基于网络熵变率的节点重要性排序方法*
2023-08-31王昌达
陈 前 王昌达
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
几乎所有的复杂系统(比如社会、生物、信息、技术、交通运输系统等)都可以表示为网络[1]。其中,节点代表系统构成要素,节点连边上的负载信息代表系统要素间的联系。对网络中少数关键节点的破坏就能导致网络整体瘫痪。其中,关键节点是指相对于网络中其他节点而言,能更大程度地影响网络通信或安全功能的特殊节点。因此对网络中关键节点进行保护,能够大幅度提高网络的可用性与抗毁性;对社交网络中的关键节点进行引导,能更好地干预网络舆情的发展。
节点的重要性不仅与网络拓扑结构有关,也与当前网络负载状态有关。在不同的网络负载状态下,不同位置的节点会体现出不同的重要性。
目前,基于网络拓扑的节点重要性评价方法主要可以分成五类:1)基于邻居节点:这一类方法主要考虑当前节点的临近节点信息。比如度中心性方法(DC)[2]使用相邻节点的数量作为节点重要性的度量。这种方法实现简单,但忽略了邻居节点自身的影响,因此度中心性方法的准确性不高。2)基于路径长度:这一类方法主要是通过节点在信息传递中所担任的角色来衡量节点重要性,比如接近中心性方法(CC)[3]通过计算节点与其他节点间的平均距离来衡量节点重要性。这类方法使用全局信息度量节点的重要性,准确性高但计算复杂度也高。3)基于特征向量:特征向量指标是从网络中节点的地位或声望角度考虑,将单个节点的声望看成是所有其它节点声望的线性组合,从而得到一个线性方程组。该方程组矩阵最大特征值所对应的特征向量就是各个节点的重要性[4]。特征向量中心性方法(EC)[5]和PageRank[6]方法是此类的典型方法。4)基于节点移除和收缩:通过删除节点或者收缩节点对网络产生的破坏性来衡量节点的重要性。比如艾新波提出的熵变量方法[7],该方法将节点的重要性定义为某节点删除前后网络熵的变化值,但由于每一次节点删除后都需要计算网络熵,导致了算法计算复杂度也变大。5)混合方法:通过综合前几类方法以达到对节点重要性更全面的分析。此类方法包括文献[8]中通过信息熵加权方法,对节点位置属性和邻居属性进行加权来度量节点重要性;文献[9]中使用一种基于相对熵的综合评价方法。
