基于用户行为特征的微博谣言检测*
2023-08-02李艳君张海军潘伟民
李艳君 张海军 潘伟民
(新疆师范大学计算机科学技术学院 乌鲁木齐 830054)
1 引言
尽管当前情报学界并未对谣言进行明确的定义与声明,但大部分研究均认为谣言是在网络空间、社交圈等信息环境中,传递于用户之间,并受到公众关注的虚假信息[1]。新浪微博作为发展火热的网络交流工具之一,它的内容不受限制,任何人通过成功申请账号,就可以发表自己的所见所闻,新鲜事件,这样谣言就很容易被发酵,使其成为热点事件。热点事件一旦出现,就会在微博迅速蔓延,然而网民的年龄、背景差异大,谣言传播时部分群众并不能很好地辨别,再加上从众心里,谣言扩散变得更加容易,它们的出现,给人们难免会带来恐慌,尤其是部分老人,更加偏向相信一些谣言,给人们身心健康带来不必要的困扰。所以对新浪微博进行谣言检测研究具有非常重要的现实意义。
目前基于用户行为特征的谣言检测主要从机器学习方法和深度学习方法两方面来进行谣言检测。在机器学习方面,通过分析提取用户行为特征及用户信息特征,采用贝叶斯[2]、决策树[3~5]、支持向量机[6]、隐马尔可夫模型[7]等来进行谣言检测。而在深度学习方面,主要采用的方法有循环神经网络RNN,卷积神经网络CNN,长短时记忆网络LSTM,注意力机制等方法。如Ma[2]等将一个微博事件使用两种不同的文本表示法,即词袋模型和神经网络语言模型,并提出一种基于神经网络的模型学习文本的特征表示来进行谣言检测。Chen等[9],利用用户评论中提取的特征,循环神经网络结合注意力机制,提高了谣言检测准确率。Ruchansky 等[10]提出一种CSI(capture,core,integrate)模型,采用RNN方法捕捉用户行为进行分类。刘政等[11]提出了基于卷积神经网络的谣言检测方法,准确率较之前研究提升了很多。Li[12]等使用共享的长短期记忆(LSTM)将用户可信度信息整合到谣言检测层中,将注意力机制并在谣言检测过程中,能得到很好的分类效果。廖祥文等[13]采用GRU 网络来进行谣言检测,将微博文本按照时间段分割,加入了局部用户信息和文本特征信息从而提高了准确率。
以上各种基于用户行为的谣言检测,虽然都能取得很好的效果,但对日益增长的谣言检测的需求而言,现有的基于用户行为特征的谣言检测方法还存在一些不足,主要表现在两方面:一方面是在前人基于用户的行为特征进行检测谣言时,没有留意句子之间关系的处理,本文通过ERNIE 方法预训练处理句子之间的关系,来增强句子之间的关系。另一方面是准确率的提高。考虑到用户的行为特征,提出UDUC算法来提高谣言检测的准确率。
2 基于用户行为特征的谣言检测算法
2.1 用户行为特征选取
本文主要选取用户行为特征作为主要参数,结合用户信息特征与微博文本特征达到谣言检测的目的。从众多用户行为特征中选取了准确率不小于78%的4 个效果相对比较明显的特征。同时选取了效果比较好的3 个用户信息特征。将用户行为特征和用户信息特征以及微博文本特征组合在一起,对微博谣言信息进行检测,来提升谣言检测的效果。选择的微博中用户行为特征主要有:主动发布微博(发布)、转发微博帖子(转发)、微博帖子点赞(点赞)、评论微博帖子(评论)等行为。选择的用户信息特征有用户的昵称(昵称),用户的简介(简介),用户在微博的认证(认证)等其他重要的用户信息,具体如表1所示。

