基于变分贝叶斯深度学习的水文概率预报方法
2023-08-17李大洋姚轶梁忠民周艳李彬权
李大洋 姚轶 梁忠民 周艳 李彬权


摘要:目前水文领域关于深度学习的研究多集中于提高预测能力方面,与具有物理机制的水文模型相比,深度学习复杂的内部结构导致其不具备可解释性,预测结果难以被信任,因此发展可信赖的深度学习对于推进水科学发展具有重要意义。基于预报残差分析框架,构建具有物理机制的水文模型与深度学习融合的混合模型,以充分利用两者优势;引入变分贝叶斯理论,提出变分贝叶斯与深度学习耦合的概率预报模型VB-LSTM,以定量评估水文预报结果的不确定性、提高结果可靠度。以黄河源区1961—2015年的径流过程为研究对象,对VB-LSTM模型进行应用示例研究。结果表明:与长短时记忆网络(LSTM)相比,VB-LSTM模型在验证期预报精度更高,结果更稳定;与传统基于“线性-正态”假设的水文概率预报方法相比,VB-LSTM模型具有更高的预报精度,且不确定性更小、预报结果更可靠。
关键词:水文概率预报;深度学习;变分贝叶斯;长短时记忆网络;混合模型
中图分类号:TV124;P338
文献标志码:A
文章编号:1001-6791(2023)01-0033-09
收稿日期:2022-10-14;
网络出版日期:2023-02-01
网络出版地址:https:∥kns.cnki.net/kcms/detail∥32.1309.P.20230131.1533.005.html
基金项目:国家自然科学基金资助项目(41730750;41877147)
作者简介:李大洋(1992—),男,江苏徐州人,博士,主要从事水文水资源方面研究。
E-mail:dayangli_hhu@foxmail.com
通信作者:梁忠民,E-mail:zmliang@hhu.edu.cn
1990年以来,机器学习在水文领域不断应用发展。人工神经网络(ANN)、循环神经网络(RNN)、支持向量机(SVM)、最近邻算法(KNN)等一系列模型被广泛应用于降水预报修正、径流预报、土壤水分预测、地下水位预测等水文领域的各个方面[1-2]。近些年,深度学习作为一种特定类型的机器学习日益受到水文学者的广泛关注。与传统的“浅层”机器学习相比,深度学习通过复杂结构或多处理层进行多层次、多维度的数据抽象处理,一些研究显示深度学习模型如长短时记忆网络(LSTM)在水位、径流、土壤水等方面展现出了更强的预测能力[3-5]。然而,与具有物理机制的水文模型相比,深度学习无法真正理解水文过程及其物理规律,其结构复杂难以被解释,导致预测结果难以被充分信任,如何构建可信赖的深度学习是当前研究的热点与难点[6]。
预报残差分析模型[7]作为一种在水文领域应用广泛的概率预报后处理模型,提供了将具有物理机制的模型与深度学习模型相结合从而充分发挥两者优势的途径,有望在提高深度学习预测结果可信赖程度方面发挥作用[8]。贝叶斯理论是进行水文概率预报的通用框架[9-10],将贝叶斯理论应用于深度学习可以实现概率预报并对预测结果可靠度进行评估,然而其中常用于估计参数后验分布的抽样算法——马尔可夫链蒙特卡罗法(MCMC)的收敛速度偏慢,消耗计算资源较多,难以进行高维参数估计。Vrugt等[11]指出采用MCMC算法估计地下水模型MODFLOW中的241个参数需花费数月才能完全收敛。