联邦学习开源框架综述
2023-07-20林伟伟李董东许银海
林伟伟 石 方 曾 岚 李董东 许银海 刘 波
1 (华南理工大学计算机科学与工程学院 广州 510006)2 (吉林大学数学学院 长春 130012)
3 (华南师范大学计算机学院 广州 510631)
人工智能(artificial intelligence, AI)从1995 年达特茅斯会议开始经过了两起两落的发展.第1 个高峰期,自动化算法的提出使得人们看到了AI 的希望,但是受计算能力的限制大规模任务训练无法完成,AI 进入了第1 个低谷.第2 个高峰期,霍普菲尔特神经网络(Hopfiled neural network, HNN)和反向(back propagation, BP)神经网络的提出使得大规模网络训练成为可能.但是由于算力和数据不够导致AI 进入了第2 个低谷.随着深度神经网络的提出、硬件设备计算能力的提升以及大数据的出现,AI 迎来了第3个高峰.特别是近年来智能边缘设备的激增,海量的数据更是推动了边缘协同技术的发展.许多研究人员尝试将AI 技术和边缘计算结合起来,挖掘庞大边缘设备的巨大潜力.其中,Neurosurgeon[1]可以说是较具代表性的研究之一,它的基本思想是将一个完整的深度神经网络分割成几个更小的部分并将它们下放到边缘设备进行训练,依靠边缘设备和用户之间的低延迟,可以显著提高模型训练速度.
虽然大数据时代提供了海量数据,但是大部分行业中的数据都是以孤岛形式存在.由于隐私安全、公司制度等问题,即使同一个公司的不同部门之间实现数据整合也非常困难.因此,在现实中想要联合各地的各个机构进行数据交流是一项艰巨的任务.由此可见,“数据孤岛”[2]问题和数据隐私安全问题成为了制约AI 发展的重要因素.
为了解决存在的问题,联邦学习(federated learning,FL)应运而生,并被成功应用于工业界和学术界.2016年,谷歌公司在安卓手机终端研究机器学习时提出了联邦学习这一概念和技术[3-4],旨在保护隐私安全的前提下进行各参与方的数据交流.具体来讲,多个数据拥有者(如移动设备)可以在中央服务器(如服务提供商)协调下训练模型.且在训练过程中,各参与方的原始数据始终保留在本地,服务器主要通过加密机制下的参数交换建立共有模型.
可以看出,联邦学习技术是一种“合作共赢”的模式,在这种联邦机制下,联邦系统帮助各参与方建立了一个“共同富裕”的策略.特别是对于各商业企业,联邦学习可以实现不同行业间的数据交流,打破数据壁垒,实现各行业间的协同发展.因此,随着联邦学习研究的不断深入,各科研团队与公司纷纷推出了适用于不同场景的联邦学习框架,如FATE(federated AI technology enabler)[5]和TensorFlow Federated[6]等.
据中国信息通信研究院推出的报告显示,2020年通过评测的联邦学习产品多达18 款,拥有联邦学习框架和产品的企业超过60 多家.除了Google 开源的TensorFlow Federated[7]、OpenMined 开源的PySyft[8]、南加州大学团队的FedML[9]和剑桥大学团队的Flower[10]外,业界内较为成熟的联邦学习框架还有微众银行的FATE[5]和百度的PaddleFL[11].根据各框架的受众定位,其主要被应用于工业产品研究和学术研究,以帮助业界的研究人员了解联邦学习的原理并进一步促进联邦学习理论、算法以及隐私安全等方面的优化和创新.由此可见,联邦学习框架是学术研究和工业应用的基石,然而,尽管联邦学习的研究和开源框架的开发进展迅速,但目前仍鲜有文献针对各框架进行系统分析和比较.因此,为了帮助大家更系统、更快速地了解联邦学习框架,本文根据各开源框架在业界的受众程度,选取具有代表性的PySyft,FATE,TensorFlow Federated,PaddleFL, FedML,Flower 框架进行详细分析和比较.针对不同类型的研究框架,本文首先从框架的系统架构和系统功能2 个层次出发分别对各框架进行详细分析;其次从算法、隐私机制、计算范式、学习类型、工业支持、可视化、硬件类型等多个维度对不同框架进行对比分析.同时本文基于目前框架存在的问题,进一步讨论了未来可能的研究发展方向,为开源框架的建设创新、结构优化、安全优化以及算法优化等提供有效思路.
1 联邦学习概述
1.1 联邦学习的定义及分类
联邦学习是一种加密的分布式机器学习范式,一般由多个客户端(如移动设备)和一个中央服务器(如服务提供商)组成.其特点是各参与客户端的数据始终保持在用户本地,以最大限度保障客户端数据安全.
联邦学习常用的框架包含2 种:中心化架构和去中心化架构.中心化架构也被称作客户端-服务器架构,在该架构中,各参与客户端利用自己的本地数据和本地资源进行本地训练,待训练完成后再将脱敏参数上传到服务器进行整合,其具体架构如图1 所示.中心化架构的基本流程大致可以分3 步:1)分发全局模型.中央服务器初始化全局模型,并根据不同的客户端状态信息(如是否充电、是否为计费网络等)选择参与训练的客户端,并将初始化后的模型结构和参数分发给所选客户端.2)训练本地模型并发回更新.客户端收到模型后利用本地数据执行模型训练,在训练一定次数之后,将更新的模型参数发送给服务器.3)聚合与更新.服务器对所选客户端参数进行聚合后更新全局模型,并将更新后的模型及参数发送给各客户端,通过重复这3 个步骤直到停止训练.

Fig.1 Centralized architecture of federated learning system图1 联邦学习系统中心化架构
不同于中心化架构,在去中心化的联邦学习[12]架构中,由于各参与客户端可以直接通信,不需要借助第三方(服务器),因此也被称作对等网络架构,其架构如图2 所示.在该架构中,联邦学习的基本流程与中心化架构相似,不同之处在于训练全局模型的任务是由某一个参与方发起,且当其他参与方对模型进行训练后,各参与方需要将其本地模型加密传输给其余参与方.虽然该架构减少了第三方服务器的参与,但是由于所有模型参数的交互都是加密的,因此需要更多的操作进行加密和解密操作.目前在工业界和学术界研究更多的还是基于中心化的联邦学习架构.
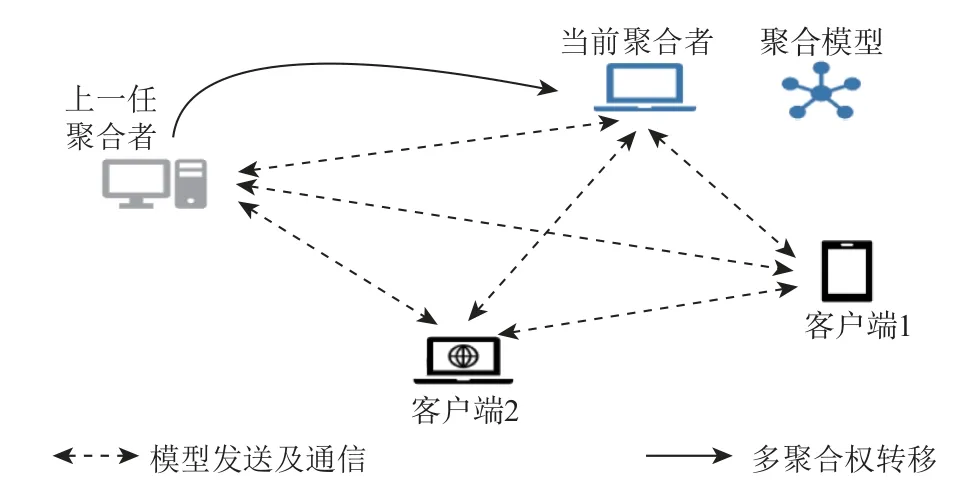
Fig.2 Decentralized architecture of federated learning system图2 联邦学习系统去中心化架构
此外,在联邦学习系统中,各参与方的数据又具有不同的分布特征.若根据参与方之间数据重叠程度的不同,联邦学习又可以分为横向联邦学习[13]、纵向联邦学习[14]以及迁移联邦学习[15].
如图3 所示,横向联邦学习也称为特征对齐的联邦学习,适用于各参与方之间数据特征空间重叠较多而用户空间重叠较少的情况.目前横向联邦学习的经典框架是FedAvg[3],唤醒单词识别[16]和输入法下一词预测[17]是横向联邦的典型应用.纵向联邦学习如图4 所示,即样本对齐的联邦学习,适用于各参与方之间用户空间重叠较多而特征空间重叠较少或没有重叠的场景.目前支持纵向联邦学习的经典框架包括FATE,PaddleFL,FedML.联邦迁移学习,如图5所示,是对横向联邦学习和纵向联邦学习的补充.联邦迁移学习用于克服数据或标签不足的情况,以解决单边数据规模小和标签样本少的问题,适用于各参与方用户空间和特征空间都重叠较少的场景.目前支持联邦迁移学习的框架主要为FATE.

Fig.3 Horizontal federated learning图3 横向联邦学习

Fig.4 Vertical federated learning图4 纵向联邦学习
1.2 联邦学习与传统分布式学习的区别
从系统架构上看,联邦学习与传统分布式学习都是由服务器和多个分布式节点组成,具有较高的相似性.但是相比于传统分布式学习,联邦学习在数据、通信以及系统构成上又具有自己的特点,其与传统分布式学习的主要区别如表1 所示.