表1 用户特征表
2.2 模型的构建
为了提升谣言检测的准确率,通过分析微博数据集中的用户行为特征和用户信息特征,以及微博文本内容,查阅国内外相关的谣言检测方法,提出应用ERNIE 模型和DPCNN 模型,将两个模型相互融合,微调整模型的结构,使其提升检测的效率与准确率。模型结构图如图1所示。
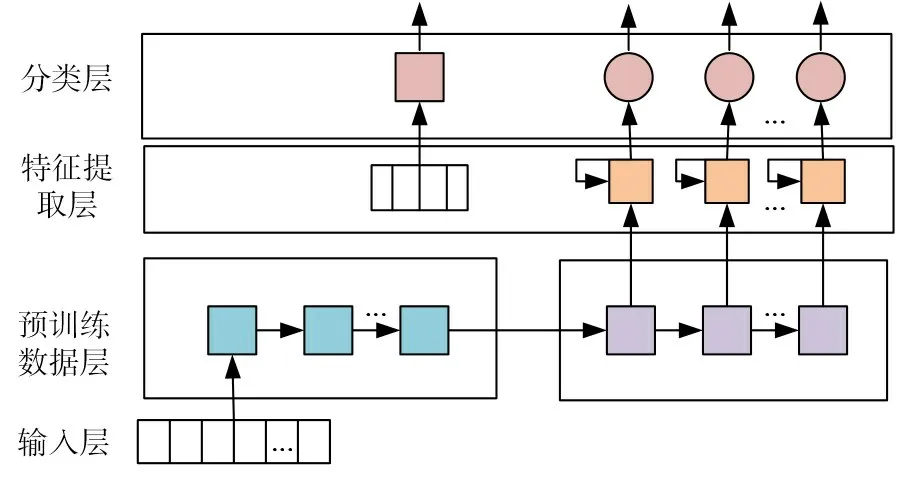
图1 基于用户行为特征的微博谣言检测模型
大体结构分为三层,分别为预训练数据层,特征提取层,分类层,最后输出结果。首先将微博文本序列向量化,使用ERNIE 预训练处理好的数据集,作为模型的输入,之后使用DPCNN 处理用户信息和文本特征,最后链接全连接层,输出分类的结果进而实现微博谣言检测。
2.2.1 预训练数据层
预训练数据层主要应用ERNIE 模型。ERNIE模型通过连续学习获取词和句子之间的语义关系,通过语法级别预训练任务,来更好地处理句子之间的关系。
构建词法级别预训练任务中的知识掩码任务,用来获取微博文本中的语义信息。构建关系预测任务来预测微博文本中的关键词,增强获取微博文本中关键词的能力。构建语法级别的预训练任务,来获取训练数据中的语法信息。微博文本段落中不同句子之间的关系可以通过句子们的重排序任务使预训练的模型学习到。这个过程就相当于一个多分类任务,如式(1)所示,一个n 分类任务,将微博文本随机分成i 段,以此来判断句子之间的关系。
构建三分类任务来判断句子对之间的位置关系(包括相邻的句子、同一个微博文本中非相邻的句子、不是同一个微博文本中的句子)这3 种类别的关系,以便辨别句子之间的相关性,以此来更好地处理句子之间的关系。
2.2.2 特征提取层
特征提取层应用的是DPCNN 模型。DPCNN有4 个明显的优势来提取特征。第一个是用多尺寸卷积层进行卷积。第二个是将维度固定,对特征进行向下采样。第三个就是采用了等长卷积。第四个是应用了残差结构,帮助解决梯度消失和梯度爆炸问题,使训练效果更好。
假设输入固定的序列长度为l,步长为s,卷积核大小为n,当输入序列长度不足时,两端各填补f个零,那么输出序列p为
选择等长卷积,在每个等长卷积后使用大小是3和步长是2的池化层。目的是把微博文本的长度压缩为原来的一半。之前是只能感知到2 个词(PAD、以前)的长度的信息,经过该池化层后就能感知到4 个词(PAD、以前、有、吃到)长度的信息。以此来更好地处理特征。
2.2.3 分类层
将特征提取层得到的输出结果输入Softmax层,分类输出结果S,判定该微博是否为谣言。
其中,Relu 为线性修正单元激活函数,W 为得到的权重矩阵,h为输入的信息,b为偏置值。
3 实验及数据分析
3.1 数据集处理
应用经典的2016 年Ma[14]所提供的公开数据集中的信息,其中包含的用户行为特征有,发布微博,转发微博,点赞微博,认证等,还包括用户的信息如用户的昵称,简介,描述以及文本内容,用字典提取出需要的特征。首先去掉停用词和特殊字符,之后按照7∶2∶1 的比例,将数据集分为训练集,测试集和验证集。其中谣言事件为2313 件,非谣言事件为2351件,共计微博总数为3805656条。