深度神经网络的参数数量一般远高于这个量级,难以采用MCMC算法在有效时间内(如1~3 d预见期)估计众多参数的不确定性并提供概率预报。Fang等[12]通过蒙特卡罗暂退算法(Monte Carlo Dropout,MC Dropout)估计深度神经网络LSTM参数的不确定性,实现了土壤水的概率预报。MC Dropout是一种将正则化算法Dropout解释为高斯过程的贝叶斯近似,有望在不增加计算成本的情况下实现深度学习的概率预报。但一些学者认为MC Dropout算法并非基于贝叶斯理论,无法正确估计参数并提供合理的不确定性分析[13];此外,该算法专为神经网络设计,无法用于水文领域其他高维参数估计问题。变分贝叶斯(Variational Bayes,VB)[14]是解决贝叶斯推断问题的新兴方法,与MC Dropout相比,VB方法理论基础与适用性更强;与MCMC算法相比,VB的计算效率更高。VB方法的本质在于能快速寻找参数化分布族的最佳近似分布,因此,对估计高维参数等问题具有显著优势。
本文引入一种基于变分贝叶斯理论的最新算法——随机变分推断(Stochastic Variational Inference,SVI)[15],提出一种耦合SVI与LSTM的概率預报方法(VB-LSTM),作为水文模型的预报残差分析模型定量评估水文预报不确定性。为充分发挥物理模型与数据驱动模型的优势,采用分布式水文模型模拟径流过程,研究SVI算法的收敛性和时效性,分析VB-LSTM模型在减少水文预报不确定性和提高预报精度方面的优势。
1 方法原理
1.1 预报残差分析模型
预报残差分析模型是一种后处理方法,用于构建预报残差与预报因子矩阵X∈RD×T之间的线性或者非线性回归关系,其中,R为实数集,D为所选预报因子的个数,T为时间序列长度。此回归关系可写作
式中:yε=[yε1,…,yεT]∈R1×T为实测流量(记为向量yo)与模拟流量(记为向量ym)之差,被称为残差;ε=[ε1,…,εT]∈R1×T为随机误差项,通常被认为服从均值为0、方差为σ2的正态分布;参数向量θ=[θ1,…,θN]∈R1×N,其中,N为参数个数。水文预报不可避免地存在着误差[10,16],在水文预报残差分析模型中,建模者认为水文预报的所有误差(如数据观测、模型初值、模型参数、模型结构)均集中在yε中,通过分析和模拟残差从而达到量化预报不确定性的目的。
贝叶斯学派认为θ是随机变量且可以通过概率分布描述。根据贝叶斯公式,θ的后验分布为
式中:条件分布p(θ|yo)在贝叶斯中被称为后验分布;p(yo|θ)称为似然函数;边际分布p(θ)称为先验分布;p(yo)称为证据(Evidence)或归一化常数;符号∝表示“成正比例”。贝叶斯推断的关键是估计参数后验分布,但这很难直接获得,主要原因在于证据p(yo)=∫p(yo|θ)p(θ)dθ是一个积分,除个别理想情况外多数不可积。以MCMC为代表的贝叶斯抽样方法通过建立参数θ的马尔可夫链依次进行抽取样本。这意味着每次迭代过程中每个参数可获得1个抽样样本,但如果不符合一定条件,该样本将被舍弃。当参数过多时,MCMC抽样效率很低且难以收敛,需要更多的迭代次数[11]。变分贝叶斯方法采用已知的一组分布逼近真实后验的思路极大地提高了高维参数估计的计算效率。需要注意的是,变分贝叶斯方法的参数估计结果存在一定的偏差,因此,使用时需要在精度与速度之间做出权衡[17]。
