面向色情音频检测的内容分类研究*
2023-08-02司朋举
司朋举
(中国石油大学(华东)计算机科学与技术学院 青岛 266580)
1 引言
色情音频检测及有效屏蔽色情信息一直是网站、直播平台信息安全检测的重要组成部分。目前存在许多用来防止未成年人浏览不良网站网页信息的网络防火墙软件,例如格雷盒子(PIRPDA)、净网大师(KNN)等,但该类软件只针对含有不良文字和图片内容的信息进行拦截,且在音频不良信息过滤方面普遍需要依靠人工对初步未过滤的音视频做进一步的审核,因此在管理方面工作繁忙且浪费人力,容易造成误判漏判等情况。
目前,国内外部分研究者将目光聚焦在了视频、弹幕文字检测上,为不良信息检测提供了很好的技术、思想以及理论支撑。但在不良信息传播过程中,音频形式占据了很重要的地位,如谈话聊天、脱口秀、在线广播等一些以语音为主的直播节目,视频检测所用到图像处理技术,如裸露检测[1]、动作识别[2],并不适用于音频检测场景下。
在色情音频分类与检测问题中[3~4],工业界及传统的色情音频检测一般通过检索关键词过滤不良信息,需要庞大的色情关键词库以及需要对关键词库不断更新支撑[5~9]。与传统的机器学习相比,深度学习在图像识别、语音识别、文本分析等方面有着更加出色的表现。同时能够有效地解决梯度扩散、过拟合等问题[10~15]。因此在色情音频信息检测问题中应用深度学习技术是解决传统方法所面临问题的一种有效途径[16~17]。然而目前国内外缺乏公开的色情音频数据库去应用测试实验效果是应用深度学习技术检测音频中色情内容中的关键问题之一。因此本文针对色情音频信息检测展开研究,实现对网络色情音频的精准而快速检测,过滤网络传播中的色情音频信息,具有一定的实际应用价值。
2 基于内容的色情音频检测算法
本章将通过借鉴语音识别和文本分类领域中的经典成果[17~18]以及作者的工作经验,设计如图1所示的基于内容的色情音频检测算法,基于GPL-Licensed 制作开源音频剪辑软件对收集的原始音频以色情、非色情为标签剪切以及预处理分为训练集和测试集,同时对收集的原始文本以及训练集中音频文本化后的数据预处理分为训练集和测试集,随后训练文本分类模型,实现检测文本化后的音频数据信息色情检测。
