基于Python 的聚焦网络爬虫的设计与实现
2023-08-02唐文军隆承志
唐文军 隆承志
(1.华南理工大学信息网络工程研究中心 广州 510640)
(2.华南理工大学计算机科学与工程学院 广州 510640)
1 引言
在信息化、全球化的今天,电子政务极大地优化政府的组织结构、业务流程以及工作方式[1]。其中,电子政务以门户网站为窗口,向社会公众透明地开放政府的政务信息和政务服务[2]。门户网站将各种应用系统、信息集成在一起,具有网页结构复杂、内容形式多样、以主题进行内容归类的特征[3~4]。随着时间的推移,门户网站中相同主题下的信息量不断累积,给公众快速准确地检索信息带来困难。
聚焦网络爬虫是基于预先定义的主题进行网络爬取的程序或者脚本[5~6]。相对于通用爬虫,聚焦网络爬虫具有爬取目标明确,爬取速度快、爬取内容精度高等优势,非常适合门户网站主题信息的搜索[7]。爬虫程序的实现一般采用脚本语言,Python 语言具有语法简单、可读性强等特征,因而常被用于编写脚本[8~9]。本文基于Python 语言的爬虫技术,以门户网站主题信息的检索为研究对象,设计和实现一个通用的聚焦网络爬虫,快速、精准地检索门户网站内的主题信息。
2 Python网络爬虫技术
Python 语言是一种跨平台的解释型语言,拥有丰富的本地库和第三方库支持网络爬虫的实现,其中包括Urllib、Request、re、Beautiful soup 等优秀的库[10~12],根据库提供的功能可以分成三类。
2.1 网页爬取库
Urllib 库是Python 语言内置的库[13],主要由url请求模块、url 解析模块、异常处理模块以及Robots协议解析模块组成。其中,urllib.request 通过模拟浏览器向网页发送请求,等待网页的应答,并获取网页返回的数据(比如:html、xml 格式文件);urllib.parse 则负责解析请求网页返回的数据,提取其中有用的数据;urllib.error 处理网页请求过程中出现的网络故障。
Request库是基于Urllib库的第三方库[14],支持get、post、put、delete、head、options 等6 种请求方法,其中,需要设置请求函数的headers 参数模拟浏览器发送网页请求。request.exception 捕捉网络通讯过程中可能发生的所有网络故障信息,从而增强爬虫的健壮性;Request 库除了兼容Urllib 库支持的html5.0、html、xml 格式的数据解析之外,request.json实现对json格式的数据解析。因此,相对Urllib库,Request库更具有易用性、可理解性和程序的健壮性。
2.2 网页解析库
Beautiful soup 是网页解析的一个比较优秀的Python 第三方库[15~16],支持不同的文件解析器。Beautiful soup库将html文件和xml文件转换成树型结构,树的每一个树枝节点是一个对象,分类为tag对象、string 对象、Beautiful soup 对象和comment 对象。其中tag 对象是html 里的标签,通过浏览器内嵌的开发工具获取标签在html内的爬取路径,以爬取路径为参数创建selecter对象并爬取网页文件内的tag 对象,tag 对象包括了该标签的所有属性,比如:标签的名称、标签值等,其中标签值是需要被提取的数据。
2.3 数据处理库
正则表达式(Regular Expression,RE)是处理文本匹配的常用库[17~18]。正则表达式的组成部分包括普通字符、通用字符、非打印字符,基于逻辑组合可以表达复杂的正则语义。通常情况下,网络爬虫爬取的数据需要进行数据去噪处理,正则表达式通过组合有规律的字符串对爬取的原始数据进行匹配、替换、提取等数据清洗操作,从而提取有用的数据。由于正则表达式的代码执行效率高,以及灵活的正则语义表达,RE是数据处理的关键技术。
3 聚焦网络爬虫的设计
