基于改进的在线迁移学习算法的电池高压故障预警
2023-08-29董臣臣孙大帅王景龙
董臣臣,孙大帅,王景龙
(上海采日能源科技有限公司,上海 201802)
锂电池是储能集装箱或者电动汽车的重要部件,电化学行为、机械行为和热行为等会造成锂电池故障[1]。由于这种电化学设备的复杂性,锂离子电池的大规模使用给储能系统的安全性带来严峻的挑战[2-3]。对于锂离子电池故障诊断和预警,样本的不足已经成为一个瓶颈[4]。
提前预知锂电池故障的发生,能够避免安全事故[5]。Zhao 等[6]采样云边端一体化架构,将边缘设备采集到的故障信息上传到云端,并在云端对数据进行特征工程和模型训练。王志福等[7]将智能优化算法引入锂离子电池传感器故障诊断,提出基于遗传算法优化粒子群算法和模糊神经网络的锂离子电池传感器故障诊断方法。然而,大多数的故障预警方法需要大量的故障数据来提供精确的结果,在实验室或生产环境下获取电池故障数据需要相当长的时间和较高的经济成本,并且以上方法没有解决数据分布偏移问题[8]。
最近,迁移学习在不同行业内受到广泛关注,迁移学习通过现有的领域知识解决不同但相关的领域的问题。迁移学习技术不仅解决源域和目标域数据分布的偏移问题,而且能够在样本较少的情况下提高模型的泛化能力[8]。Mao等[9]使用迁移学习和卷积神经网络(convolutional neural network,CNN)模型实现电池健康状态的估计。Ruan 等[10]利用迁移学习技术先使用相关的数据训练模型,然后再微调模型。Von Bülow 等[11]提出一种使用多层感知器(multilayer perceptron,MLP)的电池健康度(state of health,SOH)预测模型的迁移学习方法。文献[9-11]由于训练过程中使用的是离线数据,在迁移学习过程中,模型只能根据目标域中历史的数据进行微调,不能在线学习,此外在数据分布发生偏移时误差较大。目前,在线迁移学习在电池故障预警中的应用较少,多数是在电池健康状态评估上的应用。在文献[12]中,采用在线迁移学习实现对电池SOH的估计。
针对上述存在的问题,本工作主要的贡献阐述如下:
首先,结合增量学习[13]的概念,提出基于改进的在线迁移学习的故障预警算法。通过使用源域中充足的故障数据来训练离线模型,并且离线模型随着时序数据增加到合适的量后进行增量学习,使其既能学习源域中的特征,又能学习目标域中的特征。
