基于时序分解与机器学习的非平稳径流序列集成模型与应用
2023-08-17张力王红瑞郭琲楠徐源浩李理谢骏
张力 王红瑞 郭琲楠 徐源浩 李理 谢骏

摘要:揭示变化环境下非平稳径流序列波动特征,可为提高径流预测精度和涉水工程规划提供支撑。针对径流序列具有非平稳性、周期性和异方差性的特征,收集长江流域攀枝花、城陵矶和大通站2008—2018年实测径流资料,基于周期趋势分解法(STL)将原始数据分解为周期项、趋势项和剩余项,结合各子序列特征采用多模型集成获取未来径流的综合预测值,并将预测结果与Prophet、LSTM和GARCH等单一模型进行对比。结果表明:联合机器学习和时序分解的集成模型在多个评价指标上均优于单一模型,且对异方差效应显著的站点模拟精度提升明显;验证期内3个站点的纳什效率系数分别为0.96、0.95和0.93,表明该模型能有效模拟长江流域径流波动过程。
关键词:径流模拟;时序分解;机器学习;异方差;集成模型;长江流域
中图分类号:TV122
文献标志码:A
文章编号:1001-6791(2023)01-0042-11
收稿日期:2022-08-27;
网络出版日期:2023-01-31
网络出版地址:https:∥kns.cnki.net/kcms/detail∥32.1309.P.20230131.1323.004.html
基金项目:国家自然科学基金资助项目(52279005);北京师范大学博一学科交叉项目(BNUXKJC2124)
作者简介:张力(1997—),男,江西鄱阳人,博士研究生,主要从事水资源系统分析研究。
E-mail:zhanglicws@mail.bnu.edu.cn
通信作者:王红瑞,E-mail:henrywang@bnu.edu.cn
20世纪以来,流域(区域)水循环机理显著变化加剧了水文复杂特性,考虑非平稳径流序列的预测成为目前水文非一致性研究的热点与难点[1-2],主要表现为:① 变化环境下流域水文序列在剧烈波动后没有呈现恢复长期均值的趋势,这种“随机游走”行为呈现典型非平稳特征,径流预测过程中众多动态不确定性因素的累积传导造成预测结果的不确定,对现有径流预测模型的适用性提出了严峻挑战;② 水文序列特征提取建模后,信息未被充分挖掘,剩余残差平方序列的自相关函数具有较强的条件异方差性,致使结果不确定性增加并导致实际风险管理中估计不足。例如,Ha等[3]在长江流域进行洪水预报时,对时间序列统计特征提取不足,影响了径流预测的准确性。此外,国际水文科学协会(IAHS)在2019年发布的水科学领域23个未决问题中强调,探究流域尺度上水文序列时间变化趋势规律在人类生活生产、发电以及防汛抗旱等多方面具有重要的现实价值[4]。
现有的径流预测模型可分为基于物理机制的流域水文过程模型和数据驱动模型,前者由于部分水文过程认识不足,在揭示流域产汇流机制和水文机理过程中有所欠缺;后者仅需捕捉输入和输出数据之间的关系,无需理解复杂物理过程,已被广泛应用于降水和径流等水文预测[5]。经典的数据驱动模型前提条件是残差序列独立且服从正态分布,方差为常数或具有季节时变性[6]。显然在实际中,大部分水文序列特性都无法满足这一前提条件,传统的随机水文学建模方法显现出一定局限性,亟需进一步探究考虑条件异方差性序列的模型和建模方法来进行径流预测[7]。为消除条件异方差影响,广义自回归条件异方差模型(Generalized autoregressive conditional heteroskedasticity model,GARCH)通过描述序列的异方差性、异偏度和异峰度特性[8],使其能够较好地捕捉随机波动特征用以提高预报精度,已在水文领域得到部分应用[9]。但在变化环境下径流序列往往具有非线性和随机性等特征,难以满足模型的初始假设[10],以长短时记忆网络(Long Short-Term Memory,LSTM)神经网络模型为代表的机器学习方法逐渐在水文预报领域得到广泛应用,且在人类活动影响显著的流域能够很好地描述径流过程[11]。