基于采样隐马尔可夫模型的移动机器人路径规划
2023-08-02白晓兰张振朋周文全任鹏博张炳贵
白晓兰,张振朋,周文全,袁 铮,任鹏博,张炳贵
(沈阳化工大学机械与动力工程学院,沈阳 110142)
0 引言
在移动机器人研究领域,路径规划是大多数移动机器人任务所应具备的基本但至关重要的能力。在过去,人们对它进行了广泛的探索,并提出了各种各样的解决方案[1],如A*算法[2-4]、人工势场法[5]、神经网络算法[6]、遗传算法[7-9]、粒子群优化算法[10]等。这些方法在移动机器人路径规划中取得较好的效果,但面对复杂环境时依然存在一定的缺陷。
隐马尔可夫模型(hidden markov model,HMM)[11]作为一种用参数表示,用于描述随机过程统计特性的概率模型,以其十分健壮的数学结构和强大的模式分类能力成为模式识别中的重要方法被广大研究人员广泛地使用和研究[12]。但是HMM在路径规划中的应用目前研究较少,邓旭等[13]针对复杂迷宫环境的目标体具体位置与路径规划问题为对象,提出了一种基于隐马尔可夫模型的粒子滤波算法。该方法通过隐马尔可夫模型的概率计算,推理出目标体可能范围,通过A*算法将目标捕获。仿真结果表明,与普通的概率计算目标体位置,粒子滤波算法计算的目标体位置,大大减少了总步数,形成了最短路径。王社伟等[14]用马尔可夫模型对无人机路径规划问题建模,提出了离散的马尔可夫模型线性化的方法,并利用数学归纳法进行了证明。仿真结果表明,对状态流程图进行线性化以后,由初始状态到终止状态的每条路径的状态转移概率变得更加直观,能够从状态流程图中清楚地得到各个因素对整个系统任务的影响。岳师光等[15]针对标准模型在对手更改终点目标和自上而下规划时无法识别的问题,提出了一种顶层策略可变的抽象隐马尔可夫模型。为模型的顶层策略增加初始分布和策略终止变量,更改了策略终止变量间的依赖关系,使下层策略能被强制终止。给出了改进后DBN结构,并通过推导条件概率更新和RB变量抽样流程实现了模型的近似推理。仿真实验表明,改进模型能准确识别给定环境下的各类典型航迹,不仅在终点目标不变时能较好地维持标准模型的识别准确率,在提供足够的观测数据后还能很好地解决变目标识别问题。
以上基于HMM的规划算法在不同程度上提高了算法规划的性能,但没有充分利用HMM的预测和学习能力。为了提高规划路径的平滑性、安全性,使算法能够在大量学习训练后能躲避行人。本文提出了一种基于SHMM的移动机器人路径规划方法,该方法基于SHMM建立移动机器人运动模型;用K-means聚类对不同复杂程度的环境分类进行初始信息素的分配,以避免蚁群算法前期收敛慢,后期陷入停滞的问题;融合SHMM因子、K-means因子和转角因子改进蚁群算法,实验仿真结果验证了所提方法的可行性。
1 基于采样隐马尔可夫运动模型的建立
1.1 隐马尔可夫模型
隐马尔可夫模型是一种将系统表示为有向图形模型的统计模型[11]。HMM由N个系统状态S=s1,s2,…,sN,M个观测信号V=v1,v2,…,vM和状态转移矩阵A、观测概率矩阵B、以及初始状态概率向量π构成。状态转移概率分布A=aij,如式(1)所示:
aij=P(qt+1=s(j)|qt=s(i)),(1≤i≤N,1≤j≤N)
(1)
此外,状态j,B=bij的观测概率公式如下:
