开源软件缺陷预测方法综述
2023-07-20常继友荣景峰王子昱张光华伍高飞胡敬炉张玉清
田 笑 常继友 张 弛 荣景峰,6 王子昱 张光华 王 鹤 伍高飞,4 胡敬炉 张玉清,6,7
1 (西安电子科技大学网络与信息安全学院 西安 710126)
2 (国家计算机网络入侵防范中心(中国科学院大学)北京 101408)
3 (河北科技大学信息科学与工程学院 石家庄 050018)
4 (广西密码学与信息安全重点实验室(桂林电子科技大学)广西 桂林 541000)
5 (早稻田大学情报生产系统研究科 日本 808-0135)
6 (海南大学网络空间安全学院 海口 570228)
7 (中关村实验室 北京 100094)
软件缺陷(software defect),也称Bug 或Fault,是由于开发过程或者维护过程中存在的错误而产生的导致计算机无法正常运行的错误或者功能性缺陷.当在软件测试期间发现缺陷时,这些缺陷可能处于多种不同的状态,常见的缺陷状态信息如表1 所示,如果缺陷没有被及时发现或者修复,则可能会影响软件系统的功能从而造成巨大的财产损失甚至威胁人身安全.

Table 1 Software Defect State Description表1 软件缺陷状态描述
传统的软件缺陷检测方法,包括手动测试、自动化分析、静态分析、代码审查等[1],但是由于人力资源和时间资源有限,传统的缺陷发现技术只能检测到较少的缺陷.基于人工智能的软件缺陷预测技术包括机器学习和深度学习,可以预测更详细的软件缺陷信息.软件缺陷的检测和预测方法对比如表2 所示,软件缺陷预测可以在较少的时间内发现更多的软件缺陷,减少用于发现和修复缺陷的成本.

Table 2 Comparison of Defect Detection and Defect Prediction Methods表2 缺陷检测与缺陷预测方法对比
软件缺陷预测根据软件历史开发数据以及已发现的缺陷数据,借助机器学习等方法来预测软件项目中的缺陷数目和类型[2].软件缺陷预测模型可以确定哪些组件具有最大的安全风险,软件工程师可以根据模型预测结果做出风险管理决策,指导安全检查和测试,并确定软件安全防御工作的优先级.
早期研究者利用源代码度量从软件源代码中提取缺陷特征,静态分析样本中的缺陷数量,后来研究者定义与软件缺陷强相关的度量,提高分类器的效率.基于软件度量的缺陷预测模型如图1 所示,模型首先从开源公共仓库或者开源社区中抽取程序模块;然后定义与软件缺陷强相关的度量元,提取对应的度量特征从而构造出缺陷数据集;最后通过软件缺陷数据集训练软件缺陷预测模型,软件缺陷预测模型就能够预测目标程序模块的软件缺陷相关信息.

Fig.1 Defect prediction model based on software metrics图1 基于软件度量的缺陷预测模型
基于软件度量的缺陷预测模型的缺陷预测方法较为简单,只需要手工定义与软件缺陷相关的度量元,但是该模型无法挖掘出与缺陷相关的更深层次信息,应用范围比较局限,模型的优劣取决于数据集和分类器.
随着深度学习的发展,研究者开始从复杂的代码中自动获取更深层次的特征,表征程序的语法语义信息.基于语法语义的缺陷预测模型如图2 所示,模型首先利用文本挖掘技术对源代码的标识符、函数名和运算符进行解析并标记,然后提取软件缺陷相关特征并抽象表示,最后通过编码器模型生成向量并送入神经网络预测模型进行训练.
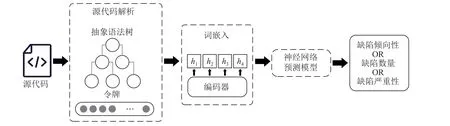
Fig.2 Defect prediction model based on semantic and syntactic图2 基于语法语义的缺陷预测模型
漏洞是一种特定的软件安全缺陷,受软件缺陷预测研究的启发和推动,漏洞预测通过挖掘软件实例存储库来提取和标记代码模块,预测新的代码实例是否含有漏洞,减少用于发现和修复漏洞的成本.与缺陷预测领域相同,漏洞预测研究领域也可以划分为基于软件度量的漏洞预测和基于语法语义的漏洞预测模型.基于软件度量的漏洞预测模型使用人工设计的代码变更、耦合和内聚等度量,表征漏洞的相关信息[3].由于漏洞数量极少且种类繁多,这些特征不能完全理解代码本身的含义且预测效果较差,因此该模型逐渐被舍弃.
随着人工智能技术在各个领域的应用,人工智能技术被用于缺陷预测和漏洞预测任务,漏洞预测模型的效果因此得到了提升.为了能够表征漏洞更多的信息,研究人员使用文本、抽象语法树(abstract syntax tree,AST)、代码属性图等多种方式提取软件代码中的特征,挖掘代码的语法语义信息,转化为向量的数字表示,随后使用机器学习或者深度学习方法预测项目中的漏洞.细粒度的漏洞预测是漏洞领域的研究热点,为了提取更细粒度的特征,一些研究人员将漏洞函数表征为漏洞切片,使用注意力机制预测漏洞的位置信息.本文使用defect prediction,software defect prediction,fault prediction,vulnerability prediction 和vulnerability detection 等关键字进行检索,收集并调研了2000年至2022 年来自IEEE Xplore、ACM、Digital Library、SpringerLink、ScienceDirect 和中国知网(CNKI)等国内外数据库和软件工程领域与网络安全领域的国际期刊和顶级会议上的论文,总结了开源软件缺陷预测已有的研究成果,并指出了该研究领域的未来发展趋势.缺陷预测和漏洞预测各年份统计的相关文献数量如图3 所示.
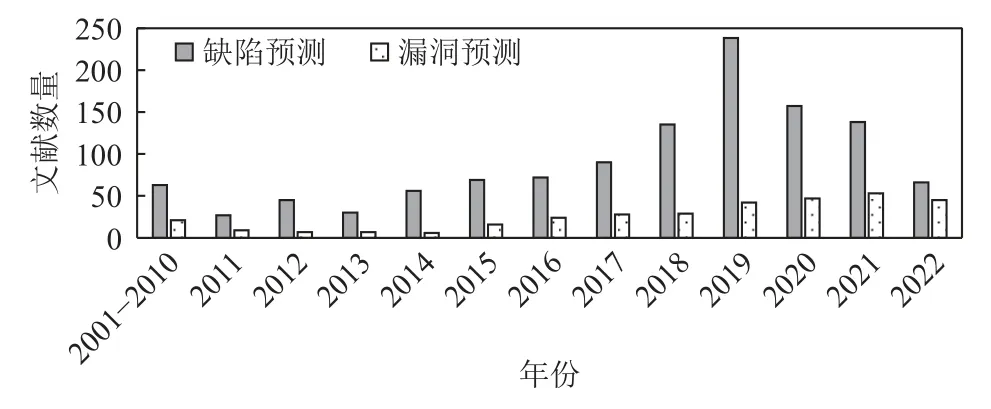
Fig.3 Number of literatures related to defect prediction and vulnerability prediction图3 缺陷预测和漏洞预测相关文献数量
本文的主要贡献有4 个方面:
1)广泛收集并调研了2000 年至2022 年12 月软件缺陷预测现有文献,从数据集、评价指标、模型构建3 个方面分析了缺陷预测的研究现状;
2)以机器学习和深度学习技术为切入点,总结了基于软件度量和基于语法语义2 类预测模型;
3)分析了软件缺陷预测模型和漏洞预测模型之间的区别和联系,探讨了缺陷预测和漏洞预测之间的可移植性;
4)归纳和分析了缺陷预测技术领域的不足,指出了当前面临的机遇和挑战,给出了未来发展方向.
1 缺陷预测框架
软件缺陷预测技术包括静态缺陷预测技术与动态缺陷预测技术.静态缺陷预测是目前主流的软件缺陷预测技术,它通过挖掘软件历史仓库,手工定义与软件缺陷相关的度量元和从源代码本身表征程序的语法语义信息2 种方式,借助机器学习或深度学习方法提前发现软件缺陷.动态缺陷预测通过研究软件缺陷随时间变化的趋势,预测软件的下一个版本或下一个生命周期中可能出现缺陷的数量.基于动态软件缺陷预测技术的核心是数学模型,包括Rayleigh分布模型[4-5]、指数分布模型[6-7]、S 曲线分布模型[8-10].对于动态软件缺陷预测模型来说,需要对软件产品进行长时间的监测以获取软件的数据.然而收集大量的开发数据需要耗费大量的成本,并且不同的数据集和动态缺陷预测模型会导致预测精度不尽如人意.因此缺陷预测的大部分研究目前都集中在静态缺陷预测,后文的缺陷预测特指静态缺陷预测.
本文以机器学习和深度学习技术为切入点,介绍了基于软件度量和基于语法语义的2 类缺陷预测模型,这2 类缺陷预测模型框架如图4 所示.
