基于Paddle Detection框架的情绪识别的研究和实现
2023-08-04胡阳李若冰李树源吕俊晓王帅昊李书涵蔡嘉琪张虎
胡阳,李若冰,李树源,吕俊晓,王帅昊,李书涵,蔡嘉琪,张虎
(河南科技大学软件学院,河南洛阳 471003)
0 引言
人脸表情识别(Facial Expression Recognition,FER)是计算机视觉领域中图像分类的一个最重要的应用场景,相较于目标检测、实例分割、行为识别、轨迹跟踪等难度较大的计算机视觉任务,图像分类只需要让计算机“看出”图片里的物体类别,虽较基础但极为重要。近年来,人脸表情识别引起了学术界和工业界的研究热潮,因为表情是人们在日常交流中重要的表达方式之一,在无法获取说话人语气的情况下,表情就成了理解语言含义不可或缺的一部分。FER 是一门交叉学科,涉及计算机视觉、人机交互、生理学、心理学、模式识别等研究领域[1]。在社会的众多领域,例如机器人制造、自动化、人机交互、安全、医疗、驾驶和通信等,表情识别同样具有很高的实用价值。同时,表情识别应用场景丰富,以表情分析为核心技术的学生课堂状态智能分析平台来关注学生的学习生活状态、通过表情分析来协助民警对表情异常和行为可疑的嫌疑人进行筛选锁定等。
深度学习是实现机器学习的核心技术,而做深度学习有较高的门槛,开发效率较低。深度学习框架通过将深度学习算法进行模块化封装,能够实现训练、测试、调优模型的快速搭建。当前流行的深度学习框架主 要包括Tensor Flow、PyTorch、Theano、Keras 和Paddle Paddle等。深度学习框架的本质是自动实现建模过程中相对通用的模块,建模者只实现模型的个性化部分,可以节省编写大量底层代码的精力[2]。
项目完成后,对通过机器识别给定的静态图像或动态视频序列中分离出特定的表情状态,从而确定被识别对象的心理情绪,实现计算机对人脸表情的理解与识别,可从根本上改变人与计算机的关系。使计算机可以更好地为人类服务,从而达到更好的人机交互。表情识别技术是人们探索和理解智能的有效途径。
1 项目研究方法
本项目采用的研究方法如图1所示。
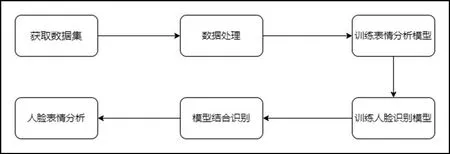
图1 项目研究过程
第一步:制作两个模型的数据集,首先下载所用的数据集图像,原始的图像数据会存在一些脏数据,需要做好数据处理工作,将图像数据整理成规范统一的形式。
第二步:数据增强处理,深度学习要求样本的数量要充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强,所以增加训练的数据量,提高模型的泛化能力,增加噪声数据,提升模型的鲁棒性。
第三步:划分数据集,对于大数据量的数据集,将80%的数据划为训练集、20%的数据划为验证集。使用fer2013 数据集进行Res Net50 分类模型训练,训练Res Net50 分类模型来获得表情分析权重,使用WIDER-FACE 数据集进行Blaze Face 模型训练,训练BlazeFace模型来获得人脸识别权重[3]。
首先,使用Paddle Detection 套件中的目标检测模型识别出人脸区域,再将此人脸区域输入基于Res Net50的表情判别网络以完成情感分类,最终实现FER任务[4]。
2 Resnet人脸识别模型
项目使用Resnet50 网路进行表情识别,Resnet 网络是在2015 年由来自Microsoft Research 的4 位学者提出的卷积神经网络,斩获当年Image Net竞赛中分类任务第一名,目标检测第一名[5]。获得COCO 数据集中目标检测第一名,图像分割第一名。而Resnet50就是指深度为50的Resnet网络,是Resnet网络中最主流的深度选择之一。