其次,设计一种分段下采样策略。在实际的储能项目中,电池故障相关的数据较少,正负样本严重不均衡。本工作通过采样技术来解决此问题,对负样本进行下采样来减少整体的数据量,从而降低计算资源的使用。电池故障预警场景下,设计分段下采样策略使算法模型在故障发生前能学习到更多细微的特征。
最后,通过在滑动窗口内计算F1-score解决模型权重缓慢失衡问题,从而提高模型的准确性。离线分类器在线学习的过程中权重会缓慢向1 趋近,为解决这种权重缓慢失衡问题,使用当前的一个时间窗口,评估离线模型和在线模型,然后确定模型的权重。通过设置评分的时间窗口,保证评分能准确表示在线模型的当前误差,从而避免权重失衡问题。
1 增量学习
增量学习可以从数据流中不断学习领域知识,是一种以增量方式进行学习的训练策略。只有少数类的训练数据必须同时存在,并且可以逐步添加新的类。传统的模型训练基于固定的数据集进行训练学习,随着不同分布的数据流的加入,一般需要重新训练整个模型,此方式较为耗时耗力,在实际应用场景中并不适用,因此增量学习应运而生。
增量学习只需使用一部分旧数据而非全部旧数据就能训练得到分类器。学习新的知识会使训练后的模型很快忘记旧的知识,这被称为灾难性遗忘,增量学习能够很好地解决灾难性遗忘问题[14-15]。
2 在线迁移学习
在线迁移学习[16-17]主要将数据分为源域和目标域;算法分为离线模型和在线模型。使用源域训练离线模型,使用目标域训练在线模型。最终的结果根据两种模型的输出进行加权获得。其中,离线分离器可以使用支持向量机(support vector machines,SVM)[18]、随机森林[19]等,在线分类器可以使用Passive-Aggressive(PA)算法[20]。
在线迁移学习过程如图1所示,具体步骤如下:
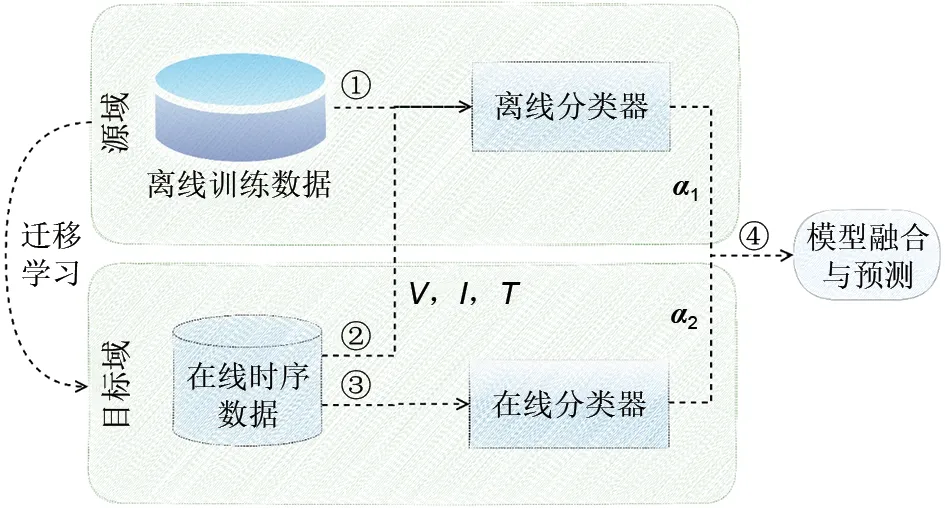
图1 在线迁移学习算法Fig.1 Schematic diagram of online transfer learning algorithm
(1)使用源域中的离线数据训练一个离线分类器;
(2)使用离线分类器对目标域中的在线时序数据进行预测得到一个分类结果A;
(3)使用目标域中的在线时序数据训练在线分类器,并预测当前的在线数据得到一个分类结果B;
(4)最后A和B进行加权求和得到最终的分类结果。