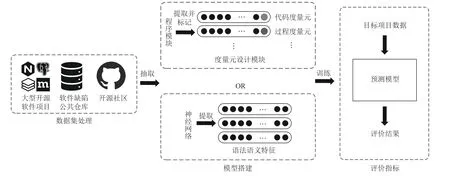
Fig.4 Defect prediction framework图4 缺陷预测框架
缺陷预测框架由3 部分组成:
1)从软件缺陷公共仓库和开源社区收集缺陷数据;
2)定义与软件缺陷高度相关的度量元,提取程序模块的软件度量特征或者使用神经网络自动提取源代码的语法语义特征,利用机器学习或深度学习技术构建预测模型;
3)使用性能评价指标对预测模型进行评价.
下文从缺陷预测框架入手,分别介绍了缺陷数据、模型的评价指标以及缺陷预测模型的搭建.
2 缺陷数据集
软件缺陷预测模型的构建离不开缺陷数据集,但缺陷数据集中的维数灾难和类不平衡问题影响着软件缺陷预测模型的质量.本节从缺陷数据集的来源和缺陷数据预处理2 个角度对缺陷数据集进行分析.
2.1 缺陷数据集来源
软件缺陷数据集包含了软件项目全生命周期的缺陷数据信息,常常被用于软件缺陷预测的研究.
开源软件缺陷数据集主要来源于软件缺陷公共仓库、开源社区和大型开源软件项目.国内外研究人员使用NASA,PROMISE 等公共库进行了一系列研究,对软件缺陷预测的发展做出了贡献,这些公共库提供了包含了Apache,Eclipse 等真实软件项目的数据集,经过验证和标注,具有较高的数据质量,通过对这些公共仓库数据的分析和实验,研究人员能够评估不同方法在缺陷预测方面的性能和效果.随着越来越多的开源软件项目公开,一些研究者选择使用大型开源软件项目,如Nginx,Redis 和Gedit 等,评估不同的缺陷预测模型在预测软件缺陷方面的准确性和有效性.SourceForge,GitHub 等开源社区提供了与软件相关的特征,研究人员利用源代码、软件描述、错误修复、审查过程等开源软件提供的信息,发现深层隐藏的软件缺陷[11].
本文对2000 年至2022 年12 月的论文进行了整理分析,软件缺陷公共仓库的数据来源及其统计信息如表3 所示.大部分研究人员使用NASA,PROMISE和AEEEM 中的KC3,PC4,CM1,PC3,KC1 和PC1 等数据集,公共数据集的属性如表4 所示,这些数据集发布在2005 年左右,主要使用C,C++,Java 等语言开发.除了使用NASA,PROMISE 中的数据集外,一些研究者使用Nginx,Redis,Gedit 等大型开源软件,在软件缺陷预测领域开展一系列研究,开源软件项目缺陷数量统计如表5 所示,文献[12]使用了2 个连续版本的6 个开源软件项目Camel,Flume,Tika,Gedit,Nginx,Redis,研究软件模块在文件级别的缺陷.文献[13]使用了多个版本的4 个开源软件项目Gedit,Nagios Core,Nginx,Redis,这些项目主要使用C/C++语言开发,文献[13]的作者从缺陷修复报告中收集到了这些项目的缺陷信息.此外,文献[14]探究6 个项目在开源软件项目的不同版本中的代码变更,并分析了这些变更对产生缺陷的可能性,开源软件代码变更对缺陷的影响如表6 所示.

Table 3 Public Warehouse Data Sources for Software Defect Modeling表3 软件缺陷模型的公共仓库数据来源

Table 4 Attributes List of the Publicly Available Datasets表4 公共数据集属性列表
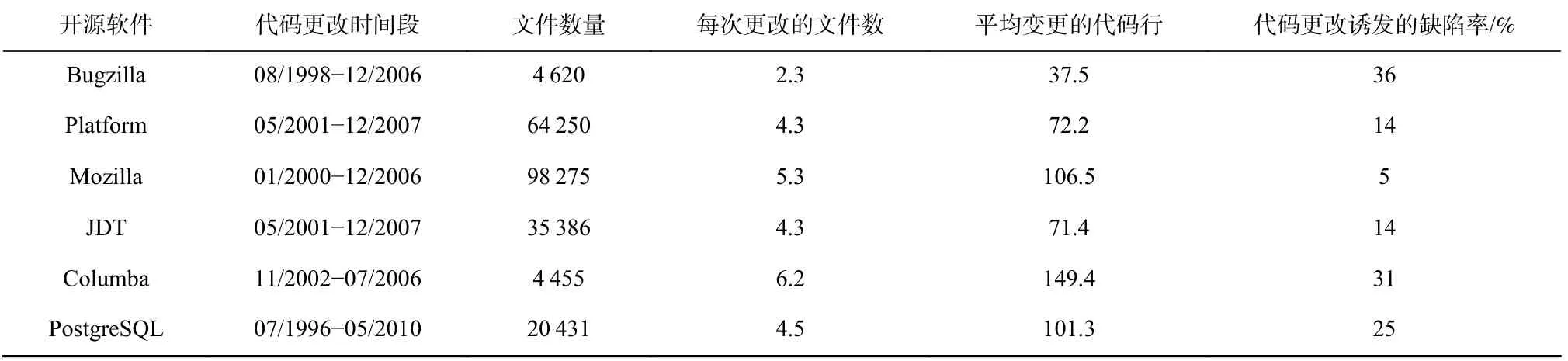
Table 6 Impact of Code Changes on Defects in Open-Source Software Projects表6 开源软件项目代码变更对缺陷的影响
经过调查发现,NASA,PROMISE 等软件缺陷公共仓库的数据集由LOC[15],Halstead[16]等度量元的属性和包含缺陷的类标记组成.大部分研究者使用NASA,PROMISE 等软件缺陷公共仓库的数据集进行模型的比较和重现,一些研究者使用Nginx,Redis,Gedit 等真实世界的开源软件,在软件缺陷预测领域开展一系列研究.这些公开数据集往往具有类不平衡、维度过高、预测特征不足以及分类标签不足等缺点[17].数据集中维数灾难和类不平衡的问题可以通过特征选择[18]、降维[19-29]等方法进行处理,但是特征不足和分类标签不足的问题则需要通过定义更细粒度的软件缺陷度量元来解决.
2.2 缺陷数据预处理
缺陷数据集中类不平衡[23-36]、维度过高[37-43]、特征不足[44-45]以及分类标签不足[46-50]等问题会降低软件缺陷预测模型的性能,在使用缺陷数据时对其进行预处理,可以提高缺陷预测模型的质量,部分缺陷数据预处理的方法如表7 所示.
2.2.1 类不平衡
程序模块中80%的缺陷集中在20%的文件中,缺陷的数量远少于非缺陷的数量,缺陷数量的不平衡分布会导致模型的预测性能受到严重影响.
20 世纪90 年代,研究人员从数据层面解决类不平衡问题,包括随机欠采样(random under sampling,RUS)[20]、随机过采样(random over sampling,ROS)[21-22],这些算法简单高效,但是效果取决于模型的训练算法.文献[23]针对ADASYN[24]自适应过采样算法造成的噪声问题和CURE-SMOTE[25]层过采样算法分类准确性问题,提出了一种AJCC-Ram 多层次过采样算法,使用ADASYN 改进算法进行边缘采样,CURESMOTE 算法进行中心区采样,分层次进行样本生成,采用最近列表噪声识别(closest list noise identification,CLNI[26])方法对噪声进行过滤.
文献[27]使用邻居清理学习(neighbor cleaning learning,NCL)去除不平衡数据集中的重叠样本,使用集成随机欠采样并重复多次,解决了缺陷数据集偏态分布的问题.结果表明,与CLNI、基于聚类的噪声检测(clustering-based noise detection,CBND)[28]两种数据清洗算法相比,NCL 在G-mean 和AUC 评价指标上表现更优.
文献[29]提出一种新的基于邻域的欠采样(neighbourhood based under-sampling,N-US)算法来处理类不平衡问题.N-US 首先识别缺陷实例的邻域,计算出邻域中的干净实例,并从有缺陷的实例的邻域中最近的位置消除干净实例.结果表明,与RUS 等基线方法相比,N-US 能够避免过度消除数据带来的负面影响,有效地提高了分类器的性能.
算法级方法通过直接修改训练机制解决类不平衡问题,算法级方法包括代价敏感学习方法、集成学习方法等.代价敏感学习不是通过不同的采样策略创建平衡的数据分布,而是通过使用不同的代价矩阵来解决类不平衡问题,这些代价矩阵表示对特定数据实例进行错误分类的成本.文献[30]提出了一种代价敏感转移核典型相关分析(cost-sensitive transfer kernel canonical correlation analysis,CTKCCA)方法,利用代价敏感技术,在迁移学习阶段使用转移核典型相关分析方法,分离有缺陷和无缺陷的实例.结果表明,该方法在PD,PF,AUC 等指标上均优于转移成分分析 (transfer component analysis,TCA)等基线方法.
对于机器学习来说,单个模型存在过拟合和缺乏泛化能力等缺点,集成学习通过组合多个分类器来处理类不平衡.常用的集成学习方法包括Boosting,Bagging,Stacking,Voting 以及随机子空间方法(random subspace method,RSM)等.文献[31]使用随机森林(random forest,RF)、人工神经网络、K 最近邻作为模型的主要学习者,逻辑回归(logistic regression,LR)作为模型的次要学习者,从多个Stacking 模型中选择了性能最好的模型.文献[32]提出一种基于随机近似约简(random approximation reduction,RAR)的集成学习算法ERAR,该算法使用RAR 扰动属性空间,以删除冗余和不相关的属性,采用重采样技术扰动实例空间.为了解决学习器中数据集不平衡问题,ERARSMOTE 在ERAR 中加入了方法SMOTE,对不平衡的缺陷数据进行预处理.结果表明,ERAR-SMOTE 在F1-Score,MCC,Recall 等指标上优于RSM,Bagging 等基线方法.
