基于单类支持向量机与KNN 的两阶段不平衡数据分类*
2023-08-02刘阳江峰
刘 阳 江 峰
(青岛科技大学信息科学与技术学院 青岛 266061)
1 引言
在实际的分类任务中存在大量的不平衡数据。所谓不平衡数据就是存在类别不平衡(class-imbalance)问题的数据集,即数据集中某一类的样本数量要远远多于或少于其它类样本数量。通常将数量占多数的类称为多数类,数量占少数的类称为少数类。在传统的机器学习分类算法中,分类器通常会尽量减少分类新样本时的整体错误率,但是,这种做法仅仅在不同类别的样本被分类错误的代价完全相等时才有效[1]。然而,在实际应用中少数类所包含的信息往往更有价值,因此,少数类样本被预测错误的代价往往更高。
对于以整体分类准确率最大化为目标而设计的传统分类算法而言,这些算法在不平衡数据集上进行训练时,可能会对数量上占优势的多数类样本存在明显的偏好,从而忽略了对少数类样本的学习。不仅不同类别样本之间的数量差距会给不平衡数据集上的机器学习带来困难,少数类与多数类样本存在类别分布重合(overlapping),或者是数据集中存在噪声等异常样本时,同样会严重影响所训练的分类器的性能。此外,数据集中少数类样本的稀疏性(sparsity)也是一个需要引起注意的问题[2],当某个数据集中的少数类样本分布在多个簇中,该数据集将会具有更高的分类难度。
近年来,针对不平衡数据分类的研究引起了广泛关注。众多研究者提出了不同的不平衡数据分类方法。这些方法大体上可以分为三大类:1)数据预处理层面的方法;2)特征层面的方法;3)分类算法层面的方法。目前,在分类算法层面,典型的方法有代价敏感学习法、集成学习法、单类学习法等。与代价敏感学习和集成学习不同,单类学习是一种特殊的分类算法,其所使用的训练样本只包括某一种类别的信息,它根据所获得的目标数据估计其边界,从而做出正确的分类[3]。OC-SVM 算法是一种典型的单类学习方法,其目标是在特征空间中求解一个最优超平面,实现目标数据与坐标原点的最大分离。OC-SVM 算法只需要一类数据样本作为训练集,可以避免对少数类学习不足的问题,有效减少时间开销,同时具有训练、预测速度快和分类错误率低等优点,适用于少数类样本非常少或类别不平衡程度很高的极端情况。因此,OC-SVM 算法正逐渐成为不平衡分类领域的研究热点。
现有的OC-SVM 算法在处理不平衡数据时通常只是将所有样本划分成多数类样本与少数类样本,实际上,除了多数类样本与少数类样本之外,可能还存在一些样本属于边界样本或离群样本。对于边界样本和离群样本,利用OC-SVM算法所构建的多数类检测器与少数类检测器在对边界样本和离群样本的预测上存在着分歧。然而,现有的OC-SVM 算法却直接忽视了边界样本与离群样本的存在,当多数类检测器与少数类检测器在预测某个样本上存在分歧时,只是简单地将该样本归为多数类(或少数类)。因此,OC-SVM 算法在对边界样本和离群样本进行分类时不可避免地会出现预测偏差,从而影响到不平衡数据上的整体分类性能。
