基于传播特征的微博流行度预测算法研究*
2023-08-02胡俊睿邹海涛于化龙
胡俊睿 邹海涛 郑 尚 于化龙 高 尚
(江苏科技大学计算机学院 镇江 212003)
1 引言
随着近几年网络的发展,人们获得信息的渠道日益增多,其中新浪微博逐渐成为了人们浏览时事新闻、社交、娱乐的主要手段。微博中每天充斥着大量的信息,人们可以对微博进行点赞、回复、转发。转发数越高,说明这条微博越流行,它的热度越高,人们对它的关注度也更高,对于回复数来说同样如此。因此这种关注度就会形成大量的流量。在如今这个流量运营的社会,网民总是倾向于关注那些热度较高的话题,也就是所谓的微博热搜。这对于企业的营销手段和社会舆论导向来说有着很重要的价值和意义,如果一个企业能把握住热门话题所带来的流量而对企业进行宣传,将会产生巨大的经济效益。
在国外,有学者对Twitter 进行了数据挖掘研究,Mario Cataldi 等[1]使用一种基于时序的社会关系评价微博热点的检测方法;Swit Phuvipadawat等[2]对Twitter中具有一定冲击力的新闻进行研究,并且提出了针对这类新闻的检测方法,但这些方法只适用于Twitter。惠普实验室[3]指出中文微博与英文微博的差异较大,比如,总体上新浪微博的热门话题大都来自娱乐类,而Twitter主要来自新闻类[4~7]。
在国内,柏建普、田芳[8]利用语义分析热点微博话题,对其进行分类,但是对于用户行为却没有进行相关研究,仅仅限于博文本身;曹玖新等[9]对新浪微博的转发行为进行了深入地分析,谭荧、夏立新等[10]对带#的话题进行了流行度的离散型分析,通过对比几种常见的分类算法如朴素贝叶斯、决策树、支持向量机等在实验中的表现来分析每个算法在这种应用场景下的特点和优劣。解军、邢进生[11]从微观角度分析数据,他们使用切词器把每条微博转化成词序列,利用信息增益获得特征词,使用模糊集理论将转发的数量分为三类,最后用KNN 算法进行话题预测。由于KNN 算法的k值非常影响预测的效果,所以他们提出了改进的KNN算法以达到更好的效果。
上述方法能正确地区分微博的热度区间,但是这些研究都只是基于分类的方法,只能通过特征提取来对微博进行如“热门”、“流行”、“不流行”的这种流行度的大概范围区间分类,并没有给出一个具体的值,不太适用于热度这种量化的连续现象。在这个出发点下,徐美婷[12]提出利用主动学习的SVM方法;韩凤娟、肖春静、王欢等[13]利用多任务学习对微博流行度进行预测。
本文提出了传播加速度的概念,使用一种基于回归的算法将微博流行度预测数学化、公式化,通过筛选合适的变量,能较为准确地预测微博未来的流行度。
2 问题陈述
2.1 微博流行度定义版心说明
对于微博的传播来说,有诸多影响其传播的因素,由于隐私等各种问题,导致很多与用户本身相关的数据很难获取[14]。文中试图设计一种度量方式既可以把流行度量化,而且量化关系可以根据易得数据计算而来,同时该度量方法与微博的流行度应具有很高的相关性。
以微博转发为例,对于一条微博来说,越是被更多的用户浏览,且有足够的用户跟这条微博互动,即可证明该条微博越流行。假设对于每一条微博m,该微博的发布时间(submission time)为t0,ti为该条微博被第i次转发时的时间,由此可以用{t0,t1,…,ti,…,tfinal}表示该条微博随时间变化的转发过程,tfinal即为该条微博最后一次转发的时间。若用Tref表示参考时刻(reference moment),即微博m发布后到开始预测流行度的那个时刻,也就是说t0到Tref为预测流行度所需要观测的微博传播的时间长度,即参考时间(reference time);用Ttar表示目标时刻(target moment),从t0到ttar为微博m从发布到其流行度逐渐趋向平稳时所经历的时间,即目标时间(target time)。则