近年来,研究人员使用深度学习解决缺陷预测中的类不平衡问题.文献[33]将嵌入最近邻(stratification embedded in nearest neighbor,STr-NN)的分层思想引入了神经网络,在标记的训练数据集上训练集成学习分类器,用来搜索目标数据的伪标签,基于伪标签确定训练数据集中缺陷的数量.文献[33]的作者使用最近邻(NN)平衡训练数据集,解决项目内缺陷预测(within-project defect prediction, WPDP)中的类不平衡问题.对于跨项目缺陷预测(cross-project defect prediction, CPDP)的类不平衡问题,在STr-NN 的基础上,引入TCA 缓解源数据和目标数据之间的特征不一致问题.结果表明,与TCA,TCA+SMOTE 相比,TCA+STr-NN 具有更高的AUC 和Recall.
文献[34]提出了一种基于双向生成对抗网络的软件缺陷预测模型(ADGAN-SDP),从异常检测的角度解决类不平衡问题.该模型使用双向生成对抗网络(bidirectional generative adversarial network,BiGAN)对无缺陷样本进行建模,并将无缺陷样本的损失值与预定义的阈值进行比较,从而预测当前样本是否含有缺陷.结果表明,该方法在AUC,G-mean,F1 等指标上优于代价敏感、过采样、欠采样、集成学习等方法.
混合方法将数据级技术、算法级技术与集成方法结合,用来处理类不平衡问题.文献[35]分别使用采样、代价敏感、集成及混合形式构建软件缺陷预测模型.结果表明,相比较于采样和代价敏感学习,集成学习实现了更好的预测结果.
传统的Stacking 方法在处理类不平衡问题时没有考虑代价成本问题.文献[36]提出一种CSSG 方法,将Stacking 方法与代价敏感学习结合.结果表明,该方法能够很好地解决项目内缺陷预测中类不平衡问题.
讨论1:不平衡的数据集中可能存在类重叠问题,主要表现在少数有缺陷的训练样本与大多数无缺陷的训练样本实例重叠,增加了分类器学习缺陷特征的难度.使用NCL,CLNI,CBDN 等方法可以去除不平衡数据集中的重叠样本,提高缺陷预测的能力.
2.2.2 高维度数据
数据集中的冗余和无关特征会降低模型的预测性能,通过对高维度数据进行处理,能够缩短模型的训练时间并提高模型的预测性能,特征选择方法可以从高维度特征中选择与缺陷高度相关的特征从而实现特征降维.20 世纪90 年代后期,研究人员使用包装器[37]和过滤器[38]从高维度特征中选择与缺陷高度相关的特征.基于过滤器的方法使用独立的学习算法评估数据集的特征,复杂度较低且不能保证学习算法的准确性.基于包装器的特征选择方法使用预定的学习算法评估数据集特征的优劣,特征选择独立性较高,但是基于包装器的特征选择方法用于子集搜索评估和选择的数量未知,存在分类器过拟合等问题.
文献[39]改进了基于包装器的特征选择方法,设计了一种EWFS 模型用来动态选择特征.该模型首先使用熵度量对数据集中的特征进行排序,然后通过增量包装方法传递排序的特征,最后使用条件互信息最大化(conditional mutual information maximization,CMIM)选择所需特征.结果表明,这种动态特征选择方法优于现有的元启发式方法和基于顺序搜索的包装法.
混合特征选择方法是基于过滤器和包装器的方法.文献[40]提出一种混合特征选择方法,通过比较方案与理想解之间的相似度来进行排序的方法(technique for order preference by similarity to ideal solution,TOPSIS)为5 种过滤方法计算分数,决策矩阵生成排序后的候选特征;使用基于Rao 的优化的包装器算法寻找最优的候选特征.结果表明,该方法优于GA[41]等特征选择方法.
文献[42]将代价矩阵结合到传统的特征选择方法,在特征选择阶段强调代价较高的样本,以解决特征选择阶段的类不平衡问题.结果表明,基于代价敏感的特征选择方法在降低成本和解决不平衡问题上优于传统的特征选择方法.
文献[43]提出了FECAR 特征选择框架,在特征聚类阶段,使用k-medoids 聚类算法将特征划分为k个聚类,并根据FC-Relevance 度量从每个聚类中选择相关的特征.结果表明,该方法可以有效地识别并剔除冗余和不相关特征.
讨论2:特征选择方法是解决高维度数据的一种有效方法,在保证数据质量的同时选择突出特征.基于包装器和过滤器的特征选择是2 种传统的特征选择方法,虽然基于包装器的特征选择方法优于基于过滤器的特征选择方法,但是基于包装器的特征选择方法仍存在着搜索特征子集高时间复杂度等问题,未来应在减少其时间成本的同时,维持该方法的性能.
2.2.3 数据差异
构建性能优越的软件缺陷预测模型需要足够多的历史标注数据,但是现实中标注足够多的训练数据相当困难,数据差异问题普遍存在于跨项目缺陷预测、跨版本缺陷预测中(cross-version defect prediction,CVDP).
跨项目缺陷预测使用其他项目的缺陷数据来预测当前项目是否含有缺陷.但不同项目的数据分布存在着差异,很难将通过源项目缺陷数据集训练的软件缺陷预测模型泛化到新的目标项目中.
文献[44]提出TCA+方法,将TCA 与数据归一化方法结合,但该方法性能不稳定.随后,文献[45]提出了FeSCH 方法,选择合适的特征缓解源项目和目标项目数据之间的分布差距,在特征聚类阶段使用DPC 基于密度的聚类方法将原始特征划分为多个簇,在特征选择阶段设计了特征的局部密度(local density of features,LDF)、特征分布的相似性(similarity of feature distribution,SFD)、特征的类相关性(feature-class relevance,FCR)这3 种策略将每个簇中的特征进行排序.结果表明,FeSCH 相比于TCA+等基线方法在AUC 指标表现更优.
但是文献[44-45]所提方法没有考虑到源数据中的类标签信息,文献[46]提出一种域适应方法LSKDSA,在子空间对齐(subspace alignment,SA)方法的基础上,使用源数据的可用类别标签,并且在域适应学习的过程中加入了判别信息,以减少源数据和目标数据分布之间的差异.结果表明,该方法在Fmeasure 和AUC 等指标上优于TCA+等基线方法.
由于开发环境等因素的影响,各个项目的度量值会存在较大差异,导致跨项目缺陷预测的精度较低.文献[47]提出了一种基于特征选择和迁移学习的度量补偿软件缺陷预测方法,首先使用Pearson 计算特征和缺陷类别之间的相关系数,使用相关系数选择训练时的特征子集;接着使用TCA 将源项目和目标项目的共同特征映射到潜在空间中;随后,使用度量补偿方法为原始度量值分配权重,以提高目标项目之间的相似性.结果表明,该方法在AUC 和Fmeasure 这2 个指标上优于传统的度量补偿技术.
跨版本缺陷预测同一项目、不同版本得到的数据分布存在着差异,这种差异对跨版本缺陷预测模型的预测性能造成影响.
软件的演进会导致开发者在原先有缺陷的基础上引入新的缺陷,文献[48]考虑了连续版本之间缺陷分布的变化,提出一种主动学习方法.但该方法依赖于先前版本的标记模块,忽略了当前版本未标记模块的信息,文献[49]在此基础上,提出了一种混合主动学习(hybrid active learning,HAL),从当前模块中选择最具有价值的未标记模块,并与先前版本的标记模块组合,共同构建混合训练集.HAL 模型使用基于核方法的主成分分析(kernel principal component analysis,KPCA)方法,将混合训练模块的数据和剩余维标记模块的数据映射到高维特征空间.
但是文献[48-49]所述方法忽略了先前版本中数据分布差异的问题,文献[50]提出了一种带有数据选择的跨版本缺陷预测模型CDS,该模型为噪声较少的历史版本以及数据集内部与测试集相似的文件分配更高的权重.通过对比发现,CDS 在Fmeasure 和G-mean 指标上优于其他的基线模型.
讨论3:对于性能优越的软件缺陷预测模型来说,大量的训练数据必不可少,但是跨项目缺陷预测、跨版本缺陷预测中的数据差异问题影响了软件缺陷预测模型的性能,未来研究人员的研究应着重构建高质量、平衡且无噪音的数据集,改善软件缺陷预测模型的性能.
3 评价指标
本节首先统计了目前软件缺陷预测研究的评价指标,分析了研究者最常用的评价指标,各项常用评价指标的具体描述如表8 所示.