针对现有的OC-SVM算法所存在的问题,本文将提出一种基于OC-SVM 与KNN 的两阶段分类算法TSC-OSK。TSC-OSK 算法通过采用OC-SVM 算法与KNN 算法进行两个阶段的分类来解决传统OC-SVM 算法不能有效处理边界样本与离群样本的问题,避免了边界样本与离群样本对OC-SVM算法性能的影响,并且继承了OC-SVM算法在处理不平衡数据上的良好性能。
2 TSC-OSK算法的设计与实现
2.1 OC-SVM算法
OC-SVM(One-Class Support Vector Machine)算法在文献[4]中提出,是基于支持边界的单类学习算法。OC-SVM 算法的原理是寻找一个能大体上将所有训练集中的样本点与坐标原点在特征空间分离开的超平面,并且最大化分离超平面到坐标原点的距离。OC-SVM 的决策函数与支持向量机类似,为
其中,ω表示垂直于超平面的法向量,ρ代表截距[5],通过求解以下二次规划问题获得:
需要特别指出的是,这里的v∈(0,1)的作用是控制支持向量在训练样本中所占的比重[3]。ξi则是为了使该算法具有鲁棒性而引入的松弛变量。再引入拉格朗日乘子α与核函数k 将上述二次规划问题转化为求解如下对偶问题:
将OC-SVM算法应用于不平衡数据的分类时,如果用不平衡数据集中的多数类样本作为训练集求解得到相应的决策函数,那么在对待测样本进行分类时,将待测样本数据代入该决策函数,若函数值等于+1,OC-SVM 算法就将该样本分类为多数类;若函数值等于-1,OC-SVM 算法就将该样本分类为少数类。与之相对,如果用少数类样本作为训练集求解得到相应的决策函数,那么在对待测样本进行分类时,将待测样本数据代入该决策函数,若函数值等于+1,OC-SVM 算法就将该样本分类为少数类;若函数值等于-1,OC-SVM 算法就将该样本分类为多数类。
OC-SVM 算法只需要一类数据样本作为训练集,可以避免对少数类学习不足的问题,有效减少时间开销。同时OC-SVM算法具有训练、决策速度快、分类错误率低等优点。但在实际应用时,数据集不同类别之间可能存在类别分布重合,OC-SVM算法仅学习一类数据样本信息,无法对处于类别分布重合区域的边界样本做出正确的分类。同时,不平衡数据集中可能会存在离群点或噪声。OC-SVM 算法易受噪音的影响,其鲁棒性较差[6],并且OC-SVM算法对训练集中的离群点非常敏感,离群点会降低OC-SVM算法的分类性能[7]。
2.2 TSC-OSK算法
针对OC-SVM 算法在处理不平衡数据上的不足,本文提出一种基于OC-SVM 和KNN 算法的两阶段分类算法TSC-OSK,TSC-OSK 算法的主要执行步骤如下:
TSC-OSK算法
输入:不平衡的训练集IT,测试集Test
输出:预测结果
1.将不平衡训练集IT划分为多数类样本子集S1与少数类样本子集上S2;
2.在多数类样本子集S1上利用OC-SVM 算法构建一个多数类检测器ND1;
