面向机器学习的安全外包计算研究进展
2023-07-20陈珍珠周纯毅高艳松付安民
陈珍珠 周纯毅 苏 铓 高艳松 付安民
1 (南京理工大学计算机科学与工程学院 南京 210094)
2 (广西可信软件重点实验室(桂林电子科技大学)广西 桂林 541004)
伴随网络通信、云计算、人工智能技术的快速发展,大数据已经融入医疗、教育、金融、电商等多个行业领域,新技术应用屡见不鲜.智能医疗、智能交通、智能电网等一系列泛在计算应用场景的普及标志着云计算和机器学习技术在智能终端数据处理上已融为一体[1].尽管近年来,终端智能化衍生出分布式计算模式,推动计算由云端趋向边端和终端,但是终端数据过载和传输速率提高也给云计算带来新的生机[2].目前,云计算仍然呈现蓬勃发展态势.据Statista 的统计数据[3]显示,全球云计算市场持续增长,在2021 年的销售额接近4 000 亿美元,而预计到2023 年底这一数额将达到5 917.9 亿美元.
众所周知,云计算是一种按需配给资源的商业计算模式[4].通过配备大量商用计算机群,云服务商可以为用户提供可伸缩的计算资源和灵活的综合云服务,包括但不限于服务器、存储、数据库、网络、软件、数据分析和商业智能等.企业采用按需付费,无需大量的前期投资即可快速访问所需的计算资源,更快研究和开发创新产品,并有效降低研发成本[5].此外,集成软件即服务(software as a service,SaaS)、平台即服务(platform as a service,PaaS)和基础设施即服务(infrastructure as a service,IaaS)的云供应商可以为企业提供从创新到运营所需的一切技术和服务,迎接数字时代的挑战,其中包括人工智能、区块链和物联网等创新技术.特别是,随着大数据时代的到来,数据处理的计算开销和资源消耗越来越大,计算任务变得日益复杂.面对产品以及业务智能需求时,资源有限的企业可以将机器学习任务外包给云服务商,通过借助云计算的处理能力和分析技术,完成信息挖掘和数据处理,同时节省升级计算设备带来的高昂费用.
机器学习是一种使机器模仿智能人类行为能力的人工智能技术[6].通过辅以数字、照片或文本数据,机器学习算法让计算机通过经验学习进行编程(即构建模型).数据越多,模型性能越好.因此,机器学习模型训练需要强大的数据存储和处理能力.通过资源连接,云计算可以承接该计算服务,帮助用户轻松试验各种机器学习技术.此外,企业还可以将机器学习模型托管在云端,经由API 接口为目标客户提供推理服务.相比于点对点(peer to peer,P2P)模式,云端托管可以减少因网络带宽或服务器故障出现的访问延迟问题,高效执行任务.同时,云端资源的可扩展性为托管模型的调整和改进提供可能,避免了数据迁移带来的额外开销.
尽管将机器学习任务外包给云服务商优点众多,但由于云端计算不透明且缺少有效监管,外包计算的数据隐私性和计算安全性仍受到外界质疑.为了解决面向机器学习外包计算的安全难题,学术界和产业界人员着手做了一系列研究.不同于模幂运算[7]、矩阵计算[8-9]等传统基础计算的外包安全研究,面向机器学习外包安全研究更着重于技术应用,平衡安全与性能.此外,云提供商也开始致力于安全技术研究,以应对潜在的威胁和满足用户的监管要求.公有云、私有云、混合云以及多云合作的复杂计算模式和终端设备整体计算能力的提升都给外包计算安全带来更复杂的挑战[10].
因此,本文重点调研和分析了2018—2022 年网络与信息安全领域的四大顶级会议(IEEE S&P,ACM CCS,NDSS,USENIX Security)以及IEEE TDSC,TIFS等著名安全期刊论文.基于这些研究成果,本文梳理了这5 年来研究者提出的面向机器学习的安全外包计算方案,文献来源分析统计如图1 所示.可以发现,面向机器学习的安全外包计算研究成果总量不多,呈逐年持平态势且每年都有顶级会议论文产出.从图1(b)关于文献的研究主题可以看到,这5 年的研究主要关注逻辑回归、朴素贝叶斯分类、支持向量机、决策树和神经网络等典型机器学习算法.研究文献的统计情况反映了面向神经网络的安全外包研究隐藏着大量尚待发掘的问题值得研究人员继续跟进.
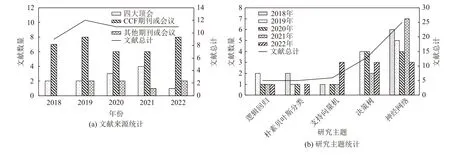
Fig.1 Statistics analysis of research literature source from 2018 to 2022图1 2018—2022 年调研文献来源统计分析
本文的主要贡献包括3 个方面:
1)给出了安全外包计算的通用框架和威胁模型,结合目前机器学习安全外包研究成果,从外包的机器学习任务阶段和云服务商数量,对计算模型进行了分类,总结了不同分类模式下的外包模型特点.
2)重点从逻辑回归、贝叶斯分类、支持向量机、决策树和神经网络等机器学习典型算法深入分析了现有安全外包计算研究进展,并对面向机器学习的安全外包计算研究进行了对比分析与探讨.
3)结合机器学习和云计算技术发展特点,分析了现有机器学习安全外包研究工作存在的不足,并重点从数据安全与效率平衡、计算完整性保护和迁移学习安全外包3 个方面探讨了机器学习外包安全研究面临的挑战以及未来研究方向.
1 安全外包计算典型模型
本节简要介绍了外包计算威胁模型以及安全外包计算的系统框架.
1.1 外包计算与威胁模型
外包计算通过将计算问题委托给云服务商处理,无需额外购买和升级计算设备,解决了用户资源受限的困境.不过,外包计算并未考虑服务提供商的安全可靠性.云服务商是营利商业个体,可能因逐利而非法收集用户数据.此外,由于云端操作的无监督和不透明,用户获取的计算结果可能因硬件故障或外部攻击而不符合要求.如图2 所示,外包计算主要包含半可信云服务商和恶意云服务商2 种威胁模型[11].
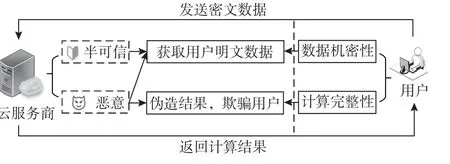
Fig.2 Threat model for outsourced computing图2 外包计算威胁模型
1)半可信云服务商.诚实遵守外包协议,正确进行计算.一旦获得正确的结果,半可信云服务商向用户发送结果.尽管如此,由于用户的外包数据和计算结果可能含有对半可信云服务商有用的信息,因此,云服务商可能觊觎用户的数据,私自留存进行转卖或商业分析.
2)恶意云服务商.相当于一个恶意的攻击者,在计算过程中可能偏离外包协议的正确流程.恶意云服务商不仅试图从用户的数据中学习隐私信息,而且还会故意伪造结果,欺骗用户以节省计算资源.
外包计算面临的威胁主要包括数据泄露和结果不可靠.因此,外包计算安全主要包括2 个方面[12]:
1)数据机密性.指对用户外包给云服务商的输入和输出数据进行保护,使其隐私信息不被非授权者(即云服务商)获取和利用的特性.
2)计算完整性.指对计算输出结果进行验证,保证数据按照用户指定要求进行处理,计算任务没有被未经授权的方式进行修改,其输出结果满足计算任务的要求.
云服务商可能受利益驱使损害外包计算的数据机密性和计算完整性.为了外包计算服务的良好发展,提供保护用户利益的安全外包方案需要着重考虑数据机密性和计算完整性保护问题.