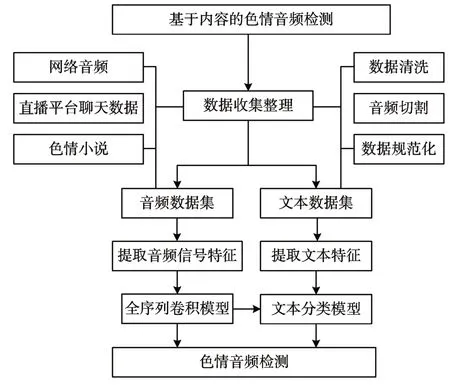
图1 基于内容的色情音频检测框架
2.1 基于全序列卷积神经网络的语音识别算法
在实现色情音频检测过程中或者在应用色情音频检测模型之前,需要将音频文本化提取出内容信息,因此本文采用科大讯飞提出的较为经典的全序列卷积神经网络框架实现语音识别。首先对音频的时域信号通过Python 中的librosa 等开发包进行分帧、加窗以及傅里叶变化得到每个音频所对应的时频图,如图2 所示,每个时频图包含了时间、频率以及幅度,其中时间通过x 轴表示,y 轴表示频率,幅度高则用亮色表示,低用深色表示。
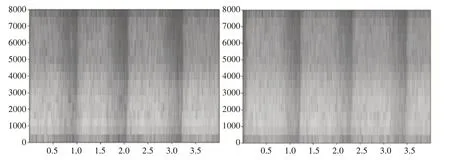
图2 全序列卷积神经网络输入时频图
图中x 轴表示音频时间,y 轴表示音频频率,可看作图像的两个维度,直接作为全序列卷积神经网络的输入,随后对时频图做多次卷积、池化操作组合,输入到全连接层中,训练输出单元与识别结果相对应。网络架构如图3所示,每个卷积层使用3×3 的小卷积核,并在多个卷积层之后再加上池化层,在增强了网络表达能力的同时表达了语音的长时相关性。
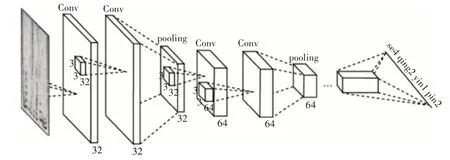
图3 全序列卷积神经网络架构示意图
2.2 文本分类
在音频及文本数据预处理后,经过word2vec转化为向量输入,使用基于深度学习的文本分类技术训练模型,以检测原始音频是否为色情,其中训练步骤如下:
Step 1:首先将切割后的文本使用Python 版的JieBa 分词工具包分词,随后转化为One-Hot 向量作为word2vec 的输入,经隐藏层以及softmax 回归训练后,将参数作为词的向量化表示;