Table 1 Difference Between Traditional Distributed Learning and Federated Learning表1 传统分布式学习与联邦学习的区别
1.2.1 数据方面
联邦学习与传统分布式学习在数据方面的区别主要体现在3 个方面:数据分布、数据量级和数据安全.
1)数据分布.在传统分布式学习中,不同设备的数据通常是均匀、随机分布的,具有独立同分布的特点.而在联邦学习中,不同设备的数据是其独立产生的,由于设备拥有者的喜好、设备的地理位置、时间等的差异往往表现出不同的分布特征,具有非独立同分布的特点.
2)数据量级.传统分布式学习为了提高训练效率,通常都会把训练数据均匀分布在每个参与设备上,实现负载均衡.然而在联邦学习中,每个参与设备拥有的数据量与设备拥有者的喜好以及设备自身有关,很难保证不同设备拥有相近的数据量.
3)数据安全.传统分布式学习中的服务器对参与设备以及其中的数据具有较高的控制权,可以将训练数据分布在各个参与设备上,也可以对参与设备进行调度,让设备之间进行数据交换等操作.当数据具有隐私敏感属性时,传统分布式学习无疑会给用户数据带来极大的隐私泄露风险.而在联邦学习过程中,由于参与设备的数据始终保持在本地,服务器无法直接或间接操作设备上的数据,因此参与设备对数据具有绝对的控制权,可以最大限度地保障数据隐私和安全.
1.2.2 通信方面
联邦学习与传统分布式学习在通信方面的区别主要体现在2 个方面:网络稳定性和通信代价.
1)网络稳定性.传统分布式场景中的服务器与参与设备通常都位于专用的机房中,且用高速宽带进行互联,网络、运行环境都相对稳定.而参与联邦学习的设备大多数是手机、平板等移动设备,由于具有移动性,其所处的网络环境并不稳定,导致其稳定性较差,随时都可能与中心服务器断开连接.
2)通信代价.由于传统分布式场景中的服务器和参与设备通常处于同一地理位置,且具有专用的信道进行通信,其通信代价往往较小.而在联邦学习中,由于参与训练的设备可能分布在不同的地理位置,与服务器一般处于远程连接的状态,受不同设备网络带宽的影响,还存在设备掉线等不稳定情况,因此联邦学习相比于传统的分布式学习通信代价要更高.
1.2.3 系统构成
联邦学习与传统分布式学习的系统构成较为相似,都是由服务器和多个分布式节点组成.不同之处在于,在传统的分布式学习系统中,数据分布、计算以及模型更新都是由服务器进行统一控制,服务器具有绝对的控制权.而在联邦学习系统中,由于节点之间数据分布、数据量级、计算能力以及网络环境之间的差别,联邦学习的系统不但需要考虑数据安全性和非独立同分布的特点,还需要考虑数据传输时延等众多因素.
1.3 联邦学习计算范例
在联邦学习中,根据其目前的应用场景,我们将其计算范例分为单机模拟、基于拓扑结构的分布式训练和移动设备端训练[9].
单机模拟主要是为了帮助研究人员快速了解联邦学习框架以及测试算法等,比较适合小型研究使用.当项目内容较为简单时,可以将项目部署在一台服务器上,由该服务器模拟整个联邦学习框架.然而,单机对于大规模数据计算和存储的处理能力有限,当需要进行复杂联邦学习训练时,单机的硬件资源将无法满足需求.
基于拓扑结构的分布式训练类似于传统的分布式训练,由多方协同进行联邦计算,可以用于大型实验测试和真实环境部署(如不同机构组织之间).在该计算范例中,中央服务器作为协调者负责分发和聚合模型,所有模型的训练都在客户端完成.因此在分布式训练范例中,通信起着至关重要的作用.在分布式通信中,应用层可以采用的协议有HTTP 和WebSocket等,会话层则可以基于RPC 进行通信.在通信过程中,联邦学习框架通常采用同态加密、差分隐私和安全多方计算等手段保护隐私安全,以求达到效率、精度和隐私的平衡.
联邦学习的重要计算范例之一是移动设备端训练,如移动电话、智能手环等设备.在学习过程中节点间需要频繁通信,非常消耗计算资源和传输资源,然而移动设备通常计算能力有限,且由于网络状况的不稳定可能随时退出训练.因此,除了PySyft,FedML,Flower 外,其他联邦学习框架并未过多关注移动设备训练,而更多考虑在服务器上训练好模型后,将存储的模型移植到终端,在终端推理模型.
2 联邦学习开源框架
为了更系统、更快速地了解联邦学习框架以及不同框架的特点,本文根据开源框架在业界的受众程度,选取目前在工业界和学术界影响较大的开源框架进行深入分析和介绍,重点从各框架的架构设计和系统功能2 个层次对各框架进行剖析.
2.1 PySyft
PySyft[8]是OpenMined 在2018 年提出、开源于2020 年的一个基于Python 的隐私保护深度学习框架,它主要借助差分隐私和加密计算等技术,对联邦学习过程中的数据和模型进行分离.PySyft 的设计主要依赖于客户端之间交换的张量链,特点是涵盖了多种隐私机制,如差分隐私、同态加密和安全多方计算;并以可扩展的方式进行设计,便于研究人员可以添加新的联邦学习方法或隐私保护机制.
2.1.1 PySyft 系统架构
由于PySyft 的设计主要依赖于客户端之间交换的张量链,因此其系统架构的重点是基于张量的链抽象模型的设计.如图6 所示,基于张量的链抽象模型的核心部分是一个称为_Syft 张量的抽象,_Syft 张量主要用于表示数据的状态或变换,并且可以链接在一起.链结构的头部始终有PyTorch 张量,并使用子属性向下访问由_Syft 张量体现的变换或状态,使用父属性向上访问由_Syft 张量体现的变换或状态.

Fig.6 Chain abstract model图6 链抽象模型
如图7 所示,_Syft 张量有2 个重要的子类:第1个是在实例化Torch 张量时自动创建的Local 张量,其作用是在Torch 张量上执行与加载运算相对应的本机运算;第2 个是当将张量发送给远程客户端时创建的Pointer 张量.Pointer 张量发送和取回十分简便:当接收到命令时,整个链将被发送给客户端,并被替换为具有双节点的链(张量(空)和指定拥有数据和远程存储地址的Pointer 张量).此外,PySyft 采用了类似指针的方式进行多方调度,当向客户端发送张量时,客户端会返回一个指向该张量的指针,所有操作都将使用该指针执行.

Fig.7 Tensor sending schematic diagram图7 张量发送示意图
PySyft 还建立了一个用于客户端间通信的标准化协议.在联邦学习环境中的客户端有2 种实现方式:Network Sockets 和 Web Sockets.Network Sockets 客户端通过调用Socket API 来完成应用层协议,实现不同客户端之间的通信.而Web Sockets 客户端从浏览器中实例化,每个客户端都被视为设备上的一个单独实体,并通过WebSocket API 进行通信,为不同机器上的远程客户端之间的联邦学习提供了解决方案.此外,由于WebSocket API 是纯事件驱动,因此可以使用异步事件在客户端监听连接生命周期的每个阶段.
2.1.2 PySyft 系统功能
作为注重隐私安全的深度学习框架,PySyft 重要的一项系统功能就是基于张量指针集成了SyMPC 多方安全计算库以实现SPDZ 协议.同时,除安全多方计算外,PySyft 还支持差分隐私,包括DP-SGD,PATE,Moments Accountant,Laplace 和指数机制.同态加密方面由TenSEAL 库负责完成,其主要依赖Microsoft SEAL中的CKKS,允许各方加密它们的数据,以便让不受信任的第三方使用加密数据训练模型,而不泄露数据本身.除此之外,还有PyDP,Petlib 等库提供了隐私保护.
对于联邦学习类型,PySyft 目前仅可用于横向联邦学习,涵盖的联邦算法包括FedAvg 等.虽然PySyft 可进行基于拆分神经网络的垂直学习,并利用PSI 协议以保护数据集隐私,但仍未提供纵向联邦的解决方案.机器学习算法方面,PySyft 支持逻辑回归和神经网络,如DCGAN 和 VAE 模型.除联邦学习的基本方法外,PySyft 还支持联邦的同步和异步机制.操作系统方面,PySyft 支持Mac,Windows,Linux.研究人员能进行单机模拟、基于拓扑架构的分布式训练和移动端设备训练.
2.1.3 PySyft 版本变化
虽然OpenMined 提供了多种隐私保护方式,但目前的版本仅支持横向联邦学习.其中,2021 年7 月发布的PySyft 0.2.8 版本取消了以模型和数据为中心的概念,引入了动态和静态的联邦概念.2021 年9月发布的PySyft 0.2.9 版本改进了函数加密共享的执行速度,添加了对BFV 方案的支持,以及监控基准.直到2021 年12 月发布的最新版 PySyft 0.6 暂时仅对功能进行一定程度上的维护.相较于FATE 和PaddleFL,PySyft 尚未提供高效的部署方案及服务器ing 端解决方案.
2.2 FATE
FATE 是微众银行在2019 年开源的联邦学习框架,旨在解决各种工业应用实际问题.在安全机制方面,FATE 采用密钥共享、散列[18]以及同态加密技术,以此支持多方安全模式下不同种类的机器学习、深度学习和迁移学习.在技术方面,FATE 同时覆盖了横向、纵向、迁移联邦学习和同步、异步模型融合,不仅实现了许多常见联邦机器学习算法(如LR[19-20],GBDT,CNN[21]),还提供了一站式联邦模型服务解决方案,包括联邦特征工程、模型评估、在线推理、样本安全匹配等.此外,FATE 所提供的FATE-Board 建模具有可视化功能,建模过程交互体验感强,具有较强的易用性.目前这一开源框架已在金融、服务、科技、医疗等多领域推动应用落地.为了让大家更清晰地了解FATE,我们将从系统架构以及系统功能2 个层次出发,对FATE 进行详细分析.
2.2.1 FATE 系统架构
FATE 系统架构主要包括离线训练和在线预测2 部分,其系统架构如图8 所示.其中,FATE Flow 为学习任务流水线管理模块,负责联邦学习的作业调度;Federation为联邦网络中数据通信模块,用于在不同功能单元之间传输消息;Proxy 作为网络通信模块承担路由功能;元服务为集群元数据服务模块;MySQL为元服务和FATE-Flow 的基础组件,用于存放系统数据和工作日志;FATE 服务(FATE serving)为在线联合预测模块,提供联邦在线推理功能;FATE-Board为联邦学习过程可视化模块;Egg 和Roll 分别为分布式计算处理器管理模块和运算结果汇聚模块,负责计算和存储数据.
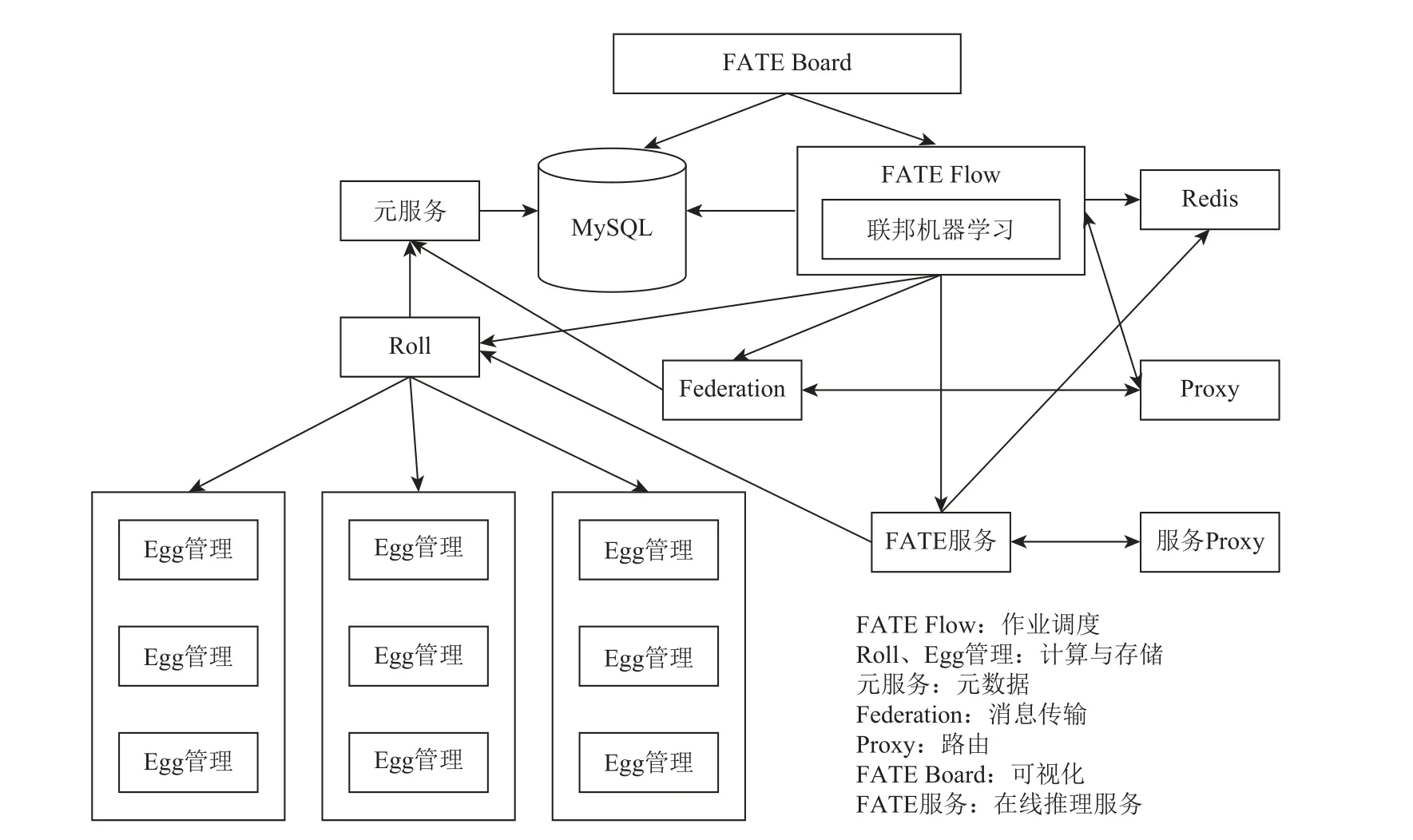
Fig.8 FATE system architecture图8 FATE 系统架构
2.2.2 FATE 系统功能
1)离线训练框架
离线训练框架如图9 所示,其架构主要分成基础设施层、计算存储层、核心组件层、任务执行层、任务调度层、可视化面板层以及跨网络交互层.在基础设施层,FATE 提供KubeFATE 模式,使用云本地技术管理联邦学习工作负载,支持通过Docker Compose和Kubernetes 进行部署.其中,KubeFATE 提供了丰富的FATE 集群生命周期管理功能,可以方便地对集群进行增加或删减、修改配置等操作.利用FATE 集群管理的任务框架,研发人员可以轻松定位与解决基础设施层的问题.