所以Tref-t0为参考时间的长度,Ttar-t0为目标时间的长度,为便于公式表达,本文把参考时间和目标时间的长度分别用Tref和Ttar的值来表示。
2.2 问题定义
若将微博m在t时刻的流行度表示为P̂(t),本文要解决的问题可定义为根据微博m从t0到Tref这段时间的传播过程{t0,t1,…,ti}的流行度变化特点,预测m在Ttar的传播变化,P̂(Ttar)则为Ttar时刻的流行度。其中ti表示在t0到Tref时间段内最后一次微博传播发生的时间。在本文中,微博传播可以看作是对微博的转发和对微博的回复。
3 基于传播特征的微博流行度预测模型设计
通过观察微博的传播规律,一条微博未来的流行度不仅与它初始的热度有关,还与它到未来时刻这段时间的传播特点有关。本文提出微博传播加速度的概念,通过计算t0到Tref内每个时间分片的体现微博影响力的相关因素,共同构成其传播加速度。
3.1 使用转发加速度的微博流行度预测模型定义
转发加速度可以通过微博转发数变化的快慢来获得。具体来说,若将微博m从时刻t0到Tref这段时间平均分为k个时间段,每个时间段的最后时刻对应的实际转发数为F1,F2,…,Fk,假设t0时刻的转发数F0=1,第k分段内的转发数变化表示为Fk-Fk-1,则微博m在第k个时间段的转发加速度表示为
为提高计算准确性,减小误差,本文选择各个时间片段加速度的加权平均数作为由t0到Tref的转发加速度,即:
在此基础上,微博流行度预测模型构建如式(3)所示,实验中该模型简称为FA(microblogging popularity prediction model using Forward Acceleration)。
对于一条微博来说,它未来的流行度不仅仅与转发数以及转发数的变化趋势有关,回复量也是一个衡量用户对于一条微博参与度的指标,回复量越多,说明用户对于该条微博有着足够的关注度,用户对于这样的微博也就会更倾向于转发。所以回复数与转发数也呈现出一个正相关。
3.2 使用回复加速度的微博流行度预测模型定义
一条发布的微博从t0到的回复数目变化(为回复数的参考时刻),其回复量加速度计算可以表示为
其中,Rk表示第k个时间分片的回复数,Rk-1表示第k-1个时间分片的回复数,Bk表示第k-1到第k时刻的回复数加速度。类似地,取各个时间分段Bk的加权平均数作为t0到T*ref这段时间的回复加速度,即:
那么,结合回复量加速度的微博流行度预测模型构建如式(6)所示,实验中该模型简称为RA(microblogging popularity prediction model using Reply Acceleration)。
3.3 基于传播特征的微博流行度预测模型定义
若微博流行度由其转发加速度和回复加速度共同决定,本文将两者首先进行线性组合,如式(7)所示:从上述公式可以看出,该传播加速度由两部分组成。由于微博流行度受其转发数影响更大(转发数目越多,说明传播的越广,潜在受影响的用户也越多;回复数越多说明其关注度更高,虽然对微博的流行度存在影响,但直接影响的用户数目仅为回复微博的用户,相较而言对于微博流行度的影响其权重要弱于转发数),本文对回复数加速度进行开三次方根处理,从公式定义和实验准确度上讲都更加合理。
