openEuler 中C 标准库替换的兼容性分析
2023-07-20吴亦泽于佳耕武延军
吴亦泽 于佳耕 郑 晨 武延军,3
1 (中国科学院软件研究所 北京 100190)
2 (中国科学院大学 北京 101408)
3 (计算机科学国家重点实验室(中国科学院软件研究所)北京 100190)
应用程序编程接口(application programming interface,API)是为其他软件提供服务的软件接口[1],将计算机与软件或软件与软件连接,为软件开发者提供帮助.应用软件使用操作系统提供的功能时,需要调用操作系统提供的API.在Linux 各发行版中,为了让应用开发者能更方便地使用系统API 以实现更复杂的功能,系统将API 进一步封装至C 标准库(本文简称C 库)中,并将C 库的API 供用户调用.C 库连接了应用软件和操作系统,C 库的接口实现影响应用软件对系统功能的使用.如果应用软件不能通过调用C库接口来和系统建立联系,很多关键的应用功能也将无法实现.
常见的GNU/Linux 类桌面和服务器系统都采用GNU C library(glibc)这套C 语言标准库,它实现了多种多样的C 库接口,支持各类系统平台,功能十分齐全.glibc 使用LGPL v2.1(GNU Lesser General Public License v2.1)协议.与GPL(GNU General Public License)协议要求“任何使用、修改和衍生GPL 库的软件必须采用GPL 协议并开源”不同的是,LGPL 允许软件通过类库引用的方式使用LGPL 库而无需开源,但对于系统开发者而言,在对库进行修改或衍生时LGPL仍具有限制性和传染性.因此,在商业化系统中使用glibc 存在强制开源的不便和安全问题.
为了避免系统搭载的C 库因开源协议而在商业化场景下带来问题,开源欧拉(openEuler)操作系统商业发行版的开发者正在考虑用musl libc 替换glibc.musl libc 是一个使用MIT 许可证的轻量级C 库,MIT许可证在有版权声明的条件下允许任意地使用、复制、修改和散布软件而无需开源.musl libc 可用于从小型嵌入式系统到通用桌面、服务器系统的很多场景,具有体量小、鲁棒性和安全性强、易于装载等优势.因其基础架构较为成熟,使用的协议也适用于商业场景,故musl libc 成为替换glibc 的首要选择.
新C 库对原有应用软件的兼容是C 库替换工作的关键——新C 库应当保证在原有C 库下能正确运行的应用软件在替换后也能正确运行.目前,musl libc 相比glibc 有较多功能缺失,如果直接进行替换,将导致C 库对应用软件的兼容性较低,而低兼容性严重影响操作系统提供的服务质量,降低商业系统的市场竞争力.因此,在替换前需要通过补全开发将musl libc 的兼容性提高到足够高的水平.
兼容性分析对新C 库的开发很有帮助[2],然而现有的兼容性分析方法并不适用于openEuler 对musl libc 的补全工作(见1.3 节和6.3 节).针对这个问题,本文提出新的兼容性分析算法来研究openEuler 的4 种主要软件生态中的musl libc 兼容性和缺失API 优先级.本文的研究目的是帮助openEuler 的C 库开发者了解musl libc 在openEuler 操作系统上的兼容性,并参照优先级顺序补全开发接口,合理安排开发工作.
本文的主要贡献有4 个方面:
1)量化对比了musl libc 与glibc 的接口.根据接口开发现状,将全部接口划分为主要接口和非主要接口,并分别进行接口对比分析,量化了musl libc 和glibc 的接口差异和重合率,论证了对musl libc 进行补全的必要性和可行性.
2)量化分析了musl libc 对应用软件生态的兼容情况.根据应用软件对缺失API 的调用情况和应用之间的依赖关系提出了兼容的定义,将依赖关系构建为图模型,将兼容的定义形式化,并统计分析了应用软件生态的兼容情况.
3)提出了兼容性度量算法——PackageRank.PackageRank 在图模型上为应用软件赋分,并通过计算兼容应用的得分占比来度量兼容性.
4)提出了缺失API 优先级算法——APIRank.APIRank 是PackageRank 的延伸,根据缺失API 被应用软件调用的情况,对图模型作出进一步扩展,并在新的图模型上为API 赋分,以度量缺失API 的优先级.
1 相关工作
1.1 C 标准库
除glibc 和musl libc 外,还有多种其他C 标准库的实现,如eglibc,uClibc,dietlibc 等.eglibc 是glibc 的一个分支,专为嵌入式场景设计,严格兼容二进制的glibc,使用LGPL v2.1 协议,2014 年初停止开发;uClibc为嵌入式Linux 系统开发,其迎合小型C 库需求,使用LGPL v2.1 协议,自2012 年5 月以来未有新发行版本;dietlibc 适用于小型场景,可以为多种体系结构的Linux系统提供静态链接二进制库,使用GPL v2 协议,最新版本于2018 年9 月发行,版本间隔为4~5 年.相较之下,musl libc 使用MIT 协议,版本更新周期为6~12个月,最新版本发布于2022 年4 月.
musl libc 官方发布了对自己C 库的兼容性分析报告[3],将musl libc(1.1.24)与多种C 语言标准和其他C 库进行了比较.分析显示,musl libc 对POSIX 2008,C99,C11 标准的兼容性良好,分别有12 个、2 个、88个API 未实现,对比POSIX 2008 标准有2 个API 有函数原型但没有实现.在与glibc,uClibc,dietlibc 进行对比时,musl libc 的鲁棒性、安全性、构建环境适配性均优于其他C 库;性能和体系结构适配性略低于glibc 而远优于uClibc 和dietlibc;体量略大于dietlibc,略小于uClibc,远小于glibc.此外,musl libc 在I/O、信号处理、正则表达式功能和动态链接等方面与glibc存在功能性差异.
我们在Ubuntu 20.04 桌面版(Intel®Core™ i7-8550U CPU @ 1.80GHz 2.00 GHz)上使用libc-bench-20110206[4]测试集分别对glibc(2.34)和musl libc(1.2.2)作了性能和内存占有量的测试,测试结果展示在图1中,其中测试用例和测试项目的含义见libc-bench[4].
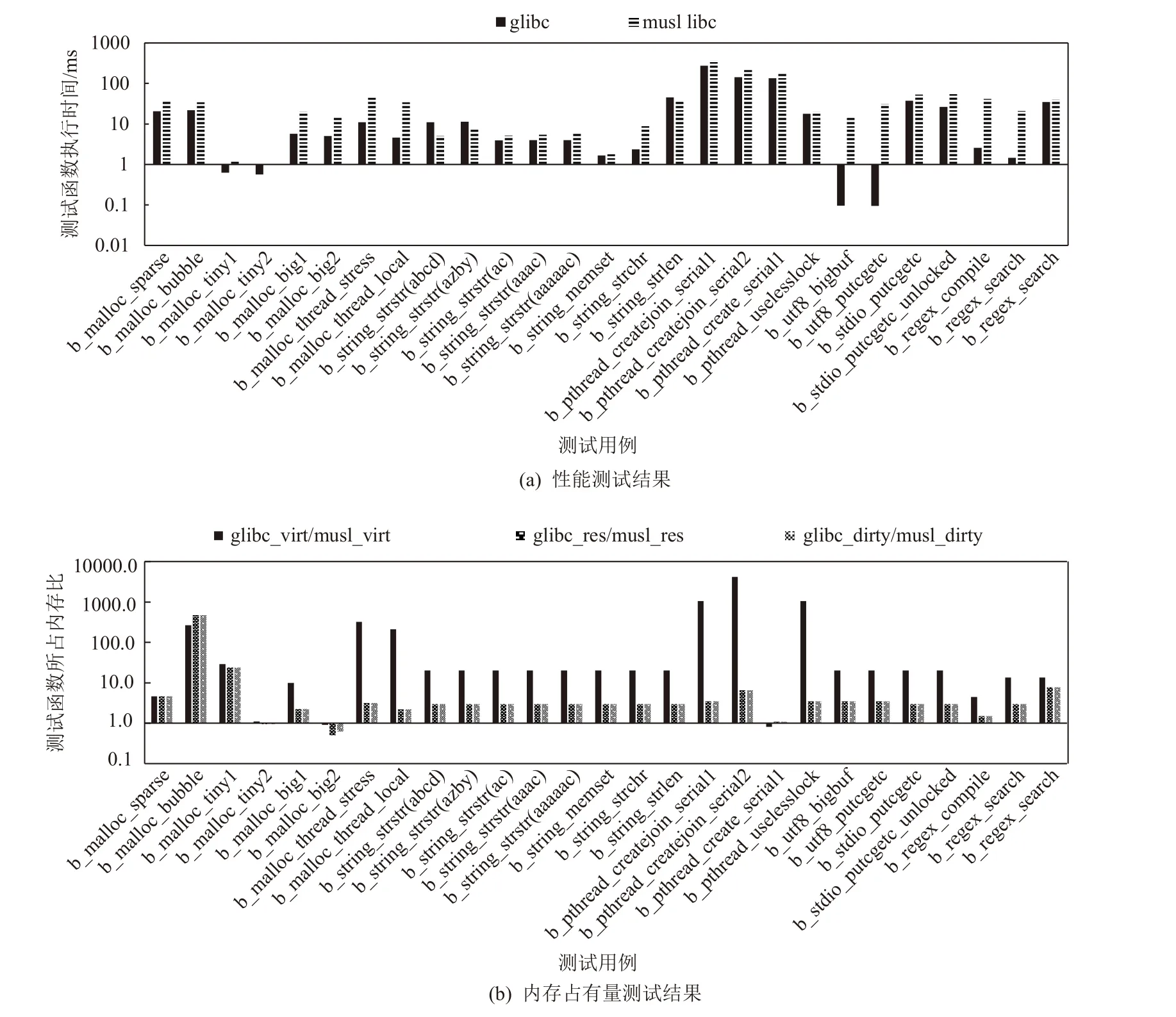
Fig.1 Experimental results of performance and memory usage on glibc and musl libc图1 glibc 与musl libc 的性能和内存占有量实验结果
数据显示,musl libc 在27 个测试中仅有3 个的性能比glibc 更高(运行时间更短),而内存占有量则有24 个更小(且基本都有明显的优势).这表明,虽然musl libc 的性能仍需提升,但其内存占有量低,因此补全开发工作将更为方便和灵活.