基于当前网络负载变化衡量节点重要性的代表性成果相对较少,其中比较有代表性的成果是我们课题组金甜甜等[10]提出的DPCR(Direct Principal Component Ranking)和CPCR(Comprehensive Principal Component Ranking)方法。此类方法可以根据网络的拓扑以及网络中数据包传输的方向性对节点的重要性排序。
为了能综合考虑网络负载变化和网络拓扑结构对节点重要性的影响,本文提出一种基于网络熵变率的MixR(Mix Ranking)节点重要性排序算法。为了验证该方法的有效性,本文在两个公开数据集上使用SIR(Susceptible-Infected-Recovered)模型[1]度量节点的影响力,并将其与其他已知的节点重要性排序方法进行比较,实证了MixR 的有效性和准确性。
2 相关概念
本节首先给出流量矩阵的数学模型和基于有向图的网络拓扑的中心性方法;然后介绍了网络熵的几种形式;最后对SIR 模型的评判标准和评判过程做简要总结。
2.1 网络负载的流量矩阵模型
在网络流量矩阵OD(Origin-Destination)Matrix中,OD 流(k1,k2)的定义是从节点k1(源节点)进入,最后流出节点k2(目标节点)的所有流量的集合[11]。对于一个有着n个节点的网络,它的网络流量矩阵共有n n个元素。一般地,用T来表示流量矩阵,用tij表示OD流(i,j),其中矩阵第i行元素的和代表从节点i流出的总流量,矩阵第j 列元素的和就代表着流入节点j的总流量。
2.2 基于网络拓扑的中心性度量方法
度中心性:有向图中度中心性分为出度中心性、入度中心性和度中心性,节点的出度就是指以节点为头的节点数量,入度就是以其为尾的节点数量。节点的度就是节点的出度和入度之和,节点的度中心性值越大,节点能接触的其他节点越多,一般认为这样的节点在网络中越重要。
接近中心性:节点的接近中心性值表示为一个节点到其他节点的平均最短距离的倒数,值越大,节点越接近其他节点,越能更好地控制网络中信息流动,一般认为这样的节点越重要。
