改进的基于YOLOv5s苹果树叶病害检测
2023-08-14周绍发肖小玲刘忠意鲁力
周绍发 肖小玲 刘忠意 鲁力


摘要:针对目前在复杂环境下苹果树叶病害检测准确度低、鲁棒性差、计算量大等问题,提出一种改进的基于YOLOv5s苹果树叶病害的检测方法。首先,该方法在YOLOv5s网络基础上,选择考虑方向性的SIoU邊框损失函数替代CIoU边框损失函数,使网络训练和推理过程更快,更准确。其次,在特征图转换成固定大小的特征向量的过程中,使用了简单化的快速金字塔池化(SimSPPF)替换快速金字塔池化(SPPF)模块,在不影响效率的情况下丢失的信息更少。最后在主干网络中使用BoTNet(bottleneck transformers)注意力机制,使网络准确的学习到每种病害的独有特征,并且使网络收敛更快。结果表明,相比于基准网络YOLOv5s,改进后的YOLOv5s网络mAP精度为86.5%,计算量为15.5GFLOPs,模型权重大小为13.1 MB,相对于基准YOLOv5s,平均精度提升了6.3百分点、计算量降低了0.3GFLOPs、模型权重压缩了1 MB。并适用于遮挡、阴影、强光、模糊的复杂环境。本研究所提出的方法,在降低了网络大小、权重、计算量的情况下提高了复杂环境下苹果树叶病害的检测精度,且对复杂环境具有一定的鲁棒性。在预防和治理苹果树叶病害上有较高的实际应用价值,在后续研究上,会扩充更多类别的病害数据集,部署到无人机等物联网设备,从而为实现智能果园种植提供技术参考。
关键词:苹果树叶病害;目标检测;YOLOv5s;bottleneck transformers;SIoU
中图分类号:TP391.41 文献标志码:A
文章编号:1002-1302(2023)13-0212-09
据国家统计局2016—2018年全国果园数据,苹果园的占比达到了18%,在所有种植水果种类中,是仅次于柑橘的第二大果类,其产量已经达到了 4 139万t[1]。苹果产量受到气候、土壤地质、灌溉、病害等多种因素的影响。在众多因素中,苹果病害是影响产量的最重要因素之一,而树叶的病害是最常见的。苹果树叶病害的特点是种类多且某些病害表现相似,用肉眼难以区分,导致无法准确定位病害,最终导致产量下降。因此,准确识别出苹果树叶病害的类别,是防治病害与对症下药的重要前提[2]。
传统的病害检测方法主要为对含有病害的图片进行分析,一般是基于图片的机器学习方法,其代表方法有基于支持向量机(SVM)和图片RGB特性分析,以及利用优化算法提高其他机器学习方法组合类方法[3]。但是以上方法表现的好坏太依赖于特征提取的方法以及原本数学方法的局限。
深度学习法对于图像的特征提取与整合有着较大的进步,已被用于各种植物病害检测。根据网络结构的不同,Bari等使用改进的Fast R CNN(卷积神经网络)实现了对稻叶的常见病害检测并具有高精度实现效果[3];王超学等使用YOLOv3来检测葡萄的病虫害并实现了实际部署[4];Richey等使用YOLOv4实现了低时延的玉米病害检测[5];Haque等使用YOLOv5实现了蔬菜病害检测,提高了对小范围病害的检测和定位效果[6];雷建云等使用改进的残差网络实现了多种类的水稻害虫识别,并实现了77.12%的高准确率和强鲁棒性[7]。
上述方法大多数都能对研究目标实现较为准确的检测,但是很少考虑所提出方法在面对不同环境下的苹果树叶病害是否能够实现高准确率、更小计算量的检测。为解决此类问题,本研究提出一种以YOLOv5网络为基础,加入Bottleneck Transformers注意力机制,并使用简单化后的快速金字塔池化(SimSPPF)代替原有的快速金字塔池化(SPPF)网络,以期实现在复杂环境下高准确率的苹果树叶病害检测。
1 材料与方法
1.1 数据集来源
本研究的苹果树叶病害数据是自建数据集,一部分来自AI Studio,为收集不同环境下的苹果病害图片,使用网络爬虫、谷歌搜索等技术获取另外一部分,总计2 041张,图片格式为jpg,像素为1 000×750。为防止数据集过少产生过拟合和泛化性差的现象,通过旋转、平移、等比例缩放、垂直和水平翻转等数据增强方法,数据集总量为4 082张。叶片病害的种类有4类:蛙眼病(frog eye)、白粉病(powdery mildew)、锈叶病(rust)、斑点病(scab),具体见图1。