1.2 变分贝叶斯方法
变分贝叶斯的主要思路是通过引入一组分布去逼近参数后验分布p(θ|yo),这组分布被称为变分分布,记作q(θ|Λ),其中Λ=[λ1,…,λN]∈RS×N是与模型参数θ=[θ1,…,θN]对应的变分参数矩阵,S意味着每个变分分布由S个变分参数控制。例如,假设变分分布为正态分布,则S=2,因为正态分布是由均值(μ)和方差(σ2)2个参数决定,该参数可以被称为变分参数,记作λ=[μ,σ2]。在变分贝叶斯计算中,Kullback-Leibler散度(DKL),又称相对熵,被用来量化变分分布与真实后验之间的距离。DKL可推导后表示为:
式中:Eq(·)为关于q(θ|Λ)的期望;p(yo,θ)为yo与θ的联合分布;(Λ)为证据下界(Evidence Lower BOund,ELBO),相当于变分贝叶斯方法的目标函数。
调整式(3)各项位置后可推导出
从在变分贝叶斯中,DKL被用来计算变分分布与真实后验之间的距离,最小化DKL可以最终得到近似的后验。最小化DKL的难点在于证据p(yo)难以被积分,导致DKL很难被计算。从式(3)可以看出,最小化DKL等价于最大化ELBO,因此,变分贝叶斯可以通过最大化ELBO的方式来获得后验分布的近似。最大化ELBO可以通过梯度优化算法获得,但ELBO中包含期望函数(见式(4))导致很难进行求导。Ranganath等[15]提出了一种目前最先进的变分贝叶斯方法——随机变分推断,该算法采用REINFORCE技巧解决此问题,详细介绍请见参考文献[15]。
1.3 变分贝叶斯与长短时记忆网络耦合模型——VB-LSTM
神经网络通常采用基于反向传播的梯度下降算法更新权重并最小化目标函数,得出最优的确定性预报结果,一般可称作确定性神经网络。然而,确定性神经网络中的众多参数使得预报结果具有明显的不确定性,预报结果难以被信任。贝叶斯理论提供了量化不确定性的基本框架,将贝叶斯理论用于神经网络参数不确定性量化并提供概率预报的方法可被称为贝叶斯神经网络[18]。图 1比较了确定性神经网络与贝叶斯神经网络的结构差异。本文采用变分贝叶斯训练先进的深度学习网络LSTM,构建耦合模型——变分贝叶斯深度学习网络VB-LSTM,作为水文预报中的预报残差分析模型并提供概率预报结果。
VB-LSTM模型由深度神经网络和变分贝叶斯方法两部分构成,因此,在构建VB-LSTM模型时需考虑两者的特点。进行变分贝叶斯估计时,需要在构建LSTM模型的基础上,合理地设置参数的变分分布、先验分布以及似然函数。下面具体介绍VB-LSTM模型的各个部分。
1.3.1 长短时记忆网络
长短时记忆网络是Hochreiter等[19]在1997年提出的一种特殊的循環神经网络。LSTM在RNN基础上引入了“门”,在一定程度上解决了标准RNN存在的梯度消失或爆炸以及长时记忆问题。LSTM网络的架构包含若干LSTM层和1个全连接层。全连接层一般用线性函数表示,负责在最后输出最终结果。每一个LSTM层由很多隐含单元(又叫神经元)组成,每个隐含单元又包括2个状态:隐含状态(又叫输出状态)和细胞状态。细胞状态是由3个门控制,分别是输入门、遗忘门、输出门。门负责决定信息的进入,其结构是一个Sigmoid层和点乘操作的组合。Sigmoid层将输入值转化成0到1之间的数值,数值大小代表了输入值通过的程度,其中0代表不通过,1代表都通过。还有一个候选细胞为细胞状态添加额外信息。具体公式可见参考文献[19]。