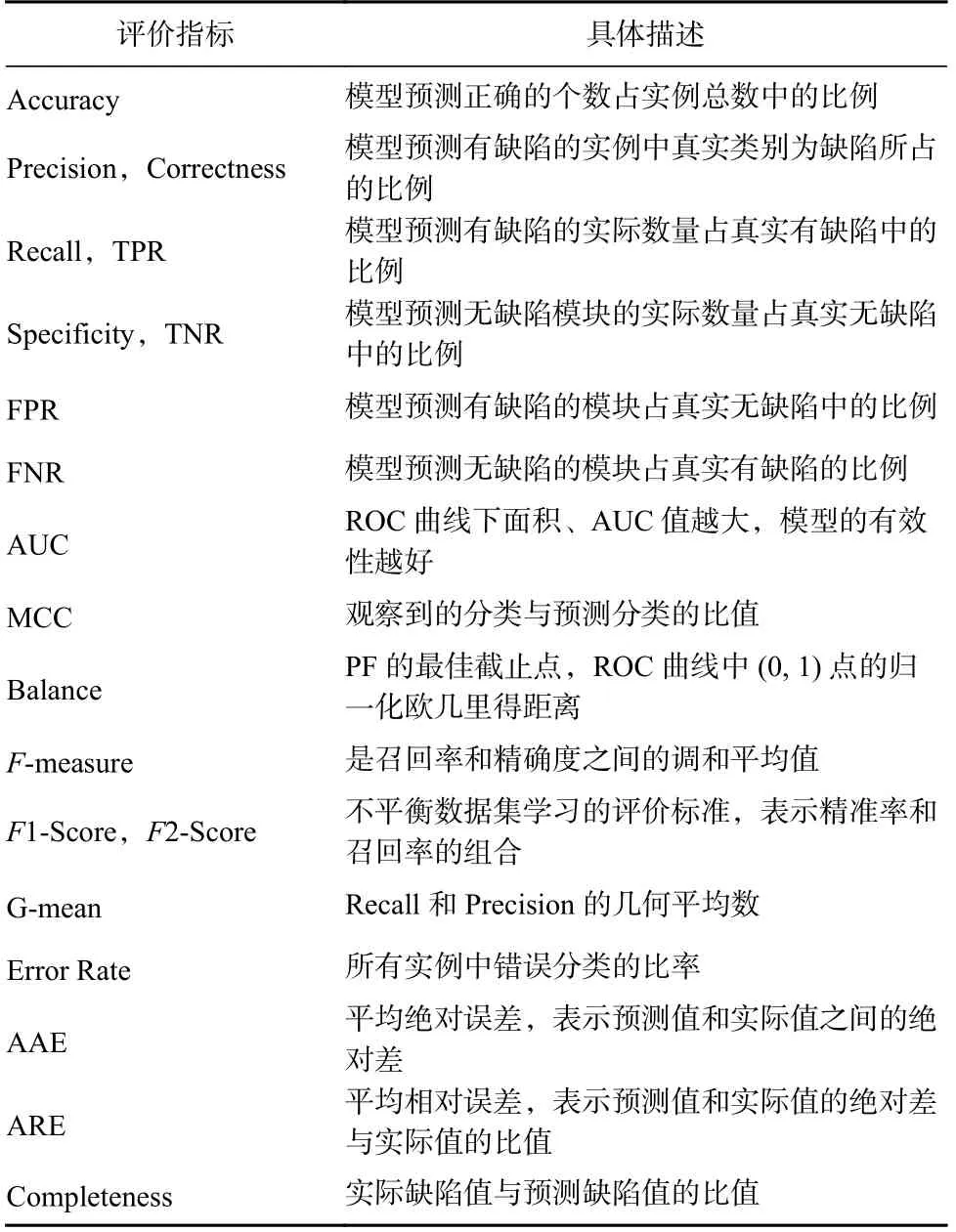
Table 8 Common Evaluation Indicators and Their Descriptions表8 常用评价指标及其描述
本文的预测指标的研究数量占比如图5 所示,可以发现,Recall,Precision,AUC,F-measure 是最常用的评价性能指标.经调查发现,研究人员对于模型的评价指标也有争议:文献[51]认为一个好的软件缺陷预测模型应该同时实现高召回率和高准确率;文献[52]对F-measure 和Precision 进行了批判,该文作者认为不是所有好的预测模型都需要高召回率和高准确率;文献[53]发现使用MCC,而不是使用F1-Score 作为软件缺陷预测的评价指标,超过1/5 的模型对比结果会发生改变.
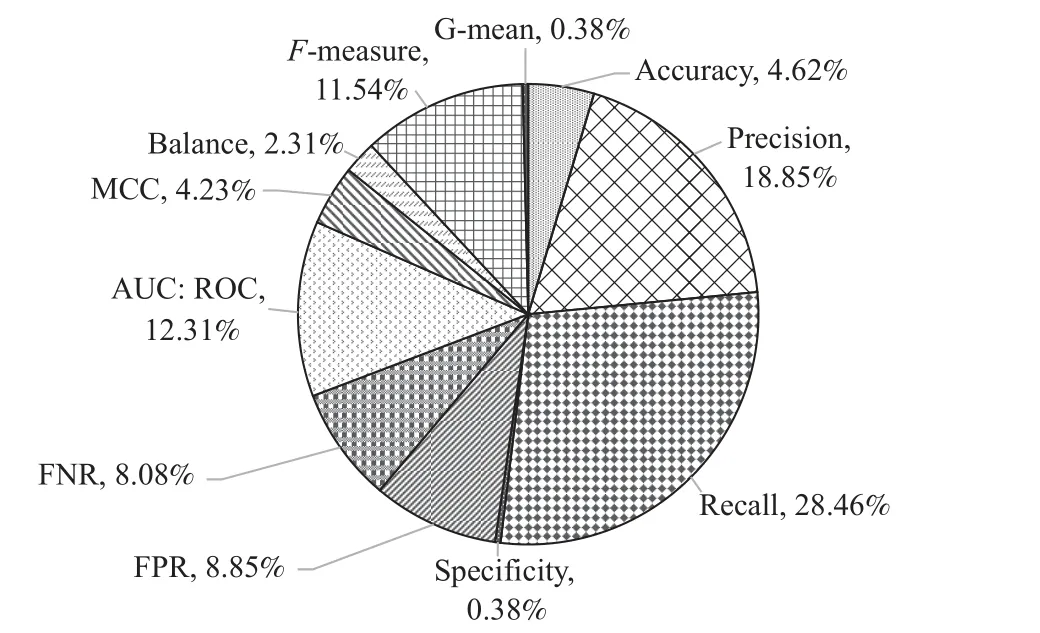
Fig.5 Summary of evaluation indicators图5 评估指标统计
软件缺陷预测研究的评价指标调查结果表明,不同模型在不同评价指标上的表现不同,研究者不应局限于单个指标评估不同模型的优劣,应结合多种评价指标,针对不同的模型采用多样性的评价指标进行评估.
4 缺陷预测模型
4.1 基于软件度量的缺陷预测
软件度量是在软件开发过程对软件进行数据收集、定义和分析的一个持续性定量化过程,描述软件产品或者开发过程的指标或者参数,以保证高效率、低成本和高质量的软件开发过程[54].度量元是最细粒度的软件度量属性,用于描述特定的度量特征,度量元主要分为代码度量元和过程度量元.不同的度量元对软件缺陷预测模型的影响不同,为了提高软件缺陷预测模型的性能,一些研究者使用混合度量元搭建软件缺陷预测模型.
基于软件度量的缺陷预测模型如图1 所示,模型首先从开源公共仓库或者开源社区中抽取程序模块,然后定义与软件缺陷强相关的度量元并提取对应的度量特征从而构造出缺陷数据集,最后通过软件缺陷数据集训练软件缺陷预测模型,软件缺陷预测模型就能够预测目标程序模块的软件缺陷相关信息.
如图6 所示,早在20 世纪70 年代,传统的代码度量基于代码行(lines of code,LOC)[15],随后研究人员发现软件缺陷不仅取决于软件规模,还取决于软件复杂度,于是提出了Halstead 度量[16]、McCabe 度量[55].20 世纪90 年代,随着面向对象技术的发展,一些研究者开始关注模块的内聚性、耦合度等特征,所以使用面向对象度量元衡量软件规模和复杂度.1994年,Chidamber 和Kemerer 基于面向对象程序的继承、耦合、内聚特征给出了6 个类级别的CK 度量标准[56].文献[57]提出了MOOD 度量,包含6 个度量标准.2002年,文献[58]提出了一套QMOOD 度量,在系统和类的层次上评估软件设计.2021 年,文献[59]第一次将代码气味作为跨项目缺陷预测的特征,使用RF、支持向量机(support vector machine,SVM)、多层感知机(multilayer perceptron,MLP)、决策树(decision tree,DT)、朴素贝叶斯(naive Bayes,NB)构建软件缺陷预测模型.结果表明,基于代码气味训练的跨项目缺陷预测模型的性能相较于基于代码度量的缺陷预测模型提高了6.5%,且基于代码气味训练的缺陷预测模型的表现效果优于代码气味和代码度量等混合度量指标训练的缺陷预测模型.
