基于人工智能的远程火灾实时探测报警系统设计
2023-08-04耿潘潘张勇昌
耿潘潘,张勇昌
(江苏建筑职业技术学院,江苏徐州 221116)
0 引言
传统的火灾和烟雾探测器基于热传感器和化学传感器。这些传感器适用于室内环境,并且需要较多的探测时间和火灾或烟雾量来提醒居住者。此外,如果系统未正确安装和维护,或位于火灾位置附近,则可能发生故障[1]。根据不完全统计,在住宅火灾中死亡的人员中,有11%没有获得火灾和烟雾探测器的有效提醒,还有60%的住宅火灾死亡是在没有烟雾探测器或探测器发生故障且未向居住者发出警报的建筑中造成的。然而,大多数消防队员在应对建筑火灾时,会受到人力、设备和预算等可用资源的限制。另外,现代建筑材料和技术、开放式布局和合成家具对火灾发生的影响比其传统产品更大。这些变化导致了火灾传播速度更快、人员逃生时间和建筑结构倒塌时间更短,导致有效火场扑救的可用时间缩短[2]。因此,亟须一套反应速度更快、覆盖范围更广的火灾报警系统来提高火灾险情的预警。
对于建筑火灾,传统的探测方法依赖于火灾和烟雾探测器,其局限性和有效性主要取决于烟雾的体积与起火位置的接近程度[3]。一个被忽视的因素是来自无处不在的智能摄像设备的图像流,这些设备在大多数建筑环境中都很容易获得。将获取的图像流与用于图像分类的机器学习集成,可为远程实时自主火灾和烟雾检测提供有效的解决方案[4]。随着人工智能、图像处理、计算机视觉和物联网平台的快速发展,与摄像头集成的智能设备为远程实时自主火灾和烟雾检测提供了有效的解决方案[5]。
研究开发了基于AI的物联网系统,系统使用来自摄像头的实时视频流来自动远程检测火灾和烟雾,并通过消息实时通知用户。用户可以验证系统检测到的火灾视频片段,并激活警报以提醒其他人或采取必要的行动。这种火灾的早期发现和及时反应可以减轻火灾进一步恶化和蔓延,使消防员能够在火灾初期控制和扑灭火灾,使居民能够尽快逃离建筑并远离火灾地点,简化搜救行动,减少财产损失,避免消防员和居民伤亡及财产损失。
1 系统设计
远程火灾实时探测报警系统部署架构(如图1 所示)主要分为三个主要组件:1)火情现场图像/视频获取;2)运用对象检测模型进行火灾和烟雾检测;3)火情预警用户通知。
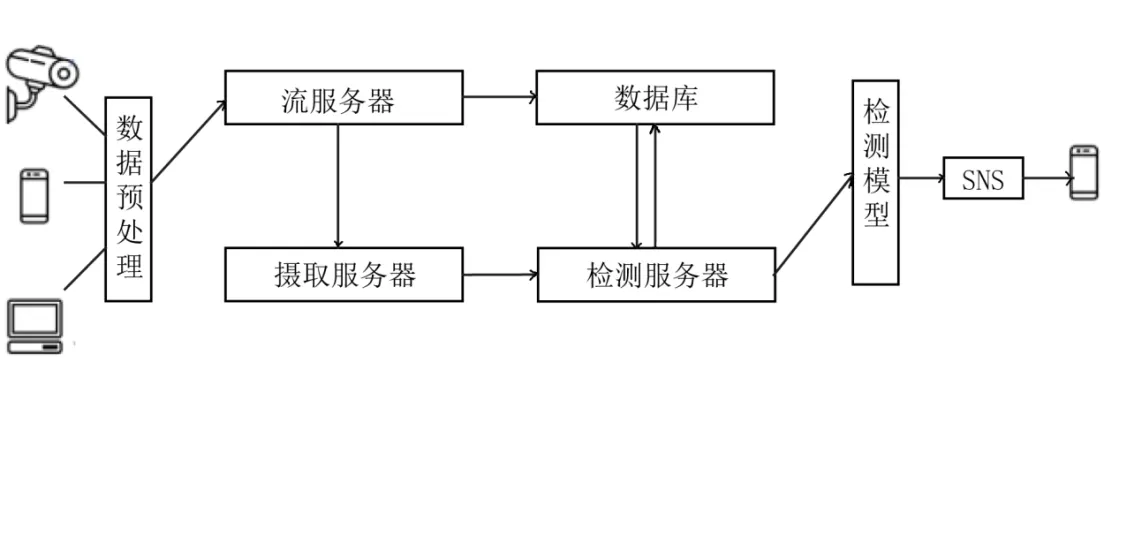
图1 远程火灾实时探测报警系统架构
在第一个组件中,将来自网络摄像头、流媒体软件、移动电话或与摄像头集成的任何其他设备的视频流传送到流媒体服务器,以备下一步处理。由于大多数移动电话和网络摄像头不支持发布编码视频流,因此流媒体服务器首先将视频编码为标准格式,并使用实时消息协议将其发布到摄取服务器。具有内置编码器(例如IP 摄像头)的设备理想情况下可以直接发布到摄取服务器,摄取服务器也可以通过中央流式服务器进行元数据捕获,将视频输入直接提供给检测服务器以减少延迟。流服务器将流元数据和用户信息存储在数据库(如Mongo DB) 中,同时流服务器将流发布到摄取服务器。检测服务器对来自摄取服务器的编码流进行检测。流服务器将得到来的流通知检测服务器,以便可以准备好执行检测。