1.2 安全外包计算框架
安全外包计算系统包含2 个不同实体:用户和云服务器.用户加密数据后将计算任务外包给云服务器处理,云服务器完成计算后,将计算结果发送给用户进行验证和解密[13].因此,安全外包计算通用模型[1]一般包含5 个模块:密钥生成、数据加密、任务计算、结果验证和数据解密.5 个模块以链式联结,模型框架如图3 所示.
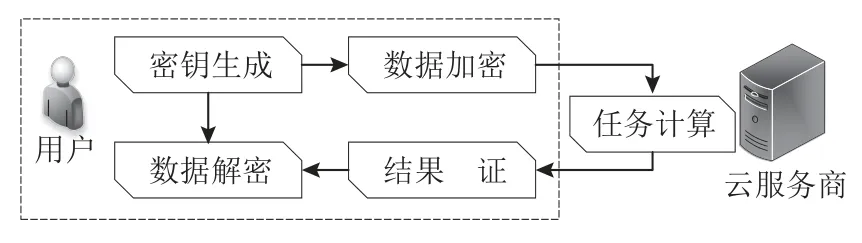
Fig.3 General model for secure outsourced computing图3 安全外包计算通用模型
1)密钥生成.根据外包协议设计,密钥生成模块会设计相应的密钥生成算法生成密钥(单个密钥或公私钥对)并完成密钥的分配.该模块可以由用户或者可信第三方完成.
2)数据加密.对用户需要外包的计算问题,数据加密模块会对问题中涉及的隐私数据进行加密.数据加密算法的设计需要考虑用户输入和输出的隐私安全.考虑到数据安全性,该模块一般只由用户完成.
3)任务计算.当用户将加密后的计算任务委托给云服务商后,云服务商根据用户要求完成计算.
4)结果验证.对云服务商返回的结果,结果验证模块会验证结果输出的正确性,判定云服务商是否如约履行计算.该模块确保了计算完整性.
5)数据解密.数据解密模块是对验证后的计算结果进行解密操作,获取计算结果的明文.该模块由用户完成,因此在确保云服务商返回的结果满足要求后,该模块才生效,以免给用户增加不必要的计算开销.
2 机器学习安全外包计算模型
本节分别从外包的机器学习任务阶段和云服务商数量等不同分类模式下,详细阐述机器学习安全外包计算模型的特点.
2.1 机器学习任务阶段
一个机器学习模型的完整任务阶段包括模型训练和模型推理.模型训练是通过揭示数据相关性从而构建利用该相关性评估目标数据的模型.因此,模型训练需要通过机器学习算法输入样本数据,利用机器学习算法帮助识别和学习数据特征属性,特别是将处理后的数据输出与样本输出相关联,利用相关性的结果对模型进行了修正,从而使模型得到预期输出.模型推理是模型通过简化并使用训练获得的能力对待验证的目标数据执行推理,获得预期结果.
在机器学习中,模型训练由于相比模型推理资源消耗更多,因此也是用户常考虑外包的计算任务.不过随着产业智能化发展,模型推理的商用场景增多,用户也会将推理任务委托给云服务商,以节省时间和计算资源.考虑到用户的需求即委托给云服务器的任务不同,面向机器学习的安全外包计算研究一般可分为模型训练和模型托管2 种模式,如图4 所示.
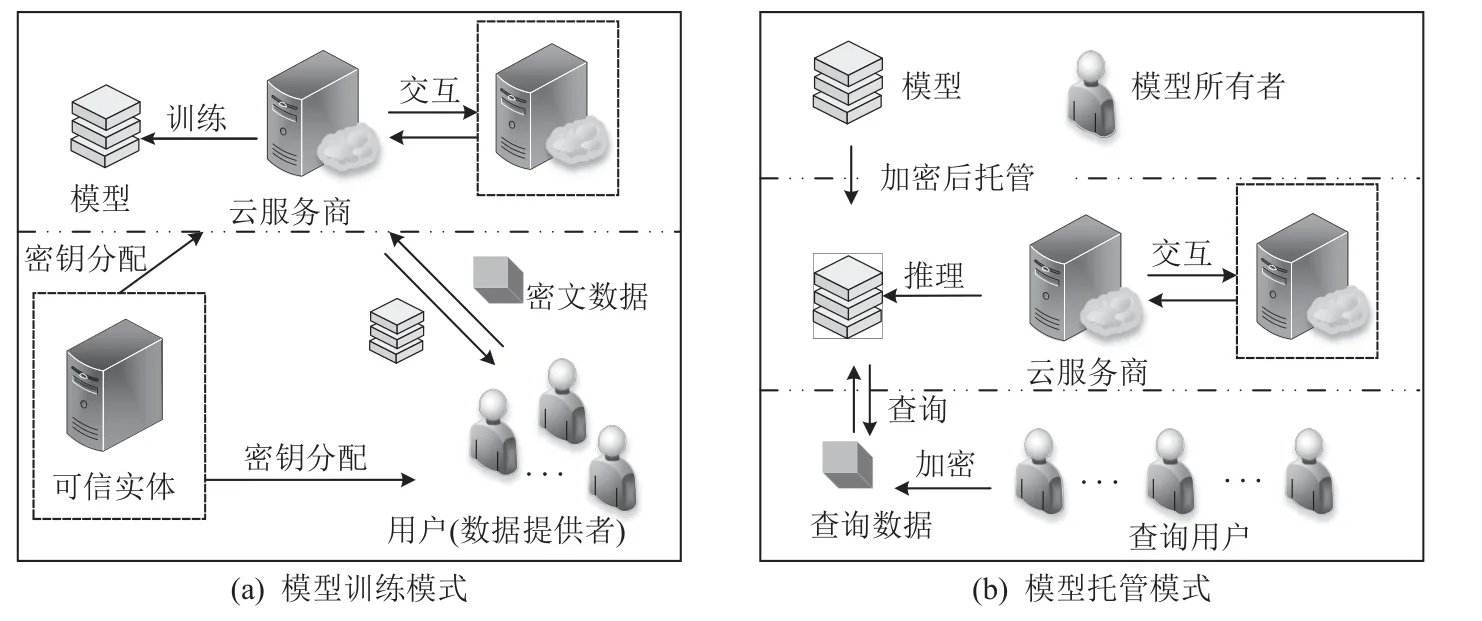
Fig.4 Two modes classified by task phase of machine learning图4 按机器学习任务阶段分类的2 种模式
1)模型训练模式,如图4(a)所示.模型训练中,一般包含2 类个体:用户和云服务商.用户担任数据提供者角色,云服务商承担模型训练任务.出于对数据保护的需要,用户会将训练数据加密后再发送给云服务商,要求其训练目标模型.云服务商需要在密文数据上构建模型,期间可能与用户进行计算交互.为了确保有效的数据保护和密文计算,模型中也会引入可信实体进行密钥生成和分发.此外,方案中也可能引入多个云服务商共同承担计算任务.
2)模型托管模式,如图4(b)所示.与模型训练模式不同,模型托管外包场景下的用户并非模型所有者,而是查询者.模型所有者将训练好的模型托管到云端,要求云服务商代理模型推理任务.用户发送查询数据给云服务商,云服务商根据模型推理,向用户返回查询结果.为了保护数据隐私,用户将查询数据进行加密,且要求查询结果对云服务商保密.推理过程一般不要求模型所有者参与,即支持模型所有者离线.
尽管这2 种模式中用户数据需要进行加密,但是模型训练模式的协议设计侧重云端密文计算的实现;模型托管模式则专注用户和云服务商之间的交互.针对同一种机器学习算法,虽然2 种模式分管机器学习任务的不同阶段,但是两者的算法计算操作相似,其安全计算协议可以相互拓展和借鉴.