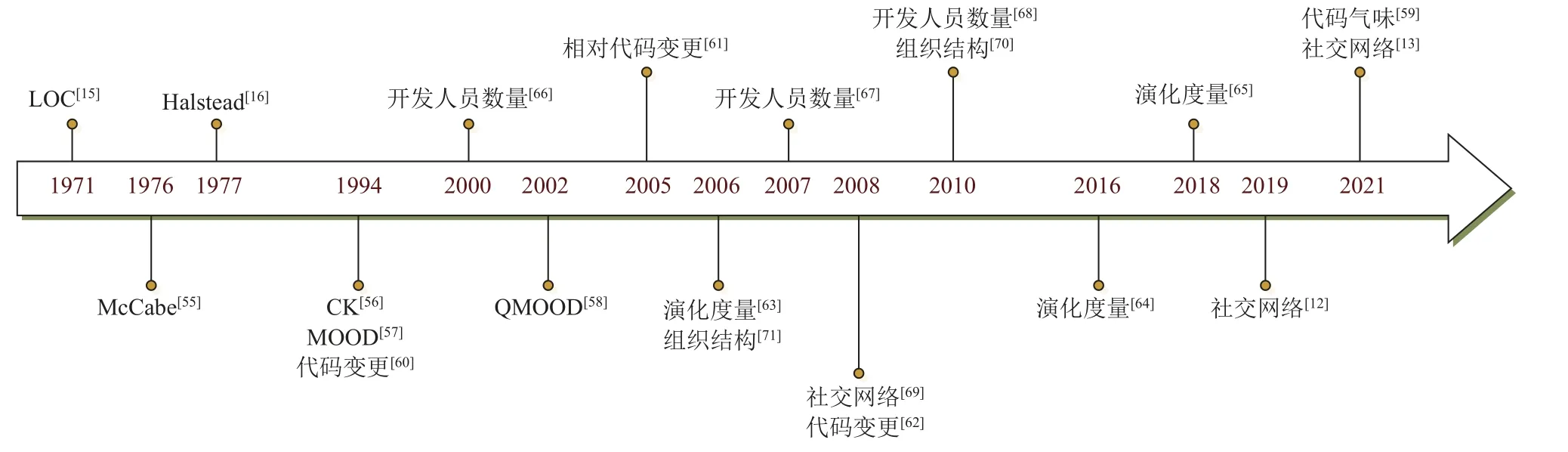
Fig.6 Timeline of metrics development图6 度量元发展时间线
研究人员发现软件缺陷不仅与软件规模有关,还与软件开发过程的各阶段有关,因此提出了一系列的过程度量.代码变更可以度量代码在不同版本之间的增加、删除或者修改量,它很容易从版本控制系统自动记录的系统更改历史中提取.20 世纪90 年代,文献[60]使用代码变更作为软件质量的衡量标准.随后,文献[61]提出了8 种相对代码变更指标,预测软件缺陷密度.文献[62]使用了LR,NB,DT 这3 种分类模型,发现对于Eclipse 数据,代码变更指标比代码度量能更好地预测缺陷.
代码度量和过程度量并不能很好地描述软件模块如何随项目演变而变化,而演化度量[63-65]是一种专门针对项目演变过程的度量元.文献[64]使用类的年龄、类出现缺陷的可能性、类连续且不含有缺陷的周期来刻画软件演化过程中类的演化模式,研究结果发现,与代码度量和代码变更相比,演化度量元能更好地预测软件缺陷.文献[65]将多个连续版本的文件度量按版本升序连接在一起,利用循环神经网络,提供了一个新的视角来解释文件如何随项目的发展而变化的趋势.
软件缺陷的产生与开发人员密切相关,早期研究人员仅仅将修改模块的开发人员数作为缺陷预测的度量元,但是后续研究发现软件缺陷与开发人员的数量无关[66-68].随后,一些研究人员从社交网络[12-13,69]分析开发人员的经验,从程序模块的所有权等角度分析开发人员与缺陷之间的关系.文献[69]使用网络中心度来衡量开发人员贡献的碎片化程度,开发人员的数量越多,代码修改的次数也相应增多,导致软件含有的缺陷数量也越多,研究结果表明中心模块比网络周围的模块更容易产生软件缺陷.
随着全球软件开发的出现,研究人员发现组织结构[70-71]也影响着软件的质量.文献[71]提出了8 项量化组织复杂性的度量用于研究组织结构与软件质量之间的关系,实验结果表明,组织指标比传统代码变更、代码复杂性、代码依赖等指标的预测效果更佳.2005—2010 年,软件缺陷预测结合各种度量元,使用各种机器学习算法提高模型的准确性和性能.NB[72]、贝叶斯网络(Bayesian network,BN)[73]、K-means[74-75]、AdaBoost[76]、DT[76]、LR[72-73,76]等方法在此期间展现了较好的性能.2010 年后,相比于传统的机器学习方法,一些新的机器学习[14,50,77-79]方法提高了软件缺陷预测的性能.现有的跨版本缺陷预测模型通常只使用一个先前版本收集的数据进行模型训练,并没有考虑在具有多个先前版本的跨版本缺陷预测场景中数据分布差异方差和类重叠问题.文献[14]提出了一种基于朴素贝叶斯的改进转移朴素贝叶斯,结果表明该模型在项目内缺陷预测和跨项目缺陷预测中的准确率、精度、PD 都优于转移朴素贝叶斯模型.文献[50]提出了一种新颖的基于聚类的多版本分类器CMVC,为每个先前版本分配适当的权重,并通过最小化目标函数来获得现有文件的预测标签,结果表明该方法优于RF,LR,NB 等模型.
随着深度学习的应用,一些研究人员提出了基于深度学习[65,80-81]的缺陷预测模型.文献[80]探索了Siamese 网络的优势,提出了一种新的软件缺陷预测模型SDNN.与以往的方法相比,SDNN 使用2 个完全相同的全连通网络学习最高相似度特征,并使用计量函数作为最高相似度特征之间的距离度量.结果表明,在F-measure 方面,SDNN 方法优于深度神经网络(deep neural network,DNN)、长短期记忆网络(long short-term memory,LSTM)、深度信念网络(deep belief network ,DBN)、NB 和LR 这5 种方法.
文献[81]提出了一种Defect-Learner 模型,从代码自然性的角度,将交叉熵作为一种新的软件度量方法引入到文件级缺陷预测.Defect-Learner 模型在学习阶段,构建了一个多层的LSTM 网络,从输入的标记向量中学习隐含的语义特征.在预测阶段,将交叉熵度量与其他度量特征结合,用来预测目标项目中的缺陷.结果表明,使用结合交叉熵的CK,QMOOD等度量,能够改进软件缺陷预测的性能.
讨论4:本节按时间顺序归纳了代码度量和过程度量,图6 展示了度量元发展历程,度量元的演变过程及其对比结果如表9 所示.从分析来看,软件的演化是一个动态的连续过程,新增模块或者修复历史缺陷都会产生新的缺陷,未来研究应该关注演化度量元,提高软件缺陷预测的性能.

Table 9 Comparison of Metric Evolution表9 度量元的演进对比
观点1:目前大多数研究者是手工定义与软件缺陷相关的度量元,忽略了软件缺陷在软件生命周期中的产生方式,未来如何从存储库中自动提取与缺陷相关的度量元仍是研究的热点.
4.2 基于语法语义的缺陷预测
基于语法语义的缺陷预测模型如图2 所示,模型首先通过AST 等技术对源代码进行解析从而提取语法语义特征信息,然后通过软件缺陷相关的词嵌入方法将语法语义特征编码为向量,最后将生成的向量数据集送入神经网络模型训练得到缺陷预测模型.
2015 年开始,深度学习、人工神经网络在软件缺陷预测中得到广泛应用.与传统的软件度量不同,研究者使用卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、MLP、DBN、LSTM 和门控循环神经网络(gated recurrent unit,GRU)等深度学习算法,通过AST 等方式生成的标记向量提取特征,从而挖掘软件程序中隐藏的语义和结构特征,并将生成的特征数据反馈到神经网络中,训练获得缺陷预测模型.文献[82]提出了一种用于即时缺陷预测的深度学习方法,利用DBN在一组初始变化特征中提取了表达特征,在选定的特征上构建了缺陷预测模型.但具有不同语义的程序文件可能具有相同的传统特征,该方法无法区分不同语义的代码区域.
鉴于此,文献[83]采用编辑距离相似度计算算法和CLNI 剔除可能存在错误标签的数据,并通过AST 分析程序源代码获取语法信息,最后将语法信息转换为特征向量并输入到DBN 网络中从而建立预测模型.结果表明,该模型提高了项目内缺陷预测和跨项目缺陷预测的性能,与传统特征相比,该方法平均精度提高了14.7%,召回率提高了11.5%,F1 提高了14.2%.文献[84]在文献[82-83]所述的文件级缺陷预测的基础上考虑了代码变更,提出了一种启发式方法,从代码变更片段中提取重要的结构信息和上下文信息;对于变更级缺陷预测,该方法从代码中提取标记,并生成基于DBN 的特征;对于文件级缺陷预测,使用源文件的完整AST 生成DBN 的语义特征.结果表明,在F1 指标上,该方法在文件级和变更级缺陷预测方面上都优于传统的CPDP 和WPDP 模型.文献[85]在DBN 模型提取语义特征的基础上,将CNN 学习到的特征与传统的缺陷预测特征相结合,提出了一种基于CNN 的缺陷预测框架,从程序的AST 中生成判别特征,并且保留了程序的语义和结构特征.结果表明,在F-measure 方面,该方法比基于DBN 的方法提高了12%,比传统的基于软件度量的方法提高了16%.文献[86]提出了一种基于注意力的RNN 的软件缺陷预测(defect prediction via attentionbased recurrent neural network,DP-ARNN)框架,通过解析程序的AST 并将语法信息转换为向量,然后使用字典嵌入和词嵌入对向量编码并输入到ARNN 网络中,利用ARNN 自动学习语法结构特征和语义信息内容,最后通过注意力机制生成关键特征向量.与RNN 相比,DP-ARNN 在F-measure 上平均提升了3%,在AUC 上平均提升了1%.