在线迁移学习主要分为同构在线迁移学习(homogeneous online transfer learning,HomOTL)和异构在线迁移学习(heterogeneous online transfer learning,HetOTL)[16]。HomOTL 中源域和目标域的特征空间,即特征的种类和个数相同,而在HetOTL中,源域和目标域的特征空间不同。
3 理论分析
3.1 总体框架
本工作提出的HomOTL-UIT 算法在整体框架上与HomOTL 类似,分为源域和目标域,但是在算法内部实现上引入下采样和批量增量学习部分。该算法的结构和流程如图2所示。
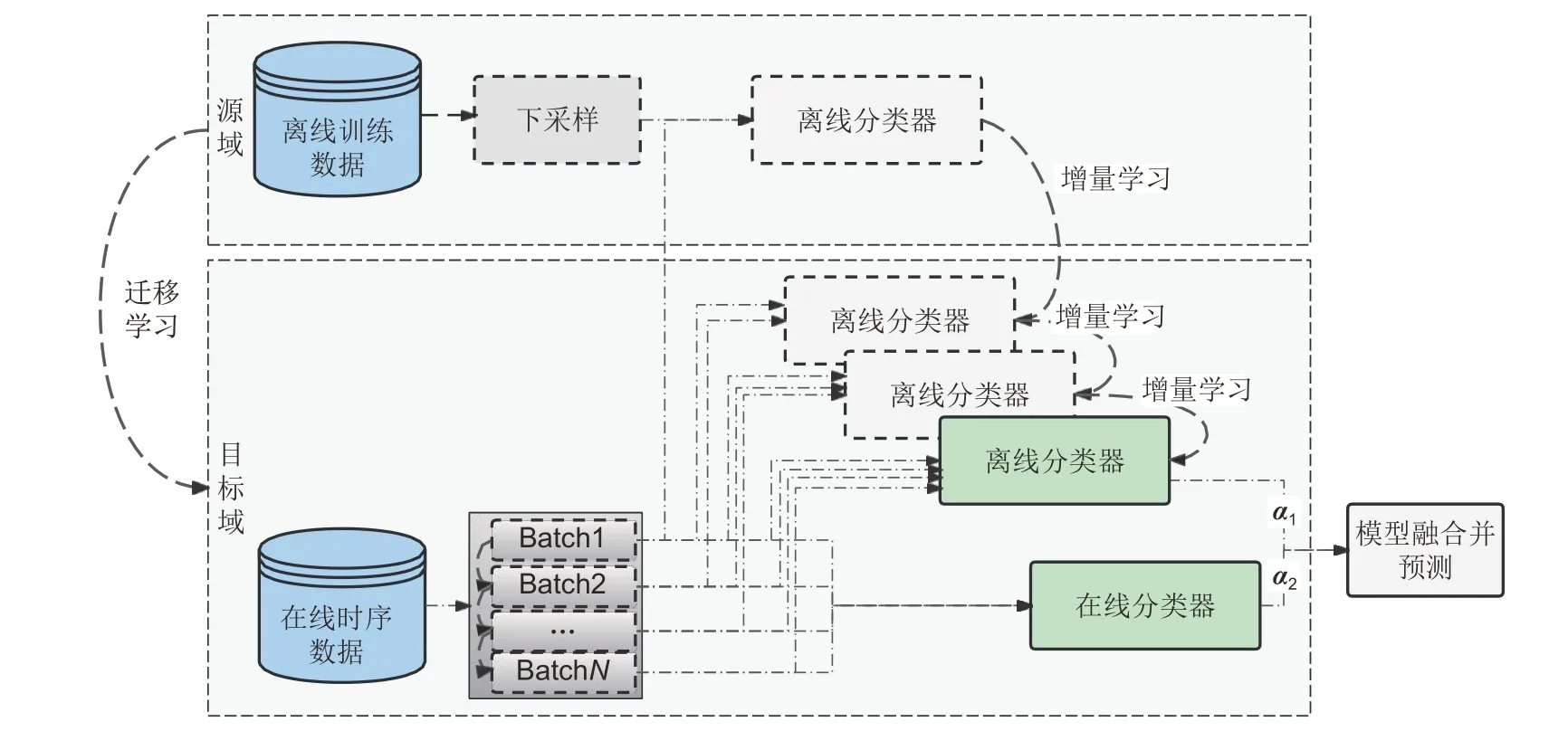
图2 HomOTL-UIT算法Fig.2 Schematic diagram of HomOTL-UIT algorithm
最外层两方框分别表示源域和目标域,要实现源域到目标域的迁移学习;源域中获取离线训练数据,然后下采样;与此同时,目标域中的在线时序数据进行分批处理,分批数据与下采样后的数据进行合并,合并后的数据训练离线分类器;随着时间的推移,每次分批数据都要训练离线模型,实现离线模型的增量学习;同时,每次的分批数据训练在线分类器;α1、α2分别代表离线分类器和在线分类器的权重,在线学习的过程中,会根据损失函数更新α1、α2,通过集成学习的思想提高算法的准确度。
3.2 分段下采样策略
通常在使用迁移学习解决数据分布偏移的问题时,目标域的数据量较少,而源域的数据量较大。此特点在故障预警中更为明显,而且正负样本比例严重不平衡。异常时间点不久前的数据往往更具有价值,因为模型可以在故障发生前学习到前期细微的特征。比如电池在发生故障之前,电压数据将发生异常变化[21]。
图3表示不同电芯、不同时间下异常发生时,电芯的电流、电压、温度和荷电状态(state of charge,SOC)的变化情况。子标题中逗号分割后依次表示:簇架号,Pack 号,电芯号和日期。可看出异常发生前,电芯有相似的整体特征,但又有细微的差异,前期这些细微的差异对模型的学习至关重要。

图3 异常发生时的数据分布情况Fig.3 The data situation before the exception occurred
然而,故障发生的N小时前或者N天前的样本对短时序的预测来说,模型的重要性相对较低。所以故障预警场景下,本工作采用分段下采样策略,异常时间点后不采样,异常时间点前采样比例依次减少。