3.2 实验设置
实验中处理的微博文本数据,用ERNIE 模型进行处理,句子长度设置为140。DPCNN 中的过滤器长度采用3,步长设置为2,dropout 设置为0.8,卷积核的数量设置为250,隐藏层的数量设置为768。输入的长度设置为256,如果数量不够时,采用0 填充。并且训练任务和测试任务以及验证任务的比例设置为7∶2∶1。最后通过Softmax 层进行划分。本文中的评价指标就采用常用的准确率(P)见式(4)、召回率(R)见式(5)以及F1 值(F1)见式(6)。
其中,Tr表示正确识别谣言的数量;Fr表示未能正确识别谣言的数量;Fn表示没能识别出来是否是谣言的数量。
3.3 实验结果与分析
3.3.1 用户行为特征的参数选择
对不同的用户行为特征进行实验分析,数据集中所包含的用户特征有:转发数量、用户ID、粉丝数量、转发微博文本、用户描述、用户简介、所在城市、省份、朋友数量、用户所在地、粉丝数量、验证与否、原始微博文本、图片、状态、创建时间、昵称、性别、评论数量、用户名等一系列特征。通过实验最终选取准确率在78%之上的有效的用户行为特征有:发布微博的文本、转发微博的文本、用户的昵称、用户的简介、用户的微博认证、用户点赞和用户评论等行为。这些特征都可以从数据集中直接获取。
3.3.2 特征有效性的验证
为了证明选取的特征是有效的,使用上节提到的选取有效的特征来验证模型加入特征是对提高谣言检测的效率有帮助。首先,将每个特征分别加入到模型中进行训练,检测结果为谣言的特征昵称得到的准确率为79%,简介得到的准确率为81.2%,认证结果为84.5%,发布结果为87.7%,转发准确率最高为89.8%,点赞为82.2%,评论的准确率为83%,得到的所有结果,采用常用的评价指标:准确率P、召回率R 以及F1 值。其中T 表示分类结果为谣言,所有的实验结果如表2所示。
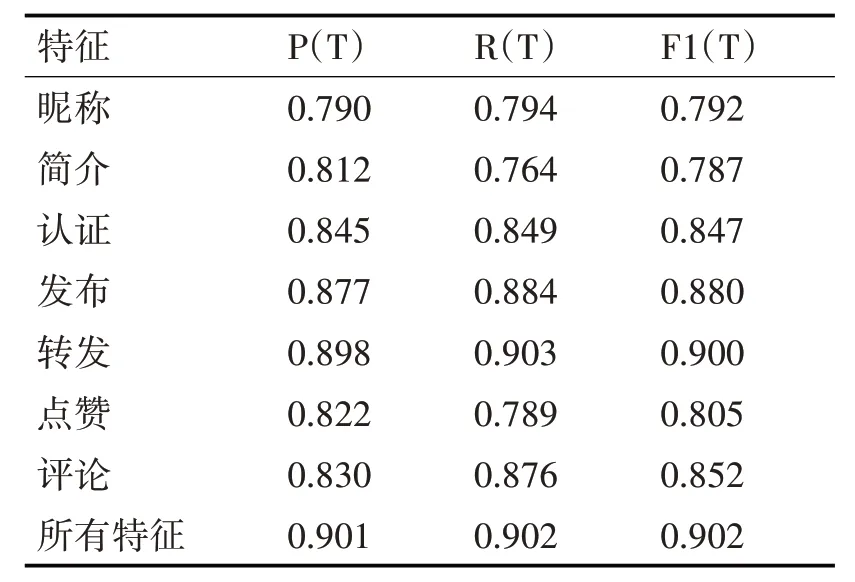
表2 特征验证结果表
从表2 可以看出,本文验证的特征分别可以得到很好的检测效果。其中转发的特征最有效,准确率89.8%,F1 值90%,从表中可以明确的看出选取的各个特征在融合之后,对提高检测的准确率是有效的。
为了进一步验证特征的有效性,分别对不同的特征进行融合,作对比实验。由于昵称、简介、认证三个特征在上面的实验中效果还是不尽如人意,但是三个特征结合在一起的结果是达到预期目标的,所以将三个特征作为固定特征,再加上剩下的用户行为特征,分别做不同的组合实验,来进一步验证特征的有效性。
首先固定特征加上发布特征,得到的准确率为0.796,固定特征加上转发特征得到的准确率为0.801,固定特征加上用户点赞特征得到的准确率为0.786,固定特征加上评论特征得到的准确率为0.831。固定特征加上发布与转发两个特征得到的准确率为0.873,依此类推,再依次加上点赞和评论两个特征,得到的准确率分别为,0.886,0.901。详细的数据信息如图2所示。
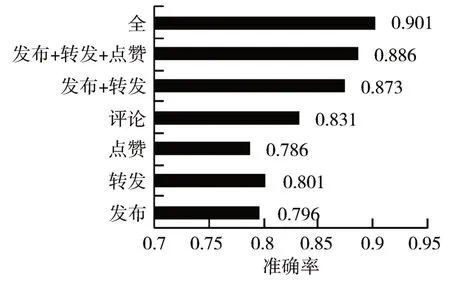
图2 固定特征与不同特征组合的结果