深度学习方法(CNN,DBN)使用AST 生成的标记向量以提取深度学习特征.文献[87]发现,CNN 和DBN 结合传统软件度量和TCA 算法,可以将源项目中提取到的深度学习特征用于目标项目,解决跨项目中分布不平衡问题.实验结果表明,将深度学习生成的特征和传统特征结合起来,比纯DBN 和CNN 模型的表现效果要好.文献[88]提出了一个新的跨项目缺陷预测方法S2LMMD,首先通过在指定节点拆分原始AST 构造联合学习语句级树SLT,从而捕获更精细的语义和结构信息;然后使用双向门控循环神经单元(bidirectional gated recurrent unit,Bi-GRU)学习序列嵌入并生成更有效的语义特征;最后使用最大平均偏差(maximum mean discrepancy,MMD)技术缓解跨项目中的数据分布差异,提高缺陷预测性能.实验结果表明,在AUC 指标上,S2LMMD 优于DBN和CNN.源代码中的语法和不同级别的语义信息通常由树的结构表示,文献[89]实现了一种基于树结构的LSTM 网络(tree-structured LSTM network,Tree-LSTM),使用Tree-LSTM 匹配代码的AST,充分捕获源代码中的语法和不同级别的语义,使用注意力机制定位源文件中可能存在缺陷的部分.
文献[90]提出一种基于图卷积神经网络(graph convolutional network,GCN)的缺陷预测模型.首先该模型从源代码中提取了7 种节点特征,根据节点特征对控制流图(control flow graph,CFG)节点进行分类并生成节点特征值,最后为CFG 创建节点向量矩阵并将其传递给图卷积网络以自动学习特征.结果表明,该模型可以适应不同规模的软件,在AUC,F1-score 等指标上优于CNN 等传统的缺陷预测模型.
缺陷特征隐藏在程序语义中,但是AST 不显示程序的执行过程,它只代表源代码的抽象句法结构.文献[91]采用CNN 的思想,将源代码转换为程序控制流程图,采用多视图多层CNN 从CFG 中自动提取学习缺陷特征,结果表明图学习可以提高基于传统特征和基于AST 方法的性能.
文献[92]提出了一种基于增强代码属性图(augmented-code property graph,Augmented-CPG)模型ACGDP,用于捕获代码的语法、语义、控制流和数据流信息.该模型在初始阶段从缺陷代码文件中获得AST 和CFG,与代码的控制流和数据流合并,生成Augmented-CPG,第2 阶段提取候选缺陷区域(graph of defect region candidates,GDRC)定位可能存在的缺陷节点,第3 阶段从GDRC 中获取代码嵌入,使用图神经网络(graph neural network,GNN)学习GDRC 中包含的缺陷特征.结果表明,该模型在Accuracy,Precision 等指标上优于VulDeePecker[93]模型.
代码注释是源代码的另一种视图,帮助生成反映代码功能的语义特征,并识别软件中含有缺陷的模块.文献[94]提出了一种评论增强程序的卷积神经网络(convolutional neural network for comments augmented program,CAP-CNN)缺陷预测模型,该模型在训练过程中将代码注释编码为语义特征,结果表明CAP-CNN 在F-measure 指标上优于CNN.
近几年,一些改进的算法被提出来用于软件缺陷预测,网络嵌入技术取得重大进展.文献[95]提出了Node2defect,一种基于随机游走的网络嵌入技术的缺陷预测模型,该模型能够自动学习软件类依赖网络的类结构特征并挖掘节点邻接信息和节点属性,最后将学习到的特征与传统度量连接并输入到后续预测模型中.结果表明,该模型在F-measure 指标上比传统的软件度量方法提高了9.15%.文献[96]提出了GCN2defect,一种基于GNN 的缺陷预测模型,该网络学习类依赖网络中节点的结构特征,并对节点的语义和结构新信息进行端到端的学习.文献[96]的作者引入了传统静态代码度量、复杂网络度量和网络嵌入3 种类型的节点度量作为节点的属性,与传统的软件度量和传统的网络嵌入相比,该方法显著提高了缺陷预测性能.文献[97]在此基础上提出了CGCN 模型,使用CNN 捕获AST 中的语义信息,GCN捕获软件网络中的结构信息,CGCN 通过这2 种方式获得联合特征,并与传统特征结合用于训练分类器.结果表明,该模型优于Node2defect 和GCN2defect 等方法.
文献[98]使用Transformer 模型自动学习序列的语义特征和句法结构特征,预测代码的缺陷密度.文献[99]考虑了源代码的语义和上下文信息,采用BERT和双向长短期记忆网络(bidirectional long short-term memory,BiLSTM)模型预测缺陷,BiLSTM 通过BERT模型学习的token 向量学习上下文的语义信息.结果表明,与现有的深度学习和传统特征相比,该模型更能有效提取程序的语义信息.
讨论5:本节统计分析了基于语法语义的缺陷预测模型,根据分析结果发现,缺陷特征隐藏在程序语义中,大多数研究者将源代码解析为AST,利用深度学习技术学习程序的语法和句法特征.
观点2:缺陷特征隐藏在程序语义中,但是AST不显示程序的执行过程,它只代表源代码的抽象句法结构,未来研究者应使用源代码的多种表征方式,帮助生成反映代码功能的语义特征.
5 漏洞预测
漏洞是一种特定的软件安全缺陷,存在能够被攻击者利用并造成危害的安全隐患.与软件缺陷研究领域不同,漏洞的研究领域可以分为漏洞检测与漏洞预测2 个任务场景.
漏洞检测和漏洞预测2 个任务侧重的研究目的不同.漏洞检测任务针对已知的漏洞,在特定的软件中检测是否存在目标漏洞.漏洞预测任务则主要负责从宏观角度进行数据上的统计,预测一个代码文件中可能存在的漏洞数量,以减少漏洞发现和修复的成本.但随着人工智能尤其是深度学习方法的大量引入,漏洞检测和漏洞预测模型愈发相似,由于都使用大规模精细标注的数据集进行训练,任务的目的和实现的方式也渐渐重合,在近年的许多研究工作中已经不再区分这两者的概念.
本节以漏洞预测过程为切入点,分别介绍了传统的基于软件度量的预测方法以及基于语法语义的预测方法.
5.1 漏洞预测模型
5.1.1 基于软件度量的漏洞预测
基于软件度量的漏洞预测模型通过人工设计软件特征表示软件漏洞相关信息,再使用机器学习算法预测并识别漏洞相关的组件.漏洞预测模型使用复杂度、代码变更、开发者活动、耦合、内聚等度量,并使用LR,SVM,J48,DT,RF,NB,BN 等机器学习算法预测漏洞相关的组件.
文献[100]对Mozilla 中的JavaScript 引擎进行了案例研究,发现9 种复杂性度量(包括McCabe,SLOC 等度量)可以用于预测漏洞,但是误报率较高.文献[100]的作者发现,漏洞函数和缺陷函数的复杂性度量仅在复杂度方面存在显著差异,因此复杂度可以区分漏洞和缺陷函数.文献[101]使用源代码行、代码变更等度量预测漏洞,结果表明该回归树模型在最佳情况下实现了100%的召回率和8%的假阳率.文献[102]研究了开发人员协作结构与漏洞之间的关系,研究发现,由9 个或者更多开发人员更改的文件比少于9个开发人员更改的文件具有漏洞的可能性高16 倍.文献[103]研究了3 种软件度量指标(复杂性、代码变更、开发人员活动)是否可以区分易受攻击的文件来指导安全检查和测试.结果表明,28 个度量中至少有24 个可以区分2 个项目的易受攻击文件和中性文件,这3 种度量可以为安全检查和测试工作提供有价值的指导.文献[104]研发出一个基于复杂性、耦合性和内聚性相关的漏洞预测框架,该框架能正确预测Mozilla Firefox 的大多数受漏洞影响的文件,且误报率较低.
观点3:基于软件度量的漏洞预测研究提出了大量的指标,试图尽可能完整地从软件代码中手动提取出漏洞相关的特征.但这些人工定义的特征并不一定能够完全理解代码本身的含义,因此在实际的漏洞预测中仍具有较多不足.
例如在图7 中的2 段Python 代码,从功能上来看都是从栈顶弹出5 个数据,但代码1 在栈中数据不足5 个时有向下溢出的风险,代码2 则没有.但这2段代码具有相同的软件度量、代码标记和频率等,仅依靠人工提取的指标难以对二者进行区分,需要一种能够提取代码的语法结构特征和语义信息内容的算法.

Fig.7 Code example图7 代码示例
5.1.2 基于语法语义的漏洞预测
基于语法语义的漏洞挖掘通过文本挖掘、AST等方式提取软件代码中的特征信息,转化为向量的数字表示,随后使用机器学习(machine learning,ML)或深度学习(deep learning,DL)方法进行分类.使用图算法或者注意力机制还可以具体定位可能出现漏洞的位置.基于语法语义的研究主要集中在探究不同的特征提取方法和各种训练模型.