Step 2:假设Xi∈Rk表示句子中的第i 个单词对应的k 维向量,那么将长度为n 的句子可表示为X1:n=X1⊕X2⊕…Xn,其中⊕为连接运算符;
Step 3:随后卷积提取连接而成的句子Xi:i+j特征ci,其中Xi:i+j由Xi,Xi+1,Xi+j连接而成;
Step 4:使用多个不同窗口大小的卷积核应用于句子Xi:i+j提取多个特征ci组成c;
Step 5:将特征输入全连接softmax 层,输出标签的概率分布,预测类别标签的置信度;
Step 6:随后输入测试集,依次将预测类别标签与实际标签对比,计算模型分类准确度。
2.2.1 基于TextCNN的色情文本分类
TextCNN 在网络结构上包含了一个卷积层、一个最大池化层,以及softmax 分类预测层,支持Word2Vec或者GLOV 等向量化方式。如图4所示,基于TextCNN 的色情文本分类模型将一个句子分割成单词,随后通过经典的word2vec将单词映射成词向量,在对输入向量进行卷积操作后,通过采用最大池化层减少参数以增加优化速度,同时为了避免模型过拟合,最终计算softmax 预测得到的标签置信度以实现色情文本检测。
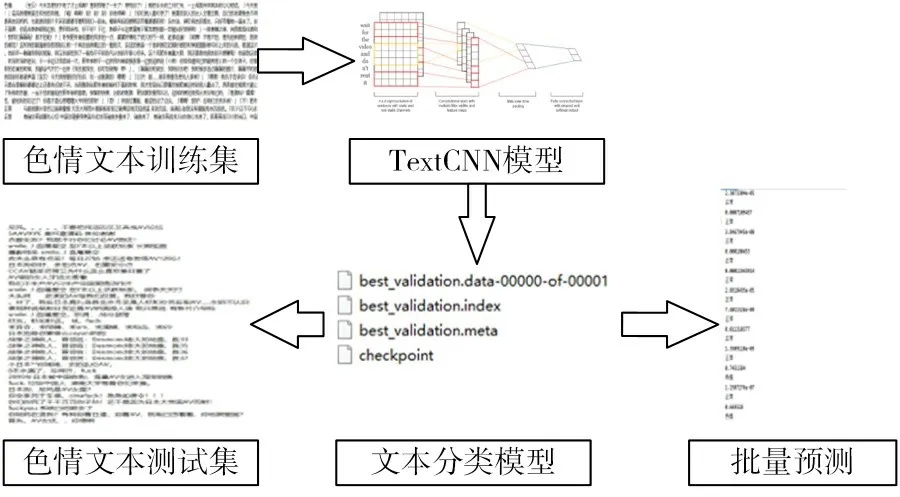
图4 TextCNN模型训练示意图
2.2.2 基于TextRNN的色情文本定义
RNN 模型具有短期记忆功能,在引入门控机制解决长期依赖问题后,比较适合处理自然语言处理等序列问题。2016 年PengfeiLiu 等提出TextRNN 应用于文本分类任务中。基于TextRNN的色情文本分类模型,经过word2vec 文本向量化后,将双向长短期记忆网络在最后一个时间步上隐藏状态,且连接其他时间步长后,其结果作为softmax 函数的输入,得到色情类别的概率分布。结构如图5所示。
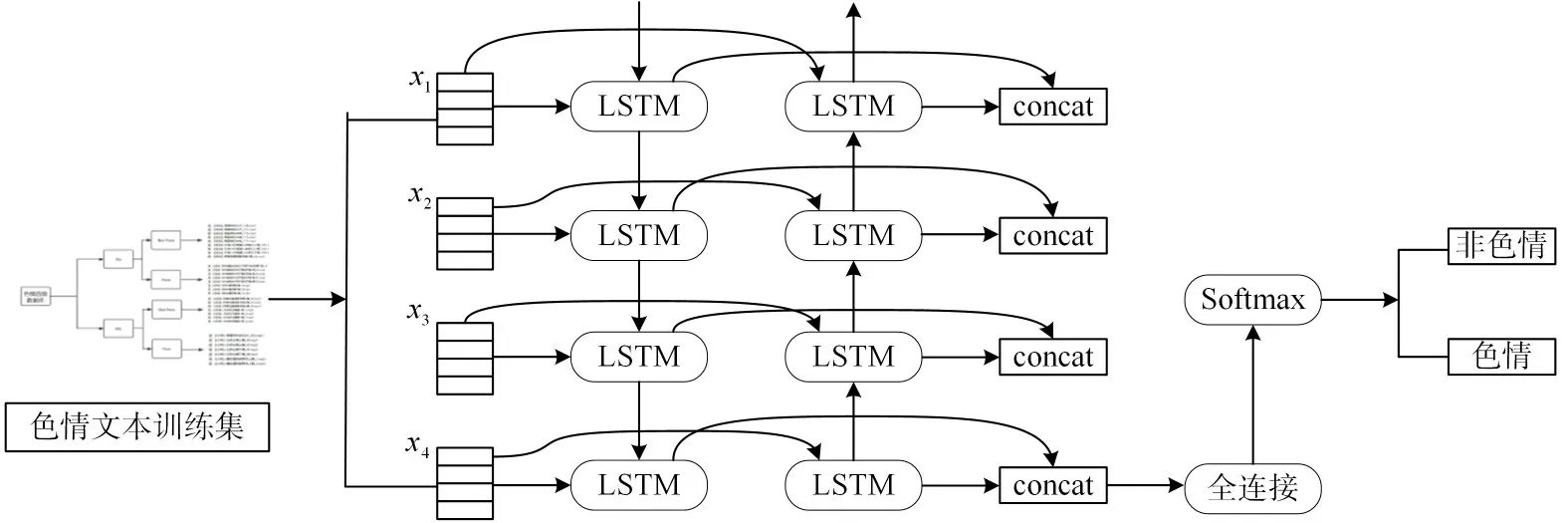
图5 TextRNN模型训练示意图
3 实验结果与分析