2.2 云服务商数量
针对数据机密性保护,机器学习外包计算研究采用了多种方法,如全同态加密(fully homomorphic encryption,FHE)、差分隐私、安全多方计算(multiparty computation,MPC)等.根据采用的数据保护方法,需要考虑采用单个云服务商模式还是多个云服务商模式帮助用户完成外包计算任务.因此,考虑到涉及的云服务商数量,面向机器学习的安全外包计算研究还可分为单云(云服务器数量为1)模式和多云(云服务器数量大于等于2)模式,如图5 所示.
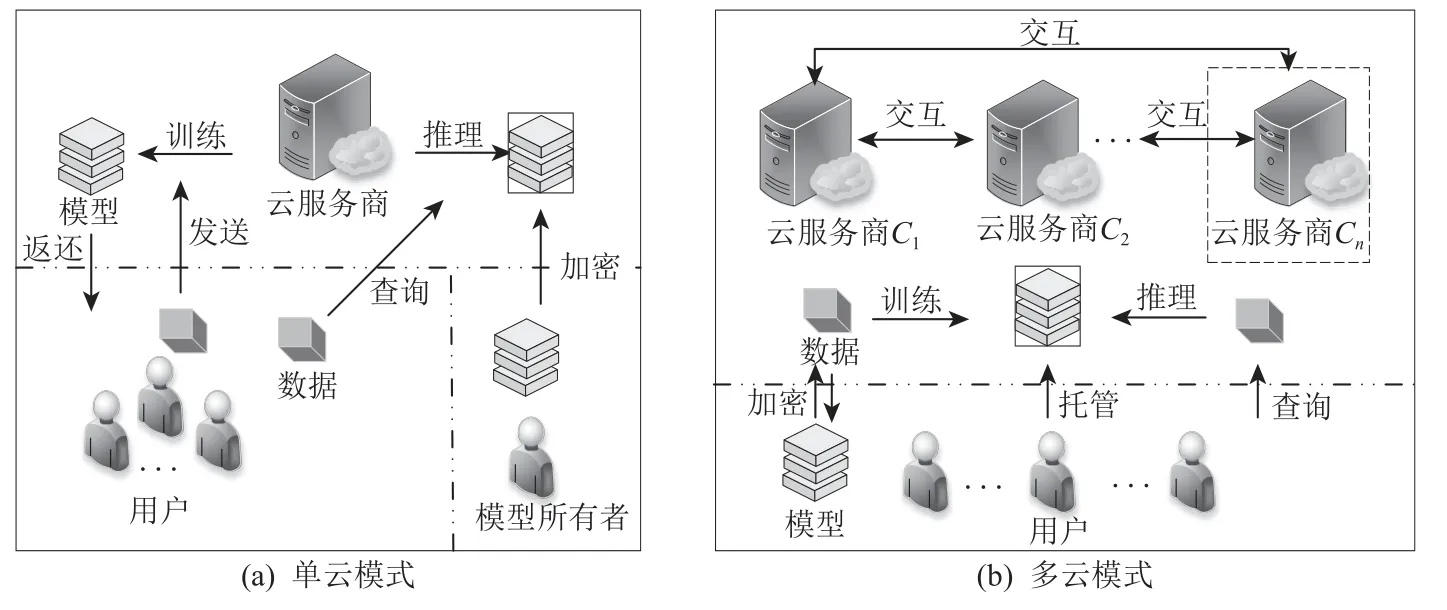
Fig.5 Two modes classified by the number of cloud service providers图5 按云服务商数量分类的2 种模式
1)单云模式,如图5(a)所示.单云模式中,用户将机器学习计算任务(模型训练或者推理)外包给一个云服务商进行处理.用户不需要考虑数据分割或模型切割.因此,单云模式的最大优点在于其简单高效,更容易协调.不过,单云模式通常采用FHE 加密实现数据保护,而该密文操作资源消耗极大,会极大地增加用户的训练费用或查询时间.
2)多云模式,如图5(b)所示.多云模式中,机器学习计算任务交由多个云服务商共同处理.云服务商通过一系列安全多方协议完成模型训练或推理.各个云服务商以用户的部分数据作为输入,并在整个计算过程中保持数据隐私性,然后将结果返回给用户.多云模式可以帮助用户采用非密码学工具,如加性秘密共享方式来保护数据隐私.因此,云服务商可以更快地处理计算任务.此外,多云模式可以避免单点故障,即使其中一个模块无法访问,用户仍然可以执行一些关键任务.不过,多云模式安全假设高,一般要求云服务商之间不串通共谋.
单云模式和多云模式的选择取决于计算和通信的取舍.单云模式不需要用户与多个云服务商交互,亦不需要云服务商之间的交互,因此通信开销较小.但是,支持单云下的密文计算一般只能选择FHE.多云模式可以通过数据分割实现隐私保护,避免了复杂的密文计算,但同时计算过程中也需要用户与云服务商之间的交互,同时增加了多个云服务商的多轮交互计算.因此,出于实用性考虑,单云模式和多云模式的选择要同时考虑具体机器学习算法和计算场景,并做好安全性和效率的权衡.
2.3 小 结
通过对2018—2022 年这5 年机器学习的安全外包相关文献采用的模型进行统计,发现机器学习的安全外包计算研究重点由模型训练趋向模型托管,单云模式与多云模式的应用情况基本持平,如图6所示.从2021—2022 年的研究情况来看,机器学习安全外包研究已经趋向多云模式.相比于面向基础计算的外包计算研究多采用同态加密(homomorphic encryption,HE),且因通信问题和共谋威胁而较少采用MPC 支持多云模式,而面向机器学习的安全外包研究偏向应用型,MPC 协议在多云模式中也崭露头角.外包计算是用户用金钱换取计算资源,因此安全外包计算方案的设计需要考虑数据机密性和计算完整性保护之外,还需要平衡计算效率.例如,高安全性的FHE 支持云服务商进行任意密文计算,但是计算高昂,不利于模型在云端的训练和应用部署.因此,模式的选择与数据隐私保护和计算效率的平衡密不可分.