3.在少数类样本子集S2上利用OC-SVM 算法构建一个少数类检测器ND2;
4.对Test中的每个待测样本t,反复执行下列语句:
4.1 利用多数类检测器ND1对样本t进行分类,并令r1表示ND1对样本t的预测结果;
4.2 利用少数类检测器ND2对样本t进行分类,并令r2表示ND2对样本t的预测结果;
4.3 将预测结果r1与r2组合在一起,并根据不同的组合,分别进行如下处理:
(1)如果r1= 1 且r2=-1,则令prediction(t)=-1(即将样本t预测为多数类);
(2)如果r1=-1 且r2=1,则令prediction(t)= 1(即将样本t预测为少数类);
(3)如果r1=-1 且r2=-1,则令O=O∪{t}(即将样本t看作是一个离群样本,并添加到离群样本集O中);
(4)如果r1=1 且r2=1,则令B=B∪{t}(即将样本t 看作是一个边界样本,并添加到边界样本集B中)。
5.对于O中的每个离群样本x,在训练集IT上构建一个KNN 分类器,利用该分类器对x进行精炼分类,并将该分类结果赋值给prediction(x);
6.对于B中的每个边界样本y,在训练集IT上构建一个KNN 分类器,利用该分类器对y进行精炼分类,并将该分类结果赋值给prediction(y);
7.返回Test中每个样本t的预测结果prediction(t);
在TSC-OSK 算法的主要步骤中,第1 步到第3步为第1 阶段的分类器的构建。首先将训练集IT划分为多数类样本子集和少数类样本子集,并采用OC-SVM 算法分别在多数类样本子集和少数类样本子集上进行拟合,从而构建出“多数类检测器”与“少数类检测器”。具体定义如下:
定义1(多数类检测器与少数类检测器)。给定一个不平衡数据集IT,令S1⊂IT和S2⊂IT分别表示IT 中的多数类样本子集和少数类样本子集,其中,S1∩S2=∅,S1∪S2=IT。我们将OC-SVM 算法在子集S1上训练得到的分类器ND1称为多数类检测器,并且将OC-SVM 算法在子集S2上训练得到的分类器ND2称为少数类检测器。
TSC-OSK 算法的主要步骤中的第4 步为TSC-OSK 算法的第1 阶段分类。利用前3 步训练出的多数类检测器和少数类检测器,分别对测试样本进行第1 阶段的分类。对于一个待测样本t,分别使用多数类检测器和少数类检测器来对其进行检测。将多数类检测器与少数类检测器对t的分类结果组合在一起,可以形成表1中的四种组合。
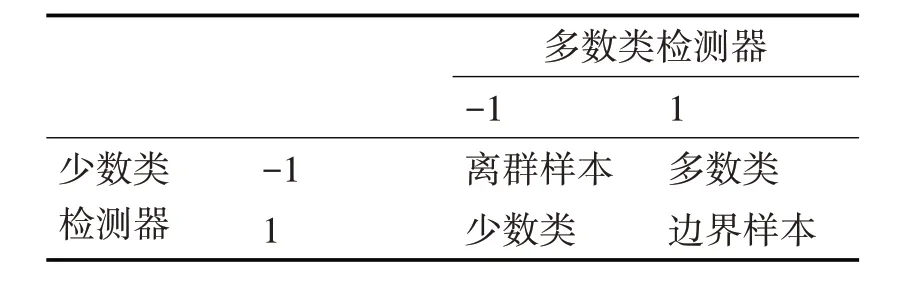
表1 多数类检测器与少数类检测器对样本t分类结果的组合
我们可以把表1中的四种组合分成两大类:
1)多数类检测器与少数类检测器对样本t的预测结果不存在分歧,我们可以直接给出样本t 最终的分类结果,即在第一阶段就可以完成对样本t 的预测。具体而言,如果多数类检测器将t 预测为1并且少数类检测器将t 预测为-1 时(直观地说,多数类检测器认为t是一个多数类样本并且少数类检测器认为t 不是一个少数类样本),则t 最终被归为多数类;如果多数类检测器将t 预测为-1 并且少数类检测器将t预测为1时,则t最终被归为少数类。
