构建重型机械装备制造企业大数据平台相关的技术架构研究
2023-07-17汪忆钟世成陈素琼
汪忆 钟世成 陈素琼

摘要:文章基于重型机械装备制造企业的数字化发展现状.对企业在进行数字化转型中面临的数据孤岛、数据沉睡束发挥价值、数据使用成本较高等问题进行了分析,并深入阐述了数字化转型涉及的大数据相关技术架构,提出了大数据平台建设可选的技术解决方案,为重型机械装备制造企业构建大数据平台技术架构提供借鉴和参考。
关键词:机械装备制造企业;大数据平台;技术架构
中图法分类号:TP311 文献标识码:A
1 概述
1.1 研究背景
作为国民经济的主体,重型机械装备制造企业面临数字化转型的诸多难题和挑战,其中最突出的问题是:传统的“烟囱式” 应用开发模式造成的“数据孤岛”现象严重,使得数据难以发挥价值;诸多业务系统数据(如PDM 系统、ERP 系统)集成度不高,经常出现数据找不到、用不上、不准确等困难;由于数据存储格式、代码标准不统一以及数据质量参差不齐导致数据不可用的现象时有发生;数据出现重复存储,重复计算,取数技术难度较大,对业务人员及IT 人员技术要求过高,造成数据使用成本较高;企业目前的信息化系统繁多,集成度低,缺乏高效可用的数据中心,企业内部的数据资产很难盘点,而且缺乏有效应用服务,数据资产价值也很难评估;信息化技术平台工具繁多,多厂商技术平台集成困难,以至于体验差、运维成本极高。
1.2 问题的提出
本文基于重型机械装备制造企业业务领域的大数据平台构建需求,对其进行了分析,并指出研究方向。在此基础上,如何基于大数据平台生态技术架构,构建重型机械装备制造企业大数据平台技术解决方案是本文的核心研究问题。
2 认识Hadoop 大数据平台
2.1 Hadoop 的起源
Hadoop 是一个由Apache 基金会所开发的分布式系统基础架构,是一个能够对大量数据进行分布式处理的软件框架,主要解决海量数据的存储和分析计算问题。Hadoop 是由Doug Cutting 和Mike Cafarella 于2002 年所创建的Nutch 项目,Nutch 是一個开源Java实现的搜索引擎,目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能[1] 。
2003~ 2004 年,Google 发表了GFS(Google FileSystem,分布式文件系统)和MapReduce(开源分布式并行计算框架)2 篇论文,受此论文的启发,2004 年,Nutch 创始人Doug Cutting 基于Google 的GFS 论文实现了分布式文件存储系统NDFS。2005 年, DougCutting 又基于Google 的MapReduce 论文,在Nutch 搜索引擎实现了该功能,同年Hadoop 作为Lucene 的子项目Nutch 的一部分正式引入Apache 基金会。2006年2 月,Nutch 被分离出来成为一套完整独立的软件,命名为Hadoop,它是以Doug Cutting 儿子的毛绒玩具象命名的,Hadoop 起源于Google 的三大论文,GFS 对应演变为HDFS, Google MapReduce 对应演变为Hadoop MapReduce,Big Table 对应演变为HBase[2] 。
2.2 Hadoop 的核心组件
在大数据时代,如何解决大规模海量数据存储和分析是关键,而Hadoop 项目作为大数据处理的框架,其核心功能就是分布式存储(HDFS) 和分布式计算(MapReduce)以及资源管理调度器(YARN),下文介绍Hadoop 的核心功能。
(1)分布式文件存储HDFS。
HDFS 源于Google 发表的一篇GFS 的论文,是描述Google 内部的一个叫做GFS 的分布式大规模文件系统,其具有强大的可伸缩性和容错性,之后DougCutting 以GFS 的论文思想为基础,开发出了一个新的文件系统叫HDFS,并在此基础上形成了一个单独的子项目,最终成为Hadoop 的核心组件之一。作为大数据生态最底层的分布式存储文件系统,其主要解决海量数据的存储问题,HDFS 将数据存储在物理分散的多个存储节点上,然后对这些节点的资源进行统一的管理与分配,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
(2)分布式计算MapReduce。
作为Hadoop 生态的分布式计算组件,MapReduce是一种并行编程模式,采用了分而治之的思想———先分后合,适用于大规模数据的并行处理,其工作原理是将待求解的复杂计算问题,先分解成若干规模较小的问题,然后分别求得各部分的结果,把各部分的结果进行合并, 最后得到整个问题的最终结果。
MapReduce 的特点是易于编程,具有良好的扩展性和高容错性, 适合大规模海量数据的离线处理。