bij=P(v(i)|s(j)),(1≤i≤M,1≤j≤N)
(2)
最后,初始状态分布π=πi定义为:
πi=P(q1=s(j)),(1≤i≤N)
(3)
因此一个隐马尔可夫模型通常简记为λ=(π,A,B)。
隐马尔可夫有两个假设:
(1)观测独立假设:在t时输出观测值的概率只取决于当前时刻t所处的状态而与以前的状态无关。
(2)马尔可夫性假设:在t时刻的状态向t+1时刻的状态转移的状态转移概率仅仅与t时刻的状态有关而与以往任何时刻的状态无关。
1.2 机器人轨迹预测模型建立
在二维(2D)环境中,轨迹可以描述为一系列具有航向θ和线速度vl的x-y位置。本文考虑将2D空间分割成规则网格,其中可以在每个网格单元中计算运动的发生。将网格扩展到包括所有4个维度,即x、y、θ和vl,将产生所谓的流场或运动直方图。可以对直方图中的值进行归一化,以获得概率,从而得到网格的联合概率分布表示为:
P(x,y,θ,vl)
(4)
式中:联合概率分布P表示x-y-θ和vl同时出现的概率,该概率模型是建立在环境中独立于时间的一种新的运动模式上。
该模型的变量分布复杂,需要采集大量数据并且计算量大。本文用一种概率方法来建立式(4)的估计,考虑到机器人是一个具有有限视野的移动观察者。建立时间t内的信念Dt(式(4)的近似值)如式(5)所示:
Bel(Dt)=P(Dt|ξt,ζt,Zt,…,ξ0,ζ0,Z0)
(5)
式中:ξt为t时间观察所有移动的人,ζt为t时间机器人的姿态,Zt为t时间所有传感器的输出。
根据上述方程,可以使用贝叶斯定理推导出增量更新规则如式(6)所示。
(6)
式中:η为一个常数。由于Bel(Dt)是时间t时的信念,它考虑到所有过去的观测、传感器读数和观察者姿势,数据量大需要进一步简化。假设当前的观测和姿态在条件上独立于过去的观测和姿态,即系统是满足马尔可夫性质的。
(7)
式中:最后一项是t-1时刻的信念,因此最终的更新规则为式(8)所示:
Bel(Dt)=ηP(ξt|Dt,ζt,Zt)Bel(Dt-1)
(8)
综上所述,通过对影响机器人运动轨迹的因素分析,本文选择用隐马尔可夫模型来解决机器人运动轨迹预测问题。以机器人观测到的移动的人的轨迹作为可观测变量,机器人轨迹作为隐状态。
1.3 采样隐马尔可夫运动模型
虽然基于网格的方法是Bel(Dt)信念的一种可能表示形式,但这种方法有许多缺点。首先,机器人的观察的视野大,只要置信度被更新,就需要更新整个环境网格,这会导致高计算成本,并且实现过程低效;此外,由于不知道运动环境的内部结构,建立运动模式的网格甚至需要对不可能运动的区域(例如墙的内壁)也要生成环境置信度;最后,需要保证选择网格的分辨率,但即使如此,也很难保证得到良好的近似结果。
考虑到基于网格的方法以上缺点,提出了一种采样的方法来表示建立的隐马尔可夫机器人轨迹算法。该算法可以预测、加权和采样,从而逐步学习式(4)的近似值。基于样本的表示方法克服了基于网格的方法的问题,只在感兴趣的区域生成样本,即观察到运动的区域,并且可以通过降采样来控制样本的数量。
式(5)中定义的置信度Bel(Dt)可以表示为一组加权样本:
(9)

(10)
综上所述,机器人的轨迹预测概率可以用观测到行人的轨迹样本来统计计算,其中追踪人的轨迹使用粒子滤波器。假设某一粒子位置为X=[x,y,θ,v]T,粒子的更新规则如式(11)所示。