然而,上述数据驱动模型主要侧重于径流序列的非线性特征,对径流周期性和非平稳性的影响存在部分忽视,在一定程度上限制了径流预测的精度。集成学习方法被证实是提高预测能力的有效方法[12],如鲍振鑫等[13]在明晰各模型优劣的基础上集成水文模型与机器学习,取得了较好的水沙模拟效果;Fathian等[14]考虑了径流序列的随机性和异方差性,综合神经网络和GARCH模型提高了月径流预测精度。基于局部加权回归的周期趋势分解(Seasonal-trend decomposition procedure based on loess,STL)即为一种简洁高效的模型集成方法,通过模型集成实现优势互补,适用于任何周期性數据[15]。
长江作为中华民族的母亲河,淡水资源丰富,研究其径流演变和预报可从不同角度向水资源管理提供决策支撑服务。本研究以长江干流代表性水文站点2008—2018年实测径流为研究对象,基于STL算法和不同模型优势,将分解后的径流季节项、趋势项和剩余项数据作为多个模型输入,输出最终预测径流序列值,旨在进一步提高径流预报精度,为涉水工程规划提供依据。
1 模型建立
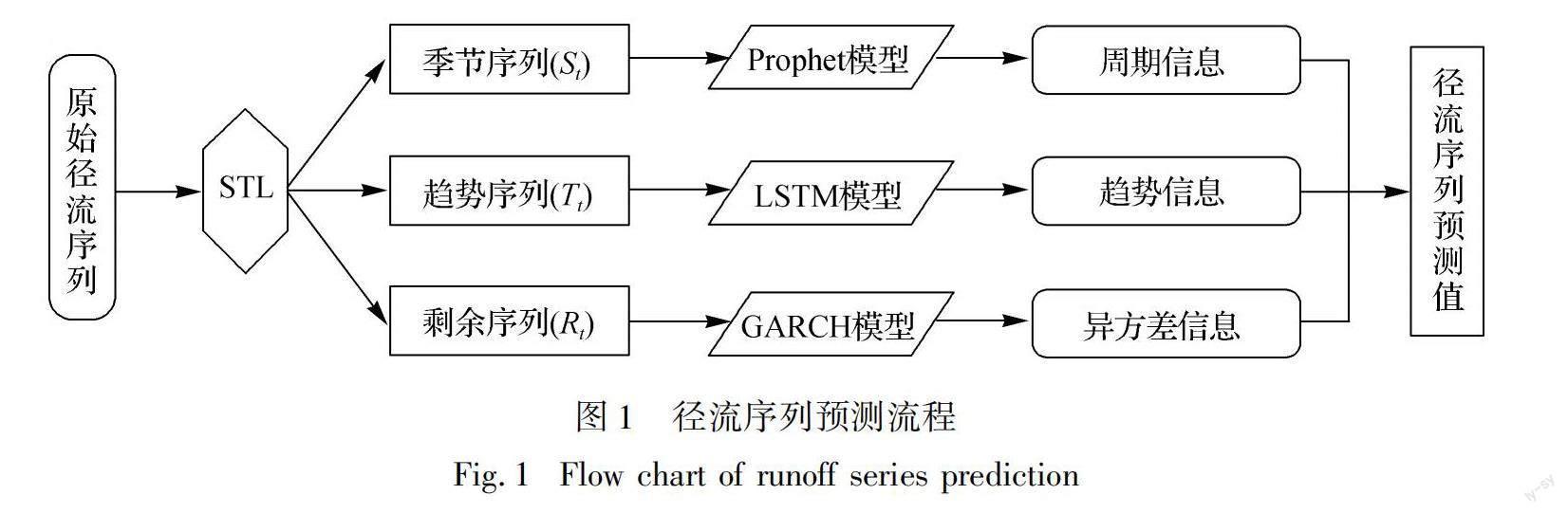
集成学习是一种根据规则整合多个基模型学习器输出的结果,从而获得相较于单一模型效果更优的机器学习方法,已在长江流域得到部分应用[16]。与此同时,多模型集成的方式能充分挖掘人类活动影响下蕴含在径流序列中的统计特征,一定程度上弥补对人类活动因素考虑的不足。建模步骤如下:首先,
通过STL模型将原始径流序列分解为季节序列、趋势序列和剩余序列;其次,根据各子序列波动特征,采用Prophet模型预测季节成分、LSTM模型预测分解后的径流趋势成分、GARCH模型预测剩余波动成分;最后,将预测得出的径流序列趋势成分预测值、剩余成分预测值和季节成分预测值相加,得到集成模型径流预测值(图1)。
1.1 周期趋势分解
周期趋势分解是典型的时间序列分解方法,区别于传统的季节分解方法,STL在处理异常值时的鲁棒性更强[17],且能够处理多种尺度样本数据的季节性。对于径流数据Yt(t=1,2,…,n),STL基于局部加权回归将原始数据Yt分解为季节成分(St)、趋势成分(Tt)和残余成分(Rt),表达式如下:
Yt=St+Tt+Rt(1)
STL可分为内循环和外循环2个递归过程,1个内循环嵌套在1个外循环内。趨势和季节成分将在每次通过内部循环时更新;外循环的每一轮都包括内循环,然后计算稳健性权重,在内循环的下一次运行中使用这些权重,以减少趋势和季节性成分中瞬时、异常值的影响。
1.2 Prophet模型
Prophet模型是一种基于广义加法模型的时间序列预测算法,在处理缺失数据和异常值时效果表现较好[18]。本研究中Prophet模型优点在于,基于STL分解提供的先验周期信息,模型提取的周期项更为完善,拟合速度快且适用于具有强烈周期性影响的时间序列,因此选用其预测分解后的季节成分。模型由4个部分组成,即
y(t)=g(t)+s(t)+h(t)+εt(2)
式中:y(t)为时间序列数据;g(t)为趋势项;s(t)为周期项;h(t)为节假日项(在径流预测中可不考虑);εt为误差项。
采用逻辑回归函数来拟合时间序列的趋势项:
式中:C为最大容量,表示未来时间序列峰值;k为增长率,增长速度随k值增大而加快,即更容易达到序列峰值;m为偏移量。
周期项采用傅里叶级数来拟合:
式中:P为时间序列的周期;N为在模型中周期使用次数;an、bn分别为正余弦函数的振幅。
1.3 LSTM模型
