室内动态场景下基于目标检测算法的语义视觉SLAM
2023-08-06阮晓钢
阮晓钢, 周 晨, 黄 静
(北京工业大学信息学部, 北京 100124)
同步定位与地图构建(simultaneous localization and mapping ,SLAM)是指主体搭载特定传感器,在无环境先验信息的前提下,在运动过程中建立环境模型并估计自身的运动状态[1]。到目前为止,SLAM研究已历经3个阶段的发展,当前阶段的SLAM研究更加注重高层次的理解能力和鲁棒性[2]。SLAM可以有效解决导航中的定位和建图问题,目前,在自动驾驶汽车[3]、室内机器人、增强现实等方面有很多应用。
视觉SLAM系统应用了各类精确的视觉传感器,在相同条件下可以获得更多有效信息[4]。机器视觉理论的诞生明显促进了视觉SLAM的发展,使视觉SLAM成为研究的主流方向之一。部分先进的视觉SLAM算法已被广泛应用。MonoSLAM[1]是最早的实时高频单目视觉SLAM,是视觉SLAM研究发展中的重要里程碑。并行跟踪与建图(parallel tracking and mapping,PTAM)[5]首次区分出前端、后端,可在不同线程下完成建图和跟踪,同时,提供了关键帧提取技术。基于直接法的LSD-SLAM[6]可从姿态跟踪中恢复半稠密的3D地图。基于特征点法的ORB_SLAM2[7]成为首个同时支持单目、双目和RGB-D这3种传感器形式的SLAM系统,该系统可实时计算出相机轨迹,并生成场景三维重建的结果。
尽管许多视觉SLAM算法的性能十分优越,但大部分算法都基于静态环境假设[8]。动态环境是视觉SLAM算法应用在现实世界的一个重大挑战。场景中存在动态物体会造成错误的特征匹配,影响系统的定位和建图精度。在处理动态物体时,大多数视觉SLAM系统是对前端进行修改,具体方法是依据特征点的几何信息进行动静状态检测。Dai等[9]通过地图点之间的相关性区分特征点的动静状态;Li等[10]通过对关键帧边缘点使用静态加权的方法减少动态物体的影响;Zou等[11]通过将地图特征投影到当前帧计算重投影误差,通过计算结果判断特征点是否为动态。以上方法均采用几何计算来判断特征点是否为动态特征点,因为没有考虑到使用图像帧中各物体的语义信息,所以在处理一些位于物体边缘等特殊位置的特征点时,容易出现状态判断错误,导致错误匹配数量增多,使系统在动态环境中的定位精度降低。
近年来,深度学习取得了重大发展,部分研究人员将深度学习和动态环境下的SLAM问题结合起来[12],依靠语义信息处理动态物体成为新的选择方式。Xiao等[13]通过使用单次多框检测器 (single shot multibox detector, SSD)有效去除了动态物体区域内的特征点;Zhong等[14]提出Detect-SLAM,通过使用更加精准的目标检测器去除了动态物体中的不可靠特征点;Bescos等[15]提出了DynaSLAM,将语义分割和多视角几何结合,利用MASK-R-CNN进行动态目标实例分割,对动态特征点进行精准去除,并修复背景;DS-SLAM将SegNet语义分割网络与运动一致性检测方法进行结合,减少了动态目标的影响,动态环境下的定位精度得到了显著提高[16]。文献[17]中提到Detect-SLAM、DynaSLAM、DS-SLAM是近年来解决动态SLAM问题的有效方法,但同时也指出:Detect-SLAM使用的语义分割网络无法有效区分同类动态物体;DynaSLAM耗时严重,实时性差;DS-SLAM通过语义分割网络和几何检测相结合的方式可以有效平衡检测的速度和精度,但动态物体只能限定为人。
针对动态环境进行的SLAM研究虽然日趋完善,但依然存在各种问题。文献[18]指出RGB-D SLAM[19]是目前通过结合深度学习解决动态SLAM的优秀系统,该系统语义分割精度高,但运动检测的鲁棒性和时间效率性能欠佳。与RGB-D SLAM系统类似,SaD-SLAM[20]也是目前通过结合深度学习对动态物体进行精准分割的动态SLAM系统,该系统借助语义信息和深度信息,跟踪性能稳健,但该系统的速度同样不满足实时性要求。除此之外,文献[18]提出的RS-SLAM系统是目前本研究领域十分成功的鲁棒语义视觉SLAM系统,通过使用金字塔场景解析网络 (pyramid scene parsing network, PSPNet)识别场景中的动态物体,显著提高了定位精度、鲁棒性和时间效率,但该系统将人限定为绝对动态物体,造成部分可用信息丢失。
本文提出的算法是将YOLOv5s目标检测网络和几何筛选进行有效结合,从而高效去除动态特征点。实验结果证明,本文算法在提高位姿估计准确性上效果明显且系统的运行速度较快。
1 系统框架
ORB_SLAM2延续PTAM的算法框架,使用ORB特征,拥有比PTAM更好的视角不变性,并且ORB_SLAM2具有更加鲁棒的关键帧和三维点选择机制,整体系统具备跟踪、局部建图、回环检测3个线程,系统在回环检测后进行全局束调整。ORB_SLAM2系统结构完善,性能较好,因此,目前众多研究动态场景的系统都是在ORB_SLAM2的基础上进行改善的,本文提出的语义视觉SLAM也是以该系统为基础,具体的系统框架如图1所示。改进后的系统在原跟踪线程上并行添加目标检测线程。原始的图像帧在采集后同时进行目标检测和提取ORB特征点,目标检测线程在进行物体识别后划分出动静区域,并将划分结果传送至跟踪线程。跟踪线程根据划分结果和几何约束方法综合判断特征点的动静状态。YOLOv5s和几何约束方法共同将提取的ORB特征点中的动态特征点进行精确剔除,使用剩余的静态特征点进行后续位姿估计。文献[21]证明单独使用几何约束的方法在判断位于物体边缘等位置的特征点时容易出现错误。文献[16]通过使用语义信息和几何信息来联合估计位姿的方法显著提高了定位的准确性,故本文使用了目标检测算法和几何约束相结合的方式。YOLOv5s目标检测算法可有效规避几何约束对物体边缘特征点判断能力弱的缺点,同时,几何约束也可以对目标检测无法检测到的潜在动态物体上所包含的动态特征点予以剔除,二者相互补充。
1.1 基于YOLOv5s的目标检测
YOLO是基于神经网络的单阶段目标检测算法,可从输入的整张图片中直接得到多个目标的边界框及对应目标的分类概率。该算法是目前较为先进的实时目标检测算法[22]。