2)多数类检测器与少数类检测器对样本t的预测结果存在分歧,需要对t 进行第二阶段的分类。具体而言,如果多数类检测器和少数类检测器都将t 预测为-1 时,则t 被认为是一个离群样本;如果多数类检测器和少数类检测器都将t 预测为1 时,则t被认为是一个边界样本。
定义2(离群样本与边界样本)。给定一个不平衡数据集IT,令ND1和ND2分别表示OC-SVM 算法在IT 上所构建的多数类检测器与少数类检测器。对于任意一个待测样本t,如果ND1和ND2都将t预测为-1时(即ND1认为t不是一个多数类样本并且ND2认为t 不是一个少数类样本),则我们称t 是一个离群样本;如果ND1和ND2都将t 预测为1 时(即ND1认为t 是一个多数类样本并且ND2认为t 是一个少数类样本),则我们称t是一个边界样本。
从定义2 可以看出,离群样本是被多数类检测器和少数类检测器都排斥在外的样本,而边界样本则是被多数类检测器和少数类检测器都接纳的样本。离群样本通常是偏离于大多数样本的一小部分样本,而边界样本则往往分布在多数类检测器和少数类检测器决策边界的重叠区域,在特征空间中呈现线性不可分的状态。离群样本的出现可能是因为分类器出现了过拟合,生成的决策边界丧失了一定的鲁棒性,也可能是因为数据本身存在异常(即噪声)。异常数据的影响在不平衡学习中非常显著,在不平衡数据集上,大多分类器都是噪声敏感的[8]。另外,边界样本的出现可能是因为训练集中存在类别分布重合,导致生成的少数类检测器和多数类检测器的决策边界发生了重合,而待测样本又分布在决策边界重合的区域。已有的研究工作表明,分类器划分错误往往集中在数据的边界区域[9]。对类别分布重合问题的处理方法目前主要有两个策略,分别是合并策略和精炼策略[10]。合并策略是将重叠的类别合并为一个新类别,并忽略原来类别的边界之间的差别。精炼策略则是对重叠的类别进行单独处理,从而对重叠类别的边界进行精炼[11]。
TSC-OSK 算法的主要步骤中的第5 步和第6步为TSC-OSK 算法的第2 阶段分类。由于数据集整体上多数类样本和少数类样本的数量不平衡,因此第一阶段分类形成的边界样本和离群样本也可能存在类别不平衡问题。在少数类样本绝对数量过少的情况下,传统的分类算法可能难以学习形成有效的分类边界。已有的研究工作[12]表明,KNN算法虽然非常简单,但在面对类别分布重合与噪声数据时可能比其他各种复杂的分类器更加鲁棒,随着类别分布重合程度的增高,k值更小的KNN 分类器其效果相比k 值较大的KNN 分类器表现更好。因此,本文采用KNN 算法进行TSC-OSK 算法的第二个阶段的分类,即利用KNN 算法来对第一个阶段所产生的边界样本和离群样本进行精炼分类。而精炼分类的结果就作为TSC-OSK 算法对边界样本和离群样本最终的分类结果。
3 实验
3.1 实验设置