1.3.2 先验分布、变分分布与似然函数
先验分布代表了进行推理前对该参数或数据的认知。由于LSTM参数没有明确的物理意义或可解释性,因此,很难给出一个有意义的先验分布。在这种情况下,一般可以用无信息(Uninformative) 的均匀分布或者数学性质较好的正态分布描述。这里假定LSTM参数的先验分布服从正态分布,误差项的方差为了保证非负则服从均匀分布,表达式如下:
式中:N(0,1)为均值为0、方差为1的正态分布;U(0,1)为下界为0、上界为1的均匀分布。
在变分推断中,变分分布用来近似真实后验分布。本文假定LSTM参数的变分分布为正态分布,主要因为正态分布简单且具有良好的数学性质。为了保证误差项的方差估计为正,采用截断正态分布N′(·)作为变分分布。变分推断通过迭代不断更新变分参数(αi、γ2i、μ和2)从而控制变分分布逼近真实后验分布,迭代时需要设置初始变分分布。这里初始变分分布的均值设定为对应的先验分布均值,标准差为对应先验分布的1/10,写作:
似然函数用条件分布的形式衡量模拟值与实测值之间的吻合程度,似然函数的选择直接决定推断结果的合理性。为了使数据减少异方差性以及更服从正态分布,将Box-Cox转换应用于观测数据与模拟数据中。然后采用标准化减少变量的尺度差异,帮助SVI算法更快地收敛。在数据转换空间(·)中,假设随机误差独立同分布且服从均值为0、方差为常数σ2的正态分布。似然函数可以表示为
其中:
式中:y~to和 y~tm分别为t时刻经Box-Cox转换后的观测数据和水文模型模拟值;(y~to
-..y~tm)表示(y~to-y~tm)的标准化;x¨t表示 LSTM输入数据的标准化;λ1和λ2为Box-Cox转换的2个参数,根据文献建议固定λ1=0.2和λ2=0[20]。
2 应用实例
2.1 研究流域与数据处理
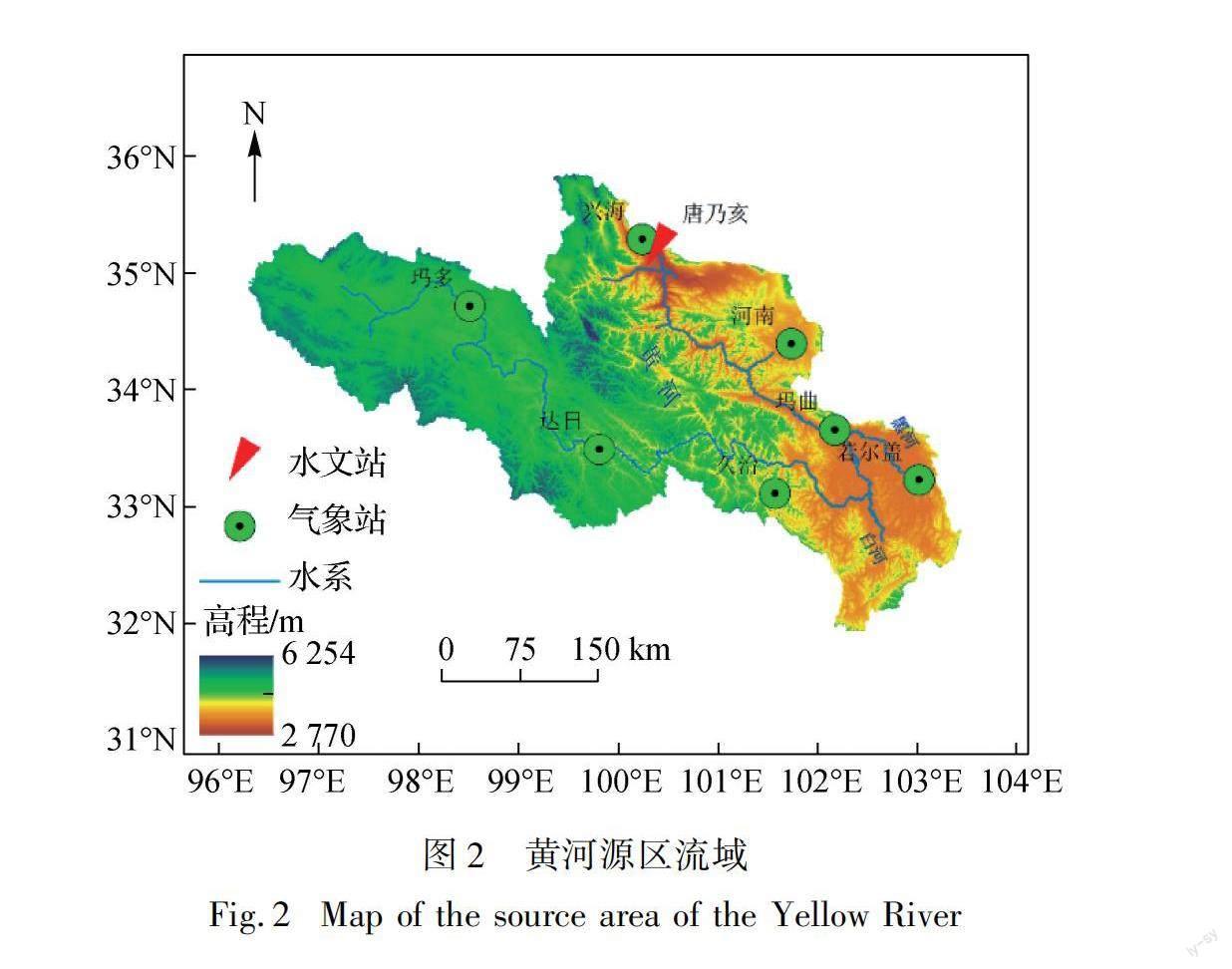
本文选取黄河源区即唐乃亥以上流域进行应用研究。黄河源区的高程、水文站点、气象站点及水系分布如图 2所示。流域面积约12.2万km2,约占黄河流域面积的15%。本文所需的气象数据包括降水、平均气温、最高气温、最低气温、相对湿度、平均风速和日照时数等日系列资料,除降水作为水文模型直接输入外其余气象数据主要用于计算潜在蒸散发(PET)。考虑到资料的一致性和完整性,本文收集了图中所示的流域内7个气象站和1个水文站的实测日系列资料,时间范围为1961—2015年。此外,收集了空间分辨率为90 m的数字高程模型(DEM)数据以及比例尺为1∶100万的土壤分类数据HWSD V1.1。采用反距离插值法将各类型数据插值到对应计算网格。
2.2 模型设置
本文采用分布式水文模型MIKE SHE模拟黄河源区1961—2015年的日径流过程。将模拟时段分成3部分,即预热期(1961—1965年)、率定期(1966—2000年)和验证期(2001—2015年)。由于研究流域面积较大(约122 000 km2),所以模型网格大小设置为5 km×5 km,总共约5 000个有效计算网格。采用数据中提取与人工率定相结合的方式率定MIKE SHE的参数,具体可见相关文献[21]。MIKE SHE模拟流量作为VB-LSTM的输入变量,将日模拟径流集成的月径流输入VB-LSTM构建月尺度的预报残差分析模型。选择月尺度主要有以下2点考虑:① 月系列数据比日数据资料长度更短,可以减少计算时间,便于研究随机变分推断SVI的收敛性;② 深度学习通常在大样本中表现优异,采用月尺度的小样本数据训练VB-LSTM,如果表现较好则可以在一定程度上说明VB-LSTM的通用性。