Xt+1=Xt+R*μt+rand
(11)
式中:rand为(0,1)随机数,状态矩阵R和μ为观测状态的元素,表达式为:
(12)
R=
(13)
式中:μ(i)和R(i)为第i个样本簇的平均值和协方差,N为状态数。
SHMM运动模型在预测行人轨迹之前,需要大量行人数据进行学习和训练,为了减少数据训练量,降低处理数据和计算数据的成本,需要对相邻运动状态进行处理。为了在降采样的同时保证数据的完整性,本文利用KLD散度来对新的状态下的轨迹做近似的估计。KL散度又被称为相对熵或者信息散度[16],是两个概率分布间差异的非对称性度量。在信息论中,相对熵等价于两个概率分布的信息熵的差值,若其中一个概率分布为真实分布,另一个为理论(拟合)分布,则此时相对熵等于交叉熵与真实分布的信息熵之差,表示使用理论分布拟合真实分布时产生的信息损耗。如式(14)所示,s*表示新的状态或者向运动模式模型中已经存在的状态添加新的信息。
(14)
式中:1≤i≤N,1≤j≤K,K为轨迹的路径数。该方程的第一项和第二项计算为:
(15)
(16)
如果状态s(i)和集群s*之间的KLD低于一定的阈值,则可以对样本集群进行组合,并相应地更新状态统计数据。该阈值可以根据连续状态之间的期望距离来计算,也可以通过实验选择一个固定的阈值。为了避免不断增长的模型增加计算工作量,KLD只计算位于状态空间中的集群。
基于上述推导,用MATLAB软件验证基于SHMM建立的机器人运动模型预测轨迹的有效性。对行人轨迹追踪仿真如图1和图2所示,初始化参数如表1所示。图1a假设一个人在10×10环境行走,深灰色是行人轨迹起点,浅灰色是行人轨迹终点,将产生黑线的轨迹。如图1b所示,机器人用粒子滤波的跟踪器产生一系列观察到的轨迹姿态。

表1 粒子追踪初始化参数
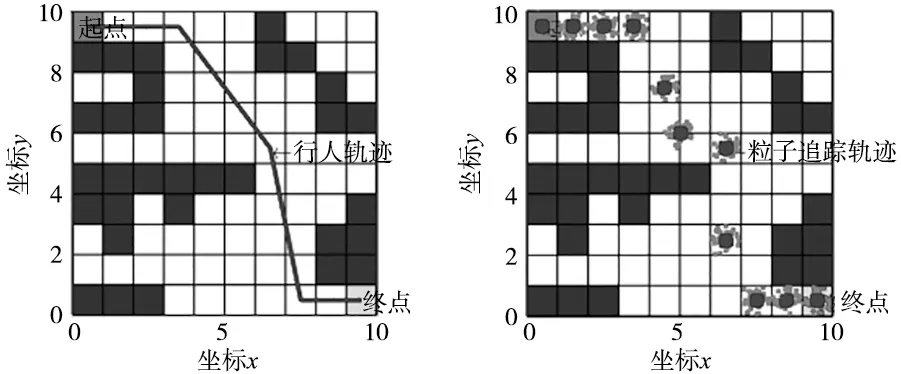
(a) 10×10环境模型下行人轨迹图 (b) 10×10环境模型下粒子追踪图图1 10×10环境模型下粒子追踪图

(a) 20×20环境模型下行人轨迹图 (b) 20×20环境模型下粒子追踪图图2 20×20环境模型下粒子追踪图
深灰色是50个粒子组成的粒子云,它们的更新规则为式(11),中间的黑点*为轨迹追踪收敛点。粒子将原来8.66 m的行人轨迹以11个姿态点表示,相邻姿态点的更新规则为式(14)。图2a是20×20环境下行人从两个不同起点到同一终点的多条行人轨迹图,用100个粒子的点云去追踪。由图2b可知,长度为16.37 mm的行人轨迹1以15个姿态点表示,长度为14.17 mm的行人轨迹2以12个姿态点表示,验证了复杂化境下多条行人轨迹追踪预测的有效性。
以上仿真验证粒子可以把这些轨迹以一组姿态样本来表示,它近似机器人在网格中x、y、θ和vl的联合概率分布,并且状态之间的转换是可以直接观察到的。在环境拥挤的区域粒子聚集更加密集,相邻姿态样本的KLD散度更小。
2 改进蚁群算法
2.1 基于K-means聚类的初始化信息素
蚁群算法的工作原理Ant System(蚂蚁系统)是一种智能仿生优化算法[17]。在寻路的过程中蚂蚁会分泌信息素,信息素分泌的多少与路径长度成反比,距离越小则当前点到该可行点被分配的信息素就越多,而蚂蚁在选择路径时会根据状态转移概率以较大概率选择信息素大的路径,信息素也会随之更新。随着大量蚂蚁个体不断搜索,最优路径上的信息素越来越多,最终整个蚁群会找出一条最优路径。