文献[105]提出了一种依赖于源代码文本分析的方法,将每个文件转换为一个特征向量.该方法将源代码的每一个字母组合都视为特征,使用给定文件源代码中给定字母组合的计数值.该研究在开源移动应用程序上实现了87%的准确率、85%的精度和88%的召回率.文献[106]将文件中的代码标记和频率作为代码的文本特征,预测可能存在漏洞的组件,该模型相比于PHP 应用程序的软件度量模型实现了更高的召回率.但是对词袋模型来说,它忽略了代码之间的语法结构信息,隐藏在程序中的语义信息可以帮助易受攻击的代码提供更丰富的表示,从而改进漏洞预测模型的效果.此后的研究引入了AST 来表征句法结构,文献[107]从代码中提取了AST 并确定树的结构模式,根据树的结构模式自动比较代码,该方法仅通过检查少量代码库就能进行漏洞预测.文献[108]使用Antlr 从C/C++源文件中提取AST,以每个函数为基本单元从AST 中提取向量,利用该向量训练分类器来预测缓冲区漏洞.
许多深度学习技术也开始应用于漏洞预测任务.深度学习技术可以从复杂的代码中自动获取更深层次的特征信息,表征程序的语法和语义特征.文献[109]在令牌(token)级数据上,采用深度神经网络,结合N-gram 分析和特征选择构造特征,该模型能够在Java Android 应用程序漏洞预测任务中实现高精度、高准确率和高召回率.文献[110]利用LSTM 捕获源代码中的上下文关系,学习代码的语法语义特征,结果表明该方法优于传统的软件度量等模型.文献[111]研究了基于文本挖掘的漏洞预测中词嵌入算法的价值,使用word2vec 和fast-text 两种模型学习代码标记之间的语法语义关系,使用CNN 和RNN 模型预测文件中是否含有漏洞.文献[111]的作者发现,使用用于生成单词嵌入向量的算法时,模型的F2-score 增大,且word2vec 算法效果最佳.基于深度学习的漏洞预测模型也成为了研究的热点.
文献[93]提出VulDeePecker 系统,在漏洞预测任务中引入了深度神经网络BiLSTM,同时采集了一个用于评估漏洞检测效果的数据集.文献[112]建立了一套基于深度学习的漏洞预测系统,能针对输入的文件或函数进行粗粒度预测,也能针对新实例中的某一小代码块,进行某几种漏洞的细粒度预测和定位.文献[113]提出基于GNN 的Devign 模型,提取了4 种属性AST、CFG、数据流图(data flow graph,DFG)和自然语言中的代码序列以完成对代码的表征.文献[114]提出的SySeVR 模型使用基于数据依赖的语义信息表征代码.文献[115]提出了IVDetect 模型,提取代码中的数据和控制依赖关系生成5 个维度的向量表示,统一交由RNN 模型训练学习,实验结果表明,IVDetect 模型带来了精度的提升并能够定位到漏洞所在函数块.基于此,文献[116]提出了LineVul 模型,使用CodeBERT 预训练模型完成代码的词向量转化,使用行粒度数据集进行训练,使用GNN 捕获文本中的依赖关系,模型得到更高预测准确性的同时能够定位漏洞所在代码行.
讨论7:从文本挖掘的角度来提取文件中的漏洞特征能够更充分地捕获代码的语法语义特征.计算机算力的提升和深度学习方法的引入也使得研究者得以从复杂冗长的代码中提取出丰富的特征.这一领域的学者们主要围绕如何完成代码到连续值向量的转换以及深度学习模型的搭建对漏洞预测任务的优化提升展开研究.通过总结归纳发现在代码特征表征阶段,AST 和RNN 这2 个思路被大多数研究者所选择,AST 可以很好地辅助理解代码中的逻辑结构,RNN 则可以在代码量巨大的文件中捕获长距离的依赖关系.除了AST 和RNN,近年来的工作开始逐渐转向大规模语言模型(例如CodeBERT),这些大规模语言模型在程序语言任务上进行了预训练,因此可以更好地捕获和理解程序语言特征以应用于各项程序语言相关的下游任务.
观点4:即便使用了AST 来表征代码的语法结构,如何用向量尽可能充分地表征一个代码文件依旧是研究的热点所在.当代码量过大时,RNN 对于代码中的依赖关系并不能充分捕获,梯度消失问题依旧存在,所以或许一种新的学习模型能够给漏洞预测领域的研究带来突破.此外,目前漏洞预测的结果较为单一,无法全方位多角度地描述漏洞,因此更细粒度的漏洞预测结果也是近年来研究的一个热点.
5.2 漏洞预测和缺陷预测的区别与联系
5.2.1 漏洞与缺陷的区别与联系
漏洞与缺陷不是2 个完全分离的概念,具体来说漏洞是一种特殊的安全性缺陷.
文献[117]表示软件缺陷是导致功能单元无法执行其所需功能的功能性缺陷,软件漏洞是软件规范、开发或配置中的缺陷实例,漏洞的执行会违反安全策略.文献[118]认为漏洞是缺陷的子集,漏洞是一种特定类型的安全性软件缺陷.文献[119]表示,漏洞是能够被人利用来进行入侵行为的缺陷,漏洞的出现是人尝试攻击的结果,而不是机器运行的结果.
根据文献的调研结果,缺陷与漏洞之间的相似性与不同如表10 所示.漏洞与缺陷的产生都与硬件[120]、代码的复杂性[117-119]以及编程人员能力[121]有关,且都会对软件造成巨大的影响.文献[120]指出硬件在漏洞和缺陷的产生过程中扮演了重要的角色.绝大多数的电子设备都采用典型的片上系统(system-on-chip,SoC)作为设备的核心部件,它由多个知识产权(intellectual property,IP)组成,包括处理器、内存和输入输出设备等.为了降低SoC 设计成本并且满足上市时间的要求,SoC 的开发涉及多个第三方公司的供应链.然而,第三方的IP 依赖性也引起了硬件安全问题,因为从不受信任的供应商收集的硬件IP 带有硬件木马、后门等其他问题.文献[121]指出软件开发者的经验和代码复杂性与缺陷密切相关,该文作者对2003—2011 年期间Linux 的不同版本进行了分析,研究发现尽管Linux 的规模在不断增加,但缺陷数量呈现减少的趋势.此外,Block,Null 等类型缺陷仍然在新的文件中引入和修复,但这些类型缺陷的影响各不相同.与缺陷不同的是,攻击者可以利用漏洞实施一系列攻击,造成更为严重的后果.
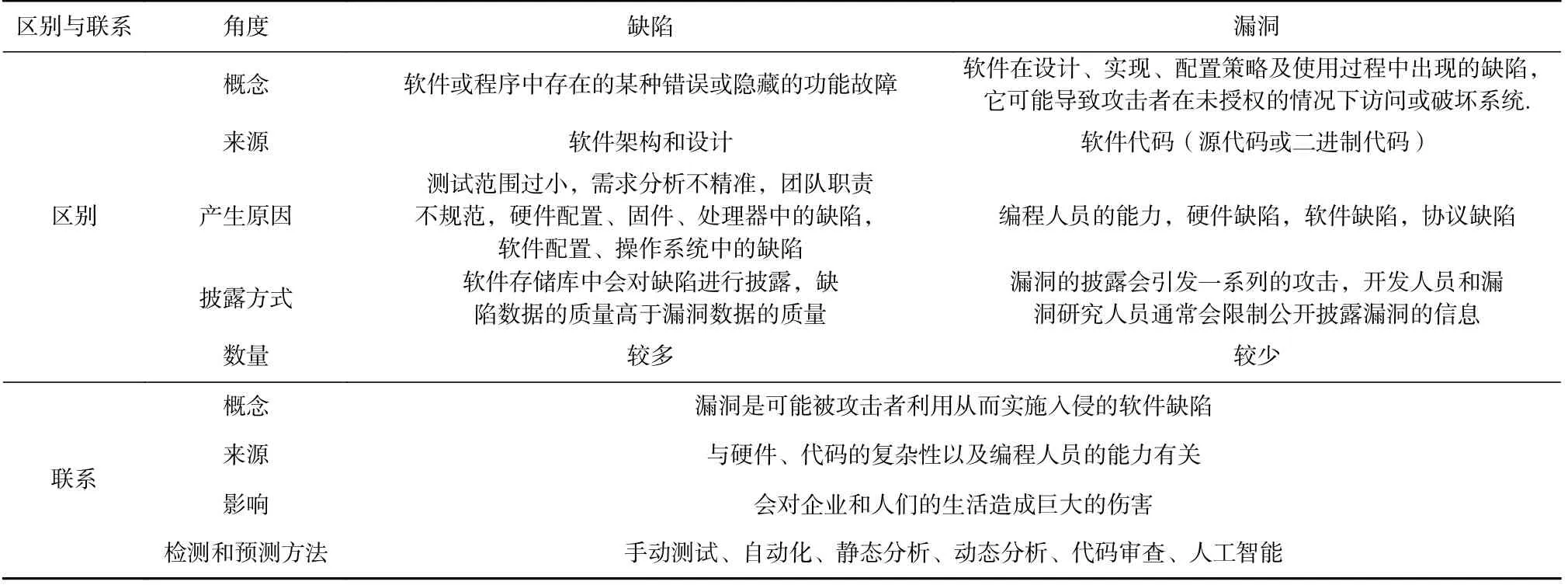
Table 10 Differences and Connections Between Defects and Vulnerabilities表10 缺陷和漏洞的区别与联系
文献[122]的结果表明,没有一套通用的指标可以有效地预测漏洞,漏洞预测不像缺陷预测那么容易,在相同的度量元下,缺陷预测可以获得合理的精度和召回率,但是漏洞预测的精度和召回率却不尽如人意.文献[123]使用3 种传统的缺陷度量构建了缺陷预测模型和漏洞预测模型,测量缺陷预测模型预测漏洞文件的准确性,结果表明传统的缺陷预测指标可以检测大部分易受攻击的文件,但是误报率较高.文献[124]发现,缺陷预测和漏洞预测模型提供了相似的预测性能,当模型使用传统的软件度量时,两者可以互换使用,且缺陷和漏洞预测的性能在很大程度上受先前版本中报告的缺陷数量和漏洞数量的影响.