通过图中的数据说明,加入单个的特征提升的效果不明显,甚至要低,如图中所示点赞的用户行为特征对比不加入特征的准确率(0.798)低0.012,只有特征相互融合两个或两个以上,可以有更加明显的提高。如图2 所示,发布与转发特征的融合准确率提升了0.075,转发发布和点赞的效果提升了0.088,本文所选出的所有特征融合之后得到的结果提升了0.103,所以用户行为特征对谣言检测的准确率提升是有所帮助的。
3.3.3 不同模型的分类结果对比
1)模型加入特征与否的比较
本文首先只用微博文本进行分类,将得到的结果与加入用户行为特征进行分类的实验作对比来验证特征的有效性,在不加入特征的情况下,得到的准确率为79.82%、召回率80.35%以及F1 为80.08%,得到的结果不尽如人意。由上节可知,所有将选择出来的特征组合之后来验证该条微博是谣言的分类结果,两项结果对比如表3所示。
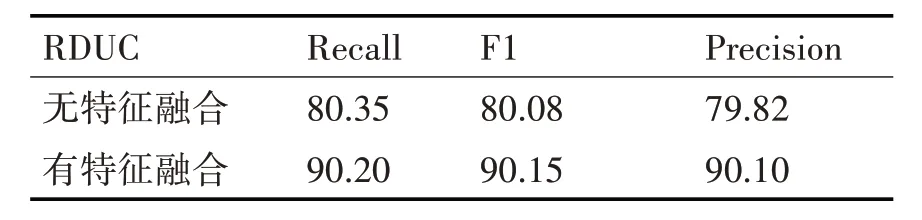
表3 模型分类结果(%)
由表3 可知,模型加上用户行为特征后召回率为90.2%,F1 值为90.15%,准确率为90.10%,所以提出的模型有效,分别比不加入特征的召回率,F1和准确率提高了9.85%,10.07%,10.28%。并且根据上一节得到的结果可知,所有特征的组合比每个单独的特征和部分组合特征的效果更好。
2)与其他实验模型的比较
为了验证谣言的分类结果是有效的,采用RNN模型[14],LSTM模型[9],GRU模型[13]和本文提出的模型作对比。其中RNN 模型是首先被用到谣言检测中的深度学习模型,并且与机器学习方法比较效果提升的很多,用该典型模型得到的实验结果,更加有说服力。LSTM 模型是RNN 模型的升级版,解决的RNN 的记忆力问题,在谣言检测方面应用与RNN 相比较更加广泛。而GRU 模型又是LSTM模型的变体,应用起来更加便捷,本文的模型与这些应用广泛的模型相比较更具有说服力,其实验结果如图4所示。
从图3 中可以看出,RDUC 方法的分类效果的准确率高于其他,主要是因为ERNIE 和DPCNN 两个模型的结合,可以双重解决文本长距离依赖的关系问题,ERNIE 还可以连续学习,缩短处理数据的时间。DPCNN 缓解梯度消失的问题同时也加快了特征的传递。从图中可以看出,模型得到的结果是最好的,相比于RNN 模型,准确率提高了8.5%;相比于LSTM 模型,准确率提高了5.5%;相比于GRU模型,准确率提高了3%,可见本文提出的模型是有优势的。但是该模型处理实时数据时性能需要进一步优化提升,接下来的工作会重点集中在这一部分,来更好地完善模型。

图3 不同模型的实验结果对比图
4 结语
本文提出了基于用户行为特征的微博谣言检测方法,主要使用用户行为特征作为主要参数,应用ERNIE 和DPCNN 两个模型的相互结合,结合ERNIE 模型的优点高效的处理微博文本的上下文信息。结合DPCNN 的优点解决文本的长距离依赖问题,更进一步的提高模型的准确率。通过对比实验表明,本文所提出的RDUC 方法其模型的准确率达到了90.1%,比其他模型效果更好一些,证明了模型的有效性。
本文目前得到较好的结果,但还是有提升的空间,在数据处理方面主要应用的是过去发生的谣言事件,没有实时的谣言信息,不能保证达到实时检测谣言的效果。因此,接下来的工作是结合用户行为特征希望找到更加合适的方法来实现高准确率的实时谣言检测。