Resnet 网络使用了一种连接方式叫作“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思。它对每层的输入做一个reference(X),学习形成残差函数,而不是学习一些没有reference(X) 的函数。这种残差函数更容易优化,能使网络层数大大加深。
ResNet50 有两个基本块,分别名为Conv Block 和Identity Block,其中Conv Block 输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络。
3 人脸识别的实现
3.1 Paddle Detection 深度学习框架
本项目在人脸识别方面使用的是飞桨Paddle Pddle深度学习框架。Paddle Detection 是百度飞桨目标检测开发套件,实现了端到端地完成从训练到部署的全流程目标检测应用。基于百度飞桨的高性能内核,使模型训练速度及显存占用有明显提高,加快了整个项目的实现。本文应用Paddle Detection套件快速开发和部署人脸表情情绪分类模型,有利于得到准确的情绪分析结果。
3.2 模型选择
BlazeFace 模型用来训练识别图片中的人脸,Blaze Face模型是训练和评估在WIDER-FACE数据集上的模型,也是一个非常轻量级的人脸检测器。WIDER FACE数据集是人脸检测的一个benchmark数据集,包含32 203 个图像,以及393 703 个标注人脸。每一个数据子集都包含3 个级别的检测难度:Easy、Medium、Hard。这些人脸图像在尺度、姿态、光照、表情、遮挡方面都有很大的变化范围,以便训练效果更加真实准确。
项目选择了Paddle Detection 内置的BlazeFace-FPN-SSH 改进模型,增加FPN 和SSH 的neck 结构,由原来的relu 激活函数改进为hard_swish,改进模型有助于提高系统识别精度和性能。
3.3 数据增强方法
尺度变换:根据随机选择的人脸高和宽,获取到v=sqrt{width*height},然后再判断v的值范围,其中v值位于缩放区间[16,32,64,128],假设v=45,则选定32<v<64,以均匀分布的概率选取[16,32,64]中的任意一个值。若选中64,则该人脸的缩放区间在[64/2,min(v*2,64*2)]中选定。
图像随机剪切:根据随机的比率aspect_ratio=math.sqrt(np.random.uniform(*ratio)),通过获取的比率随机对原图像进行选择剪切,获取到目标区域target_area=img.shape[1]*img.shape[0]*np.random.uniform(scale_min,scale_max) target_size=math.sqrt(target_area)后,将原来的图片进行随机裁剪。
随机旋转:根据选择的人脸高和宽,angle=np.random.randint(-14,15),将图片随机旋转-14 到15 之间的某一个角度获取图像的尺寸,旋转中心后设置选择矩阵,最后重新计算图像旋转后的新边界。loss 可视化效果如图2所示。

图2 loss可视化
3.4 模型训练
Blaze Face 和Face Boxes 默认训练是以每卡batch_size=8 在4 卡GPU 上进行训练(总batch_size=32),并且训练320 000轮,但因为笔者使用的GPU数量为1,所以将学习率调制0.000 25,变化节点范围在[480 000,640 000]。训练过程loss 变化趋势loss 可视化如图3所示。