MapReduce 的核心思想是Map 和Reduce,它们分别对应map 函数和reduce 函数,这2 个函数由应用程序开发者负责具体实现,开发者仅需要编写少量的业务逻辑代码,不需要处理其他应用方面的各种复杂问题,如数据存储、资源调度、容错处理、结果收集、网络通信等,这些问题全部由MapReduce 框架负责处理。需注意的是,并不是所有任务都适合用MapReduce,能用MapReduce 来处理的任务有一个基本要求,即待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
3 Hadoop 生态圈
3.1 Hadoop 生态圈组件
Hadoop 是一个分布式系统基础架构,其利用分布式集群对海量数据进行高速并行运算以及存储,开发人员在进行开发分布式程序中,无需了解分布式底层细节。Hadoop 不是一个孤立的技术,而是一套完整的生态圈,目前Hadoop 生态包含多个组件,除了核心组件HDFS 和MapReduce 及YARN 外,还包括HBase,Hive,YARN,Flume,Sqoop,Zookeeper,Ambari,Oozie,Mahout,Pig 等。
3.2 Hadoop 版本
大数据处理框架Hadoop 的版本经历了Hadoop1.x,Hadoop2.x 以及最新Hadoop3.x 版本。首先,Hadoop11.x 版本到Hadoop12.x 版本变迁的最大变化是对MapReduce 进行了大的拆分,Hadoop1.x 主要由MapReduce(分布式计算)和HDFS(分布式存储)构成,Hadoop2.x 在第1 代版本的基础上演变而来,在此基础上增加了YARN(资源调度管理系统)以及其他的一些组件,主要解决了Hadoop1.x 中MapReduce和HDFS 中存在的各种问题,如MapReduce 在扩展性和多框架方面支持不足等。在Hadoop2.x 时代增加的YARN 组件不仅支持MapReduce,还支持其他的计算框架,其具有较好的扩展性、可用性及向后兼容性等,如兼容支持后来的Spark,Flink 等框架。
Hadoop3.x 架构组件和Hadoop2.x 架构组件类似,Hadoop3. x 着重于性能优化。从Hadoop2. x 到Hadoop3.x 版本,构架组件已经没有太大的改变,Hadoop3.x 增加了许多新特性,如支持cup 的多重运算、多重备份,而且内部的数据还支持动态平衡,提高了存储效率,采用了纠删码存储等,主要性能优化有以下几个方面。
(1)通用方面:精简内核、类路径隔离、shell 脚本重构。
( 2)HDFS 存储方面:支持EC(Erasure Code)纠删码、支持多NameNode。
(3)MapReduce 计算方面:任务本地化优化、内存参数自动推断。
(4) Hadoop YARN 时间线服务方面:Hadoop3.x采用TimelineServiceV2 时间线版本服务,具有分布式写入器体系结构和可扩展的后端存储,并将数据的写入与读取分开,具有更强的可伸缩性、队列配置、可靠性等。
4 大数据计算架构
4.1 离线计算架构
离线计算是指对海量静态数据进行处理和分析,并产生相应的数据结果,供下一步数据应用使用的过程。其特点是处理时间要求不高,处理数据量大,处理格式多样, 占用计算存储资源多, 通常使用MapReduce,Spark,Spark SQL 等计算框架,以HDFS 为数据存储,YARN 为资源调度引擎,为各种离线批处理引擎提供资源调度能力,实现了多租户资源分配的基础。根据数据来源到应用的流程,可以将离线处理架构分为数据源、数据采集、离线处理引擎、业务应用层[3] 。
(1) 数据源:数据源的种类包括流式数据(如Socket 数据流),文件数据库等。
(2)数据采集系统:Flume 用于批量采集数据文件、日志文件,Sqoop 用于批量采集数据库的数据,第三方ETL 采集工具用于数据采集加载转换。
(3) 离线处理引擎:离线处理的引擎有Hive,Spark SQL,MapReduce,Spark。Hive 使用传统SQL 批处理引擎,用于处理SQL 类批处理作业,在处理海量数据时表现稳定,但处理速度较慢。MapReduce 为传统批处理引擎,用于处理非SQL 类,其广泛应用于数据挖掘和机器学习类的批处理作业,在处理海量数据时表现稳定,但处理速度较慢。Spark SQL 为新型SQL 批处理引擎,用于处理SQL 类批处理作业,相较于MapReduce,其处理速度较快。Spark 为新型批处理引擎,用于处理非SQL 类,以及数据挖掘和机器学习类的批处理作业,处理速度较快。一般推荐优先采用Spark/ Spark SQL, 当有存量应用时可以使用MapReduce/ Hive,2 种处理引擎也可以同时使用。
4.2 实时计算架构
实时计算是指数据从生成到实时采集、实时缓存、实时计算分析、实时展示应用等处理流程,完成时间在秒级甚至毫秒级。其特点是处理速度快,且要求端到端的处理速度需要达到秒级,甚至毫秒级。实时计算架构分成数据源、数据采集、实时计算处理引擎、业务应用层。