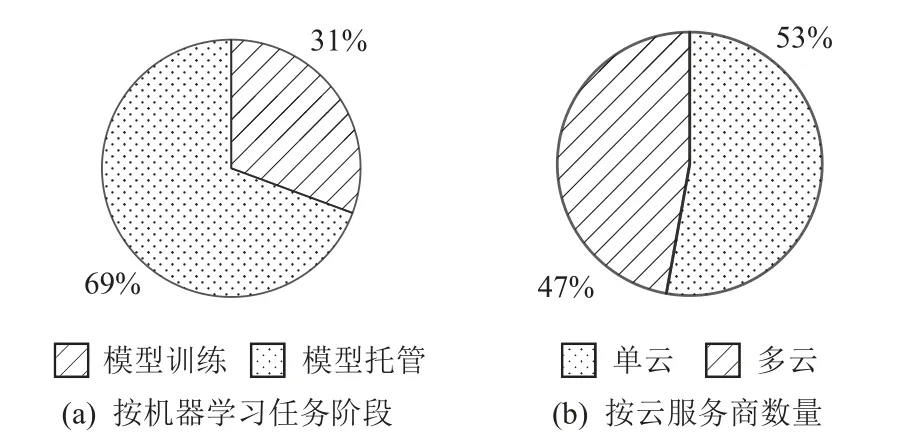
Fig.6 Model statistics of machine learning security outsourced research图6 机器学习安全外包研究模型统计
根据统计调研,表1 给出了机器学习外包计算模型应用趋势特点,具体总结为4 个方面:
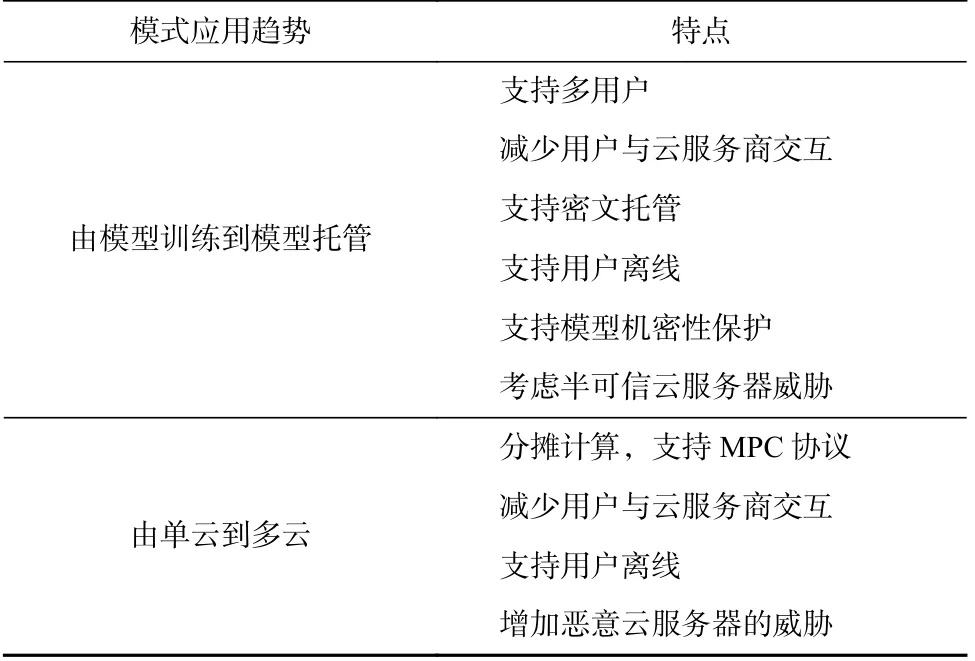
Table 1 Features of Machine Learning Outsourced Computing Modes表1 机器学习外包计算模型的特点
1)云服务器和数据源由单个趋向多个.机器学习模型的训练和推理涉及多种计算,包括线性计算和非线性计算.单云模式中一般采用FHE 来支持多种运算,保护数据隐私,但FHE 会严重拖慢模型计算进程.多云模式的引用可以分摊计算,加快计算进程.此外,机器学习基于数据建立统计模型进行分析预测,算法由数据驱动.因此,用户趋向聚集多源数据或者多个用户共同委托云服务器训练模型来提高机器学习模型性能.不过,多数据源场景中需要考虑不同密钥加密的密文对模型计算的影响.
2)用户端计算由在线趋向离线.面向机器学习的安全外包计算方案需要考虑现实应用场景.模型所有者将模型托管在云端以降低实施和运行成本,同时用户期望减少查询等待时间(即响应时间).因此,机器学习安全外包研究考虑将用户与云服务器的交互计算转移到云服务器之间,以支持用户离线.
3)外包阶段由训练趋向推理,模型托管由明文趋向密文.随着分布式学习[14]的兴起,机器学习模型训练方式趋向分布式.受此影响,面向机器学习的安全外包研究将重点转向模型托管的安全问题.在模型托管中,相比私有评估(即明文模型托管),密文模型托管外包除了需要保护查询数据和结果隐私外,还需要考虑模型机密性保护问题,安全性更高.
4)威胁模型主要考虑半可信.随着监管规范要求和竞争加大,机器学习安全外包研究主要考虑半可信威胁,去掉了计算完整性考虑.但是,验证模块的缺失并没有为用户节省很多计算开销,而多云和多用户模式的引入增加了隐私泄露的风险.
这些趋势表明了机器学习外包计算面临的安全威胁多元且复杂.根据应用场景,针对性选择模型部署模式,定制设计算法模块对机器学习安全外包研究至关重要.
3 典型机器学习算法安全外包计算研究进展
本节根据机器学习常见的不同算法,对2018—2022 年的相关安全外包计算研究工作进行了梳理和分析,总结了目前研究存在的问题及不足之处.
3.1 逻辑回归
逻辑回归[15]是一种统计模型,是监督学习中常用的预测二元结果的分类器.逻辑回归本质是将线性回归的输出用Sigmoid 函数进行映射来估计事件发生的概率,即输出结果数值在0 和1 之间.给定变量X和模型参数θ,逻辑回归模型表示为
文献[16]针对模型训练提出了一个基于HE 的逻辑回归安全外包方案.相比于之前的逻辑回归外包研究工作[17-18],该方案主要解决了2 个问题:1)由于计算量较小,基于推理阶段的安全外包难以应用于训练阶段;2)云端的密文计算量大,并随着多项式级数增加呈指数增长.该方案采用近似FHE 方案和近似Bootstrapping 方法来减少计算开销.一方面,通过支持高效的近似计算的FHE 方案加密训练数据,同时采用Nesterov 加速梯度法作为优化方法和最小二乘拟合方法模拟Sigmoid 函数,可以快速计算出复杂操作的近似结果并避免密文除法操作.另一方面,设计并行化Bootstrapping 操作算法,将密文分割成多个小块,并行执行Bootstrapping,可以显著提高整体性能.此外,该方案通过对训练数据集分区,将子数据集打包成一个密文,避免了密文重构的额外开销.实验证明,该方案具有较好的性能提升,但引入的加密方案对训练模型的精度和性能的影响并不显著.
文献[19]重点探讨了生物医学场景中的逻辑回归模型在公共云环境下的训练问题,提出了SecureLR框架,帮助研究人员利用云计算对生物医学数据进行学习和预测.基于HE 和软件保护扩展SGX 的安全硬件,SecureLR 考虑采用双云模式,一个执行HE计算,另一个支持安全硬件计算.相比于文献[16]的方案,SecureLR 采用了HE 和安全硬件相结合的混合模式,提供了一种多层面的数据提供方法.文献[16]和文献[19]都采用了密文批处理,用一种单指令多数据(single instruction multiple data,SIMD)的方式实现并行处理,提高计算效率.
跟进研究[20-21]延续了应用FHE 加密数据和模拟Sigmoid 函数的设计,但是在细节上略有差异.文献[20]改用泰勒展开式进行逼近Sigmoid 函数,而文献[21]仍然选用最小二乘法.除此之外,文献[21]提出的P2OLR 方案允许数据所有者和云服务器在训练过程中交互,判断密文训练的模型是否满足要求,避免错误训练浪费资源.不过尽管FHE 支持密文加法和乘法,但逼近Sigmoid 函数的多项式每一次运算都会叠加噪声,而Bootstrapping 操作虽然可以重置噪声,但计算成本极大.为此,文献[22]提出了一种不同的隐私保护方法支持逻辑回归的安全外包.该方法不需要用多项式逼近Sigmoid 函数以及预先确定多项式级数,而是将其转化为对应的岭回归逻辑函数并采用层次HE 方法.如图7 所示,该方案包括3 个步骤:1)用未加密的数据集D1训练教师模型fs,从目标标签中提取概率;2)利用加密教师模型推导出加密数据集D2的逻辑值,通过均值匹配进行优化;3)在D2上训练岭回归.具体来说,该方案通过将加密变量和非加密变量的运算分开从而采用免Bootstrapping 的层次HE 方法实现数据保护,同时采用均值匹配缓解了由于未加密数据和加密数据分布差异而导致的模型性能下降问题.实验表明,应用层次HE 方法不仅具有更好的分类效果,且计算时间更短.