为解决递归神经网络(Recurrent Neural Network,RNN)的梯度消失和梯度爆炸问题,Hochreiter等[19]提出了长短时记忆神经网络模型。该模型的核心思想是门控逻辑,基于其独特的门控结构和反馈连接,将数据的时序特征引入神经网络,使得数据关系在网络结构中传递,并通过记忆模式和遗忘模式充分提取数据的时序规律。径流序列趋势项具有较强的时序特征,采用LSTM算法对其预测能够有效利用长距离的时序信息。
为使收敛速度加快并提高集成模型预测精度,采用Python中MinMaxScaler函数对分解后的趋势项时间序列进行归一化处理,将径流数据量化在[0,1]之内。归一化公式如下:
式中:x为实际值;x′为归一化处理后的值;max(x)和min(x)分别为数据集中的最大值和最小值。
1.4 GARCH模型
GARCH模型通过对时间序列增加方差的滑动自平均项,来刻画时间序列的条件方差随时间的变化特征,能有效捕捉时间序列中的异方差效应和随机项特征,然其在水文领域研究尚不多见。在国内,Wang等[20]最早开展水文序列异方差模型研究,并基于实测径流资料建立GARCH模型,表明水文序列具有异方差效应,同时能够提高预测精度。因此,采用GARCH模型来预测STL分解后剩余项序列效果较好,其表达式如下:
式中:yt是时间序列;εt为误差项;σ2t为误差平方项;δ0为常数项;ηi为波动的自回归系数;j为波动的条件异方差系数。一般要求p>0,q>0,δ0>0,ηi≥0,j≥0以保证条件方差为正。
由于模型参数估计复杂且具有多重共线性,选择太多滞后期可能会带来更多“噪音”,而GARCH(1,1)模型在方程正确设定的情况下足以捕捉到波动性[21]。因此,本研究分别采用Augmented Dickey-Fuller(ADF)和拉格朗日乘子(LM)对剩余项单位根以及异方差效应检验后,建立GARCH(1,1)模型对其模拟。
1.5 模型效果评估
采用克林效率系数(EKG)、纳什效率系数(ENS)、均方根误差(ERMS)以及平均绝对百分比误差(EMAP)4个指标对模型效果进行评价。计算公式分别为:
式中:r为皮尔逊线性相关系数;α为实测流量与模拟流量标准差的比率;β为实测流量与模拟流量均值的比率;y为观测序列;y′为模拟序列;
y为观测序列的均值;n为序列长度。
2 结果及分析
2.1 研究区概况
本研究收集了长江干流攀枝花、城陵矶和大通3个水文站2008—2018年逐日径流数据(图2),数据来源于长江流域水文年鉴。攀枝花站扼守上游金沙江流域,控制面积约为25.92万km2;城陵矶站为中游洞庭湖出口水文站,素有长江水文情势和洞庭湖“晴雨表”之称,多年平均年径流量高达2 600亿m3;大通站位于下游安徽省池州市,控制面积约170万km2。这3个站点地理位置、气候因子和下垫面状况均有不同,且径流量变化也存在一定差异。采用上述3个站点径流的样本数据进行预测可更加客观、系统地评价模型的有效性和稳定性。
机器学习需要较多的训练数据以期获得较好的参数估计,同时为避免数据量过少导致的模型过拟合或欠拟合现象[22],本研究按照9∶1的比例将原始数据划分为训练集和验证集,即训练集为2008年1月1日至2017年12月31日(共3 653个数据),验证集为2018年1月1日至12月31日(共365个数据)。
2.2 径流序列分析
由逐日径流过程可以看出,3个代表性水文站在2008—2018年的逐日径流序列具有相似的过程形态,在长江三峡及上游金沙江河段一批大型水库投入运行影响下季节性和波动性显著(图3)。攀枝花站日均流量为1 820 m3/s,非汛期内的实测日径流过程变化较为平稳,而流量过程线在汛期及汛后波动显著;城陵矶站径流年内年际变化均极其剧烈,日均流量为7 650 m3/s;下游地区支流众多、降水丰富,流量和变化幅度显著增大,大通站日均流量为27 600 m3/s,2008—2018年间最大洪峰流量是攀枝花站的8.8倍。