图2 YOLOv5的4种模型的速度和精度Fig.2 Speed and accuracy of four models of YOLOv5
本文算法在训练中使用的是MS COCO[24]数据集训练权重,数据集包括80种物体,如人、自行车、显示器、笔记本电脑、冰箱、键盘、椅子、杯子、猫、狗等,几乎包含了常见室内环境下的所有动态物体。YOLOv5s网络在Backbone和Neck部分分别使用了不同的跨阶段网络结构,其特征融合能力很强。经过实际训练发现,YOLOv5s的训练时间远远短于YOLOv4。YOLOv5s会对原始图像进行预处理,使之成为标准大小,然后,将图像划分为若干网格,每个网格分别预测多个边界框,每个边界框的预测值含5个元素:x、y、w、h、c。其中:(x,y)表示边界框中心位置坐标;(w,h)表示预测边界框和整张图片在高度、宽度上的比例;c表示置信度,置信度大小由边界框包含的目标概率和边界框预测的准确度共同决定,而最终识别的物体类别概率就是在该置信度下产生的条件概率。为避免划分的多网格响应同一目标,YOLOv5s通过使用非极大值抑制(non-maximum suppression,NMS)获得置信度最高的边界框。
常见场景中除MS COCO数据集列举的动态物体外,还存在一类潜在的动态物体,虽然这类物体无法依靠自身移动,但可以跟随人一起移动,如人拿着杯子,人移动会带动杯子运动,显然单独使用YOLOv5s检测到杯子是静态物体是不准确的,语义静态区域并非真实的静态区域,还需要与几何约束的判断相结合,共同判断动静区域。图3展示了对目标检测的实际效果。图3(a)为YOLOv5s对慕尼黑工业大学(Technical University of Munich,TUM)数据集的一张图像帧进行目标检测的效果;图3(b)为YOLOv5s对实际室内场景进行目标检测的效果。