特征向量中心性:该方法的本质是将一个节点的重要性表达成它的邻居节点的重要性之和。节点的特征向量中心性值越大,节点连接的邻居节点越重要,节点本身也就成为一个重要节点。
2.3 半局部中心性方法
节点的半局部中心性方法(semi-local centrality)[12]是一种基于半局部信息的节点重要性排序方法。该方法首先给出节点的两层邻居度的定义N(w),其值为节点w两跳范围内邻居节数量和。在有向图中,节点的半局部中心性方法只考虑出度,因此将N(w)定义为从节点w出发两跳范围内可到达的节点数量,其定义为
其中T(u)是从节点u出发一跳范围邻居节点的集合,最终给出节点i的半局部中心性
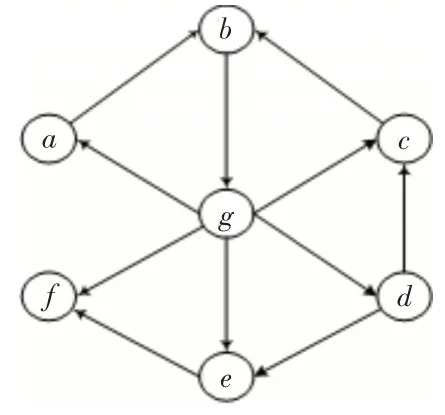
图1 拥有七个节点的有向图
以图2 为例,计算节点a的半局部中心性,Q(a)out=N(b)out,从节点b出发到达节点g,而节点g可以到达的节点有a,c,d,e,f,所以N(b)out=6,依此类推,我们有以下结果:CLa-out=Q(b)out=N(g)out=6。
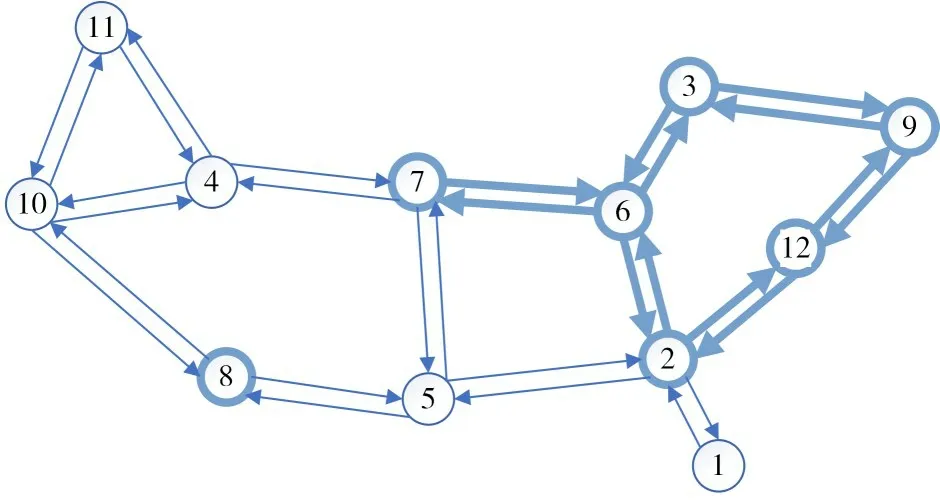
图2 Abilene网络的拓扑结构
2.4 网络熵
网络熵有香农熵[13]、Rényi 熵[14]和Tsallis 熵[15]等多种不同的形式。在Rényi 熵和Tsallis 熵中,参数α可以调节不同概率p 分布对整体结果产生的影响。当α=1 时,Rényi 熵和Tsallis 熵就退化成香农熵;当α>1 时,由于p 值的范围是0~1 之间,p 值越小,pa的值越趋近于0,此时高概率事件的分布相比于低概率事件更明显,因此主要体现的是高概率事件的分布状态;当α<0 时,主要体现的是低概率事件的分布状态。
2.5 SIR模型
SIR模型是一种常用的节点影响力评估模型[1,16]。在SIR 模型中,节点重要性的评判标准一般有:给定时间内感染源感染的节点总数以及感染总数达到稳态时的用时。