如图4所示,若8:10发生异常,则异常时间点的前10分钟内(8:00—8:10)的数据,采样个数为总采样个数的35%;7:30—8:00采样个数为总样本个数的30%;同理,6:30—7:30采样20%,4:00—6:30采样10%,00:00—4:00 采样5%。异常时间点之前的数据,通过下采样处理后,使用采样后样本训练离线分类器。正样本的比例提高使得离线分类器更容易学习到异常样本的特征。因此,本工作引入的分段下采样技术,解决样本不均衡问题,并且减少样本数量,降低计算资源的使用。

图4 分段下采样策略Fig.4 Schematic diagram of segmentation downsampling strategy
3.3 分批增量学习
为方便算法步骤的描述,将不同符号所表示的含义列于表1。
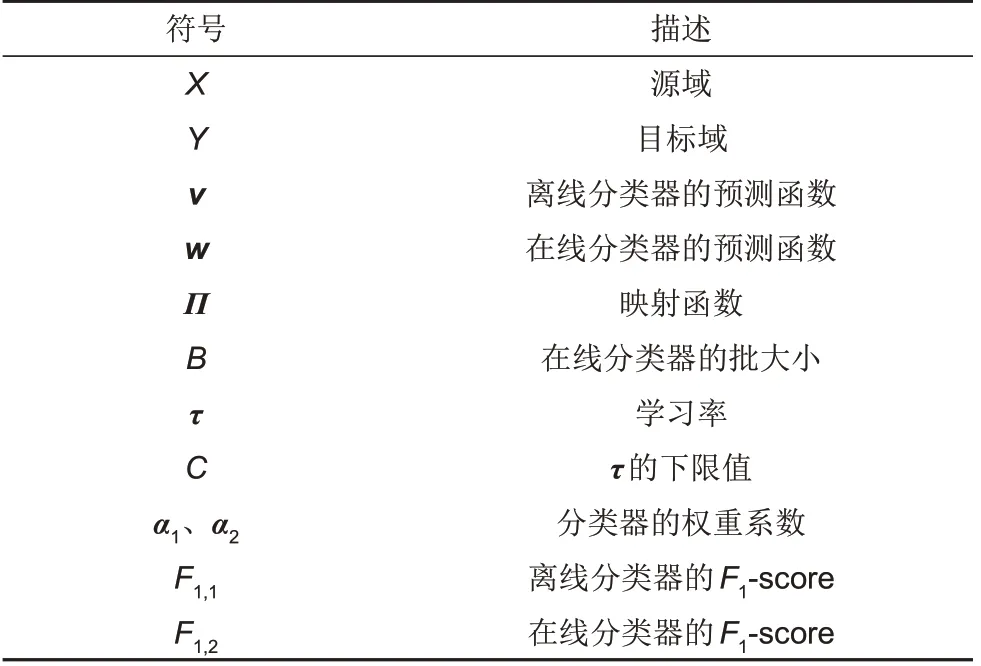
表1 不同符号的含义Table 1 Meaning of the different symbols
当源域X和目标域Y的数据差异很大时,离线分类器v如果仅仅根据源域的数据进行训练,则离线分类器的预测误差始终最大。即离线模型在迁移学习中的权重α1始终为0,使得在线迁移学习退化成在线学习。为解决此问题,本工作采用分批增量学习的方法进行模型的训练。
分批增量学习,首先源域中训练的离线分类器需要在合适的时间进行更新,以此来适应目标域中不断变化的数据分布,从而解决数据分布偏移问题。在目标域中,为降低多次训练带来的计算资源的开销,将在线数据进行分批处理,通过增量学习,不断从目标域中学习,从而不断提高离线分类器的准确度。
如图5 所示,Xs为分批后的源域数据,Yt1、Yt2、Yt3,…,Ytn为分批后的目标域数据。时序数据到达分批的时间时,进行下采样处理,然后对离线分类器进行全量数据x1,t的离线模型训练,图中,t=0 时,使用源域中的数据Xs训练离线分类器v;若t=1 时,到达分批处理的时间点,此时使用源域中的数据Xs和目标域中的数据Yt1训练离线分类器v;同理,若t=2 时,到达分批处理的时间点,此时使用源域中的数据Xs,目标域中的数据Yt1和Yt2训练离线分类器v。每次分批处理后都要更新模型权重α,最后根据模型权重α进行模型融合求取最终预测结果。
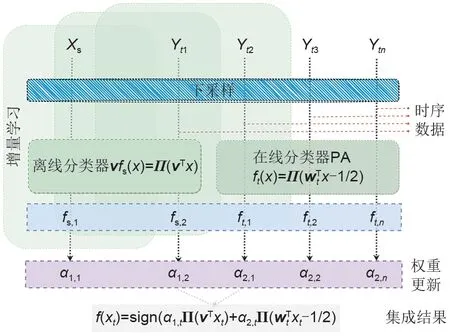
