基于Hadoop高校网络舆情监管平台研究
2023-08-04王娟琳陶宇炜高东伟封红旗
王娟琳,陶宇炜,高东伟,封红旗
(常州大学信息化建设与管理中心,江苏常州 213164)
0 引言
校园网络同样具备互联网络的匿名性、虚拟性、隐蔽性和即时互动性,一旦突发网络舆情传播快、波及面广、影响范围大等,高校校园网络信息管理部门高度关注积极应对。从2003 年起我国开始对网络舆情监管平台进行研究[1],十年来随着网络信息技术发展,高性能计算、云计算等技术在高校网络舆情监管中被应用,通过构建Hadoop 集群与MapReduce 分布处理架构,从智慧校园数据中心各个应用系统数据接口采集高校网络舆情数据,关联爬取到学生在校园内的学习生活静态、动态数据并针对这些数据进行处理、分析获取相关的高校网络舆情预警信息[2]使职能部门的教师、辅导员主动关注目标学生做好学生工作预案及时研判、疏导,降低和避免负面事件发生。
1 平台架构
高校网络信息管理部门在构建舆情监管平台时,在Linux操作系统上通常使用出现较早的开源分布式大数据计算Hadoop 平台(如常州大学高性能计算集群上构建Hadoop 平台,计算节点服务器操作系统是Redhat V6.2,共有30 多个计算节点,总存储容量50TB),该大数据平台具有稳定性、扩展性、容错性、投资少、维护成本低等特性,在此平台上可使用多种编程语言[2]、使用一般硬件配置。主要的两个核心平台架构分别是:1)HDFS 分布式文件管理体系可实现高效存储,2)MapReduce 分布式并行计算可将一组数据按照某种Map 函数映射成新的数据再将若干组映射结果进行汇总并输出,Hadoop平台架构如图1所示。
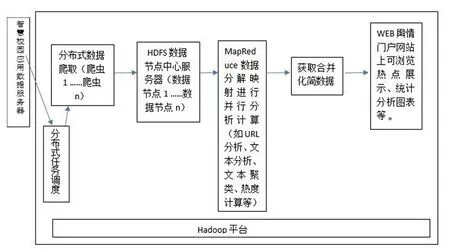
图1 平台架构示意图
1.1 HDFS分布式文件系统
HDFS 是将大文件、大批量文件进行分布式存储的文件系统,在投资成本较低的高性能计算机服务器集群上可进行文件切块、副本存储,使用统一的命名空间目录树进行文件定位,用户可使用客户端访问文件系统。它是一个主从存储模式的文件系统[3],如图2所示。有一个Namenode 主节点管理目录树、文件所对应的文件块id以及所在的从节点服务器等;而多个Datanode 数据从节点执行主节点所发出的指令来进行数据存储,主节点与从节点通信方式采用心跳信号进行。每个数据块可以将副本存放在多个datanode从节点上(通过参数可设置存放副本的数量),由此可见HDFS具有高容错性特性。
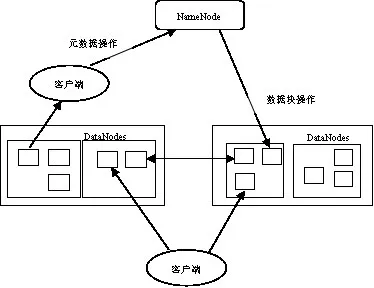
图2 HDFS结构
1.2 MapReduce并行计算
MapReduce 主要针对大数据计算(TB 级数据以上)模型如图3 所示。其主要有两个过程即Map 和Reduce,为达到高计算效率采用并行计算框架或者说是一种编程模型。计算时先将一个大的计算作业分解成多个子作业(复杂问题简单化),再将这些子作业分别处理将得出结果再合并成最后的计算分析结果。整个作业计算流程主要分为:提交作业、初始化作业和任务分配[4]。MapReduce 分布式并行计算框架其功能是实现高校网络舆情数据的并行爬取及分析计算,使高校开展网络舆情的数据收集和分析工作快速而高效。
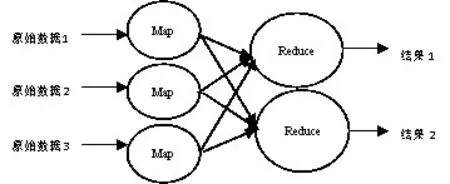
图3 MapReduce模型
2 学习模式算法
采用K-Means算法是基于划分的聚类算法,其核心思想根据用户所设的类别数量,随机在文本集里选择K个文本设置成最初的类簇中心,计算剩余的文本集里的各个文本到类簇中心的距离,把文本分别划分到就近的类簇中,当全部划分完毕后重新再计算每个类簇的中心,再次计算剩余每个文本到这些新类簇中心的距离,将文本重新划分到当前最接近的类簇中去;不断重复以上过程,当完成设置的迭代次数或簇不发生变化了停止算法[5]。K-Means算法的优点是复杂度较低并且易实现,任意范围内都可进行聚类。但比较难选择到最初始的全局最优化的聚类中心,算法还容易受到噪声和例外文本的影响。
3 构建Hadoop实验环境
3.1 软硬件配置