综合以上分析,musl libc 架构成熟,许可协议对商用友好,适合进行补全开发和C 库替换.另一方面,性能较低、功能有差别和缺陷等问题使得直接替换并不可行,补全开发工作是必要的.
1.2 openEuler
openEuler 是一个开源、免费的Linux 发行版平台,它通过开放形式的社区与全球的开发者共同构建一个开放、多元和架构包容的软件生态体系.2020年3 月,openEuler 社区正式发布了首个长期支持版本——openEuler 20.03 LTS,并与多家操作系统厂商共同发布了基于openEuler 的商业系统发行版.openEuler每6 个月发布一个社区创新版本,提供6 个月社区支持,而LTS 版本的发布间隔周期为2 年,提供4 年社区支持.目前,openEuler 22.03 LTS 已经发布,有多家国内外机构宣布将推出基于openEuler 22.03 LTS 的商业发行版.
1.3 兼容性研究
在兼容性度量方法中,一种简单而直接的方法是计数满足兼容条件的API 个数[5-8].其算法比较容易实现,但缺乏准确性,即只关注API 本身是否兼容,并未考虑真实场景的API 调用情况.
一些兼容性研究者已经意识到应当在度量方法中引入应用软件对API 调用情况进行考量,而单一内核(unikernel)的出现也启发了他们做出这样的改变.单一内核由应用程序与其依赖的系统组件的最小集打包制成,具有单一地址空间,可以直接在管理程序(hypervisor)或硬件层面运行[9].由于单一内核是根据应用需求搭建的最小集,它必须确保囊括的API 足够兼容应用.一种搭建思路是以现有通用系统的构件为基础进一步开发,例如Rumprun[10]和OSv[11]是由BSD 模块重组生成,Lupine Linux[12]则采用了Linux内核的特殊配置和Kernel Mode Linux 补丁.另外还可以设计API 兼容层来增强自己系统的兼容性[13-14].这样搭建的单一内核仍在使用通用系统的API 标准,因此兼容性是其开发过程的关键,它们的兼容性度量也应当从API 调用的角度出发.
文献[2]以Ubuntu 15.04 为基准,分析了其他一些Linux 类系统或构件(系统调用、C 库、文件系统等)的API 重要性(API importance)和加权完整性(weighted completeness).文献[2]的作者认为“产生兼容性度量不准确问题的根本原因是缺乏对系统API 在实际中被调用情况的数据统计和分析”.该文献利用Ubuntu/Debian 的应用软件安装次数统计,从概率角度度量其他系统或构件的兼容性.该文提出2个度量概念:
1)API 重要性.一部操作系统上会安装多个应用软件,这样的一个“安装集”是该文献统计的基本单位.API 的重要性定义为“调用该API 的应用被安装的概率”.一个应用软件被安装的概率是包含该应用的安装集个数(该应用的安装次数)与所有安装集个数(即系统总安装次数)的比值,将不同应用软件的安装视为独立事件,便可以通过将所有调用某个API 的应用软件的安装概率相乘,来计算API 重要性.
2)加权完整性.加权完整性用于度量系统或构件对应用的兼容性.应用软件分为被支持的(supported)和不被支持的(unsupported),而加权完整性的定义为“安装集中被支持应用数量占该集中所有应用数量的比值的数学期望”.仍将不同应用软件的安装视为独立事件,便能计算出加权完整性的估计值.
许多有待进一步开发的系统构件都有API 兼容性上的不足,但也有研究表明Linux API 提供的功能是溢出的.Quach 等人[15]认为现代Linux 内核中无用的二进制内容可能引发栈膨胀(stack bloating),而DeMarinis 等人[16]指出多余的API 为系统黑客留下了更大的攻击面.这些研究也从另一个角度辩证地解读了兼容性:兼容作用应当贴合应用的需求,盲目地追求兼容可能带来负面效果,提升API 兼容性的开发工作需要有的放矢.
本文采用静态分析度量兼容性,此外还可以采用动态分析或静态和动态分析结合的方法.文献[2]也采用了静态分析度量系统和构件的兼容性,Cui 等人[17]利用动态二进制翻译(dynamic binary translation)技术分析了Intel SGX Enclaves 的系统调用的兼容性,Atlidakis 等人[18]将静态和动态结合来分析POSIX标准是否仍符合现代应用的需求.郑炜等人[19]总结了近年来安卓移动应用兼容性的静态和动态分析方法.动态分析收集程序的运行时数据,比静态分析更加接近实际场景,但往往又无法准确模拟程序实际工作时的行为.在兼容性研究中,测试用例的选取不当会导致兼容问题不能在测试中暴露,降低兼容性分析的准确性.
2 musl libc 与glibc 的接口对比
本节将进行musl libc 与glibc 的接口对比分析.本节的结果是本文后续内容的基础和依据.
在本文的研究中,musl libc 和glibc 均由官方仓库源码编译并安装,见表1.编译C 库时使用的编译器是x86_64-linux-gnu-gcc 9.4.0,安装C 库的系统是Ubuntu 20.04 桌面版.

Table 1 Versions and Repository Addresses of C Libraries表1 C 库的版本号与仓库地址
2.1 接口名称提取
链接器在链接时需要知道库文件内部定义了哪些接口,这要求被链接接口的信息必须完整保存在库文件的符号表中.因此,可以从库文件的符号表内提取接口名称.
本文研究中的接口名称提取自C 库中的可执行文件(executable and linkable format,ELF).具体方法为:遍历C 库所在目录中的所有文件,读取其中每个ELF的符号表.对于每个符号表项,如果其类型(type)为FUNC 或IFUNC 且可见度(bind)为GLOBAL 或 WEAK,则提取其符号名(name).这样提取的接口名称仅包含可被链接的接口,而不可链接的接口与C 库的兼容无关(仅定义在内部,不能被应用软件调用),故不在本文的研究范围内.
经过提取,glibc 共有6 466 个接口,musl libc 共有1 898 个.
2.2 主要接口
C 库的接口有这样的命名习惯:以字母起始的接口供用户调用,以下划线起始的接口实现内部和底层的功能(与操作系统交互、初始化和退出、编译优化等).例如,printf 是标准输出的常用接口,而__libc_start_main 是C 程序初始化启动的一部分,gcc 在编译时可能会将printf 替换为_printf_chk 以防止栈溢出[2].本文将名称以字母起始的接口称为主要接口.
应用软件开发者应该避免直接调用非主要接口[20],故C 库的底层差异不会导致兼容问题.然而,在静态分析应用软件对接口的调用情况时,非主要接口可能会带来兼容性的误判.例如,应用软件调用的printf在gcc 编译时被替换为_printf_chk,由于musl libc 未实现_printf_chk,所以分析结果将显示该应用软件调用了未实现的接口,从而存在兼容问题.但是,如果使用musl-gcc 编译,程序可以正确链接musl libc 的printf 接口,所以兼容问题实际上并不存在.