Fig.9 Off-line training framework architecture图9 离线训练框架架构
在计算存储层,离线训练框架使用EggRoll 以及Spark 作为分布式计算引擎.当使用EggRoll 作为计算引擎时,簇管理器(cluster manager)负责提供服务入口以分配资源,节点管理器(node manager)执行实际计算和进行存储,Rollsite 负责数据传输.当使用Spark作为计算引擎时,需要使用HDFS 来实现数据的持久化,而Pipeline 的同步和训练过程中消息的同步则要依赖于Nginx 和RabbitMQ 服务来完成.
核心组件层主要提供数据交互、算法和模型训练评估相关的实现.本层主要由FederatedML 组成,其包括许多常见机器学习算法的联邦实现以及必要的实用工具.简单来说,可分为4 个功能模块:①算法模块,用于数据预处理和联邦特征工程的机器学习算法;②实用程序模块,作为启用联邦学习的工具,例如加密算子、参数定义及传递变量自动生成器等;③框架模块,用于开发新算法模块的工具包和基础模型;④安全协议模块,包括SPDZ,OT 等协议,以实现安全联邦学习.
任务执行层以及调度层主要由FATE-Flow 构成.FATE-Flow 是实现联邦学习建模和任务协同调度的重要工具,主要包括:DAG 定义联邦学习Pipeline、联邦任务协同调度、联邦任务生命周期管理、联邦模型管理、联邦任务输入输出实时追踪以及生产发布功能.
可视化面板层由FATE-Board 构成,主要实现联邦建模过程的可视化.FATE-Board 由任务仪表盘、任务可视化、任务管理与日志管理等模块组成,可以对联邦学习过程中模型的训练状态及输出结果进行可视化展现.FATE-Board 提供了矩阵图、回归结果、树模型等的可视化反映,从而研究人员可以更及时地了解模型状态与调整参数,提升联邦学习的效果.
跨网络交互层由Federated-Network 联邦多方通信网络构成,它的架构为:元服务为元数据管理者和持有者,负责定位不同数据在不同机器的位置;Proxy为应用程序层联邦学习路由,Federation 负责全局对象的抽象和实现,FATE-Exchange 提供通信功能.
2)在线预测框架功能
FATE 服务是针对联邦学习模型的高性能工业化服务系统.在离线建模后,FATE-Flow 将模型推送至FATE 服务,FATE 服务通过加载训练模型实现在线预测功能,主要支持动态加载联合学习模型、多级缓存、生产部署的预/后处理、联邦学习在线批量预测、各方并行预测等.其具体部署架构如图10 所示.其中服务器服务(serving-service)为预测功能的核心,用于处理各种请求,提供基于gRPC 的模型在线推理服务.服务器服务从FATE-Flow 加载好模型后,将该模型相关的服务信息注入注册中心(zookeeper),以便网关服务从中拉取可用服务并调用.同时,训练好的模型信息将被发送给模型管理服务完成持久化存储,作为备份可在特殊情况下恢复.

Fig.10 FATE-serving deployment architecture图10 FATE 服务部署架构
服务代理(serving-proxy)主要是在多方交互时作为网关服务实现服务路由,实现客户端与主机之间的通信.它对外提供gRPC 接口以及HTTP 接口,维护一个各参与方partId 的路由表,通过路由表中的信息转发外部系统的请求.
从FATE 的系统架构和系统功能可以看出,FATE的优势在于其具有丰富的算法组件,具有简单、开箱即用、易用性强的特点.作为目前唯一的一个可以同时支持横向联邦学习、纵向联邦学习以及联邦迁移学习的开源框架,FATE 得到了业界广泛的关注与应用.同时,FATE 还提供了一站式联邦模型解决方案,可以有效降低开发成本,相比于其他开源框架,在工业领域优势突出.
2.2.3 FATE 版本变化
2019 年首款工业级联邦学习框架FATE 由微众银行推出,其具有区别于其他开源框架的特色功能,包括可视化模块FATE-Board、联邦学习建模pipeline调度和生命周期管理工具FATE-Flow.截至2019 年12 月发布的FATE v1.2 版本覆盖横向联邦学习、纵向联邦学习、联邦迁移学习,得到了社区内广泛的关注与应用.2020 年10 月发布的 FATE 1.5 版本对纵向联邦的通信效率进行了提升,支持不同的计算、存储和传输引擎的组合,并对用户的便捷使用做出改进,引入了Pipeline 和CLI v2 等.2021 年3 月,该框架新增了本地文件系统目录路径虚拟存储引擎和消息队列Pulsar 跨站传输引擎,对组网模式进一步扩充,并在后续加入了1 对多的FATE 服务的集群推送.在FATE 1.7 版本中,开始支持EggRoll、Spark-Local 计算引擎、Hive 存储,进一步提升Spark-Local 和Spark-Cluster 之间的异步融合.2022 年4 月发布的FATE 1.8 除了添加加密性能评估Paillier、性能评估SPDZ 和管道dsl的转换工具外,还对纵向联邦的性能进行了提升,例如SecureBoost 节省带宽75%,提速1.5~5 倍.
2.3 TFF (TensorFlow federated)
2019 年,谷歌发布了基于TensorFlow 构建的全球首个大规模移动设备端联邦学习系统[6],该系统用于在移动智能设备执行机器学习和其他分布式计算,旨在促进联邦学习的开放性研究和实验.
2.3.1 TFF 系统架构
为协调客户端和中央服务器的交互,TFF 除了提供与GKE(Google Kubernetes engine)和Kubernetes 集群的集成,还提供容器映像来部署客户端并通过gRPC调用进行连接,其系统架构如图11 所示.

Fig.11 TFF framework architecture图11 TFF 系统架构
从系统架构图可以看出,TFF 的训练流程包括3 步:1)服务器从所有设备端筛选出参与该轮联邦学习任务的设备,为了不影响用户体验,筛选标准包括是否充电、是否为计费网络等.2)服务器向训练设备发送数据,包括计算图以及执行计算图的方法.而在每轮训练开始时,服务器向设备端发送当前模型的超参数以及必要状态数据.设备端根据全局参数、状态数据以及本地数据集进行训练,并将更新后的本地模型发送到服务端.3)服务端聚合所有设备的本地模型,更新全局模型并开始下一轮训练.由此可见,设备端的功能主要包括连接服务器、获取模型和参数状态数据、模型训练、模型更新.TFF 的客户端架构设计如图12 所示.

Fig.12 TFF client architecture图12 TFF 客户端架构
对于服务器端,TFF 围绕编程模型参与者模式(actor model)设计,使用消息传递作为唯一的通信机制,采用自顶向下的设计结构,如图13 所示.其中协调方(coordinator)是顶级参与者,负责全局同步和推送训练.多个协调方与多个联邦学习设备集群一一对应,负责注册设备集群的地址.协调方接收有关选择器的信息,并根据计划指示它们接受多少设备参与训练.而选择器负责接收和转发设备连接,同时定期从协调方接收有关联邦集群的信息,决定是否接受每台设备做出本地决策.主聚合器(master aggregator)负责管理每个联邦学习任务的回合数,它可以根据设备的数量做出动态决策,以生成聚合器(aggregator)实现弹性计算.
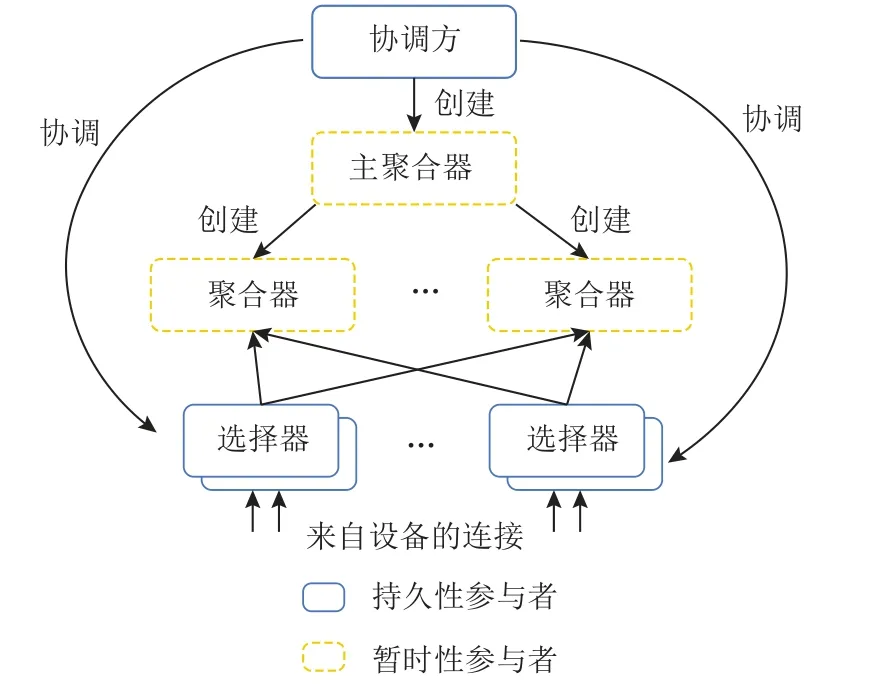
Fig.13 TFF top-down structure图13 TFF 自顶向下结构
2.3.2 TFF 系统功能
为实现联邦学习模型训练的实验环境和计算框架,TFF 构建了FL API(federated learning API)和FC API(federated core API)两个级别的接口.
如图14 所示,FL API 包括模型、联合计算构建器、数据集3 个部分.模型部分提供封装完成的tff.learning 函数,研究人员可以直接调用该函数实现各种联邦学习算法而无需自行构建,如可以使用FedAvg和Fed-SGD 进行模型训练.联邦计算构建器的主要目的是使用现有模型为训练或评估构造联邦计算,主要用于辅助联邦学习的训练和计算过程.在数据集模块,通过TensorFlow API 中提供的LEAF[22]生成联邦学习特定训练数据集,给出了用于TFF 仿真和模型训练的可直接下载和访问的罐装数据集.除了高级接口外,FC API 提供了底层联邦学习接口,它是联邦学习流程的基础,研究人员可以通过它方便地构建自定义联邦学习算法.