图5 算法结构Fig.5 Structure of HomOTL-UIT algorithm
3.4 组合权重的更新
混淆矩阵(表2)能够有效而全面评估分类模型的性能。通常用于评估多分类或单标签分类模型[22]。
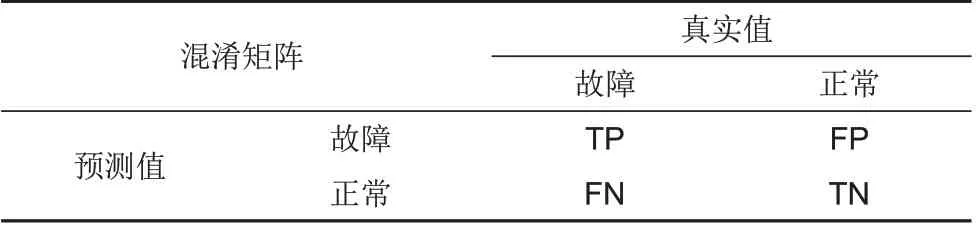
表2 混淆矩阵Table 2 Confusion matrix
根据混淆矩阵可以计算出分类模型的性能评价指标。精准率P(Precision)[式(1)]表示预测为正例的样本中预测正确的比重。当数据集不平衡时,P不能再用来度量分类模型性能,因为它对大多数类提供过度乐观的估计[20]。
召回率R(Recall) [式(2)],表示实际为正例的样本中预测正确的比例。
F1-score [式(3)]是精准率和召回率的调和平均。调和平均数的特点是易受极端值影响,该特点的具体表现如下:
(1)精准率和召回率都很高时,F1-score很高;
(2)精准率和召回率都很低时,F1-score很低;
(3)精准率和召回率中的一个很高,另一个很低,F1-score为中等。
单纯追求精准率,会造成分类器或者模型少预测为正样本,这时FP 低,P就会很高。故障预警中,由于正负样本极度不平衡,正样本极其稀少,而负样本较多,所以本工作更关注正样本的评分情况,同时,根据调和平均数易受极端值影响的特点,即精准率和召回率过大或过小都会使F1-score变低,需要兼顾精准率和召回率,所以使用F1-score更能反映分类模型的性能。
在线迁移学习中分类器的权重更新相关的原理见式(4)。
式(4)中损失函数为(z-y)2,其中变量z表示预测值,变量y表示真实值,u表示分类器,n表示学习率,整个公式表示使用分类器u时预测值和真实值之间的误差大小。该损失函数考虑的是正负样本的预测情况,故障预警中,由于正负样本比例严重不平衡,对于负样本的预测一般都比较准确。然而,本工作更关注正样本的预测情况,所以在模型训练的过程中,使用F1-score 进行度量模型的误差。t+1 时刻的权重由上一时刻的分类器的损失值占全部损失值的比例来决定[式(5)]。
在线迁移学习的模型误差考虑的是FP 和FN,离线分类器的FP+FN个数始终小于PA模型的,因为统计的是累计值,在线模型前期在试错,所以错误比较多,后期在线模型如果不能更优越,累计错误会始终很高,所以在线学习的过程中,离线分类器的权重会缓慢向1趋近。为解决这种权重缓慢失衡问题,使用当前的一个时间窗口,评估离线模型和在线模型,然后确定模型的权重。使用累计的FP+FN 评估在线模型不能反映当前模型的情况,设置评分的时间窗口,保证评分能准确表示在线模型的当前误差。