互联网是由相互链接的网站和网页组成,网络爬虫的爬取策略决定着爬取数据的流程。聚焦网络爬虫的爬取数据明确、爬取网页范围小,因此常采用广度优先爬取策略。广度优先爬取策略是从一个种子页面出发,在种子网页发现第一层的网络链接,先从第一层的网页链表开始,爬遍第一层的所有网页链接,然后再沿着网络向前爬取下一层的网页链接,网页爬取顺序为:O->A->B->C->D->E->F,如图1所示。
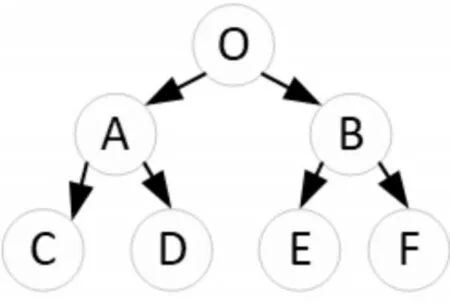
图1 广度爬行策略
3.1 爬取数据流程
网络爬虫涉及爬取的数据和网页,在明确数据内容和网页范围后,首先要分析网页的文件格式(比如:html5.0 文件、html 文件、xml 文件、json 文件)、数据在网页内的组织结构和表达形式,然后确定数据的爬取方式和爬取路径。基于广度爬行策略的聚焦网络爬虫的爬取数据流程如下。
设置入口的种子页面Url 以及数据爬取规则,网页爬取器向种子网页发送请求并等待网页返回处理后的数据文件;网页解析器则解析返回的网页文件,根据标签对象的搜索路径提取数据;数据处理器将提取的数据进行去噪处理,如果获得下一层网络链接Pageurl,则将Pageurl传递给网页爬取器;网页爬取器继续对下一层网络进行数据爬取,如此循序地进行网页爬取,直到满足停止爬取的条件才终止网页爬取。爬取数据流程图如图2所示。
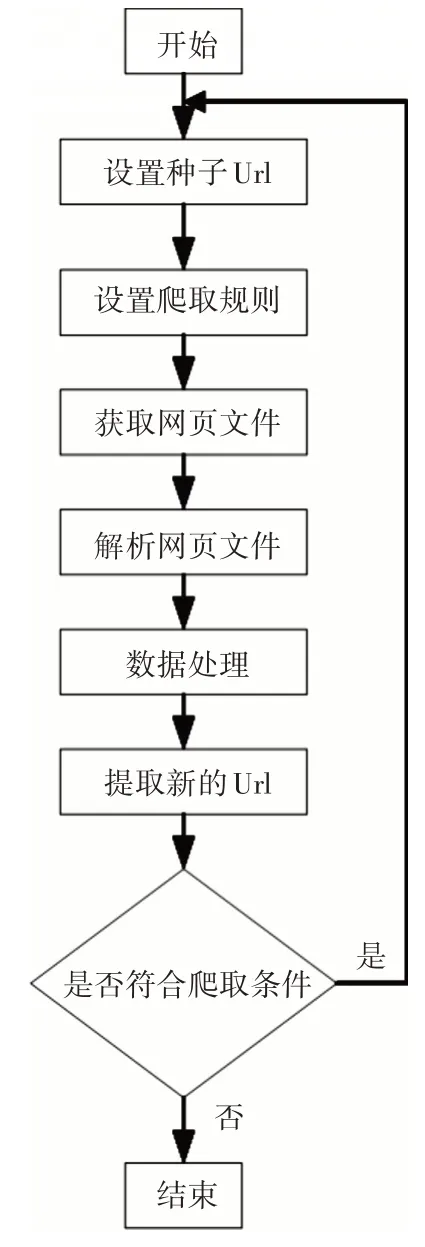
图2 爬取数据流程图
3.2 爬虫的结构模型
聚焦网络爬虫按照预定的主题爬取特定网页的数据,解析网页数据并进行清洗处理,最终将提取的有用信息存储在本地文件或者数据库内。结合上述的爬取数据流程图,爬虫主要由调度器、网页爬取器、网页解析器、数据处理器以及数据存储器组成[19~20],结构模型图如图3所示。

图3 爬虫结构模型图
1)调度器。包含main 函数的模块。首先,调度器初始化网页爬取器的种子页面Url以及网页爬取规则,然后启动网页爬取器。
2)网页爬取器。该模块管理爬取网页Url 列表,遍历列表内的每一个网页Url元素,将数据爬取规则转换成网页Url 后的请求参数;然后,利用Request 库向网页发送请求,等待网页的响应并获取返回的网页文件。
3)网页解析器。模块调用Beautiful soup 库和各类型的文件解析器实现,首先设置Beautifulsoup构造函数的两个参数,即网页爬取器获取的网页数据文件和该网页文件格式相应的文件解析器,然后创建一个Beautifulsoup对象soup,soup对象的select函数根据网页内数据的爬取路径提取相应数据。
4)数据处理器。网页解析器获取的网页数据往往不能满足数据的需求,数据内包含太多的无效数据,需要对数据进行清洗处理。模块采用re定义正则表达式匹配数据并进行字符替换,最后提取正确的数据。
5)数据存储器。数据处理器提取的数据需要存储到本地硬盘或数据库,以支持后期的数据检索和分析。数据存储包括文件存储和数据库存储两种方式,通过调用Python提供的相应库将内存里的数据转换成统一格式存储到本地文件(如:excel 文件)或数据库中(如:MySQL数据库)。
4 招标网站爬虫案例的实现
4.1 招标网站爬虫的需求
某省政府采购网是面向某省的招标采购信息平台。该平台提供信息发布门户,采购人在门户内发布采购意向、采购计划、采购需求以及采购公告等信息,供应商则通过门户检索该省内的采购需求,获得潜在的商业机会。某供应商的核心业务是为高等教育学校的信息化建设提供解决方案,销售部门访问门户内的“项目采购公告”栏目获取某省高校发布的信息化建设需求和计划。以该供应商的需求为案例,以某省政府采购网为爬取对象,爬取所有学校发布的信息化建设的招标信息。
4.2 招标网站数据分析
使用chrome 浏览器打开“项目采购公告”主页(https://gdgpo.czt.gd.gov.cn/cms-gd/site/guangdong/xmcggg/index.html),主页的布局分成两块,即信息检索条件输入块和公告信息列表的信息块,如图4所示。