(1)数据源:包括关系型数据库数据、实时数据流、实时文件数据。
(2)数据采集:实时采集数据源产生的数据,并将数据缓存到分布式消息系统Kafka 中,通过实时采集工具Kafka 和第三方采集工具(如GoldenGate 数据库)实时采集与定制化实时采集数据。
(3) 实时处理引擎:实时处理引擎包括SparkStreaming,Structured Streaming,Flink,Storm,其主要作用是对实时数据进行快速分析。Structured Streaming是基于Spark 的流处理引擎,支持秒以内的流处理分析;Flink 是新一代流处理引擎,支持毫秒级的流处理分析;Spark Streaming 以Spark Core 为基础,提供数据的流式计算功能,支持秒以内的流处理分析;Storm 是一个事件驱动的实时流计算框架,支持毫秒级以内的流处理分析。一般根据实际需求,选择不同的流计算引擎。
( 4)实时应用:数据应用是大数据技术和应用的目标。大数据实时计算架构为大数据的实时业务应用提供了一种通用的架构,其需要根据行业领域、公司技术积累以及业务场景等,对业务需求、产品设计、技术选型到实现方案流程等进行具体问题具体分析,并应用大数据可视化技术,对其进行深入研究,最终形成更为明确的应用标准。
5 重型装备制造业大数据技术解决方案
通过构建统一的大数据共享和分析平台,对重型机械装备制造企业各类业务进行前瞻性预测及分析,为集团各层次用户提供统一的决策分析支持,同時可以提高数据的共享与流转、交换能力。
5.1 总体解决方案
重型机械装备制造企业大数据平台主要实现以下几方面的应用。
(1)实现数据共享。通过数据平台实现数据集中,确保企业集团各级部门均可在保证数据隐私和安全的前提下使用数据,充分发挥数据作为企业重要资产的业务价值。
(2)加强业务协作。各个业务系统中的数据在数据平台中进行整合,建立产品、客户等数据的企业级视图,有效促进业务的集成和协作,并为企业级分析、销售提供基础。
(3)促進业务及管理创新。企业集团营销人员可以基于明细、可信的数据,进行多维分析和数据挖掘,为企业业务及管理创新创造有利条件。
(4)改善数据质量。从中长期看,数据仓库对企业分散在各个业务系统中的数据进行整合、清洗,有助于改善企业整体数据质量,提高数据的实用性。
(5)提升企业数字化、智能化建设效率。通过大数据平台对数据进行集中,为管理分析、挖掘预测类等系统提供一致的数据基础,改变现有系统数据来源多、数据处理复杂的现状,实现应用系统建设模式的转变,提升相关IT 系统的建设和运行效率。
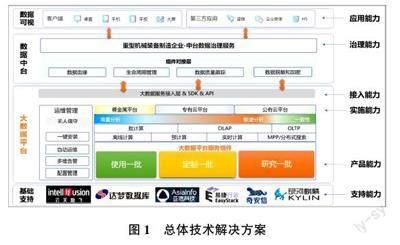
本文提出的重型机械装备制造企业大数据平台架构是基于信创龙头企业“中国电子”的产品线。其主要产品有大数据基础平台、数据中台,如图1 所示。
5.2 大数据基础平台技术架构
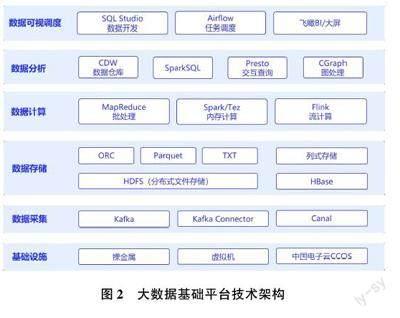
将中国电子的大数据基础平台产品作为解决方案,该公司产品“大数据基础平台”兼容Hadoop 等主流开源存储与计算引擎、兼容市面上常见的商用大数据基础平台,最大化兼容目标企业已有的大数据平台体系,充分利旧、保护投资[4] 。大数据基础平台技术架构如图2 所示。
5.3 数据中台技术架构
在大数据平台总体架构中,作为技术解决方案架构中的核心产品,数据中台部署于IAAS 层、PAAS 层之上和应用体系之下,处于企业的数字化转型总体架构中的底座位置。数据中台是大型企业总体IT 架构中的核心,该产品是构建数据资产中心的一站式数据技术工具,是支撑各类数据应用建设的基础服务体系,将长期承载着大型企业的数据资产统一运营,提供螺旋向上的数据治理与数据价值发挥的能力。数据中台技术架构如图3 所示。
6 结束语
本文从研究背景、问题的提出,再到具体技术架构的研究,对Hadoop 大数据平台及生态圈、Spark 技术架构、大数据离线计算架构、实时计算架构进行阐述,并提出了重型机械装备制造企业以信创龙头企业的产品线为基础的大数据平台技术解决方案,旨在为重型机械装备制造业大数据平台的构建提供参考。
参考文献:
[1] 卢滢.大数据技术在智慧工程中的应用[J].电子技术与软件工程,2022(2):208⁃211.
[2] 黄硕.省级广电网络大数据平台设计与建设[J].广播与电视技术,2022,49(6):81⁃85.
[3] 凌诺娟.云农场智慧服务大数据平台研究与实现[D].合肥:安徽农业大学,2022.
[4] 中国电子技术标准化研究院.大数据平台技术白皮书[R].北京:中国电子系统技术有限公司,2021.
作者简介:汪忆(1981—),硕士,高级工程师,研究方向:大数据技术、人工智能技术、机械装备制造业信息化、高等职业教育。