1.2 数据预处理及分析
收集到的数据是没有标注或者标注不准确的。使用Label-Img对全部苹果树叶做病害标注。采用最大矩形框标注明显病害处,标注格式为YOLO的txt格式。每张图片至少有1个病害标注。叶片标注示例与标签分布见图2。
1.3 YOLOv5网络
YOLOv5网络是在YOLOv4的基础上改进的1阶段(one-stage)目标检测方法[8],相较于生成候选区域(region proposal),再通过卷积神经网络预测目标的分类与定位的2阶段(two-stage)检测方法更加简洁有效。YOLOv5具体的改进是增加了自适应锚框和K-means算法聚类,并采用遗传算法在训练过程中调整锚框。使得整个训练过程可以找到更好的先验框,提高检测准确率。YOLOv5根据不同的使用场景目的有YOLOv5l、YOLOv5m、YOLOv5s等版本,为保证算法的实时性和大小可控,本研究选择了YOLOv5s版本,具体结构见图3。
YOLOv5s网络结构大致分成4个部分:输入(input)、主干网络(backone)、颈部(neck)及预测头(head)。首先输入部分是对图像进行预处理,如Mosaic增强。主干网络通过卷积神经网络提取图片特征信息,颈部负责将信息上采样,不同网络层的特征信息融合并将图像特征传递到预测层。预测头对图像特征进行预测,生成边界框并预测类别。
1.4 YOLOv5s网络的改进
1.4.1 SIoU 边界框回归损失是评价目标检测算法准确度的重要评判标准之一,而最常用的计算指标是交并比(IoU),即目标检测中预测框与真实框的重疊程度,具体见式1。IoU值越高说明A框与B框重合程度越高,代表模型预测越准确。
IoU=|A∩B||A∪B|。(1)
式中:A代表预测框;B代表真实框。
但是IoU对尺度不敏感,如果2个框没有相交,根据定义,IoU=0,不能反映2个框的距离大小,会造成Loss=0没有梯度回传,无法进行学习训练。随着目标检测技术的不断改进,随后出现不同的IoU改进算法:在IoU的基础上,解决边界框不重合时的问题的GIoU[9];在IoU和GIoU的基础上,考虑边界框中心点距离信息的DIoU[10];在DIoU的基础上,考虑边界框宽高比尺度信息的CIoU[11]。YOLOv5s默认使用CIoU。
SCYLLA-IoU (SIoU)是Gevorgyan在2022年提出的新边界框回归损失函数,重新定义了惩罚指标,极大改进了目标检测算法的训练和推理速度。通过在损失函数代价中引入方向性,与现有方法CIoU损失相比,训练阶段的收敛速度更快,推理性能更好[12]。主要由角度损失(angle cost)、距离损失(distance cost)、形状损失(shape cost)、IoU损失(IoU cost)4个损失函数组成。
Angle cost的目的是如果α≤π4就最小化α,反之最小化β=π2-α。具体见图4-a和式(2)。
Λ=1-2×sin2arcsinx-π4
x=chσ=sinα
σ=(bgtcx-bcx)2+(bgtcy-bcy)2
ch=max(bgtcy,bcy)-min(bgtcy,bcy)。(2)
式中:ch为真实框和预测框中心点的高度差;σ为真实框和预测框中心点的距离;sinα在训练过程中若大于45°取β,否则取α;bgtcx、bgtcy为真实框中心坐标;bcx、bcy为预测框中心坐标。
Distance cost是真实框和预测框的最小外接矩形相关。具体见图4-b和式(3)。
Δ=∑t=x,y(1-e-γρt)
ρx=bgtcx-bcxcw2,ρy=bgtcy-bcych2,γ=2-Λ。(3)
式中:cw、ch为真实框和预测框最小外接矩形的宽和高;ρt指距离损失使用2次幂来赋权重。
Shape cost具体见式(4):
Ω=∑t=w,h(1-e-ωt)θ
ωw=|w-wgt|max(w,wgt),ωh=|h-hgt|max(h,hgt)。(4)
式中:w、h,wgt、hgt分别为预测框和真实框的宽和高;θ控制对形状损失的关注程度;ωt是由w、h共同确定的幂数值。
最终的损失函数包含了IoU cost,详见图4-c和式(5)。
