融合偏旁特征的化学命名实体识别研究*
2023-08-02尹止戈陆建峰
尹止戈 陆建峰
(南京理工大学 南京 210094)
1 引言
命名实体识别(Named Entity Recognition,NER)是自然语言处理中一项关键的上游任务,也是信息抽取的技术支撑。传统的命名实体识别任务是识别出文本中的七小类(人名、地名、机构名、时间、日期、货币和百分比),除此以外,NER技术还可用于特定领域,提取出特定意义的实体。例如中学化学课程中的实体识别任务通常是从非结构化的文本数据中提取出具有化学意义和特征的知识点实体。
早期的NER 系统主要分为三类,基于字典,基于规则和统计机器学习。基于字典的方法[1],主要利用字符串匹配,包括精准匹配和模糊匹配,存在着高精度,低召回,扩展麻烦的问题;基于规则的方法,主要利用模式规则以及上下文词语,需要专家辅助和筛选,可移植性弱;统计机器学习模型包括隐马尔可夫模型(Hidden Markov Model,HMM),最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM),条件随机场(Conditional Random Field,CRF)等。HMM 模型基于两个重要假设,马尔科夫性假设和观测独立性假设,数据依赖多为一阶,忽略了邻域多阶的信息。MEMM是局部归一化方法,其利用维特比算法解码,但不一定全局最优,会出现标注偏置。CRF 通过转移特征函数和状态特征函数,针对前后多个位置进行限定,统计全局概率,其更依赖标注数据库的质量和数量。近年来,深度学习技术为命名实体识别任务带了新的机遇,以word2vec[2],长 短 期记 忆 网 络(Long Short-term Memory Networks,LSTM)[3]为代表的半监督模型以及ELMo,BERT[4],XLNet[5]为代表的大规模预训练模型,在泛化能力和准确率上都得到了提高。相比较LSTM 系列模型而言,预训练模型通常需要更大的训练预料且对算力要求更高。基于Bootstrapping,CGExpan[6]的半监督算法,通过实体集扩充,克服了语料稀缺,数据稀疏的问题。
中学化学领域缺少大量的具有高质量的标注数据,且语料多为非结构化文本。目前中学化学领域实体识别的主要问题包括以下两个方面:1)中学化学课程领域的数据往往呈现中英文结合,化学式简写或嵌套的特点。化学实体没有固定的表述方式,因此,难以构建全面合理的实体特征。2)现有的NER 研究通常针对通用领域,例如新闻领域,这些研究更多地依赖公开的大规模训练语料,难以移植到中学化学课程领域。
化学实体的偏旁部首多为“石”、“气”、“钅”等,而具有相同词根的汉字通常具有相近的语义和语法用法,现有的中文处理算法往往把字或词作为基本单位,而忽略了偏旁部首特征中的词汇义原知识[7]。因此笔者构建了以BiLSTM-CRF 为基础的改进神经网络模型,融合了偏旁部首的词根嵌入向量,有效提升了语言模型的可解释性,在中学课程化学领域的非结构化文本数据中进行信息抽取。实验表明,该方法在F1 度量上高于实验中的基准模型。