图3 YOLOv5s的检测效果Fig.3 Detection effect of YOLOv5s
1.2 几何约束筛选
在几何判断中,首先使用光流法进行特征点跟踪,光流不需要计算描述子和匹配特征即可实现跟踪,实时性好。Lucas-Kanada光流算法[16,25]基于相邻帧像素灰度不变假设,将图像视为时间的函数f(t),t时刻坐标(x,y)的特征点灰度值为f(x,y,t),t+dt时刻的后续帧中特征点的灰度值f(x+dx,y+dy,t+dt)基于灰度不变假设应符合
f(x,y,t)=f(x+dx,y+dy,t+dt)
(1)
泰勒展开后满足
(2)
计算式(2)可得
(3)
(4)
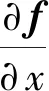
拈花湾集聚了当地的山水资源、灵山景区的佛教文化资源等,塑造了禅意景观和表演等新的旅游吸引物。而当地政府部门,无论是在土地配给,还是资金扶持方面,都给予了实质性的支持。在各类旅游风情小镇开发中,政府居于主导地位。因此,开发旅游风情小镇,便应该发挥政府在区域中的协调功能,有效地统筹区域内的各类旅游资源,合理规划,整体布局,为旅游者提供更加丰富的旅游服务。
(5)
Lucas-Kanada光流算法假设同一子图像内像素点运动相同,基于这样的假设可计算得到u和v,也即得到像素点在后续帧中的位置,最终实现特征点跟踪。
在使用光流法获得相邻帧中的匹配特征点后,可利用匹配特征点计算基础矩阵。假定p1和p2为匹配的特征点,坐标依次表示为
(6)
利用基础矩阵和特征点坐标可得到极线
(7)
式中F为基础矩阵。p2到极线I1的距离d可表示为
(8)
当距离d大于预定阈值时,可判断p2为动态特征点。
2 实验部分
本文选用TUM数据集的多组序列进行3组实验。其中:第1组实验展示通过使用YOLOv5s识别动态目标进而剔除目标区域内动态特征点的效果;第2组实验用于检验本文算法在轨迹误差方面的精度;第3组实验用于检验本文算法的运行速度。TUM-RGBD[26]开源数据集是评估RGB-D SLAM系统基准的常用数据集,该数据集包含39个序列,每个序列包含彩色图、深度图和相关的地面真实相机位姿。图像的采集分辨率为640×480像素,记录频率为30 Hz。 本文针对室内动态环境进行研究,故选用walking序列作为实验数据序列,walking序列主要记录2个人围绕办公桌的走动。其中:walking_xyz、walking_static、walking_half均为高动态序列,不同之处在于拍摄时的传感器运动方式不同;sitting_static为低动态序列,主要记录2个人坐在桌前,仅手部有动作变化。文献[16,19,27-28]针对动态场景进行的视觉SLAM研究均以ORB_SLAM2为基础框架,对ORB_SLAM2算法的内部参数均未提及,鉴于ORB_SLAM2算法已被多次使用,是十分成熟的算法,内部参数已经实现充分优化。为了保证各组实验对比的公平性,本文有关ORB_SLAM2部分的参数均为其原始参数。
衡量SLAM系统定位精度的常用指标为相对位姿误差(relative pose error,RPE)和绝对轨迹误差(absolute trajectory error,ATE)。RPE可测量固定时间间隔内估计运动和真实运动之间的姿态变化量差值,ATE通过比较估计运动和真实运动的绝对距离可评估全局一致性。RPE需要同时考虑平移误差和旋转误差,ATE只考虑平移误差。定义时间步长为i,时间间隔为Δ,则相对位姿误差为
(9)
式中:Qi为第i帧的真实位姿;Pi为第i帧的估计位姿。绝对位姿误差为
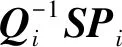
(10)
式中S为估计位姿到真实位姿的转换矩阵。
2.1 效果对比实验
选用TUM数据集中walking_xyz序列的一组图进行对比,图4(a)为传统ORB_SLAM2算法在室内动态场景下采集的特征点,图4(b)为本文算法采集的特征点。可以明显看出,本文算法可有效识别2个人为动态物体,并去除人所包含的动态特征点,而其余的静态特征点则被保留。
2.2 精度对比实验
本文实验使用walking_xyz、walking_static、walking_half、sitting_static共3个高动态序列和1个低动态序列进行精度对比,采用ATE和RPE进行定量估计,给出均方根误差(root mean square error,RMSE)、标准差(standard deviation,Std)共2个具体指标。精度提高程度的计算公式为
(11)
式中:α为ORB_SLAM2的运行结果;β为本文算法的运行结果。
图5~7依次显示了ORB_SLAM2和本文算法在使用3个高动态序列时ATE和RPE的对比。可以看出,本文算法的ATE和RPE在不同序列中均显著小于ORB_SLAM2,但图7(b)显示当相机进行翻滚等快速运动时,本文算法容易出现跟踪丢失,这是因为目标检测网络所划分的动态区域过大,导致区域外的静态特征点数量太少,无法实现有效跟踪。

图5 walking_xyz的ATE和RPEFig.5 Absolute trajectory error and relative pose error of walking_xyz

图6 walking_static的ATE和RPEFig.6 Absolute trajectory error and relative pose error of walking_static