根据相关文獻[5]以及人工试错,VB-LSTM设置为1个包含20个隐含单元的LSTM层,后面接1个全连接层。在SVI中,采用梯度下降优化算法Adam最大化证据下界ELBO,其相关超参数采用默认设置如下:ρ=0.001,β1=0.9,β2=0.999以及=10-8。VB-LSTM最大迭代次数设置为50 000次。VB-LSTM在Python环境中运行并基于开源机器学习库Pytorch与概率模型工具库Pyro构建,计算采用服务器集群中英特尔CPU中的4颗核心。
2.3 结果分析
图3给出了ELBO值(NELBO)的迭代变化轨迹(N′ELBO为NELBO除以数据个数)。在SVI中,采用梯度下降优化算法Adam最大化证据下界来估计参数后验,设定最大迭代次数阈值为50 000。SVI的收敛性可通过观察NELBO的变化轨迹判断。如图3所示,NELBO的轨迹图不够平滑,有不少噪声。为方便观察收敛性,引入窗口为20的滑动平均函数处理NELBO(黑色线条)。可以发现当迭代次数超过30 000时平滑后的NELBO稳定不变,这时可认为NELBO已经收敛,并且收敛时的计算时间少于1 h,能够满足一定的预报时效性需求。此时,本文中的LSTM具有20个隐含单元的单层神经网络,参数数量为1 861个,这对于MCMC算法而言难以在该时间内完成如此多参数的后验估计。
采用ELBO收敛时刻的参数后验分布作为最优分布计算相应预报流量,如图4所示。为了与VB-LSTM比较,选择传统的基于“线性-正态”假设的预报残差分析模型,该模型中的回归模型即为贝叶斯线性回归模型(LR),并采用改进的MCMC算法(AM-MCMC)估计参数后验。引入“精度-可靠度”指标综合评价体系评估VB-LSTM概率预报结果。精度指标选择常见的纳什效率系数(ENS)、克林效率系数(EKG)以及平均絕对误差(EMA),可靠度指标选择概率预报评价指标区间覆盖率(Coverage Ratio,RC)、区间离散度(Dispersion of Interval,ID)以及连续排位概率评分(Continuous Ranked Probability Score,SCRP)。RC是指给定可信水平下的预测区间覆盖实测值的比例;ID是指该预测区间的平均宽度。从图4看出,与LR模型相比,VB-LSTM的90%预测区间更窄,说明预报结果不确定性更低;VB-LSTM的SCRP分别在率定期和验证期比LR模型低11%与10%;对于90%预测区间,VB-LSTM的ID分别在率定期和验证期比LR模型低15%和16%,并且有着更接近90%的RC。以上分析表明,VB-LSTM比LR模型的概率预报结果不确定性更小,预报结果更可靠。对于确定性预报结果(预报分布均值),VB-LSTM与LR模型均优于MIKE SHE,且VB-LSTM预报结果的精度指标ENS和EKG的值比LR模型平均高0.06,所以VB-LSTM模型预报精度更高。此外,将确定性神经网络LSTM作为MIKE SHE的后处理模型,预报结果与VB-LSTM作对比,如表 1中所示。