基本蚁群算法将地图所有可行栅格的初始信息素设为一个常数,蚂蚁在迭代初期主要依靠启发函数,不仅搜索盲目,还容易陷入地图死点。为了解决这个问题,在建立栅格地图后,根据地图复杂度对地图环境进行K-means聚类,按聚类结果分配初始信息素。K-means聚类是一种无监督学习的方法[18],是许多领域中常用的统计数据分析技术。它的基本思想是通过迭代寻找k个簇(cluster),使得聚类结果对应的损失函数最小。本文损失函数定义为各个可行点到起点与终点连接线之间距离差平方和:
(17)
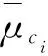
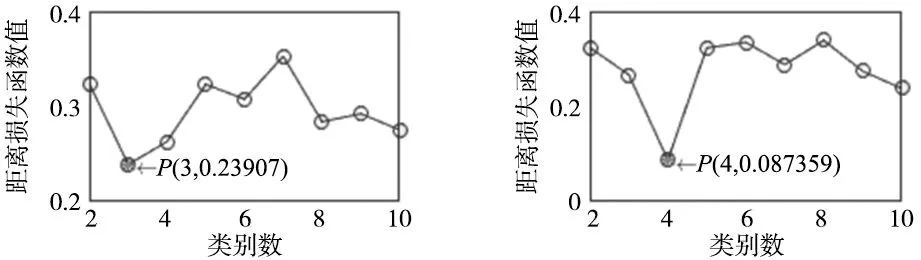
图3是4种不同障碍物占比K-means聚类结果,先对栅格地图统计其障碍物占比,然后利用式(17)进行聚类。图3a是障碍物比例0.1时地图聚类结果折线图,类别数为3时损失函数最小为0.239 07;图3b是障碍物比例0.3时地图聚类结果折线图,类别数为4时损失函数最小为0.087 359;图3c是障碍物比例0.5时地图聚类结果折线图,类别数为6时损失函数最小为0.222 58;图3d是障碍物比例0.8时地图聚类结果折线图,类别数为9时损失函数最小为0.048 33。
(a) 障碍物比例0.1聚类结果分析 (b) 障碍物比例0.3聚类结果分析

(c) 障碍物比例0.5聚类结果分析 (d) 障碍物比例0.8聚类结果分析图3 4种障碍物比例下聚类结果
根据式(17)的损失函数设计初始化信息素函数的如式(18)所示,改进后的信息素在距离起点和目标点连线欧氏距离远的区域含量低,在距离近的区域含量高,可以兼顾广义搜索和局部快速收敛。
(18)
式中:τ(i,j)为节点i到j的初始信息素,C为信息素常量,J为损失函数,G为地图大小。
2.2 融合SHMM因子的状态转移函数
传统蚁群算法状态转移函数由信息素函数和启发函数决定的,这两个函数主要受局部或全局路径长度控制,所以距离信息对状态转移概率的影响很大。当遇到U形环境时可能会出现死锁,在寻路时也容易出现自锁和寻得路径为次优路径的问题。为解决这些问题,另外增加轨迹预测的功能。本文对状态转移函数[17]融合第2.1节聚类类别信息和SHMM预测轨迹概率信念,改进如下:
(19)

传统信息素函数在环境复杂时,初期不能快速收敛。在多次迭代后,由于路径上信息素布趋于平稳,造成蚂蚁的路径选择趋于单一,容易造成蚁群陷入局部最优,阻碍蚁群进一步搜索到潜在的最优路径。为了解决蚁群早期不能快速收敛,后期容易陷入停滞现象的问题,加入栅格环境聚类的因子,如式(20)所示。当k=1时,初始信息素分布按式(18);当k>1时,若i到j的损失函数增加,信息素比重增加,反之减少;当i到j为同一类栅格,不会按照聚类信息更新。
(20)
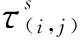
为了快速搜索到最优路径,使得机器人转角损耗最小并且能够预测轨迹,改进后的启发函数由距离因子、转角因子和SHMM预测因子组成。
(21)