本文依据色情音频以及文本特点特征,收集整理形成色情文本训练集以及色情音频测试训练集,其中共1387 个音频,包含了897 个色情音频片段,490个非色情音频片段,每段音频持续1min或30s,同时本文提出了一种基于内容的色情音频检测方法,采用基于深度学习的文本分类技术作为文本分类模块,并将其与语音识别技术相结合,用于色情音频检测以及评估本文所公开数据集。并提出了基于内容的色情音频检测算法,验证了色情音频数据集的合理性。实验综合比较了本文所提算法以及经典音频分类算法在色情音频数据集上的各项指标如表1 所示,其中TP表示综合真正率、TN表示综合真负率,FP表示假正率,FN表示假负率,accuracy表示正确率。
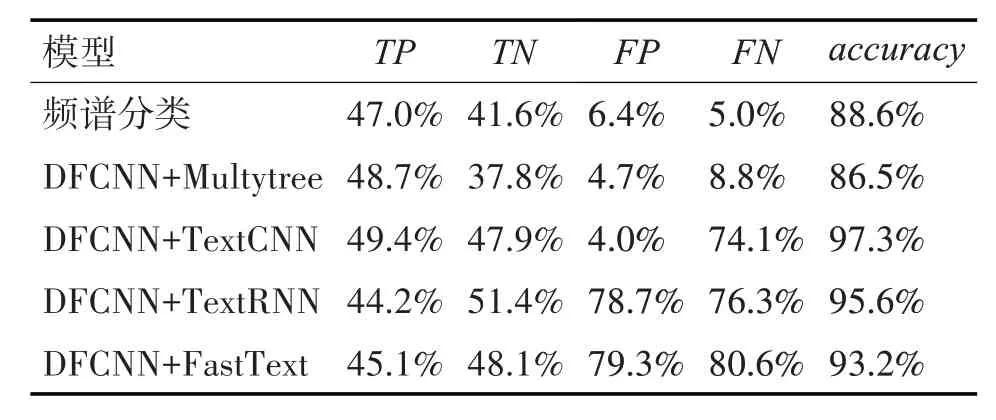
表1 各方法在色情音频数据集中的各项指标
可以看出在识别色情音频问题中,本文将全序列卷积神经网络结合文本分类技术经典模型后,所提出的基于内容的色情音频检测算法,同等条件下相较于基于频谱特征的分类模型准确率可提高将近9%左右,相较于多叉树关键词匹配算法可提高将近11%左右,且真正率和真负率均有提高。其中全序列卷积神经网络结合TextCNN 后在数据集上的平均分类正确率为97.3%。为便于工作人员后续使用,形成了cs 形式的客户端,其流程界面如图6所示。
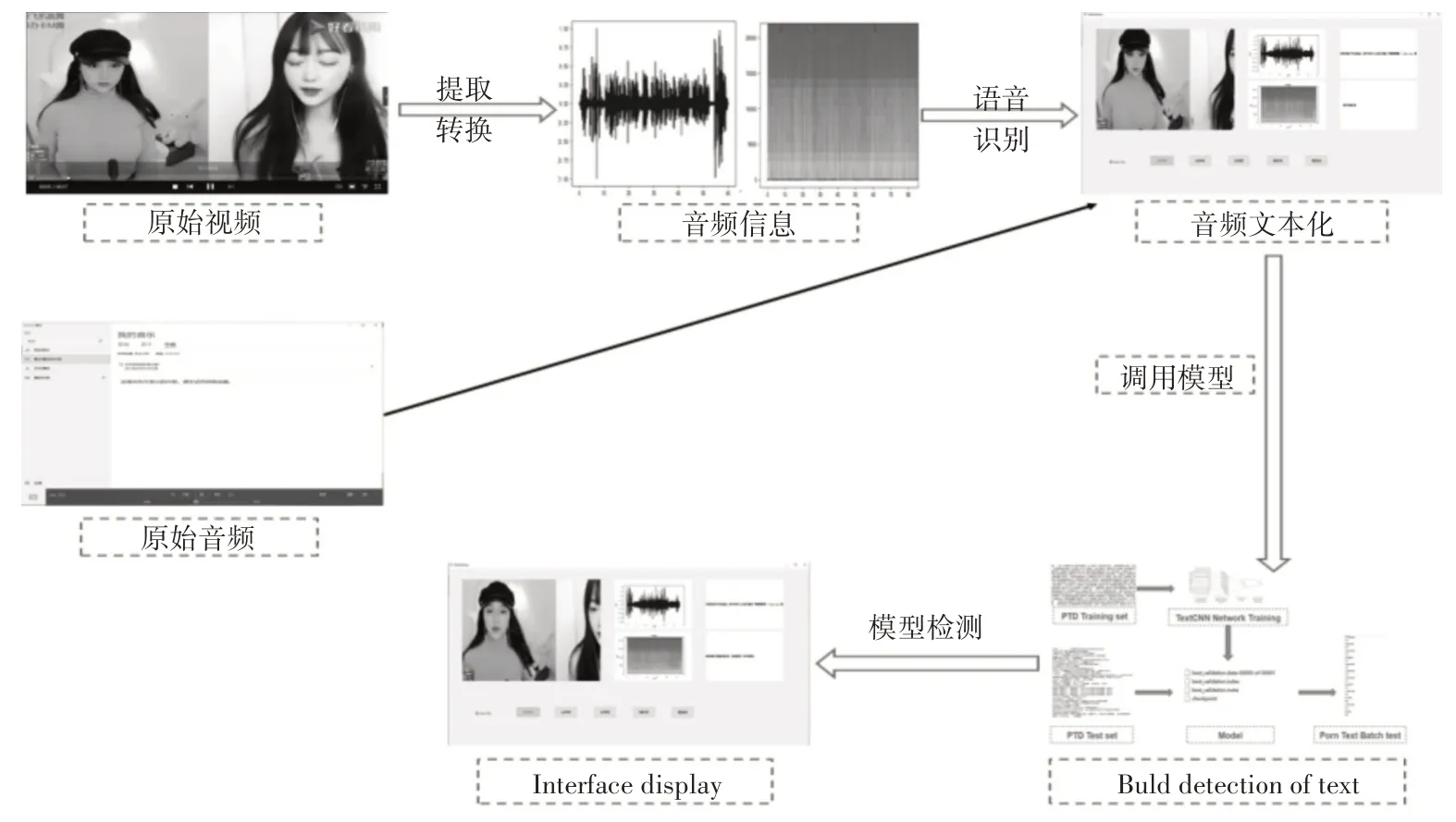
图6 cs客户端系统流程图
4 结语
本文通过收集分析色情音频以及文字小说,整理形成了色情音频、文本数据集,结合语音识别与文本分类等技术提出了CA-PAD算法,验证了数据集的合理性,实现了基于内容的面向网络色情音视频智能监管的系统设计实现。在多种文本分类经典模型算法的基础上进行有效融合,使之更加适用于网络环境中的音视频监管,保证青少年的浏览信息安全健康以及平台工作的顺利开展,以及充分考虑音频其他特征。将成为下一步的主要研究工作,且在实验训练过程中,随着训练集的扩充,模型各项指标均有提高的趋势,因此如何利用数据增强等算法扩充数据集也是下一步的主要研究工作。