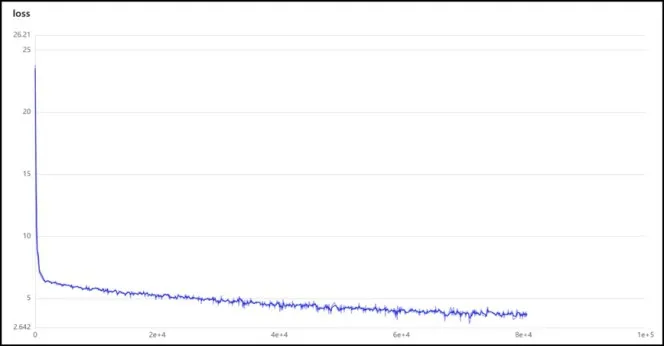
图3 loss可视化
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着需要花费更长的时间进行收敛。学习率也不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛。
3.5 模型评估
对已经训练出来的权重模型在WIDER-FACE 数据集上进行评估,ppdet将对数据集进行预处理,通过设置multi_scale=True 进行多尺度评估,待评估完成后,再生成每个数据txt 格式的测试结果。保存在txt的评估结果信息记录评估结果信息如图4所示。
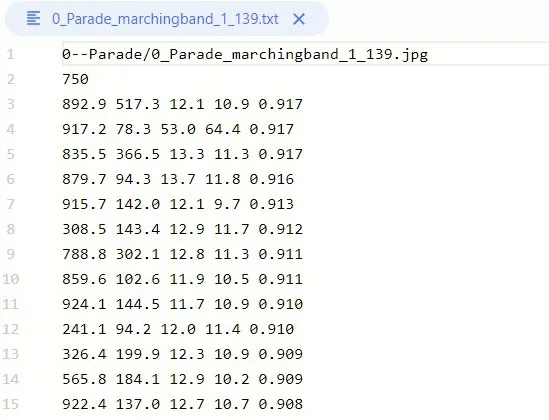
图4 记录评估结果信息
其中,第一行是文件夹文件名;第二行是图中人脸的数量;再往下是人脸信息的参数。x1,y1代表识别的人脸框的位置(检测算法一般都要画个框框把人脸圈出来);w,h即为识别的人脸框的宽度和高度。最后一项为记录识别的人脸得分,范围[0,1.0]之间。
WIDER-FACE 数据集中40%的数据为训练集(Training),10% 的数据为验证集(Validation),50%的数据为测试集(Testing)。每个集合中的数据根据人脸检测的难易程度分为“Easy”“Medium”“Hard”。最后Blaze-Face-FPN-SSH 改进模型在Easy/Medium/Hard Set 表现分别为0.907、0.883、0.793,如图5所示。
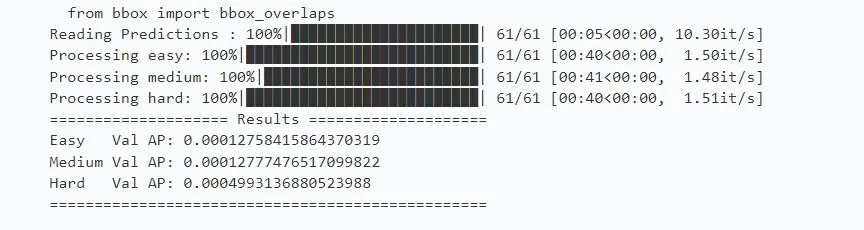
图5 分类评估结果信息
3.6 情绪识别
Fer2013 数据集由生气(angry)、厌恶(disgust)、恐惧(fear)、开心(happy)、难过(sad)、惊讶(surprise)和中性(neutral)七个类别组成。
下面以识别出第一个人脸,输入ResNet50模型中返回的结果为例:
从识别的结果来看,返回Tensor包括七个表情对应的概率值,然后lab=np.argsort(results.numpy()),取概率最大的标签作为预测输出,标签lab=0 对应SAD表情、标签lab=1 对应DISGUST 表情、标签lab=2 对应HAPPY 表情、标签lab=3 对应FEAR 表情、标签lab=4对应SUPERISE 表情、标签lab=5 对应NATUREAL 表情、标签lab=6对应ANGRY表情。最后单个人脸数据源识别效果如图6所示。

图6 单人脸表情识别结果
结合标注
通过标注代码如下:
其中label 是ResNet50 分类模型识别出来的表情,score 是PaddleDetection 识别出来的人脸准确度。最终多人脸表情识别效果如图7所示。

图7 表情识别效果展示
4 结束语
项目基于PaddleDetection 检测人脸+ResNet50 分类模型情绪识别,经过评估验证分析在fer2013 数据集上识别人脸表情的准确率在65%左右,实际情况可能有些许波动,但已经达到预期结果。因为fer_2013数据集存在错标的情况,所以正确率还有待提高,人眼的正确率就是60%~70%,所以目前的精度已经在可接受的范围内。目前的方法处于项目应用的第一阶段,由于数据集大小和GPU 计算力等因素的限制,模型的泛化性不强,网络的结构仍需要优化,还不能满足实际生活中实时检测的要求,如人脸识别、情绪识别与人物活动场景氛围识别等。后续的工作还需进一步研究与实现,如需要提高模型的泛化能力、增加ResNet50模型的精确度,对于一些模糊的人脸应该加以判断并进行其他处理,筛除过于模糊而不能判断情绪的人脸。
