基于结构系数的K-means 初始聚类中心选择算法*
2023-08-31李汉波魏福义张嘉龙刘志伟方月宜
李汉波 魏福义 张嘉龙 刘志伟 黄 杰 方月宜
(华南农业大学数学与信息学院 广州 510642)
1 引言
聚类分析是数据挖掘中的一个重要研究领域。聚类算法是衡量数据相似性的典型算法,它以“物以类聚”的思想,在文档分析、图像压缩[1]、特征提取、图像分割等领域得到广泛的应用。Mac-Queen 于1967 年首次提出K-means算法,它基于样本间相似度对数据进行划分,具有聚类效果好和收敛速度快等特点,属硬聚类算法[2]。传统K-means算法随机选取初始聚类中心会导致聚类结果不稳定[3]。为了削弱初始聚类中心选取的随机性对聚类结果不稳定的影响,研究确定初始聚类中心的有效方法具有重要意义。
一个好的聚类算法具备各类中包含的样本点彼此相似,并且聚类中心在空间分布上尽量分散[4]的特征,这样才能更好地让每一类体现不同于其他类的特性。确定聚类中心和数据分类问题一直是大数据研究的热点内容[5~12]。文献[13]运用了相异度的概念,通过构造相异度矩阵,选取K 个与其他样本相异度较低且聚类个数最多的样本作为初始聚类中心,该算法削弱了传统算法对初始聚类中心的敏感性,在传统算法的基础上具有更高的分类准确率。文献[14]在文献[13]的基础上增加了一个判断,当最大相异度参数不唯一时,提出了一种合理选取最大相异度参数值的解决方案,改进算法与文献[13]的算法在准确率和迭代次数方面有所优化。而文献[15]提出了一种基于最大距离中位数及误差平方和(SSE)的自适应改进算法,通过SSE变化趋势决定终止聚类或继续簇的分裂。本文算法基于文献[13]的相异度概念,定义一个可变邻域参数τ,从最小结构系数开始,按结构系数递增的顺序寻找初始聚类中心,直到找到K 个初始聚类中心。本文实验表明:采用新方法构造的算法相比文献[13]、文献[14]以及文献[15]具有更高的准确率和更少的迭代次数。
2 改进的选取初始聚类中心算法
首先给出基于相异度的四个新概念,在此基础上推导改进的K-means 选取初始聚类中心的新方法,最后得到基于结构系数的新算法。