因此,微博流行度预测模型表示如式(8)所示,实验中该模型简称为FA+RA(microblogging popularity prediction model combining Forward Acceleration and Reply Acceleration)。和
此外,粉丝数对于微博传播也存在影响,粉丝数越多,该条微博的曝光度就会越高,相应对于它的传播就有促进作用。并且微博博主的粉丝数存在数量级比较大的情况,考虑到这个因素对算法的影响,最终微博流行度模型构建如式(9)所示,实验中该模型简称为FA+RA+NF(microblogging popularity prediction model combining Forward Acceleration,Reply Acceleration,and Number of Followers)。
4 实验结果与讨论
4.1 数据集
本文的实验数据为2020 年4 月到7 月由爬虫抓取的部分微博数据,其中清理了转发和回复均为零的微博,最终得到微博31,159 条,微博回复1,009,552 条,转发1,314,910 条,涉及1,968 位微博用户,其具体数据分布如表1 所示。实验中将数据集分成训练集和测试集两部分,其中30%作为训练集,70%作为测试集。以FA 为基础算法,采用十折交叉法与文中设计的RA、FA+RA,以及FA+RA+NF进行对比和分析。
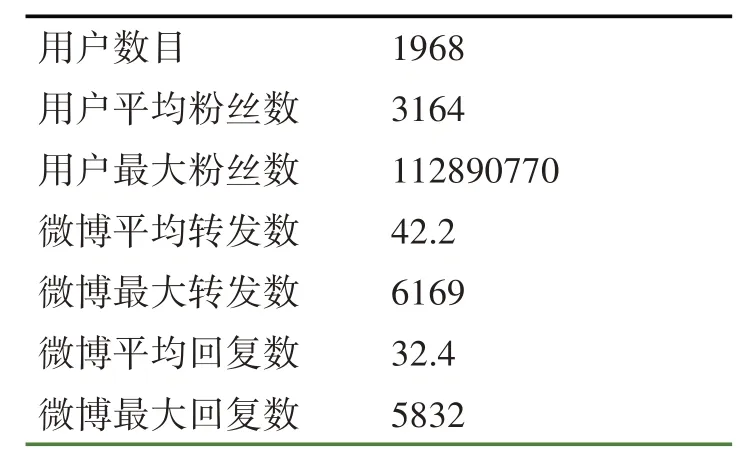
表1 数据分布
4.2 测试指标
1)平均百分比绝对误差(Mean Absolute Percentage Error,MAPE):该方法用于衡量目标预测值与实际值的相对误差,实际值为测试集中各条微博在目标时刻的真实转发数。MAPE值越小,误差也就越小,预测性能也就越好。反之误差越大,预测性能越差。具体计算如式(10)所示。
其中n为测试的微博消息数,S表示整个测试集。
2)准确度(Accuracy):用于衡量预测结果的准确度。实验中将测试结果离散地分为两类,一类是表示目标预测值与实际值相对误差值小于0.1的微博条目;另一类则是其相对误差值大于0.1 的微博条目,其计算方法如式(11)所示。
其中f[X]为指示函数,X是真时其值为1,否则为0。这一指标用于衡量目标预测值与实际值相对误差小于0.1的比例,准确度值越高,表明误差值小于0.1 的测试结果所占的比例越大,预测准确度也就越高。反之表明预测准确度越差。
4.3 参数选取

图1 回复参考时刻对MAPE的影响

图2 回复参考时刻对精确度的影响
然而参考时间设置过长,预测成本也会随之增加,并且效率也不高。通过观察实验结果发现,当从5 变为6 时,误差值还存在较大的减小,准确度也有较大的提升。当它的值从6 变为7 和8 时,准确度增加的幅度相对变小并且之后也趋于平稳,预测性能的提升变得很有限。所以为了尽可能使参考时间最短的情况下减小误差,本文设置,得到这段时间加速度的加权平均值,并将这个值作为该参考时刻的传播加速度。
2)Tref取值设置
类似地,由于FA、RA+FA、FA+RA+NF 模型均需考虑Tref的时间位置,以及时间分片数量k值的大小,为了节省篇幅,文中仅选取FA的实验结果进行展示,RA+FA、FA+RA+NF模型中也有同样的表现。实验结果如图3和图4所示。

图3 转发参考时刻对MAPE值的影响
从实验结果可以看出,与回复数的变化趋势类似,当参考时间增加时MAPE值与精确度值分别减小和增加。但当Tref=4 及以上时,精确度值虽有增加但是并不明显。因此本文设置Tref=4。