随着汛期内每日流量均值的升高,攀枝花站每日流量的标准差也上升(图4)。从全年的范围来看,径流标准差的变幅很大,最低只有60.7 m3/s,最高达到1 871.2 m3/s。同时,大的方差主要集中在6—9月,而在1月、2月、3月以及12月中方差都很小,这是一种明显的条件异方差(ARCH)效应[6]。表1中径流序列的拉格朗日乘子检验结果表明,3个站点径流序列ARCH-LM检验的F统计量和Nobs*R2(Nobs为样本量;R2为决定系数)统计量所对应的P值均为0,通过1%水平下的显著性检验,表明径流序列存在显著异方差效应,满足异方差模型建立的前提条件。F统计量越大,异方差效应越显著,因此,3个站点异方差效应呈现沿江递减趋势。
2.3 STL分解时序
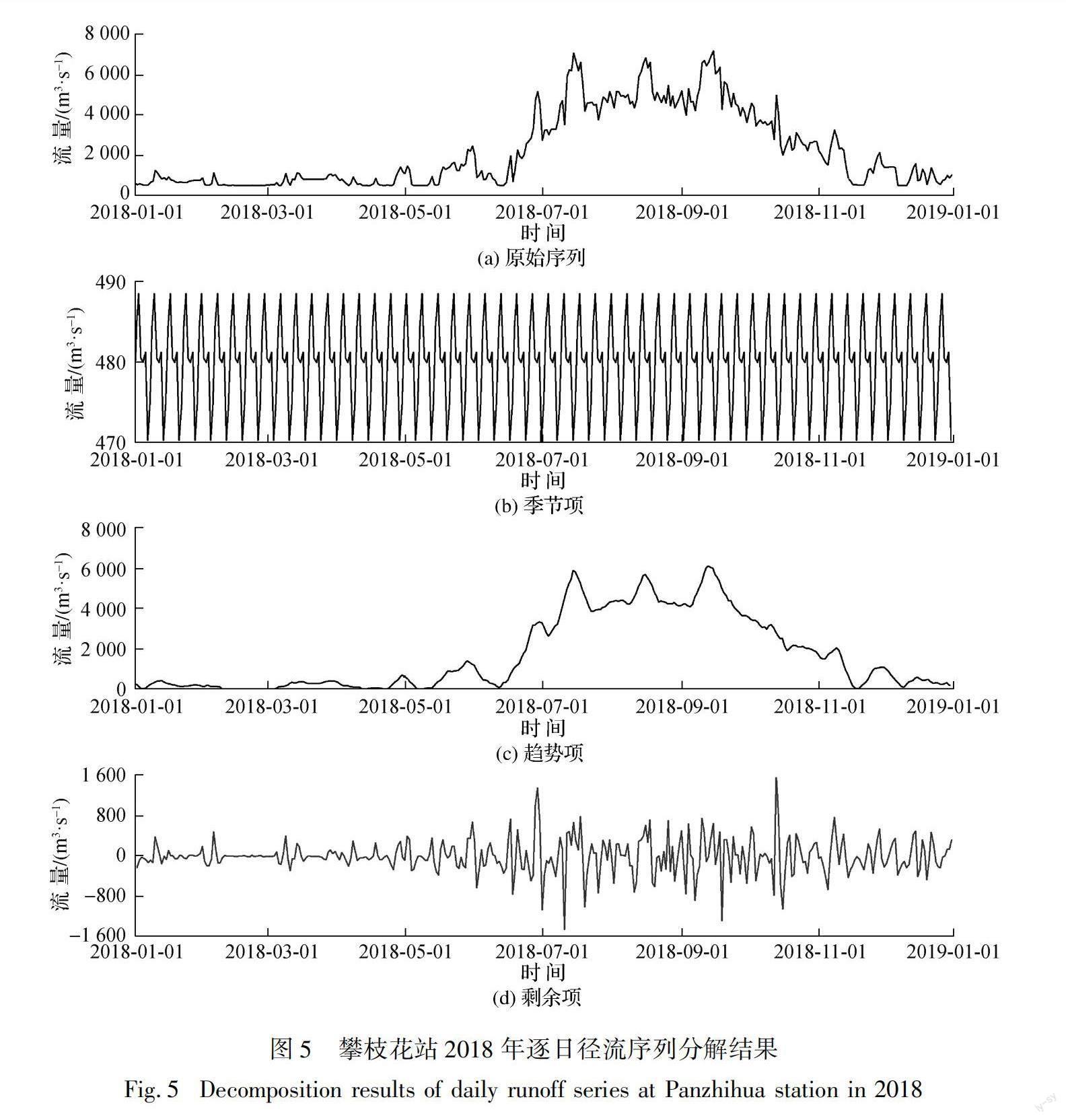
采用STL方法将原始径流序列进行分解,得到长期趋势变化、周期变化和不规则随机变化序列。以攀枝花水文站2018年的日径流为例,其趋势项与原始径流序列数据呈现总体一致的变化规律,但是在分解后变化更为平滑。径流序列分解出的剩余项波动呈现随机性,且波动幅度随着汛期的来临明显增大,与季节项不同的是,未呈现出明显变化规律(图5)。
图5 攀枝花站2018年逐日径流序列分解结果
Fig.5Decomposition results of daily runoff series at Panzhihua station in 2018
根据式(1)分解结果进行协方差计算,进一步分析季节项、趋势项和剩余项在汛期(6—9月)与非汛期对径流序列波动的贡献率[15]。各成分贡献率分别为:
式中:Ct为趋势项对径流序列波动贡献率;Cs为季节项对径流序列波动贡献率;Cr为剩余项对径流序列波动贡献率。
表2展示了各子序列分量对径流序列波动的贡献率。横向对比序列分解成分差异,表明趨势项一直是影响径流序列波动的主导贡献因子,出现这种情况是因为长江流域河川径流主要来源于大气降水,径流随降水呈现显著的年际丰枯趋势变化,导致趋势性特征的主导地位。剩余项的贡献率次之,而季节项对径流序列波动的长期影响相对较小,贡献率均维持在0.1%。纵向对比各站点分布地理位置,趋势项对径流序列波动的贡献率从上游至下游逐渐增加,剩余项对径流序列波动的贡献率逐渐减小,季节项贡献率保持不变。究其原因,上游在降水和下垫面的时空分布不均匀性影响下导致径流湍急且呈现不规则波动,但在沿江水利工程和江河湖泊的调蓄作用下,下行湍急的长江中游和下游段变得水势平缓,显著平抑了上述不确定性因素对径流不规则波动的影响,致使剩余项对径流序列波动贡献率从上游到下游逐渐减小,相应地,趋势项影响越来越大。
2.4 模型参数设置
模型参数设置对模拟精度影响较大,Prophet模型中参数较少,异方差模型采用定阶后的GARCH(1,1)模型,而LSTM模型包含多个超参数,需在学习过程之前进行优化确定,以提高学习性能。对于单变量时间序列数据,过于复杂的模型结构反而无法较好地进行参数训练,同时可能导致训练的计算和时间成本增加。因此,本研究基于深度学习开源Keras框架搭建LSTM神经网络模型,模型结构由输入层、1个LSTM层及输出层组成,损失函数使用均方误差,模型训练过程采用Adam(Adaptive momentum)算法进行优化[23]。模型关键超参数包括输入时间步长、批处理数据大小、神经元数量以及迭代次数。输入时间步长是用来预测径流所用到的时间序列长度,过短的时间步长将导致预测不确定性,而过长将会提高预测难度。在长江流域径流预报模型构建中,初始设置输入步长分别为3、7、14和21 d进行预测,发现输入步长为14 d时模型精度高且训练时间较短,因此,选择输入过去14 d的日径流数据用于预测。批处理数据大小的选择对模型预测效果较小,为提高模型效率,将该参数设置为128。另外,神经元数量反映网络复杂程度,迭代次数指模型学习一次数据的全过程。在本章中,分别将神经元数量设置为5、10、20、50、100,并将迭代次数设置为一个较大的值进行训练,随后发现神经元数量取10时预测误差最小。图6展示了LSTM模型在模拟过程中训练误差及验证误差随迭代次数变化的过程,可以看出,在迭代次数为75时,3个站点LSTM模型的收敛速度快且此时模型训练误差及验证误差均呈现一致下降的趋势,直至最终基本稳定,表明此时模型训练完毕。