2.1 基本概念
设待聚类样本数据:X={x1,x2,x3,…,xn},其中xi={xi1,xi2,xi3,…,xim},n为数据集中的样本数,m为样本属性的个数。
采用三个步骤计算样本间相异度并构造相异度矩阵[13]:
3)构造相异度矩阵:
记Ri={ri1,ri2,…,rii-1,rii+1,…,rin},其 中i=1,2,…,n。
定义1 对于样本xi和邻域参数τ,从Ri中任意取τ-1个元素求和,和最小的值称为样本xi的τ邻域的结构系数,记为D(τ,x)i。
定义3 对于样本集X={x1,x2,x3,…,xn},集合{D(τ,x1),D(τ,x2),…,D(τ,xn)}称为对应参数τ的结构系数集合,记为M(τ)。
由定义2 和定义4 可知,最小结构系数D(τ)对应含有τ个样本最密集的邻域。对于样本集X,若要选取K个聚类中心,则,其中表示数取下整。
2.2 算法思想
本文从τ=出发,计算并确定D(τ)及其对应的邻域U(τ,x)i,逐步寻找初始聚类中心。
遴选K个初始聚类中心的方法:
1)首先采用三个步骤构造出相异度矩阵,以及计算邻域的结构系数集合M(τ);
2)计算M(τ)的最小结构系数D(τ),其对应的样本不妨设为xi,将样本xi作为第一个初始聚类中心,同时标记其邻域U(τ,x)i的内点,并将其结构系数都设置为∞,记新的结构系数集合为M(1τ);
3)选取M(1τ)中最小结构系数D(τ),其对应的样本不妨设为xj,将样本xj作为候选点。若邻域U(τ,x)j的内点均没有被标记,则选取xj作为下一个初始聚类中心,并标记其所有内点,同时将内点的结构系数设置为∞。否则,将D(τ,x)j设为∞,随后选取M(1τ)中最小的元素对应的样本作为候选点;
4)反复进行以上判断直至所有样本的结构系数都为∞,此时得到的初始聚类中心个数记为l0;
5)若l0≥K,则选择前K 个候选点为初始聚类中心;若l0<K,则清空初始聚类中心和内点标记;
6)缩小邻域参数τ,循环以上方法,直到选出K个初始聚类中心。
根据以上分析,得到算法的流程图如图1 所示。
