基于HLS和PYNQ图像缩放的硬件加速器设计
2023-08-26赵思捷高尚尚王如刚王媛媛周锋郭乃宏
赵思捷 ,高尚尚 ,王如刚 ,王媛媛 ,周锋 ,郭乃宏
(1.盐城工学院 信息工程学院,江苏 盐城 224051;2.盐城雄鹰精密机械有限公司,江苏 盐城 224006)
随着现代电子技术的迅速发展,人们对机器视觉以及图像处理的要求逐渐提高。目前,图像处理技术主要集中在基于PC机、DSP等传统平台技术和基于现场可编程门阵列(field programmable gate array,FPGA)硬件平台技术等[1-3]。基于传统的PC机平台中,存在体积较大、不方便携带以及对高速图像信号难以实时处理等缺点,使得该技术不能运用在无人机侦查等场合。基于DSP平台的技术中,只能处理某些特定的图像算法,不能实现实时图像信息的采集与处理;若利用多个DSP芯片并行运算实现快速处理,则大大提高了系统的成本。FPGA是在可编程器件PAL、GAL、CPLD的基础上进一步发展的产品,可以更加高效地处理数据,既解决了定制电路的不足,又克服了原有可编程器件门电路个数有限的缺点。但FPGA使用的是硬件描述性语言,开发难度大、可移植性差,因此利用FPGA对图像进行实时处理是一种挑战。
近些年,随着Xilinx公司高层次综合(highlevel synthesis, HLS)工具的运用,可以使用C、System C 和C++语言代替传统的Verilog语言进行编程,大大降低了开发难度,减少了开发时间[4];而PYNQ框架的出现不仅缩短了开发周期,提高了开发效率,还可以实现高性能应用程序如并行硬件执行、实时信号处理、高帧率视频处理和硬件加速算法等[5]的运用。
由于HLS工具可以减少FPGA的植入时间,而PYNQ框架可以提高生产力[6],因此它们在理论研究中得到了大量的运用。Vashist等[7]使用HLS提供的xfOpenCV库实现了Canny的边缘检测,提出了使用xfOpenCV库可以更好地检测带有噪声图像的边缘,但是它并没有在PYNQ框架上使用;张瑞琰等[8]提出了基于PYNQ框架的高精度异构无预选框检测模型,处理时长由ARM端的9.228 s缩减到FPGA端的0.008 s,大大提高了检测模型的速度;Cui等[9]提出了基于PYNQ框架的核相关滤波异构跟踪系统,该系统具有良好的实时性,跟踪速度平均为27.9 帧/s,具有较高的执行效率,易于开发和移植,具有一定的工程参考价值。
基于以上研究,本文提出了基于HLS和PYNQ的图像处理硬件加速器设计,利用HLS工具实现缩放算法,再经过优化、仿真、综合后生成IP核;在Vivado 2018.3硬件平台上连接IP核,并输出硬件描述文件和比特流文件;把PYNQ镜像复制到SD卡并启动开发板,再在浏览器上打开Jupyter Lab进行运行验证和分析。
1 缩放算法
在图像处理过程中,图像缩放是对图像大小作一定的调整,目的是为了适应显示区域的大小。图像缩放包含图像的缩小和放大,分别称为图像的下采样和上采样,一般是利用图像的插值实现的。常见的图像插值算法有最近邻算法、双线性插值法和双三次插值法等[10-11],其中最近邻算法具有计算量小、算法简单、处理速度快、占用资源少等特点,但采样后的图像具有明显的不连续现象,且图像放大时会出现马赛克,缩小时会有失真现象;双线性插值法具有连续性好,缩小时具有较好的图像品质,但放大时会有一定的细节损失;双三次插值法具有计算精度高、图像品质好等特点,但算法复杂、计算量大。
经综合比较,本文采用双线性插值法进行加速测试,原因是双线性插值法比最近邻算法只是计算量稍大一些,但缩放后图像质量高,基本克服了最近邻插值算法灰度值不连续的特点。
双线性插值又称为双线性内插,即在两个方向上分别进行一次线性插值(在一个方向上使用线性插值,然后在另一个方向上再使用线性插值执行双线性插值),如图1所示。
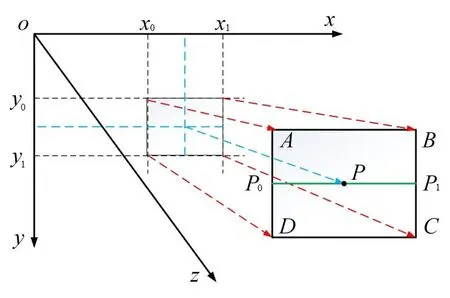
图1 双线性插值坐标Fig. 1 Bilinear interpolation coordinates
图1中,设二元函数z=f(x,y),A、B、C、D点的坐标分别为(x0,y0)、(x1,y0)、(x1,y1)、(x0,y1),若P点的横、纵坐标分别为x'、y',则要在A、B、C、D中通过插值法计算点P的z轴坐标z',计算步骤如下:
(1)根据AD与BC的线性关系,得:
(2)设P0、P1分别为线段AD、BC上的任意一点,其z轴坐标分别为Z0、Z1,令α=(x-x0)/(x1-x0),则P0、P1的z轴坐标分别为:
(3)令β=(y-y0)/(y1-y0),则P点在z轴上的坐标z'为:
整理式(4),得z'表达式为:
2 硬件加速器设计
2.1 系统整体设计
根据对缩放算法的特性分析,可以发现执行缩放算法时一方面需要系统控制和过程调度,另一方面需要大量的计算。因此,硬件加速器的实验开发板采用Xilinx公司的ZYNQ-7000系列XC7Z020CLG400-2芯片为核心,实验平台采用Vivado2018.3、HLS 2018.3以及Firefox。
在缩放算法中,由于涉及的数据重复程度高,但计算结构并不繁琐,因此采用具有并行加速度特性的PL(programmable logic)端来实现(即FPGA来实现);算法涉及的复杂结构化过程控制与调度部分,由PS(processing system)端来实现(即ARM来实现)。PS与PL的互联完成了硬件加速器控制流与数据流的交互。
硬件加速器整体系统如图2所示。从图2可以看出,该系统分成3部分。在第一部分的HLS里,编写缩放算法的C代码和C测试代码;功能验证成功后,添加优化指令并进行高层次综合;高层次综合后再对结果进行评估。评估时,如果速度、资源等不满足条件,则需要重新优化设计,直到满足条件后,导出RTL作为IP核。第二部分由开发板的PL端和PS端组成,PL端的作用是在Vivado平台上设计Block design并连接IP核,然后导出.hwh文件和.bit文件;PS端的作用是在ARM上启动装有PYNQ镜像的SD卡。第三部分是通过网线或者USB连接PC端,在Firefox上打开Jupyter Lab运行代码并查看结果。