2.5 径流预测结果
分别构建长江干流不同站点径流序列STL分解后的Prophet、GARCH(1,1)和LSTM模型,然后叠加子序列的预测结果,进而得到各站点的最终预测流量。集成模型在3个站点的总体表现如表3所示:训练期内,模型在攀枝花、城陵矶和大通站的EKG分别为0.95、0.93
和0.98,ENS分别为0.94、0.92和0.92;而在验证期,模型在3个站点的EKG分别为0.96、0.91和0.98,ENS分别为0.96、0.95和0.93,参照《水文情报预报规范:GB/T 22482—2008》,集成模型模拟精度为甲等。训练期内模型在攀枝花、城陵矶和大通站的ERMS分别为345.7 m3/s、1 383.6 m3/s和1 438.3 m3/s;而在验证期,模型在3个站点的ERMS分别为393.8 m3/s、1 187.7 m3/s和1 302.9 m3/s。可以看出,训练期和验证期内模型效果评价指标总体相近,但由于训练期内异常值更多,考虑到提升模型应对噪声数据时的鲁棒性和反映径流的真实变化规律,在数据处理阶段并未将其直接删除,导致训练期内模型模拟效果在一定程度上稍逊于验证期。此外,在异方差效应最强的攀枝花站,结合GARCH(1,1)的集成模型模拟精度最高,表明适当阶数的GARCH型模型在捕获线性时间序列模型残差中的异方差性和提高模型精度方面具有优势。对比集成模型模拟的时间序列结果与实测数据,结果表明,模型能够较为精准地学习径流的波动规律和极值,在汛期流量激增的情况下,尽管模型预测的变幅在时间上出现一定迟缓,对径流极值的模拟效果仍然较好,因此,可以认为基于STL分解和机器学习构建的集成模型能够很好地模拟长江流域典型水文站点的径流过程(图7)。
为更直观地反映集成模型的预测性能和优势,对攀枝花、城陵矶和大通站分别建立了Prophet、LSTM和GARCH 3种日径流预测模型与本文模型对比,验证期内径流模拟评价指标如表4所示。验证期内,集成模型在攀枝花、城陵矶和大通站的ENS值均高于单一模型模拟结果。从EKG来看,各单一模型在攀枝花站的EKG分别为0.66、0.85和0.86;而在径流波动更剧烈的大通站,EKG分别为0.82、0.91和0.89,集成模型在大通站的EMAP对比单一模型也分别降低了8.25%、6.91%和7.28%。对比模型效果评估指标可以发现,基于STL分解的集成模型展现出明显优于单一模型的拟合性能,模拟效果在不同程度上均有所提高,模拟出的流量过程线与观测序列波动最为相似。对各模型效果进行排序,集成模型性能优于单一LSTM和GARCH模型,而Prophet模型在对此类非平稳且波动剧烈的时间序列模拟时精度相对较差。
一般来说,模型模拟的ENS达到0.75时即表明模拟效果较好。因此,本研究构建的集成模型模拟精度较高,能够反映长江流域径流过程的季节变化特征。值得一提的是,在对此类ARCH效应显著的时间序列进行建模预测时,GARCH(1,1)模型表现出不输于机器学习模型的性能,表明通过建立GARCH类模型修正序列异方差性对开展不确定性分析更加有利。因此,水文序列异方差效应在实际建模中是值得考虑的,未来可推广至其他流域,具有较为广阔的应用前景。此外,相对于Prophet、LSTM和GARCH單一模型,基于STL分解的集成模型有着更为明显的优越性。主要原因在于,Prophet、LSTM和GARCH单一模型在对径流数据模拟时并未对原始序列进行先验处理,先验信息的不足致使无法准确识别非平稳径流序列中的波动性和周期性,导致在最终预测中不可避免地存在一定的模型输入不确定性。而基于STL分解的集成模型则充分考虑了上述问题,在对径流序列分解后,选择适合各项数据特征的模型进行模拟,最终有效提升了模拟精度,表现为较好的模拟效果。