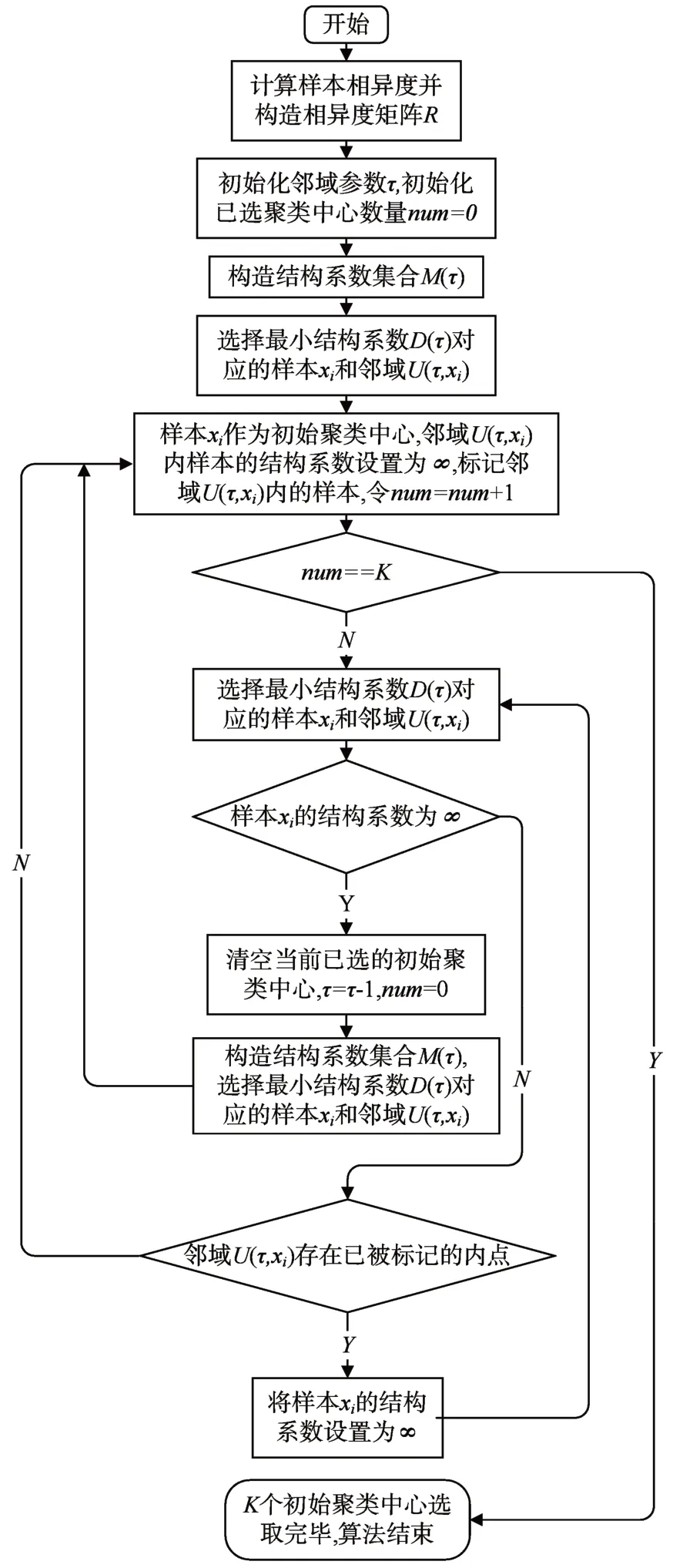
图1 算法流程图
3 实验结果与分析
以常用的五个UCI数据集为实验数据,将本文算法与文献[5]、文献[6]和文献[7]的算法进行对比实验,验证新算法的有效性。
3.1 实验数据集
UCI 数据集作为标准数据集,经常用于测试机器学习算法的性能,为了验证以上算法选取初始聚类中心的有效性,本文采用UCI 数据集中的Diabetes 数据集、Iris 数据集、Harbeman 数据集、Wine 数据集和Seed 数据集作为实验数据集,数据集详细信息如表1所示。
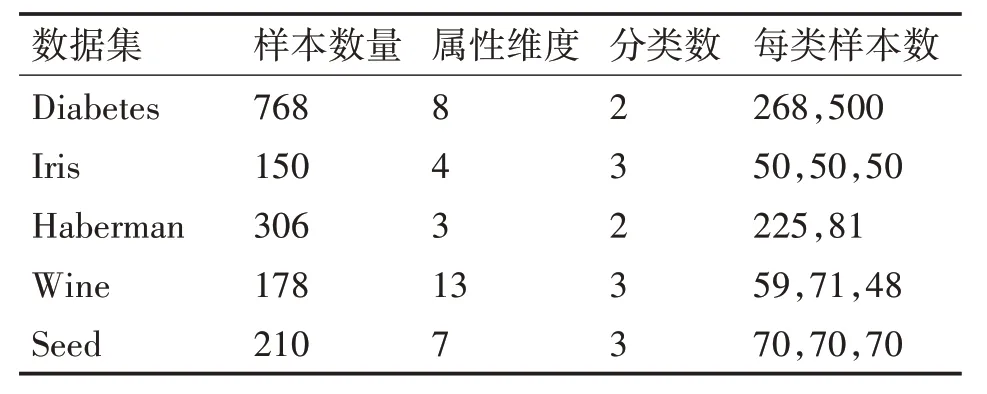
表1 实验数据集描述信息
由于Diabetes 数据集、Haberman 数据集和Wine 数据集各维度属性取值范围差异较大,先对这三个数据集进行零-均值规范化,以便消除属性差异对聚类性能的影响。对于每一维度属性,有如下计算公式:
3.2 聚类效果评价指标
衡量聚类算法性能的评价指标有许多种,本文选用准确度和迭代次数作为判定聚类算法性能优劣的指标。设数据要求分为K 类,则准确度的计算公式[14]如下:
其中n 为样本总量,αi表示被正确划分为第i 类的样本数量,MP值越接近1,表示聚类效果越好。
对于数据集要求分为K 类,在保证准确度前提下,迭代次数越少越好。
3.3 实验结果和分析
表2~表6 分别是文献[13]、[14]、[15]算法和本文算法在5个UCI数据集上的对比实验。
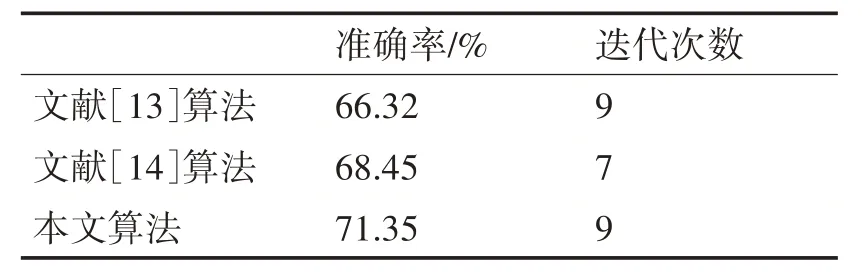
表2 Diabetes数据集的实验结果
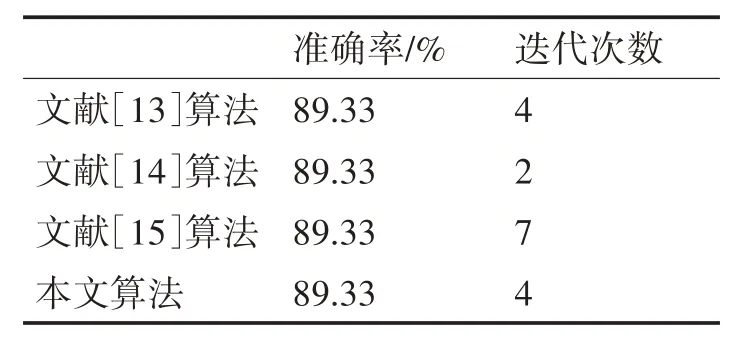
表3 Iris数据集的实验结果
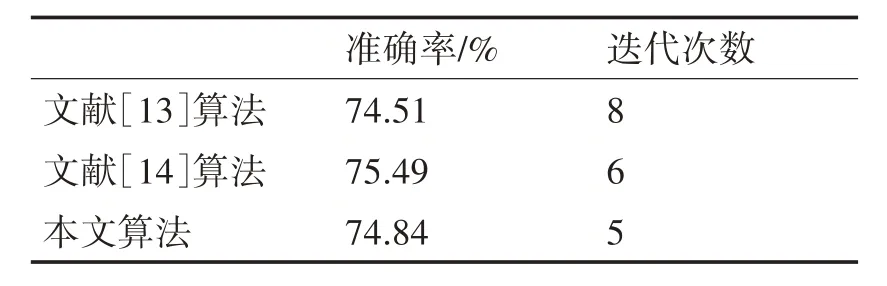
表4 Haberman数据集的实验结果
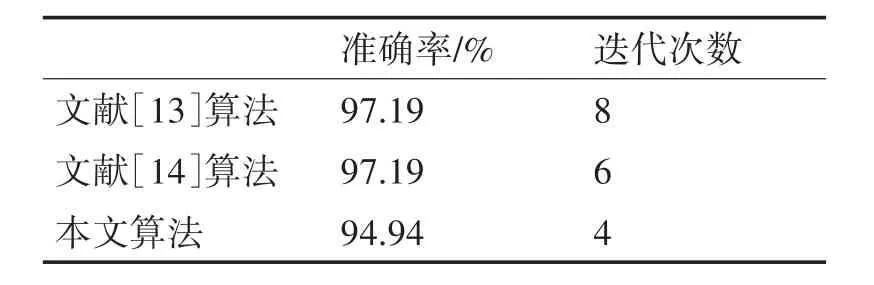
表5 Wine数据集的实验结果