Fig.14 TFF API architecture图14 TFF API 架构
在联邦学习类型方面,TFF 目前只支持横向联邦学习,尚未提供纵向联邦及迁移学习的方案;模型方面,提供了FedAvg,Fed-SGD 等算法,同时也支持神经网络和线性模型;在计算范式方面,TFF 支持单机模拟和移动设备训练,不支持基于拓扑结构的分布式训练;在隐私保护机制方面,TFF 采用差分隐私以保证数据安全.TFF 的主要受众目标是研究人员和从业者,他们可以采用灵活可扩展的语言来表达分布式数据流算法,定义自己的运算符,以实现联邦学习算法和研究联邦学习机制.
2.3.3 TFF 版本变化
谷歌于2019 年2 月首次发布TFF 框架,12 月发布TFF 0.11.与PySyft 相同,该框架也仅支持横向联邦学习.用户可以通过FL API 与TensorFlow/Keras 交互,完成分类、回归等任务,也可以基于FC API 构建自定义的联邦学习算法.其中,2020 年发布的TFF 0.17版本支持计算跟踪控制,消除了客户机数量对分布式运行的影响.2022 年TFF 0.20 版本除了对API 功能进行了升级外,明确了对零客户端聚合的支持,增加了张量的流量.直至最新的TFF 0.23 版本,该框架仍然仅提供了基于差分隐私的隐私保护,未添加同态加密和多方安全计算.
2.4 PaddleFL
2019 年,百度基于安全多方计算、差分隐私等领域的实践,开源了PaddlePaddle 生态中的联邦学习框架PaddleFL[11],旨在为业界提供完整的安全机器学习开发生态.PaddleFL 提供多种联邦学习策略,因此该框架在不同领域都受到了广泛关注.
2.4.1 PaddleFL 系统架构
PaddleFL 架构的整体设计可以参考图15.如图所示,PaddleFL 可以支持横向联邦和纵向联邦2 种策略.对于横向联邦学习,其主要支持FedAvg,DPSGD,SECAGG 等策略;对于纵向联邦学习,其主要支持LR with PrivC 和NN with MPC[23]的神经网络.PaddleFL 底层的编程模型采用的是飞桨训练框架,结合飞桨的参数服务器功能,其可以实现在 Kubernetes 集群中联邦学习系统的部署.训练策略方面,PaddleFL 可进行多任务学习[24]、迁移学习、主动学习等训练.

Fig.15 PaddleFL architecture图15 PaddleFL 的架构
2.4.2 PaddleFL 系统功能
PaddleFL 主要提供2 种实现联邦学习的方案:数据并行(data parallel, DP)和基于多方安全计算的联邦学习(federated learning with MPC, PFM).在DP 中,模型训练过程主要分2 个阶段:编译和分布式运行.
如图16 所示,编译包含4 个组件:联邦学习策略、用户自定义程序、分布式配置、联邦学习任务生成器.联邦学习策略主要提供横向和纵向联邦学习算法,如神经网络和逻辑回归等,用户也可以自己定义机器学习模型和训练策略;用户自定义程序定义了机器学习模型结构和训练策略;分布式配置的作用是设定分布式训练的节点信息;联邦学习任务生成器负责为联邦服务器端和客户端生成联邦任务,并将它发送到联邦参数服务器进行联邦训练.分布式运行由服务器、客户端、联邦学习调度器3 部分组成.服务器为联邦参数服务器,是联邦学习的管理者;客户端为联邦学习的各参与方,与联邦参数服务器进行通信,其中通信模式包括 Gloo 和gRPC;联邦学习调度器在训练过程中负责调度,选择每一训练回合中参与的客户端.
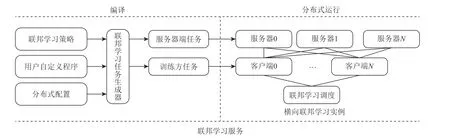
Fig.16 Data parallel training framework图16 Data parallel 训练框架
PFM 整个训练过程包括数据准备、训练推理、结果解析3 个阶段.其中数据准备阶段主要包括2 项工作:1)隐私集合求交.在保护数据隐私的前提下,求出各参与方的数据交集.2)数据加密及分发.采用Secret Sharing 进行数据和模型加密,并分发给参与方.数据准备完成后,根据用户设定的联邦学习模型进行训练,同时基于多方安全计算保证训练安全.在训练结束后,对结果解密并发送给各参与方.PFM 提供了多方安全计算下的联邦学习,支持横向和纵向联邦学习.在PFM 中,一共有3 个参与者:输入方(IP)、计算方(CP)和结果方(RP).输入方(数据或模型的拥有者)负责将数据或模型加密后发送给计算方;计算方(云上的虚拟机)接受加密后的数据或模型后基于特定的MPC 协议进行训练或任务推理,完成后将结果发送给结果方;结果方接受加密计算结果后重构明文结果.三方参与者角色可以重叠.
PaddleFL 提供的联邦学习策略涵盖了横向联邦学习和纵向联邦学习,相比于其他的联邦学习框架,其适合在大规模分布式集群中部署.其中,横向联邦学习主要涵盖了FedAvg[3],DP-SGD[25]等算法,纵向联邦学习主要包括了基于PrivC 的逻辑回归和基于ABY3协议的神经网络.目前Paddle FL 开源了横向联邦学习场景,可以用于具有相同类型任务的多个组织进行联合训练.对于纵向联邦学习场景,百度公司指出将会在未来开源纵向联邦学习编程框架,并实现不同联邦学习类型的编程接口统一,同时在性能方面也将提升训练的速度和精度、跨地域的稀疏通信、通信的稳定性等.
2.4.3 PaddleFL 版本变化
PaddleFL 自2019 年11 月开源以来,百度公司随后在2020 年5 月发布的Paddle 1.8 版本深度优化了命令式编程模式功能.对原生推理库性能进行了显著优化,推出了可以轻量化部署的推理引擎PaddleLite,并发布了前端推理引擎Paddle.js.且Paddle-服务器ving 全面升级,提供了强大简单化的部署功能,其对应的开发库和工具组件也进一步丰富完善.2022 年11 月百度公司推出了Paddle 2.4.0 版本,对框架使用了新动态图架构,对框架的调度性能进行大幅度提升,超过90%的API 的调度性能提升超过50%.全面提升了Paddle 的动静统一能力,提供了更加丰富的Python 语法支持.新增稀疏计算类API,支持多种稀疏Tensor,极致节省内存.
2.5 FedML
FedML 是由美国南加州大学联合MIT、Stanford、MSU、UW-Madison、UIUC、腾讯、微众银行等众多高校与公司联合发布的联邦学习开源框架.FedML 不但支持3 种计算范例(单机模拟、基于拓扑结构的分布式训练和移动设备训练),还通过灵活通用的API设计和参考基准实现促进了各种算法研究,并针对非独立同分布(non-independent identically distributed, Non-IID)数据设置了精选且全面的基准数据集用于公平性比较.
2.5.1 FedML 系统架构
FedML 主要包含FedML-core 和FedML-API 这2个组件,分别对应低级别接口(low-level API)和高级别接口(high-level API),系统架构如图17 所示.

Fig.17 FedML system architecture图17 FedML 系统架构
图17 中FedML-core 将分布式通信和模型训练分为2 个单独的模块.分布式通信模块负责不同客户端之间的底层通信,并使用统一的通信管理来完成算法通信协议.目前,FedML-core 支持MPI,RPC,MQTT通信后端.其中MPI 主要用于满足单个集群中的分布式训练需求;RPC 主要用于满足跨数据中心的通信需求(例如cross-silo FL);MQTT 主要用于满足移动设备的联邦学习训练.由于FedML 默认采用MPI通信,因此下面简要介绍其通信过程,而针对移动设备的MQTT 通信则在2.5.5 节介绍.
在FedML 中,MPI 通信主要由通信管理和其维护的发送线程和接收线程实现.其中发送线程和接收线程各自维护一个缓冲队列,发送线程每隔0.003 s轮询一次自己的队列,如果有新消息放入,就将其发送.对于收到的消息,通信管理每隔0.3 s 进行1 次对其自身的轮询,有新消息收到则通知观察者,观察者利用回调机制处理信息.
具体通信过程如图18 所示:①服务器启动,发送初始化信息给客户端;②客户端收到服务器端发送的消息,触发handler 函数;③训练方进行本地模型的训练;④每轮训练结束后,将训练好的参数放入发送队列;⑤发送线程将队列中的数据传回服务器;⑥服务器收到客户端端发送的消息,触发handler 函数;⑦更新全局模型参数;⑧将更新后的全局参数传入发送队列进行下发,开始下一轮迭代训练.此外,FedML还支持用户自定义通信协议.如果需要使用不同的通信协议,用户只需替换底层的通信管理即可.

Fig.18 MPI communication diagram图18 MPI 通信示意
在分布式通信模块内部,TopologyManager 支持多种网络结构,如基于数据中心的联邦学习、去中心化联邦学习、分层联邦学习[26-27]等.
FedML-API 建立在FedML-core 之上,FedML-API包括模型、数据集和算法.FedML 支持的算法包括线性模型(逻辑回归)、神经网络(CNN,RNN)等;每个算法包括服务器Manager 和客户端Manager 这2 个对象,用于集成FedML-core 的通信模块的ComManager与机器学习组件的客户端和coordinator,完成分布式算法协议(如FedAvg,FedNAS,FedNova,FedOpt 等)和分布式训练.FedML-API 采用模型、数据集和算法相互分开的系统设计,以实现代码重用和公平比较,避免由于不同实现方式导致的算法之间的统计或系统级差距.此外,通过这种设计,研究人员无需了解不同的分布式算法的细节就可以开发新模型并提交更现实的数据集.
2.5.2 FedML 系统功能
从图17 可以看出,FedML 的系统功能主要包含FedML-core,FedML-API,FedML-Mobile,FedML-IoT.
1)FedML-core 功能
①自定义客户端及信息交换.FedML-core 采取了面向客户端的编程设计模式,当设计联邦学习算法中的训练过程时,用户可以通过继承客户端Manager类并使用其预定义的API 来定义接收消息和发送消息,从而在联邦学习网络中自定义其客户端.另外,消息交换方面,FedML 还支持梯度或模型之外的消息交换(如特定的中间结果),每个客户端都可以从发送的角度定义消息类型.客户端Manager 用于处理各客户端定义的消息,并发送其自身定义的消息.
②拓扑管理.联邦学习具有各种拓扑定义,例如垂直联邦学习[28]、拆分学习[29]、去中心化联邦学习和分层联邦学习[27].为了满足这种多样化的要求,FedML提供了TopologyManager 来管理拓扑,并允许客户端在培训期间将消息发送给任意相邻客户端.在完成TopologyManager 的初始设置后,网络中的每个客户端都可以通过TopologyManager 查询相邻客户端的ID、权重等信息.
③隐私安全和鲁棒性.除了保护数据隐私外,联邦学习框架(尤其是移动设备训练时)的另一个关键要求是应对用户退出的鲁棒性.为了增强安全性和隐私性,FedML-core 实现了常见的密码原语,可支持多方安全计算(秘密共享)和同态加密(密钥协议和数字签名).针对联邦学习中对抗攻击的防御,FedML涵盖了规范差异裁剪[30]、弱差分隐私[30]、RFA[31]、KRUM和MULTIKRUM[32].该框架还提供了通用的对抗性攻击API,该API通过实施模型替换攻击[33]和边缘案例后门攻击[34]来支持后门.
2)FedML-API 功能
①算法.FedML 提供了网络拓扑结构不同、交换信息不同(如交换模型参数或特定中间结果)的各种联邦学习算法.不同计算范式支持的算法有:单机模拟支持FedAvg、FedOpt、FedNova、FedNAS[35]、去中心化联邦、纵向联邦、分层联邦;分布式计算支持去中心化联邦、FedAvg、FedRobust、FedNAS、FedSEG、FedGKT、纵向联邦、Split Learning;移动设备仅支持FedAvg.同时,这些算法也可以用作实现示例和基准,以帮助用户开发和评估自己的算法.FedML 还在不断添加新的联邦学习算法,如Adaptive Federated optimizer,FedProx,FedMA.
②模型和数据集.由于不同实验中模型和数据集的用法不一致,因此很难公平比较联邦学习算法的性能.为了加强公平比较,FedML 采取了模型和数据集合二为一的方法,明确规定了数据集和模型的组合.FedML 提供的模型和数据集分为3 类:线性模型(凸优化)、轻型浅层神经网络(非凸优化,一般用于Cross-device 设置)以及深度神经网络(非凸优化,用于Cross-silo 训练大型DNN).其中线性模型的数据集包括MNIST[36]、联邦EMNIST[37]和Synthetic(α,β)[38];浅层神经网络的数据集包括联邦EMNIST[22]、CIFAR-100[39]、莎士比亚[40]和StackOverflow[41];深度神经网络的数据集有CIFAR10,CIFAR100,CINIC10,Stack-Overflow.具体模型和数据集的组合如表2 所示.