2 相关工作
Safaa Eltyeb[8]概述了基于字典、基于规则和机器学习方法在化学文献中进行化学实体识别的解决方案。Zhihao Yang[9]针对生物化学领域中实体形式多变,提出了基于词典扩展的CRF实体识别方法。刘烨宸[10]对特定领域知识图谱状况进行了较为全面的总结。Zhiheng Huang[11],Guillaume Lample[12],Yue Zhang[13]提出了多种基于LSTM 的序列标注模型及变体,由于加入了CRF 层,使用句子级标记信息,与之前的方法相比,具有较强的鲁棒性和较少的词嵌入(word embedding)依赖。Zenan Zhai[14]等在化学和疾病实体识别任务上比较了LSTM 和CNN(Convolutional Neural Networks,卷积神经网络)的字符级词嵌入在BiLSTM-CRF模型上的差异,识别率相当,但CNN 具有计算性能优势。Xinlei Shi[15]等深入研究了汉字处理的基本层次,提出了一种新的深度学习技术,词根嵌入(radical embedding)。Chuanhai Dong[16]将 中 文 词 根 嵌 入Bi-LSTM-CRF 模型中,在MSRA 数据集上取得了良好的识别率。Jie Yang[17]提出NCRF++,设计了一个CRF推理层,通过配置文件建立自定义模型结构,对于词向量和字向量的嵌入更加灵活。Yao Chena[18]在中文不良药物事件报道(ADERS)数据集上,通过四轮数据标注和半监督扩充数据集,使用基于词汇特征的BiLSTM模型在自由文本上取得了较高的F1得分。Xiaoya Li[19]提出的Unified MRC框架通过将NER 任务格式化为阅读理解任务,能够同时应对嵌套NER 和扁平NER 任务。Jan-Christoph Klie[20]针对实体歧义,提出了一种实体链接消歧方法,面对资源匮乏,展示了统计机器学习模型的有效性,且在注释速度上提升了35%。
针对中学化学领域语料,本文确定了五个实体类别,分别是化学药品(CHE),化学仪器(EQU),属性(ATT),反应现象(REA)和操作方法(OPE)。本文采用了高效简洁的BIO 标注模式,B 代表实体的起点,I代表实体的内部和终点,O 代表非实体。表1为人教版高中化学语料的实体标注方法。
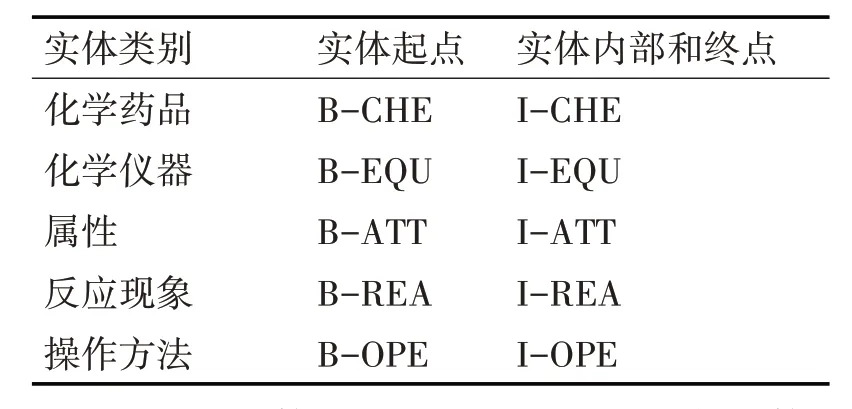
表1 人教版高中化学语料实体标注方法
中学化学实体中有较多中英文结合实体以及嵌套式实体,例如“NaCl 溶液”,“NaCl”通常是一种晶体状的化学药品(氯化钠),而“NaCl 溶液”则表示的是一种液态的化学药品,此时应该将英文的“NaCl”和中文“溶液”包含在同一个实体中,而不应该遗漏掉“溶液”,虽然单独的“溶液”在这里不属于预先定义的五个实体类别,但“溶液”接在“NaCl”后便有了不同的实体含义。图1 为化学数据集中的标注示例。