在对比的3种单一模型中,Prophet始终是在各个站点径流模拟精度最低的模型,主要原因在于,Prophet模型可供调节的参数较少,其假定在一定周期内序列波动范围是恒定的,无法捕捉目标函数的可变性范围。而径流的年际波动较为剧烈且无明显周期规律,致使对此类复杂特性的数据拟合会产生较大偏差[24]。将Prophet模型替换成其他契合季节性数据的模型,如SARIMA模型、支持向量机或者是其他神经网络模型[25],可能会取得更优的模拟性能,但与此同时也会带来更高的复杂性和更低的可解释性。一方面,模型拟合给定训练数据集的能力会随着其复杂性的增加而增加;另一方面,过于复杂的模型可能会提取噪声数据导致训练误差减小、测试误差增加。事实上,由于洪水的非线性特征和复杂过程,没有任何模型或者算法可以达到完美的预测效果,不确定性始终存在于建模过程中[26]。而在实际工程应用中,复杂的模型设置将在整个建模周期中产生越来越大的影响,如何平衡时间、成本和性能是必须考虑的重要因素。在前文基于协方差计算的波动贡献率分析中,季节序列对径流波动影响最小,选择契合其波动特征的Prophet模型不仅降低了预测误差,同时有效提高了建模效率,最终达到整体较好的预测效果。
3 结论
本研究构建了一种基于时间序列分解和多模型组合的径流预测集成模型,分析了长江干流攀枝花、城陵矶和大通站2008—2018年的日径流异方差效应并进行模拟预测,主要结论如下:
(1) 2008—2018年攀枝花、城陵矶和大通站日均流量分别为1 820 m3/s、7 650 m3/s和27 600 m3/s,通过方差分析及拉格朗日乘子检验表明径流序列具有明显的异方差效应,呈沿江递减趋势。
(2) 径流波动序列分解后的趋势项与原始数据较为一致,但变化更为平滑,剩余项序列未呈现明显规律;通过方差分解表明趋势项是径流序列波动的主导贡献因子,而季节项对径流波动的长期影响相对较小。
(3) 集成模型能够较为精准地学习径流的非平稳特征和波动规律,验证期内3个站点的纳什效率系数分别为0.96、0.95和0.93,均优于单一的Prophet、LSTM和GARCH模型,且模型对异方差效应显著的站点模拟精度提升明显。
参考文献:
[1]徐宗学,班春广,张瑞.雅鲁藏布江流域径流演变规律与归因分析[J].水科学进展,2022,33(4):519-530.(XU Z X,BAN C G,ZHANG R.Evolution laws and attribution analysis in the Yarlung Zangbo River basin[J].Advances in Water Science,2022,33(4):519-530.(in Chinese))
[2]孙鹏,孙玉燕,张强,等.淮河流域洪水极值非平稳性特征[J].湖泊科学,2018,30(4):1123-1137.(SUN P,SUN Y Y,ZHANG Q,et al.Evaluation on non-stationarity assumption of annual maximum peak flows during 1956—2016 in the Huaihe River basin[J].Journal of Lake Sciences,2018,30(4):1123-1137.(in Chinese))
[3]HA S,LIU D R,MU L.Prediction of Yangtze River streamflow based on deep learning neural network with El Ni?o-Southern Oscillation[J].Scientific Reports,2021,11(1):11738.