LSTM设置为1个包含20个隐含单元的LSTM层,与VB-LSTM设置相同;采用Adam算法训练LSTM,目标函数为EMA,迭代次数为200;采用暂退法(Dropout)减少LSTM过拟合,暂退概率设置为0.5。从表1中ENS、EKG和EMA 3个精度指标可以看出,尽管VB-LSTM在率定期比LSTM预报结果稍差,但在验证期表现出了更好的预报结果,表明VB-LSTM预报结果更稳定,变分贝叶斯深度学习模型在一定程度上能够减少神经网络的过拟合现象。
尽管基于MCMC方法的参数后验估计更准确,可以近似于参数的真实分布,但难以处理高维参数,因此,无法直接比较SVI与MCMC来判断SVI是否能正确估计参数不确定性。观察参数后验分布对应的预测区间变化是一种简单的间接方法。理想情况下,随着训练数据的不断增多,参数后验也趋于集中,对应的预测区间也会变窄。为此,本文将黄河源区1966—2015年共600个月连续数据分成3种长度,分别采用前200、400、600个数据训练深度模型,观察预测区间的变化以判断SVI能否捕获LSTM中众多参数的不确定性。需要指出的是,提出的后处理模型不仅考虑了模型参数不确定性,也包含了随机误差的不确定性,因此,总的预测区间(不确定性区间)可以划分为参数不确定性区间与随机误差不确定性区间。表 2给出了训练数据长度分别为200、400、600时VB-LSTM的参数不确定性与总误差不确定性的变化,可靠度指标区间离散度与区间覆盖率用于衡量不确定性变化。从表2中可以看出,随着训练数据长度的增加,90%预测区间中参数不确定性对应的ID与RC不断减少,并且在总不确定性中的比例也在下降。表明随着训练数据的增加深度学习参数不确定性在减少,与设想吻合,这为SVI在一定程度上能够捕获参数不确定性提供了间接证据。
3 结论
为提高深度学习预测结果的可信赖程度,本文基于预报残差分析框架构建了将深度学习与具有物理基础的水文模型相融合的混合模型;通过引入变分贝叶斯算法SVI,提出了基于变分贝叶斯与深度学习的水文概率预报新方法VB-LSTM,该方法可与任意的确定性水文模型相耦合,具有一定的灵活性与通用性。主要结论如下:
(1) 实例研究显示,SVI能够在较短时间内(1 h)完成数以千计的参数后验估计,可为水文领域其他高维参数估计问题提供新方法。
(2) VB-LSTM的径流预报结果可信程度更高。与传统基于“线性-正态”假设的水文概率预报模型相比,VB-LSTM的预报结果精度与可靠度更高,不确定性更小。根据“精度-可靠度”指标综合评价显示,VB-LSTM的概率预报结果的90%预测区间覆盖率更合理,区间宽度更窄,区间宽度与连续排位概率评分平均低10%以上;VB-LSTM的确定性预报结果精度更高,纳什效率系数与克林效率系数均在0.8以上,平均提高0.06以上。此外,与LSTM相比,VB-LSTM在验证期也表现出更高的预报精度。
参考文献:
[1]SHEN C P,LALOY E,ELSHORBAGY A,et al.HESS opinions:incubating deep-learning-powered hydrologic science advances as a community[J].Hydrology and Earth System Sciences,2018,22(11):5639-5656.