图4 “项目采购公告”主页
启动chrome 浏览器内嵌的“开发者工具”,然后输入“公告类型”、“发布时间”、“验证码”等检索条件,点击“提交”按钮后,在network内发现输入的检索条件以“&key=value”的形式作为参数添加在网页url 后,浏览器向组合后的网页url 发送请求,网站接收浏览器的请求后将处理后的结果以json格式文件放回给客户端。json 文件内包含网络处理结果状态(status)、检索的公告记录总条数(total)、公告内容列表(data),其中公告内容包括公告标题(title)、公告详细内容网页链接url(pageurl)、公告发布时间(noticeTime)。点击公告的详细信息链接地址,服务器返回html 文件,右击页面内的公告信息,选择“检查”,进入浏览器的源代码调试窗口,获得该公告信息在html页面内的“selecter”的检索路径,比如:“公告标题”的selecter的检索路径是“#print-content-dzmc>p”。
4.3 招标网站爬虫的实现
如4.1节和4.2节所述,爬虫的数据主题是项目采购需求,爬取规则是{公告类型,发布时间}的组合条件,提取数据是高校信息化采购公告信息,最后数据需要保存在本地的excel 文件内。基于第2节提出的聚焦网络爬虫的架构,招标网站爬虫的实现由以下几个模块组成,如图5所示。
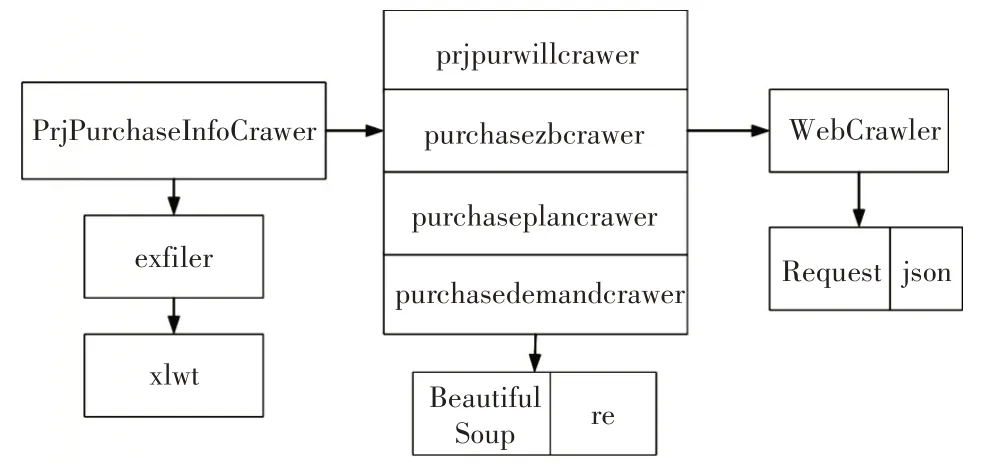
图5 招标网站爬虫模块
1)webcrawer 模块是网页爬取器,调用Request和json 库实现网页爬取功能。首先通过Request爬取“项目采购”首页并获取json格式的网页数据,然后采用json 库解析数据获取公告列表内所有公告信息(包括公告标题、详细网页url、公告发布时间),最后爬取公告详细网页,返回包含公告详细信息的html文件。
2)prjpurwillcrawer 模 块、purchasezbcrawer 模块、purchaseplancrawer 模块、purchasedemandcrawer模块分别实现“采购意向”、“采购招标”、“采购计划”、“采购需求”四类采购公告信息的数据解析和数据处理功能。首先调用Beautiful soup 解析webcrawer 返回的html 文件,根据“selecter”路径获取公告的详细信息,然后定义正则表达式匹配公告标题,匹配的逻辑规则是:{“学院”、“大学”、”学校”}&{“信息”、“软件”、“系统”、“硬件”},爬虫停止条件是爬遍所有满足检索条件的全部招标公告的详细信息网页。
3)exfiler 模块是数据存储模块,调Python 的第三方库xlwt,实现在本地文件系统内创建excel 文件,并往文件内写入数据。
4)PrjPurchaseInfoCrawer 模块 是 爬虫的 调 度器,定义main 入口函数,main 函数首先初始化数据爬取规则,然后分别调用prjpurwillcrawer、purchasezbcrawer、purchaseplancrawer、purchasedemandcrawer 四个模块爬取四类公告类型的招标信息;如果有数据返回,调用exfiler 模块以当前时间为文件后缀名在本地文件系统内生成excel 文件,最后将返回的数据以统一格式保存在相应的excel 文件中。
招标网站爬虫每天定时爬取高校信息化采购公告的相关信息,其中爬取的部分数据保存结果如图6所示。

图6 招标网爬虫的爬取数据
5 结语
聚焦网络爬虫能够快速、准确地爬取门户网站主题信息。本文采用Python 语言提供的本地库和第三方库,以模块化编程思想为指导,设计了一个通用的聚焦网络爬虫。以某省政府采购网为例,实现了一个招标网站爬虫系统,为聚焦爬虫系统的设计和实现提供了一个实现案例,下一步将增强爬虫组件的松耦合性和扩展性。