在第二个组件中,检测服务器从摄取服务器中读取视频流,并从视频输入流中提取帧,将每个帧传送到对象检测模型,执行火灾和烟雾检测。由于传统常规的检测算法在检测速度和准确度方面都没有特别显著的性能优势[6],因此为了提高火灾检测的准确性,系统运用EfficientDet 和Scaled-YOLOv4 两种检测模型进行图像帧的检测。
EfficientDet 是一种快速、高精度的检测器,它使用EfficicentNet 架构作为其主干[7]。将图像作为输入并生成特征图,这些特征图被发送到具有可学习权重的双向特征网络(BiFPN),以确定每个输入特征图的重要性。BiFPN 作为一个特征网络,产生融合特征,这些融合特征被传送到基于卷积的类和框网络,以分别检测对象类和边界框。为了提高特征网络的效率,提出了一种新的双向特征网络BiFPN,它结合了FPN/PANet/NAS-FPN 的多级特征融合思想这使信息能够在自上而下和自下而上的方向上流动,同时使用常规和高效的连接。传统方法通常平等地对待输入到FPN 的所有特征,即使是那些具有不同分辨率的特征[8]。然而,观察到不同分辨率的输入特征通常对输出特征的贡献不等。因此,需要为每个输入特征添加一个额外的权重,并允许网络学习每个特征的重要性。通过优化,新的双向特征网络BiFPN进一步将准确度提高了4%,检测速度快了3倍。
在COCO 数据集上评估EfficientDet,COCO 数据集是一种广泛使用的对象检测基准数据集[9]。EfficientDet实现了52.2的平均精度(mAP),比之前的最先进模型高出1.5 个百分点,同时使用的参数减少了4倍,计算量减少了9.4倍。
Scaled-YOLOv4 在视频分析的准确性和速度方面都有显著的优势。与EfficientDet 相比,Scaled-YOLOv4 能选择的网络结构更多[10]。它使用跨阶段部分Darknet53(CSPDarknet53)架构作为其主干,从输入图像和路径聚合网络(PANet) 中提取特征图。此外,还在主干之后使用空间金字塔池来增加其感测度,并从特征图中分离重要特征[11]。除了架构改进,Scaled-YOLOv4 还使用了其他两种技术来提高性能。通过在训练模型时应用若干数据增强来实现图像的识别,并通过使用Mish激活函数、DIoU NMS、CmBN和DropBlock正则化来提高图像的识别率。
对于给定的帧,如果两个模型检测到火灾的概率都高于风险阈值,则系统会确认帧中存在火灾。为了避免误报,如果两个或任何一个模型都没有在给定的帧中检测到火灾,则该帧不会被作为火情用于最终输出。实验发现与EfficientDet 的预测相比,Scaled-YOLOv4的预测更准确和精确。
因此,一旦两个模型都确认给定帧中存在火灾,则将Scaled-YOLOv4 生成的边界框通知用户。实验实现了类似的逻辑来确认和通知烟雾的检测。在给定的帧中(尤其是在火灾的初始阶段),火和烟可能同时存在,也可能不同时存在,因此,如果两个模型都检测到火灾或烟雾,则将通知用户。这些检测结果基于存储在数据库中的流密钥和流索引存储在检测服务器中,以满足GPU支持快速推断的需要。