Lbox=1-IoU+Δ+Ω2
IoU=|B∩BGT||B∪BGT|。(5)
1.4.2 SimSPPF SPP(spatial pyramid pooling)结构又被称为空间金字塔池化,是He等在2015年提出的,它能将任意大小的特征图转换成固定大小的特征向量[13]。这避免了对图像区域裁剪、缩放等操作导致的图像失真等问题,解决了提取到重复特征的问题,极大地提高了产生候选框的速度,且节省了计算成本。而YOLOv5在SPP的基础上将原本并行的Maxpool替换成串行Maxpool,并行和串行的效果一样,但串行的效率更高,称之为SPPF。而SimSPPF将SPPF的激活函数SiLU替换为ReLU,更加高效,具体改变见图5。
1.4.3 BoTNet 当前,注意力机制在目标检测领域已经得到广泛应用[14]。注意力机制的灵感来自于人类视觉面对不同事物时会选择性地关注重要的信息部分,忽略其他不重要的信息。在注意力机制的帮助下,神经网络可以将有限的计算能力去捕捉更重要的图像特征,最终达到更好的检测精度。
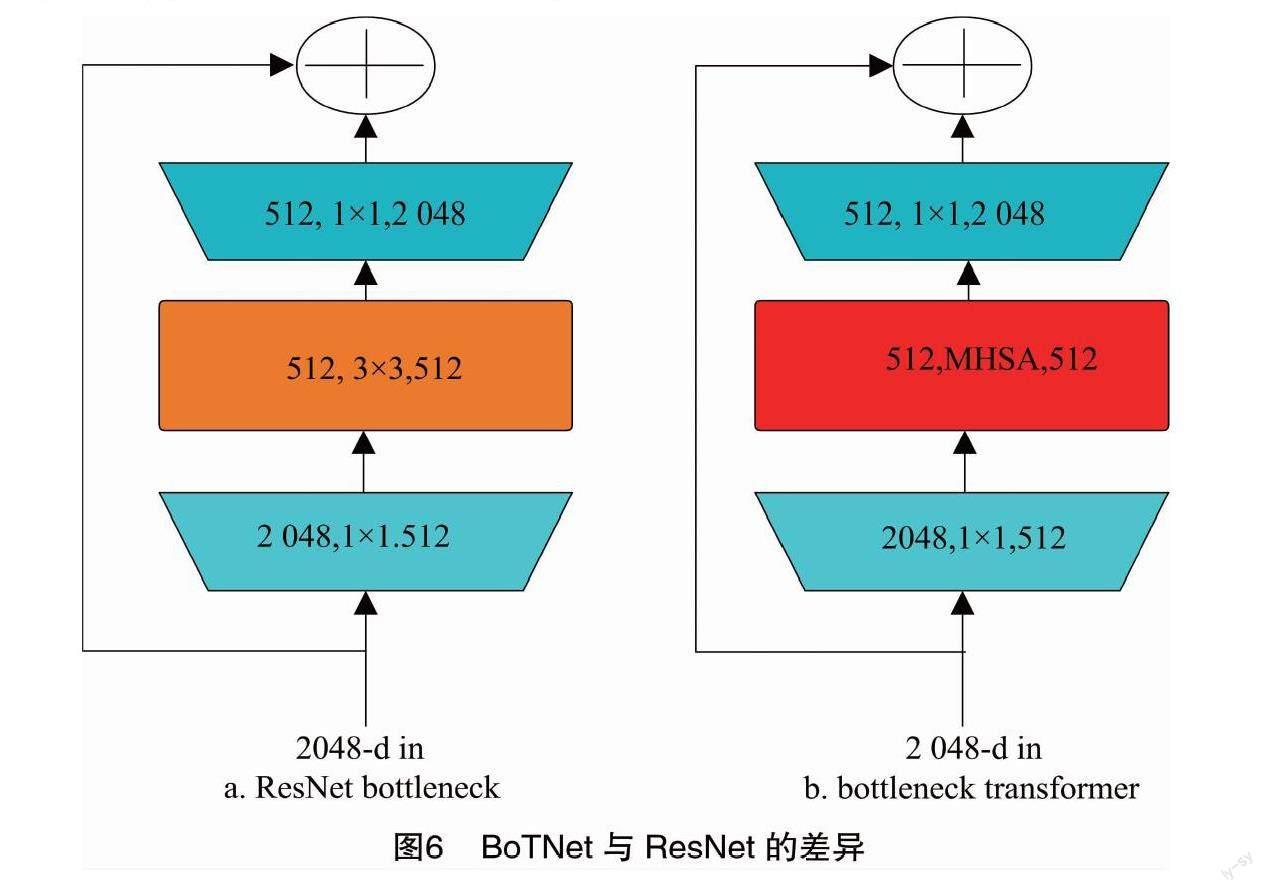
为了使网络能够在不加大计算量的前提下获取到更重要的苹果树叶病害特征,引入了BoTNet(bottleneck transformers)——基于ResNet改进的一种多头自注意力机制(multi-head self-attention,MHSA)[15]。BoTNet与ResNet相比,是在一个标准的bottleneck block中将空间3×3卷积层替换成MHSA,差异见图6,而MHSA原理见图7。
不同的注意力层对应不同的树叶病害类别,在自注意力部分采用的是相对位置编码[16]。具体计算见式(6)至式(8)。
Attention(Q,K,V)=softmaxQKTdkV。(6)
式中:Attention(Q,K,V)为得到的注意力的值;Q、K、V分别为查询量(query)、键(key)和值(value);dk是key的维度。
MHSA是由多个不同的单注意力组成,具体见式(7)~式(8)。
headi=Attention(QWQi,KWKi,VWVi);(7)
MultiHead(Q,K,V)=Concati(headi)WO。(8)
式(7)至式(8)中:Wi和WO为参数矩阵。
综上,改进后的网络结构对不同病害添加了注意力机制,能够学习到每种病害独有的特征,在提取特征时,使用更加高效的SimSPPF,并在预测阶段引入了具有方向性的SIoU,提高了推理速度及准确度。整体改进的结构见图8。
2 结果与分析
2.1 试验环境与参数设置
本研究试验的环境:CPU为AMD R5 5600,GPU为NVIDIA RTX 3070,操作系统为Windows10,编译环境为Python3.7、Pytorch1.12.1深度学习框架,GPU训练加速为CUDA11.6。试验时间为2022年7—9月,试验地点为长江大学农学院与计算机科学学院。试验初始参数设置见表1。
表1中图像大小是调整大小之后得来的,学习率下降方式采用余弦退火(cosine annealing),实现动态的学习率。Batch size为16,训练总的轮次为300次(epoch)。在每个epoch中,对图片的色调、饱和度、亮度进行变化调整,并使用了Mosaic方式将多张图片进行拼接,以实现每个轮次的数据都是不同的,增加网络的泛化性。将原始数据集按照 8 ∶1 ∶1 的比例划分为训练集、验证集和测试集。
2.2 评价指标
本研究采用目标检测领域常见的精准率(precision,P)、召回率(recall,R)、IoU阈值设置为0.5的平均精度均值mAP(mean average precision,mAP)和计算量(GFLOPs)作为评价指标。其中GFLOPs代表10亿次浮点运算量,其他具体计算见式(9)~式(12)。
P=TpTp+Fp;(9)
R=TpTp+Fn;(10)
PmAP=∫10P(R)dR;(11)
PmAP=∑PmAPn;(12)
式中:TP(true postives)是预测正确的正类样本数量;FP(false postives)是预测错误的正类样本数量;Fn(false negatives)是预测错误的负类样本数量;n为预测的类别数。
