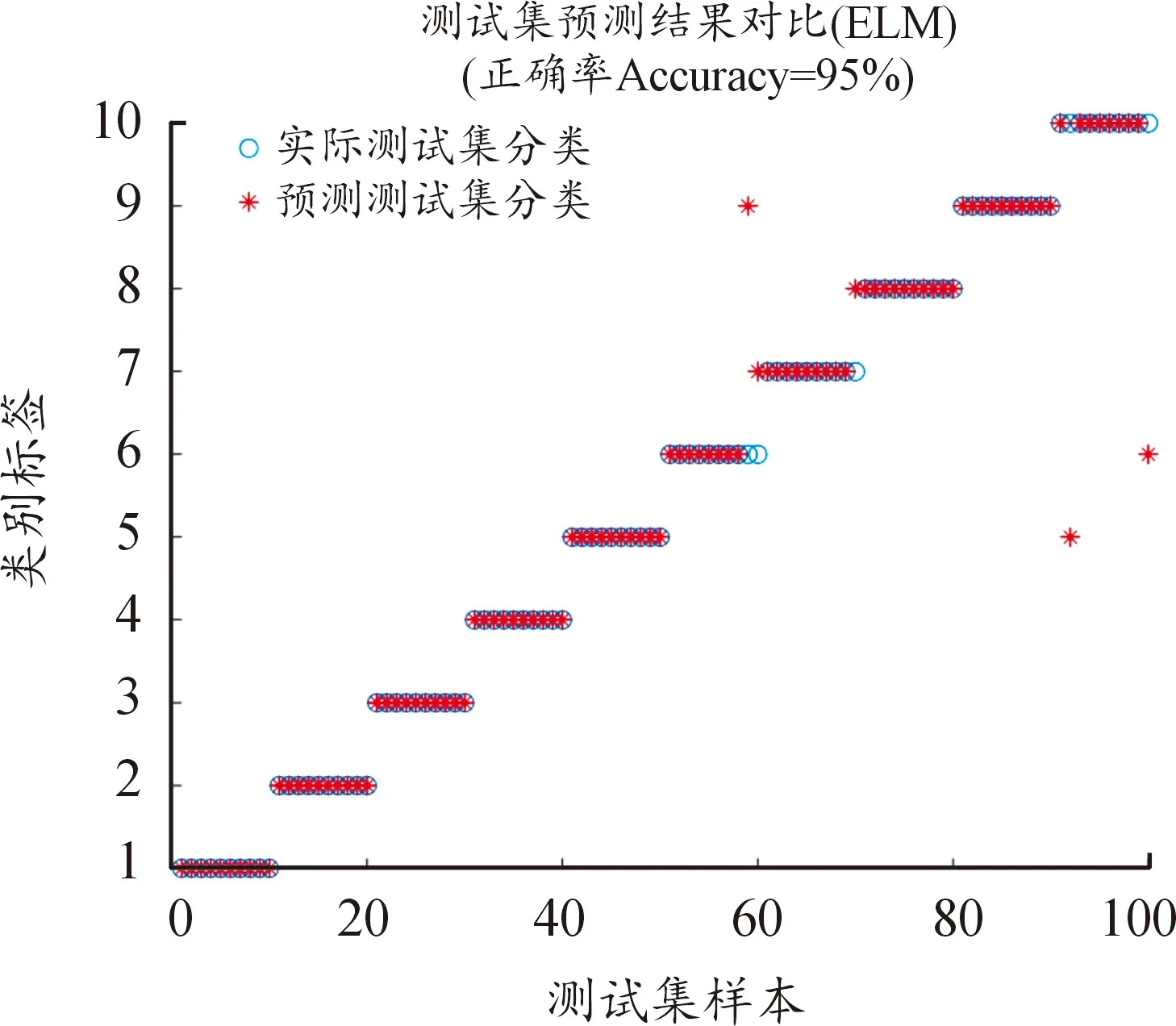
图6 ELM测试结果
通过“1”、“2”、“3”、等10个标签分别代表滚动轴承的十种工作状态,可以看出经ELM识别后的结果准确率达到了95%,为进一步体现ELM的优势,将该方法与一些机器学习算法如多分类支持向量机(MSVM)、k近邻(KNN)、随机森林(RF)、朴素贝叶斯(NB)、决策树(DT)进行对比,采用交叉验证(Cross Validation)的方式,把6种方法分别运行5次,然后求他们的平均准确率以及平均运行时间,将它们的对比结果列于表3所示。
从表4可以看出,极限学习机ELM和多分类支持向量机MSVM的准确率都比较高(分别为95%和94.25%),其次是朴素贝叶斯NB(92.75%)、K近邻KNN(92%)、随机森林RF(91.75%),决策树 DT的准确率最低(88.75%)。从运行时间来,决策树 DT的运行时间最短(0.612 6 s),其次为随机森林RF(0.892 4 s)、朴素贝叶斯NB(1.783 3 s)、K近邻(2.164 7 s),极限学习机ELM(2.829 7 s),多分类支持向量机MSVM(3.646 2 s)。