虽然本文的研究角度是二进制兼容,但这样的误判将导致兼容性分析结果不准确,这是我们希望避免的.因此,本文在兼容性度量时只对主要接口做统计和分析.除特别注明外,后文中所述的结果均以主要接口为研究对象.
经筛选,glibc 有2 883 个主要接口,musl libc 有1 516 个.
2.3 接口对比分析
全部接口和主要接口的统计结果见表2.除接口数量外,为比较C 库的接口实现相似度,表2 还统计了接口重合率,即C 库的共同接口数与该C 库在该项的总接口数的比值.
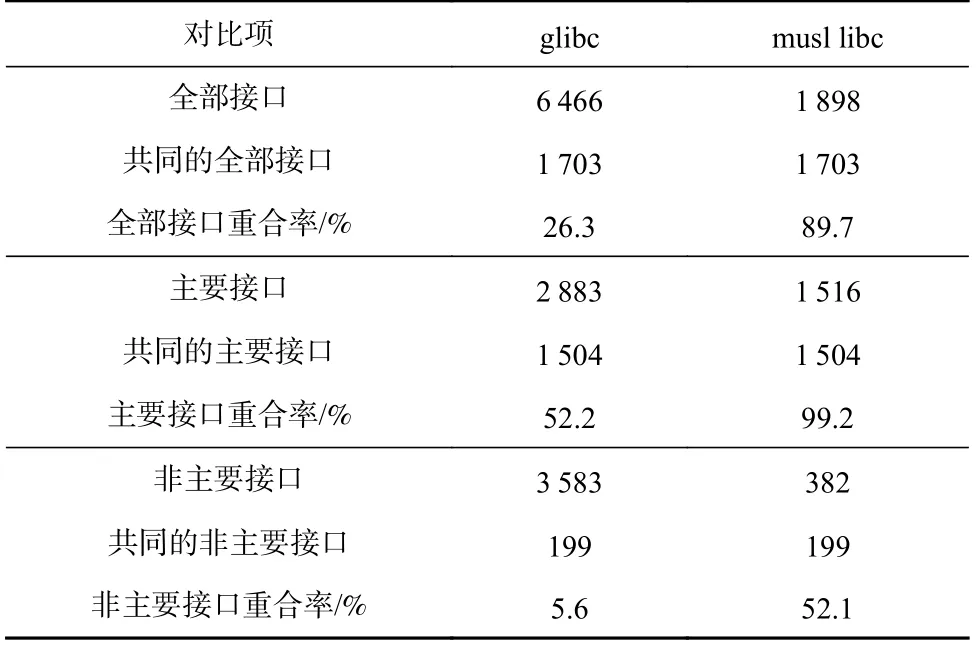
Table 2 APIs Comparison of musl libc and glibc表2 musl libc 和glibc 的接口对比
结果显示,2 个C 库的主要接口重合率均远高于各自的非主要接口重合率(glibc:52.2%和5.6%;musl libc:99.2%和52.1%).这表明C 库顶层接口的相似度较高,而底层实现区别较大.此外,glibc 中55%(3 583/6 466)的接口为非主要接口,可见其底层实现十分复杂,大量的非主要接口将严重影响接口对比结果的准确性,对后续的分析也不利,而只分析主要接口便能避免这个问题.
musl libc 的主要接口集几乎完全包含在glibc 的主要接口集中(重合率为99.2%).因此,从主要接口的角度来看,musl libc 可以基本被视为glibc 的子集.这表明musl libc 充分遵从了glibc 的接口命名习惯,为open-Euler 的C 库移植和替代工作带来了很大便利.但同时,musl libc 的主要接口仅覆盖glibc 主要接口的一半左右(52.2%),这也势必降低了musl libc 对应用软件的兼容性.
表3 列出的12 个主要接口是musl libc 独有的.我们在统计应用软件调用接口的情况(具体方法见第3 节)后发现,这12 个接口均未被任何应用软件调用.值得一提的是,接口strlcat 和strlcpy 其实在应用软件中十分常见,虽然glibc 并未实现这2 个接口,但应用开发者仍会想办法使用它们:有些开发者将它们实现在自己的链接库中(例如x86_64 的multipathtools-0.8.5-7,strlcpy),有些静态链接了他们自己编写的函数(例如aarch64 的entr-4.5-1,strlcpy).也正因如此,这些应用软件才能够在glibc 下正确调用这2 个接口.
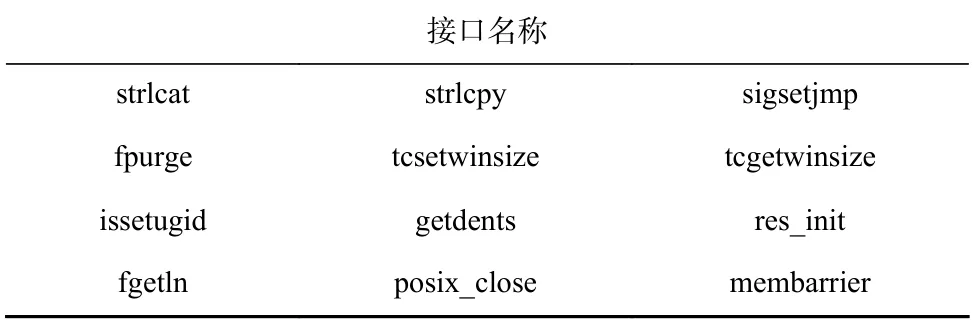
Table 3 Main APIs Owned by musl libc表3 musl libc 独有的主要接口
musl libc 相比glibc 有1 379 个主要接口尚未实现,但它们的情况与musl libc 独有的12 个接口截然不同.由于glibc 的广泛使用,应用软件开发者一般都遵循glibc 的规范而进行相应的编程适配.如果开发者认为glibc 已经实现了某个接口,他们大多会选择直接调用它而不会再自行实现该接口,因为非标准实现不仅带来了更大的工作量,而且存在安全性隐患,也不利于代码复用和移植.然而,开发者想要调用的接口可能是musl libc 未实现的,这便引发了musl libc 的兼容性问题.
“接口重合率”是度量兼容性的一种思路.如果将其用于本文的研究,能得到结论:musl libc 的兼容性是52.2%.然而,这种思路并未考虑被兼容的应用软件所包含的信息.C 库通过实现接口来为应用软件提供功能支持,而应用软件通过调用接口来满足自身的功能需求.在兼容的过程中,主体是C 库,客体是应用软件,而用接口重合率来度量兼容性的方法仅考虑了主体,而忽略了客体.由此可见,应用软件对C 库接口的调用情况也应当被纳入兼容性的度量中.我们将在第4~5 节中提出了相应的算法,更加全面而准确地度量兼容性,并进一步度量了每个缺失API 的优先级.
3 应用软件生态兼容分析
应用软件生态是指系统上可运行的所有应用软件的集合,本文中简称为软件生态或生态.不同系统的应用软件生态不同,故C 库的兼容情况也有区别.本文研究musl libc 在openEuler 操作系统的4 种软件生态中的兼容性,软件生态分别为aarch64 服务器、x86_64 服务器、aarch64 嵌入式和x86_64 嵌入式.
openEuler 软件生态中的应用软件均可通过RPM(RedHat package manager)格式的软件包安装.RPM 包中含有应用软件安装所需的文件和信息,包括ELF、文档、协议等.为提高结果的准确性,本文所统计和分析的应用软件生态均排除了glibc 和musl libc 的基本包与扩展包,如表4 所示.

Table 4 Basic Package and Extended Package of C Libraries表4 C 库的基本包与扩展包
本节将介绍C 库兼容应用软件的定义,并依照此定义分析4 种生态中的应用软件兼容情况.
3.1 直接兼容的定义
兼容的直观判定标准是,新C 库能否保证应用软件的全部可执行文件正确运行.C 库无法支持可执行文件正确运行的原因有很多,被调用的接口未实现、实现的功能有缺陷或错误、应用开发者编程错误、链接器有漏洞等都是可能的原因.本文只考虑C库未实现需要调用的接口的情况,即只要C 库实现了应用软件调用的接口,就认为该调用不会发生错误.另一方面,如果C 库未实现需要调用的接口,本文也假设应用软件开发者未在别处(如自行开发的链接库中)实现这些接口(2.3 节中解释了这样假设的合理性).
既然C 库接口不会被自行实现,那么应用软件调用的库接口便完全依赖C 库提供.因此,如果C 库要保证应用软件不出现错误,就必须实现应用软件调用的全部接口.这种“保证”是C 库对应用软件的直接支持,本文将其称为直接兼容.
定义1.C 库直接不兼容应用软件.如果在该应用软件的RPM 包中存在某个ELF,该ELF 调用了C库缺失的接口,则C 库直接不兼容该应用软件.如果不满足上述条件,则C 库直接兼容该应用软件.
