图像超分辨率技术研究
2023-08-04陈萱华张静陶建平顾帅楠
陈萱华,张静,陶建平,顾帅楠
(武警海警学院情报侦察系,浙江宁波 315801)
0 引言
图像超分辨率SR(Super Resolution) 指从低分辨率的图像或图像序列中恢复出高分辨率的图像。将低分辨率的图像用LR(Low Resolution)表示,恢复出的高分辨率的图像用HR(High Resolution)表示。根据输入图像进行分类,输入为单张图像即为SISR(Single Image Super-Resolution),输入为图像序列则称作MFSR(Multi-Frame Super-Resolution)。
图像超分辨率是计算机视觉中一个很经典的问题,在过去的十几年中,在国内外都有非常广泛和深入的研究。
获得高分辨率图像的最直接方法是使用高分辨率图像传感器得到,然而这种方式的成本较高,在很多场景下无法实现。由此,使用图像超分辨率技术从低分辨率图像中重建高分辨率的图像细节十分重要。
1 问题建模
图像超分的关键在于尽可能多地恢复出图像中的高频信息,即由高分辨率图像退化为低分辨率图像中丢失的图像信息。如图1所示,高分辨率图像经过模糊、降采样、加噪等步骤,退化为低分辨率的图像,这个退化过程为图像超分技术提供了技术原理基础。很直观地,若是按照这个过程直接反推,便可重建出高分辨率图像,由此进一步发展出了图像去模糊化、图像上采样、图像去噪等不同研究分支。
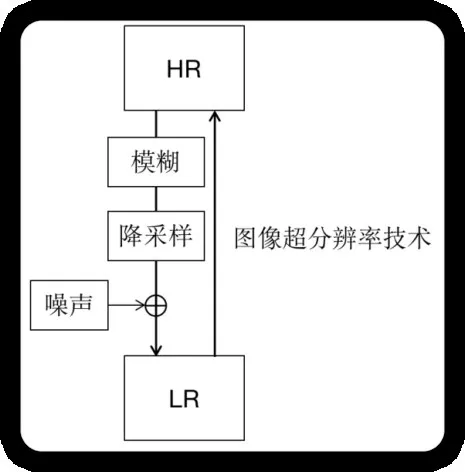
图1 高分辨率图像(LR)和低分辨率图像(LR)相互转换的过程
2 方法研究
对于图像超分辨率,存在各种各样的解决方案。传统方法中,一种常用的技术是插值,该方法易于实现,但在视觉质量和细节的保留上存在很多不足,重建的图像较为模糊。一种更复杂的方法是利用图像内部的相似性或者低分辨率图像和对应的高质量图像的数据集,通过某种方法学习二者之间的映射,而这就给了深度学习用武之地。由于深度学习模型可以很好地通过大量数据集学习这种映射,所以从2014年开始,计算机视觉领域的科学家们提出了许多开创性的深度学习模型,不断刷新图像超分辨率的表现。
2.1 传统方法
2.1.1 基于插值的方法
图像超分的传统方法中最常用的是基于插值的方法将图像放大,比如最近邻(nearest)、双线性(bilinear)、双三次(bicubic)等不同的插值方法。这种方法的本质是用像素周围相邻像素的信息来推测当前像素的像素值。但该方法无法恢复出图像中缺少的高频信息,也难以处理图像中的边缘等像素值发生巨变的地方,导致恢复出的图像整体较为模糊,物体边缘不清晰。
2.1.2 基于回归的方法
另一个常用的方法是将图像超分的过程看作一个回归问题,利用贝叶斯中的最大后验概率模型,对退化模型进行反向求解(比如计算模糊矩阵的逆矩阵、构建映射关系等)。
2.1.3 基于浅层学习的方法