式中:d(i,j,G)为距离因子,θ(i,j,G)为角度因子,D(i,j)为SHMM轨迹预测,β1、β2、β3为权重。
为了更快地获得最短路径,距离因子增加聚类损失函数和待选节点j与目标终点G之间的欧式距离,设计函数如下:
(22)
式中:Ji为i节点的损失函数,Jj为j节点的损失函数,d(i,j)为当前点i和可行点之间的欧氏距离,d(i,G)为可行点j和目标点G之间的欧氏距离。
为了降低机器人运行时的转弯损耗,角度因子设计如下:
(23)
由第1节理论和仿真可知,SHMM能很好地预测轨迹,本文加入节点i和j的D信念D(i,j)来增加路径规划时的轨迹预测功能,规划路径在遇到行人时能实时进行处理,路径规划更加合理、安全,D(i,j)的更新公式为:
(24)
3 路径规划仿真验证
本文假设已经利用SHMM机器人运动模型进行了大量的各种环境行人轨迹追踪的训练。为验证本文基于SHMM运动模型的蚁群算法(sampled hidden markov model-ant colony optimization,SHMM-ACO)的可行性和有效性,针对不同的环境进行了大量仿真实验,并与传统蚁群算法(ant colony optimization,ACO)、其他改进蚁群算法[19]得到的最优路径进行比较。其中SHMM-ACO的流程图如图4所示,参数初始化设置如表2所示。仿真环境为Windows11 64 bit,处理器Intel(R) Core(TM) i7-6300HQ,CPU频率2.30 GHz,内存16 GB; MATLAB R2016b。

表2 改进SHMM蚁群算法的参数设置

图4 SHMM蚁群算法的具体实现流程
3.1 10×10简单环境仿真对比和分析
利用K-means对10×10栅格环境进行聚类预处理,图5a为初始栅格,设起始点S为序号为1的可行栅格,标记为红色;目标点G为序号100的可行栅格,标记为绿色,障碍物栅格标记为黑色参数,可行栅格为白色。障碍物占比27%。由3.1可知,将可行栅格分为4类利用式(17)进行类聚类,图5b是聚类的栅格图,图中按到起点和目标点连线的欧式距离从小到达的类别分别是4,1,2,3。类别4占比6%,类别1占比37%,类别2占比为占比19%,类别3占比为占比9%。然后对3个类别用式(18)进行初始化信息素。图5c为聚类的轮廓图,可以对聚类效果进行度量,横坐标为轮廓量(Silhouette ),纵坐标为类别(Cluster)。由图可知,类别4的Silhouette最接近1表明类别更倾向于属于当前类,数据比较集中稳定;类别1的Silhouette最接近0表明类别更倾向于其他某一类,数据比较离散。

(a) 10×10初始栅格环境 (b) 10×10栅格环境K-mean聚类 (c) 10×10栅格环境轮廓图图5 SHMM蚁群算法10×10栅格环境聚类
图6为10×10栅格环境最优路径对比,粒子追踪参数为表1数据,其他参数条件都相同的情况下得到的结果。由图6a可知,在相同的迭代次数下ACO最优路径长度为15.414,转弯次数6次;其他改进ACO的最优路径长度14.312,转弯7次;SHMM-ACO最优路径长度12.484,转弯次数2次。分析可知ACO和其他改进ACO规划的最优路径长度长、转弯多,不利于移动机器人的移动。而本文改进的SHMM-ACO比ACO和其他改进ACO规划的最优路径短19.33%、12.77%,转弯次数少66.66%、71.42%,能大大减少机器人移动和转弯的能耗。