上述的接口“调用”指的是静态调用,即ELF 的符号表中存在能够动态链接该接口的条目.提取符号表中动态链接项的符号名,便提取出了所调用接口的名称.
然而,即使“调用”了C 库缺失的接口,ELF 运行时也未必会发生错误,因为执行流可能并不会经过这个接口.例如,某个负责崩溃处理功能的接口在符号表中有相应的项,但若程序未遇到崩溃,便不会真正调用它.因此,即使存在对缺失接口的“调用”,应用软件在运行时也未必出现错误.
本文不考虑动态调用引起的偏差,即应用软件对任何C 库缺失接口的静态调用都会被判定为直接不兼容.事实上,可以充分信任应用软件开发者的编程能力,从而相信这些极少或从未被真正调用过的接口并非冗余,而是开发者希望该应用实现的功能(如崩溃处理功能)的一部分,它们的缺失也会使应用的正确运行不再得到保证.
3.2 不兼容的传递性
RPM 包中还记录着应用软件对其他应用软件的依赖关系,这种显式的依赖关系是功能上的依赖.除此之外,应用之间还存在隐性的依赖关系,例如用户在使用一个后端应用时必须搭配某个前端应用才能获得良好体验.本文只考虑RPM 包中显式标注的依赖关系,不考虑其他隐性依赖关系.
应用软件的兼容与否和它所依赖的其他应用软件有关.对于某个应用软件,即使它所依赖的应用软件使用C 库时都能正确运行,它也未必能正确运行,故“应用是否被兼容”和“所依赖应用是否被兼容”没有直接关系.但反之,如果所依赖的应用不能正确运行,应用软件本身的正确运行便也无法得到保证,则是一个因果关系.
因此,不兼容具有传递性,即C 库如果不兼容某个应用软件,则也不兼容依赖该应用软件的其他应用软件,即使这些应用软件自身是被直接兼容的.图2 是一个例子:A,B,C,D这4 个应用中,C依赖A,D依赖A和B,E依赖C和D,箭头表示依赖关系.库直接兼容应用A,C,D,E,直接不兼容B.虽然D被直接兼容,但因为B是直接不兼容的,而D依赖B,所以B的不兼容传递到D,D也不被兼容.同理,D再将不兼容性传递到E,E也不被兼容.
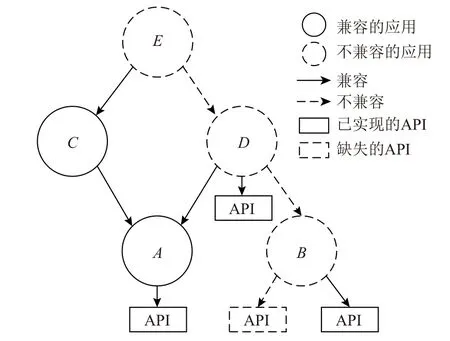
Fig.2 Illustration of transitivity of incompatibility图2 不兼容的传递性示意图
3.3 兼容的定义
从3.1 节的直接兼容和3.2 节中的不兼容传递性出发,可以对C 库兼容应用软件做出定义.
定义2.C 库是否兼容应用软件.
1)如果C 库直接不兼容一个应用软件,则C 库不兼容该应用软件.
2)如果C 库不兼容一个应用软件所依赖的某个应用软件,则C 库不兼容该应用软件.
3)如果无法通过以上2 条定义证明C 库不兼容一个应用软件,则C 库兼容该应用软件.
定义2是递归的.首先有一些应用是直接不兼容的,从而依赖它们的应用是不兼容的.不兼容性沿着依赖关系网传递,直至所有不兼容的应用都被传递到,而未被传递到的应用就是兼容的.
定义2也是无歧义的.该定义将应用软件严格分为兼容的和不兼容的,不存在一个应用可以同时被判定为兼容和不兼容的情况.这是非常重要的,因为模糊的定义将从根本上降低兼容性分析结果的准确性.
3.4 软件生态图
定义2是自然语言表述的兼容定义,不利于直接用于判定应用软件是否兼容.数学化的模型在判定时将更为有效.
应用软件之间的依赖关系存在方向性.由此,可以将整个软件生态视为一张有向图,应用软件与图中的点一一对应,而依赖关系与图中的有向边也一一对应.我们把这样的图模型称为软件生态图.
定义3.软件生态图.它是一张表示软件生态中的应用软件及其之间依赖关系的有向图.图中的每个点对应生态中的一个应用软件,每条边对应一个依赖关系,边的方向规定为:应用A依赖应用B,对应从A指向B的边.
在软件生态图中,我们把被兼容的应用称为兼容点,不被兼容的应用称为不兼容点,同理也有直接兼容点和直接不兼容点.我们提出定义2 在软件生态图模型下的一个等价定义,并证明其等价性.
定义4.软件生态图中的不兼容点.它是那些可通过图中的路径到达直接不兼容点的结点(路径长度可以为0),即
其中Sdi是直接不兼容(directly incompatible)的结点集,(v,vn,vn1,…,v1,v0)表示从v经过vn,vn-1,…,v1到v0的路径.
定义4与定义2 的等价性证明为:
1)对于可通过一条路径到达直接不兼容点的点,如果这条路径长度为0,则该点是直接不兼容点,当然也是不兼容点;否则,可以将该点记为a,路径记为(a,an,an-1, …,a1,a0),n≥0,a0是直接不兼容点.根据定义2,a0是不兼容点,a1因为依赖了不兼容点a0,也是不兼容点.反复进行推理可知,a1, …,an-1,an,a都是不兼容点.
2)对于一个不兼容点b,现在要找到一条从它到某个不兼容点的路径.根据定义2 第3 条,一定存在证明b是不兼容点的方法.也就是说,通过某种方法运用定义2 的第1 条和第2 条,最终可以推导出b不兼容.如果运用了定义2 的第1 条,即b是直接不兼容点,则长度为0 的路径即为所求;否则,它依赖另一个不兼容点(第2 条),即存在从它到另一个不兼容点b0的边.如果b0是直接不兼容点,则证明完成;否则,又存在b0到另一个不兼容点b1的边.反复进行这样的推理,如果一直没有访问直接不兼容点,将不断访问b,b0,b1, …点序列,点序列与推理过程是一一对应的.也就是说,既然存在b是不兼容点的证明方法,就存在相应的点序列.可以认为证明方法对应的点序列是无重复的(序列中每个点都是不同的),因为出现重复点意味着推理过程遍历了一个环,而这又意味着循环论证.循环论证本身不能作为证明方法,故最终还是需要从某个点跳出这个环才能完成证明,故不妨第一次访问“跳出点”时就跳出,访问过程便没有了环.又由于图中点的个数有限,故无重复的点序列只能是有限长度的,因而可以把证明方法对应的点序列记作b,b0,b1, …,bn,n≥0.这表明,整个推理过程只会重复有限次便停止在bn,而推理停止的唯一原因为bn是直接不兼容点.(b,b0,b1, …,bn)就是所求路径.
根据定义4,只要遍历某个应用结点的所有无环路径,就可以判定该应用是否被兼容.
3.5 应用软件生态兼容分析结果
表5 展示了openEuler 的4 种软件生态的musl libc 兼容情况,其中第n级不兼容数的含义为在第n轮传递后新增加的不兼容应用个数,兼容率为被兼容的应用个数占全部应用个数的比例.

Table 5 Statistics of Compatible Applications in the Four Ecosystems表5 4 种生态中的兼容的应用软件统计
比较表5 中数据发现,C 库在相同应用场景(服务器或嵌入式)、不同体系结构下有着相近的直接兼容率和不兼容传递模式,而在相同体系结构、不同应用场景下数据的差异很大:服务器场景中兼容率分别为31.89%和31.87%,其各级不兼容传递的应用个数分别为537/547,6 936/6 985,4 721/4 727,198/190,7/10;嵌入式场景中兼容率分别为45.24%和44.58%,其各级不兼容传递的应用个数分别为33/33,13/13.而在不同应用场景下,兼容率的差值分别为13.35%(aarch64)和12.71%(x86_64),不兼容传递模式也有明显区别.
这表明,软件生态兼容情况受应用场景的影响很明显,而受硬件体系结构的影响很微弱.
4 兼容性算法
兼容性的度量是许多系统开发者的需求,而好的度量方法是获得优质度量结果的关键所在.
3.5 节中提到的兼容率是一种朴素的度量方法,它基于一个简单的数学原理——计数.每个应用软件都在计数时被同等地视作“1”,兼容应用的个数和所有应用的个数的比值就是度量结果.因此,兼容率不能体现不同应用软件之间的差别.