2.3 对比试验
2.3.1 损失对比 对本研究改进后的YOLOv5s与原YOLOv5s进行对比试验,除本研究改进部分,其他网络参数都参照表1设定,类别训练损失与类别验证损失的过程见图9。由图9可知,改进后的网络,在同样的迭代轮次的情况下,损失更小,网络训练更高效。
2.3.2 注意力机制对比 为验证本研究所提出的BoTNet注意力機制的有效性,在基准模型采用YOLOv5s,且在超参数和图像输入设置相同的情况下,分别将其与当前比较热门的SE(squeeze-and-excitation)、CBAM(convolutional block attention module)、SimAM(simple attention module)注意力机制进行对比,试验结果见表2、图10。
由表2、图10可知,本研究提出的BoTNet注意力机制在更小的计算量和模型权重的情况下,能实现更高的目标检测精度。
2.3.3 网络对比及消融试验 为体现本研究所提出网络性能的优越性,选取SSD、YOLOv3、YOLOv4、YOLOX等几种热门目标检测网络。都使用默认网络参数,且其他条件相同的情况下进行了对比试验。各种网络试验结果见表3。
由表3可知,在最重要的评价指标mAP上,改进后的YOLOv5s网络比SSD网络提升27.9百分点;比YOLOv3网络提升26.6百分点;比YOLOv4提升20.6百分点;比YOLOX网络提升16.2百分点;比基准YOLOv5s网络提升6.3百分点。在精准率和召回率上也都远高于其他网络。
为全面地验证本研究所提出每个改进部分的有效性,对每个改进部分进行消融试验(ablation experiment),即在网络其他条件不变下,每次只增加1个改进部分的试验。试验结果见表4。
通过表4的试验数据可知,每个改进的部分都有效果,在将IoU损失函数改成SIoU后,mAP上升,同时权重大小有微小的下降,说明SIoU相较于CIoU是更高效的。使用了SimSPPF和BoTNet后,在权重大小和计算量(GFLOPs)下降的情况下,mAP实现了明显的上升。说明在将任意大小的特征图转换成固定大小的特征向量的过程中,SimSPPF丢失的信息更少。而BoTNet让整个网络更好地学习到了每种病害的独有特征。
2.4 实例检测
选取测试集的图片,使用上述训练好的各个网络进行实例检测,实例检测结果见图11。
由图11可知,本研究所提出的方法,在识别病害时平均置信度是最高的,实现了更准确的检测。
为验证本研究所提出网络在不同环境下的鲁棒性,选择遮挡、阴影、强光、模糊4种非正常环境的部分测试集图片。环境实例检测见图12。由图12可知,本研究所提出的方法在复杂的环境下也能达到较高的准确度。
3 结论
针对目前苹果树叶病害检测准确度低的问题,本研究提出了一种基于YOLOv5s的方法,首先将边界框损失函数替换成考虑方向性的SIoU,实现了更高效的网络训练,更加准确的推理。在提取图片特征并转换为固定特征的过程中,使用了更优的SimSPPF,丢失的图片特征信息更少。在网络训练过程中加入了BoTNet注意力机制,使网络能学习到每种病害的独有特征。试验表明,所改进的网络相比于其他网络,有着更高的mAP,更低的计算量,更小的模型权重。对复杂环境下采集到的叶片病害图片也能准确地检测,具有一定的环境鲁棒性。在
实际的病虫害防护中,具有一定的应用价值。后续,会收集更加复杂环境下的数据,增加数据集,并采用不同数据预处理方法来提取不同环境下的图片特征,来达到更好的模型泛化性能与精确度。
参考文献:
[1]李会宾,史 云. 果园采摘机器人研究综述[J]. 中国农业信息,2019,31(6):1-9.
[2]李书琴,陈 聪,朱 彤,等. 基于轻量级残差网络的植物叶片病害识别[J]. 农业机械学报,2022,53(3):243-250.
[3]Bari B S,Islam M N,Rashid M,et al. A real-time approach of diagnosing rice leaf disease using deep learning-based faster R-CNN framework[J]. Peer J Computer Science,2021,7:e432.