针对实况视频流可能包括火灾静态图(例如,挂在墙上的火灾图片)或周围类似物体的静态图像,而使得当前人工智能检测模型产生错误警报的问题,系统通过算法检测火灾和烟雾的大小变化来判断是否是真实的火灾,即它可以区分视频流中存在的真实火灾和火灾(或类似物体)的静态图像。在火灾初期,火灾和烟雾的规模都较小,随着时间的推移,它们会不断变化和增加。系统算法通过测量从模型中获得的火灾和烟雾的边界框的面积来记录火灾和烟雾大小。基于视频流的帧速率,如果算法检测到火灾或烟雾的边界框的总面积在特定时间内有80%的帧在变化或增加,则确认视频流中存在真实或实况火灾。然而,火灾(或类似对象)静态图像的边界框不会连续更改或增加。因此,该技术有助于本系统显著消除错误检测。
对于视频流中的所有连续帧,来自两个AI模型的输出可能一致,也可能不一致。因此,在最后的第三部分中,如果某个时间段内的80%的连续帧被报告为火灾或烟雾,其概率超过两个模型的风险阈值,则相应时间段的所有输出帧以编程方式组合,以生成视频剪辑,该视频剪辑将自动实时发送给最终用户。通知通道使用简单通知服务(SNS)发送消息。在收到通知后,用户可以根据需要采取必要的行动,或者如果判断收到视频并非火情,则忽略该消息。同时,要求用户验证输出并反馈,以进一步改进系统的模型和精度。
2 实验仿真
系统运用PyTorch框架创建和训练模型。训练平台包括一台32GB 内存的Linux 服务器和一台48GB GDDR6 VRAM的Nvidia Quadro RTX8000 GPU。
根据燃料类型,国家标准(GB/T 4968)将火灾分为六种主要类型:A 类指固体物质火灾,这种物质通常具有有机物质性质,一般在燃烧时能产生灼热的余烬。B类指液体或可熔化的固体物质火灾。C类指气体火灾。D 类指金属火灾。E 类指带电火灾。F 类指涉及可燃烹饪介质的烹饪器具火灾。实验收集13000张图像,确保了图像在所有六类火灾中的均匀分布。这些原始图像非常嘈杂,并且格式不统一,无法将它们直接输入模型进行训练。因此,通过预处理程序对所有图像进行清理。预处理步骤包括移除重复或相似的图像以保持六类火情的平衡,移除含有大量文本的图像,清理损坏的图像等。最终的数据集包括7560张图像,其中包括所有类均匀分布的火情图像,并用适当的边界框手动注释。
首先在公共环境数据集COCO 上对模型进行预训练。预先训练模型有助于卷积层从日常图像场景中识别图案、纹理和对象。因此,模型内核不需要学习从图像中提取特征的基础知识,并且当预训练的模型最终在系统中的火灾和烟雾数据集上训练时,可以提供更快的收敛速度。然后针对火灾和烟雾数据集对其进行微调。该模型被训练了150个周期,批大小为16,随机梯度下降法(SGD)优化器的初始学习率为0.003,在第120个周期后下降了10%。系统还添加了0.0005的L2正则化调整,以避免过度拟合。
为进一步提高模型从图像中检测到火灾和烟雾的速度,系统创建定制大小的锚框,以适应数据集。为了找到数据集的模板锚框的尺寸,首先通过将训练集中的图像边界框尺寸除以各自的图像尺寸,使其在范围[0,1]内,即对其进行标准化。归一化后,将每个边界框的高度和宽度发送给k-Means 算法,该算法将这些边界框分割,其中分割数n 可以是9 或12。每个簇的质心被视为模板锚框尺寸。通过将所获得的尺寸乘以640,即给定模型的输入图像的尺寸。算法从初始值开始,并尝试在每一代优化之后最大化适应度得分。该算法主要运用变异和交叉的遗传算子,算法使用90%概率和0.04 方差的变异,将模型运行300次,其中每一次模型训练10个周期,根据前几次中最好的组合创建新的后代。该方法显著提高了Scaled-YOLOv4模型的性能。