应用软件在生态中的重要性并不等同,这种差异体现在:
1)系统用户的角度.生态中的一些应用提供的功能十分基础,很多其他应用都依赖有基础功能的应用,这些“基础应用”往往存在于不同用户所使用的应用软件的交集中.例如,所有的Python 扩展包都需要Python 解释器来运行,故Python 解释器便时常存在于交集中.用户乐于身处能满足他们个性化需求的软件生态中,而这源于基础应用对生态中其他应用的广泛支持.对整个用户群体而言,基础应用正常工作时的收益和崩溃时的损失都比其他应用更大,这便是应用重要性差异的体现.
2)应用软件开发者的角度.应用软件开发者大多选择以那些已经广泛支持其他应用的应用为基础,开发自己的应用软件,因为基础应用的功能丰富,正确性和安全性得到广泛的实践验证,一般能得到持续稳定的维护,从而使得开发工作更加便捷、产品稳定性更佳、产品便于和其他应用互通或适配,等等.这些优势使得开发者的产品更受用户青睐,而这又促使更多开发者在这些基础应用之上开展工作,形成以基础应用为中心、其他应用对其依赖的生态结构,这是应用重要性差异的又一体现.
本节基于3.4 节中的软件生态图模型,提出了利用PackageRank 算法计算应用软件的重要性和C 库的兼容性,以在兼容性度量时体现重要性差异.
4.1 影响应用软件重要性的因素
应用软件之间的依赖关系能反映其重要性差异.不论是从系统用户还是应用软件开发者的角度,依赖关系都和应用软件重要性有着紧密的联系.
被大量应用软件依赖的应用软件相对更加重要.然而,把被依赖次数当作应用软件的重要性也有失偏颇,如某个“只被一个很重要的应用依赖”的应用可能比“被多个很不重要的应用依赖”的应用更重要,因为它事关生态中的重要应用软件的正常运行.
综上所述,应用软件的重要性受2 种因素影响:
1)被其他应用依赖的次数;
2)依赖它的应用的重要性.
4.2 PackageRank 算法
PackageRank 算法是本文提出的兼容性度量算法.该算法分为2 个部分:计算应用软件的重要性、计算C 库的兼容性.
4.2.1 计算应用软件的重要性
PackageRank 算法同时考虑了4.1 节所述的影响应用软件重要性的2 种因素.它的思想基于Page 等人[21]提出的PageRank 算法,即PageRank 算法应用于代表互联网的有向图中,而PackageRank 算法则是将其应用到软件生态图.
图3 展示了经过简化的PackageRank 算法,它是一个迭代过程:每个结点将它现有的得分沿所有“出边”平均分发,并将所有“入边”的得分求和,作为新一轮迭代之前的得分.本文将PackageRank 算法经过多次迭代得到的稳定结果作为应用软件的重要性度量值.
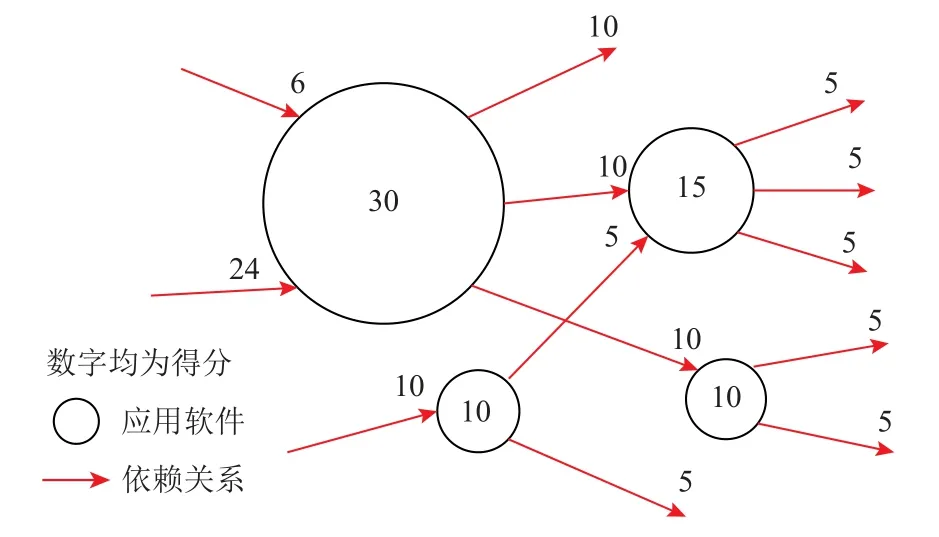
Fig.3 Illustration of PackageRank algorithm图3 PackageRank 算法示意图
Package Rank 算法的含义是:
1)“入边得分求和”使得被更多应用依赖的应用因为有更多得分来源而获得更高得分;
2)“出边平均分发”使得被更高得分的应用依赖的应用能获得更高得分.
由此可见,PackageRank 算法兼顾了影响应用软件重要性的2 个因素.
简化的PackageRank 存在2 个问题,Page 等人[21]将它们分别称为排序沉没(rank sink)和悬链接(dangling link),本文也采用这2 个称呼.
1)排序沉没.软件生态图中可能存在环,即应用之间可以环形依赖.当环中的全部应用都被兼容时,它们都能正确运行,否则便都不能正确运行.如果存在指向环中某个点的边,所有的点又均没有指向环外其他点的边,则得分可以进入环但不能排出,从而在环中无限积累,如图4 所示.可能存在1 个或多个这样的环,而不在这些环内的点最终都将没有得分.

Fig.4 Illustration of rank sink图4 排序沉没示意图
2)悬链接.有些应用不依赖任何其他应用,即它对应的点在软件生态图中没有出边.在迭代过程中,赋予这些点的分数将从图中泄漏,如图5 所示.
为了解决排序沉没和悬链接,算法在每次迭代后令每个结点都“流失”一定比例的得分,同时向所有结点补充分配分数以维持总得分恒定.其中,得分流失和补充使得所有得分不会全部流入闭环中,而得分补充还可以补足因悬链接而泄漏的得分.
考虑到上述问题和解决方法,我们把由Package-Rank 计算的应用软件重要性定义.
定义5.应用软件的重要性.重要性度量结果为向量R,满足:
其中R(i)是应用i的得分,流失因子ε <1,Bi是依赖应用i的应用软件集合,E是重新分配和补充得分的方法,并且通过方法E来保持‖R‖1=1,E(i)是为应用i补充的得分的初值(或称为补充方案,εE(i)是真实的补充值).
可以根据软件生态图构造矩阵An×n(n是生态中应用的个数):将所有应用软件编号为1~n.对于1≤i≤n和1≤j≤n,如果应用i被应用j依赖,则Aij= 1 /Nj,Nj是应用j依赖的应用个数(点j的出度);否则Aij=0.算法收敛后的向量R(第i维上的值是应用i的得分)满足R=AR.An×n称为依赖关系矩阵.
算法1 展示了PackageRank 计算应用软件重要性的过程.
算法1.PackageRank 计算应用软件重要性R.
初始向量R0可以是任何满足‖R‖1=1的向量,它并不影响最终收敛时的结果.本文采用等值向量作为初始向量,即
流失因子ε的大小会影响算法的计算结果.如果ε过大,依赖关系网在算法中的作用将被减弱,导致结果不准确;如果过小,算法收敛速度更慢.Page 等人[21]建议ε=0.15,以表征网络用户随机跳转访问网页的概率;而由于ε在此处仅为避免排序沉没,选取的值太大将带来较大误差,故本文设定ε=0.001.重新补充分配得分的方法是平均分配,这是因为open Euler 缺乏其他与应用软件相关的统计数据或信息.
图6 展示了排名前N的应用软件重要性(PackageRank 得分)之和随N的变化曲线.相同应用场景、不同体系结构的软件生态得到了形状相似的结果曲线,但不同应用场景的结果有明显差异,这和第3 节中兼容分析的结论是相同的.
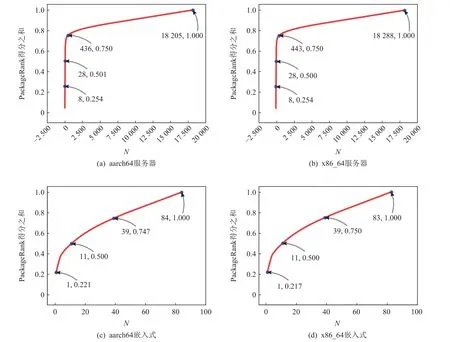
Fig.6 Importance of applications computed by PackageRank图6 PackageRank 计算的应用软件重要性
不同应用软件的重要性得分差距很大,少量的应用聚集了大量的重要性得分,同时很大一部分应用的得分是极小的.图6(a)(b)显示,服务器生态中7 个应用的重要性得分之和已经达到全部应用的25%,28 个应用达到了50%,近800 个达到了75%,而生态中共有1.8 万余个应用软件;嵌入式生态的得分分布相对更加均衡,但也存在明显的差距.