(a) 10×10栅格环境最优路径对比 (b) 10×10栅格环境目标点更换路径对比图6 10×10栅格环境最优路径对比
为了验证SHMM-ACO的学习能力,图6b为临时更换目标点3种算法最优路径对比。ACO和其中其他改进ACO由于没有学习能力,会出现局部路径冗余现象,路径冗余量分别为131.48%、27.34%;SHMM-ACO具有学习能力,对于临时更换目标点问题适应更好,未出现路径冗余现象。另外ACO、其他改进ACO和SHMM-ACO平均50次算法运行时间为0.294 s、0.243 s、0.208 s,SHMM-ACO算法速度更快,验证算法的时间高效性。
图7为10×10栅格环境在迭代次数为50次时50只蚂蚁3种算法最短路径和平均路径收敛曲线,由图7a可知,ACO最短路径在迭代10次后开始收敛,收敛时最短路径为18;其他改进ACO和SHMM-ACO虽然都是在迭代1次后就开始收敛,但收敛时其他改进ACO最短路径为14,SHMM-ACO最短路径为12;SHMM-ACO规划的收敛路径长度更短。由图7b可知,ACO平均路径在迭代30次后才开始有收敛趋势,30次以后还有波动;其他改进ACO在迭代6次后开始收敛趋势,但收敛后还是个别异常值,算法不够稳定;SHMM-ACO在迭代3次后开始收敛,3次以后收敛曲线平稳,且收敛后的平均路径长度比ACO、其他改进ACO短40.33%、20.22%。验证了简单环境下SHMM-ACO在规划最短路径的有效性。
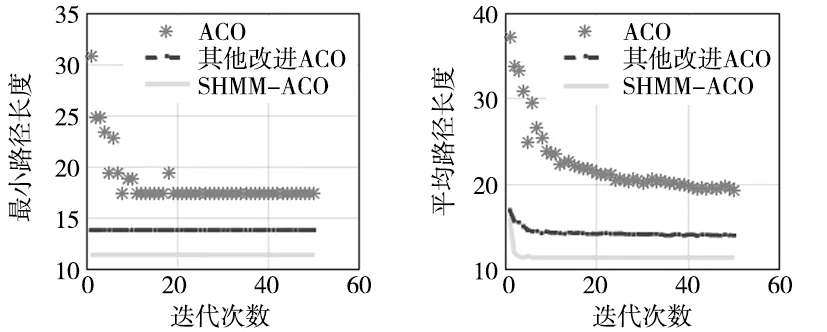
(a) 各算法最小路径长度对比 (b) 各算法平均路径长度对比图7 最短路径和平均路径对比
3.2 20×20复杂环境仿真对比和分析
图8为20×20栅格带U型障碍复杂环境最优路径对比,K-means将可行栅格分为6类。由图8可知在相同的迭代次数下ACO最优路径长度为38,转弯次数12次;其他改进ACO的最优路径长度32.968,转弯15次;SHMM-ACO最优路优路径长度30.312,转弯次数6次。由式(20)和图8仿真可知,ACO更倾向选择水平和垂直方向的节点,容易选择局部最优路径。其他改进ACO只考虑路径最短,未考虑转弯次数,比ACO虽然路径长度短了13.24%,但转弯次数却多25%。而本文改进的SHMM-ACO比ACO和其他改进ACO规划的最优路径短20.17%、8.05%,转弯次数少50.00%、60%,在考虑路径最短的同时兼顾转弯次数,规划的全局路径更加平滑,寻路的效果更优。与第3.1节简单环境对比,HMM-ACO各项对比百分比都在提高,证明了越是复杂的环境,本文HMM-ACO规划路径长度越短,转角越小,路径越平滑。
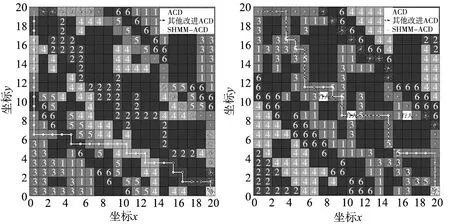
图8 20×20栅格带U型障碍复杂环境最优路径对比 图9 20×20栅格带U型障碍复杂环境躲避行人对比
