基于深度学习的手绘图形识别的研究*
2023-08-02孟志刚廖帅元
孟志刚 廖帅元
(长沙学院计算机工程与应用数学学院 长沙 410003)
1 引言
Quick Draw 是一个由谷歌提出的教育体验项目,主要是为了更好地帮助用户了解深度学习,比如它能实现什么效果,如何在现实生活当中应用。Quick Draw 中有全球十亿多个手绘的涂鸦组成的涂鸦训练集,且Quick Draw 采用的循环神经网络(RNN)是通过训练集能自主学习具有连续笔画序列特征的工具,在手绘图形的时候,RNN 可在停顿的地方提出更多可实行的方法,通过一系列一维卷积操作后应用在LSTM层进行涂鸦分类。
因为谷歌的数据集庞大,处理数据的时间较长,且由于Google 采用的sketch-rnn 是图形的方式训练样本,它较于其他常用的机器学习算法复杂些,所以为了使用户更加了解机器学习、深度学习以及了解人与机器学习系统的交互。本文采用图像识别的方法:随机森林、K 近邻、支持向量机、逻辑回归和卷积神经网络算法研究手绘图形识别,训练集选取QuickDraw中的10种不同类的涂鸦数据,采用图像分类的方法得到28×28 的灰度位图,并将大量的数据存储成.npy格式,方便用户使用np.load()方法加载数据,每一类别训练集6000 张图,测试集1000张,主要比较算法间的准确率及运行时间。
2 手绘图形特征提取与分类
手绘图形的特征提取及分类主要采用图像分类的方法。首先,提取图像特征采用梯度方向直方图(HOG)方法,为了调整图像的对比度,降低图像局部阴影和照明变化的影响,以及减少噪音的干扰,使用Gamma 校正使输入的灰度化图像的颜色标准化。其次,计算图像中每一个像素的梯度(包括角度和倾斜方向),目的在于图像轮廓信息的计算,从而进一步降低图像光照的影响。将图像切割成小cells,计算切割后的每一个cell 的梯度直方图(计算不同梯度的个数),即每个cell 的特征都要生成,每几个cell 组成一个block,该block 的HOG 特征主要是有block 内所有cell 特征串联起来得到的。若需要得到检测目标(手绘图形)的HOG 特征,则需要将检测目标中所有block 的HOG 特征串联起来,最终得到的特征向量可供图像分类使用。不管是手绘图形识别还是图像的识别,都需要经过HOG 特征提取后再采用常见的分类方法分类。该方法在人工智能各分支领域中已普遍使用,常用的人工智能学习模型主要有逻辑回归、随机森林、支持向量机(SVM)、K 最近邻分类等。
2.1 随机森林(RF)
随机森林分类算法是一种便于使用且更为灵活的机器学习算法,在没有调整参数到最优的情况下,也能得到比较好的分类结果。随机森林主要是从原始训练样本集中有放回的重复随机抽取N 个样本,形成新训练样本集合,然后根据新样本集生成N个分类树组成,新数据的分类结果主要是由分类树投票形成的分数决定。随机森林分类法是在决策树分类法上进一步改进得到的,它将多个决策树联合起来,创建的每一棵树都需要依赖独立抽取后的样本,所以森林中的每一棵树都有类似的分布,每棵树之间的联系和分类能力都决定了每棵树的分类误差。通过随机的方法分裂每一个节点来选择主要特征,比较不同状况下产生的误差。一个测试样本因为单颗树的分类能力可能出现较大误差,所以在随机产生大量的决策树后可通过所有决策树分类结果后统计选择最优的分类结果。
采样、完全分裂是在在建立每棵决策树的过程中需要注意的地方。随机森林(random forest)采样方法有行采样和列采样。行采样主要是为了避免使用有放回的方式进行样本采样(即样本集合中有重复的样本),从而出现过度拟合(over-fitting)的情况。行采样后进行列采样,从M 个feature 中,选择m 个(m <<M)。使用完全分裂的方法对采样后的数据处理从而建立每棵决策树,通过这种方式得到的决策数的某一个叶子节点要么无法接着分裂出子节点,要么所有分裂结果样本都指向同一个分类。为了不出现过度拟合的情况,决策树需要采用剪枝操作。由于随机森林是通过行、列采样方法得到样本的,确保了样本的随机性,所以即使不用剪枝方法,也不会出现过度拟合的情况。
2.2 支持向量机(SVM)