这一软件生态的特点符合自然界生态系统的规律.少数食物链顶端的物种能得到大量的能量输入,在系统中也更具支配性;而底端的低级生物只能靠更多的数量来维持平衡.软件生态和自然界生态系统的发展过程有所相似,依赖关系网和食物链网也是类似的结构,而PackageRank 的结果也正是自然界的生态规律在软件生态中的延伸,这体现了算法的合理性.此外,嵌入式生态中的得分分布更为均衡的原因则是其生态规模更小、复杂度更低,重要的应用不能积累足够的分数而与其他应用拉开差距.
4.2.2 计算C 库的兼容性
兼容性的度量方法应当体现应用软件重要性的差异.C 库兼容更重要的应用软件,对生态的积极作用更显著,C 库的兼容性便得到更大幅度的提升;C库不兼容重要应用,对生态造成的破坏也更大,兼容性将受到更大的影响.因此,通过对被兼容应用的重要性评价(PackageRank 得分)来计算兼容性是十分合适的.
虽然PackageRank 为每个应用软件输出一个确定的得分,但如果将所有应用软件的得分缩放同样的比例,得到的结果仍是稳定的.通过改变定义5 中‖R‖1的值,就能实现得分的缩放.因此,得分的比值更具意义,它反映的是生态中各个应用的“相对重要性”.这个属性是应用软件生态的固有属性,与得分的缩放无关.我们采用所有被兼容应用的重要性得分之和与全部应用得分之和的比值来度量C 库的兼容性.由于‖R‖1=1,故只需将所有被兼容应用的得分求和便能得到这个比值.
定义6.C 库在软件生态内的兼容性.兼容性定义为所有被兼容应用的重要性得分之和与全部应用得分之和的比值,即为所有被兼容应用的得分之和.
表6 展示了musl libc 在openEuler 的4 种生态中的兼容性度量结果.
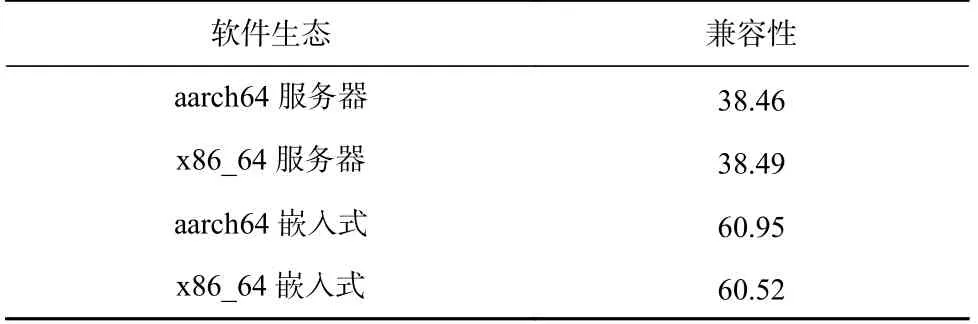
Table 6 Compatibility of musl libc表6 musl libc 的兼容性%
不同应用场景的兼容性差别很大,而体系结构对兼容性的影响很小.嵌入式生态的C 库兼容性较服务器生态高出26%左右,而实际情况也确实如此,即嵌入式生态的应用多为主流应用,它们更多地调用常用的API,而缺失API 普遍是不常用且功能特殊的,因此应用软件调用缺失API 的概率更低.
至此,我们发现musl libc 对应用软件的兼容性仍有很大的提升空间,在替换前需要进一步补全开发工作.
5 缺失API 优先级算法
C 库的开发者不仅需要了解C 库的兼容性,而且更需要获知缺失API 的优先级,以便按序进行补全.
缺失API 的优先级差异体现在兼容性价值上:C库通过补全API 而兼容更多应用软件运行,不同API被应用软件调用的情况有差别,应用软件的重要性又有差别,从而补全不同的API 对生态的兼容性价值也有高低之分.
本节提出了有接口的软件生态图模型,并在该模型上提出了APIRank 算法以度量缺失API 优先级,然后按照优先级次序进行了API 补全模拟.
5.1 影响缺失API 优先级的因素
与4.1 节类似,缺失API 的优先级也受多重因素的影响.被大量应用软件调用的缺失API 应优先实现,以满足众多应用的功能需求;重要的应用软件调用的缺失API 应优先实现,以保证重要应用的正常运行.此外,如果一个应用软件调用的缺失API 数量过多,要兼容该应用就需要大量的工作,兼容性提升效率降低,且开发过程不易调试[21],故这些API 的优先级降低.因此,缺失API 的优先级受3 种因素的影响:
1)调用它的应用软件的数量;
2)调用它的应用软件的重要性;
3)调用它的应用软件所调用的缺失API 总数.
5.2 APIRank 算法
为综合考虑5.1 节所述的3 个因素,我们基于软件生态图和PackageRank 算法作进一步延伸,提出了有接口的软件生态图模型和APIRank 算法以度量缺失API 的优先级.
在软件生态图中,应用软件之间的依赖关系对应着图中的有向边.这种将依赖关系模型化的思路在有接口的软件生态图中得到了延续.应用软件对API 的调用可以被视作一种广义的“依赖”关系.应用软件“依赖”API,正如应用软件依赖其他应用一样.依照这个思路,可以构造一张由应用软件和缺失API 共同组成的有向图,并根据广义依赖关系在图中连接对应的边.我们把这样的有向图称为有接口的软件生态图.
定义7.有接口的软件生态图.它是一张表示软件生态中应用软件和缺失API 及其之间广义依赖关系的有向图.图中的每个点对应生态中的一个应用软件或一个缺失API,每条边对应一个广义依赖关系,边的方向规定为:应用A依赖应用B,对应一条从A指向B的边;应用C调用缺失APID,对应一条从C指向D的边.
算法1 中的PackageRank 的计算过程同样可以用于有接口的软件生态图,收敛后图中每个结点也会有一个稳定的得分.本文将收敛后代表缺失API 的结点的得分视为缺失API 的优先级,这个算法称为APIRank,如图7 所示,它是图4 添加了缺失的API 而生成的.
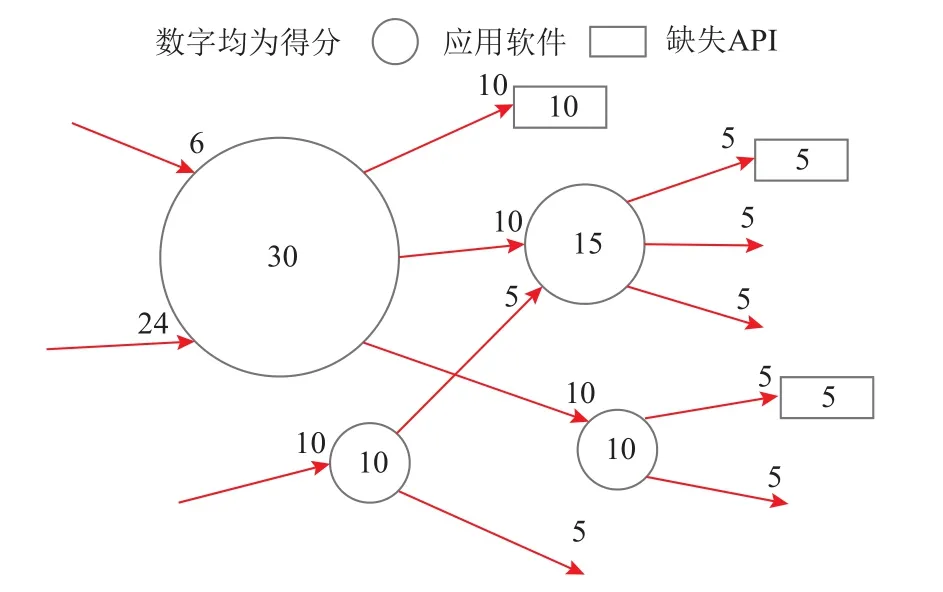
Fig.7 Illustration of APIRank图7 APIRank 示意图
APIRank 算法的含义是:
1)被更多应用软件调用的缺失API 有更多的分数来源,从而获得更高的分数;
2)更重要的应用有更高的分数,它调用的缺失API 也能获得更高的分数;
3)调用多个缺失API 的应用有更多的出边,每个缺失API 能从出边获得的分数更低.