图2 整体系统框图Fig. 2 Block diagram of overall system
2.2 HLS设计
为了加速传统“寄存器传输级(register transfer level,RTL)”开发FPGA的时间,Xilinx公司推出了可以提升行为抽象等级的编译器Vivado HLS。该编译器可以使用C++对算法进行设计开发,并最终综合成HDL描述。
HLS设计流程如图3所示。在编写C代码时,首先使用hls::AXIvideo2Mat函数将AXI4-Stream格式的输入图像转换成HLS工具可以处理的hls::Mat格式,然后调用HLS Video Library 里的函数或者自定义算法函数进行图像处理,最后使用hls::Mat2AXIvideo函数将hls:Mat格式的图像转换成FPGA可以处理的AXI4-Stream格式;同时结合C测试代码验证算法功能的有效性,并进行高层次综合;然后根据高层次综合的评估结果,观察FPGA中的资源使用情况,以及支持的最高时钟频率是否满足条件等。如果不满足条件,则需要重新优化,直到满足条件为止,然后导出IP核。

图3 HLS设计流程图Fig. 3 Flow chart of HLS design
在上述过程中还需要对代码进行优化,而优化HLS代码的方式有约束和指令两种。约束是指对时钟周期、资源利用情况等指标进行限制,确保实验结果能够满足系统要求;而指令的添加可以优化C代码中的循环、数组和运算延时等,能够在很大程度上改变RTL的输出结果。因此,本文在设计缩放算法代码时,添加了如下优化。
(1)#pragma HLS UNROLL:FPGA可以实现并行处理,所以代码可以展开循环,并创建多个独立的操作,即在单个时钟里并行处理for循环中的操作。
(2)#pragma HLS PIPELINE:PIPELINE可以允许上一个操作完成前,同时执行下一个操作,即循环流水线操作,以提高系统的吞吐率。
(3)#pragma HLS LOOP_FLATTEN OFF:可以防止优化等级过高,把嵌套循环结构优化成单层次循环结构。
(4)#pragma HLS dataflow:可以使各个图像处理函数能够并行执行,并获得高质量处理结果。
(5)将输入图像和输出图像综合成AXI4-Stream接口:
#pragma HLS INTERFACE axis port=INPUT_STREAM
#pragma HLS INTERFACE axis port=OUTPUT_STREAM。
(6)将图像行数和列数配置成AXI4-lite接口:
#pragma HLS INTERFACE s_axilite port=rows
#pragma HLS INTERFACE s_axilite port=cols。
在高层次综合后,经对综合结果评估后得到资源占用情况,如表1所示。从表1可以看出,缩放算法占用资源较少,能够满足系统的要求。