[4]王超学,祁 昕,马 罡,等. 基于YOLOv3的葡萄病害人工智能识别系统[J]. 植物保护,2022,48(6):278-288.
[5]Richey B,Shirvaikar M V. Deep learning based real-time detection of northern corn leaf blight crop disease using YOLOv4[C]//Real-Time Image Processing and Deep Learning. 2021:39-45.
[6]Haque M E,Rahman A,Junaeid I,et al. Rice leaf disease classification and detection using YOLOv5[EB/OL]. (2022-09-04)[2022-10-10]. https://arxiv.org/pdf/2209.01579.pdf.
[7]雷建云,陳 楚,郑 禄,等. 基于改进残差网络的水稻害虫识别[J]. 江苏农业科学,2022,50(14):190-198.
[8]Ultralytics.YOLOv5[EB/OL]. (2020-06-26)[2022-02-22]. https://github.com/ultralytics/YOLOv5.
[9]Rezatofighi H,Tsoi N,Gwak J Y,et al. Generalized intersection over union:a metric and a loss for bounding box regression[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019:658-666.
[10]Zheng Z,Wang P,Liu W,et al. Distance-IoU loss:faster and better learning for bounding box regression[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020:12993-13000.
[11]Zheng Z H,Wang P,Ren D W,et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics,2022,52(8):8574-8586.
[12]Gevorgyan Z.SIoU loss:more powerful learning for bounding box regression[EB/OL]. (2022-05-25)[2022-10-10]. https://arxiv.org/abs/2205.12740.
[13]He K M,Zhang X Y,Ren S Q,et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[14]Guo M H,Xu T X,Liu J J,et al. Attention mechanisms in computer vision:a survey[J]. Computational Visual Media,2022,8(3):331-368.
[15]Srinivas A,Lin T Y,Parmar N,et al. Bottleneck transformers for visual recognition[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville:IEEE,2021:16514-16524.
[16]Shaw P,Uszkoreit J,Vaswani A.Self-attention with relative position representations[EB/OL]. (2018-04-12)[2022-09-10]. https://arxiv.org/pdf/1803.02155.pdf.