3)Tref对FA模型转发加速度的影响
对于转发数参考时间长短设置所引起的实验效果的不同,本文对微博转发数在参考时间长短不同的情况下统计了部分微博的转发加速度的变化情况(具有类似影响,本文不再赘述)。如图5所示。

图5 参考时刻的长短对传播加速度的影响
实验结果表明,当Tref=4 时,传播加速度最大,而随着Tref的增加,传播加速度逐渐减少并且趋于稳定。结合微博流行度变化的规律可以解释为:一条微博刚发布的几个小时热度最高,随着时间增加,用户的关注点也开始逐渐转移,如今是碎片信息爆炸的时代,用户的注意力随时间会被大量的不同信息所占据。随着时间的推移,用户会被其他更多的信息所吸引,所以该条微博的传播速度会逐渐变慢。本文的传播加速度求的是各个时间分片的加权平均值,后段的加速度变得很小导致整体加速度逐渐减小并且趋于稳定,直至微博转发或者回复不再增加。因此观测微博最有效率的方式就是考虑微博刚发布的前几个小时。
为了更详细地展示Tref选取的合理性,针对不同的Tref,本文将FA、RA、FA+RA 以及FA+RA+FN四个模型分别做实验进行对比。特别地,为了控制变量排除干扰,在模型RA、FA+RA 以及FA+RA+FN 中,得到它们在时的,然后设置不同的Tref进行实验。实验结果如图6 和图7 所示。

图6 参考时刻对MAPE的影响
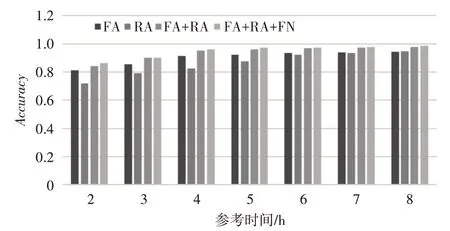
图7 参考时刻对精确度的影响
从实验结果可以看出,无论是何种模型,随着Tref的增加,预测效果都会有提升。整体来看,改进后的模型公式FA+RA和FA+RA+FN在任何参考时间下都要比原公式的预测效果好。
4.4 实验结果与讨论
通过以上的实验,确定了针对回复数和转发数最适宜的Tref和值。即Tref=4,。将上文四种模型的Tref和分别设置为4和6,进行四种模型的对比实验。其结果如图8和图9所示。
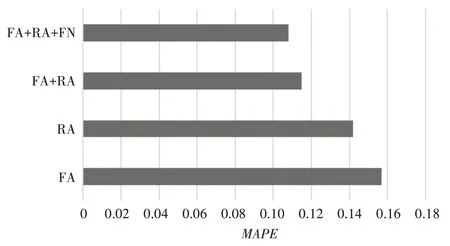
图8 不同模型预测的MAPE值对比
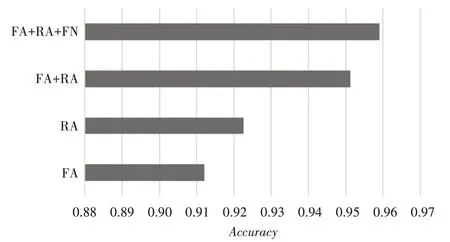
图9 不同模型预测的精确度值对比
从实验结果可以看出,在确定了Tref后,FA+RA 和FA+RA+FN 具有更好的预测效果,其中FA+RA+NF 模型表现最好,它相比于其他模型的MAPE值更低,误差更小,准确度的值更高。因为它对于参数的选取考虑更全面,因此有更好的预测效果,并且说明增加了回复数和粉丝数这两个变量能有效地减小误差提高预测的准确性,证明了微博回复数和微博粉丝数会影响微博的传播速度。RA比FA 模型从数据上看来具有稍好的表现,因为利用回复数加速度的时候基于它的传播特点采用了相对更长的参考时间,而且从侧面说明,用户的回复比转发更能代表其感兴趣的程度。此外,FA+RA+NF 相对于FA+RA 模型性能提升的效果不明显,说明粉丝数变量对于模型性能的提升空间不大。
5 结语
本文通过对微博传播特征的分析和归纳,提出了一个结合转发加速度、回复加速度、以及用户粉丝数的微博流行度预测模型。实验中分析了在不同的参考时间下微博的转发数和回复数在模型上的不同表现,在考虑实验成本和预测性能的平衡性的前提下,得到了二者最适宜的参考时间长度。
微博的传播往往还受其他很多因素影响,计划在以后的工作里进一步分析影响微博传播规律的其他因素,比如微博营销号、网络水军对微博实际真实流行度所带来的干扰,以及微博本身的种类对用户关注度的影响等,建立更加完善的模型以进一步提升实用性。