[4]BL?SCHL G,BIERKENS M F P,CHAMBEL A,et al.Twenty-three unsolved problems in hydrology (UPH):a community perspective[J].Hydrological Sciences Journal,2019,64(10):1141-1158.
[5]LIANG Z M,LI Y J,HU Y M,et al.A data-driven SVR model for long-term runoff prediction and uncertainty analysis based on the Bayesian framework[J].Theoretical and Applied Climatology,2018,133(1):137-149.
[6]WANG H R,GAO X,QIAN L X,et al.Uncertainty analysis of hydrological processes based on ARMA-GARCH model[J].Science China Technological Sciences,2012,55(8):2321-2331.
[7]巴歡欢,郭生练,钟逸轩,等.考虑降水预报的三峡入库洪水集合概率预报方法比较[J].水科学进展,2019,30(2):186-197.(BA H H,GUO S L,ZHONG Y X,et al.Comparative study on probabilistic ensemble flood forecasting considering precipitation forecasts for the Three Gorges Reservoir[J].Advances in Water Science,2019,30(2):186-197.(in Chinese))
[8]BOLLERSLEV T.Generalized autoregressive conditional heteroskedasticity[J].Journal of Econometrics,1986,31(3):307-327.
[9]王红瑞,高雄,常晋源,等.基于条件异方差分析的水文时序模型及其应用[J].系统工程理论与实践,2009,29(11):19-30.(WANG H R,GAO X,CHANG J Y,et al.Hydrological time series model based on conditional heteroskedasticity analysis and its application[J].Systems Engineering-Theory & Practice,2009,29(11):19-30.(in Chinese))
[10]刘磊,高超,王志刚,等.基于非线性相关性和复杂网络的径流相似性分区[J].水科学进展,2022,33(3):442-451.(LIU L,GAO C,WANG Z G,et al.Study on streamflow similarity regionalization based on nonlinear correlation and complex network[J].Advances in Water Science,2022,33(3):442-451.(in Chinese))
[11]徐源浩,邬强,李常青,等.基于长短时记忆 (LSTM) 神经网络的黄河中游洪水过程模拟及预报[J].北京师范大学学报(自然科学版),2020,56(3):387-393.(XU Y H,WU Q,LI C Q,et al.Simulation of the flood process in the middle reaches of the Yellow River by a long-short term memory (LSTM) neuro network[J].Journal of Beijing Normal University(Natural Science),2020,56(3):387-393.(in Chinese))
[12]孙少龙,魏云捷,汪寿阳.基于分解-聚类-集成学习的汇率预测方法[J].系统工程理论与实践,2022,42(3):664-677.(SUN S L,WEI Y J,WANG S Y.Exchange rates forecasting with decomposition-clustering-ensemble learning approach[J].Systems Engineering-Theory & Practice,2022,42(3):664-677.(in Chinese))
[13]鲍振鑫,张建云,王国庆,等.基于水文模型与机器学习集合模拟的水沙变异归因定量识别:以黄河中游窟野河流域为例[J].水科学进展,2021,32(4):485-496.(BAO Z X,ZHANG J Y,WANG G Q,et al.Quantitative assessment of the attribution of runoff and sediment changes based on hydrologic model and machine learning:a case study of the Kuye River in the Middle Yellow River basin[J].Advances in Water Science,2021,32(4):485-496.(in Chinese))
[14]FATHIAN F,MEHDIZADEH S,KOZEKALANI SALES A,et al.Hybrid models to improve the monthly river flow prediction:integrating artificial intelligence and non-linear time series models[J].Journal of Hydrology,2019,575:1200-1213.