基于Hadoop 架构的高校舆情监管平台,管理员可自由地开发运行基于大数据的应用程序[6],兼容性好,以常大高性能计算集群linux 操作系统为例,在4个计算节点服务器上进行安装部署。将其中一台计算节点服务器作为Namenode 主节点命名为Masternode,作为名字空间存储服务和下发指令任务;另外3台计算节点服务器作为DataNode 从节点分别命名为Branch1、Branch2、Branch3 负责存储具体数据。为每台计算机服务器配置IP 地址(vim/etc/hosts 文件中配置),再进行测试主节点和所有从节点网络通信状态;设置主节点和从节点之间实现SSH 免密登录。(免密登录需关闭防火墙再配置远程连接SSH服务)。配置的软件、硬件如下表1、表2所示。

表1 集群软件信息表
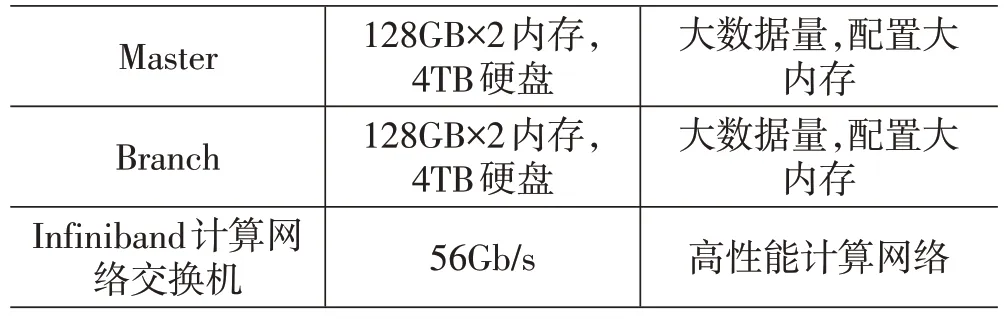
表2 集群硬件信息表
3.2 数据来源及导入
由于舆情数据大部分都是结构化数据,使用Sqoop工具从智慧校园数据中心MySQL等结构化数据库中将数据从接口导入Hadoop 平台。MySQL 数据需导入HDFS 中,由DataNode 负责数据块元数据的存储根据NameNode 的指令进行检索读取数据。每个DataNode 会定期向NameNode 发送“心跳”信息判断DataNode的运行情况。
3.3 数据清洗
从校园网上爬取在校学生信息数据如:学号、姓名、班级、所学专业、爱好等静态特征数据和动态特征数据如:上课出勤率、使用校园一卡通图书馆借阅率、食堂消费率、考核成绩、使用校园网时长等。
结合高校的工作内容,Hadoop平台获取的关键信息还有:
1)学习。主要包括自主学习、授课、网上教学等模式信息。
2)考试。涉及考试纪律、考试成绩、成绩服务器、考核方式等信息。
3)上课。涉及教师授课方法、上课教室软硬件条件、兴趣爱好等信息。
4)宿舍。同学间聊天的话题、宿舍软硬件条件、后管服务满意度等信息。
5)爱情。爱情观、失恋等信息。
6)食堂。涉及饭菜种类、口味、价格、卫生、环境、服务等信息。
7)图书馆。涉及软硬件条件、电子借阅、占位、馆员服务等信息。
8)其他。在校体育活动场地、运动器材、校园文化环境、教学管理服务等信息。
将“高校”“高校大学生”“高等院校”等关键词与上述信息进行组合,在Hadoop 平台中进行爬取。再对这些数据进行清洗,去除不符合用户标准的数据。网页信息数据含有文本、图像、除了我们所需的正文信息,还包含了多种辅助信息如:商家广告、导航、弹窗等。在进行数据清洗时,也要对网页内容进行清洗,消除一些不需要的内容干扰。获得有价值数据后再将两个时段数据合并进行曼哈顿距离计算(如本时段的数据和前一个时段的数据合并),得到某个特征数据离中心距离的偏离大小及某个数据的异常情况。
通过搭建的实验平台可以提取在校学生行为的静态、动态信息数据中与舆情信息关联的敏感关键字,依据一些有负面风险影响信号的关键字给相关学生画像,再通过这些学生在校内的各种上网行为轨迹(如QQ、微信、网页浏览、短信等)达到对监测的舆情进行追溯。积极发挥班主任、辅导员老师的主观能动性做好预警和研判工作,从而降低舆情负面风险值达到高校网络舆情监测的目的。
3.4 聚类分析
清洗干净的学生静态、动态特征数据通过Map-Reduce进行并行计算,在主成分分析中用协方差矩阵的特征值而在求协方差矩阵时,用的就是矩阵的加减乘除。针对主成分进行分析后将结果合并在一起提取关键字,通过离中心距离的划分聚类算法,再从多角度出发对不同的数据将其结果聚合在一起,从中获取出离中心距离偏大的一系列学生数据,针对提取的异常数据实时进行监测和研判。
4 实验平台性能测试与结论
Hadoop 平台获取信息速度与快速分析信息是一项重要的性能指标。实验中针对单机模式与Hadoop模式进行爬取信息的速度和热点计算所需时间、聚类分析所需时间的测试。通过实验对比依据平台运行时间递增单机模式与Hadoop模式运行结果是:在平台运行较短时间内,单机模式与Hadoop 模式没有明显差别,这是因Hadoop 模式在开始集群运行时各种系统存在比较大的开销。运行时间逐渐增加时,信息爬取、数据清洗、聚类分析的数据量也在递增,Hadoop模式爬取信息速度明显较单机模式块、热点计算时间与聚类分析时间较单机模式信息计算分析速度明显加快。由此可见,Hadoop模式在并行计算分析方面有着明显的优势,能快速有效提升高校网络舆情的数据采集与分析效率。
通过基于Hadoop 高校网络舆情监管平台研究,实施分析爬取到学生在校园内的各种学习生活静态、动态数据,提取到偏离中心的负面风险信号关键字并关注这些学生在校内学习生活行为轨迹相关数据,由班主任、辅导员针对这些学生给予一对一的关注并解决问题。数字化技术手段助力高校学生管理工作科学、高效,同时促进建设高校智慧平安校园。由此可见,构建高校Hadoop 网络舆情监管平台具有广泛的实际应用价值。