随着时间的推移,固定窗口大小的滑动窗口,不断新加入数据,并且去除旧的数据,F1-score仅根据当前时间下滑动窗口内的数据进行计算,从而保证模型评分是最新的(图6)。
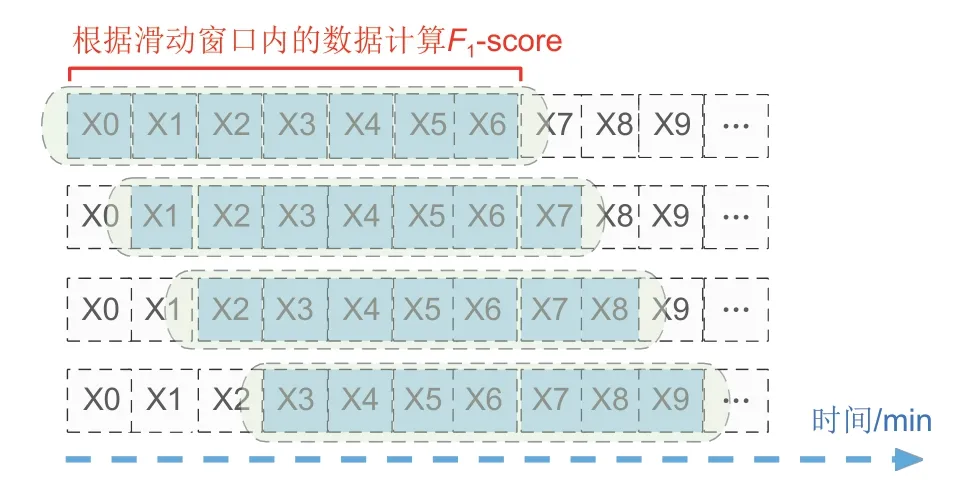
图6 滑动窗口下的F1-score示意图Fig.6 Schematic diagram of F1-score under sliding window
然后使用基于滑动窗口下的F1-score进行权重更新[式(6)],F1,1t表示t时刻离线模型的F1-score,F1,2t表示t时刻在线模型的F1-score。
最后,使用预测函数[16][式(7)]进行模型融合,其中sign 函数为符号函数,将最终结果映射成-1或1,Π函数实现归一化。
总体的算法步骤如下:
Algorithm 1 展示HomOTL-UIT 算法的整体步骤。首先,算法的输入为:离线分类器ν、批大小B和系数τ的下限值;初始化PA 算法函数[16]w和模型权重α。然后随着时间t的推移,不断接收时序数据xt;对接受的时序数据进行下采样(序号3);然后通过预测函数预测出结果ŷt(序号4);接收真实数据yt;计算下一时刻(t+1)的模型权重α1、α2,其中,Precison和Recall是根据预测数据ŷt和真实数据yt计算得到(序号6);计算真实数据和预测数据的损失值lt(序号7);当累计的数据量达到分批大小时,更新离线分类器ν(序号8~10);最后,当存在预测错误时,更新PA算法函数w。
4 实 验
电池故障类型较多,本工作主要针对电池高压故障进行生产环境下的验证。
4.1 不同电芯的数据分布情况
生产环境下电芯的基础信息见表3。

表3 电芯信息Table 3 Battery cell infomation
由于电芯A 先上线运行,已经存在大量的数据,但是电芯B为后上线运行,数据量较少。本工作希望通过电芯A的数据训练模型,能从电芯A中学习到一些电池高压故障的前期症状,并且根据这些症状也能推断出电芯B的健康状态。因此首先需了解两种电芯在数据分布上的差异[23]。