Table 2 Combination of FedML Specific Models and Datasets表2 FedML 具体模型和数据集的组合
3)FedML-Mobile 和FedML-IoT
FedML 的一项主要功能是其在实际硬件框架上对联邦学习的支持.具体来说,FedML 包括FedMLMobile 和FedML-IoT,这是2 个基于实际硬件框架构建设备上的联邦学习测试框架.当前,FedML-Mobile(包括FedML-服务器和Android 客户端 Simulator 这2 个API)支持在Android/iOS 智能手机进行设备的培训.而FedML-IoT 支持Raspberry PI 4 和NVIDIA Jetson Nano.借助建立在实际硬件框架上的测试框架,研究人员可以评估实际系统性能,例如训练时间、通信成本和计算成本.FedML 的架构设计可以将分布式计算代码平稳地移植到FedML-Mobile 和FedML-IoT 框架上,从而几乎重用了分布式计算范式中的所有算法.
根据训练设备的异构性,FedML 采用了当前最流行的物联网协议MQTT,实现FedML-服务器与移动/IoT 设备之间的通信.在发布/订阅体系结构中,FedML-服务器为订阅者,主要识别设备何时准备好开始培训以及接收模型;而参与训练的客户端为发布者.
图19 为服务器和设备之间的工作流程.在步骤1~3 中,服务器和设备与代理建立连接,然后由代理进行通信.同时,服务器为自己订阅一个特定的主题,以便从设备端接收状态更新.步骤4 和步骤5 将训练模型发送到设备.在模型发送之前,服务器分配并准备所有对通信阶段有用的参数(资源分配、模型序列化等).在步骤6 和步骤7 中,参与训练的设备开始训练并返回模型更新.
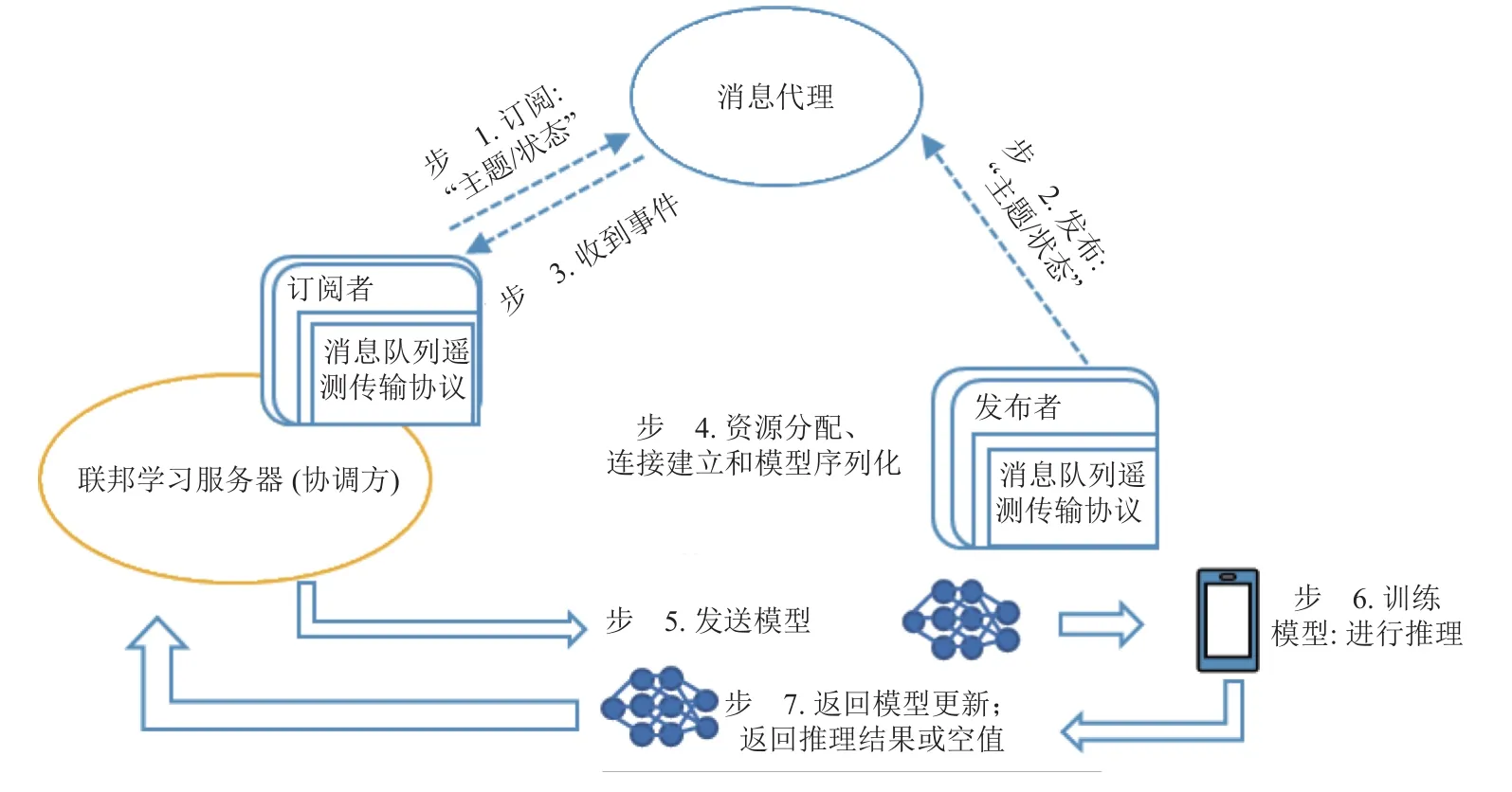
Fig.19 Workflow between FedML servers and devices图19 FedML 服务器与设备之间的工作流程
2.5.3 FedML 版本变化
2020 年9 月由南加州大学联合多所科研院所联合发布了FedML 联邦学习开源框架,针对现有软件框架不能充分支持多样化算法开发以及实验对比存在不一致的问题,提供了一个开放的研究库以及基准.2020 年10 月7 日的版本提供了面向研究的数据集和模型.2020 年10 月28 日的版本对单一的FedAvg聚合算法进行扩充,加入了更多的联合优化算法.2020年11 月5 日的版本针对物联网设备的联邦学习模式进行支持.直至2022 年5 月发布了最新的版本,本次升级对原有的MPI 训练进行了扩充,加入了NCCL 的模式,支持跨组织的跨仓联合训练.相较于FATE,Paddle FL 等工业联邦学习框架, FedML 更适合开发人员作为学术研究使用.
2.6 Flower
Flower[10]是由英国牛津大学在2020 年发布的一款联邦学习框架,其优点在于Flower 可以模拟真实场景下的大规模联邦学习训练.基于其跨平台的兼容性、跨设计语言的易用性、对已有机器学习框架的支持以及抽象的框架封装,用户可以快速高效搭建所需的联邦学习训练流程.Flower 综合计算资源、内存空间和通信资源等因素,高效实现了移动端和无线客户端下异构资源的使用.
2.6.1 Flower 系统架构
Flower 包含Flower 客户端(Flower client)、Flower服务器端(Flower service)、Flower 联邦策略(Flower federation strategy)、Flower 协议(Flower protocol)、Flower 数据集(Flower datasets)、Flower 基准(Flower baselines)、Flower 工具(Flower tools)这7 部分,系统架构如图20 所示.

Fig.20 Flower system architecture图20 Flower 系统架构
Flower 客户端允许用户借助接口实现相应的操作,如软件开发工具包(software development kit, SDK),SDK 主要为用户处理连接管理、Flower 协议和序列化等操作.在目前的版本中,SDK 提供了对Android和Python 的支持,研究团队指出将陆续开放SDK 对iOS 端等移动终端的支持.
Flower 服务器端在整个框架中负责节点之间的连接,客户端生命周期的管理,联邦学习执行的定制、验证、聚合和度量等处理.联邦策略中,用户可以借助抽象的策略来实现新的联邦学习算法,如FedAvg,FedProx,QFedAvg,FedOpt.
此外,Flower 协议降低了对联邦学习设备的要求和对特定编程语言的依赖程度,提高了使用上的客制化程度.Flower 数据集中考虑到不同实验数据的使用以及数据的划分,提供了一组内置的数据集和相应的分区函数,满足客户机之间数据的动态分配.Flower 基准提供了端到端的联邦学习实现,用户借助特定领域语言(domain-specific language,DSL),设置好相应的实验条件就可创建.Flower 工具提供了一套部署、模拟、检测参数的系统级工具.主要包括1)部署实例去模拟客户端和服务器端;2)模拟不同性能的客户端设备;3)改变客户端和服务器端之间的网络带宽,模拟真实场景下的网络状态.
Flower 的通信模块位于Flower 服务端组件中,该组件可大致分为4 层,如图21 所示.目前Flower 仅支持gRPC 的通信方式,但是也支持用户自定义通信协议的替换.gRPC 的交互过程主要通过连接管理(connection management)和gRPC 网桥(gRPC bridge)这2 个模块实现.其中连接管理模块负责维护当前的所有gRPC 连接,如图22 所示.当gRPC 服务器第1次收到请求时,会触发注册函数进行客户端连接的注册管理,将该客户端的信息存放到一个数组中,每一个gRPC 对应一个客户端.服务器借助这个模块来获得指定客户端的gRPC 连接,之后进行通信,获取模型信息.在完成通信或者因为等待超时等情况导致gRPC 断开,则调用非注册函数将断开连接的客户端从当前的记录中删去.

Fig.21 Flower server architecture图21 Flower 服务器端架构

Fig.22 Connection management diagram图22 连接管理示意图
客户端和服务器端的通信由gRPC 网桥进行,该模块负责缓存客户端和服务器端的gRPC 信息.首先由客户端向gRPC 网桥放入信息,客户端再从中获取;客户端本地训练完模型后,将模型信息上传至网桥,服务器端从网桥获取客户端所上传的本地模型信息进行全局模型的更新.该过程通过状态转换的方法来保证其中储存的都是相同信息.大致的状态转换见图23.