[2]鲍振鑫,张建云,王国庆,等.基于水文模型与机器学习集合模拟的水沙变异归因定量识别:以黄河中游窟野河流域为例[J].水科学进展,2021,32(4):485-496.(BAO Z X,ZHANG J Y,WANG G Q,et al.Quantitative assessment of the attribution of runoff and sediment changes based on hydrologic model and machine learning:a case study of the Kuye River in the Middle Yellow River basin[J].Advances in Water Science,2021,32(4):485-496.(in Chinese))
[3]周研来,郭生练,张斐章,等.人工智能在水文预报中的应用研究[J].水资源研究,2019,8(1):1-12.(ZHOU Y L,GUO S L,ZHANG F Z,et al.Hydrological forecasting using artificial intelligence techniques[J].Journal of Water Resources Research,2019,8(1):1-12.(in Chinese))
[4]郭燕,賴锡军.基于长短时记忆神经网络的鄱阳湖水位预测[J].湖泊科学,2020,32(3):865-876.(GUO Y,LAI X J.Water level prediction of Lake Poyang based on long short-term memory neural network[J].Journal of Lake Sciences,2020,32(3):865-876.(in Chinese))
[5]KRATZERT F,KLOTZ D,BRENNER C,et al.Rainfall-runoff modelling using Long Short-Term Memory (LSTM) networks[J].Hydrology and Earth System Sciences,2018,22(11):6005-6022.
[6]JIANG S J,ZHENG Y,WANG C,et al.Uncovering flooding mechanisms across the contiguous United States through interpretive deep learning on representative catchments[J].Water Resources Research,2022,58(1):e2021WR030185.
[7]梁忠民,蒋晓蕾,钱名开,等.考虑误差异分布的洪水概率预报方法研究[J].水力发电学报,2017,36(4):18-25.(LIANG Z M,JIANG X L,QIAN M K,et al.Probabilistic flood forecasting considering heterogeneity of error distributions[J].Journal of Hydroelectric Engineering,2017,36(4):18-25.(in Chinese))
[8]RAZAVI S.Deep learning,explained:fundamentals,explainability,and bridgeability to process-based modelling[J].Environmental Modelling & Software,2021,144:105159.
[9]刘章君,郭生练,许新发,等.贝叶斯概率水文预报研究进展与展望[J].水利学报,2019,50(12):1467-1478.(LIU Z J,GUO S L,XU X F,et al.Bayesian probabilistic hydrological forecasting:progress and prospects[J].Journal of Hydraulic Engineering,2019,50(12):1467-1478.(in Chinese))
[10]梁忠民,戴荣,李彬权.基于贝叶斯理论的水文不确定性分析研究进展[J].水科学进展,2010,21(2):274-281.(LIANG Z M,DAI R,LI B Q.A review of hydrological uncertainty analysis based on Bayesian theory[J].Advances in Water Science,2010,21(2):274-281.(in Chinese))
[11]VRUGT J A,LALOY E.Reply to comment by Chu et al.on “High-dimensional posterior exploration of hydrologic models using multiple-try DREAM (ZS) and high-performance computing”[J].Water Resources Research,2014,50(3):2781-2786.