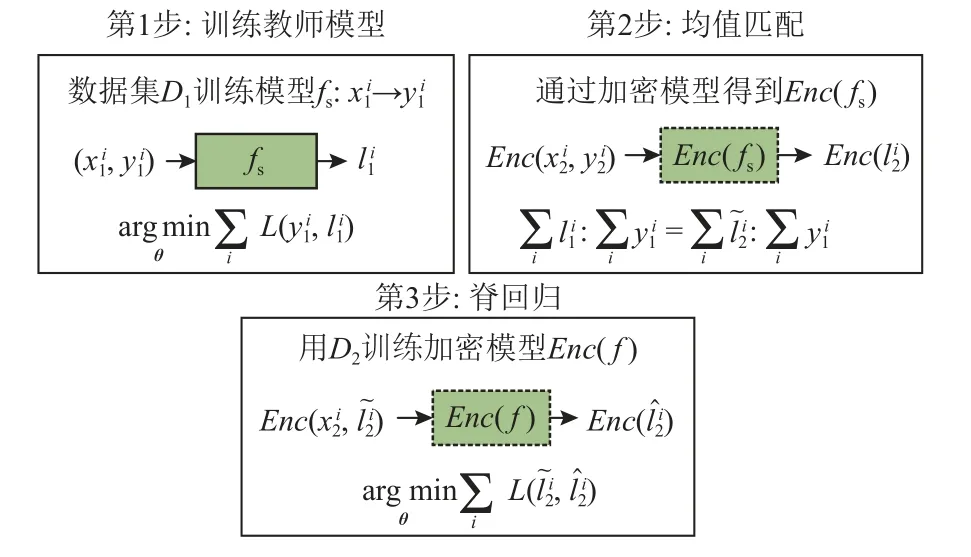
Fig.7 Training logistic regression by ridge regression图7 通过岭回归训练逻辑回归
表2 总结了已有的逻辑回归外包方案的对比情况.可以看到,现有的逻辑回归外包方案主要采用单云模式且重点考虑模型训练阶段的外包安全问题.尽管现有方案都倾向采用密文打包,用SIMD 实现并行化处理以提高计算效率,但是在实际应用中FHE带来的计算开销不容乐观.此外,现有的方案都假定参与实体为半可信或可信且不共谋,但是在现实世界中仍然存在恶意参与者破坏或窃取模型.因此,如何在恶意敌手假设下提高外包方案的安全性并降低计算开销需要进一步研究.

Table 2 Comparison of Logistic Regression Outsourced Schemes表2 逻辑回归外包方案对比
3.2 朴素贝叶斯分类
朴素贝叶斯分类[23]是基于贝叶斯定理的分类算法集合,通过对数据属性集和数据类之间建立概率关系判定数据的类别.给定数据X=(x1,x2,…,xd)、类别集{c1,c2,…,cm}、先验概率{P(C=c1),P(C=c2),…,P(C=cm)}和条件概率是类ci时的第j个属性为v的概率),则朴素贝叶斯分类定义为
文献[24]专注朴素贝叶斯分类的推理外包,提出了一种朴素贝叶斯分类模型的安全托管方案.如图8 所示,模型所有者采用Paillier 算法对分类器进行加密后将其托管到云端,并向用户授权查询令牌和私钥.授权用户用私钥加密查询数据,而云服务器存储加密模型,并对授权用户的查询做出响应.该方案通过加法HE 同时完成分类器模型和用户数据的机密性保护.不过,该方案需要用户和服务器频繁交互,通信开销较大,对资源受限的用户并不友好.因此,文献[25]提出了改进方案.改进方案引入了一个可信处理器,承接原本查询过程中用户需要完成的解密操作,使用户在与服务器不超过2 次的交互后即可获得查询结果.

Fig.8 Naive Bayes classification model hosting framework图8 朴素贝叶斯分类模型托管框架
文献[26]指出文献[24]的方案容易遭受替换攻击,被窃取模型信息,即查询用户可以在执行argmax协议期间特意替换一些值从而恢复模型参数.针对这一漏洞,文献[26]引入了盲化技术,向模型添加特定的扰动值,使恶意用户无法在执行替换攻击后获得模型参数的有效信息.此外,方案改用OU 加密算法[27],减少了用户与服务器之间的交互次数,提高了计算效率.实验证明,该方案可以在防止替换攻击造成的信息泄露下有效降低计算成本和通信负担.
文献[28]重点关注朴素贝叶斯分类的训练外包.针对现有研究[29-30]中存在的不支持多个数据提供者和统计信息泄露的问题,文献[28]将Paillier 加密算法和差分隐私技术相结合,提出了多数据源的朴素贝叶斯学习外包方案.该方案通过Paillier 算法加密数据,支持不同数据所有者上传的密文加法计算,利用差分隐私向训练模型中添加噪声,使模型使用者无法从训练器判定数据所有者是否拥有某个样本.不过,文献[28]的作者未在实验中提供模型性能的评估结果,尚无法确定差分隐私对模型准确度是否产生影响.
针对在线疾病风险诊断,文献[31]基于贝叶斯分类设计了支持模型动态更新的疾病风险评估CARER方案.CARER 方案实现了云服务器上的模型训练到模型推理的承接.模型提供商可以收集多个医疗中心的密文数据进行模型训练和更新,同时为用户提供疾病风险预测服务.CARER 方案引入了一个可信实体用来分发密钥.相比于之前的研究,CARER 方案通过将密钥切割和聚合,防止模型提供商恢复医疗中心的数据统计信息,同时支持模型的明文训练,提高了模型计算效率.
表3 总结了已有的朴素贝叶斯分类外包方案的对比情况.可以看到,现有的朴素贝叶斯分类外包方案都采用单云模式,但会考虑引入可信实体承担密钥处理工作以增加安全性.考虑到朴素贝叶斯分类算法中以加法操作为主,大部分方案选用Paillier加密算法保护数据和模型的机密性.不过,与逻辑回归外包研究类似,现有方案都只考虑半可信安全,尽管文献[26]考虑了存在恶意用户情况,但是仅针对文献[24]的漏洞,不具有普适性,计算完整性保护问题仍待解决.

Table 3 Comparison of Naive Bayesian Classification Outsourced Schemes表3 朴素贝叶斯分类外包方案对比
3.3 支持向量机
支持向量机[32]是一种常见的监督机器学习模型,它主要用来解决二分类问题.支持向量机通过训练数据集在高维空间寻找超平面分隔数据点来确定决策边界.支持向量机也可以通过为每一类数据创建一个分类器,解决多分类问题.假设训练集包含N个样本即{(x1,y1),(x2,y2),…,(xN,yN)},其中yi∈{-1,1},i∈{1,2,…,N}.对线性可分问题,可以直接寻找决策超平面w·x+b=0.分类器模型定义为
尽管之前关于支持向量机外包安全研究[33-34]已经采用相关隐私保护技术,如随机扰动、加法同态和安全多方计算,尝试解决了外包训练中存在的数据隐私问题,但是后续的研究发现它们仍然存在可靠性和安全性问题.比如,文献[35]指出文献[34]的Paillier 密文计算中由于存在溢出风险,[[zmod10l]]*[[rmod10l]](*表示同态密文乘法)不一定等于[[(z+r)mod10l]],因此云服务器可能返回错误的分类结果.为了解决这一问题,文献[35]采用了一种混合方法,将HE 和混淆电路(garbled circuits,GC)结合,避免溢出风险,减少计算时间.
针对模型仅支持单个数据所有者的问题[34],文献[36]则在制药应用场景下探讨了多数据源的支持向量机训练外包安全问题,提出了POD 方案.POD方案支持云服务器采用多个数据所有者的数据来训练支持向量机模型,并提供查询.为了解决多用户采用不同密钥加密的密文不支持同态计算的问题,POD 方案特别设计安全域转换算法,将不同密钥中的密文转换为一个域,支持密文计算.同时,针对密文的明文长度存在溢出的问题,设计了分数近似协议减小明文长度.然而,文献[37]认为只给定密文情况下无法判定明文长度,因此该分数近似协议并不实用.为此,设计了一种控制浮点数在安全计算过程中比特长度的协议,强化了分数近似协议,消除了预知消息长度的前提.