本工作以数据分布图的形式展现5天(2022-10-02、2022-10-16、2022-11-27、2022-10-30、2022-11-13)的数据分布情况。在图7中,图(a)、(b)为电芯A和B的电压折线图和数据分布图,从图7(a)可以看出,电芯A和B在一天内的电压变化情况有较大差异;从图7(b)可以看出,电芯A和B在电压数据分布有很大差异;图7(c)、(d)展示的是电芯A和电芯B的温度的折线图和数据分布图,可以看出电芯A和B温度的数据分布发生了偏移;同理,从图7(e)、(f)可以看出电芯A和B电流的数据分布发生了较大的偏移。综上所述,可以得出电芯A和B的数据分布发生了更大的偏移。
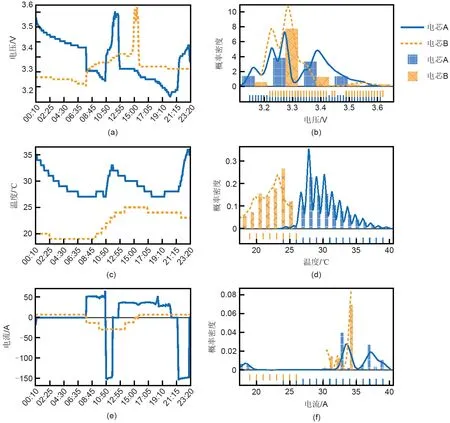
图7 告警发生时的数据分布情况Fig.7 Data distribution when an alarm occurs
4.2 分类器性能评分
4.2.1 训练过程中的评分
训练过程中,使用部分未参与训练的数据对模型进行的评分,能够反映模型的性能。
图8 为迁移学习算法在训练过程中的评分情况。训练集正负比例为1∶10。其中图8(a)表示的是在线迁移学习的评分情况,Offline 模型使用SVM 实现,可以看出训练过程中,SVM 的评分始终很低,说明在数据分布发生偏移的情况下,传统机器学习技术已经不再适用。PA为在线学习算法,通过不断纠错来提高模型的准确性[20]。图8(b)是HomOTL-UIT训练过程中的评分情况,其中Offline模型使用LightGBM 实现,可看出Offline 模型的评分明显提高。图8(c)是LightGBM、HomOTL 和HomOTL-UIT的评分对比,可以看出HomOTL-UIT算法评分始终高于其他模型。
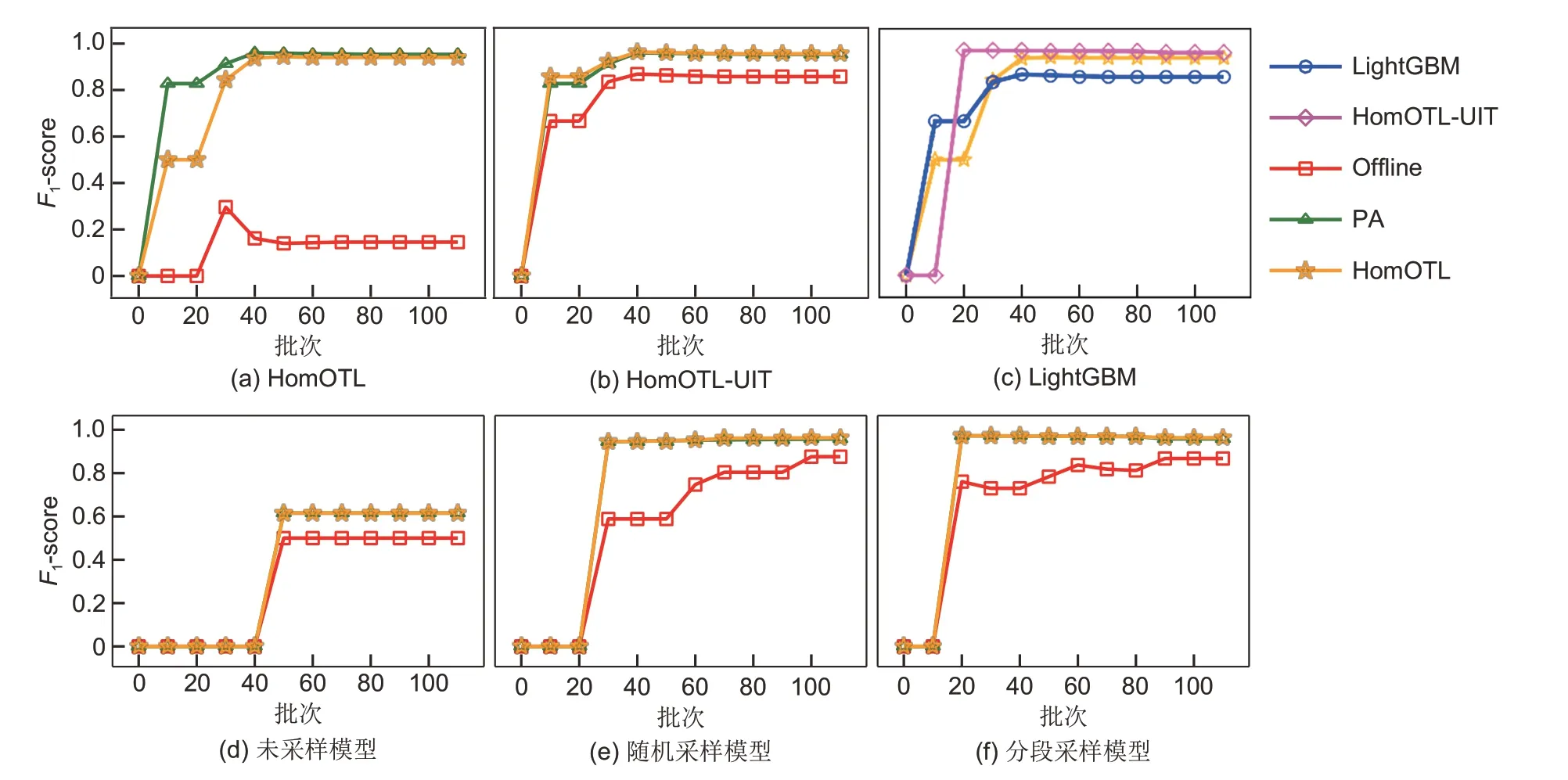
图8 训练过程中的评分情况Fig.8 Scoring during training
不同的采样策略对模型的影响不同,如图8(e)~(g)所示,图8(e)展示不进行采样时的模型评分情况,可以看出模型训练过程中,F1-score始终很低;图8(f)展示随机采样后模型的评分情况,结果表明,采样相比不采样评分更高;图8(g)展示分段采样后的模型评分情况,可以看出分段采样在分批到达20 后,明显高于随机采样,并且最终的评分也高于随机采样。因此,本实验验证了分段采样策略的有效性。
4.2.2 测试集的模型评分