优先考虑准确性,再综合考虑运行时间,采用极限学习机ELM方法能获得较高的准确性和较少的运行时间,该方法具有一定的优越性。
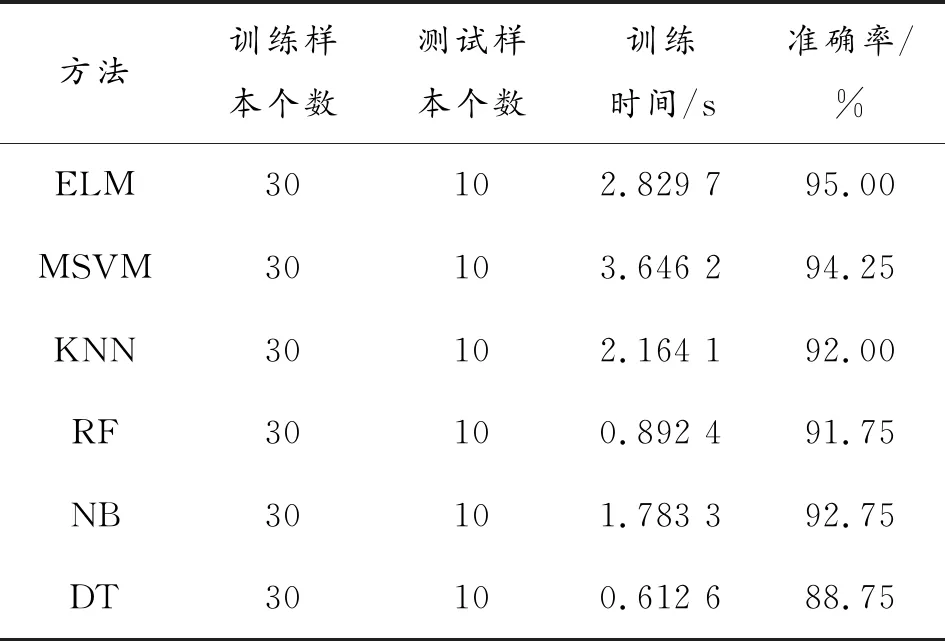
表4 测试结果对比
4 结论
1) 针对滚动轴承振动信号的非线性、非平稳特点,采用CEEMD方法对滚动轴承振动信号进行模态分解,抑制了采用EMD方法分解产生的模态混叠现象,得到IMF分量。
2) 在不同故障状态下,采集到的轴承振动信号的频率分布和能量分布不同,其对应的能量熵有明显差异。在本文中,计算了各IMF分量的能量熵,将不同IMF分量的能量熵构成特征向量,用于识别滚动轴承的故障状态。
3) 将提取到的特征向量信息输入ELM中进行故障状态诊断,发现ELM的准确率为95%,运行时间为最高,运行时间2.829 7 s,能很好地用于滚动轴承故障状态的识别,具有一定的实际应用价值。