[12]FANG K,KIFER D,LAWSON K,et al.Evaluating the potential and challenges of an uncertainty quantification method for long short-term memory models for soil moisture predictions[J].Water Resources Research,2020,56(12):e2020WR028095.
[13]HRON J,MATTHEWS A G D G,GHAHRAMANI Z.Variational Gaussian dropout is not Bayesian[EB/OL].2017:arXiv.:1711.02989.https:∥arxiv.org/abs/1711.02989.
[14]JORDAN M I,GHAHRAMANI Z,JAAKKOLA T S,et al.An introduction to variational methods for graphical models[J].Machine Language,1999,37(2):183-233.
[15]RANGANATH R,GERRISH S,BLEI D M.Black box variational inference[J].Journal of Machine Learning Research,2014,33:814-822.
[16]茍娇娇,缪驰远,徐宗学,等.大尺度水文模型参数不确定性分析的挑战与综合研究框架[J].水科学进展,2022,33(2):327-335.(GOU J J,MIAO C Y,XU Z X,et al.Parameter uncertainty analysis for large-scale hydrological model:challenges and comprehensive study framework[J].Advances in Water Science,2022,33(2):327-335.(in Chinese))
[17]BLEI D M,KUCUKELBIR A,MCAULIFFE J D.Variational inference:a review for statisticians[J].Journal of the American Statistical Association,2017,112(518):859-877.
[18]van de SCHOOT R,DEPAOLI S,KING R,et al.Bayesian statistics and modelling[J].Nature Reviews Methods Primers,2021,1:1.
[19]HOCHREITER S,SCHMIDHUBER J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[20]WU X,MARSHALL L,SHARMA A.The influence of data transformations in simulating total suspended solids using Bayesian inference[J].Environmental Modelling & Software,2019,121:104493.
[21]LI D Y,LIANG Z M,LI B Q,et al.Multi-objective calibration of MIKE SHE with SMAP soil moisture datasets[J].Hydrology Research,2019,50(2):644-654.
Probabilistic hydrological forecasting based on variational Bayesian deep learning
The study is financially supported by the National Natural Science Foundation of China(No.41730750;No.41877147).
LI Dayang1,YAO Yi2,LIANG Zhongmin3,ZHOU Yan4,LI Binquan3,5
(1. College of Civil Engineering,Yancheng Institute of Technology,Yancheng 224051,China;
2. State Key Laboratory of Hydrology and Water Resources and Hydraulic Engineering Science,Nanjing Hydraulic Research Institute,Nanjing 210029,China;3. College of Hydrology and Water Resources,Hohai University,Nanjing 210098,China;4. Jiangsu Provincial key Laboratory of Coastal Wetland Bioresources and Environmental Protection,Yancheng Teachers University,Yancheng 224007,China;5. Cooperative Innovation Center for Water Safety & Hydro Science,Nanjing 210024,China)
Abstract:The field of deep learning research in hydrology primarily aims to enhance prediction capabilities.However,the intricate structure of deep learning models often leads to predictions that are difficult to explain and trust,making the development of trustworthy deep learning models a challenging and increasingly important topic.In this paper,we present a novel hybrid model that combines the strengths of deep learning and physical-based hydrological models to improve predictions in hydrology.Utilizing a framework of a residual error model,our approach develops a VB-LSTM (variational Bayesian deep learning model) to quantify hydrological uncertainty and enhance predictive reliability.We applied our model to predict streamflow in the source area of the Yellow River from 1961 to 2015,and the results demonstrate its superiority over traditional methods.Compared to long-short term memory networks (LSTM),the VB-LSTM model achieved stable performance and higher predictive accuracy in the validation period.Additionally,it outperforms the traditional probabilistic hydrological post-processing method that relies on a “linear-normal” assumption,by providing higher predictive accuracy and reliability,and reducing predictive uncertainty.
Key words:probabilistic hydrological forecasting;deep learning;variational Bayes;long short-term memory;hybrid model