图7 walking_half的ATE和RPEFig.7 Absolute trajectory error and relative pose error of walking_half
表1~3依次显示了ORB_SLAM2和本文算法在4个不同序列下的数据对比及对应数据的提高程度,表中各个数据是使用同一计算机得到的结果。可以看出:在高动态序列中,本文算法相较于ORB_SLAM2在各项数据中都有了显著提高;在低动态序列中,各项数据的提高程度并不明显,这是因为此时的动态物体较少,ORB_SLAM2可以依靠自身的噪声剔除算法很好地处理低动态场景,本文算法在低动态场景中所能提升的性能并不明显。本文算法和DS-SLAM、DynaSLAM的RMSE对比结果见表4,DS-SLAM、DynaSLAM的相关数据分别见文献[16]和DS-SLAM。与DynaSLAM对比后发现,本文算法的RMSE稍大于DynaSLAM,这是因为DynaSLAM降低了系统实时性而提高了检测精度。本文算法在精度上虽然稍差,但速度快,改进了DynaSLAM系统在速度和精度上无法平衡的缺点。
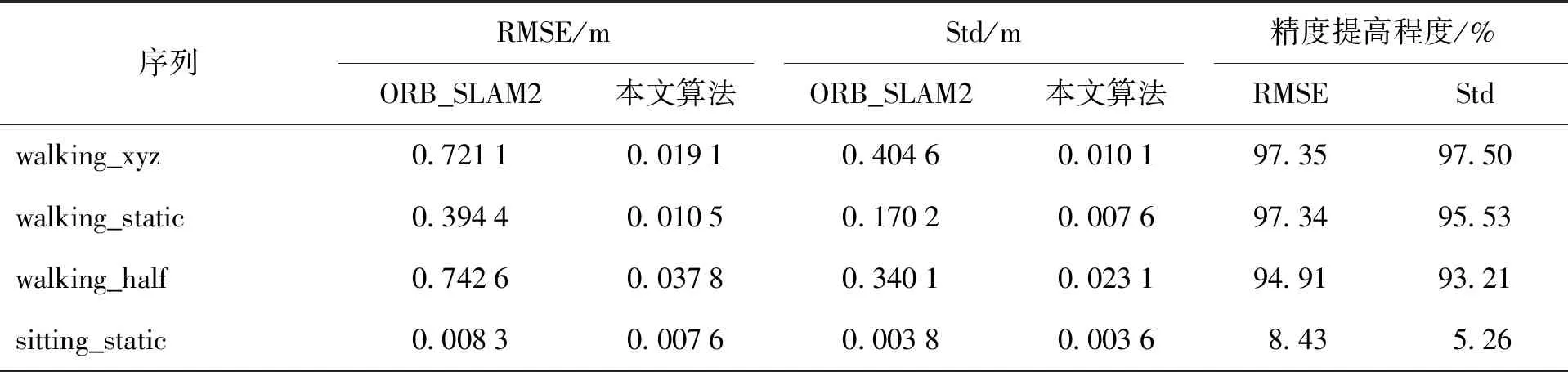
表1 ATE对比

表2 RPE中平移误差对比

表3 RPE中旋转误差对比

表4 动态环境下的SLAM算法RMSE对比
文献[15]。由表可知,本文算法在各序列中可实现与DS-SLAM、DynaSLAM相近的精度。在walking_xyz序列中,本文算法的RMSE小于DS-SLAM,在walking_static和walking_half序列中RMSE大于
2.3 速度对比实验
在处理动态环境的语义视觉SLAM研究中,速度是一个重要指标,表5对比了本文算法和ORB_SLAM2、DS-SLAM及DynaSLAM等在同一计算机上的运行时间。因为在ORB_SLAM2的系统框架上增加了目标检测线程和几何筛选部分,所以本文算法的跟踪时间长于ORB_SLAM2,但与DS-SLAM、DynaSLAM相比,本文算法在速度方面的性能有显著提升。综合考虑各项数据,本文算法在精度和速度上实现了很好的平衡。

表5 动态环境下SLAM算法的图像处理时间
3 结论
1) 本文提出一种面向室内动态环境的语义视觉SLAM系统,该系统在ORB_SLAM2的基础上添加了YOLOv5s目标检测线程,经过检测可以获得图像帧中动态物体所在区域,配合几何约束判断可准确筛选动态特征点。
2) 经过和其他SLAM算法在多方面的对比,结果显示本文算法显著提高了位姿估计的精度,并保证了运行速度,实现了速度和精度的平衡。
3) 本文算法在处理动态区域过大的图像帧时,容易造成特征点数量不够。当图像帧中动态物体移动过快时,容易造成目标检测线程和其他线程在图像帧处理上出现异步。如何解决以上问题,并且还能平衡未来动态场景下语义视觉SLAM算法的速度和精度,成为下一步需要解决的问题。