在SIR模型中,每一个节点都有3种状态:1)易感染状态;2)已感染状态;3)恢复状态。这三种状态节点在所有节点中所占个数分别为S(t),I(t)和R(t)。对于初始受到感染的节点,节点以概率λ感染其它易受感染的节点。在复杂网络SIR 模型中,假设被感染的节点周围所有的邻居节点都有机会被感染。经过t 时间后,将感染态的节点在整个网络中所占的个数F(t)作为传播范围衡量指标。
3 MixR动态节点重要性排序方法
本节首先给出网络熵变率的定义,并对其原理进行分析,然后在此基础上设计了MixR算法。
3.1 网络熵变率
网络熵可以用来描述网络安全性能,网络熵值越小,说明系统的安全性越好[17]。对于网络中某一项性能来说,可以将其熵值定义为pi,pi是与这项性能相对应状态出现的概率。
若将一个源节点附近聚集的所有OD流看成是基本状态,则在节点i附近网络熵的定义如下:
文献[17]中利用熵差来反映网络遭受的攻击效果。而在本文中,熵差是网络流量变化导致的网络熵值的变化,所以单靠熵差无法体现网络熵随网络负载变化的快慢。因此本文给出了网络熵变率的概念,即用网络熵值变化的速率来反映网络流量的变化快慢。
我们选取不同时刻的网络流量矩阵T1和T2,最终得到节点i附近的网络熵变率为
在网络中,大部分流量总是聚集在少量节点附近[18],这些节点附近的流量变化对节点产生的影响越大,这些节点也被称为关键节点。以网络熵变率为指标,可以在网络中快速、准确地找到这些关键节点。
3.2 MixR算法
为了兼顾网络拓扑结构对节点重要性产生的影响,本文在熵变率的基础上结合了网络拓扑结构信息,即基于节点出度的半局部中心性方法。半局部中心法能够衡量节点四跳范围内的邻居信息,这种方法比度中心性方法的准确度高,比接近中心性方法和特征向量中心性方法复杂度低。将其与网络熵变率的方法相结合,能在准确性和复杂性之间实现一个可接受的折中。最终得到的MixR算法是一个动态方法与静态方法相结合的方法。算法的具体操作过程为:
基于不同时刻的网络流量矩阵求得节点的网络熵变率:REC=[r1,r2,…,r3]T,同时基于网络的邻接矩阵求出节点的出度半局部中心性:CLout=[c1,c2,…,cn]T,最后将两者相结合得到MixR的公式:
得到的是最终的节点重要性指标,值越大的元素对应的节点越重要。