图1 化学数据集中的标注示例
3 融合偏旁特征的BiLSTM-CRF算法模型
3.1 长短时记忆网络
循环神经网络(Recurrent Neural Network,RNN)是针对序列标注任务的重要神经网络模型,RNN输入一个向量序列(x1,x2,…,xn),输出的是一个包含状态层位置信息的序列(y1,y2,…,yn)。通常,RNN 可以训练得到序列的距离依赖特性,但是往往学习到的是近距离的依赖,不擅长捕获更复杂的长距离依赖。LSTM 在RNN 的基础上添加了记忆单元以及Sigmoid 激跃函数,能够有效捕捉长期依赖关系。LSTM的记忆单元包括输入门(it)、输出门(ot)、遗忘门(ft)和细胞状态(ct) ,c为tanh 网络创建的备选值向量,其中输入门和遗忘门的结果影响单元状态的更新。公式解释如下:
其中σ是Sigmoid 激跃函数,⊙是元素积,w是权重矩阵,b是偏差。我们使用双向的LSTM 得到文本的字符向量。对于一个给定的句子(x1,x2,…,xn)包含了n个字符,每个字符都包含了一个d维的向量,正向的LSTM 能够捕获上文的依赖关系,得到一个隐层,在LSTM 的基础上,加上一个反向的LSTM 得到下文的信息,将两个隐层拼接成一个新的隐层,以此得到上下文的表示信息。
3.2 条件随机场
LSTM 考虑的是输入序列的上下文信息,条件随机场还可以考虑实体标签之间的依赖关系。CRF是一种基于统计的序列标注方法,给定的观测序列X和输入标签Y,CRF 通过条件概率P(Y|X)来判别,假设一个输入序列X={x1,x2,xn},标签的序列为Y={y1,y2,yn},其中xi表示第i 个单词的向量,yi第i个单词对应的标签,则对于给定序列X,随机变量Y的条件概率可由以下公式表示:
公式中tk(yi-1,yi,,X,i)表示相邻输出标签之间的转移特征函数,sl(yi,X,i)表示当前观测序列的状态函数,Z(X) 是规范因子,α,β为模型参数,条件随机场的训练过程中,使用最大似然估计L(αk,βl),选取对数似然最大的参数,在训练集上(X),Y则有
最大条件概率的标签序列为
原始的CRF是统计每个实体对应标签的分数,然后输入给解码器,而LSTM 中的CRF 是使用LSTM 传上来的隐藏层状态值yi作为统计分数,同时考虑了标签依赖关系,添加了限定特征。
3.3 词向量
词向量是一种分布式嵌入向量,词向量是根据大样本的语言数据中的分布属性来量化和分类语言词汇之间的语义相似性。最初的词向量是独热编码(one-hot),词出现的位置标记为1,其余为0,通过词出现的频率排序得到一个V 维的稀疏矩阵,该方法具有维度灾难和语义鸿沟的问题。通过对共现矩阵进行矩阵分解,能够得到更加稠密的词向量,但求解计算复杂度较大。word2vec 是利用神经网络对词的上下文训练得到词向量化表示的一种工具,训练方法包括CBOW 和Skip-gram,优化效率高,但只考虑了词的局部信息,得到的是静态的词向量,且无法解决一词多义问题。