Fig.23 gRPC bridge state transition diagram图23 gRPC 网桥状态转换图
2.6.2 Flower 系统功能模块
Flower 主要提供可复现实验、机器学习算法、网络扰动、跨平台接入、大规模接入这5 个功能模块.
1)可复现实验模块
一个完整的联邦学习框架需要多个组件来实现,Flower 中提供了一套可靠、成熟的组件来实现,研究人员可以在一套组件下快速进行实验验证.此外,已有算法库可以让研究人员快速与现有方案进行对比.
2)机器学习算法模块
联邦学习计算的方式弥补了传统单机模式下的不足,但是仍旧有许多的ML 算法尚未迁移过来.Flower通过对现有机器学习框架的链接,允许用户在现有机器学习代码库的基础之上将机器学习算法快速应用于联邦学习模型的训练中.
3)网络扰动模块
通信网络贯穿联邦学习的整个始末,在现实场景中,网络通信状态直接会影响模型训练的效率和结果.Flower 提供了对网络带宽约束的功能,方便量化网络波动对整个联邦学习过程的影响.
4)跨平台接入模块
现有联邦学习框架对异构设备的支持十分有限,更多的是倾向于对服务器端的定义和客户端的计算,或是倾向于对服务器集群而忽视对移动客户端的关注.Flower 中提供了对不同架构的支持,因此可以测试异构环境下不同算法的表现.此外,Flower 在设计上抽象类的设计,使得Flower 对于特定编程语言的依赖降到最低.
5)大规模接入模块
在真实场景下的联邦学习训练需要大量的设备参与.然而,在实验场景中往往不会以真实的参与规模进行设计,对于大规模设备参与的可扩展性有待考察.Flower 在设计之初就考虑到了大量并发连接客户机的场景,具有很好的可扩展性.
2.6.3 Flower 版本变化
相比于其他联邦学习框架,Flower 具有可扩展性、兼容性、易扩展等特性,使得使该框架不仅可以用于项目研究,还能方便地进行生产部署.除了2020年11 月发布的首个版本,2021 年1 月Flower 0.13.0版本实现了由集中式训练向联合式训练的转变.2021 年9 月的Flower 0.17 版本引入了虚拟客户端引擎,支持在单台机器或计算集群中实现大规模客户端的模拟.2022 年2 月Flower0.18.0 版本实现了对Android 移动端的支持.
3 其他联邦学习框架
除了目前业内较常用的几款开源框架外,其他的公司也根据自己的业务场景设计、开源了其框架.其中开源框架包括Fedlearner,FedNLP,FederatedScope;闭源框架有ClaraFL 和蜂巢.由于闭源框架的封闭性,本文后续的对比仅针对开源框架进行.
3.1 其他开源框架
3.1.1 Fedlearner 框架
字节跳动公司在2020 年初就开源了联邦学习框架 Fedlearner,该框架可以支持各类联邦学习模式,包括模型管理、训练任务管理等模块[42].与微众银行等开源框架不同,Fedlearner 实行产品化工作,将模块部署于平台侧和广告主侧,注重于在推荐行业开展联邦学习,如图24 所示.
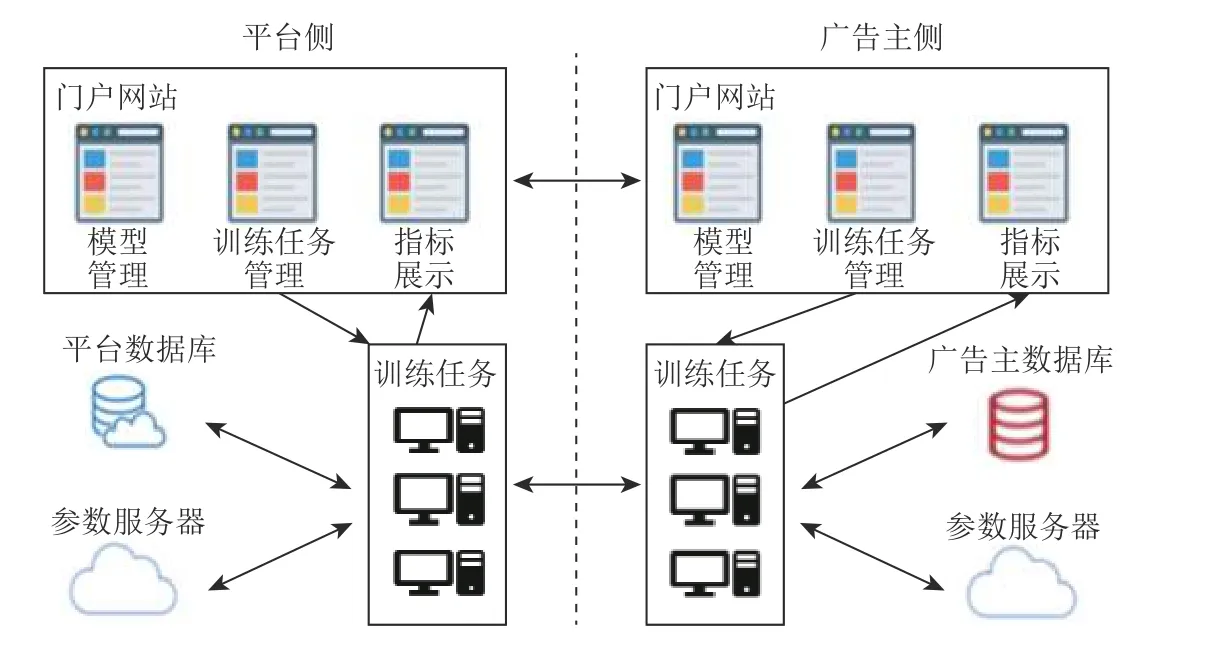
Fig.24 Fedlearner architecture图24 Fedlearner 架构
Fedlearner 的主要架构如图24 所示,主要流程可以概括为3 个部分:数据求交、模型训练和部署.
1)数据求交
在进行联邦学习前,首先要对训练双方数据求交集,找到共有的数据特征,数据求交的方法有2 种:流式数据求交和隐私集合求交(private set intersection,PSI)数据求交.①流式数据求交.流式数据通常是指由共同在线流量产生的数据,它们的数据落盘时间、样本存储可靠性都不能做到一致,且不同的训练方还存在样本缺失和样本顺序不统一的问题.因此,Fedlearner针对这些数据采取了流式数据求交的方法.②PSI 数据求交.对于各方独自持有的数据,例如不同机构的用户信息数据,Fedlearner 提供了PSI 加密数据求交的方式,通过该方式完成数据求交后,双方不会得到除交集信息之外的其他任何信息.
2)模型训练
由于字节跳动公司在推荐场景有丰富的技术资源,因此模型训练部分包括神经网络模型训练(支持横向和纵向联邦学习)和树模型训练(SecureBoost 算法).
3)部署
为了实现一键式部署,Fedlearner 的设计团队推出了Kubernetes+HDFS/MySQL/Elasticsearch 的部署模式.其中,Kubernetes 管理集群和任务;HDFS 负责数据存放;MySQL 负责存储系统数据;Elasticsearch 用于实现一个动态可扩展的集群,实现主节点、客户端和数据节点的多角色部署.由此,用户可以利用Helm Chart 轻松完成大规模部署.
3.1.2 FedNLP 框架
除了工业界,南加州大学Lin 等人[43]也开源了首个以研究为导向的自然语言处理联邦学习框架(federated learning natural language processing, FedNLP).其具体框架如图25 所示,主要由应用程序层、算法层和基础架构层这3 层组成.

Fig.25 FedNLP architecture图25 FedNLP 架构
1)应用程序层
应用程序层定义了数据管理、模型定义和自然语言处理(natural language processing,NLP)训练器3个功能模块.①数据管理.在数据管理中,4 种不同类型的数据管理负责控制从加载数据到返回训练函数的整个工作流程.用户可以根据需要开展联邦学习任务,实现自定义数据管理.②模型定义.FedNLP 提供了Transformer 和LSTM 模型.其特点是与HuggingFace Transformers 库兼容,研究人员可以直接应用现有NLP生态中各种类型的Transformer,无需重新设计.此外,Fedlearner 也支持LSTM 模型,以实现一些特定的联邦学习案例.③NLP 训练器(单进程角度).该NLP 训练器不需要研究人员了解分布式系统的内容即可完成设定,即用户只需完成单进程代码编写.为实现联邦训练,用户需要继承应用层的训练分类来实现操作:获取本地模型参数并传输至服务器、获取服务器聚合后模型并更新本地模型参数.
2)算法层
算法层由服务器管理和客户端管理核心对象组成,其作用是集成基础结构层的通信模块,以完成分布式算法协议(如FedAvg,FedProx,FedOpt 等)和分布式训练.同时,用户也可以通过将自定义的训练方传递给算法API 来自定义训练方,API 的参数包括模型、数据和单进程训练器.
3)基础架构层
该层包括分布式计算、训练传输、训练引擎3 个模块.其中分布式计算模块主要负责管理各联邦学习参与端,进行GPU 资源分配.训练传输模块中使用统一抽象的通信管理来完成复杂的算法通信协议.当前,该架构支持MPI,RPC,MQTT 通信后端.其中MPI 主要用于满足单个集群中的分布式训练需求;RPC 主要用于满足跨数据中心的通信需求(例如,跨孤岛联邦学习);MQTT 主要用于满足智能手机或物联网设备的通信需求.训练引擎模块的主要作用是通过训练分类重用现有的深度学习训练引擎.虽然该模块的当前版本是基于PyTorch,但它可以轻松支持TensorFlow等框架.同时,未来该框架可能会考虑在此级别上支持通过编译器技术优化的轻量级边缘训练引擎.
3.1.3 FederatedScope
FederatedScope 是由阿里巴巴达摩院研发、开源的框架[44].该框架采用事件驱动的编程范式,用于支持现实场景中联邦学习应用的异步训练,并借鉴分布式机器学习的相关研究成果,集成了异步训练策略来提升训练效率.具体而言,FederatedScope 将联邦学习看成是参与方之间收发消息的过程,其通过定义消息类型以及处理消息的行为来描述联邦学习过程.
如图26 所示,FederatedScope 通讯模块由信息和通信两部分组成,在服务器和客户端之间交互.信息主要由发送方、接收方、“TYPE”和数据载体4 部分组成,发送方和接收方用于信息的跟踪和验证,“TYPE”用于区分信息的类型,数据载体用于保存交换的信息.

Fig.26 FederatedScope architecture图26 FederatedScope 架构
FederatedScope 的优点在于不需要开发者将联邦学习的过程用顺序执行的视角来完整描述,而只需采用事件驱动的方式增加新的消息类型和消息处理行为,系统协助完成自动调参和高效异步训练,降低了所需的开发量以及复杂度.
之后该团队开发了FS-G (FederatedScope-GNN),一种基于FederatedScope 面向于图神经网络的联邦学习(GFL)框架[45].FS-G 包含了一个FGL 包,用于构建可配置、统一、全面的基准.其系统架构如图27 所示.