为了验证本文提出的两阶段分类算法TSCOSK在不平衡数据集上的分类性能,我们选用Kaggle 数据库中的Personal Loan 数据集,UCI数据库中的Page Blocks 数据集[13],KEEL 数据库中的abalone19、yeast3、segment0、vowel0 等数据集[14]进行实验。实验数据集的具体信息见表2。其中IR 为多数类与少数类样本数量的比值,反映了数据集的不平衡程度。

表2 数据集主要特征
为保证实验的客观有效,我们采用10 折交叉验证法来构建训练集、测试集。对于每个数据集:将数据集划分成10 个大小相似的互斥子集,轮流将其中1 个子集作为测试集,余下9 个子集的并集作为训练集,从而获得10 组训练集和测试集;用这10 组训练集和测试集进行10 次实验,取这10 次结果的平均值作为该数据集上的实验结果。
为了能更客观地反映TSC-OSK 算法的性能,我们将TSC-OSK 算法与以下方法进行对比:1)KNN 算法;2)OC-SVM 拟合多数类;3)OC-SVM 拟合少数类;4)Borderline-SMOTE+KNN;5)EasyEnsemble+SVM。其中,OC-SVM 拟合多数类与OC-SVM 拟合少数类表示采用OC-SVM 算法分别在训练集中的多数类样本子集上和少数类样本子集上进行拟合,从而构建出两个分类器对测试集进行预测;Borderline-SMOTE+KNN 表示先用Borderline-SMOTE 算法对训练集进行平衡化处理,在平衡化的训练集上使用KNN 算法构建分类器对测试集进行预测;EasyEnsemble+SVM 表示用EasyEnsemble算法将训练集中的多数类样本分为多个组,分别与少数类样本组成多个平衡数据集,进而在这些平衡数据集上训练基分类器为SVM 算法的集成分类器对测试集进行预测。实验中,KNN 算法,Borderline-SMOTE+KNN,TSC-OSK 算法所用到的KNN算法的k值均设置为3。
3.2 评价指标
为了准确评估分类器在不平衡数据集上的分类性能,学者们提出了一系列基于如表3 所示的混淆矩阵的评价指标,例如,KS 曲线、G-Mean、ROC曲线等。

表3 混淆矩阵
本文选择G-Mean[15]和AUC[16]作为衡量分类器在不平衡数据集上的整体分类性能的指标。G-Mean综合考虑了分类器对多数类样本和少数类样本的分类准确率。ROC 曲线是一个由“真正率(True Positive Rate,TPR)-伪正率(False Positive Rate,FPR)”所刻画的二维图[17],能够比较全面地描述分类器的性能,是目前评价不平衡数据集分类器性能的常用方法之一,AUC 为ROC 曲线下面积。G-Mean 和AUC 的值越高,说明分类器的分类性能越强。其中:
同时,计算实验结果中少数类样本的F1-Measure 值,用来衡量分类器对不平衡数据集中的少数类样本的分类性能。F1-Measure 是查准率(Precision)和查全率(Recall)的调和平均值,F1-Measure值越高,说明分类器对少数类样本的分类能力越强。其中:
3.3 实验结果
各个方法在各个数据集上的实验结果如表4~表6。
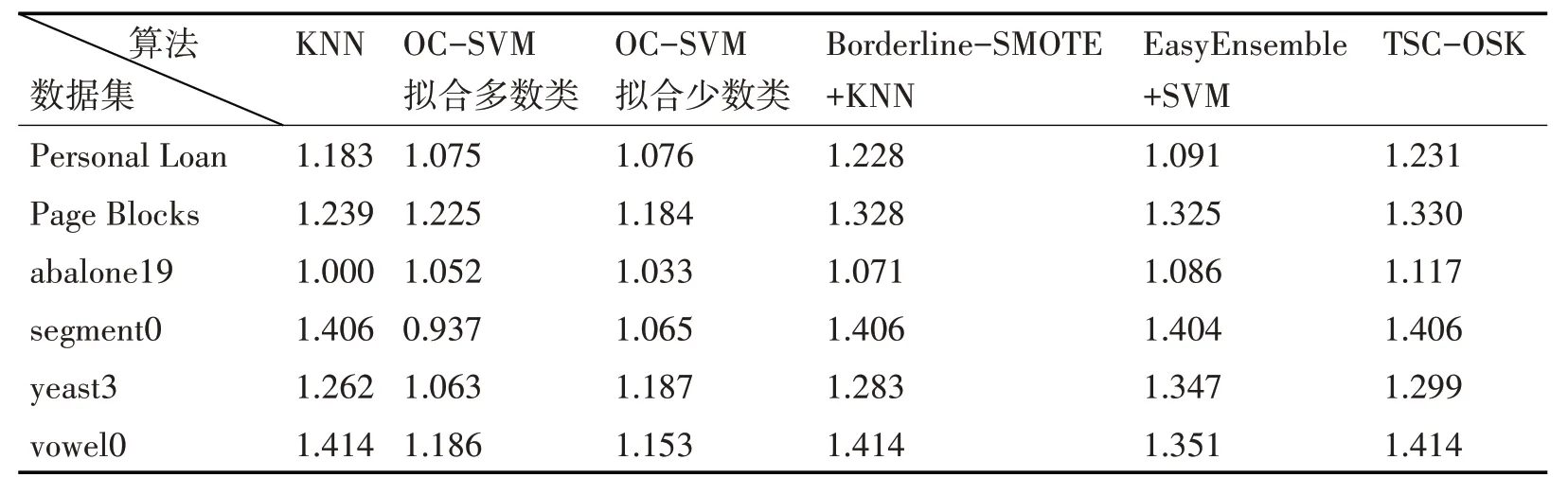
表4 不同方法的G-mean值
由表4可以看出:在yeast3数据集上,TSC-OSK算法的G-Mean 值仅低于EasyEnsemble+SVM 方法。在segment0 数据集和vowel0 数据集上,TSC-OSK 算 法、KNN 算 法 和Borderline-SMOTE+KNN 方法均取得了最高的G-Mean 值。而在其余三个数据集上,TSC-OSK 算法均取得了最高的G-Mean值。
由表5可以看出:在yeast3数据集上,TSC-OSK算法的AUC 值仅低于EasyEnsemble+SVM 方法。在vowel0 数据集上,TSC-OSK 算法与KNN 算法和Borderline-SMOTE+KNN方法均取得了最高值。在其余4个数据集上,TSC-OSK 算法均取得了最高的AUC值。
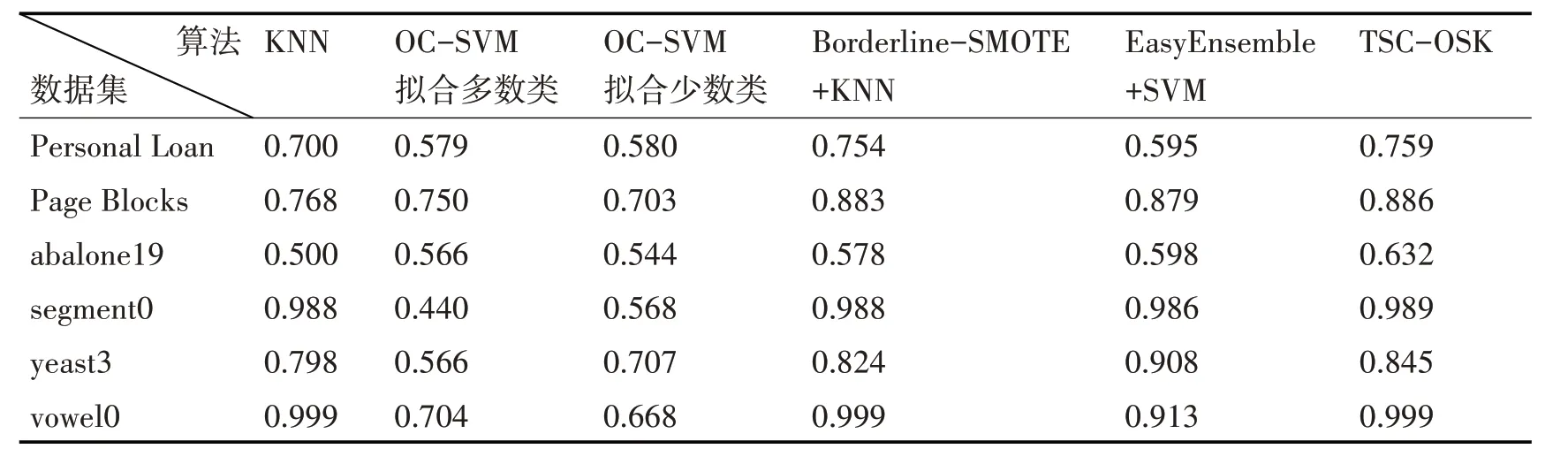
表5 不同方法的AUC值
由表6 可以看出:在abalone19 数据集上,TSC-OSK 算法的F1-Measure 值仅低于Borderline-SMOTE+KNN 方法;而在其余5 个数据集上,TSC-OSK算法均取得了最高的F1-Measure值。
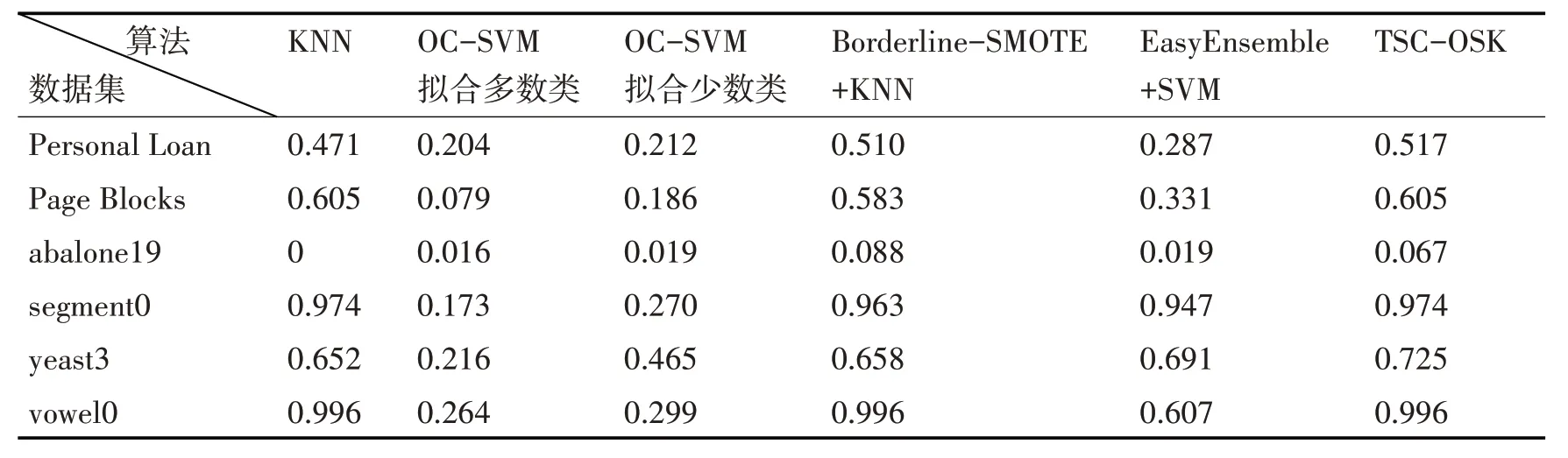
表6 不同方法的F1-Measure值
综合以上实验结果可以发现,本文所提出的TSC-OSK 算法,通过采用OC-SVM 算法与KNN 算法进行两个阶段的分类,继承了OC-SVM算法在处理不平衡数据上的良好性能,同时避免了边界样本与离群样本对OC-SVM算法性能的影响,为不平衡数据的处理提供了一种更加合理的机制。因此,TSC-OSK 算法能够在不增加训练成本的情况下,取得相比其他算法更好的分类性能。
4 结语
针对OC-SVM 算法无法对不平衡数据集中的边界样本与离群样本做出正确的分类的问题,本文提出了一种基于OC-SVM 与KNN 的两阶段分类算法TSC-OSK。实验证明,TSC-OSK 算法在各个领域的不平衡数据集上均能表现出不错的分类性能。但在实际使用TSC-OSK 算法时,难以通过试错调参的方式让第一阶段的多数类检测器与少数类检测器各自拟合到最合适的状态。同时,第二阶段中KNN 算法的k 值也对TSC-OSK 算法的分类性能有很大的影响,需要通过进一步的研究选择更好的k 值取值策略。因此在未来的研究中,针对两阶段分类算法TSC-OSK 的第一阶段分类,可以尝试将优化算法结合到多数类检测器与少数类检测器的构建过程中,解决OC-SVM算法参数设置困难的问题,也可以尝试使用其他的单类学习算法;针对第二阶段分类,应当寻找一种启发式的k 值确定策略,或是尝试使用不同的分类算法来进行第二阶段的分类。