2004年,Chang等人[1]使用了流形学习中的locally linear embedding(LLE) 局部线性嵌入方法,假设低维空间中的低分辨率图像内部特征之间的线性关系在高维空间中的高分辨率图像中能够保持。2008 年,Yang 等人[2]引入稀疏表示方法,将高分辨率图像和低分辨率图像分别用字典和原子进行表示,构建高-低分辨率图像集进行字典的训练,该训练可以离线进行,训练后的字典可以直接使用。2009年,Glasner 等人[3]使用示例学习方法,将图像分为多个相互重叠的图像块,进行最近邻搜索,只利用低分辨率图像自身的信息进行重构,重构在低分辨率纹理信息丰富的部分效果较好,但受限于低分辨率图像自身特性。
这些传统方法都较为简单直观,重建质量较差,或是需要提供对图像的先验认知。其中,传统方法中通过回归、浅层学习等方式计算图像内线性关系、高-低分辨率图像之间的映射关系来恢复高分辨率图像的方法的特性与深度学习的优势非常适配,为深度学习方法的引入提供了很好的切口。
2.2 深度学习方法
基于深度学习方法进行图像超分辨率的关键之一在于深度学习网络的架构,随着科学技术的发展,不同的新型网络模型被提出,将它们运用在图像超分辨率的问题中,图像超分辨率的模型和性能也日新月异。
2.2.1 SRCNN
SRCNN是Dong等人在2014年发表的文章Learning a deep convolutional network for image superresolution[4]中提出的图像超分辨率方法,是将深度学习的方法应用在图像超分辨率问题上的开山之作。
SRCNN 是Super-Resolution Convolutional Neural Network 的缩写,即超分辨率卷积神经网络。与传统方法相比,SRCNN 使用卷积神经网络提取图像特征(图像块)、学习低分辨率图像与高分辨率图像间的映射和高分辨率图像重建。这三个步骤分别经过三个卷积层来实现。
在经过卷积层之前,SRCNN需要对输入图像进行预处理,利用双三次插值方法将输入的低分辨率图像放大为与目标高分辨率图像相同的尺寸。
如图2 所示,SRCNN 的网络结构非常简单,只有三层神经网络,按照输入数据经过的顺序分别为低分辨率图像块的提取和表示层、低-高分辨率图像的特征非线性映射层和高分辨率图像重建层。三个卷积层的卷积核的大小分别为9×9,1×1 和5×5,得到的低分辨率图像、高分辨率图像特征的特征通道数分别为64和32,文章中的实验经过双三次插值处理后的输入到输出的维度变化为:256×256 →256×256×64 →256×256×32 →256×256。
SRCNN在Timofte数据集(包含91幅图像)和ImageNet数据集上进行训练,损失函数为均方误差MSE,使用峰值信噪比PSNR 作为图像超分的质量评价标准。SRCNN 的成功证明了深度学习在图像超分领域的可行性。
2.2.2 VDSR
2015年,ResNet的提出解决了深度学习中网络太深时难以训练的问题,更深层的网络拥有更大的全局感受野,大幅提高了网络的学习能力。VDSR[5]将残差网络的思想用于图像超分辨率,与SRCNN 相比,VDSR不需要将大量的图像信息从输入端经过所有网络层达到输出端,而是学习图像的残差,极大地提升了效率。