与独热编码(one-hot),共现矩阵的矩阵分解,word2vec 等方法产生的静态词向量相比较,通过语言模型例如双向LSTM,GPT,BERT 预训练得到的词向量是动态的,其本质思想是用模型去动态调整单词的词向量,使用时单词因其在句子中的位置和语法结构具备了特定的上下文信息,因此可以根据上下文语义动态调整单词的词向量。传统的分布式嵌入向量主要包括词向量和字符向量(character embedding)。在英文或中文中,词可以拆分为更小的字符,字符向量可以避免分词的麻烦,能够更好地解决未登陆词问题。图2 是带有字符向量的BiLSTM-CRF 模型结构。
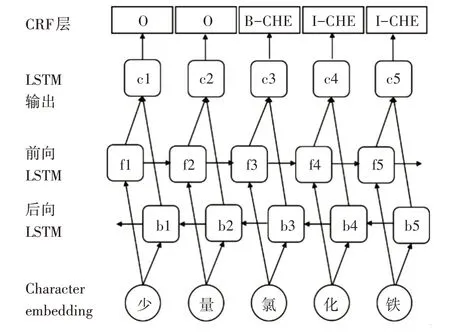
图2 带有字符向量的BiLSTM-CRF结构
3.4 偏旁部首向量
偏旁部首向量(radical embedding)是分布式嵌入向量的一种表示形式,与词向量相似,即将字或词映射为相对低维空间的实数向量,数字空间中的邻近性体现了代数语义关系,不同点在于它是词根级别,包含了偏旁部首特征,是更细粒度的语义单位。中文是象形文字的代表,在语言学中,具有相同词根的汉字通常具有相近的语义和语法用法,例如“铁”和“镁”,它们是拥有相似化学性质的金属,又如“氢气”和“氦气”,相同的“气”字头,具有相似的物理形态和化学性质。在化学语料中,95%的化学元素由两个部位组成(包括它的偏旁部首),化学实体拥有众多的相似词根,因此本实验针对化学实体,融合了词根级的偏旁部首特征。在融合偏旁特征时,使用了一个词根映射的在线新华字典,其包括265个偏旁部首,20552个中文字符,每个字符在字典中都附有它的偏旁部首,例如<碘,石>。我们将化学元素以及中学化学语料中常见的偏旁部首列成表,如表2 所示。
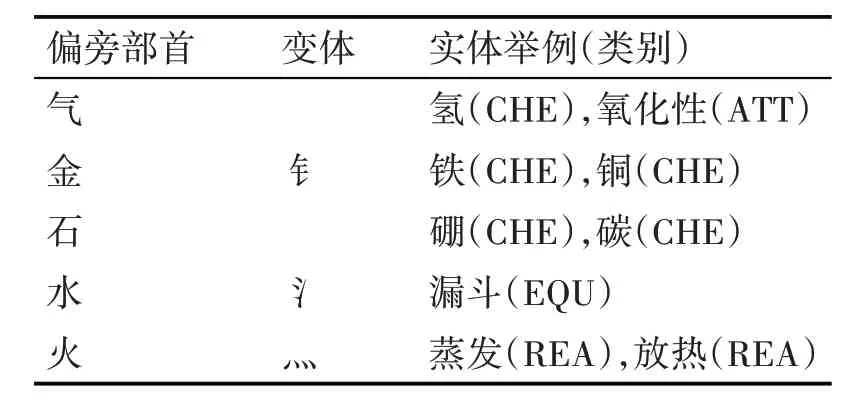
表2 化学语料常见偏旁部首与实体举例
偏旁部首向量的训练本文采用了双向的LSTM模型,输入模型的偏旁序列是未经过预训练随机初始化的50 维向量,字向量是经过BiLSTM-CRF 模型预训练的100 维向量,最后将字向量和前向偏旁向量,后向偏旁向量拼接。结合了字向量和偏旁向量的“碳”字表示如图3所示。
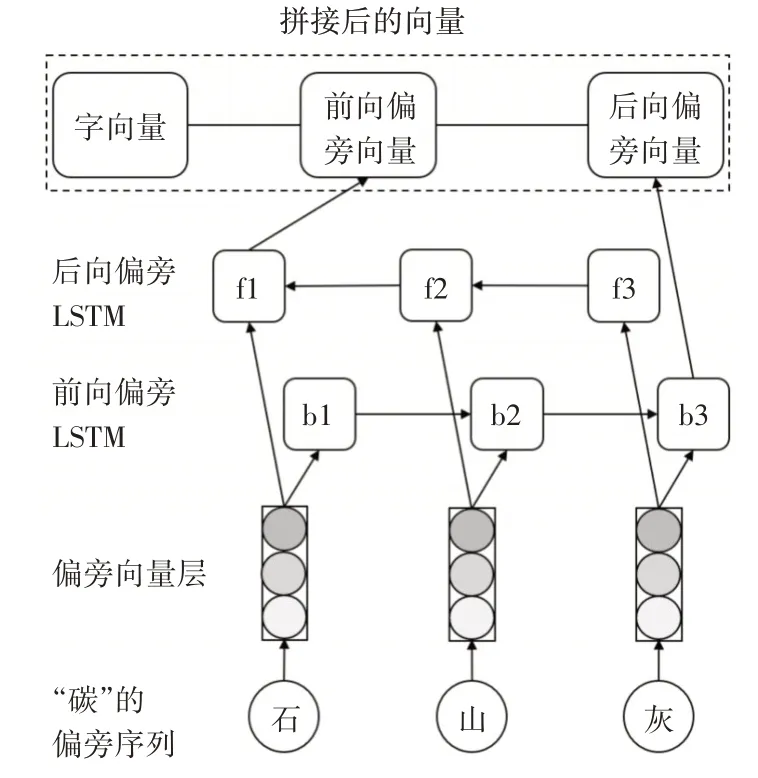
图3 结合字向量和偏旁向量的“碳”字表示
4 实验与分析
4.1 数据预处理
实验数据来自于人教版高中化学教材,选取《人教版高中化学必修一》与人教版新课标《高中化学选修4 化学反应原理》的教师用书各两章节作为语料,选取了中学化学实验作为语料,同时以《新课标高中化学教学大纲》为指导。实验随机划分80%的中学化学语料为训练集,20%语料为测试集。此文本数据中存在大量的图片和停用词,如“的”,“了”,删除这些干扰信息,同时将表格中的词转为文本形式,以保留可能的上下文信息,考虑到LSTM的距离依赖的有限性,将长句子切断为20 至40 字左右。通过预处理共得到247条句子,1213个化学知识点实体。