Fig.27 FS-G architecture图27 FS-G 架构
FS-G 系统组件功能为:
1)GNN 模型库模块用于处理不同级别任务;神经网络模块构建不同结构的GNN;GNN 训练方封装本地训练方法接口;图数据库模块允许用户通过配置数据集、分割器、转化器以及数据下载器来构建联邦学习数据集.
2)图学习后端模块可对接包括TensorFlow,Pytorch,JAX 在内的多种主流机器学习框架以及 SQL 前端.
3)FGL 运行模式模块为FS-G 的运行调用接口,可接收配置参数信息并返回训练结果指标集合.
4)模型调优组件模块为模型调整组件.超参数优化模块用于自动调整参数,通过减半算法(SHA)加快超参数评估和搜索,降低资源消耗.监控器模块通过可视化损失函数以及准确率等指标监控训练过程.个性化模块允许用户在Non-IID 的条件下调整模型参数或者实现GNN 的超参数个性化.
5)攻击与防御模块主要继承了现成的各种主动和被动隐私攻击方式,包括成员推理攻击、属性推理攻击和标签推荐攻击等.隐私安全保护策略,包括差分隐私、多方安全计算.
3.2 闭源框架
英伟达也推出了一款主要应用目标为医院和医疗机构的联邦学习框架ClaraFL[46].该框架的特点是客户端可以部署于面向边缘的英伟达服务器上,在本地进行模型训练,并通过联邦学习的方式实现数据交流,从而与多参与方共同训练出更精准的全局模型.ClaraFL 可以将患者数据保存在医院内部,实现隐私保护的同时,帮助医生进行高速而准确的诊断.由于单个医疗机构的数据量有限,基于ClaraFL 进行联邦学习可以有效汇总海量医疗数据,打破数据壁垒,提高医疗救治水平.
此外,平安科技也推出了一款主要应用于物流行业的联邦智能框架——“蜂巢”.该框架的特点是支持定制化,采用了国密SM2、国密SM4 以及差分隐私和同态加密等加密方式,以满足不同场景所需的不同保密级别.
3.3 框架对比分析
在3.1 节介绍的开源框架中,框架在隐私泄露风险和数据加密都有各自的方案.其中FedNLP 和FederatedScope 共同支持差分隐私的加密技术.在此基础之上,FederatedScope 除了支持多方安全加密和同态加密之外,还提供了主流的隐私评估算法.Fedlearner则是采用嵌入式的保护框架.例如采用PSI 加密数据或是采用Paillier 算法对梯度加密.在算法级别,FedNLP,FederatedScope 和Fedlearner 三者均支持传统的机器学习算法、深度学习网络,但是在学习类型中FederatedScope和FedNLP 都支持横向联邦学习和纵向联邦学习,而Fedlearner 暂时仅支持横向联邦学习.在计算范式方面,三者均支持单机模拟和分布式训练,其中FederatedScope为单机模拟和分布式部署提供了统一的算法描述和接口.除了单机和分布式2 种模式外,FedNLP 还支持移动设备端的训练.针对可视化系统的支持,Fedlearner自身有可视化图表功能,FedNLP 借助wandb 模块完成对框架的监控.
4 框架对比分析
为了更好地根据应用场景以及应用需求选择相应的开源框架,本节从各框架支持的隐私机制、机器学习算法、计算范式、联邦学习类型、训练架构以及可视化等方面对目前应用较广的6 个开源框架进行了深入分析和对比,具体如表3 所示.
降低隐私泄露风险、提升私密数据安全性是联邦学习的初衷之一,因此各框架均采用多样的加密技术(如同态加密、多方安全计算和差分隐私)以保障参与方的隐私安全.其中同态加密主要是利用具有同态性质的加密函数对数据加密,实现对加密后的数据处理和保证隐私安全.Deffie-Hellman 算法的通信双方通过交换信息生成共同密钥,并利用密钥进行对称加密通信.RSA 加密算法则是非对称加密技术,由一对公钥和私钥组成密钥.
多方安全计算是指在无可信第三方情况下,通过多方共同参与安全完成协同计算.SPDZ 是许多联邦学习框架采用的协议,它包含混淆电路、秘密共享和不经意传输等技术.ABY3 协议则综合采用算术分享、布尔分享和混淆电路协议.
基于差分隐私的数据保护,是通过向数据或模型参数注入随机噪声以实现隐私保护,同时防止对模型的推理攻击.目前的联邦学习框架主要采用DPSGD 算法对随机梯度下降算法进行改进而使其具有差分私有性.
PySyft 具有相对完善的隐私保护机制,同时应用差分隐私、基于CKKS 的同态加密和基于SPDZ 协议的安全多方计算来保障数据安全;而TFF 和Flower仅采用了差分隐私技术.与PySyft 类似,FedML 同样提供了较为全面的隐私保障,同时它还能抵御对抗攻击,采取RFA 和KRUM 等技术让联邦学习具有鲁棒性.PaddleFL 利用差分隐私和基于PrivC 和ABY3的安全多方计算来实现安全联邦学习.FATE 在隐私机制上主要采用同态加密技术和安全多方计算,其中前者包括Paillier,RSA,Affine,IterativeAffine 等加密算法,后者基于SPDZ、混淆电路、不经意传输等密码学协议实现.
在算法级别,FATE 框架最为全面,对于横向联邦学习、纵向联邦学习和联邦迁移学习均支持许多机器学习算法.该框架集成了各种线性模型和DNN,RNN,CNN 等神经网络.此外,除了FATE 提供了SecureBoost 安全树外,其他框架均尚未支持决策树相关算法.PaddleFL 在横向联邦方面提供了DP-SGD等算法;Flower 在横向联邦方面,除了对常规神经网络有很好的支持外,对Sklearn 中提供的算法也有很好的支持.对于纵向联邦学习,支持关于神经网络和逻辑回归的相关算法.TFF,PySyft,FedML 可以实现线性模型和神经网络算法.总而言之,FATE 和PaddleFL倾向于提供现成算法供用户直接使用,而PySyft,TFF,FedML 则更侧重用户构建自定义联邦学习算法.
计算范式方面,针对科学研究、测试开发和工业生产等不同使用场景,需要有不同的计算范式,因此是否拥有多样化的计算范式是衡量联邦学习框架的一个重要因素.目前较多学者主要采用支持3 种范式的PySyft,FedML,Flower 开展学术研究;此外,Flower相较于其他框架,提供了一套用于模拟真实场景下网络拥塞和大规模并发的机制,使得模拟场景更贴近现实场景.FATE 作为工业级联邦学习框架,可进行单机模拟和分布式计算,虽然在工业应用上较有优势,但暂未支持移动设备端训练.PaddleFL 目前主要支持单机模拟与基于拓扑结构的分布式训练,但研究团队指出在下一版本中将开源手机端的联邦学习模拟器.
联邦学习中服务器与客户端间存在大量的通信,需要保证通信的效率和可靠性.多数开源框架都利用Google 提供的gRPC 来实现RPC 通信,包括TFF,FATE,Paddle FL,Flower.RPC 框架可以有效连接跨数据中心的设备,适用于相互之间数据传输频繁的Crosssilo 联邦学习场景.FedML 支持的通信后端最为丰富,包括MPI,gRPC,MQTT,这是FedML 框架的一个突出优势.此外,Flower 和FedML 的通信模块采用了灵活的设计,可以通过替换底层的通信管理模块来使用自定义的通信协议.
对于工业生产应用,利用FATE 可以轻松构建端到端的联邦学习 Pipeline ,包括生产服务、建模训练、模型管理、生产发布和在线推理等方面.PySyft 尚未提供大规模或工业部署方案,更适合作为学术研究的工具.Flower 提供了大规模的部署方案以及网络模拟,此外也在移动端、无线端提供了跨平台支持,适合作为模拟大规模场景下的学术研究工具.TensorFlow,Federated 和FedML 同样缺少对线上生产的完善支撑.
可视化方法可以帮助研究人员形象了解复杂模型的本质和过程[47],从而进行模型设计和模型调试等任务[48].截至目前,只有FATE 和FedML 提供了可视化功能,其他框架尚未推出相关功能.相对于其他框架,FATE 设计了针对模型训练过程的可视化组件,可以记录联邦学习的全流程.对于联邦学习了解较少的研究人员来说,使用FATE 可以更好地跟进联邦学习过程,完成模型调试等操作.
异步聚合方面,FATE 提供异步聚合的接口,其他框架未直接提供异步聚合接口,但可以基于框架进行2 次开发实现异步聚合的功能.现有原生的框架本身都提供了比较健全、完善的方法接口,用户可以根据需求编写自己的算法来满足不同的联邦学习场景的需要,如用户掉线场景.
5 基于开源框架的联邦学习实验
为了帮助研究人员更好地根据应用需求选择合适的联邦学习框架,本节以2 个不同的场景为例,阐述如何选择以及搭建联邦学习框架,并基于搭建的框架进行实验.
5.1 应用场景1:基于IoT 的图像识别
随着智能设备感知能力和计算能力的不断提升,越来越多的设备具备了微型计算机的能力.而如何利用这些智能设备的本地数据和计算资源创造更有益的技术成为了目前的研究热点之一.因此,我们选择的第1 个应用场景是:在IoT 网络中,通过在分散的IoT 设备中训练一个图像分类模型,使其可以准确识别、分类图片.
对于此应用场景,其需求是在IoT 网络中部署联邦学习框架,分析已有的开源框架,目前FedML 和Flower 支持该需求.我们以FedML 为例搭建联邦学习框架,利用树莓派搭建IoT 设备集群,在MNIST 和CIFAR10 数据集上实现图片的分类任务.
5.1.1 实验基本设置
该系统主要包含4 台树莓派,并将其中1 台作为中心服务器,用于模型聚合;另外3 台作为客户机,基于本地数据集进行训练并上传模型.
算法:采用常规的联邦学习算法Fedavg.
其他参数:采用Adam 优化器,学习率为0.01.
数据集:为了测试搭建框架在不同数据集以及不同模型上的训练效果,分别基于真实数据集MNIST和CIFAR10 进行实验.
对比方法:①集群训练.联合3 台客户机的本地数据进行分布式联邦学习模型训练.②单机本地训练.单台客户机基于本地数据集进行模型训练.
5.1.2 基于MNIST 数据集的实验
MNIST 数据集包含了60 000 个样本(50 000 个训练集、10 000 个测试集).在MNIST 数据集中的每张图片由28× 28 个像素点构成,每个像素点用1 个灰度值表示.采用MobileNet 模型,模型由13 个Depthwise Separable 卷积层、1 个二元自适应均值汇聚层和1 个全连接层构成.图28 分别分析了客户端数据为500和5 000 这2 种情况下的联邦学习和单机的模型准确率收敛曲线.相比于单机本地训练,图28(a)下联邦学习可以提升12.4%的准确率;图28(b)下联邦学习可以提升2.3%的准确率.可见,在数据缺乏的情况下,联邦学习可以带来更大的收益.

Fig.28 Model convergence curves under MNIST dataset图28 MNIST 数据集下模型收敛曲线
5.1.3 基于CIFAR10 数据集的实验
CIFAR10 是1 个包含60 000 张图片的数据集.其中每张照片为32× 32 的彩色照片,每个像素点包括RGB 3 个数值,数值范围是 0~255.所有照片分属10 个不同的类别,分别是“airplane”“automobile”“bird”“cat”“deer”“dog”“frog”“horse”“ship”“truck”.其中50 000张图片为训练集,剩下的10 000 张图片属于测试集.
模型采用2 个5× 5 的卷积网络(每层有64 个通道),1 个2× 2 的最大池化层,2 个完全连接层(分别包含384 个单元和192 个单元),最后是一个softmax 输出层.该实验设置单机随机选择1 500 个数据(图29 (a))和5 000 个数据(图29(b))作为对比,观测在联邦学习和单机模式下训练模型准确率的收敛曲线.2 组对照实验中,联邦学习的准确率整体提升了8%,相较于传统的单机模式性能有所提升.

Fig.29 Model convergence curves under CIFAR10 dataset图29 CIFAR10 数据集下模型收敛曲线
5.2 应用场景2:医疗系统中的辅助病理诊断
人工病理诊断一般都要求医院具有较强的技术支持和医生具有较丰富的经验.而在一些医疗资源相对欠缺的区域,如果医生无法通过一些仪器进行辅助诊断,则可能存在误诊与漏诊情况.目前,人工智能的发展大大推动了智能药物研发、辅助医疗诊断、基因特性分析的发展,使得不同医疗机构之间共享医疗资源成为可能.因此,第2 个应用场景是:通过学习不同医疗机构的医疗数据,训练一个可以辅助医生进行病理诊断的模型.
对于此应用场景,我们最基本的设计需求是需要搭建一个支持数据隐私保护的分布式学习架构.虽然已有开源框架几乎都支持该需求,但是由于医院对其医疗数据的安全性要求特别高,且目前工业支持和应用较为成熟的只有FATE,因此,我们选择以FATE 为例搭建病理诊断模型的联邦学习系统,选用UCI 数据库中Wisconsin 州乳腺癌数据集[49]进行模型训练.
5.2.1 配置文件
1)dsl 文件.用来描述任务模块,以有向无环图(DAG)的形式组合任务模块.
2)conf 文件.设置各个组件的参数,如输入模块的数据表名、算法模块的学习率、batch 大小、迭代次数等.
5.2.2 参与各方角色
1)Guest.任务的发起者,代表数据应用方.
2)Host.数据提供方,为Guest 提供数据.
3)Arbiter.辅助多方完成联合建模,主要作用是聚合梯度或者模型.比如聚合各方本地模型,各方将自身梯度模型参数发送给Arbiter,Arbiter 进行联合优化等.
5.2.3 横向联邦场景
1)数据集.采用乳腺癌数据集Breast Cancer 作为实验数据.Breast Cancer 数据集有569 组31 维实例数据,30 维的诊断属性包括radius 半径(从中心到边缘上点的距离的平均值)、texture 纹理(灰度值的标准偏差)等,1 维的标签类分为WDBC-Malignant 恶性和WDBC-Benign 良性.该数据集中,469 条数据作为训练样本,100 条数据作为测试样本.从469 条训练样本中,选取200 条样本作为参与方A(host)的本地数据,将剩余的269 条样本作为参与方B(guest)的本地数据,测试数据共享.
2)任务.采用Breast Cancer 数据集在Logistic Regression 模型下进行医疗病例诊断.
3)对比方法.①联邦训练.联合参与方A,B进行联邦学习模型训练.②本地训练.参与方B基于本地数据进行模型训练.
实验结果如图30 所示.图30(a)为模型准确率的收敛曲线,在整个训练过程中,双方都达到了不错的效果,但是采用联邦学习的方式,相比于单机模式提高了2.3%的准确率.在图30(b)所示的模型损失函数的收敛曲线中,联邦学习的方式使得损失以更快的速度达到最小.相比于本地训练,联邦学习下模型的准确率有所提升.横向联邦学习可以联合多个参与者的具有相同特征的数据样本,提高样本的丰富性.