除此之外,文献[38]针对现有研究[39]中存在计算开销大的问题,提出了PPSVM 方案.该方案通过使用SIMD 技术来加速支持向量机中内积求和操作,即线性计算,同时使用近似方法来计算符号函数,即非线性计算部分.文献[40]考虑了恶意云服务器伪造结果欺骗用户的情况,针对半可信和恶意威胁模型提出了解决方案AADP.该方案综合使用安全哈希函数、Householder 变换和随机排列,保证了数据机密性、模型机密性以及结果可验证性.文献[41]则考虑了恶意用户对模型隐私的影响,提出了一种基于多分类支持向量机的隐私保护医疗诊断方案.该方案采用DT-PKC 和BGN 密码系统,保护用户数据隐私,同时提出了用户认证机制用于规避非法用户对诊断系统的恶意攻击.如图9 所示,方案AADP 要求对每个用户身份进行真实性验证(如医疗资质),验证通过后会分发给用户一个包含公钥、颁发者、过期日期等信息的文件.发送查询请求时,用户需要在第三方的协助下发送时间戳和证明文件.但是,由于方案AADP 采用的BGN 加密算法是基于双线性映射,增加了同态乘法的计算开销,降低了方案的计算效率.
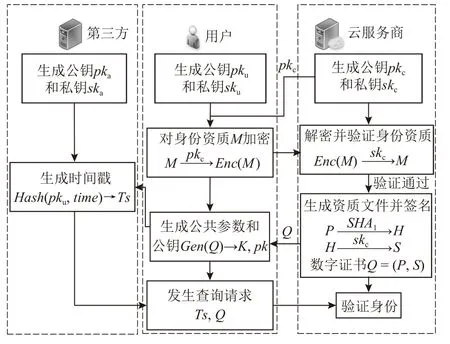
Fig.9 User authentication mechanism图9 用户身份认证机制
表4 总结了已有的支持向量机外包方案的对比情况.可以看到,现有的支持向量机外包方案大多采用HE 技术.但是由于计算中涉及非线性操作,部分方案采用在线交互的模式.通过用户与服务器多次交互对中间结果进行加解密完成非线性计算,给用户带来额外的计算和通信开销.尽管有研究[40]考虑解决了支持向量机外包中的计算完整性保护问题,但是提出的方案对矩阵盲化的数据大小比较缺乏正确性推导.因此,文献[40]方案的有效性也存在质疑,支持向量机外包中的计算完整性保护问题仍值得后续跟进.

Table 4 Comparison of Support Vector Machine Outsourced Schemes表4 支持向量机外包方案对比
3.4 决策树
决策树是一种树形结构的非参数监督学习算法,是目前最流行的机器学习算法之一,用于回归和分类.决策树包含1 个根节点、多个内部节点和叶节点,节点之间通过分支连接,每个节点通常有2 个或多个从其延伸的节点.分支是连接节点的箭头,通过在根节点和内部节点上采用阈值比较,决定分支走向,形成决策路径.目前常用的决策树生成算法有ID3,C4.0,C5.0 等[42].
早先关于决策树的外包安全研究[43-45]主要集中在私有评估上,即云服务器持有明文形式的模型.大多数方案依赖FHE,GC,ORAM 保护用户的查询数据,计算开销较大.文献[46]探讨了私有评估中3 个子协议:特征选择、比较和路径评估,分析并评估了分别使用加性HE 和GC 时协议的效率,发现采用混合协议可以有效提高模型的评估效率.文献[47]则针对协议执行轮次进行改进,通过将树表示为一个数组,将执行深度控制在树的深度.
文献[48]提出了一种密文模型托管的安全外包方案.该方案基于双云模式,采用加性秘密共享方法解决了模型托管和推理过程中的安全输入特征选择、决策节点评估和推理结果生成保护问题.具体而言,查询用户将特征向量分成2 个秘密共享,分别分发给2 个云服务器,云服务器收到数据后进行交互计算运行决策树算法,并发送结果给用户解密.整个查询过程不需要用户在线.之后,研究人员又在拓展版文献[49]中提出了一个基于多项式的结果生成算法,进一步降低了用户的通信开销.不过,文献[50-51]指出文献[49]方案的计算成本随节点数量呈指数增长,不适用于大规模树,并提出了优化方案.针对密文模型托管,文献[52]也提出了一种决策树分类外包方案.不同的是,该方案采用了单云模式,并将决策树转换为决策表,如图10所示.决策树转换可以将模型推理转换为决策表查找.具体来说,模型所有者通过将决策树分类器转换为一个决策表,并采用可搜索对称加密对其处理后再托管到云服务器上.用户加密数据特征后再发送给服务器进行查询.云服务器通过对比加密表格搜索预测值,并发给用户.相比其他方案,该方案在保证模型和数据机密性的同时也降低了用户和云服务器之间的通信开销.文献[53]则在此基础上,考虑了恶意用户威胁,引入了用户身份认证协议.
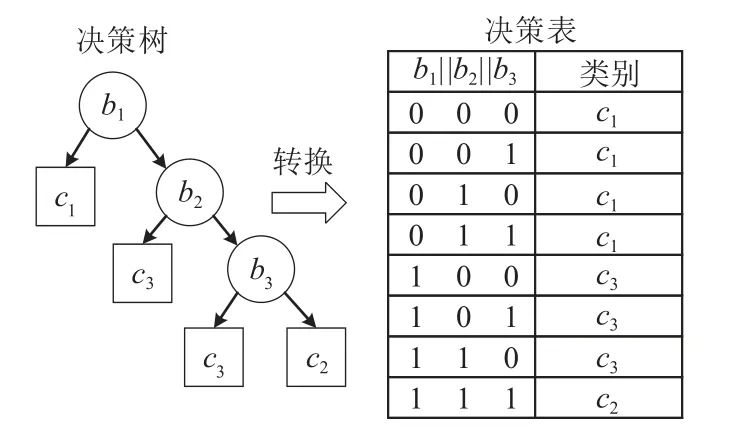
Fig.10 Decision tree transformation图10 决策树转换
针对现有方案不支持密文数据上的模型训练问题,文献[54]提出了一个具有隐私保护的外包方案支持决策树的训练和预测.该方案采用FHE,并利用密钥管理服务(key management service,KMS)提供密钥支持多个云服务器在密文数据上进行模型训练和模型预测.不过该方案需要满足密钥一致性,可能存在不适用于多数据源场景.文献[55]将重点转向多数据源场景下的模型训练外包,构建了PPDT 方案,并针对私有评估提出了PPDE 方案.这2 个方案都采用了DT-PKC 加密算法保护数据隐私.此外,考虑到云服务器无法对密文数据集进行最佳属性划分,设计了不分割数据集的决策树训练方法,分别满足3种隐私级别:2 个服务器都知道数据属性频率;只有1 个服务器知道数据属性频率;2 个服务器都不知道数据属性频率.在模型训练后,经过训练的云服务器得到决策树模型以提供私有评估服务.
文献[56]提出了由多个模型所有者托管决策树进行联合决策的外包方案,即随机森林安全外包方案.相比于单个决策树分类器托管,随机森林安全外包方案需要对多个决策树分类结果进行聚合得到最后结果.因此,该方案需要模型所有者们创建一个联合密钥,然后用分密钥加密模型再托管到云端.在收到用户的查询请求后,云服务器会对单个加密的随机森林安全外包方案模型执行推理并计算聚合的结果.