表1 缩放算法占用资源情况Table 1 Resource usage of scaling algorithms
2.3 Overlay设计
Overlay设计本质上就是ZYNQ的PL端设计,它既可以加速软件应用程序,也可以定制相应的硬件平台。
缩放算法的Overlay系统框图如图4所示。图4中1号位置所指的IP是HLS综合后导出的缩放IP,它采用的是双线性插值算法,上采样支持小于或等于8倍的放大比例,下采样支持大于或等于25%的缩小比例。2号位置所指的IP是Vivado平台自带的IP,可以直接添加。DRAM中的数据是DMA IP利用位宽转换IP将32位图像数据转换成缩放IP可处理的24位图像数据;数据处理完毕后,将24位图像数据转换成32位图像数据,再经过DMA传到DRAM。其余方框是系统根据设计自动生成的。

图4 缩放算法的Overlay系统框图Fig. 4 Block diagram of Overlay system with scaling algorithm
IP核添加完成后,进行配置和连线,从而完成Overlay的设计。
2.4 PYNQ 框架
随着Python的流行,Xilinx公司推出了可以使用Python语言和特定库的PYNQ框架。该框架利用ZYNQ中的FPGA和ARM快速构建高性能的嵌入式应用程序,不仅免除了传统的SDK开发方式,还代之以不限平台的浏览器开发,极大地方便了软件开发人员使用硬件设备。PYNQ框架包括以下几层:
(1) FPGA为主的硬件层:FPGA部分的设计被称为Overlay设计,在Vivado2018.3平台上搭建并连接好IP核后,点击综合分析,在生成bit流文件后,就可以在软件上调用API,实现FPGA逻辑功能的动态切换以及PS和PL的协同交互。
(2) Linux内核加Python为主的软件层:主要是运行在ZYNQ的ARM端,可以通过Python调用API库来访问FPGA端的处理单元。
(3) Jupyter Lab为主的应用层:Jupyter Lab是一个基于浏览器的交互式实验环境,在这环境里,可以使用Python语言运行代码、查看结果和可视化分析等。
3 实验与结果
在Firefox上打开在线编辑工具Jupyter Lab,然后导入文件库,下载Bitstream文件,最后将准备存放在SD卡中图片加载到DDR3中。图片加载完成后,Jupyter Lab会显示原始图像的尺寸。为了方便调用,可以创建 DMA 和Resize IP对象,然后通过Overlay字典查看DMA IP和Resize IP的配置信息(IP字典会显示具有 AXI Lite 接口且需要用户进行控制调配的AXI IP)。
鉴于计算复杂,Jupyter渲染大图片时可能需要一段时间。为了获得更好的视觉效果,可以将显示图片的画布在Jupyter Lab上增加一倍。
图5为在Jupyter Lab中实现Resize IP的情况。由图5可知,加载的测试图片大小为3840 pixels×2400 pixels,在Jupyter Lab上执行Resize IP后的图像大小为1920 pixels×1200 pixels,测试图片缩小为原图像的一半。此外,本文在Jupyter Lab上还设计软件版本的缩放算法,该算法是由Python环境和PYNQ框架提供的OpenCV库实现的。

图5 在Jupyter Lab中实现Resize IPFig. 5 Implementing Resize IP in Jupyter Lab
Resize IP执行时间如表2所示。从表2可以看出,软件实现本文算法的执行时间为1110 ms,而硬件实现本文算法的执行时间为213 ms,硬件加速下处理性能提升了5倍左右。

表2 Resize IP执行速度Table 2 Execution speed of Resize IP
4 结论
针对CPU上无法满足图像实时处理的需求,提出了一种基于PYNQ框架的图像处理加速器设计。首先选取缩放算法作为图像加速测试的算法,再利用HLS工具使用C++语言完成了Resize IP的设计,最后在Jupyter Lab上完成了算法的验证与分析。
实验结果表明,基于PYNQ硬件平台的执行速度约是软件平台的5倍,极大地提高了算法的处理速度;并且硬件平台系统是模块化IP设计,便于移植和二次开发,在计算机图像处理领域具有一定的工程应用价值。