讨论8:基于软件度量的缺陷预测和漏洞预测提供了相似的预测性能.但是传统的软件度量不能识别语义不同的代码,因为大多数情况下2 段代码具有相同的复杂度,但是受到的攻击可能不同.未来研究者可以从语义角度自动提取缺陷和漏洞相关特征,探究缺陷预测模型在漏洞预测问题上的可移植性.
5.2.2 基于语法语义的预测模型
随着人工智能技术在各个领域表现出强大的预测能力,近年来安全研究领域也引入人工智能技术用于执行缺陷预测和漏洞预测任务.
缺陷和漏洞预测的研究需要提取不同的软件度量,基于人工智能技术的预测模型也逐渐有了类似的结构,包括向量表征、提取特征和ML/DL 分类器训练等流程.通过对缺陷和漏洞任务中的深度学习模型统计发现,CNN,RNN,DBN 等模型均是缺陷和漏洞预测任务中的常见方法,大量的研究工作用它们搭配不同的特征提取方法进行预测.
AST 能够高效地表征程序语言的语法语义,因此AST 特征提取是目前最主流的缺陷预测和漏洞预测的向量表征方法.由于软件代码平均长度较长,所以许多研究也开始使用LSTM 模型来捕获长距离代码之间的语义依赖关系,基于LSTM 模型的注意力机制被广泛用于定位具体缺陷和漏洞的位置.随着BERT 模型的出现,一些大规模语言模型加入数据流、控制流等深层次的程序语言依赖关系来帮助模型更好地捕获和理解程序语言的语义特征.
讨论9:随着深度神经网络的可解释性逐步增强,面临具体问题时应当选择的网络模型也愈发明晰.而缺陷与漏洞的预测模型越来越相似,也从某方面说明2 个任务在实现思路上具有较强的共性,缺陷预测的可移植性问题也值得探究.
6 未来研究展望
本节通过梳理和归纳缺陷预测和漏洞预测任务的研究成果,总结了这2 个研究领域现阶段面临的挑战与机遇,如表11 所示.

Table 11 Opportunities and Challenges of Defect Prediction and Vulnerability Prediction Tasks表11 缺陷预测和漏洞预测任务的挑战与机遇
6.1 数据集的来源与处理
缺陷预测常用数据集及其属性如表4 所示,研究者主要使用NASA,PROMISE,AEEEM 缺陷公共仓库中的CM1,JM1,KC1,KC2,KC3 等数据集进行缺陷预测相关研究,但这些缺陷数据集大多数已经无人维护.
随着深度神经网络(deep neural network,DNN)在缺陷预测模型中的发展,预测模型对于数据集质量的要求也越来越高.这些公共数据集不包含缺陷相关的细节信息,不能给DL 模型提供充分的特征信息.因此,创建新的数据集、增加多标签预测是未来的研究点.
除了数据集的来源,数据集的标注也是一个值得关注的方面.当前研究发现通过GNN 或者注意力机制等方法能够具体定位到预测缺陷和漏洞出现的函数块或代码行,并且数据标注越细粒度,模型所能捕获的信息也越具体.
目前软件缺陷预测和漏洞预测使用的数据集往往具有类不平衡、维度过高、预测特征不足、分类标签不足等缺点.类不平衡和维度过高问题可以通过研究者人工规范化或者降维处理来缓解,但特征和标签不足的问题则只能寻求更加高质量、平衡且无噪音的数据.因此,为了更好地预测缺陷、改善资源分配和修复缺陷代码,研究者需要创建一个高质量的缺陷数据集.
6.2 代码向量表征方法
目前的代码向量表征研究尝试了包括变量名称和类型、AST、程序依赖图、数据依赖在内的多种方法来表征代码蕴含的语法语义信息.
除了单一表征方法外,许多研究也着眼于多维度的混合表征方法,并给模型带来了一定的性能提升.其中,AST 能够出色提取代码中语法结构特征,因此被广泛应用于各种模型的代码表征阶段.但如何在不丢失语法结构特征和语义信息内容的前提下,将源代码嵌入到向量空间,从而更好地完成代码表征工作,仍需要研究者们继续探索.
6.3 预训练模型的提高
人工定义的各种代码表征方法似乎已经走到一个瓶颈,当前许多工作尝试了各种方法来提取代码中的特征,但都不能全面地捕获程序语言的全部语义信息,于是有的研究工作开始尝试引入code2vec模型.
近年来出现的Glove 等词向量模型给代码表征带来了一定的启发.最近人工智能领域也提出了许多诸如CodeBERT 的大规模预训练程序语言模型,但它不能深入地捕获到程序语言的语义级别信息,它的后继者GraphCodeBERT 加入了数据流的依赖关系,得到了更多的代码语义表征,并在多个程序分析相关下游任务中取得了SOTA 成果.可以预见,引入更好的预训练模型也会给漏洞挖掘领域的DL 方法带来极大提升.
6.4 深度学习模型探索
由于软件代码的长度较长,代码中经常出现远距离的数据和控制依赖关系,因此尽可能完整地提取其中的语法结构特征和语义信息内容一直是相关研究面临的一个难题.
选择合适的深度学习模型就可以帮助研究者更好地捕获语法语义信息,目前主流的观点认为使用具有记忆门单元的RNN 系列模型可以帮助提取部分远距离依赖关系的特征,但有些研究指出RNN 在更长的代码文本中同样力有未逮.因此,更适合缺陷和漏洞的预测任务的深度学习模型仍待研究者们进一步探索.
6.5 细粒度预测技术
为了在实际应用中减少查找、修复缺陷和漏洞的成本,预测任务中也产生了定位可能出现的缺陷或漏洞的位置需求,因此如何更加细粒度地定位缺陷和漏洞也是未来研究工作的突破方向之一.
通过各种图算法或者注意力机制,目前大部分预测工作可以对代码文件或者具体函数进行缺陷和漏洞定位,甚至还有部分研究工作实现了将缺陷和漏洞具体定位到代码行.可以预见,细粒度预测技术会随着算法的改进和数据集的精细化而得到提升.
6.6 缺陷预测和漏洞预测模型的迁移
缺陷和漏洞都与代码或者设计的复杂性有关.漏洞和缺陷之间的相似性使得能够用传统的缺陷预测指标进行漏洞预测.如果缺陷预测模型可以用于漏洞预测,则不需要花费额外的时间和资源为漏洞创建单独的模型.
基于软件度量的缺陷预测模型在一定程度上提供类似于漏洞预测的功能.一些缺陷预测模型可能会具有预测漏洞的性能,但是这种缺陷预测模型并不是专门为预测漏洞而产生的,如果要预测漏洞则需要对模型进行一定的改进.未来,研究者可以开发一种通用模型区分缺陷与漏洞.
7 结束语
软件缺陷预测借助机器学习或深度学习方法提前发现软件缺陷,可以减少软件修复成本并提高产品的质量.研究开源软件缺陷预测,能够提高对各类项目的软件缺陷的认识,更好地指导代码检测和测试工作.本文通过调研分析软件预测研究领域相关文献,以机器学习和深度学习为切入点,梳理了基于软件度量和基于语法语义的2 类预测模型.基于这2类模型,分析了软件缺陷预测和漏洞预测之间的区别与联系.最后,对软件预测的六大前沿热点问题进行详尽分析,指出软件缺陷预测未来的发展方向.
通过总结软件缺陷预测相关的研究,本文认为,未来的研究方向可以从4 个方面展开:1)创建一个高质量的缺陷数据集有助于预测缺陷、改善资源分配和修复缺陷代码;2)构建一种最大程度蕴含语法语义信息的表征方法、利用其他领域训练好的词向量嵌入能够提高缺陷预测模型的性能;3)适应细粒度的预测技术可以更加精确地定位缺陷和漏洞可能出现的位置;4)开发一种通用模型区分缺陷与漏洞,可以更好地预测易受攻击的代码位置.
作者贡献声明:田笑负责设计研究方案及论文撰写和最终版本的修订;常继友负责调研分析、数据统计及画图;张弛负责部分论文的撰写;荣景峰和王子昱负责调研分析;张光华、王鹤、伍高飞、胡敬炉负责论文的整体修订;张玉清提出论文的整体研究思路,及最终论文的审核与修订.