考虑到现实世界中数据流的存在,文献[57]将模型训练和推理过程动态连接在一起,即模型可以针对标签数据和无标签数据,在训练和推理中来回切换,并提出了EnclaveTree 方案.该方案包含2 个执行区以及2 个缓冲区:透明训练区、透明推理区,训练缓冲区和推断缓冲区.缓冲区用于接收加密的带标签和无标签数据,分别进行训练和推理.EnclaveTree方案会周期性读取一批数据样本进行训练,并用矩阵盲化技术进行加密.与现有的决策树方案相比,EnclaveTree 不仅支持数据流处理,且通信和计算开销更小.此外,文献[58]结合树编码方法、共享无关选择功能和安全计算构造了决策树外包方案,隐藏决策树评估过程中被访问节点,并将通信复杂性优化到O(d).
表5 总结了现有决策树外包方案对比情况.通过分析可以发现,现有的决策树外包研究主要关注模型托管安全问题,而且主要采用HE 或秘密共享实现数据机密性保护.决策树推理主要包括3 个部分:特征选择、比较和路径评估.对模型托管,尤其是密文模型托管,需要考虑密文比较协议和路径评估协议的设计,避免比较次数增多带来的通信开销和路径暴露带来的信息泄露.
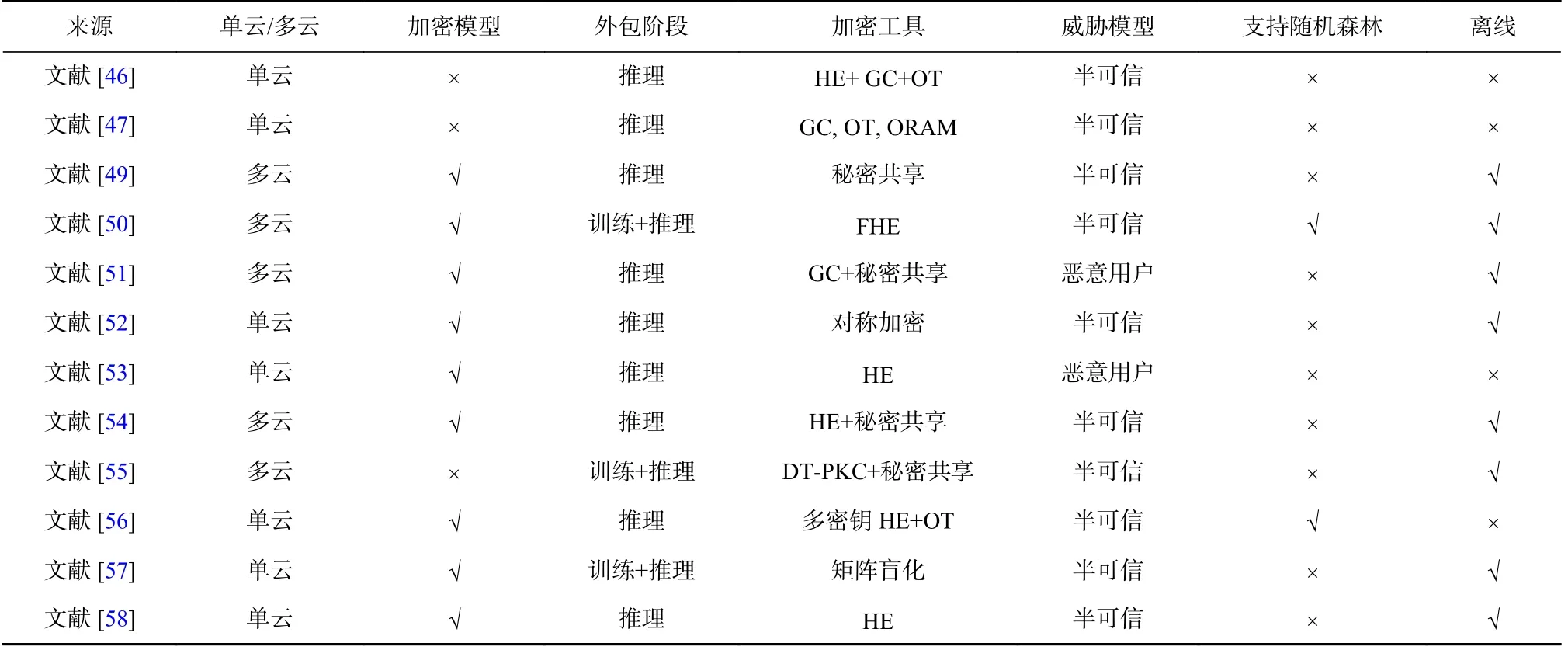
Table 5 Comparison of Decision Tree Outsourced Schemes表5 决策树外包方案对比
3.5 神经网络
神经网络[59]是机器学习中最为常用的监督学习算法,也是深度学习算法的核心.神经网络由多个人工神经元联结组成,包括输入层、1 个或多个隐藏层和1 个输出层.除了输入层外,其他层神经元都会进行数据处理.单层的神经网络也称为单层感知机,其只包含输入层和输出层,是最小学习单元,其模型表示为
其中w和b是模型参数,σ(·)是输出神经元的激活函数.神经网络可以看作由多个感知机联结而成.
文献[60]针对单层感知机(single layer perceptron,SLP)的训练和推理提出了一种安全外包方案.该方案利用矩阵盲化技术加密训练数据和查询数据,保证了数据机密性.不过,文献[61]指出该方案中用户端计算开销为O(n3),并没有为用户节省开销.对此,文献[61]将盲化矩阵替换为稀疏矩阵,并设计了结果验证协议,在降低用户计算开销的同时保护了计算完整性.不过由于单层感知机的应用较少,不适用于大规模数据,因此未有其他外包安全研究继续跟进.
文献[62]针对深度神经网络的训练和推理提出了一种基于多密钥的安全外包方案.该方案支持多个用户加密数据上传给云服务器进行模型训练和推理.多密钥技术的采用使得云服务器可以进行密文转换,完成模型训练.文献[63]引入了双云模式,采用加性秘密共享和数据分割完成了区域卷积神经网络(region convolutional neural network,R-CNN)的安全训练外包.相比采用多密钥和秘密共享对训练数据加密引入了额外的计算开销,文献[64]借鉴了联邦学习的思想,将深度神经网络(deep neural network,DNN)的训练分为2 部分.多个用户在本地训练DNN的初始层进行特征提取,然后上传特征,将剩余层训练外包给云服务器.该方案可以避免数据加密操作的同时防止数据泄露.除此之外,文献[65]采用秘密共享,引入了3 个云服务器完成DNN 的模型训练;而文献[66]采用了矩阵盲化技术加密训练样本,降低了用户和云端的计算开销.不过文献[66]方案并未对模型更新中的非线性计算部分给出说明,其方案有效性存在疑问.
除了模型训练外包外,文献[67]还考虑了分布式学习框架下模型训练后的托管问题.为了避免模型的泄露,引入了一个监管者共同托管模型,监管者和云服务器同构MPC 协议,重构乘法和非线性LReLU 激活函数,并分享基于查询数据的计算结果.文献[68]提出了一种用于医疗诊断的神经网络推理外包方案MediSC,该方案针对神经网络中的线性层和非线性层设计了计算协议,同时采用秘密共享技术,减少了服务器和用户之间的交互,降低了延迟.除了医疗场景外,文献[69-70]还分别考虑了移动式磁感测定系统中的特征提取和图像去噪服务.此外,文献[71]针对模型推理过程中存在的延迟问题做出了改进,但是方案的计算和通信开销较大,跟进研究[72-73]对此做了改进.文献[74]考虑了恶意用户存在的情况;文献[75-80]引入了双云设置加快计算进程.如图11 所示,双云模式中,数据采用秘密共享协议进行分割,然后分别发给2 个云服务商.服务商之间采用MPC协议进行模型计算,得到的结果也采用秘密共享形式分别发给用户.最后,用户组合得到结果.除此之外,文献[81-84]也考虑了恶意云存在的情况,将双云设置拓展到多云设置,解决了在诚实多数环境下的模型推理安全问题.