以下是算法的伪代码:输入网络的邻接矩阵A和不同时刻的网络流量矩阵,输出由Ranknode表示,我们通过对Ranknode进行排序来得到最终的节点重要性排序序列。
算法:MixR算法
输入:Traffic1N*N Traffic2N*N AN×N
输出:Ranknode
1)For i=1 to N do
2) For j=1 to N do
4 实验
4.1 使用的数据集
本文使用两个公开数据集来验证MixR 的有效性,其中一个来自Abilene 网络[19],另一个来自GEANT 网络[20],这两个数据集的下载地址是https://blog.csdn.net/qq_36042551/article/details/103207827。Abilene 网络拥有12 个PoP 点和30 条边;GEANT 拥有23 个PoP 点和74 条边。两个数据集中采集的流量矩阵之间的最小间隔时间是可调整的。Abilene的最小时间间隔是5min;GEANT 最小时间间隔是15min。
Abilene 网络和GEANT 网络的拓扑结构分别见图2和图3。

图3 GEANT网络的拓扑结构
4.2 实验方法
本文首先使用DC,CC,EC,半局部中心性算法和MixR 算法对网络中节点的重要性进行排序,然后使用SIR 模型对排序的结果进行验证。具体方法是首先将上述各算法得到的排名前6 的节点分别作为网络的初始传染源,然后使用SIR 模型进行感染模拟,最后比较传染源节点在网络中感染的节点总数和达到稳态时所用的时间。需要强调的是本文网络熵变率在计算中都是采用的出流量,所以在计算节点的DC值和半局部中心性值时都是采用出度。
4.3 结果分析
实验得到的节点重要性排序序列会随着流量矩阵的更新而改变。为了节约篇幅,只给出排名前六的节点变化序列,表1 给出了Abilene 网络中每隔五分钟的节点重要性序列的变化,表2 给出了GEANT 网络中每隔15min 的节点重要性序列的变化。
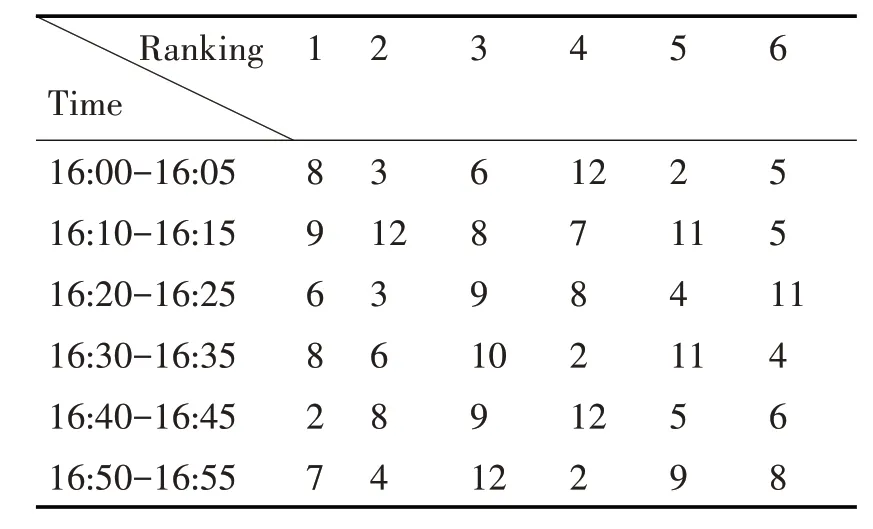
表1 Abilene网络的节点重要性变化情况
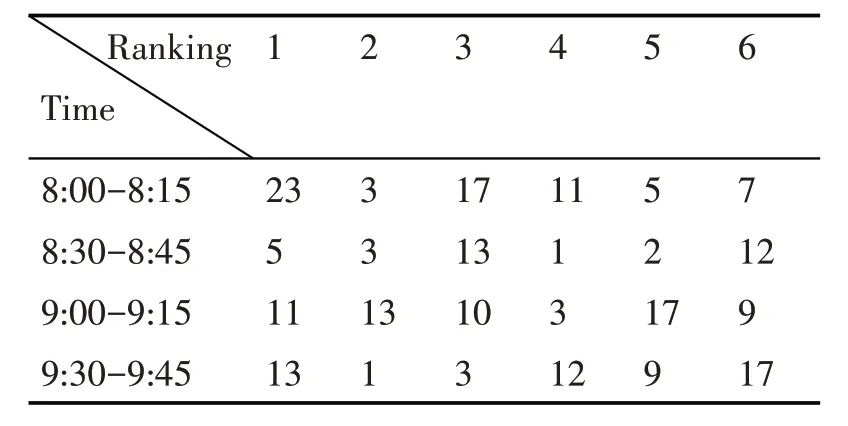
表2 GEANT网络的节点重要性变化情况