4.2 实验设置
偏旁向量是随机的50 维向量,经过双向LSTM和字典映射后,与预训练过的字向量拼接,其中字向量采用了在人民日报语料上预训练过的维度为100 的字向量,为了降低网络训练过拟合的风险,设置初始学习率为0.001,训练轮次为100,每轮次训练数为64,每10轮为一个标记点,每次标记点后学习率缩小为原来的一半,既保证了前期训练的速度,又有效防止过拟合。LSTM 尺寸为100,文本窗口大小设置为5,Dropout设置在每轮训练中以一定概率使部分神经元失活,实验中Dropout设置为0.5时,随机生成的网络结构最多,泛化能力更强,因此本实验设置Dropout为0.5。
4.3 实验结果分析
命名实体识别的基本评价指标有精准率P(Precision Rate),召回率R(Recall Rate)和F1值,精准率表示预测为正样例的样例占全部预测样例的比率,召回率表示预测正确的正样例占全部样例中正样例的比率,F1 值的计算方法为两倍的精准率与召回率的乘积再除以精准率与召回率的和。本实验以F1 值为最终评价指标,针对特定领域中学化学语料,实验分别将本论文模型和CRF,BiLSTM-CRF,NCRF++做对比,实验结果如表3所示。
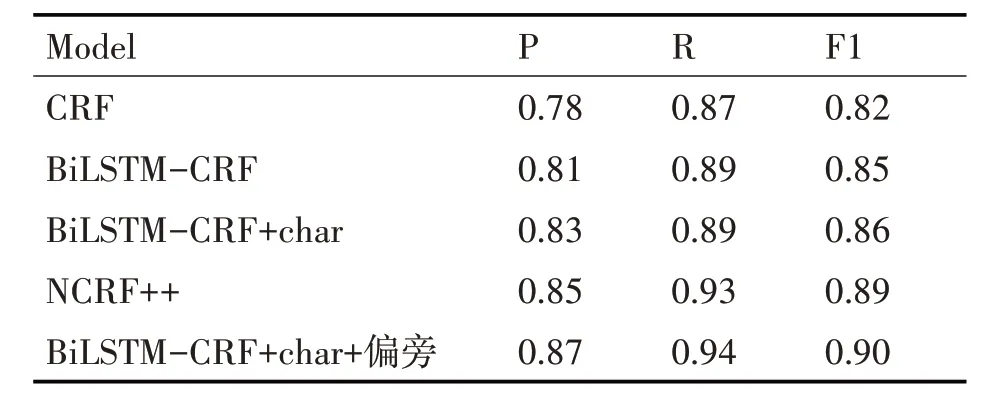
表3 在中学化学数据集上的实验结果
在本实验的中学化学数据集上,以上模型召回率均比精准率高,原因可能是此化学非结构化文本中,负样本远多于正样本,例如某些章节中化学知识点实体较少,有些句子在描述实验的教学目标,教学设计等,对于众多非实体的负样本容易识别错误。
从CRF和BiLSTM-CRF模型结果对比可知,双向LSTM 在精准率,召回率,F1 值上均有不同程度的提升,加入了char embedding 的BiLSTM-CRF 在精准率上提升了2%,NCRF++通过配置文件设置字向量和词向量,更加灵活,较BiLSTM-CRF+char 模型结果更优,但当融合了偏旁部首特征向量后,改进的BiLSTM-CRF模型在中学化学数据集上,取得了最优的F1值。
5 结语
本文以中学化学领域非结构化信息为抽取对象,针对化学命名实体的领域特征,提出了融合偏旁部首特征的BiLSTM-CRF算法模型,通过偏旁向量、预训练的字符级向量和领域知识的结合,捕捉化学知识背后的语义信息,达到了对化学非结构化文本实体精准识别的目的,证明了当没有大规模的特定领域语料库时,偏旁部首特征的有效性。
针对中学学科领域和本实验,有待提高的部分,例如能否将词向量、字向量、词根向量统一在一个模型之中,以及如何将BERT 等大规模无标注预训练模型和领域知识相结合,充分融合知识与数据的优势,使深度学习模型具有更好的鲁棒性和可解释性。后续工作将围绕上述部分继续展开。