支持向量机(SVM)主要是进行二分类操作的方法,因为本文采用的是多分类问题,所以需要修改SVM 分类结果改成多类别问题的分类。支持向量机主要分成两大类:线性、非线性。SVM 为了得到较好的分类结果,即使在样本数量少的情况下,一般选择最小风险的结构来提高学习泛化能力。
SVM 多分类:采用一对一分类法(one-versus-one)。SVM 多分类主要是在任意两类样本之间再设计一个SVM,即测试样本有m 个类别,需要设计m(m-1)/2 个SVM。对测试样本进行分类时,分类测试结果为最后得票最多的类别。
具体原理:
1)将在n 维空间中找到一个分类超平面上的点进行分类;
2)分类预测的准确度可以由一个点与超平面的距离远近表示。支持向量机(SVM)主要用于这个距离值的最大化。支持向量(Support Verctor)表示的是虚线上的点;
3)因为样例的线性不可分,常常在高维空间中折射样例特征;
4)线性不可分映射到高维空间,可能会导致较高的维度,导致计算复杂。为了避免直接在高维空间中的复杂计算,使用核函数从低维到高维的转换的特征,事先在低维上进行计算,而将实质上的分类效果表示在高维上;
5)数据噪音使用松弛变量处理。
2.3 K最近邻分类(KNN)
K 最近邻分类(k-NearestNeighbor)是分类算法当中最容易运用以及理解的算法。KNN 中表示有K 个邻居,邻居在K 最近邻中表示样本的分类类别,每个样本可由最接近的K 个邻居一起表示。KNN 属于懒惰学习(lazy learning),是因为它的输入是基于实例的学习(instance-based learning)。KNN 相比于其他分类没有训练阶段,数据集最开始就有了分类和特征值,待收到测试样本后直接进行分类处理,所以KNN 学习过程并不是显式的。KNN 测量不同特征值之间的距离主要是采用欧氏距离公式,计算向量xA与xB之间的距离:
将得到的不同特征值间的距离依次进行排序存入特征空间,再判断K 个最邻近的样本在特征空间中大多数属于哪一类别,则将样本归属于哪一类。KNN 方法在分类决策上根据最邻近的一个或多个样本的类别决定待分类样本所属类别,且KNN中邻居选择都是已正确分类的对象。
K 近邻模型是一个没有参数训练的过程,是根据测试样本在训练数据的分布上直接作出分类决策。因此该方法不需要建模与训练就能实现,简单、易于理解。它适合对多分类问题进行分类,同样也适用于稀有事件分类。其中K 最近邻算法(KNN)比支持向量机分类算法(SVM)分类效果表现要好,但由于KNN 属于惰性算法,存在一定的缺点,即对测试样本分类时需要非常高的计算复杂度和内存消耗。
2.4 逻辑回归(LR)
逻辑回归分类法:建立分类边界线的回归公式,主要基于现有数据所得。因为分类算法需要一个能够进行分类的函数,所以逻辑回归需要选择一个函数进行分类。本文在单位阶跃函数和sigmoid函数之间,选择了更易理解和处理的sigmoid 函数。当sigmoid值>0.5为一类,<0.5为一类,0.5为分界线。
在机器学习之线性回归中,我们需要得到一个映射函数hΘ(X)去贴近样本点可使用梯度下降的方法。为了得到一个映射函数f:X->y,我们可以通过逻辑回归算法,其中X 为特征向量,X ={x0,x1,x2,…,xn},y 为预测结果。在逻辑回归算法中,样本标记为某一类型的概率由概率函数hΘ(X)表示,标签y 表示为一个离散值。我们可以将逻辑回归二分类法扩展为一对多(one vs rest)型:1)将类型1 看作正样本,其他类型全部看作负样本,然后将得到的样本标记类型为该类型的概率记为p1;2)将另一类型2 看作正样本,其他类型全部看作负样本,同理得到该类型的概率记为p2;3)以此循环,可得到未知样本的标记类型分别为类型n 时的概率记为pn,最后取pn 中概率最大的对应的样本标记类型作为未知样本类型。
3 卷积神经网络-LeNet模型
3.1 卷积神经网络
卷积:因为卷积神经网络(CNN)下的卷积核是未知的,所以人们训练一个神经网络,旨在于要训练得出卷积核。由于人们学单层感知器的时候需要用到参数W,那么这些未知的卷积核可看作是那些参数W,因此人们可以把神经网络的训练参数W用这些待学习的卷积核替代。