为了验证SHMM-ACO对行人轨迹的预测能力,在20×20栅格带U型障碍复杂环境进行了躲避行人的仿真。如图9所示,浅灰色实线是ACO规划的最优路径,在22节点出突然出现行人,规划的路径会经过22节点,可能会使得机器人与行人发生碰撞,造成不安全问题。黑色虚线是其他改进ACO规划的最优路径,当移动机器人行进到11和14节点时突然出现行人,由于转移概率中没有行人轨迹预测的信息,机器人没法紧急躲避行人,可能会与行人发生碰撞,因此规划路径对应动态行人也是不安全路径。灰色*为基于SHMM轨迹预测的收敛路径点,在移动机器人行进13节点时突然出现行人,SHMM-ACO预测到行人轨迹,能够实时躲避行人,验证了SHMM-ACO具有躲避行人的能力,规划的路径更加安全。
图10为20×20栅格带U型障碍复杂环境中各算法最短路径和平均路径收敛曲线对比。由图可知,ACO在复杂环境下出现蚂蚁死锁现象,即陷入U型障碍无法出来,这大大影响蚂蚁种群的质量和路径搜索的效率。而其他改进ACO和SHMM-ACO采用了回退策略,即当蚂蚁无路径搜索时释放禁忌表,回退一步。未出现蚂蚁死锁的现象,但SHMM-ACO最短路径收敛速度和平均路径收敛速度比其他改进ACO快50%、55%。验证了SHMM-ACO在带U型障碍复杂环境更具优势,能够减少蚂蚁死锁现象,搜索效率更高,算法时间更短。
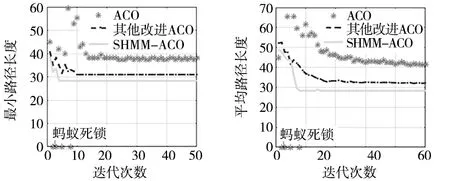
(a) 各算法最短路径收敛对比 (b) 各算法平均路径收敛对比图10 最短路径收敛曲线和平均路径收敛曲线
图11为20×20栅格带U型障碍复杂环境中存活蚂蚁数量和路径长度方差对比,其中ACO的蚂蚁在前10次迭代都几乎全部死锁,死亡蚂蚁数量较多。
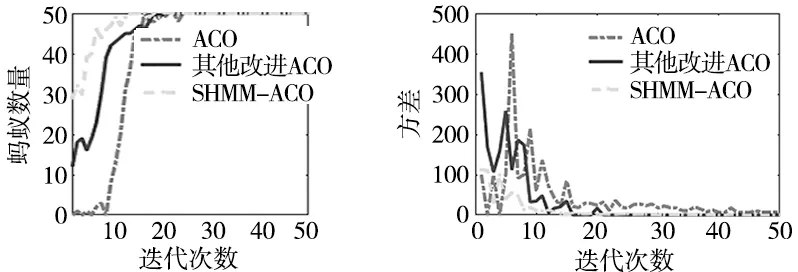
(a) 各算法存活蚂蚁数量对比 (b) 各算法路径长度方差对比图11 存活蚂蚁数量和路径长度方差
虽然其他改进ACO算法前几代蚂蚁未全部陷入死锁,但是蚁群的质量不高,在第20次迭代种群质量才有所提高。而SHMM-ACO有K-means聚类因子和SHMM因子种群之间可能相互学习,在第10代蚁群整体质量达到最优。
图12是20×20栅格带U型障碍复杂环境中各算法转弯次数三维对比图,x坐标是蚂蚁编号,y坐标是迭代次数,z坐标是转弯次数。由12a可知,ACO转弯次数没有收敛,转弯次数在20~80大范围跳动;其他改进ACO虽然有收敛迹象,但是在迭代30次以后仍然存在波动;SHMM-ACO在迭代8次以后,整个转弯次数稳定收敛在12次,一直平稳。验证了复杂环境下SHMM-ACO在复杂环境下的转弯稳定性,规划的路径更有利于机器人平稳转弯。
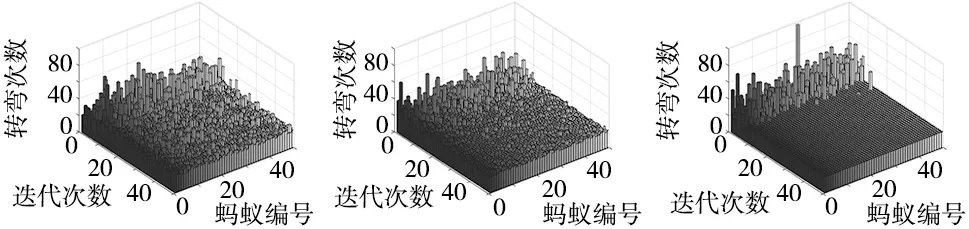
(a) ACO转弯次数 (b) 其他改进ACO转弯次数 (c) SHMM-ACO转弯次数图12 转弯次数对比
4 结论
本文提出了一种基于采样隐马尔可夫模型的移动机器人规划:
(1)基于SHMM建立移动机器人运动模型,以提高移动机器人路径规划的学习和预测能力。
(2)用K-means聚类对不同复杂程度的环境分类进行初始信息素的分配,以避免蚁群算法前期收敛慢,后期陷入停滞的问题。
(3)融合SHMM因子、K-means因子和转角因子改进蚁群算法,改进后的蚁群算法规划路径长度更短,转角更少,能够躲避行人,更加平滑安全。
最后经大量的仿真实验,验证了本文提出算法的有效性和可行性,为移动机器人动态避障、规划出更安全、平滑的路径,给出了自己的解决方案。