Fig.30 Breast Cancer horizontal federated learning图30 Breast Cancer 横向联邦学习
5.2.4 纵向联邦学习场景
1)数据集.采用Breast Cancer 数据集作为实验数据.其中,400 条数据作为训练样本,169 条数据作为评估测试样本.从400 条训练样本中,选取Breast Cancer数据集前20 个特征作为参与方A的本地数据,后10个特征以及标签作为参与方B的本地数据,测试数据参与方B独享.
2)任务.采用Breast Cancer 数据集在逻辑回归模型下进行医疗病例诊断.
3)对比方法.①联邦训练.联合参与方A和B进行联邦学习模型训练.②本地训练.参与方B基于本地数据进行模型训练.
实验结果如图31 所示.图31(a)为模型准确率的收敛曲线.在准确率方面:联邦学习的结果相较于本地训练这种方式,准确率提升了4.7%.在训练速度方面:联邦学习的结果也比本地训练加快了约10 轮.图31(b)为模型损失函数的收敛曲线,可以明显看出联邦学习的损失函数以更快的速度达到收敛.因此,从图31可以看出,纵向联邦学习可以联合多个参与者的共同样本的不同数据特征,丰富样本特征,提高模型的识别准确率.
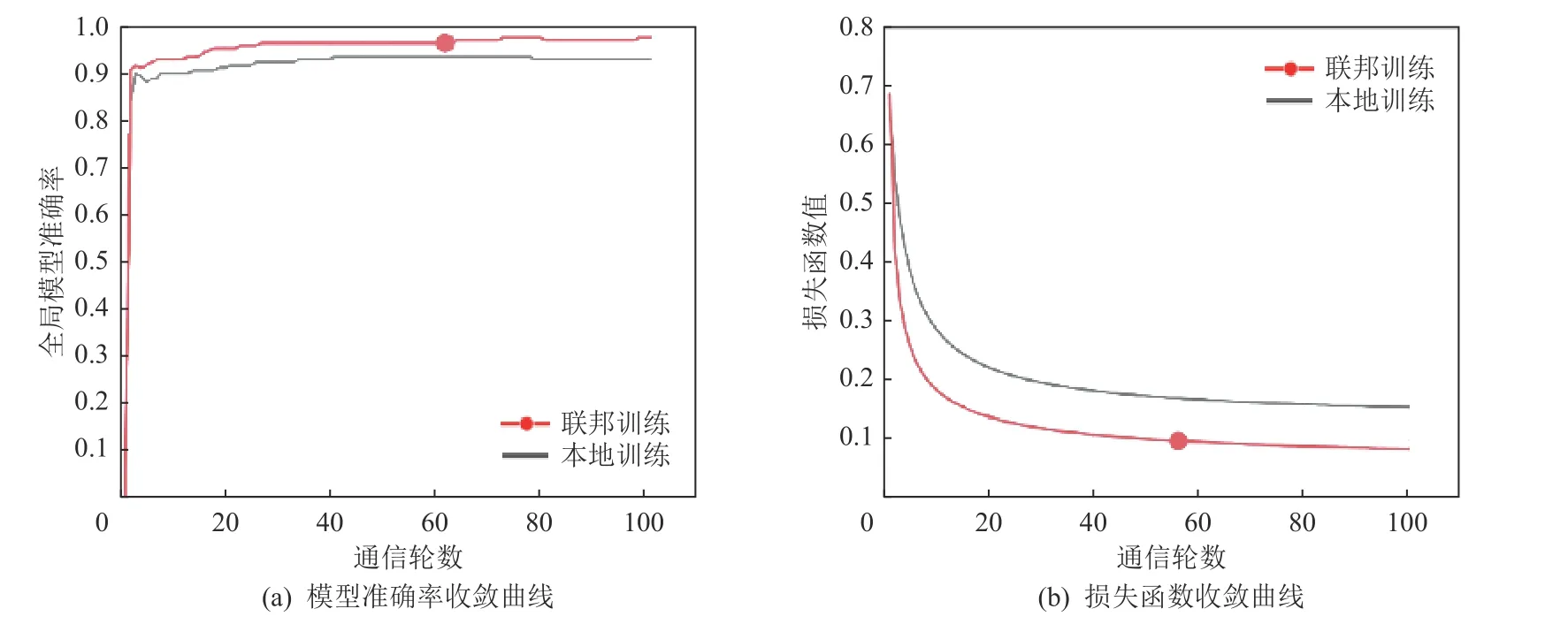
Fig.31 Breast Cancer vertical federated learning图31 Breast Cancer 纵向联邦学习
总之,从图30 和图31 表明,横向联邦学习和纵向联邦学习都可以有效提高模型的训练效果,同时,联邦学习的计算范式保证了用户本地数据的隐私安全.此外,在开展联邦学习时,需要根据场景选择合适的联邦学习模式,缺少样本数据可以选择横向联邦学习,缺少样本特征可以选择纵向联邦学习.
5.3 框架训练效率对比
为了进一步对比不同框架的效率,我们基于FedML和FATE 框架分别对Breast Cancer 数据集进行横向联邦学习模型训练和纵向联邦学习模型训练,从时间角度来比较2 个框架间的效率差异.服务器配置清单:CPU 为i5-4460,1.86 GHz,6 核;内存容量为16 GB;网络带宽为30 Mbps;操作系统为CentOS Linux release 7.9.2009.
实验结果如图32 所示,横向联邦学习到达指定目标准确率时,FedML 框架比FATE 框架耗时少8s,有8%左右的速度优势.究其原因,FedML 相比于FATE更轻量级,时间优势主要体现在框架启动过程中,但整体上2 个框架在横向联邦学习训练效率上比较相近.纵向联邦学习到达指定目标准确率时,FedML 框架只需103s,相比于FATE 框架速度提升了86%.这主要由于FATE 框架中的纵向联邦学习采用了多方安全的样本对齐算法,该算法基于RSA 加密算法和散列函数实现,在增强隐私保护的同时严重降低了模型的训练效率.

Fig.32 Comparison of training time of different frame models图32 不同框架模型训练时间对比
FATE 框架相比于FedML 有隐私保护机制支持,因而不可避免地造成效率上的损失.其他框架也是如此,追求数据的高度隐私安全会造成训练效率的急剧下降,但可以通过并行加密计算等技术加速训练,提高效率.
6 挑战与展望
尽管联邦学习已有实际落地的项目,但是其仍然处于发展初期,对于各种复杂的学习场景还有很多待解决的挑战问题以及待提升的技术,通过对目前联邦学习开源框架的研究和应用现状的分析,本文总结了5 点挑战与展望.
1)隐私安全
隐私安全问题是联邦学习研究的动因.虽然通过训练数据不离开本地进行训练可以保护数据隐私信息的安全性,但在实际应用过程中,由于联邦学习的训练过程包含多个复杂环节,因而每个环节依然面临许多安全与隐私挑战,如投毒攻击[50-51]、基于GAN[52-53]的攻击、推理攻击[54]、通信节点攻击和中央服务器攻击等.多数实验证明,即使只上传模型的相关参数,仍然能反推出终端的隐私数据[55-56].针对以上威胁,联邦学习框架在安全和隐私保护方面采取了一系列的措施,如差分隐私[57-58]、同态加密[59-60]和安全多方计算[61-62]等.虽然这些技术能实现安全联邦学习,但仍然存在一些易受攻击的漏洞需要填补.此外,采用隐私技术的同时也会造成较大的通信开销,因此如何平衡模型安全和通信也是一个相当大的挑战.
2)效率、准确性和隐私的权衡
增强联邦学习的隐私保护,在一定程度上牺牲了模型训练效率与结果准确性.在联邦学习场景下,一个模型训练包括大规模的数据样本和复杂计算,此时运算效率是一个重要问题.联邦学习框架采用复杂的加密系统以保护隐私,而这需要庞大的计算量和通信量.网络带宽有限、设备掉线等通信问题都会使传输的数据量和传输速度下降[63-64],从而导致联邦学习的效率不高.结果准确性方面,如果加密级别太高或添加噪声过多,无疑会降低模型的准确性.因此,如何在保障隐私安全的前提下提高联邦学习的训练效率和结果准确性,实现安全、效率和准确性之间的平衡[64-66],是联邦学习框架需要解决的问题.
3)激励机制
联邦学习是一个多方数据联盟的技术,只有提高参与用户的数量才能训练出更精确有效的模型.如果没有采取合适的激励机制,那么获取的数据和训练的模型质量受限.同时,各方可能因利益冲突、互不信任等问题导致最终合作失败.如何制定合理的激励机制是联邦学习框架面临的一大挑战.未来,联邦学习框架不仅需要考虑隐私保护,更要考虑如何通过共识机制实施公平激励[67-68],以实现联邦集体利益最大化.各框架可以通过计算各参与方对模型的贡献建立数据记录机制(例如记录于区块链中[69-70])以激励不同程度参与方,从而形成最优联邦组织.
4)异构性与个性化
现有的联邦学习框架要求全体参与方训练出一致的全局模型,而这在实际复杂的物联网应用中是不现实的.由于设备、统计和模型的异构性[71],现有的联邦学习模型不能直接在物联网设备中有效应用.为了解决异构性挑战,联邦框架需要考虑个性化处理[72-74],让每个设备获得高质量的个性化模型,如采取多任务和元学习的方法.
5)跨框架交互
随着联邦学习逐渐进入大众视野,不同行业的公司都推出了各自的联邦学习框架.而这在丰富市场选择中也出现了新的问题:由于各框架技术实现的差异和安全协议的区别,不同框架所托管的数据在实际应用中无法跨框架交互.不同联邦学习技术框架之间互联的阻碍限制了跨行业数据的交流和行业间融合互通,制约了数据价值的释放.因此,联邦学习框架应朝着数据跨框架交流、算法跨框架部署、任务跨框架执行的方向发展,使不同行业可以在统一的标准下进行联邦学习,实现行业互联互通,推进数字化融合发展.
7 结 论
作为破解“数据孤岛”问题和保障隐私安全的有效手段,联邦学习的重要性日益凸显.而联邦学习的有效应用主要依托于开源框架的研究和建设.因此,考虑到联邦学习开源框架的重要性,本文重点从系统架构、系统功能、版本变化3 方面介绍开源框架FATE,PySyft,TensorFlow Federated,Paddle FL,FedML,Flower.并从隐私机制、机器学习算法、计算范式、学习类型、训练架构、通信协议、可视化等方面对比总结了各框架的优劣势.为了更好地帮助读者搭建开源框架,本文给出了2 个不同应用场景框架搭建的实例.并基于目前框架存在的开放性问题,从隐私安全、激励机制与置信规则、跨框架交互等方面讨论了未来可能的研究发展方向.总之,本文对于联邦学习未来的研究具有较好的参考意义,可为开源框架的建设创新、结构优化、安全优化以及算法优化等提供有效思路.
作者贡献声明:林伟伟提出文章的整体思路和框架;石方和曾岚负责撰写论文;李董东和许银海负责完成实验;刘波提出指导意见并修改论文.