池化:图片下采样表示池化的过程。卷积神经网络(CNN)的每一层搭建是先通过卷积得出卷积核后再进行图像下采样为之后特征图做准备。CNN的图像下采样方法有:归一化采样、均值采样、随即采样、均方采样、重叠采样、形变约束采样、最大值采样。本文所采用的池化方法是更符合当前实验的最大值采样(Max pooling)。
特征图:特征图片主要指CNN 中的每张图片。CNN 中的每个卷积层的卷积核数目以及卷积核大小都需要手动的选取恰当的。每个卷积核与图片进行卷积可得每一张特征图。比如在LeNet-5经典结构中,在第一层网络特征输入时,可以将输入的图像看成一张特征图,作为初始的输入。因为经典结构中第一层的卷积核选择了6 个,所以通过卷积可以得到6 张特征图,那么这6 张特征图将会变成下一层网络的输入。
在CNN 中,我们要训练的卷积核并不是只有一个,卷积核个数越多,提取的特征越多,因为提取特征需要使用这些卷积核。理论上来说卷积核个数越多准确度也会更准,然而卷积核量过高,我们要训练的参数的个数也越高。卷积核数目具体选择多少个合适,还有待进一步的研究。
3.2 CNN的经典结构LeNet-5模型
LeNet-5模型运用在手绘图识别上的具体原理如下:
1)用十分类的28×28 的手绘图形数据作为输入;
2)搭建第一层网络:(1)输入大小为28*28 的手绘图(特征图),设置每个训练数据(batch_size)有1个特征图,总共5个训练数据,设置卷积核个数为20(nkerns[0]),因此每个训练样本经过本层训练将生成20 个特征图。(2)经过卷积操作(28-5+1,28-5+1),图片大小变为24*24。(3)经过池化操作(24/2,24/2),图片大小变为12*12,最后生成的本层网络为(batch_size,nkerns[0],12,12)。
3)构建第二层网络:(1)输入batch_size个训练图片,经过第一层的卷积后,每个训练图片有nkernes[0]个特征图,每个特征图大小为12*12。(2)经过卷积后(12-5+1,12-5+1),图片大小变为8*8。(3)经过池化后(8/2,8/2),图片大小变为4*4,最后生成的本层网络为(batch_size,nkerns[1],4,4)。
4)全链接:输入一个二维的矩阵,第一维表示样本,第二维是经过上述步骤卷积采样后所得到的每个样本的神经元(每一个样本的特征),最后把神经元个数由800个压缩映射为500个。
5)逻辑回归层:把500个神经元压缩映射成10个神经元,分别对应成手绘图形的10 分类。整个网络结构如图1所示。
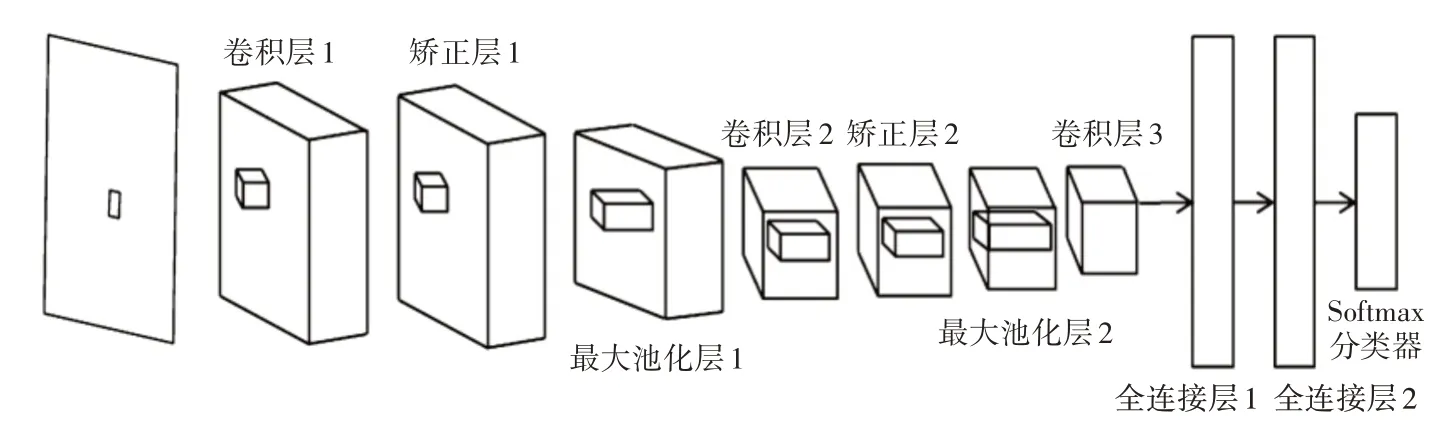
图1 LeNet-5结构网络示意图
4 实验结果与分析
从QuickDraw中选取10类手绘图形,其中每类包含7000张灰度手绘图,图像大小为28×28。其中6000 张图作为训练集,1000 张图作为测试集。其手绘图形集的部分图像如图2 所示。比较不同的算法,实验评价指标采用手写绘图识别正确率。

图2 手绘图形库示例
实验结果如表1所示,对数据进行HOG特征提取后采用随机森林分类法的准确率(82.9%)低于逻辑回归分类算法(85.4%),但随机森林算法运行时间高于逻辑回归;支持向量机分类法(86.9%)低于K 近邻分类(88.0%),虽然KNN 在HOG 提特征后是分类算法中准确率最高的,但是运行速度却是最慢的,由于KNN 非常高的计算复杂度和内存消耗致使运行时间加长。当传统的图像处理方法HOG-KNN 和经典深度卷积神经网络模型CNN-LeNet相比,LeNet模型正确率明显较高,可达93.7%。

表1 算法间的对比结果
5 结语
近年来,图像领域的研究已经占据主流地位,手写绘图识别工作仍是一个艰巨的任务,更多相关领域的研究者对手写绘图识别更加关注。随着深度学习的兴起,各式各样的经典深度学习模型随之出现,但并不一定所有的算法都能适用于手写绘图识别。本文的研究重点在于通过经典的机器学习算法和深度学习算法进行比较,研究手写绘图识别准确率的高低。与现有的主流方法相比,本文提出的LeNet-5模型获得了较高的识别正确率。