测试集评分是使用B电芯最后3天(2022-11-13、2022-11-20、2022-11-27)的电池高压故障相关数据,这3天数据未参与过模型的训练,能够反映算法模型的最新评分情况。
表4展示HomOTL模型、SVM模型、LightGBM模型和HomOTL-UIT 模型在测试集的评分情况。可以看出,HomOTL模型和SVM模型在1989条数据中,39 条故障都没预测出来,说明在数据分布发生偏移时,HomOTL模型和SVM模型性能较差;LightGBM模型仅能预测在1989条数据中,不存在误报情况,但是39条故障中仅预测出8条。

表4 测试集的模型评分Table 4 Model scores on the test set
表4中第7条对应的混淆矩阵见表5。

表5 正负样本严重不平衡时混淆矩阵Table 5 Confusion matrix when positive and negative samples are seriously unbalanced
本工作提出的HomOTL-UIT 算法在1927 条数据中(表4中序号4),39条故障预测出37条,仅2条漏报,并且不存在误报情况;在17434 条数据中(序号6),39条故障预测出37条,仅2条漏报,并且仅4 条误报;在26526 条数据中(序号7),39 条故障预测出37 条,仅2 条漏报,并且仅8 条误报。由此说明,HomOTL-UIT算法不仅在正负样本比例不均衡的情况下能较为准确地预测故障,而且在样本严重不均衡时,也能达到较高的准确率。
5 结论
在储能领域的电池高压故障预警方向,提出HomOTL-UIT算法模型,主要的结论总结如下。
(1)针对正负样本不均衡问题,设计出一种新的采样策略。
(2)提出分批增量学习的方法,解决在线迁移学习退化为在线学习的问题。
(3)针对模型权重缓慢失衡问题,提出一种新的模型评估方法,即滑动窗口下的F1-score,解决模型权重缓慢失衡问题,从而提高模型的准确性。
最后,本工作使用生产环境下的两种真实电芯的储能集装箱数据对算法进行验证,并与当下常用的算法模型(如SVM、LightGBM 和HomOTL 等)进行对比,结果表明HomOTL-UIT 算法具有较高的准确性。本工作提出的HomOTL-UIT 算法模型在储能领域电池上取得了较好的效果,在新能源汽车领域也具有实际的应用价值,切实降低电池的安全隐患,为实现动力电池的故障预警和提高动力电池的安全性提供了一条新的路径。