结合网络拓扑观察节点的重要性变化,我们可以发现,虽然网络中节点的重要性是在不断变化,网络中仍然还是存在一个节点的重要区域。在Abilene 网络中,在下午六点至七点这个时间,重要节点大多数都集中于右边的区域(图2 加粗区域)。在GEANT网络中,在早上八点至九点这段时间,重要节点大多数都集中于中间的区域(图3 加粗区域)。
表3和表4分别给出了两个网络中各种算法的前六名节点排序结果。我们将这些节点作为SIR模型中的感染源进行影响力分析,并比较了几种方法的差异性,结果见图4。
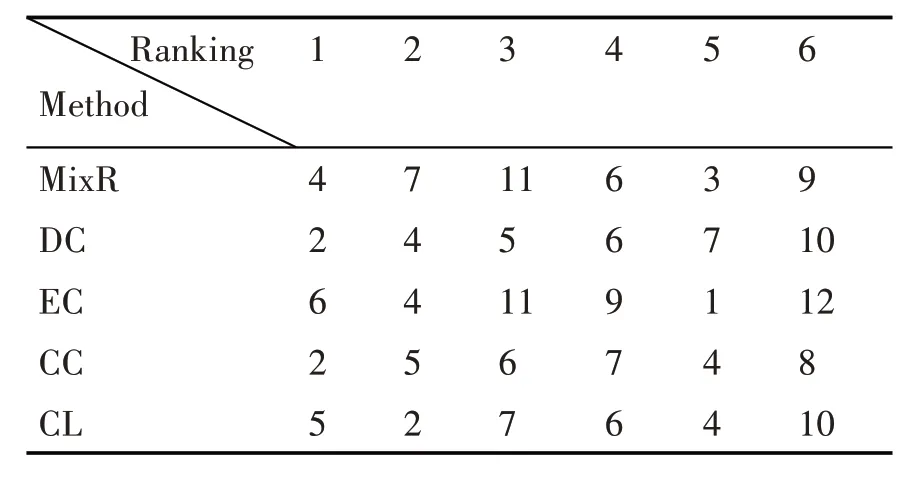
表3 Abilene网络的前六名节点排序结果
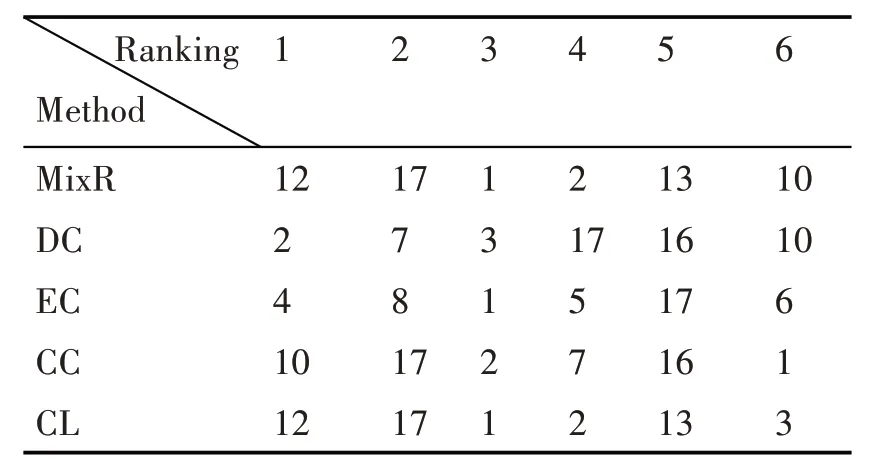
表4 GEANT网络的前六名节点排序结果
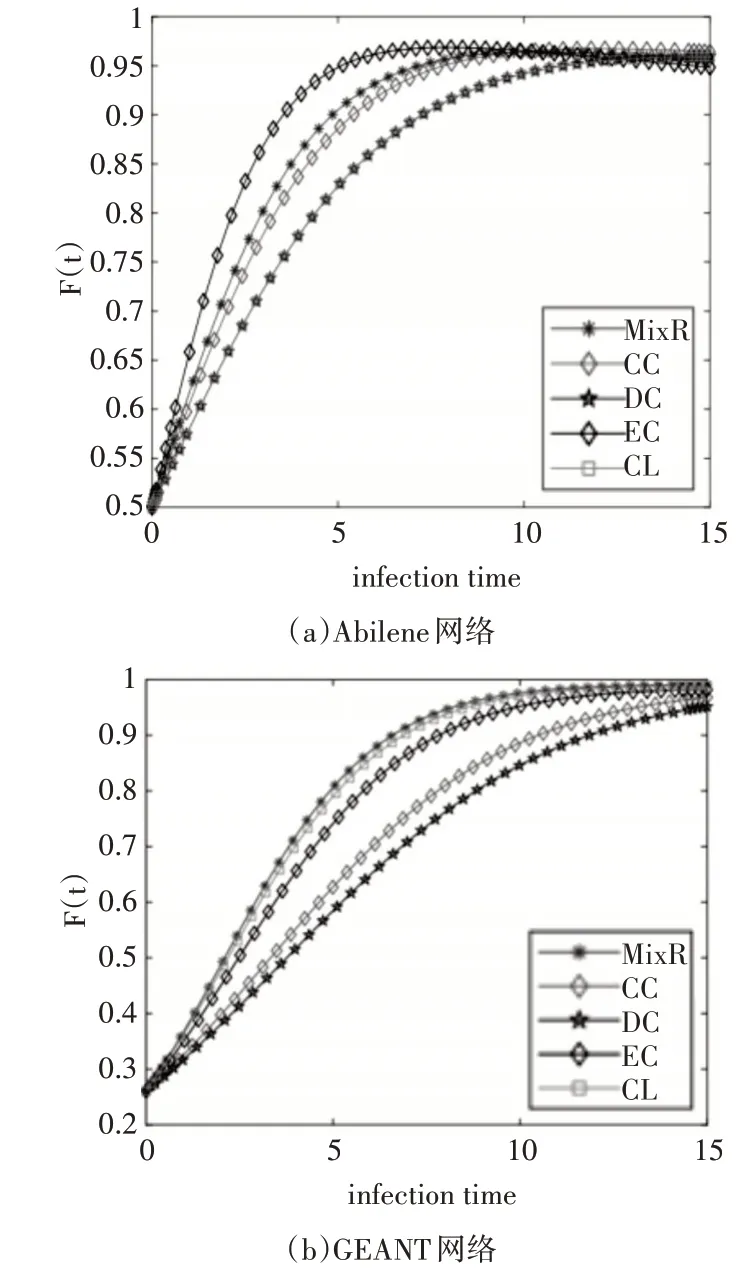
图4 两个网络上的SIR模型实验结果
如图4(a)所示,在Abilene 网络中,EC 方法得到的前6 名节点的传播性能最好,其次就是MixR。EC 的表现如此好是因为特征向量中心性本身就适合于描述节点的长期影响力,如在疾病传播、谣言扩散中,一个节点的EC 分值较大说明该节点距离传染源更近的可能性越大[4]。根据我们的节点排序结果,EC 方法得到的排名前6 的节点6,4,11,9,1,12 在网络中相对分散,而且网络中只有12 个节点,这导致剩下的节点每个都能找到与自己距离十分相近的感染源。由此,EC 的表现优于我们的方法。但随着网络规模的扩大,在GEANT 网络中,MixR 算法要优于其他4 种方法,这说明MixR 得出的重要节点在规模较大的网络中处于更为关键的位置。
5 结语
节点的重要性不仅与网络的拓扑结构有关,而且与当前的网络负载状态相关,本文提出了网络熵变率的概念,利用其来研究网络负载变化对节点重要性的影响。同时,我们利用半局部中心性方法来衡量节点附近的拓扑结构。通过两者相结合,得到的MixR算法从网络负载和网络拓扑两方面综合衡量节点重要性,这是一种静态方法和动态方法相结合的方法。方法的有效性最终也在公开数据集上进行实验得到了验证。