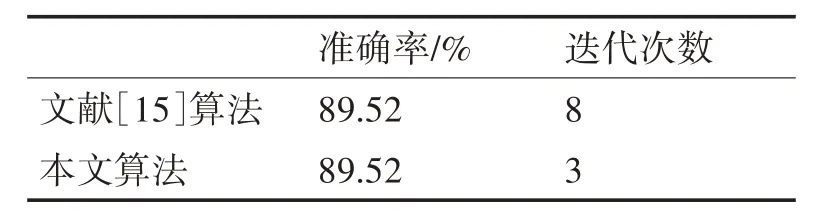
表6 算法在Seed数据集的实验结果
在Diabetes 数据集中,使用本文算法改进的K-means算法的准确率最高,为71.35%。虽然在迭代次数方面略微高于文献[14]算法,但与文献[13]算法持平。由此可见,本文算法对于Diabetes 数据集聚类性能具有改良效果。
对于Iris 数据集,本文算法的准确率为89.33%,准确率效果与文献[13]、[14]、[15]的算法持平。在迭代次数方面,本文算法与文献[13]算法性能相同,相比文献[15]迭代次数减少3 次,但略逊于文献[14]算法。
在Haberman 数据集中,虽然本文算法在准确度方面略低于文献[14]算法,但略高于文献[13]算法。且本文算法的迭代次数为5,均低于文献[13]和文献[14]算法的迭代次数。
在Wine 数据集中,本文算法在准确度方面略逊于文献[13]、[14]算法,但相对于文献[13]、[14]算法,本文算法的迭代次数较小,收敛速度快。因此,本文算法对于Wine 数据集的改进性能可以接受。
在Seed 数据集中,对比于文献[15]算法,本文算法能取得相同的准确率,且本文算法的迭代次数为3,远低于文献[15]算法。
由表2~表6 的实验结果可见,相比于文献[13]、[14]、[15]算法,本文算法均能取得较为良好的聚类效果。
4 结语
K-means算法应用广泛,但由于其选取初始聚类中心的随机性,会导致聚类结果不稳定。针对这一缺陷,本文提出邻域及其结构系数的概念,在充分考虑数据集的整体分布后,结合数据集的局部密集程度和样本的相异度这两个性质,选取周围密集程度较大且相距较远的样本作为初始聚类中心,采用依次缩小邻域的方法,逐个找出K 个不同的初始聚类中心。同时,本文给出了一种数据聚类新方法,不仅得到数据集的K 个初始聚类中心,而且还得到了li=(i=0,1,…,q-1)个初始聚类中心及其对应的数据分类。
实验结果表明,新方法有效地削弱了传统K-means算法选取初始聚类中心的盲目性,改进后的算法提高了准确度和减少了迭代次数,具有准确性高和收敛速度快的聚类效果。