由此可见,APIRank 算法兼顾了影响接口优先级的3 个因素.
同样地,可以根据有接口的软件生态图构造矩阵A(n+m)×(n+m)(n是应用个数,m是缺失API 个数):所有应用编号为1~n,所有缺失API 编号为n+1~n+m.对于1≤i≤n+m和1≤j≤n+m,如果点j有指向点i的边,则Aij= 1 /Nj,Nj是点j的出度;否则Aij= 0.A(n+m)×(n+m)称为广义依赖关系矩阵.
算法2 展示了APIRank 计算缺失API 优先级的过程.
算法2.APIRank 计算缺失API 优先级.
同样地,APIRank 也采用等值向量作为初始向量,流失因子ε=0.001.
根据缺失API 的得分R的高低,可以对其优先级进行排序.
5.3 接口补全模拟
我们模拟了按照缺失API 优先级排序进行补全时,musl libc 兼容性随着每个API 的补全而逐步提升的过程,如图8 所示.

Fig.8 Increase of compatibility in simulations process of API complementation图8 API 补全模拟过程中兼容性的提升过程
图8 的结果显示,musl libc 兼容性的提升呈阶梯型,这是因为在开发过程中往往需要实现多个API才能兼容某一个应用软件,而该应用软件的兼容能够(或许会大幅度地)提升C 库的兼容性.同一应用场景、不同体系结构的兼容性提升过程相似,而不同应用场景的过程区别较大,这也完全符合我们的预期.
注意到,当C 库达到完全兼容(兼容性为100%)时,并非所有的缺失API 均已被补全,即代表完全兼容的点的横坐标值均小于表2 中的主要接口缺失总数(1 379).这表明有些缺失API 未被生态中的任何应用软件调用.根据本文对兼容的定义,这些缺失API 没有对应用软件生态提供任何有效的兼容支持,目前并不需要补全它们就能达到完全兼容,它们也不包含在有接口的软件生态图中,从而不存在APIRank 算法得分(无优先级).
图9 展示了被调用和未被调用的缺失API 数量和占比.我们发现未被调用的API 所占的比例很高:嵌入式生态中有95.9%的缺失接口未被应用软件调用过;服务器生态中,aarch64 和x86_64 的数据分别是85.3%和85.1%.API 未被任何应用软件调用,一般是因为其功能过于特殊而缺乏实用场景,或存在与其功能类似但更受应用开发者喜爱(性能更好,更符合编程习惯等原因)的其他API.嵌入式生态的比例比服务器生态低10%,而这也和嵌入式生态的兼容性更高(见表6)相呼应.

Fig.9 Proportion of called missing API and not called missing API图9 被调用和未被调用的缺失API 占比
openEuler 的C 库开发者当前无需担心这些未被调用的API 会带来兼容性问题.而且,目前未被调用的API 短期内也很可能不会被应用软件的开发者使用,因此C 库开发者有较长的时间来逐一补全它们(如果需要),同时该C 库又能不受影响地提供服务.
6 评 估
本节评估了PackageRank 算法和APIRank 算法的效果,分析算法误差,对比其他现有算法,展望算法的延伸,以及阐明本文研究的局限.
6.1 算法效果
6.1.1 PackageRank 算法效果
PackageRank 算法的评估采用aarch64 体系结构的结果作为例子.表7 给出了在aarch64 的2 种应用场景下PackageRank 得分排名较高的应用的分值.为了更清晰地显示结果,表7 中的得分是经过等比例放大的,这样的放大并不影响算法结果的稳定和准确.
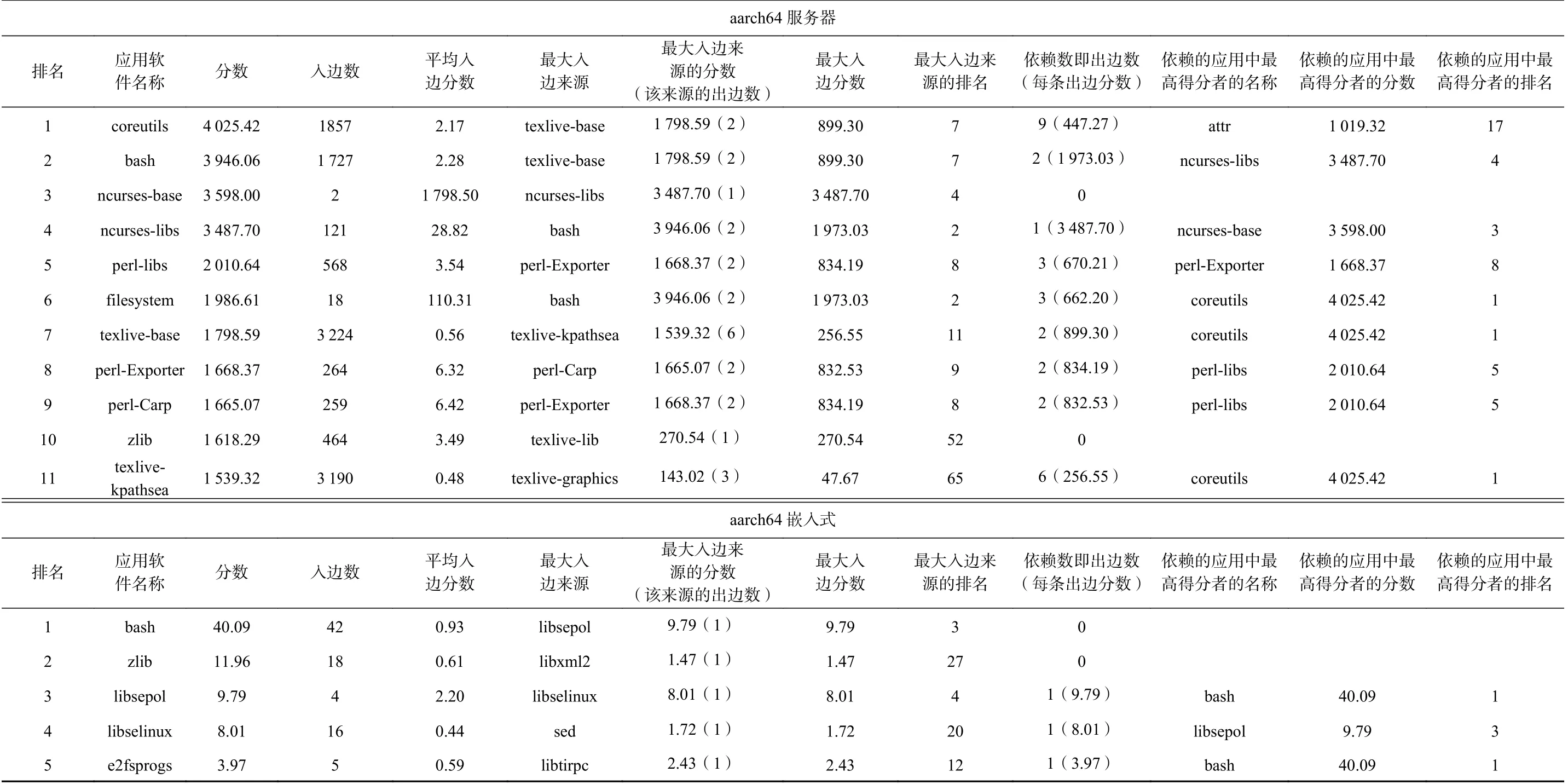
Table 7 Statistics of High-ranked Applications of PackageRank in aarch64表7 aarch64 体系结构下PackageRank 高优先级应用的统计
PackageRank 考虑了影响应用软件重要性的2 个因素:被依赖次数、依赖应用的重要性.由表7 可知,这2 个因素实际都对结果产生了影响.服务器生态中,bash,texlive-base 都既被大量应用依赖(入边数很高),又被高分应用依赖并获得了大量得分(最大入边分数高,最大入边分数来源的分数和排名高);texlivekpathsea 是典型的仅因大量应用依赖而积累出高分的例子,有3 190 个依赖它的应用,但其中最高得分的应用也仅排名65;ncurses-base 则完全因为高分应用的依赖才成为了排名第3 的应用,它只有2 个依赖者,而其中ncurse-libs 为它输送了96.9%(3 487.70/3 598.00)的高额分数.嵌入式生态中,bash 受2 种因素影响而排名第1,zlib,libselinux 主要因为被依赖次数高,而libsepol 则主要因为从libselinux(排名第4)处获得大量分数而排在第3 位.
此外,服务器生态中的perl-libs 和perl-Exporter存在双向依赖,这是排序沉没问题出现的例子,在算法中已经解决了这个问题(4.2 节).