[15]刘雪,刘锦涛,李佳利,等.基于季节分解和长短期记忆的北京市鸡蛋价格预测[J].农业工程学报,2020,36(9):331-340.(LIU X,LIU J T,LI J L,et al.Egg price forecasting in Beijing market using seasonal-trend decomposition procedures based on seasonal decomposition and long-short term memory[J].Transactions of the Chinese Society of Agricultural Engineering,2020,36(9):331-340.(in Chinese))
[16]LIU D R,JIANG W C,MU L,et al.Streamflow prediction using deep learning neural network:case study of Yangtze River[J].IEEE Access,2020,8:90069-90086.
[17]童林,官铮,王立威,等.基于时序分解与误差修正的新能源爬坡事件预测[J].浙江大学学报(工学版),2022,56(2):338-346.(TONG L,GUAN Z,WANG L W,et al.New energy ramp event prediction based on time series decomposition and error correction[J].Journal of Zhejiang University(Engineering Science),2022,56(2):338-346.(in Chinese))
[18]TAYLOR S J,LETHAM B.Forecasting at scale[J].The American Statistician,2018,72(1):37-45.
[19]HOCHREITER S,SCHMIDHUBER J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[20]WANG H R,LIN X,QIAN L X.Crytic period analysis model of hydrological process and its application[J].Hydrological Processes,2009,23(13):1834-1843.
[21]丁藤,馮冬涵,林晓凡,等.基于修正后ARIMA-GARCH模型的超短期风速预测[J].电网技术,2017,41(6):1808-1814.(DING T,FENG D H,LIN X F,et al.Ultra-short-term wind speed forecasting based on improved ARIMA-GARCH model[J].Power System Technology,2017,41(6):1808-1814.(in Chinese))
[22]BAI P,LIU X M,XIE J X.Simulating runoff under changing climatic conditions:a comparison of the long short-term memory network with two conceptual hydrologic models[J].Journal of Hydrology,2021,592:125779.
[23]王卓鑫,趙海涛,谢月涵,等.反向传播神经网络联合遗传算法对复合材料模量的预测[J].上海交通大学学报,2022,56(10):1341-1348.(WANG Z X,ZHAO H T,XIE Y H,et al.Prediction of modulus of composite materials by BP neural network optimized by genetic algorithm[J].Journal of Shanghai Jiao Tong University,2022,56(10):1341-1348.(in Chinese))
[24]ZHAO N Z,LIU Y,VANOS J K,et al.Day-of-week and seasonal patterns of PM2.5 concentrations over the United States:time-series analyses using the Prophet procedure[J].Atmospheric Environment,2018,192:116-127.
[25]唐奇,王红瑞,许新宜,等.基于混合核函数SVM水文时序模型及其应用[J].系统工程理论与实践,2014,34(2):521-529.(TANG Q,WANG H R,XU X Y,et al.Hydrological time series model based on SVM with mixed kernel function and its application[J].Systems Engineering-Theory & Practice,2014,34(2):521-529.(in Chinese))
[26]CHEN W,HONG H Y,LI S J,et al.Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles[J].Journal of Hydrology,2019,575:864-873.
Integrated model and application of non-stationary runoff based on time series decomposition and machine learning
The study is financially supported by the National Natural Science Foundation of China(No.52279005) and BNU Interdisciplinary Research Foundation for the First-Year Doctoral Candidates(No.BNUXKJC2124).
ZHANG Li1,WANG Hongrui1,GUO Beinan2,XU Yuanhao3,LI Li2,XIE Jun4
(1. College of Water Science,Beijing Normal University,Beijing 100875,China;2. School of Government,Beijing Normal University,Beijing 100875,China;3. School of Civil Engineering,Sun Yat-Sen University,Guangzhou 510275,China;4. School of Artificial Intelligence,Beijing Normal University,Beijing 100875,China)
Abstract:Revealing the fluctuating characteristics of non-stationary runoff series under changing environments can improve the precision of runoff prediction and support water-related project planning.Given the characteristics of non-stationarity,periodicity,and heteroscedasticity of runoff series,the observed runoff data from 2008 to 2018 were collected from Panzhihua,Chenglingji,and Datong stations in the Yangtze River basin,and based on the seasonal-trend decomposition method,the original data was decomposed into periodic sequence,trend sequence,and residual sequence.Combined with the features of each subsequence,an integrated model was applied to obtain the total predicted value of future runoff,and the results were compared with the single model of Prophet,LSTM,and GARCH.The results show that the integrated model combined with time series decomposition and machine learning is superior to the single model in different evaluation indexes,and the simulation accuracy of stations with a strong heteroscedasticity effect is significantly improved.The Nash-Sutcliffe efficiency coefficient of the three stations in the validation period is 0.96,0.95,and 0.93,respectively,indicating that the model can effectively simulate the runoff fluctuation process in the Yangtze River basin.
Key words:runoff simulation;time series decomposition;machine learning;heteroscedasticity;integrated model;Yangtze River basin