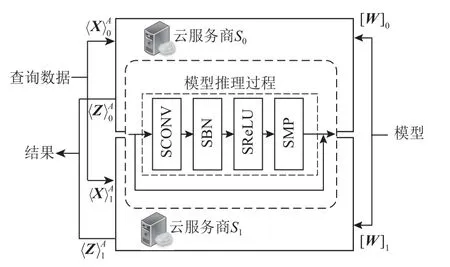
Fig.11 DNN inference in two cloud modes图11 双云模式下的DNN 推理
表6 总结了已有的神经网络外包方案的对比情况.可以看到,神经网络外包方案已经逐渐由单云模式转向多云模式.相比于其他的分类模型,神经网络的模型训练和计算更为复杂.因此,多云模式可以引入秘密共享协议,比密文计算更能提升方案计算效率.相对于单云模式,多云模式中常采用GC 和秘密共享,在实用性方面其通信开销仍然较大.现有采用多云模式的外包方案已经考虑了恶意云服务商的威胁,但是其解决方案是引入多云,且没有考虑出现共谋情况下的数据和模型隐私安全.

Table 6 Comparison of Neural Network Outsourced Schemes表6 神经网络外包方案对比
3.6 对比分析与讨论
通过对典型机器学习安全外包计算研究深入调研,可以发现面向应用型的外包计算研究已经从简单模型拓展到复杂模型,但是由复杂的训练外包转向模型托管.尽管目前大多数外包方案主要基于半可信威胁,但是仍有研究尝试解决恶意云服务器和恶意用户存在下的数据隐私保护问题.相比针对基础计算的安全外包方案,机器学习安全外包计算研究在数据保护技术的选择和协议构建上更注重实际应用.比如,决策树外包研究在解决模型托管问题时,主要采用HE 或秘密共享而非计算开销极大的FHE.除此之外,单云模式中引入可信实体以及采用多云模式分担计算,也是为适应实际模型计算中的数据机密性保护做出的努力.
根据调研分析,总结3 个机器学习安全外包计算研究进展趋势:
1)数据保护技术由单一趋向混合.面向简单分类模型的外包方案一般采用单一的加密技术,如FHE或加性HE,而面向决策树和神经网络的外包方案较多采用HE、GC 和秘密共享的两者结合或三者结合.混合技术的使用避免了开销过大的密文计算,同时也减少了用户与云服务器的交互,易于方案的实际部署.
2)问题的解决思路多样化.基础计算的安全外包方案按照计算类型设计数据保护协议,但面向机器学习的外包方案中由于每种模型涉及的计算操作不同,较多且复杂,因此协议设计可以依据模型特点做出改变.比如,在决策树外包计算研究中可以将决策树模型转换成决策表,由密文搜索代替密文比较.在支持向量机外包计算研究中则可采用增加用户和服务器交互,对中间结果进行加解密,解决密文的非线性计算问题.
3)威胁模型开始讨论恶意云服务器和恶意用户的存在.尽管在面向简单模型的安全外包研究中较少考虑恶意云服务器和恶意用户对数据隐私的威胁,但是有研究已经针对恶意用户提出了身份认证的要求,且考虑引入多云解决恶意云服务器对模型计算安全造成的威胁.不过与传统的计算完整性保护不同,现有研究提出的解决方案主要针对隐私保护,即数据隐私和模型隐私,未针对验证问题提出相应的验证机制.
4 挑战与机遇
通过对现阶段机器学习安全外包研究现状的深入调研,发现机器学习安全外包研究虽然已经取得了一些显著的成果,但是仍然存在不足之处.本节从待改进、未解决和新出现3 个层面分析总结机器学习安全外包研究面临的问题和挑战以及潜在机遇.
4.1 数据安全与效率权衡
为了保护数据机密性,目前大多数机器学习安全外包方案大多采用牺牲通信或计算来换取数据安全,即采用多云模式结合数据分割或者单云模式结合HE.但是,从外包计算的实用角度来看,密文计算或多云租赁不仅对用户的本地计算提出挑战,也增加了云端消耗,即用户花费.特别对于模型托管中的查询用户来说,查询前的数据加密操作和查询过程密文计算造成的延迟都可能降低用户的模型使用意愿,不利于模型所有者的商业发展目的.因此,如何同步平衡外包方案中的计算和通信开销、减少用户本地消耗、降低用户和云服务器的交互轮次,是机器学习安全外包研究目前待改进的问题.
4.2 计算完整性保护
计算完整性保护是外包计算安全研究的核心之一,但是面向机器学习的安全外包方案大部分只考虑半可信威胁,即数据隐私问题.尽管有研究者探索了在恶意云环境下的安全性问题,但是只涉及简单分类器,如支持向量机[40]、单层感知机[61],面向复杂模型(如神经网络)的计算完整性保护工作仍存在空白.现实世界中,单云模式中可能因为出现单点故障而计算错误.多云模式中如果一方出现恶意计算,则会因为监管缺失无法判定责任所属.此外,模型训练中的计算完整性也同样重要.关于机器学习的模型安全研究[85]已经发现后门攻击可以在不破坏模型性能的情况下对模型安全造成影响.尽管目前后门攻击只涉及明文模型,但是这也说明仅通过验证数据集判定模型性能是否良好不足以保护计算完整性.因此,为用户设计模型完整性和结果正确性验证机制可以有效增强机器学习外包方案的安全性,这也是机器学习安全外包研究目前未解决的问题.
4.3 迁移学习安全外包
现有的机器学习安全外包研究已经考虑了多用户多数据源场景下的模型训练外包问题,说明数据多样性有助于模型性能提升.但是,多用户场景存在用户异构性,即用户数据、计算能力和需求不同,异构性会影响外包方案的实际部署.为解决这一问题,可以考虑迁移学习的安全外包.迁移学习可以在较少训练数据情况下训练高性能模型,同时减少训练时间和计算资源.在公众数据安全意识提高和数据获取困难的情况下,用户可以在较少数据时利用迁移学习训练模型.因此,设计迁移学习安全外包方案,帮助模型所有者安全托管教师模型,支持多用户采用云资源按需训练学生模型,以及如何实现数据短缺下的模型训练,是机器学习安全外包研究新出现的挑战.
5 结 论
机器学习技术推动了现代社会的数字化发展,企业借助云资源完成产品和服务的智能化优化,具有广泛应用,然而云计算安全问题逐渐显露引起了学术界的广泛关注.本文通过深入调研面向机器学习的安全外包研究成果,按任务阶段和云服务商数量对模型进行分类,总结了不同分类模式下外包模型的特点.同时发现,现有研究的外包模型趋向模型推理,且较多采用多云模式.然后,集中分析了国内外的相关研究工作,按逻辑回归、朴素贝叶斯分类、支持向量机、决策树和神经网络等算法讨论了目前取得的研究进展.最后,从不同角度分析和讨论了目前机器学习安全外包研究待改进、未解决以及新出现的问题,并探讨了未来面临的挑战和机遇.
作者贡献声明:陈珍珠提出了整体框架,负责内容设计、论文撰写和最后版本修订;周纯毅负责完成文献整理、分析和最终审核;苏铓针对论文框架和表述提出指导意见并修改论文;高艳松针对研究进展分析提出了指导意见并进行了完善;付安民针对整体论文提出了指导意见并修改论文.