应当指出,平均入边分数与入边数的乘积并不等于得分,而是约等于得分减1(存在微小误差).这是因为PackageRank 在迭代时对每个点进行了等额的得分补充(4.2 节).补充的得分并不来自入边,而表7 中的得分就是将这部分补充的得分缩放为1.00后的结果.
上述分析表明PackageRank 算法有效地实现了对应用软件重要性的多重影响因素的兼顾.
6.1.2 APIRank 算法效果
APIRank 算法的评估采用x86_64 体系结构的结果作为例子.表8 列出了在x86_64 的2 种应用场景下APIRank 算法中优先级较高的API 的分值.

Table 8 Statistics of High-ranked APIs of APIRank in x86_64表8 x86_64 体系结构下APIRank 高优先级API 的统计
服务器生态中,应用软件的高分对其所调用的缺失API 的优先级提升作用明显:PackageRank 中排名第1 的coreutils 调用了6 个缺失API,它们均排在前7 名中.另一方面,被大量应用软件调用也能提升API 优先级,fcntl64 有远超其他API 的被调用数(入边数),这也使得它排在第2 名.另外一个例子则能体现这2 个因素对优先级的共同影响:dlvsym 和argz_add 得分接近,但分别主要受被调用数和调用者重要性的因素影响,表明在不同主要因素影响下缺失API 也能得到相近的分数.
嵌入式生态结构比较简单,且其应用软件调用的缺失API 数量更少,因此API 优先级得分比较接近,但仍能看出多个因素共同影响优先级的效果.特别地,mallinfo 和obstack_vprintf 的得分接近,前者的被调用数和调用者最高得分都更高(3 对1,3.26 对1.00),但其调用者(e2fsprogs)所调用的总缺失API 数更多(4 个,另外1 条出边是应用依赖关系),故其得分与后者接近,这体现了第3 个因素对结果的影响.
上述分析表明APIRank 算法有效地实现了对缺失API 优先级的多重影响因素的兼顾.
6.2 算法误差
本文算法的误差有2 个来源:
1)流失因子ε和得分补充.本文中ε=0.001,得分补充方法为平均分配,因此在每轮迭代后有0.1%的分数从各个结点中流失,并平均分配到所有结点.因此,兼容性误差在0.1%以内;缺失API 优先级的数值存在误差,但排序不存在误差,即按比例流失和平均分配不影响得分之间的大小关系.
2)收敛极限的设定.本文收敛极限设定为“迭代向量差的2-范数不超过10-5”,因此兼容性的误差在0.001%以内,缺失API 优先级的平均误差在10-7以内.
综上,兼容性误差在0.1%以内,缺失API 优先级的平均误差在10-7以内.由于在4 种生态内的所有缺失API 的优先级得分均高于10-5,故APIRank 的平均误差低于1%.
6.3 算法对比
第4 节提出了本文的兼容性算法PackageRank,而1.3 节中也提到了其他2 种兼容性度量方法.
1)算法A:已实现的API 个数;
2)算法B:文献[2]的加权完整性.
算法A的度量方式因缺乏应用软件所包含的信息而不准确,在本节中不再讨论.
算法B是将其他系统与Ubuntu 15.04 作比较,或模拟将系统构件安装在Ubuntu 15.04 上并研究其兼容性.之所以选择Ubuntu 15.04 为基准系统,是因为它是“管理良好的、广泛支持应用软件的、统计软件包安装数据的Linux 发行版”.文献[2]统计API 调用情况时使用Ubuntu 的RPM 包,API 重要性和加权完整性的计算也均采用Ubuntu 的安装次数统计.
我们认为算法B不适用于openEuler 对musl libc兼容性分析的原因是:
1)openEuler 的应用软件生态与Ubuntu 有区别,RPM 包的内容也有所不同;
2)openEuler 不具备像Ubuntu 一样完备的应用软件安装记录;
3)应用软件的安装并非独立事件,而是存在互相依赖关系.
表9 列出了通过各种算法计算的musl libc 兼容性.其中,“算法B”一栏是文献[2]给出的度量结果,而“算法B*”一栏是将算法B的基准系统设定为open-Euler 得到的结果.由于不具备安装次数统计,我们在算法B*中将下载次数设为相同.按照算法2 的定义,此时计算的兼容性值即为应用软件的兼容率.如第4节所言,兼容率不能准确地反映兼容性,因此在缺乏数据统计时,本文提出的兼容性算法比算法B更为准确.
对比其他算法,本文提出的PackageRank 算法的优势和特点在于:
1)为系统提供从自身应用软件生态出发的、个性化的兼容性评估.不同系统能够搭载的应用软件范围(即生态)不同(Ubuntu/Debian 生态中有30 976 个应用[2],openEuler x86_64 服务器生态有18 288 个,open-Euler x86_64 嵌入式生态有83 个),很难为多种多样的系统确定统一的“基准生态”.本文的算法以每种系统或构件各自的应用软件生态信息作为输入,反映API 在其真实应用场景的兼容性,为开发者提供准确的、个性化的评估结果.
2)适用于缺乏应用软件安装统计的系统.包括openEuler 在内的大多数操作系统的发行版都不具备像Ubuntu/Debian 一样完备的应用软件安装记录.即使存在统计数据,如果数据量不足而不能视为满足“大数定律”,那么“用频率估计概率”也并不准确.在统计数据缺失时,本文提出的算法既能够利用有限的信息,又能紧密结合API 的调用情况,准确地度量兼容性.算法所需的信息仅是应用软件的RPM 包.对于大多数系统而言,它们的生态中应用软件的RPM包都是完整且容易获取的.
APIRank 的优势和特点除包含前述内容外还有:面向仍有开发需求的系统和构件,为API 的补全实现工作提供帮助.现有研究大多面向已经完整实现的系统和构件,分析已有API,而本文的算法仅度量缺失API 的优先级,为仍需开发的系统和构件提供补全顺序的建议.本文算法并非为Linux API 的全局现状和生态环境做分析,而是为系统和构件开发者提供方案建议.
6.4 展 望
1)目前并没有将PackageRank 和APIRank 应用于完整开发过程的例子,但openEuler 已经开始按照APIRank 计算出的优先级顺序开展补全工作.在开发过程中发现,有些高优先级API 并非在musl libc 中实现,而是以别名实现(如error)或在其他分支库中实现(如backtrace),这表明高优先级API 在musl libc 的开发者看来也十分重要,因此他们没有拒绝实现这些API,只是其实现细节与glibc 存在区别.APIRank的分析结果和musl libc 开发者的观点存在一致,有望为补全工作提供准确的信息和实质性的帮助.
2)在PackageRank 和APIRank 中,除应用软件全集外,系统开发者还可以选择将某个目标应用集作为研究对象,从而获知系统或构件对该目标集的兼容性和缺失API 优先级.
3)PackageRank 和APIRank 不针对某种特定系统或构件,因此它们有望适用于其他场景下的API兼容性分析,如其他C 库、系统调用、向量化参数等.此外,还有望将它们应用于系统模拟器的兼容性度量.
6.5 局 限
1)有2 处假设存在不准确性:应用的可执行文件存在可链接API 的符号表条目,即视为API 被调用;API 存在即视为API 能正确工作.在3.1 节中,已经对它们的不准确性做出说明.
2)仅采用静态分析而未考虑API 调用频率等其他有关API 调用的信息,而静态分析方法也无法准确给出这些信息.
3)没有参考用户对应用软件的使用喜好和倾向,包括应用软件之间的其他隐性关联.
4)未全面考虑编译环境和源码对API 调用情况的影响,即应用软件的开发者可能会通过宏命令,根据编译环境的不同而调用不同的接口(特别是那些不在ANSI/ISO C 标准中的接口).应用软件的编译环境会影响接口调用,接口缺失仍存在误判.
5)实验对象单一.本文的算法仅在openEuler 上的musl libc 兼容性研究中使用,未曾在其他系统或构件上开展工作.
7 结束语
本文研究了openEuler 的4 种软件生态中的musl libc 兼容性和缺失API 优先级,以帮助openEuler 的C 库开发者进行接口补全工作.
本文的分析结果表明:一方面,musl libc 目前的兼容性仍有待提高,若要用其替代glibc 则需要进一步开发;另一方面,开发者可以根据本文的缺失API优先级按序而高效地开展工作.
本文基于应用之间的依赖关系和应用对API 的调用关系进行兼容性和缺失API 优先级的度量.从依赖关系和调用关系到兼容性和优先级的转化,是本文的核心思想和成果.
作者贡献声明:吴亦泽提出算法、完成实验并撰写论文;于佳耕提出算法思路和指导意见并修改论文;郑晨提出指导意见并修改论文;武延军给出选题、提出指导意见并修改论文.