如图3所示,VDSR的网络主要学习残差,将经过插值得到的目标图像大小的原低分辨率图像与经过神经网络学习到的残差相加,得到最后的高分辨率图像。
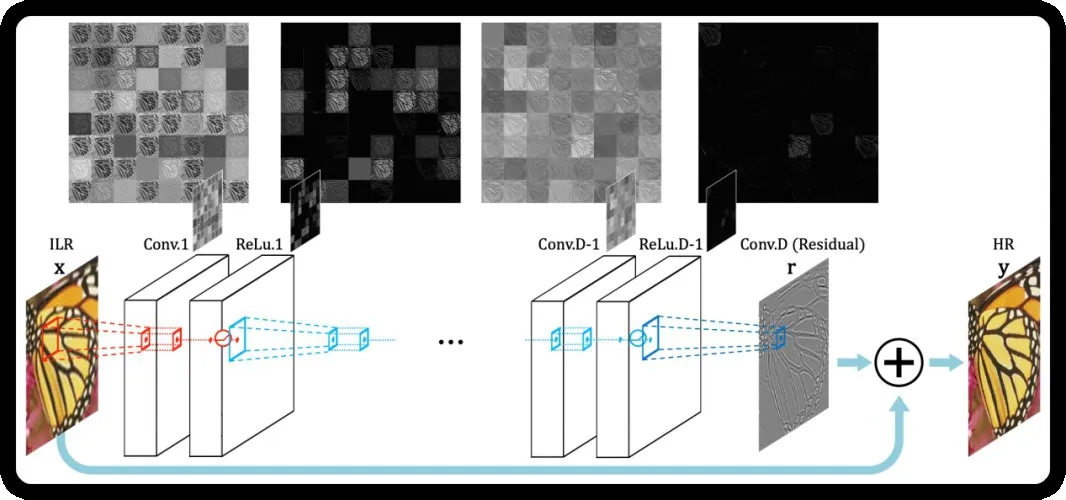
图3 VDSR的模型框架
残差的思想非常适用于图像超分辨率。低分辨率图像和高分辨率图像中其实有大部分信息是相似的,即图像中携带的低频信息,而差异明显的部分主要在于细节部分的高频信息。因此,相较于直接学习低分辨率图像到高分辨率的映射关系,让网络学习低分辨率图像与高分辨率图像内部高频信息之间的残差不但能够减少开销、增加网络的深度,更能提高模型性能。感受野是指输出图像中每个像素能够反映输入图像区域的大小,增加网络深度能够增大,使得网络能够利用更多的上下文信息,学习到更全局的映射。VDSR的网络中有20层的卷积,网络的学习和表示能力都比只有3层卷积的SRCNN有了显著的提升。同时,残差学习的图像信息较为稀疏,大部分为0或很小的值,使得学习的收敛速度快。
除了学习残差,VDSR 还提出了其他贡献。比如对图像进行补零操作,使得经过卷积层的各级特征保持和目标图像一样的大小,而不随着卷积核大小和步长的变化而变小。VDSR还将不同尺度的图像一起进行训练,使得训练得到的网络具有解决不同超分辨率的能力。在VDSR 中,图像被转化至YCbCr 色彩空间,只使用亮度通道(Y),网络的输出端合并输入端经过插值图像的CbCr 通道,得到最终的彩色图像。基于的原理在于相较于色差,人类视觉对亮度变化更为敏感。另外,VDSR 使用了自适应梯度裁剪(Adjustable Gradient Clipping)策略,将梯度限制在某一范围之内,加快了收敛速度。在VDSR 基础上,后续提出的DRRN[6]中就使用了VDSR 的调整梯度裁剪策略和DRCN[7]的递归学习策略。
以上的几种基于深度学习的图像超分辨率方法都有对图像进行预采样的部分,即在将图像输入深度神经网络之前,先使用插值方法将低分辨率图像放大。但是这样的处理会引入插值方法固有的问题,比如会使放大后的图像较为平滑和模糊,丢失了边缘等细节信息。并且,网络一直传递高分辨率图像大小的数据,增加了网络的开销。
针对这个问题,研究者们提出了对图像超分辨率采用后上采样框架,将上采样模块集成到网络末端的可学习层,形成一个端到端的模型架构。这种方法令网络能够在低分辨率大小上进行学习,最后再使用上采样方法得到目标大小的图像,节省了开支,提高了效率和性能。
3 总结
图像超分辨率是计算机视觉中的重要研究问题,运用范围十分广泛。经过较长时间的研究,图像超分辨率无论是在传统方法还是深度学习方法上,都已经形成了非常成熟的技术架构。本文按照传统方法和深度学习方法两种类型,对图像超分技术进行了探究和分析。目前,图像超分仍然需要解决大尺度、真实场景下的图像超分,以及深度学习网络轻量化的问题。