通过仿真实验对EfficientDet、Scaled-YOLOv4 和Faster RCNN 三种模型进行比较。与EfficientDet 和Scaled-YOLOv4 相比,通过训练Faster RCNN 获得的平均精度mAP值最低。实验对Faster RCNN的平均精度mAP 值与EfficientDet 和Scaled-YOLOv4 模型中的最佳对象探测器的mAP进行了比较,如表1、表2、图2和图3 所示。可以看出,Scaled-YOLOv4 在三种模型中给出了最佳的平均精度mAP。表2 比较了每个探测器在每个图像或视频帧中探测火灾和烟雾所用的平均时间。研究分析发现,Scaled YOLOv4 和EfficientDet模型检测图像的速度更快、更准确。因此,将它们集成到物联网系统中,用于实时检测图像和视频流中的火灾和烟雾。
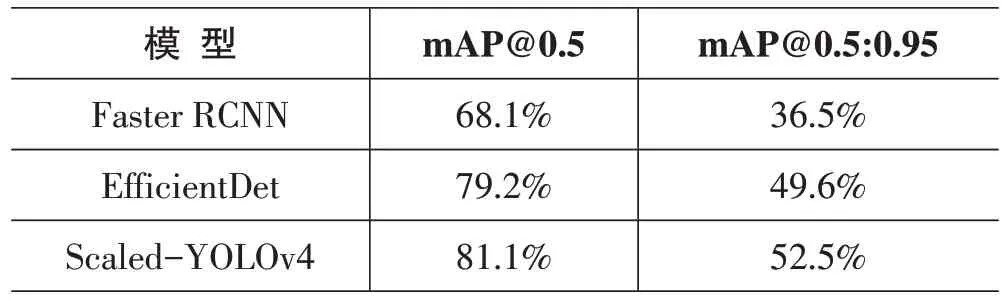
表1 三种检测模型的mAP值比较

表2 三种检测模型对图像或帧的平均目标检测时间比较
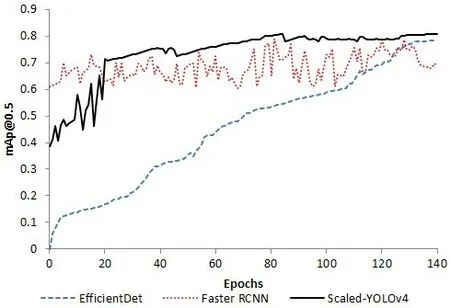
图2 验证集上mAP@0.5值的比较
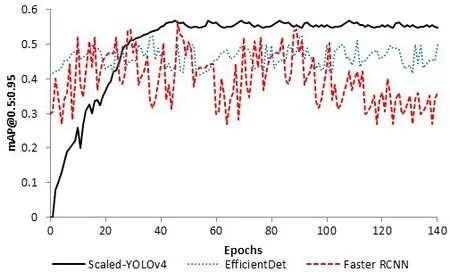
图3 验证集上mAP@0.5:0.95值的比较
图4 显示了从EfficientDet、Scaled-YOLOv4 和Faster RCNN 获得的输出与大小不同的原始目标图像和所有六类火灾的比较,火灾用蓝色边界框描绘,烟雾用红色边界框描绘。显然,Scaled-YOLOv4 和EfficientDet 的火灾和烟雾检测明显优于Faster RCNN。因此,系统将其集成到物联网系统中,用于实时检测图像和视频流中的火灾和烟雾。

图4 EfficientDet、Scaled-YOLOv4和Faster RCNN检测模型的输出比较
3 结论
研究开发了一种用于实时远程火灾和烟雾目标检测的AI 模型。设计了一个自定义的火灾和烟雾图像数据集,其中包括国家标准指定的所有六类火灾。与Faster RCNN 相 比,Scaled-YOLOv4 和EfficientDet在实时检测给定输入图像或视频流中的火灾和烟雾方面更准确、更快、更可行。实现了一种基于端到端物联网云的远程火灾预警系统,系统可以从摄像头集成的设备接收实时视频流(RTSP/RTMP/SDP),提取帧,将其同时传送到多个对象检测模型,并计算输入中存在火灾和烟雾的概率。基于系统中设置的风险阈值和自定义标准,可以在火灾的初始阶段发现火灾,并以编程方式编译输出视频剪辑,通过消息自动实时发送给用户,使其在必要时立即采取适当的行动。这种火灾的早期发现和及时反馈可以减轻火灾蔓延,使消防员能够更有效地控制和扑灭火灾,使居住者能够及时逃离火灾地点,简化搜救行动,尽量避免消防员和居民的伤亡及财产损失。
